Расскажу о тестировании кода и о существующих инструментах тестирования, которые можно применять при разработке решений 1С.
Начну с теории – я постараюсь, чтобы ее было поменьше и побольше техники.

Тестирование в 1С набирает популярность. Это можно объяснить увеличением сложности решений и взрослением сообщества 1С – потребность в качестве решений признается всеми, а с недавнего времени за это стали готовы платить, этим стали готовы заниматься.
Существует множество видов тестирования, но их можно сгруппировать на три основных категории.
-
Ручное тестирование. Исторически внедрение тестирования всегда начинается с ручных проверок. Сначала сам разработчик проверяет свой код. Потом привлекают аналитиков, консультантов, тестировщиков – они проверяют. И в конце заказчик тоже проверяет, что разработка соответствует его ожиданиям. В большинстве случаев готовое решение на тестовой базе мы проверяем вручную. Минус этого подхода – это длительность и затратность. Понятно, что есть ошибки, и приходится постоянно все заново перепроверять.
-
Автоматизированное тестирование поведения. С появлением в платформе 1С возможностей автоматизированного тестирования – менеджера и клиента тестирования – стали рождаться инструменты, которые предоставляют возможность такой автоматизации. Это известные инструменты семейства Vanessa Behavior – Vanessa ADD и Vanessa Automation, другие инструменты: Тестер, Тестирование 3.0, 1С:Сценарное тестирование и 1С:Тестировщик от фирмы «1С», и так далее. Этих решений очень много, они той или иной степени удобности, кому какой нравится. Но все это – про тестирование поведения, когда мы тестируем именно пользовательские сценарии.
-
Модульное тестирование. Зачастую нам необходимо протестировать отдельные функции. Причем провести этот тест гораздо быстрее – проверять не пользовательскую функциональность, а именно ту самую низовую техническую работу методов, модулей и так далее. Такое тестирование называется модульным или unit-тестированием.

Модульное тестирование – это как раз проверка изолированных методов, общих модулей, подсистем на их корректность, программную функциональность и обыгрывание всех возможных случаев.
В процессе написания таких тестов мы сталкивались с набором сложностей, обходя которые постепенно удавалось прийти к более качественному коду. Этот побочный эффект возникал по ряду причин:
-
Поскольку при покрытии метода тестами нужно обыграть все возможные входные параметры и зайти во все ветки условий, которые есть в этом методе, возникнет потребность его максимально упростить. Даже если у нас хороший правильный метод, но в нем несколько тысяч строк и 50 параметров, количество необходимых ему тестов будет стремиться в бесконечность. Его никогда не получится покрыть полностью – придется его некоторым образом декомпозировать.
-
Плюс в процессе покрытия тестами, скорее всего, придется написать документацию, чтобы понимать, почему тесты не проверяют те или иные сценарии и кейсы. Например, вы сами захотите явно описать в документации, что в этот параметр нужно передавать именно строку – все остальное здесь даже не проверяется.
-
В дальнейшем сопровождать решение становится гораздо проще, потому что оно красивое, аккуратное, ну еще и тестами покрыто – вообще шикарно.

Чтобы писать тесты, нужны инструменты. На слайде я привел известные мне живые инструменты, которые существуют на данный момент.
Первый и наиболее популярный инструмент – это xUnitFor1C и его форк Vanessa ADD, куда он в дальнейшем переехал. Решение содержит обработку-движок и набор обработок, в которых мы реализуем тесты. Плюс имеется некоторое программное API, которое необходимо реализовать в этих тестовых обработках.
Минус фреймворка xUnitFor1C – это как раз использование внешних обработок. Здесь они себя показывают с неудобной стороны, поскольку:
-
код в обработках сложно версионировать;
-
происходит дублирование методов, потому что нет никакого общего модуля;
-
чтобы реализовать для обработок общую функциональность, приходится использовать тайную магию, подгружая код динамически из файлов.
Я сам проходил этот путь, пытался коллегам, особенно молодым, предлагать использовать этот инструментарий, но у всех в процессе возникали сложности, потому что вход туда достаточно тяжел. В результате возникает следующее:
-
система постоянно развивается;
-
контролировать изменения и их связь с тестами в множестве этих разрозненных обработок достаточно проблематично;
-
версионировать бинарники я не хочу;
-
а каждый раз их собирать – слишком затратно.
Следующее решение, уже более позднее, возникло уже после появления EDT, когда Александр Капралов разработал запускатель модульных тестов в виде плагина для EDT.
Этот плагин на основании общих модулей, расположенных в специальном расширении, генерирует специальные фича-файлы, которые при тестировании запускаются с помощью специального шага Vanessa Automation по выполнению произвольного кода.
Решение интересное, но мне оно не подошло:
-
В первую очередь, из-за использования Vanessa Automation – потому что это такой огромный «комбайн», в котором очень много лишнего, чего не должно быть. Повторюсь, модульные тесты должны быть быстрые, мы их должны выполнять очень часто. А затраты на запуск этого «комбайна», на мой взгляд, избыточные.
-
Еще одна проблема этого решения – в том, что оно генерирует в Git-репозитории, контролируемом EDT, несколько тысяч непонятных лишних файлов, которые, по сути, не несут никакой пользы – по факту, они содержат просто вызов метода из общего модуля расширения.
-
Кроме этого, Vanessa Automation – это внешний инструмент, и при написании тестов нужно знать, что у неё там есть внутри. Чтобы узнать, что у неё есть внутри, приходится открывать исходники и пытаться найти в этом классном, но сложноанализируемом для неподготовленного человека инструменте то, что нужно: какой там контекст, где утверждения и так далее. В общем, есть нюансы.
Мы с командой регулярно сравнивали имеющиеся инструменты тестирования с тем, что имеем, но ни один из них нам не подошел. А мы пишем тесты уже почти 10 лет, и на всем протяжении пути разрабатывали различные инструменты, которые помогали нам в этом.
Поскольку интерес к тестам увеличился, а хороших инструментов так и не появилось, мы решили поделиться своими наработками. Правда, выкатить наше исходное решение в паблик по некоторым причинам, увы, не удалось. Поэтому мы портировали все наши наработки в новый инструмент, о котором я и хочу рассказать.
YAxUnit. Идем в направлении JUnit

Решение я назвал YAxUnit – это небольшая отсылка к xUnitFor1C. Архитектурно оно состоит из двух компонент: расширение и плагин для EDT.
Почему расширение?
-
Посредством расширения мы смогли реализовать движок, который содержит всю необходимую функциональность и в дальнейшем может дополняться новыми подсистемами.
-
За счет общих модулей, входящих в состав движка, мы снижаем дублирование кода.
-
Расширение позволяет применять методики мокирования – переопределения функциональности, которая есть в той или иной конфигурации. Об этом я скажу чуть позднее.
Расскажу про особенности YAxUnit:
-
При разработке мы добивались, чтобы тестирование производилось идентично – и в конфигураторе, которым еще многие пользуются, и в EDT, и на CI. Нам было важно, чтобы для запуска тестов в разной среде не нужно было придумывать поверх какие-то дополнительные утилиты.
-
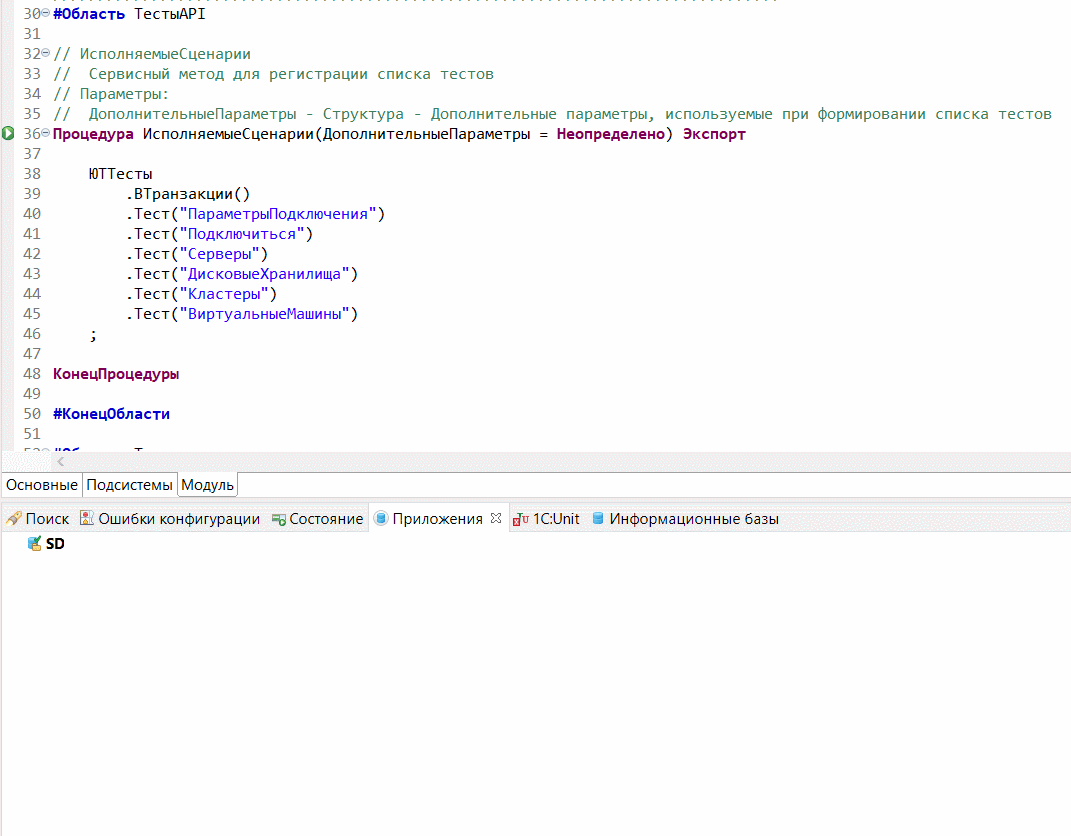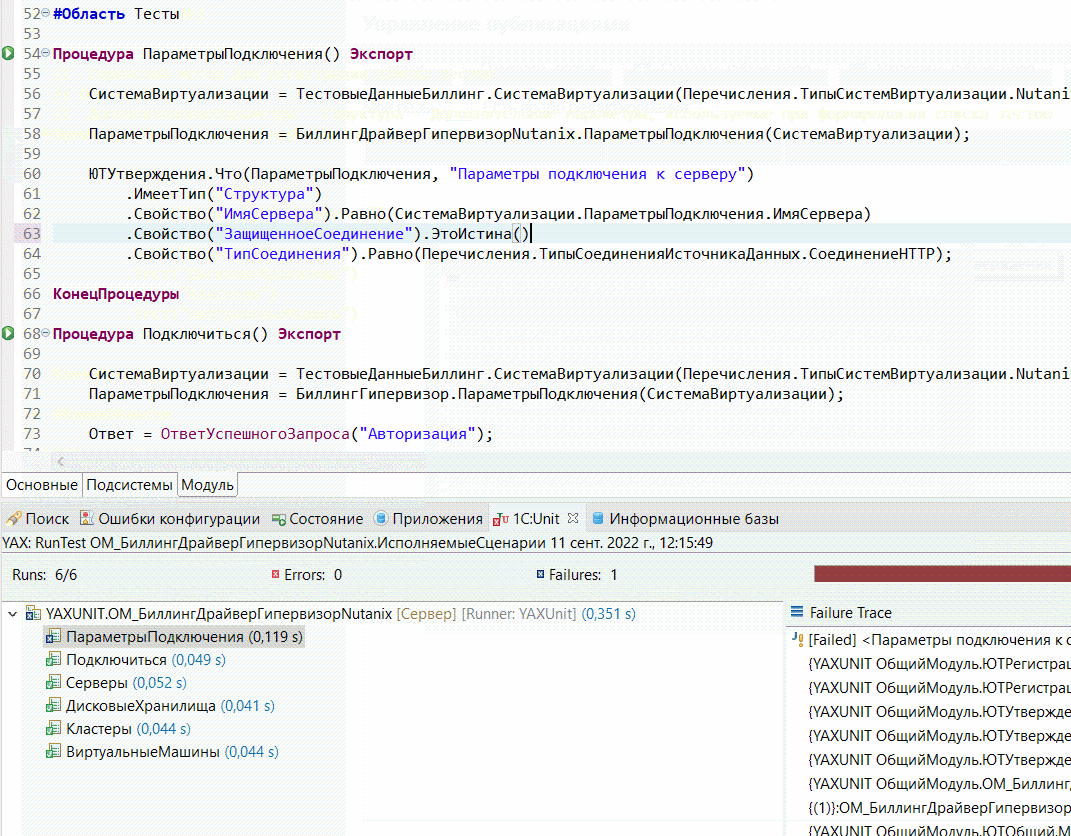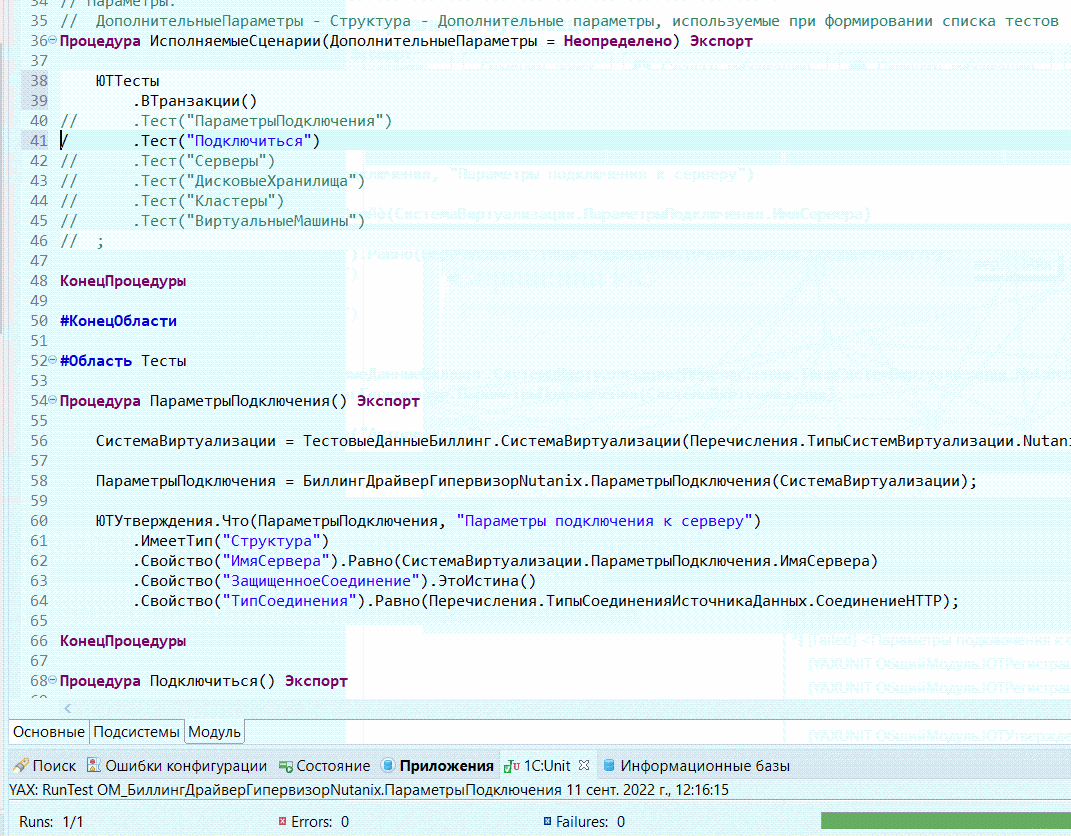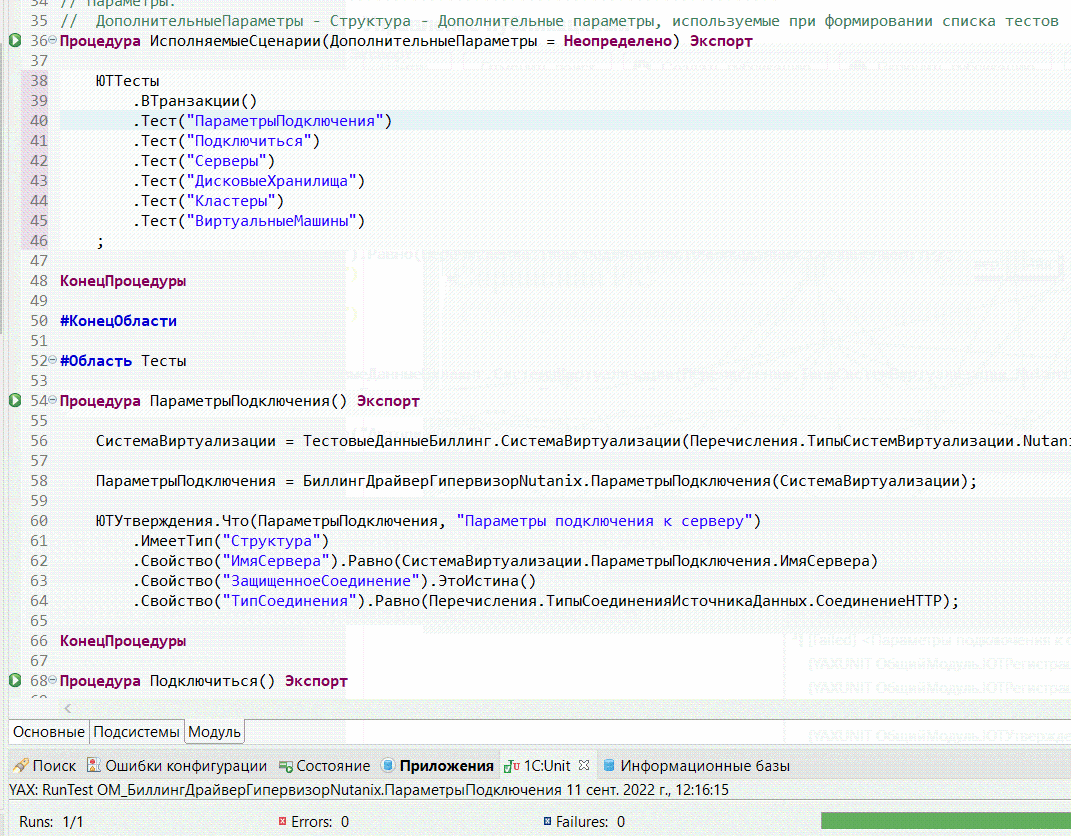
Управление всеми настройками происходит с помощью конфигурационного файла, который можно передавать в параметрах запуска – и для конфигуратора, и для EDT, и для CI.
-
В качестве основной среды разработки мы у себя используем EDT. Эта модная современная среда разработки дает нам достаточное количество плюшек, одна из которых – плагинизация. Спасибо разработчикам EDT, что открыли такую возможность и поддерживают процесс написания плагинов.
-
А раз мы используем EDT, мы решили упростить процесс написания и запуска тестов из среды разработки с помощью плагина. Потому что конфиг-файлом пользоваться, конечно, можно, но неудобно. А тесты хотелось бы запускать как можно более оперативно – сразу же видеть результаты выполнения и использовать многие другие фишки этой модной молодежной IDE.
-
В качестве основы для своей разработки мы использовали готовый плагин для юнит-тестирования JUnit – адаптировали его под работу в EDT.
-
И так получилось, что разработку и сборку плагина для Eclipse мы построили на IntelliJ.
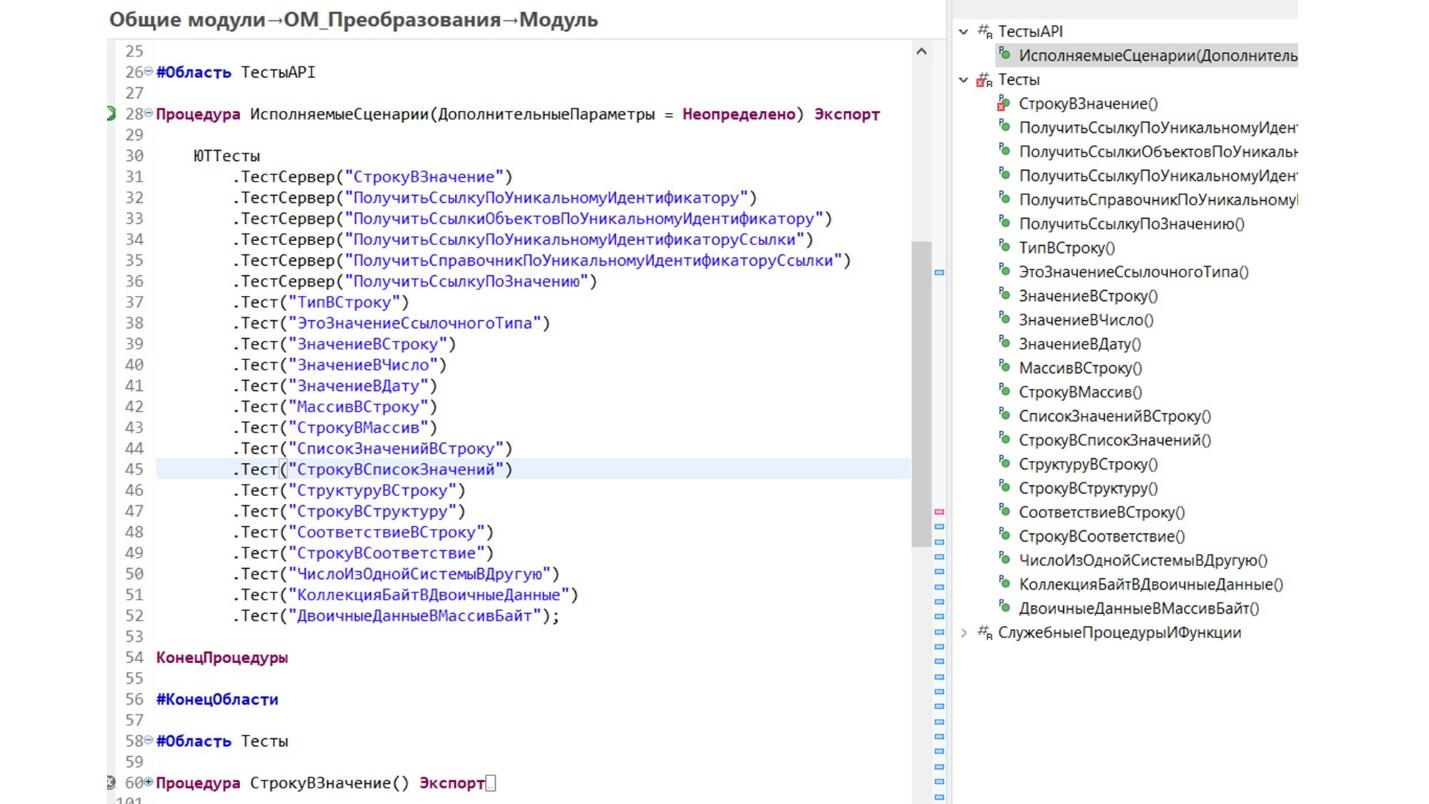
Тест мы пишем в расширении – это просто общий модуль, который содержит некоторый набор программных интерфейсов. Среди них:
-
Один обязательный метод ИсполняемыеСценарии(), который инициализирует тесты, находящиеся в этом модуле.
-
Непосредственно сами экспортные методы реализации этих тестов.
-
Обработчики событий для тестов.
-
И вспомогательные процедуры/функции, используемые в коде.
Обратите внимание, как выглядит инициализация тестов:
-
ЮТТесты – это общий модуль, к которому мы обращаемся, используя текучий интерфейс Fluent.
-
Никаких дополнительных параметров в сами тесты при инициализации мы не передаем – никакой ссылки на движок, никаких внешних файликов и т.д.
-
Мы смогли реализовать почти настоящие текучие выражения – такие же, как реализованы в том же самом JUnit или в библиотеках на OneScript. Такие текучие выражения используются как для создания наборов, так и для проверки результата.
Справа показан список методов тестов. Как видите, ни в один из методов ничего дополнительного не передается – тест сразу выполняется в контексте самого движка.
Структура тестового модуля

В простом случае, каждый общий модуль расширения представляет собой набор тестов. Таких тестовых наборов можно создать необходимое количество.
Тестовый набор состоит из тестов, которые мы хотим запускать комплектом. При создании тестового набора есть возможность дополнить информацию о тесте, например, добавив его представление или пометив тегами.
-
По умолчанию, один модуль – это один набор тестов. Но с помощью метода ТестовыйНабор() программный API предоставляет возможность создать в одном модуле несколько наборов. Например, это удобно, чтобы смотреть отчеты JUnit – тестовые наборы в нем красивым образом группируются в виде дерева. Т.е. даже несмотря на то, что у вас один общий модуль, вы можете разделить тесты в нем по функциональности: здесь работа со строками, здесь – с датами, здесь мы отправляем какие-то сообщения. Вспомните наш любимый модуль ОбщегоНазначения – там же все есть.
-
При использовании обычного метода «Тест()» для добавления теста в тестовый набор, контекст исполнения тестов (на клиенте или на сервере) определяется автоматически, исходя из установленных флагов модуля. Т.е. если у модуля стоит два флажка «Клиент» и «Сервер», тест будет выполнен два раза: и для клиента, и для теста.
-
Если же явно использовать методы ТестКлиент() или ТестСервер(), движок не будет опираться на эти флажки, а выберет тот режим, который нужен. Таким образом можно определить: «с этим тестом иди только на сервер, а остальные отработай и там, и там». Это позволяет сократить количество кода – не нужно дублировать код или писать в нем больше строк.
-
Кроме того, с помощью метода ВТранзакции() мы добавили возможность запуска тестов в транзакциях – в некоторых случаях это необходимо.
Кроме тестов, построенных по принципу JUnit, мы реализовали дополнительный набор необязательных событий, которые могут быть применены в конкретном тестовом наборе. С помощью событий можно выполнить действия перед и после набора, теста или всего модуля.
Например, можно сгенерировать какие-то тестовые данные, которые будут использованы последующими тестами. А после выполнения набора за собой прибрать.
События срабатывают вне зависимости от того, упал тест или нет – т.е. даже если тест упадет, события все равно отработают, и мы за собой приберем при необходимости.
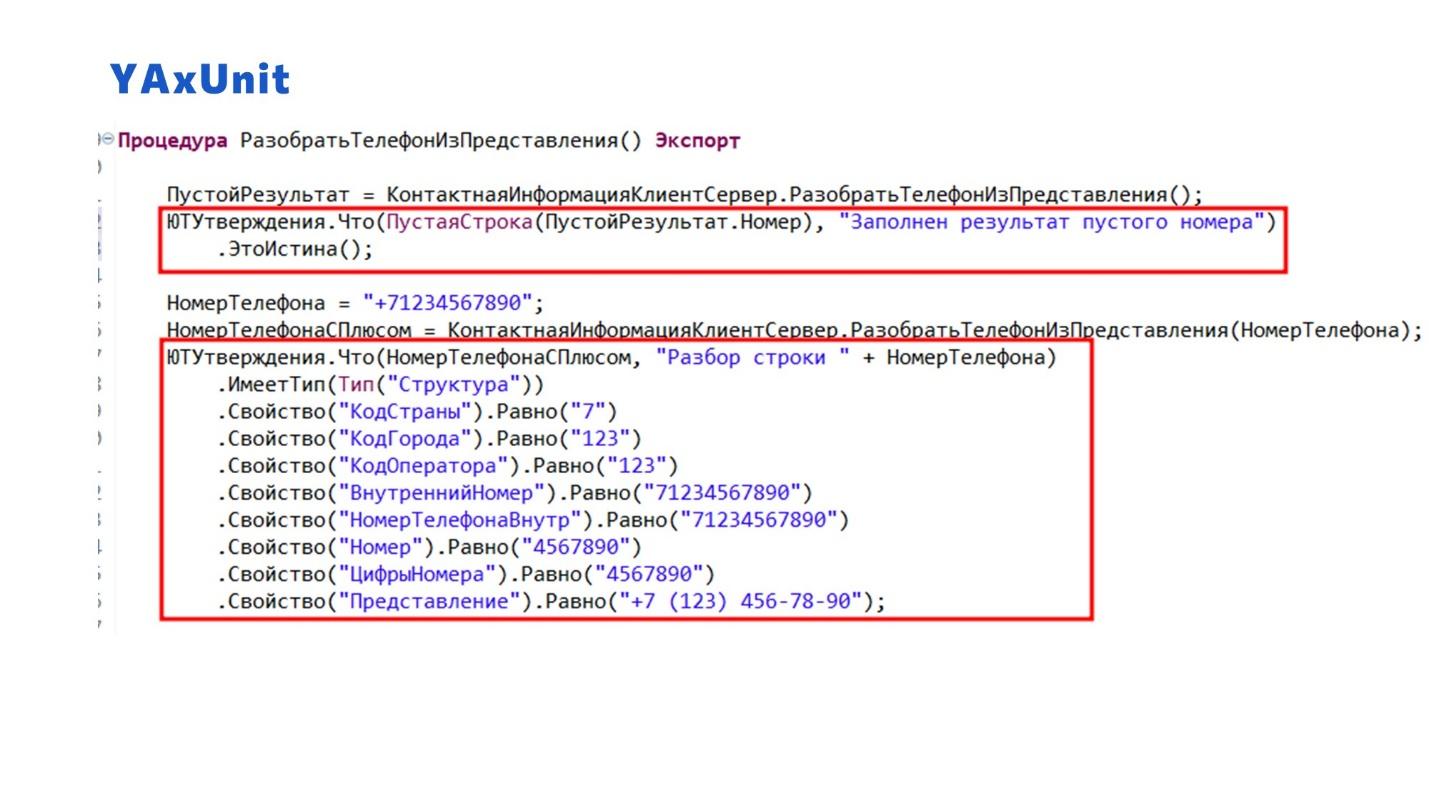
Что касается интерфейса текучих выражений, мы постарались его поприкручивать везде по максимуму. Т.е. у нас все проверки при написании используют набор утверждений.
Fluent-интерфейс позволяет делать это лаконично – не нужно каждый раз писать сто тысяч строк, обращаясь к тому значению, которое мы проверяем.
Например, в данном примере мы один раз говорим, что проверяем правильность разбора номера телефона, и дальше смотрим, какие свойства есть у полученной структуры. Проверяем:
-
что у результата – тип «Структура»;
-
свойство «КодСтраны» равно такому-то значению;
-
и так далее.
Так гораздо удобнее писать, чем если мы это будем расписывать по отдельной строчке через «Если…Тогда…Иначе…КонецЕсли;».
Механизм утверждений

На слайде показан список используемых в инструменте утверждений – здесь выведены не все.
Большинство утверждений мультиформатные. Т.е. мы старались писать их таким образом, чтобы они сами понимали, какие типы данных в них заходят. Допустим, утверждение «ИмеетДлину()» для строки проверяет длину строки, для коллекции – количество элементов и т.д.
Но есть отдельные утверждения, которые касаются конкретных вещей. Например, понятно, что метод ВыбрасываетИсключение() нет смысла применять к структуре и т.д.
Мокирование

Когда нужно проверить не 2+2, а что-то более сложное, например, проведение документов или код, который взаимодействует с какой-то сторонней системой, в YAxUnit можно использовать мокирование.
С его помощью удобно проверять функциональность по принципу «черного ящика», когда мы не имеем доступа к другой системе, но точно знаем, как она работает. Или когда мы хотим проверить всю функциональность, но пропустить для себя какой-то блок.
Для этого в состав YAxUnit вошла подсистема Мокито на примере одноименного фреймворка из мира Java – похожая библиотека есть и для OneScript.
На слайде показан пример, где мы проверяем функцию создания виртуальной машины. В данном случае мы не хотим создавать физическую виртуальную машину – для теста она не нужна, я уверен, что она создастся на Terraform. Но я хочу проверить какие-то дальнейшие функции – убедиться, что у меня создалась заявка, что она заполнилась и так далее.
С помощью Мокито мы указываем юнит-тесту, чтобы он при тестировании общего модуля УправленияВиртуальнымиРесурсамиТерраформ пропустил и не выполнял метод ОпубликоватьКонфигурациюВиртуальнойМашины(), когда дойдет до него.
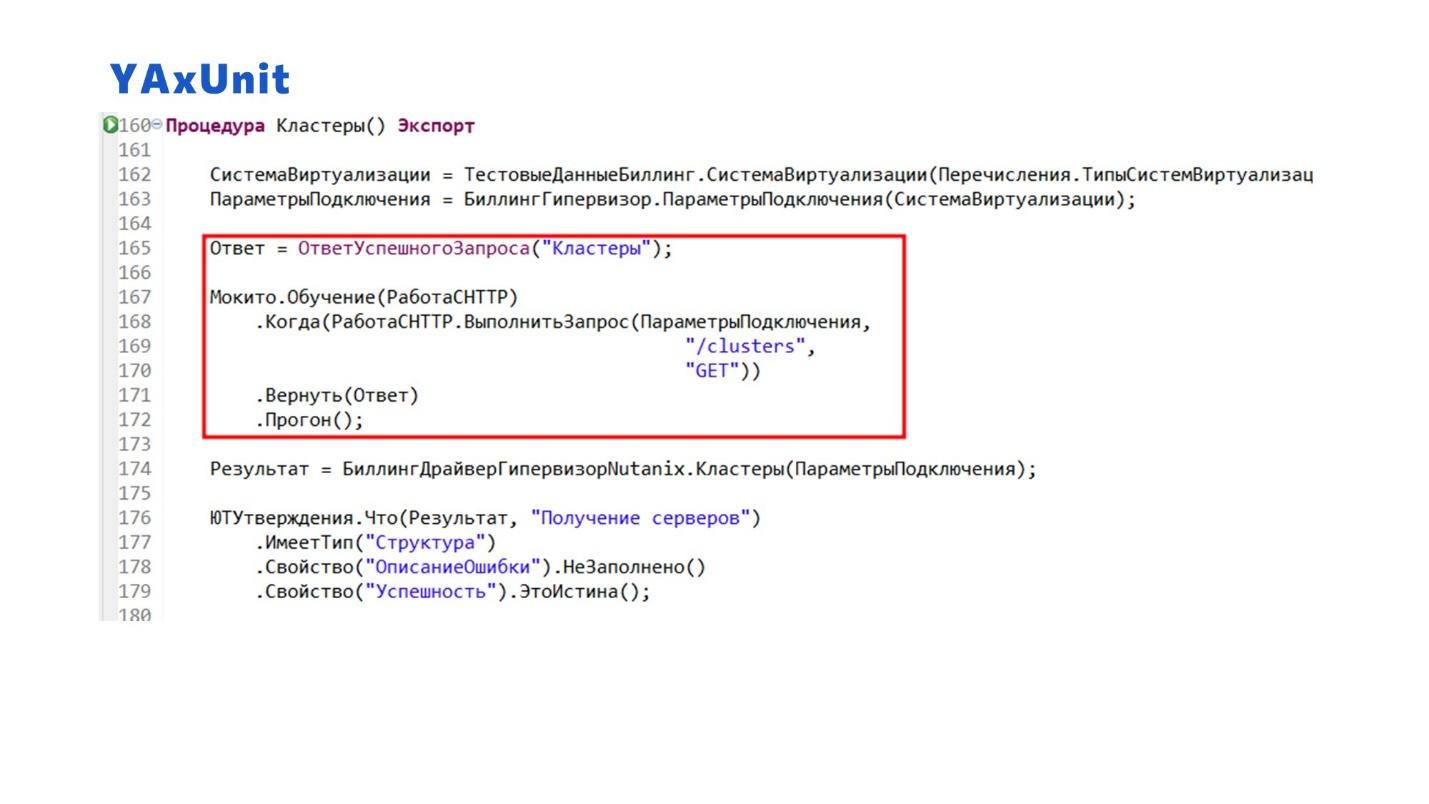
Здесь показан еще один пример, как можно протестировать взаимодействие с внешним сервисом, который нам отдает какой-то ответ – например, мы точно знаем, что он возвращает JSON определенной структуры.
Опять же, мы указываем, что при вызове такого-то метода нужно вернуть некоторый ответ, который заранее сохранили. Нас не интересует, как этот ответ сохранился – мы точно знаем, что система отвечает именно так.
Чтобы корректно протестировать обработку результата, мы должны гарантировать его повторяемость, независимую от расположения звезд на небе. А для этого нам нужно проверять результат некоторой фиксированной фикстуры.
Плагин для разработки и запуска тестов в EDT

Перейдем к самому плагину.
В качестве основы был взят плагин юнит-тестирования для Eclipse JUnit. Чтобы нормально прикрутить его к EDT, пришлось форкнуть исходный репозиторий, иначе там были некоторые сложности.
Кстати, благодаря тому, что мы построили плагин на базе классического плагина Eclipse, нам удалось не привязываться к конкретной реализации EDT – мы на разных версиях EDT можем использовать одну и ту же версию плагина без пересборки.
Функций там на данный момент (прим. ред. доклад от октября 2022 года) реализовано немного – самое горящее реализовали, а дальше планируем дорабатывать по необходимости. Планов много.
На слайде показан пример создания модуля теста в EDT:
-
По умолчанию текст модуля заполнился настроенным шаблоном.
-
Дальше я заменяю тестовый блок API из шаблона кодом реализованного теста. И показываю, как ведет себя EDT при объявлении новых тестов – для этого я построчно убираю комментарии в основном методе ИсполняемыеСценарии. Все происходит в динамике, я тут ничего не сохраняю.
-
Сразу после объявления теста напротив каждого метода появляется соответствующая лампочка. Плагин объясняет EDT, что это тест, и вешает соответствующую команду, чтобы этим тестом в дальнейшем можно было пользоваться. Т.е. определение того, что это тест, происходит на основе анализа текста модулей и используемых методов.
А теперь самое интересное – как работают тесты:
-
Мы можем выполнить как отдельный тест, так и весь комплект тестов.
-
Результат выполнения показывается в отчете JUnit. При клике на тест в списке результатов, мы переходим к тестовому методу.
-
При объявлении теста отрабатывает автокомплит, который подсказывает возможные варианты для текучего выражения.
-
В последней версии мы еще добавили возможность перезапуска только упавших тестов. Если у вас большой модуль, и три теста упало, чтобы не каждый отдельно тыкать, можно перезапустить отдельно только упавшие.
Это только начало пути…

Подводя итоги рассказа:
-
Расширение и сам движок YAxUnit работают с версии 8.3.10 и до последних релизов платформы.
-
Есть возможность писать тесты в соседних расширениях по отношению к движку. Только нужно учесть нюанс с неработающим автокомплитом, потому что пока EDT не научилась пробрасывать контекст – но мы попробуем тоже что-нибудь придумать, чтобы это исправить.
-
Я рассказал о малой доли функциональности из того, что заложено в сам движок – возможностей там гораздо больше, плюс они будут расширяться.
-
Решение может работать на CI – в результате будут формироваться отчеты в формате JUnit. Эти результаты можно смотреть в EDT или средствами самого CI, например, в Jenkins. Либо можно перегнать отчет в формат Allure и смотреть это красиво-модно-молодежно.
-
Код опубликован на GitHub под открытой для коммерческого и некоммерческого использования лицензией.
-
По ссылке https://github.com/bia-technologies/yaxunit вы можете скачать расширение для разработки и запуска тестов.
-
По ссылке https://github.com/bia-technologies/edt-test-runner лежат исходники плагина со средством запуска тестов для EDT.
-
-
Наша команда будет продолжать развивать и дополнять это решение. Если вам это тоже интересно, оставляйте отклики – пишите, какую новую функциональность вы бы хотели в нем видеть. Еще больше ждем контрибьютеров – тех, кому эта функциональность нужна, и кто захочет это развивать.
На мастер-классе (видео) мы вместе вживую попробуем это все пощупать на специальном демонстрационном примере.
Вопросы
Вы сказали, что YAxUnit работает еще и в конфигураторе. А как? Просто ставишь расширение и пишешь код по шаблону?
Да, все то же самое. Для запуска тестов нужно через \c прописать параметр RunUnitTests. Вся документация и примеры находятся в репозитории.
У Vanessa ADD тоже есть возможность писать тесты в расширениях. И у нас уже есть тесты в расширениях для Vanessa ADD с теми же утверждениями. Получается, что если мы захотим адаптировать их под YAxUnit, нам нужно прислать вам мерж-реквест? А нельзя сделать так, чтобы эти утверждения можно было где-то в одном месте держать?
Предложение интересное, можно обсудить отдельно – мы не закрыты. По-хорошему, в таком случае эти утверждения должны выехать в отдельный проект, который должен получаться у всех по зависимостям.
Там единственное, что реализация разная. Опять же, из-за внутреннего контекста, потому что утверждения Vanessa все-таки завязаны на ее движок, на обработку. У нас все построено иначе.
Кстати, никто не догадался, как мы сделали проброс контекста в эти утверждения? Сразу скажу, никакой черной магии, недокументированных возможностей, только средствами платформы. Посмотрите код. Все лаконично и просто.
Было бы здорово, если бы вместе сообществом удалось разработать такую архитектуру, когда можно иметь одно расширение с тестами и несколько движков для их выполнения. Это был бы такой open source в реале.
Если перейти на GitHub и посмотреть, как называется плагин, который я упоминал, он называется EDT Test Runner, а не YAxUnit Runner. Т.е. у нас есть идея подключить туда и другие раннеры.
Если это еще кому-то интересно, код открыт, и мы сами готовы сотрудничать, чтобы вместе это допилить.
Получится ли при помощи этого инструмента покрыть тестами внешние обработки?
Получится. Тест можно написать к чему угодно. Вопрос только в том, как запустить эту обработку и обратиться к тестируемому методу.
Если вы у себя в тесте напишете «Загрузить обработку №2» и что-то с ней сделаете, чтобы проверить ее работу, остальное будет работать точно так же.
Либо, если обработка у вас лежит в справочнике, вы точно так же можете ее программно вызвать и проверить результаты.
Движок позволяет проверять все, к чему можно обратиться из кода 1С.
Какое количество тестового кода у вас получается по отношению к продуктовому коду? Допустим, если вы пишете какой-то новый код, и сразу стараетесь его покрыть тестами, какая доля получается тестового кода?
Все зависит от кода, который мы будем покрывать.
Можно ориентироваться на цикломатическую сложность, которая есть в Visual Studio Code. Цифры, которые она показывает – это минимальное количество тестов, необходимых для этого метода. Но дополнительно нужно учитывать еще и типы параметров.
И если нам, допустим, нужно покрыть тестами метод с одним параметром типа Булево (принимает Истину или Ложь), который выполняет простейшую операцию – у него одно какое-то условие внутри. В этом случае мы должны написать четыре теста: два теста для двух разных параметров, помноженные на количество веток.
А теперь вспоминаем, что у нас в 1С нет в параметре понимания – Булево это или объект. Поэтому умножаем количество веток на количество объектов метаданных и всех примитивных типов – вот такое идеальное количество тестов мы должны написать.
Никто же так делать не будет, правильно? Поэтому количество написанных тестов определяется по правилу Парето – 80 на 20. Т.е. если учесть, что покрывается не 100% написанного кода, то у нас код тестов – это, наверное, четвертая часть максимум.
В первую очередь, мы покрываем тот код, который считаем для своего решения наиболее критичным. И в дальнейшем покрываются те участки, которые так или иначе сломались, чтобы они не ломались в будущем.
При этом количество строк кода в тесте может быть больше, чем в самом методе, который тестируется:
-
Во-первых, нужно подготовить исходные данные для этого метода – количество исходных данных зависит от того, насколько глубоко закопан этот метод, что в него приходит и насколько он сложен.
-
Еще количество тестов зависит от результатов, которые нужно провалидировать. Если мы хотим протестировать метод «Прочитать файл из банка», который читает 100 строк определенной структуры, нам нужно проанализировать, что это поле соответствует такому-то типу, здесь лежит такое-то значение, здесь – такая-то кодировка и так далее. Чем больше мы этих условий пропишем, тем больше мы будем верить этому методу.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции Infostart Event.

Вступайте в нашу телеграмм-группу Инфостарт