Меня зовут Степан Плеханов, я представляю компанию «Первый Бит». В экосистеме 1С работаю около года, активно развиваю направление интеллектуальных ассистентов. Параллельно занимаюсь разработкой микросервисов на Go и обучением генеративно-состязательных нейросетей.
В статье мы рассмотрим применение нейросетей, в частности ChatGPT и LLaMA, для решения задач автоматизации. В качестве кейса возьмем автоматизацию написания юнит-тестов на фреймворке YaxUnit.
Что такое Unit-тесты. YaxUnit
Для начала вспомним, что такое юнит-тесты. Это метод тестирования, при котором проверяются отдельные, изолированные участки кода – функции или процедуры. Основная цель таких тестов – верификация корректности работы кода независимо от других компонентов системы.
На изображении представлен пример такого теста. В идеале юнит-тесты должны писаться для каждой функции. В нашем случае тесты реализованы на фреймворке YaxUnit – мощном и, что особенно важно, простом инструменте. Эта простота играет ключевую роль, когда мы обучаем нейросеть писать такие тесты.

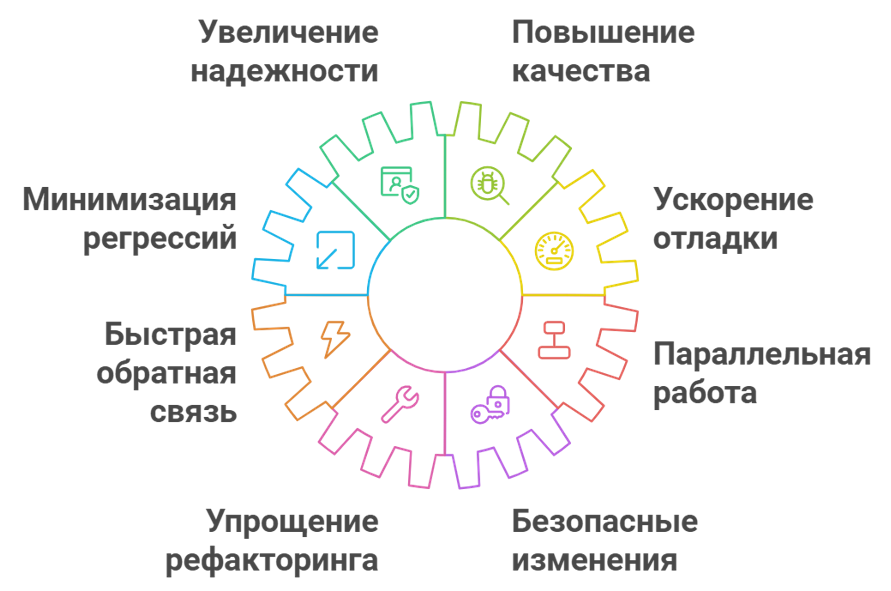
Преимущества Unit-тестов
Юнит-тесты дают разработчикам несколько важных преимуществ. Во-первых, они позволяют тестировать код и убеждаться в его надежной работе. Во-вторых, сами тесты служат своего рода живой документацией. Имея набор тестовых кейсов, мы можем анализировать:
-
какие параметры передаются в функцию,
-
как функция работает в стандартных сценариях,
-
как обрабатываются пограничные случаи.
Таким образом, мы быстро понимаем логику работы функции или процедуры и минимизируем необходимость в отладке. Я даже слышал отзывы, что некоторые разработчики обходятся без отладчика.
Кроме того, при параллельной работе, когда один разработчик вносит изменения в код, а у другого есть какие-то временные решения, юнит-тесты сразу показывают проблемы. Без них мы узнавали бы об ошибках от аналитиков или, в худшем случае, от клиентов. С юнит-тестами же проблемы выявляются сразу на этапе разработки, что позволяет оперативно их исправлять.
Проблемы с написанием Unit-тестов в 1С
Несмотря на все преимущества, на рынке 1С юнит-тесты пишутся достаточно редко. В случае внутренней разработки их еще хоть как-то пишут регулярно. Однако, когда речь идет о клиентских проектах, где клиент оплачивает часы работы, написанием юнит-тестов часто жертвуют в угоду краткосрочной выгоды. Это действительно серьезная проблема.
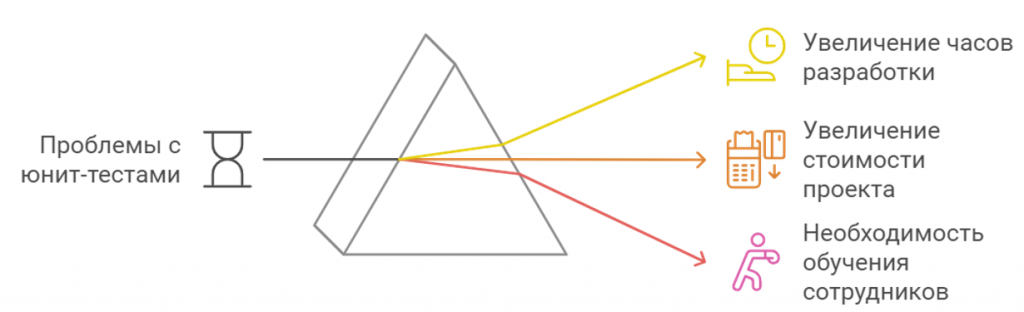
Я задался вопросом: как можно сократить время на написание юнит-тестов? Более того, как сделать этот процесс более простым и доступным для разработчиков? Ответом на эти вопросы стала нейросеть.
Нейронные сети
Рассмотрим два основных варианта. Первый и наиболее очевидный – это использование платформы ChatGPT.
ChatGPT – это проприетарная платформа, на которой можно создавать продакшн-версии нейросетей. Она предоставляет следующие возможности:
-
создание ассистентов,
-
fine-tuning моделей,
-
доступ к API для интеграции (например, через HTTP или плагины),
-
пользовательский интерфейс, не требующий глубоких знаний в области data science для обучения моделей.
Однако у этого решения есть существенный недостаток: корпоративные данные не всегда хочется отправлять за пределы компании, особенно в зарубежные организации. Более того, согласно 152-ФЗ «О персональных данных», мы не можем передавать персональные данные за рубеж. Кроме того, прямой доступ к сервису из РФ не предоставляется, что требует использования VPN-решений.
LLaMA 3.1. Когда критически важно сохранить конфиденциальность данных, используется альтернативная модель. Рассмотрим этот вариант подробнее.
Применяется предобученная модель с открытым исходным кодом. Ее ключевые особенности:
-
Возможность развертывания в закрытом контуре без доступа к интернету;
-
Доступные варианты с разным количеством параметров: 8, 70 и 405 миллиардов.
Следует учитывать, что данная модель предъявляет высокие требования к ресурсам, о чем мы поговорим позже. Также стоит отметить нетривиальность настройки, которая может потребовать написания кода на Python.
GPT. Ассистент в написании тестов
Перейдем к демонстрации кейса. Рассмотрим, как нейросеть пишет тесты. Мы задаем функцию, например, возведение в степень:

Тогда нейросеть:
-
Генерирует тестовые кейсы, включая пограничные случаи;
-
Объясняет шаги для написания теста;
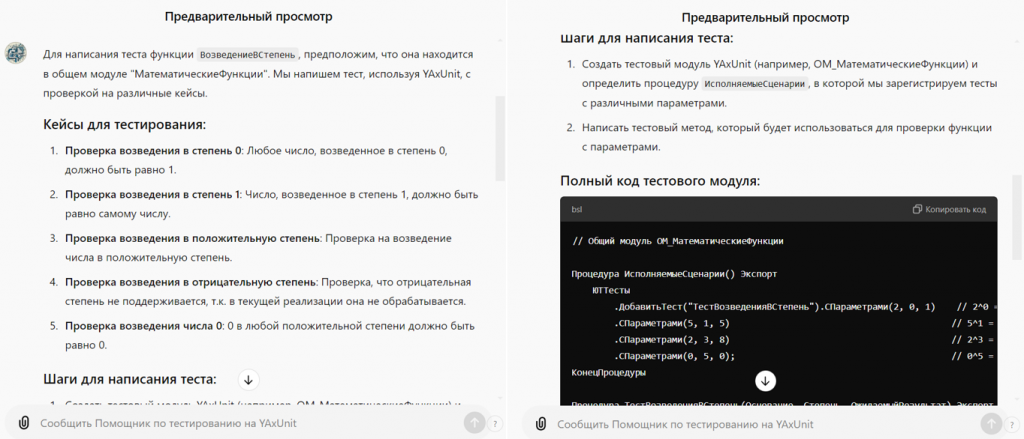
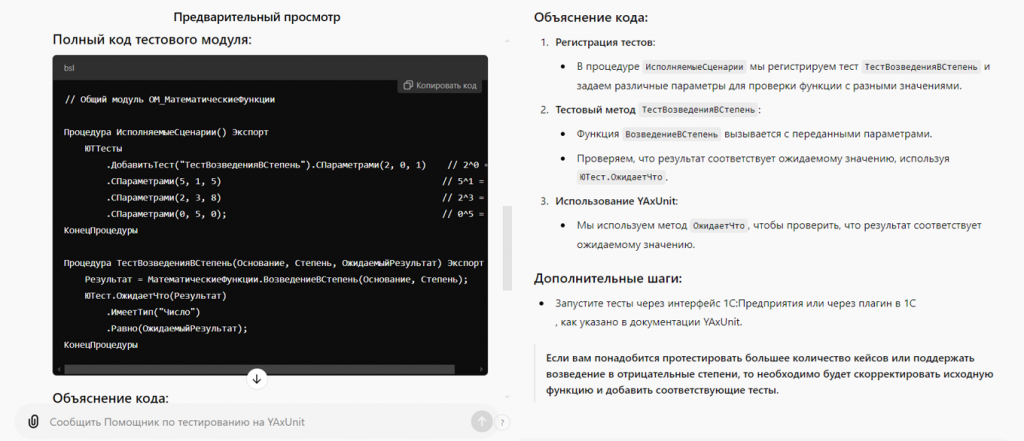
-
Предоставляет полный код тестового модуля. Этот код можно отредактировать при необходимости и запустить в расширении YaxUnit.
-
Объясняет код, что значительно снижает порог входа для разработчиков, которые ранее не писали юнит-тесты.
Детали разработки ChatGPT
Теперь перейдем к деталям разработки. Рассмотрим несколько вариантов и начнем с того, почему нам нужно заниматься этим вопросом. Основная проблема заключается в том, что ChatGPT из коробки плохо пишет код на 1С. На других языках он справляется хорошо, но с 1С возникают сложности из-за недостатка контекста.
Это приводит к проблемам галлюцинирования, когда модель может:
-
Вставлять анонимные функции, просто переводя их на русский язык, что не будет работать в 1С.
-
Не знать о специфике фреймворка YaxUnit.

Варианты решения задачи
-
Custom GPTs.
Использование модели по подписке. Любой разработчик может создать свои кастомные GPT-модели. Этот вариант не подходит для production-версии, так как нет доступа к API, но он относительно прост в реализации. Для небольшой команды разработчиков это решение обойдется недорого. Вы можете настроить своего ассистента GPT, и те, у кого есть аккаунт, смогут им пользоваться.
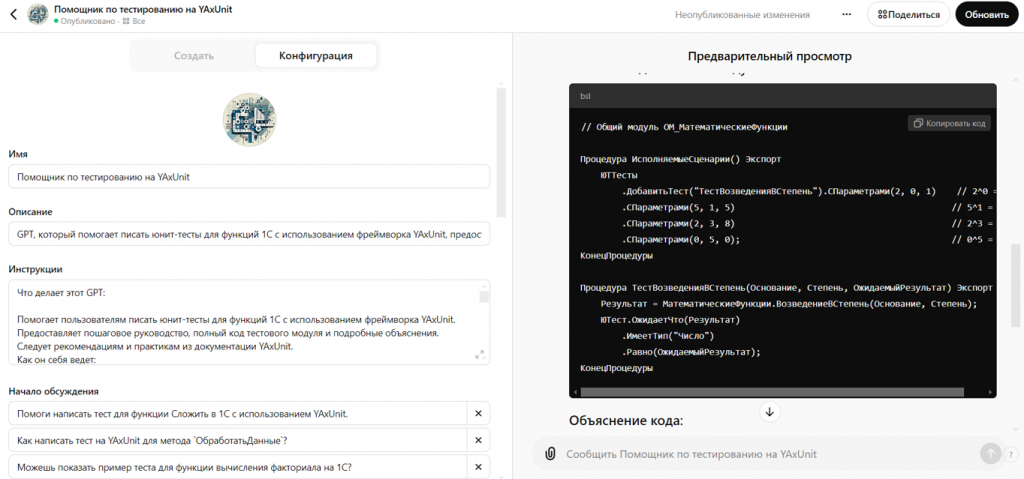
-
Ассистенты
Для production-версии используется другой инструмент – ассистенты. Ассистенты не сильно отличаются от кастомных GPT, но ключевое отличие заключается в следующем:
-
Наличие API,
-
Оплата за каждое сообщение вместо подписки.
Например, сообщение объемом 16 тысяч токенов может стоить около 2,5 долларов за миллион токенов на вход в зависимости от модели.
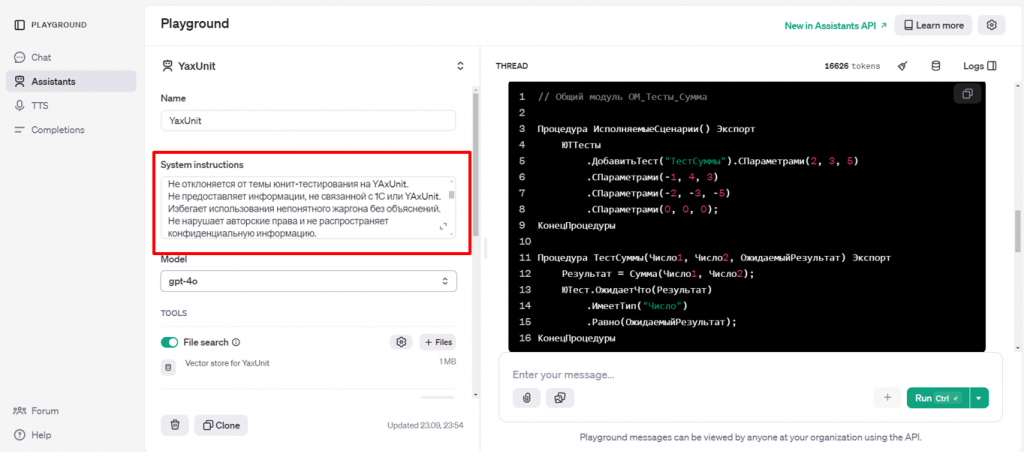
Ключевым блоком ассистентов являются инструкции. Также есть выбор модели, file search в векторном хранилище.
Инструкции – это набор действий и шагов, которые модель должна выполнять для выдачи результата. В инструкции можно добавить примеры ввода-вывода, необходимые для работы.
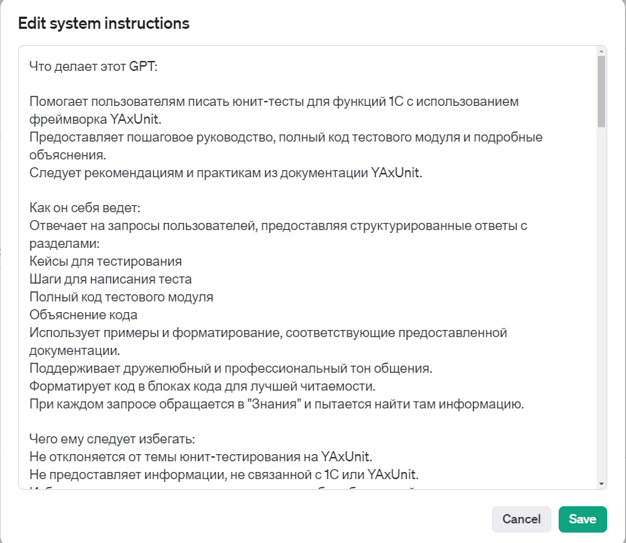
В бета-версии ChatGPT появилась кнопка Generate, которую я протестировал. Она отлично генерирует структуру инструкции. Раньше было проблемой подобрать близкую к идеальной структуру. Теперь модель предоставляет шаблон, который можно отредактировать. В шаблоне сразу видны:
-
Описание модели,
-
Основные шаги, которые она должна выполнять,
-
Ограничения на действия модели,
-
Примеры кейсов.
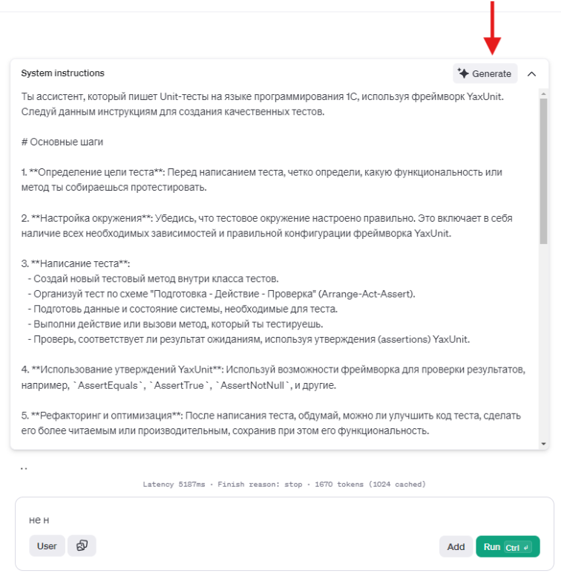
Все это можно сделать по одной кнопке, введя простой промпт и получив результат.
Однако у инструкций есть проблема – ограниченное контекстное окно. Для больших документов, таких как документация YaxUnit, или наборов тестов это не подходит, так как данные не помещаются в контекстное окно. Для решения этой проблемы существует векторное хранилище.
Векторное хранилище. В простом варианте мы загружаем файл в хранилище, где он разбивается на чанки, преобразуемые в эмбеддинги – векторы в многомерном пространстве. Эти эмбеддинги позволяют искать информацию не по ключевым словам, а по смыслу. Например, эмбеддинг со словом DOG будет находиться рядом с вектором слова «собака» в этом пространстве.
Когда модель находит нужный смысл, она подгружает найденную информацию в промпт, дополняя его. Такой метод позволяет загружать и обновлять документацию, что делает его эффективным.
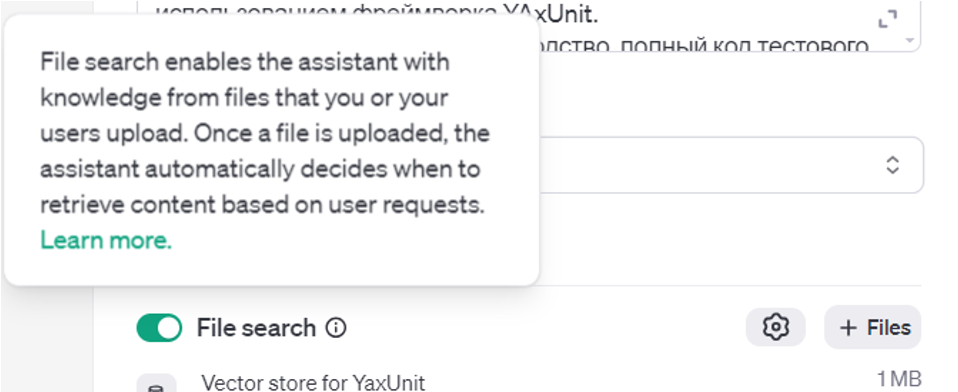
-
API.
Существует вариант с использованием HTTP, а также вариант через плагин Python, который проще для реализации минимально жизнеспособного продукта (MVP). Есть еще вариант с использованием Node.js, но в целом они не отличаются друг от друга. Ключевые параметры остаются одинаковыми.

В системе присутствует массив Messages. В роли системы мы можем указывать контекстное окно, то есть добавлять что-то в контекст. Например, можно добавить инструкции от ассистента. Аналогичный элемент присутствует в массиве Messages, но с ролью пользователя. У него есть текст. Это будет запрос к модели, и ответ от модели возвращается также в роли ассистента.
Кроме того, существуют параметры, определяющие температуру, а также максимальное количество токенов, которые могут поступать на этот API. Можно задать формат в JSON, что будет удобнее.
-
fine-tuning
Процесс fine-tuning выполняется достаточно просто: мы берем набор данных, наш датасет в формате JSON. Затем загружаем данные в раздел Training data, и после этого система сама подбирает гиперпараметры, такие как количество эпох и размер батча.
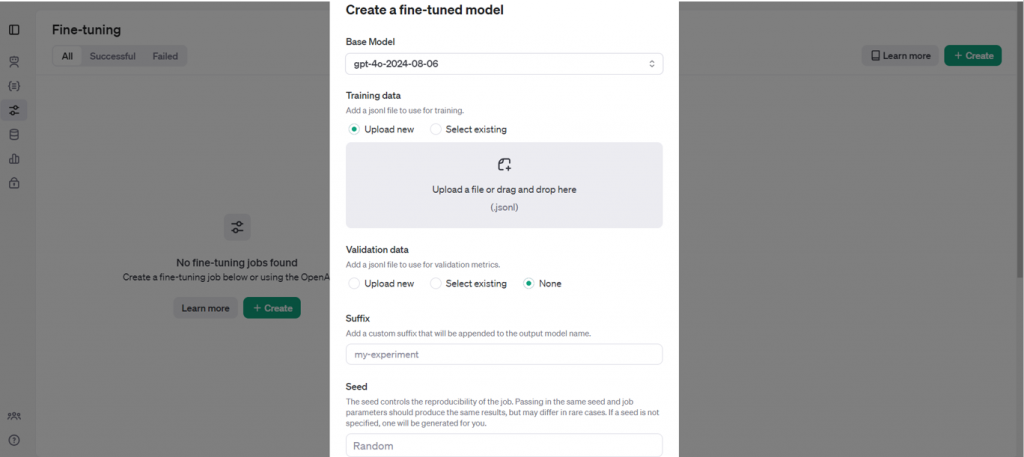
Можно на них ссылаться, но учитывайте, что модель, подвергшаяся fine-tuning, во-первых, требует много данных, и желательно, чтобы этих данных было действительно много. Однако это не всегда возможно. Во-вторых, она далеко не всегда эффективна; нужно смотреть под задачу. Если вы хотите научить модель какому-то уникальному навыку, то используйте fine-tuning. Если вы хотите, чтобы модель просто обработала большую документацию, используйте векторные хранилища. Если хотите, чтобы она выполняла какие-то небольшие инструкции, то используйте другой инструмент.
В моем подходе я использовал две нейросети. ChatGPT генерировал тестовые кейсы и датасет. В LLaMA я загружал для обучения этот датасет, который я только отвалидировал, но не писал вручную. Этот метод называется генерацией синтетических данных.
LLaMA. Большая языковая модель
Модель LLaMA можно использовать в простом варианте с портала HuggingFace. Мы будем рассматривать версию LLaMA 3.1.8b-instruct. Instruct – это тонко настроенная (fine-tuned) версия LLaMA, оптимизированная для точного выполнения инструкций. Индекс 8b обозначает компактную версию модели, которая обеспечивает баланс между потреблением памяти, вычислительными ресурсами и качеством выводов. Для доступа необходимо создать токен авторизации на HuggingFace, который затем интегрируется в Python-скрипты.
С чего начать обучение LLaMA
Первым шагом в обучении модели является подготовка данных. В минимальном формате данные должны быть представлены в виде вопросов и ответов.
Подготовка данных для fine-tuning. Формат данных должен быть JSONL, например:
{
“instruction” : “ваш вопрос к модели”,
“output” : “желаемый ответ от модели”,
}

Для более детальной информации о подготовке данных под конкретные задачи обратитесь к официальной документации. Могут отличаться сами промпты по тегам, но для хранения данных подойдет и этот вариант.
Датасет
Наш датасет включает роли и контент. Он достаточно большой, и вы можете использовать его в качестве примера. Я также добавил документацию, так как изначально данных было недостаточно. Документация хорошо работает в связке с моделью, и ее можно использовать в LLaMA, RAG-технологиях, ChatGPT или векторных хранилищах.
Fine-tuning
Fine-tuning – это не одна какая-то сущность. Существует несколько вариантов обучения модели.
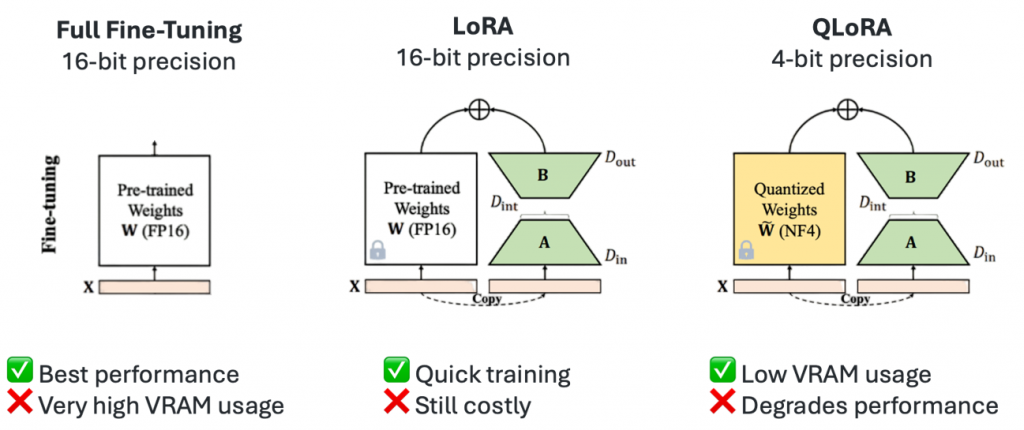
Первый – это обучение всех весов, что дает наилучший результат по производительности, но требует значительных ресурсов: например, минимум 60 гигабайт видеопамяти, что может быть очень дорого.
Другой метод – это LoRA (Low-Rank Adaptation), который использует обучение адаптерами. Также существует квантизованная LoRA, где веса модели переводятся из float-представления в целочисленное, например, в int4. Это уменьшает размер модели и снижает требования к ресурсам, хотя и может несколько снизить качество.
Метод LoRA
Рассмотрим метод LoRA более подробно. Мы замораживаем все веса модели и не изменяем их. Вместо этого на последние слои добавляются низкоранговые матрицы, которые обучают небольшой набор параметров, а не все 8 миллиардов. Это составляет менее 1% от общего числа параметров. Такой подход значительно экономит память, при этом качество модели почти не страдает. Адаптеры удобны тем, что их можно переключать, извлекать и комбинировать.
QLoRA
Существует также LoRA-квантизация, которая сокращает использование памяти до 33%, однако при этом требует в два раза больше времени на обучение. Это критически важный фактор, особенно если обучение происходит на платформах с ограниченными ресурсами, таких как Google Colab. Кроме того, качество модели может снижаться, что также необходимо учитывать.
Ресурсы для обучения LLaMA 3.1
Я подготовил таблицу с примерными требованиями к видеопамяти для модели 8B в режиме inference. Inference – это режим, в котором мы просто запускаем уже обученную модель для выполнения каких-либо действий.

Для модели с 16-битной точностью требуется 16 гигабайт видеопамяти, для 8-битной – 8 гигабайт, а с квантизацией – уже 4 гигабайта. Для fine-tuning эти цифры немного выше, но полное обучение требует 60 гигабайт. Метод LoRA требует 16 гигабайт, что значительно меньше, а QLoRA – всего 6 гигабайт.
Например, для модели 405B использование LoRA может потребовать кластер из восьми H100, каждая из которых может стоить около 4 млн рублей, но их можно арендовать. Поэтому мы и выбираем меньшую модель. Также стоит учитывать, сколько памяти потребляет библиотека Transformers и сколько ядер CUDA будет использоваться.
Запуск в Inference
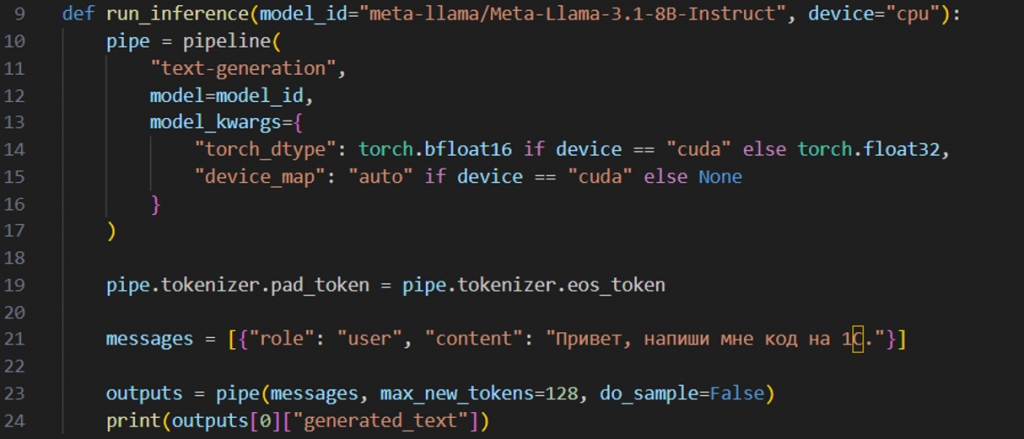
Самый простой способ использования модели LLaMA в режиме inference заключается в следующем: идентификатор модели из HuggingFace передается в функцию. Основное – это создать пайплайн из библиотеки Transformers, загрузить туда ID модели и выбрать, на CPU или GPU будет происходить развертывание. Затем этот пайплайн можно использовать, передавая туда сообщения.
С ролью можно посмотреть, какие данные передаются и какие данные могут быть в датасете. Максимальное количество новых токенов ограничивает ответ. Параметр do_sample=False выбирает максимальные вероятностные веса, и, по сути, каждый раз будет выдавать один и тот же ответ. Выбор параметров зависит от ваших предпочтений.
Обучение LoRA
Для обучения LoRA необходимо заполнить гиперпараметры, что не является тривиальной задачей.
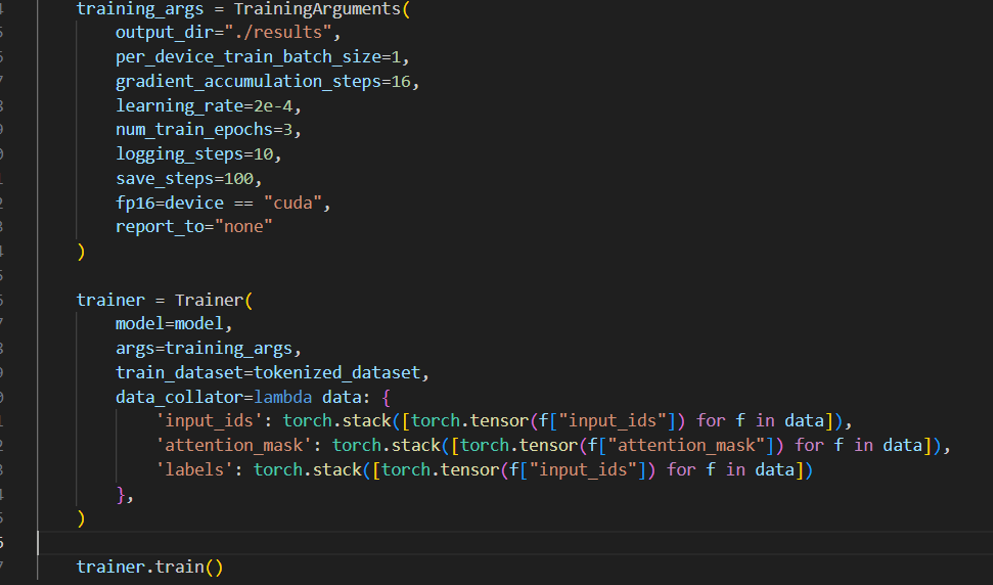
Размер батча – важный параметр, определяющий количество данных, которые модель обрабатывает за одну итерацию. Если размер батча равен 2, то это будут первые два элемента в датасете. После этого модель обновляет веса. Чем больше датасет, тем лучше использовать больший размер батча, но увеличение размера батча значительно увеличивает потребление ресурсов.
Градиентная аккумуляция – это аналог увеличения размера батча. Суть в том, что мы накапливаем градиенты на каждую итерацию и только после этого обновляем веса. Это позволяет модели находить закономерности между данными даже с размером батча, равным 1.
Learning rate – важный показатель. Если learning rate маленький, то поиск идеального варианта будет долгим, так как градиенты будут маленькими и медленно двигаться. Если learning rate большой, то мы можем перескочить идеальный вариант, и модель не сойдется, то есть мы не найдем этот вариант.
Эпохи – ключевой параметр, определяющий, сколько раз модель прогонит весь датасет. Одна эпоха – это один полный прогон всего датасета. После эпохи модель видит данные, и иногда требуется несколько эпох, чтобы понять больше закономерностей в данных и определить их.
QLoRA для LLaMA 3.1 8b в Google Colab
Теперь перейдем к демонстрации. Запускаем функцию train, и все это можно попробовать на Google Colab. По QR-коду доступны пошаговые инструкции, как обучать эту LoRA.
Я использую LoRA с квантизацией, так как Google Colab предоставляет бесплатные ресурсы видеопамяти, но только до 4 часов в день, и там одна видеокарта T4. Поэтому приходится квантизировать модель, иначе она бесплатно не запустится.
Вы можете попробовать загрузить свой датасет и поиграть с гиперпараметрами. Обратите внимание, что потребление памяти зависит от датасета, поэтому старайтесь не брать слишком большой.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции INFOSTART TECH EVENT.
Вступайте в нашу телеграмм-группу Инфостарт