Меня зовут Сергей Сковпин, я – руководитель отдела архитектурных решений 1С в компании Самокат. И сегодня я бы хотел поговорить про недооцененный на мой взгляд инструмент – хранилище запросов для MS SQL Server.

Почему я решил сделать этот доклад?
-
По результатам многочисленных собеседований с администраторами и экспертами 1С я увидел, что хранилищем запросов пользуются очень мало людей. Большинство вообще не знают, что это такое – хотя хранилище запросов существует с версии MS SQL 2016. Эту гипотезу подтверждает тот факт, что на Инфостарте практически нет информации об использовании хранилища запросов. Это большое упущение.
-
Конечно, в современных реалиях рассказ про инструменты для MS SQL может показаться неактуальным. Но забывать про MS SQL рано – еще много компаний используют давно купленные лицензии MS SQL, и от них никуда не деться, быстро не съехать. Да и в принципе, зачем закупать что-то новое за много миллионов, если у тебя все работает и покрывает текущие потребности. Поэтому знания по MS SQL будут актуальны еще продолжительное время.
Что такое хранилище запросов в MS SQL

Итак, знакомимся.
-
Механизм хранилища запросов или Query Store – это компонент, который расширяет возможности мониторинга и анализа работы запросов. Он появился в MS SQL 2016 и присутствует во всех более поздних версиях. Если у вас стоит MS SQL версии 2016 или старше, то хранилище запросов у вас есть, оно просто не включено.
-
Хранилище запросов входит в состав MS SQL Server независимо от редакции – Express, Standard, Enterprise.
-
Оно не требует никакой дополнительной установки.
-
И минимально влияет на нагрузку всей системы.

Хранилище запросов – это готовая подсистема, которая:
-
Собирает для вас статистику выполнения запросов; статистику использования ими ресурсов вашего сервера; статистику ожиданий; статистику использования планов запросов. Она все это аккуратно собирает и хранит.
-
Вдобавок к этому она предоставляет хороший и достаточно мощный инструмент для анализа накопленной статистики.
-
С хранилищем запросов становится проще анализировать, что пошло не так – почему возникло большое потребление памяти, процессора, диска или еще что-нибудь.
-
Также особенность хранилища запросов – это возможность принудительно указать план запросов, который вы хотите, чтобы использовался при их выполнении. Об этом чуть позже расскажу. Это важная и полезная штука, но с нюансами.
Как включить и настроить
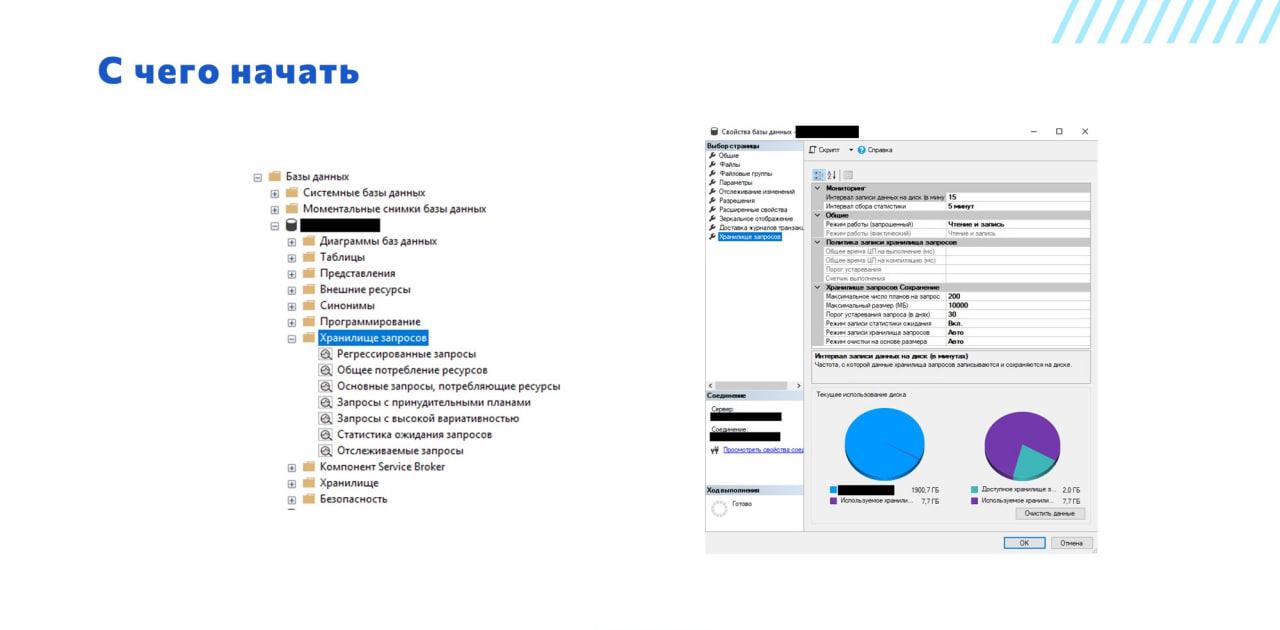
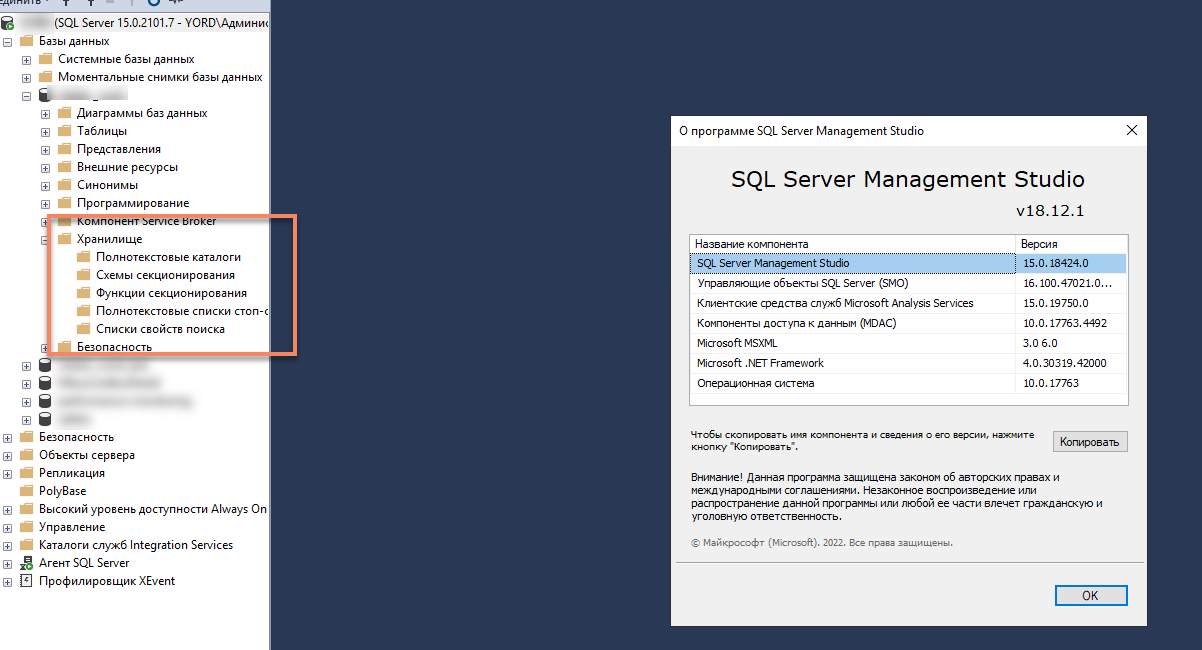
В дереве метаданных MS SQL в Management Studio хранилище запросов лежит в ветке самой базы.
Почему в ветке базы? Потому что хранилище запросов настраивается индивидуально под каждую базу. В нем хранятся все метрики, которые MS SQL Server собирает по запросам к этой базе.
По умолчанию хранилище запросов выключено, и этой чудной папки с объектами хранилища запросов в дереве метаданных MS SQL нет. Чтобы она появилась, его нужно включить.
Чтобы его включить, нужно зайти в настройки базы (скриншот справа). Нижний пункт в настройках так и называется «Хранилище запросов» – там есть немного настроек и парочка диаграмм на тему того, как на данный момент хранилище запросов использует ваше дисковое пространство.

Подробнее про настройки.
-
Чтобы начать использовать хранилище запросов, его, очевидно, нужно включить. Для этого идем в настройки хранилища запросов и ищем параметр «Режим работы (запрошенный)». Чтобы все заработало, нужно перевести его в значение «Чтение и запись» Как только мы это сделаем, хранилище начнет работать и собирать статистику.
-
Сразу укажите параметр «Максимальный размер (МБ)» – сколько места вы разрешаете выделить под хранилище запросов. Оно не съедает все доступное место, оно ест ровно столько, сколько вы ему разрешили. Когда хранилище запросов упирается в этот потолок, оно просто выключается и переходит в режим «Только для чтения» – ничего нового не запишет.
-
Еще важным моментом может быть указание параметра «Порог устаревания запроса (в днях)» – по умолчанию это 30 дней. Порог устаревания означает глубину хранения вашей статистики – через какой промежуток времени она начнет удаляться. Просто посмотрите и имейте в виду, что у вас установлено такое значение, чтобы потом не было вопросов – куда делись мои статистики.
Как только вы заполните эти три параметра – режим работы, объем диска и глубину хранения – вы, в принципе, закончите с настройкой хранилища запросов. Нажимаете ОК, и все, оно работает. Поздравляю, вы счастливый обладатель отличной подсистемы для анализа и мониторинга.
Давайте быстро пробежимся по остальным настройкам:
-
Интервал записи данных на диск (в минутах). В своей работе хранилище запросов собирает статистику первоначально в оперативной памяти. Оно не сразу пишет все на диск, оно сначала аккумулирует данные в оперативной памяти, после чего записывает на диск. Этот параметр как раз отвечает за то, как часто данные будут выгружаться из памяти на диск. По умолчанию – раз в 15 минут. Если хотите, можно поставить чаще, тогда у вас диск начнет чуть больше использоваться.
-
Интервал сбора статистики – тоже важный параметр, отвечает за то, как статистика у вас будет храниться в самом хранилище запросов в базе данных. Значение по умолчанию – 1 час. Это означает, что для каждого запроса данные будут агрегироваться по одному часу – на 1 час времени одна запись для этого запроса. Можно уменьшить – установить 30 минут, 15 минут, 5 минут, 1 минута, но ожидайте, что вы кратно увеличите место под тот объем статистики, который вы хотите иметь под рукой. И вдобавок увеличится время на то, чтобы построить какой-нибудь запрос, потому что им придется собирать и агрегировать больше данных.
-
Максимальное число планов на запрос – по умолчанию 200. Мы здесь проблем никогда не имели – это сколько планов будет храниться на один запрос в хранилище до того момента, пока он скажет: «Ой слишком много, я перехожу в режим чтения»
-
Режим записи статистики ожидания – по умолчанию включен. Параметр отвечает за то, будет ли хранилище запросов в себе сохранять информацию о том, какие ожидания этот запрос поймали. По умолчанию включен, не вижу смысла его отключать.
-
Режим записи хранилища запросов – по умолчанию «Авто». Интересный режим, который показывает, какие запросы мы будем сохранять к себе в хранилище запросов. «Авто» означает, что хранилище запросов не будет сохранять незначительные и редко вызываемые запросы. Как он их определяет – загадка. Но это, в принципе, нормальная история, помогает немного сократить время. По умолчанию стоит именно «Авто», можно включить вообще все либо можно все выключить – тогда у вас вообще ничего писаться не будет.
-
Режим очистки на основе размера – по умолчанию «Авто». Этот режим означает, что, когда у вас место, отведенное под хранилище запросов, будет заканчиваться, хранилище запросов начнет автоматически удалять старые записи. Это важный и нужный параметр, чтобы у вас хранилище запросов не ушло в режим «Только для чтения», если вы не заметили, что под него изначально было выделено мало места.
-
Плюс в серединке есть отдельный блок, который называется «Политика записи в хранилище запросов». Интересная штука, позволяет вручную задать показатели, по которым хранилище запросов будет понимать, что вот этот запрос мы сохраняем, а вот эти нам не нужны. Чтобы эти показатели разблокировались, нужно перевести «Режим записи хранилища запросов» из «Авто» в «Пользовательский» – тогда можно будет управлять самому, за какими запросами вы хотите приглядывать, а за какими – нет.
В целом в настройке всё. Больше тут ничего особого нет.
Как анализировать собранные данные
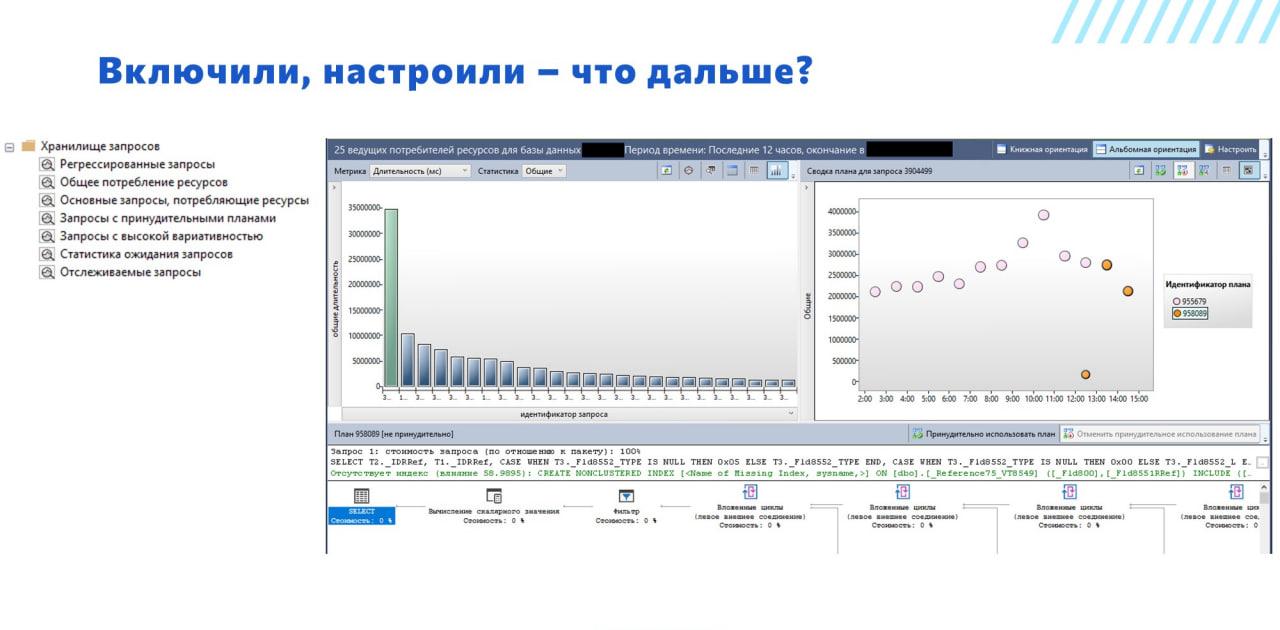
Включили, настроили, что делать дальше?
Во-первых, немного подождать, чтобы статистика насобиралась. В принципе, ждать много не нужно – в зависимости от того, насколько у вас нагружена база. Где-то и 5-минутного интервала достаточно, чтобы уже увидеть первые результаты о том, что какие-то запросы бьют по ресурсам и вываливаются из общей картины.
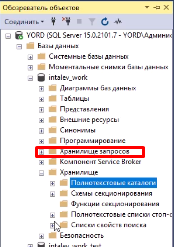
Из меню настроек переходим в папочку «Хранилище запросов» – там, где у нас хранятся преднастроенные отчеты. Их немного, но они очень хорошо покрывают все типовые нужды для работы с этим.
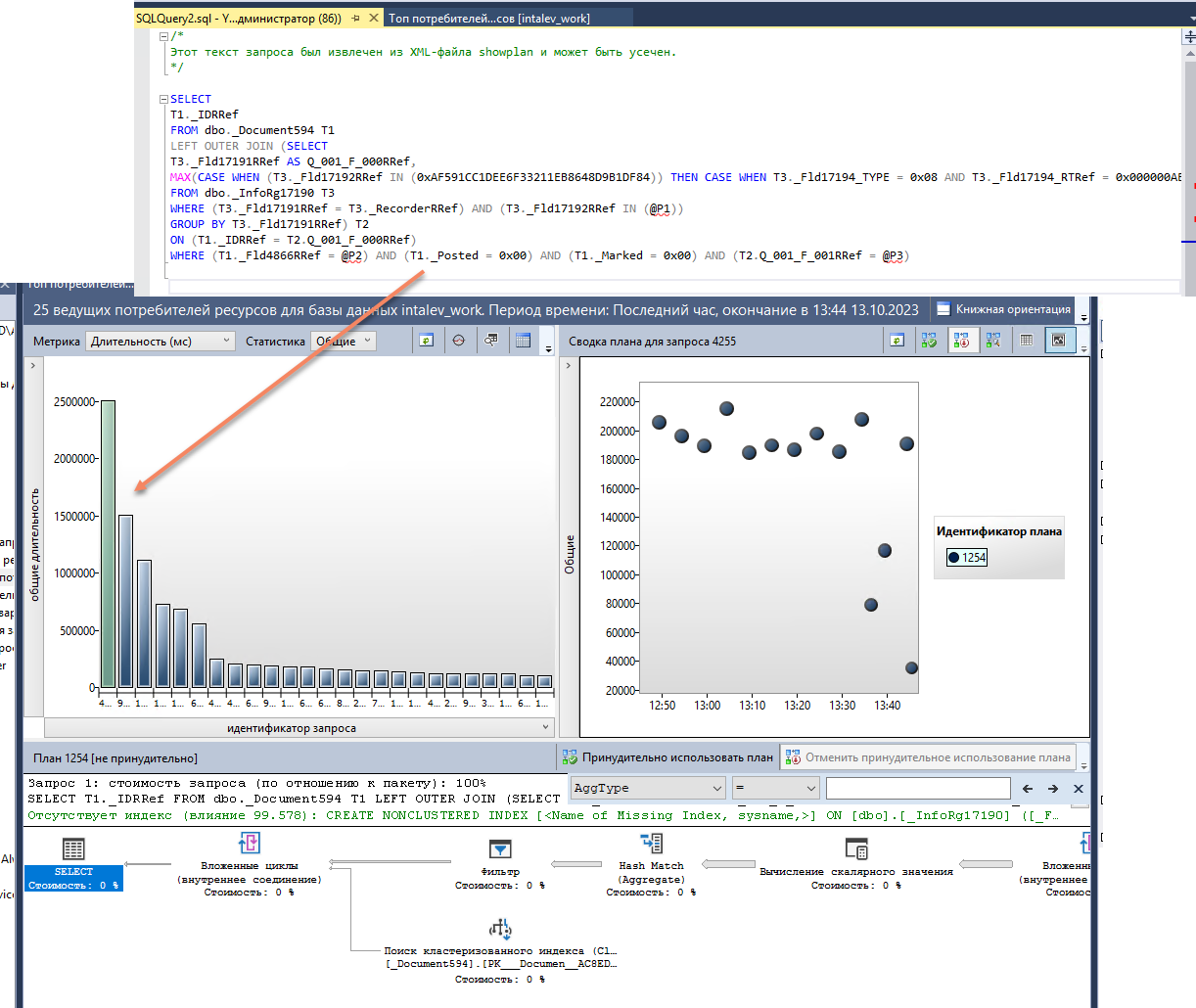
Вот так выглядит окошко с отчетом, который называется «Основные запросы, потребляющие ресурсы»:
-
Слева мы видим диаграмму, которая построена по метрике, выбранной в шапке. В данном случае это «Длительность (мс)», общая длительность выполнения запросов. На диаграмме отображены запросы с указанием того, сколько у них было суммарное время выполнения.
-
Справа мы видим планы запросов, которые были применены в разные моменты времени для выбранного слева запроса. Тут все примерно ровненько – появился новый план, но он не сильно отличается от старого, работает одинаково плохо или одинаково хорошо.
-
Снизу видим текст самого запроса и графическое представление того плана запросов, которые мы выбрали в правой части нашей таблички.
-
Из интересного – тут нас сразу же информируют о том, что у нас отсутствует индекс, и предлагают SQL-код, чтобы его создать. Мы уже давно знаем, что создавать индексы на SQL – это дело плохое, неправильное и порочащее лицензионную политику фирмы «1С». Поэтому мы этим заниматься, конечно, не будем. Но сама по себе информация о том, что нам не хватает каких-то полей, полезна, чтобы проанализировать, как мы можем решить эту проблему через платформенные механизмы.
-
Также здесь есть посередине две кнопки: «Принудительно использовать план» и «Отменить принудительное использование плана». Они позволяют нам управлять используемым планом для запроса. Допустим, здесь на диаграмме справа розовые кружочки – это старый план, а желтые кружочки – это новый план. Если бы розовые кружочки были намного лучше по качеству, мы могли бы выбрать розовый кружочек, нажать «Принудительно использовать план», и для всех этих запросов стал бы принудительно использоваться именно этот план.
Этот инструмент нужен для временного и очень срочного оперативного исправления ситуации. Когда у вас что-то произошло, вы увидели резкую деградацию производительности по запросу и хотите вернуться к тому, как было, и иметь время на то, чтобы спокойно разобраться, почему планировщик начал ошибаться в своих прогнозах.
Использовать, не использовать – спорный момент.
-
Во-первых, нет ничего более постоянного, чем временное. Очень хочется нажать «Принудительно использовать» для старого плана запроса, и дальше не копать. Потом окажется, что запрос поменялся по метаданным, и в итоге он вообще перестанет работать
-
А во-вторых, это спорный момент, потому что мы таким образом уже вторгаемся в область работы СУБД – соответственно, попадаем в сторону пункта о нарушении лицензионного соглашения. В общем, так делать нельзя, потому что мы используем нетиповые механизмы для работы с СУБД. Поэтому не рекомендую. Но знать о том, что такая штука у нас есть, хорошо.
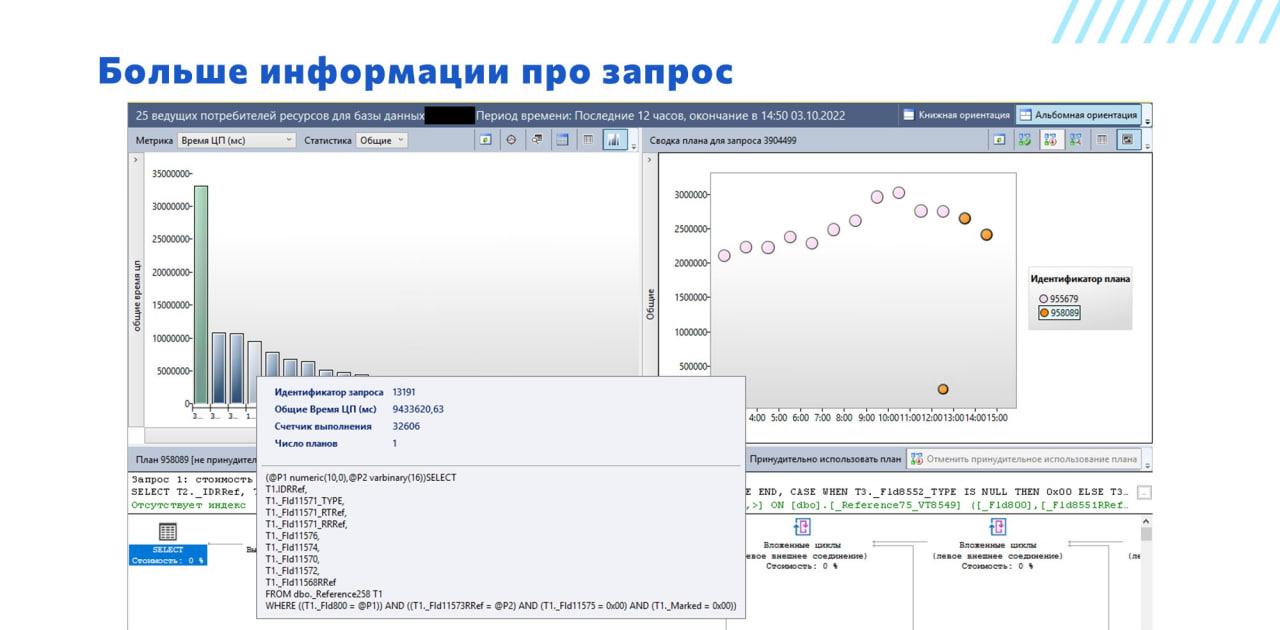
Помимо того, что у нас есть красивые графики по основным запросам, потребляющим ресурсы, мы можем подвести курсор к этим графикам и посмотреть дополнительные показатели – идентификатор запроса, общее время и счетчик выполнения.
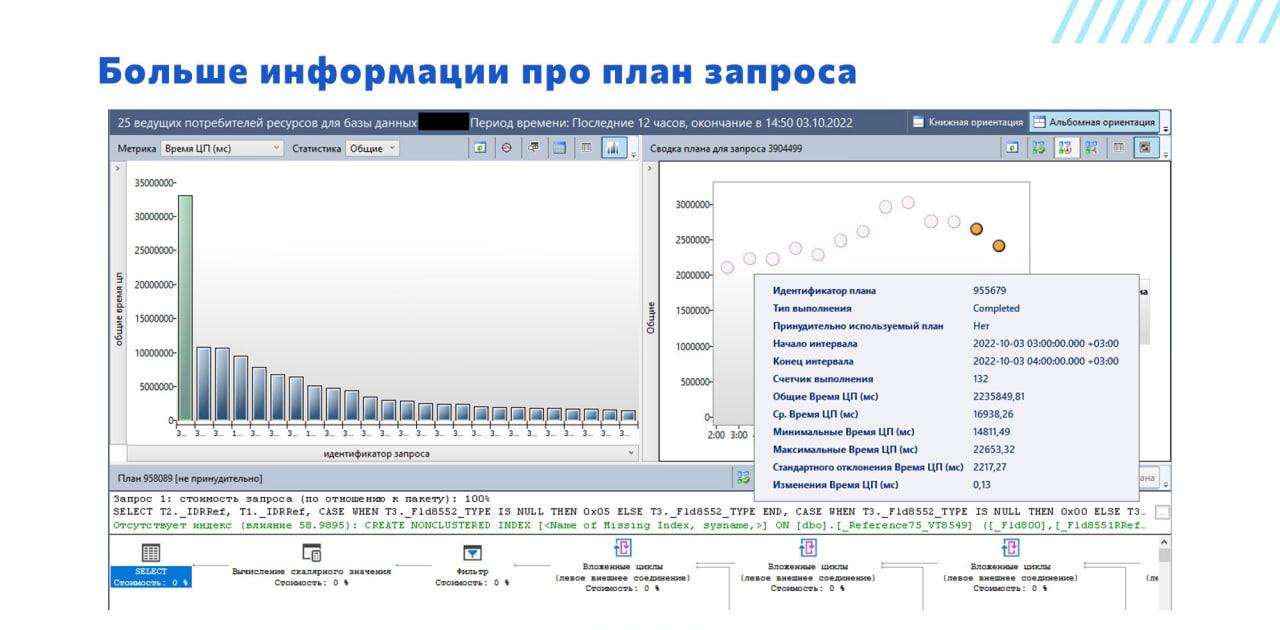
На диаграмме планов запроса мы также можем посмотреть среднее время выполнения, и его пиковые значения. Все это позволяет нам оценить – плохо это или нет.
В примере у нас есть один столбец крайний, который явно выбивается из всего ряда. И мы очень им заинтересовались. Но, возможно, что все в порядке, просто это самый популярный, самый используемый запрос, у которого суммарное время выполнения действительно большое, потому что это – основной запрос нашей системы. Чтобы это определить, мы смотрим на то, как часто он выполняется, какое у нас среднее время выполнения и так далее.
Здесь, кстати, мы поменяли метрику на «Время ЦП» – время использования процессора этим запросом. По сравнению с прошлой картинкой ничего не поменялось, потому что основная работа запроса в данном случае ложилась на плечи процессора.
Возможности готовых отчетов, их показатели
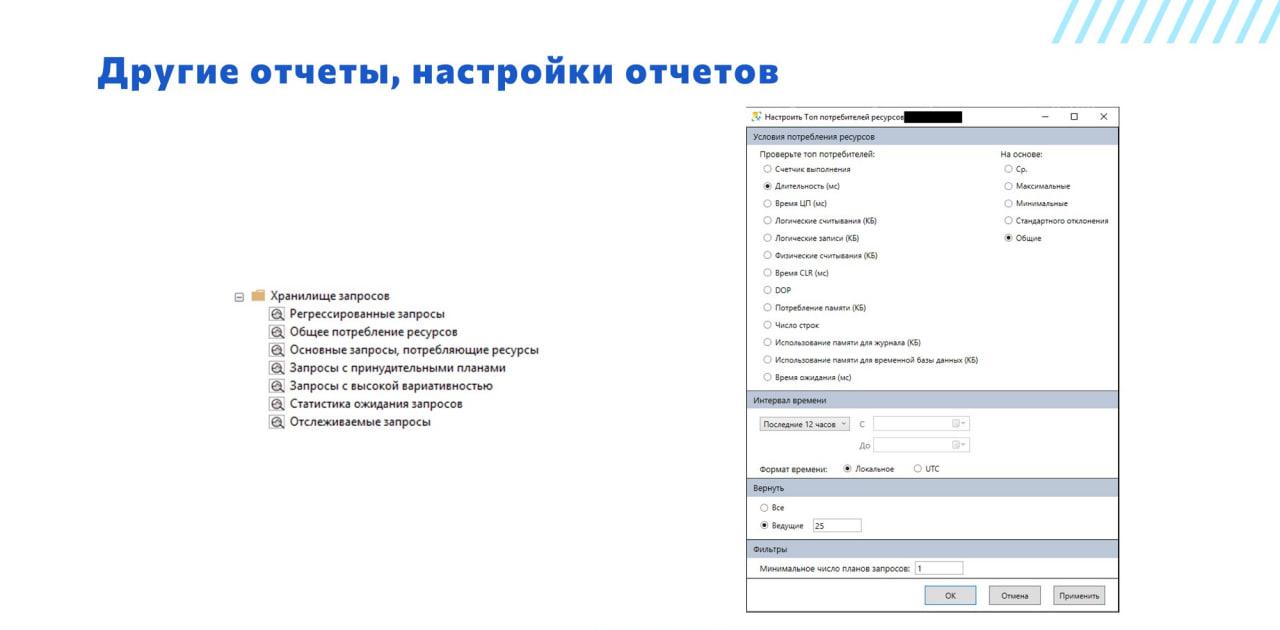
Таких готовых отчетов немного, их буквально семь штук, но у каждого из них есть настройки, которые можно менять, чтобы гибко разбираться, что у нас происходит в операционной системе, на сервере или в самой базе.
На слайде – пример настроек по отчету «Основные запросы, потребляющие ресурсы». Здесь перечислены метрики, которые мы можем смотреть. Это:
-
счетчик выполнения;
-
длительность;
-
потребление процессора;
-
потребление памяти;
-
потребление дисковой подсистемы;
-
работа с tempDB;
-
ожидания и т.д.
В общем, много чего из этого можно вытащить и пользоваться для того, чтобы отслеживать, насколько у вас все хорошо сейчас и разбирать проблему, почему стало внезапно плохо.
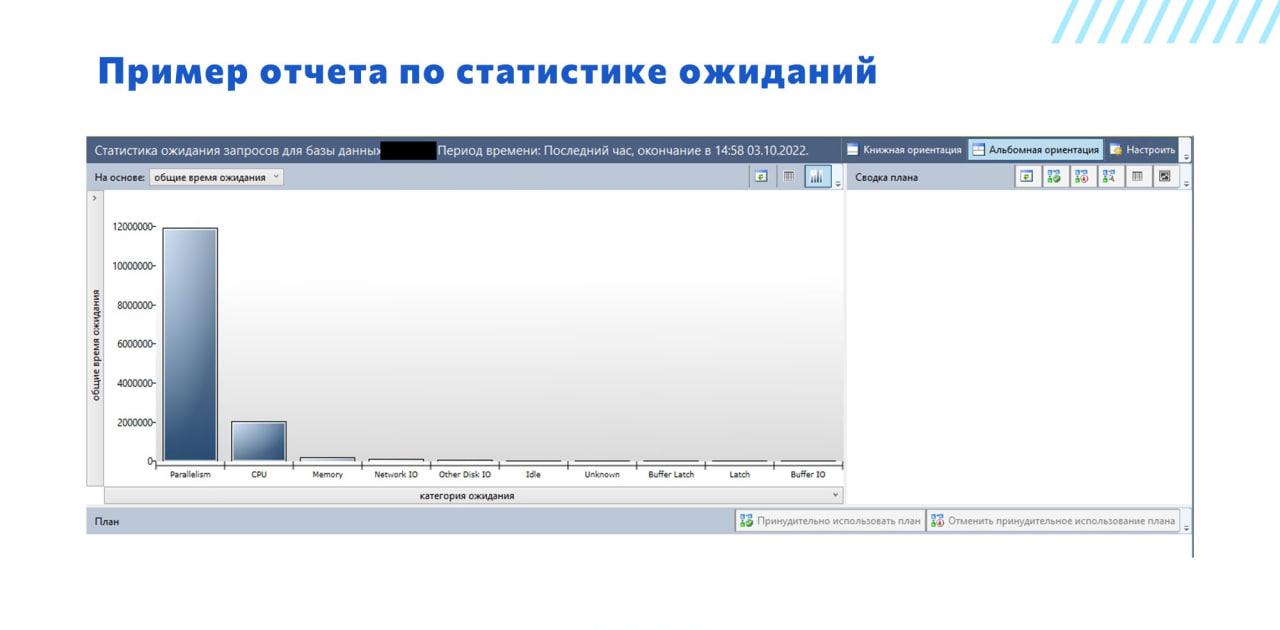
Пробежимся немножко по примерам этих отчетов. То есть, вот пример отчета «Статистика ожидания запросов». Здесь мы видим колонки, которые дают сумму общего времени ожидания, разделенные по видам.
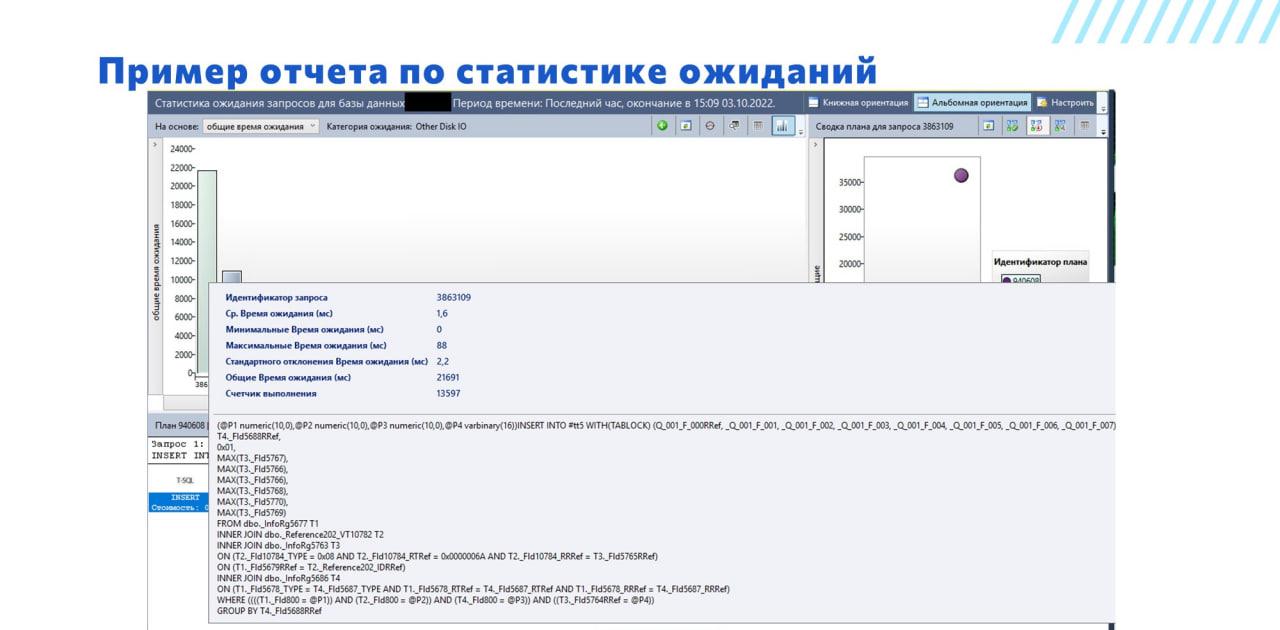
Мы выбираем интересующую нас колонку и получаем подробную информацию по выбранной метрике – в данном случае у нас метрика «Общее время ожидания» на работу с диском.
И смотрим, какие у нас запросы в топе. Возможно, это у нас просто какой-нибудь плохой запрос, который слишком много диска потребляет и мешает нам жить.
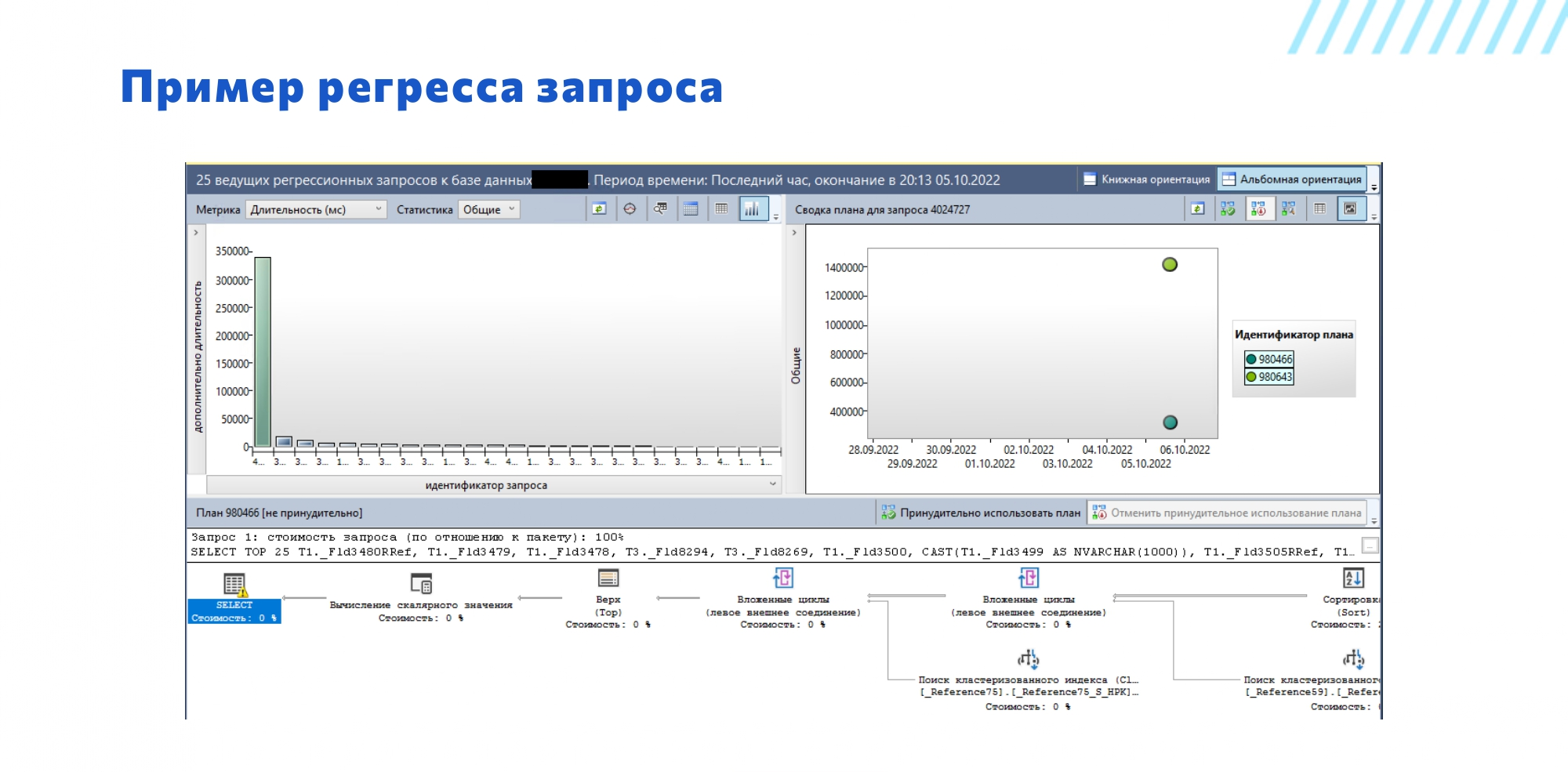
Отдельный интересный отчет – «Регрессированные запросы». Он автоматически анализирует, есть ли у системы такие запросы, у которых изменился план запроса, и при этом старый план был значительно лучше, чем новый. Это готовый типовой отчет, показывающий нам список запросов, в которых планировщик ошибается. И это отличный пример того, как можно заходить и выискивать проблемные кейсы – когда в этом запросе у нас планировщик начал работать хуже.
Например, здесь на слайде мы видим два плана запросов: один снизу, другой сверху. Разница между ними значительная.
Если кому-то не нравятся графики, а больше нравятся циферки, там сверху есть переключатели на табличный вид. Переключайте в табличный вид и получайте всю ту же самую информацию, только уже в виде табличек, где показана дополнительная информация, которая на диаграмме выводится во всплывающих окошках. Если вам так удобно – пожалуйста, работайте.
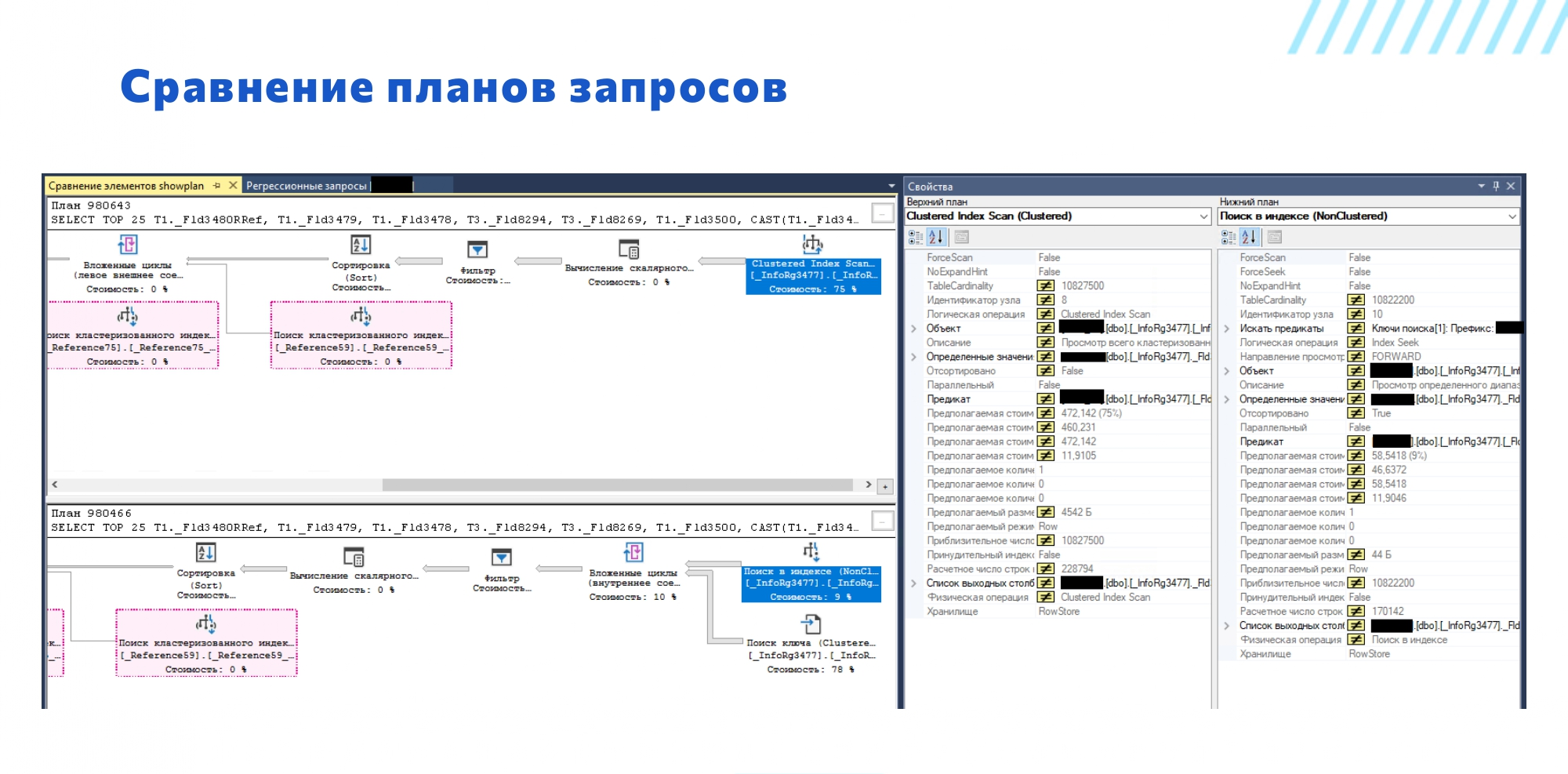
Чтобы провести быстрый анализ, есть инструмент по сравнению планов запроса.
Выбрали два плана запросов, нажали «Сравнить» и получаем графическое представление сравнения, которое подсвечивает одинаковые объекты, но с разными значениями параметров. Выделяем нужные объекты и быстро получаем сравнение их свойств.
Тут ничего супермощного нет, но, чтобы быстро разобраться в том, что в конкретный момент пошло не так, очень даже полезная история. На слайде мы видим, что у нас index seek против index scan – вопросов нет.

Естественно, со всем этим можно работать, используя запрос. Если вам вдруг не хватает предлагаемых стандартных отчетов, и вы хотите построить что-то свое – пожалуйста, стройте, никаких ограничений нет.
На слайде приведен маленький запрос, показывающий текущие настройки и текущее состояние хранилища запросов. Он может быть полезен, чтобы отслеживать состояние хранилища запросов: не упустить, что у него место заканчивается, или что оно перешло в режим «Только для чтения».
Особенно полезное поле здесь – readinly_reason. Это поле, которое показывает нам причину нашего перехода в режим read only. Об этом чуть позже.
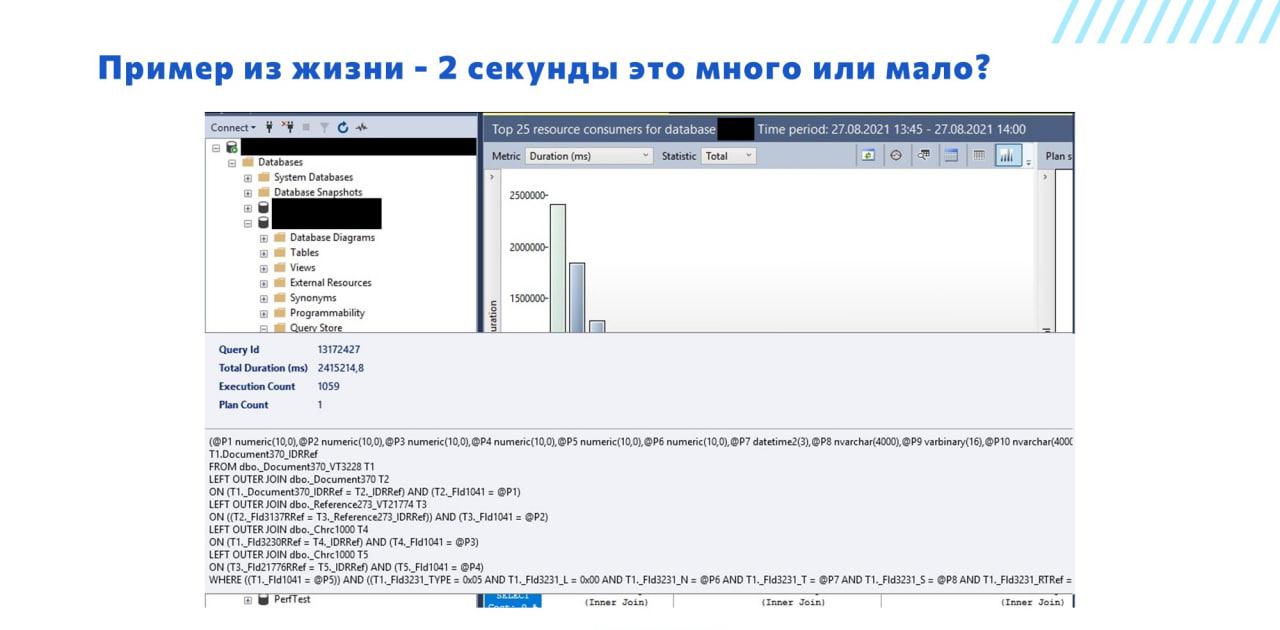
Пример из жизни на тему – 2 секунды это много или мало?
Как видно из скриншота, у нас был запрос, который за 15 минут выполнился 1059 раз. Причем сам запрос был всего лишь 2 секунды, и поскольку сбор логов техжурнала был настроен на события запросов более 5 секунд, там мы его не наблюдали.
С помощью хранилища запросов мы его быстро нашли – увидели, что суммарное время выполнения запроса составило 2415 секунд (40 минут), что практически в 3 раза больше чем период отчета. Из этого можно сделать вывод, что данный запрос загружает 3 ядра процессора на сервере СУБД.
Плюсы и минусы от использования

На слайде приведена цитата из официальной документации Microsoft по хранилищу запросов – оно действительно предоставляет прекрасные возможности для устранения неполадок с минимальным воздействием на обычную рабочую нагрузку.
Хранилище запросов – это очень простой инструмент, который встроен в MS SQL Server, он легко включается, его удобно использовать, и для этого не нужно закапываться в документацию.
Вы включили, в течение одной минуты выбрали настройки, нажали OK – и все, оно у вас работает. Вы можете пользоваться всеми этими благами.
Пожалуйста, используйте, все очень здорово.

Но мы здесь на конференции про жизнь, поэтому небольшая ложка дегтя – с чем мы столкнулись, и с чем, возможно, вы столкнетесь, когда будете использовать хранилище запросов.
-
Первый нюанс – это, конечно же, увеличение размера базы. Тут нужно самим понимать, насколько она будет у вас увеличена, потому что хранилище запросов не превысит тех объемов, которые вы ему разрешили. Нужно держать в голове, что у вас увеличится база, увеличится объем бэкапов, увеличатся размеры тестовых баз. Но этим управляете вы, поэтому выбирайте компромисс, который вам подходит.
-
Второй момент – хранилище запросов может внезапно уйти в режим «Только для чтения». Во-первых, пользуемся запросом, который я показывал, чтобы понять причину, почему оно ушло в этот релиз. Чаще всего у него просто место закончилось, не уследили. Но может оказаться, что на это повлияли какие-то другие вещи. Устраните их, и никаких проблем не будет. Но, чтобы не оказаться в ситуации, когда у вас авария, вы бежите в хранилище запросов и внезапно узнаете, что оно уже неделю нового не пишет, следите за тем, чтобы все было в порядке.
-
Еще у нас была история, когда нам понадобилось очистить хранилище запросов полностью по кнопке «Очистить» в настройках. Оказалось, что это не просто TRUNCATE таблички под ноль, при этом хранилище что-то делает, и это требует времени. На период этого времени проявилась просадка в производительности. Оговорюсь сразу, что это было на нашей основной, самой нагруженной рабочей базе, где хранилище запросов занимало несколько сотен гигабайт. После того как мы столкнулись с такой ситуацией, мы поставили решение в регламент, и теперь занимаемся этой операцией только в наименее нагруженное время суток.
-
Еще одна отдельная история – это увеличение времени на остановку службы. Здесь написано «на перезапуск», но правильнее – на остановку службы. Так как MS SQL Server переживает за то, чтобы все ваши данные были в сохранности, при работе с хранилищем запросов он сначала все хранит в памяти, а потом перегружает на диск. За периодичность этой выгрузки отвечает параметр «Интервал записи данных на диск». Соответственно, прежде чем ваша служба сервера остановится, ей нужно будет весь накопленный объем данных сохранить на диск. При значительных объемах это может потребовать какое-то время. Когда у вас очень сжатое технологическое окно, и даже несколько минут могут сыграть роль, для вас это может оказаться неприятным сюрпризом. Решение здесь – использовать флаг 7745, который отвечает за то, что при остановке службы операция по сохранению данных из оперативной памяти на диск игнорируется. Обратная сторона такого решения – мы теряем данные за этот промежуток времени. Т.е. если у нас данные из оперативной памяти на диск сохраняются каждые 15 минут, значит при остановке службы мы потеряем последние 15 минут статистики.
-
А последний интересный момент – это история о том, что при старте службы сервера хранилище запросов пытается начать работать с самого начала и не пропустить ни одного запроса, который будет обращен к базе данных – всю статистику по ним сохранить. Но для корректного подсчета ему нужны какие-то данные из диска, и в итоге при запуске службы он начинает эти данные из дисков подтягивать. Это может занять продолжительное время – в зависимости от того, насколько у вас большое хранилище, насколько у вас нагруженная база. По итогу вы видите большую просадку в производительности: некоторые запросы могут вообще не отрабатывать, а некоторые – начнут отрабатывать с большими задержками. А все потому, что они ждут, когда Query Store разрешит им нормально работать. Он им говорит: «Ребята, подождите, вы не выполнитесь, пока я сам полностью не загружусь. Вот когда я подготовлю все нужные мне данные, тогда у вас все будет хорошо». Мы у себя наблюдали, что он там полчаса что-то подгружал. И в течение этого получаса мы не могли полноценно работать. Если у вас это плановый перезапуск службы в какое-нибудь ненагруженное время – хорошо. Но если у вас авария или сжатое тех. окно, и вы службу поднимаете внезапно, это для вас может стать большой проблемой. Решение – это флаг 7752, который включает асинхронный режим загрузки Query Store. Он означает примерно обратное от прошлого флага – Query Store будет спокойно запускаться и точно так же будет подгружать данные из дисков в оперативную память, но, пока он это будет делать, он будет в режиме только для чтения и не будет мешать запросам выполняться. Как только Query Store перейдет в свое рабочее состояние, он переключится на режим записи, и все будет хорошо. В таком режиме вы после старта службы опять будете иметь небольшое окошко потерянной статистики. Критично для вас это или нет – решайте сами.
На этом, в принципе, с нюансами все. Как можно заметить, ничего фатального нет. Особенно, если знать, к чему готовиться.
И опять-таки отдельная ремарка, что все эти проблемы у нас проявлялись только на самой большой и нагруженной базе. На всех остальных наших базах, где данных, меньше двух терабайт, мы ни с чем подобным не сталкивались. Поэтому сильно не переживайте.
Вопросы
1С очень активно использует tempDB, а к нему можно применить хранилище запросов?
Хранилище запросов на tempDB включить нельзя. Только к базам. На tempDB в свойствах вы этого вообще не увидите в графическом интерфейсе. Можете попробовать командой SQL выполнить инструкцию для включения хранилища запросов, но получите ответ о том, что на tempDB это сделать нельзя.
Т.е. проанализировать полный цикл запроса не получится?
В tempDB нельзя анализировать статистику использования с помощью хранилища запросов. Но при этом там есть статистика использования самого tempDB. Например, если вы хотите понять, кто отжирает tempDB – почему она постоянно то пухнет, то пустеет – вам это поможет.
Выбираете настройку топ-потребителей ресурсов, выбираете метрику использования файла tempDB и смотрите в интересующий вас промежуток времени – какие были самые прожорливые запросы. Ну и дальше, собственно, их разматываете и анализируете.
Поскольку tempDB каждый раз формирует разный состав таблиц, там можно анализировать только, использовался tempDB или нет. Больше вы там ничего особо найдете, потому что таблица каждый раз создается новая, ей даже привязаться не к чему.
Так как хранилище запросов лежит в той же базе, что и 1С, не будет ли являться нарушением лицензионной политики, по аналогии, как если бы мы индексы сами строили?
Я за то, что нет, потому что это никак не влияет на работу самих запросов, никак не влияет на структуру хранения самой 1С. Это просто нечто, лежащее рядом. Система мониторинга. Это только если за уши притягивать, то можно в эту сторону пойти.
На этот вопрос вам ответит только фирма «1С», вы можете им написать письмо. Вообще, если формально читать, что является, то скорее всего скажут, что нарушение – вы не средствами 1С лезете в структуру базы данных, так нельзя. Это если формально. Но, возможно, они сделают исключение.
У нас есть динамические представления (DMV-шки), есть трассировка, а вот этот инструмент – это их развитие или аналог? В чем его преимущество перед тем, что мы собираем теми же DMV-шками и трассировкой?
Да, в некоем виде это аналог. Но если вы захотите собирать статистику с помощью DMV-шек, вам нужно будет запускать джобу, которая будет проверять состояние DMV-шки с таким-то интервалом, писать его в какую-то таблицу, потом к этой таблице обращаться, как-нибудь ее визуализировать.
А это – уже готовый инструмент, который двумя кликами настраивается. Это не замена и не альтернатива, это что-то рядом.
Это не отменяет использование DMV-шек. С DMV-шками вы можете делать, что хотите – точечно высматривать, что вам нужно.
А здесь же вы просто включаете комплексный мониторинг и сбор статистики по тому, как у вас система работала.
Есть ли какие-то специфичные правила написания запросов, чтобы этот механизм эффективнее работал?
Этому механизму без разницы, какие у вас запросы, как вы их пишете. Он ими не управляет, он их просто отслеживает.
Написали плохой запрос – он записал в статистику, что запрос потребил такое-то количество ресурсов и выполнялся столько-то. Написали хороший запрос – он записал его в статистику, что он отработал хорошо.
С точки зрения разработки здесь нет вообще никаких нюансов или историй, на что нужно было бы обращать внимание.
Если в запросе 1С одновременно используется таблица из базы данных и временная таблица, механизм хранилища запросов использовать нельзя?
Механизм хранилища запросов будет работать. Но когда это поедет в MS SQL, это будет разбито на два запроса – один запрос на то, чтобы что-нибудь получить и засунуть во временную таблицу, второй запрос – на то, чтобы что-то из временной таблицы взять и как-нибудь обработать.
Т.е. в хранилище запросов итоговый запрос будет разбит на кусочки. И, возможно, будет сложно определить, что это за запрос – придется искать соответствие по технологическому журналу.
Но в хранилище запросов фиксируются все запросы – без разницы, есть там временная таблица или нет.
Но ведь имена временных таблиц будут каждый раз отличаться – их платформа так генерирует. И, по сути, агрегации не произойдет. Т.е. мы, может быть, не заметим проблемный вопрос.
Хороший вопрос, надо над ним подумать.
Как применять хранилище запросов в повседневной работе? Ведь при наличии достаточно подробного технологического журнала и журнала регистрации все задачи мониторинга и сбора статистики использования запросов решаются без хранилища запросов. Может, у вас есть какие-то примеры задач, которые можно решить только с его помощью?
Применение здесь понятно – мы можем найти запросы, потребляющие больше всего ресурсов.
Мы можем ежедневно заглядывать, что было вчера, насколько у нас сейчас все в порядке.
Это нормально, если мы в рамках дежурства приглядываем за этими графиками, уже выучили, какие запросы у нас в топе. Если внезапно в десятке появляется что-то новое, мы можем оперативно разобраться.
Потом, когда мы что-то меняем в системе, мы можем сравнить, какая производительность, какие показатели работы СУБД, у нас были раньше. И что у нас есть сейчас. Получить дополнительную аналитику.
Это не замена технологическому журналу или каким-то другим вещам, это дополнение.
Мы можем сравнить, какое у нас было потребление ресурсов до релиза и после релиза. Особенно, если это мы говорим про типовой релиз – там много чего изменилось, мы можем поискать какие-то вещи.
Расскажите примеры из вашей жизни, когда резко ухудшался план запроса. Почему это происходило, как решали?
Самое популярное и самое распространенное – это, конечно же, статистика. Внезапно статистика стала неактуальной, и планировщик начал строить совершенно другие показатели.
Бывает еще, что мы используем запрос, у которого есть вложенный подзапрос – и он сначала работал хорошо, а потом начал работать плохо. Причем там нет проблем со статистикой – час назад он работал моментально, а сейчас он отрабатывает по несколько секунд, и у нас в базе все висит.
Здесь история о том, что планировщик иногда ошибается со временными таблицами. И когда размер таблицы доходит до определенного момента, он решает, что нужно поменять seek на scan.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции Infostart Event.


Вступайте в нашу телеграмм-группу Инфостарт