










{kind=link}
Наша компания занимается внедрением и сопровождением систем на базе 1С. Один из заказчиков – крупная сеть АЗС. На каждой станции в резервуарах с топливом есть специальные датчики. Они снимают различные показания о состоянии резервуара, например, температура, объем топлива. Эта информация сервером на АЗС считываются и далее передаются на хранение и анализ в центральный офис. Передаваемые данные легко представимы в виде одной таблицы. Периодичность передачи показаний – каждые 5 минут.
Первоначально хранение в центре было организовано в рамках 1С через периодический регистр сведений с измерениями «Cтанция» и «Резервуар». Спустя некоторое время пришлось отказаться от хранения данных в 1С по нескольким причинам. Три основные:
- рост объема БД за счет непрофильных данных. Данные по замерам не относятся непосредственно к оперативному учету, а места в базе данных занимают много.
- относительно низкий уровень доступности 1С из-за технических окон: остановка сервера 1С или ограничение доступа к нему на определенное время. Технические окна применяем для установки новых релизов, доработок, обновления платформы и конфигурации сервера, прочие технические работы. В среднем, получается 3 часа в неделю, когда станции не могут передать показания в центральную систему. Заказчику же данные замеров нужны нон-стоп.
- на регистре сведений не получалось достаточно быстро строить аналитические запросы из-за ограничений с индексацией РС и общей высокой нагрузкой на дисковую подсистему 1С другими пользователями. Об этом расскажу чуть позже.
Был разработан небольшой сервис на Python, который очень быстро и массово обрабатывал HTTP-запросы от станций и складывать данные в базу на PostgreSQL. PostgreSQL был выбран как одна из знакомых и привычных СУБД, которую можно подключить к 1С через механизм внешних источников данных и работать с ней через объектную модель. Это значит, что по данным этой БД можно легко собрать отчет на СКД. Кроме того, на этот Python-сервис были возложены еще некоторые операции по работе со станциями (не по резервуарам), которые требовали транзакционной модели обновления данных в БД. Исходя из всего перечисленного, PostgreSQL казался хорошим выбором.
Время шло, все работало значительно быстрее, чем на 1С, все были довольны. Спустя некоторое время размер таблицы с замерами превысил 10 миллионов записей, потом 20, потом 50… На таких объемах данных планировщик запросов PostgreSQL начал отдавать предпочтение Table scan вместо Index scan при некоторых типах запросов. Что стало очень больно бить по производительности. Были добавлены дополнительные индексы, под конкретные типы запросов, поигрались с настройками планировщика запросов, но существенных результатов добиться не удалось. Встал вопрос об удалении исторических данных, на который было получено категорическое «НЕТ» от заказчика. Вариантов развития событий виделось несколько:
- Модернизировать аппаратную составляющую сервера СУБД PostgreSQL. Решение дорогое, т.к. железо и так хорошее. Плюс решение временное.
- Заниматься разделением таблиц на условно архивную и оперативную. Позволило бы быстро строить отчеты за последние пару месяцев, но очень долго за больший период.
- Разрабатывать вспомогательные таблицы, которые заполнялись бы каким-нибудь образом различными обработчиками. Позволило бы выполнять фоновую обработку данных и их подготовку под конкретные отчеты так, чтобы они строились в разы быстрее. Решение довольно трудозатратное, плюс не универсальное: завтра появится новый отчет, под который нет подготовленных данных и построить его за адекватное время не получиться.
- Искать другие решения для хранения и анализа данных.
Т.к. хотелось найти решение уровня «сделал и забыл на пару лет», то первые три варианта так или иначе не подходили. Началась исследовательская работа, которая вскоре привела к open-source решению от Яндекс – Clickhouse. Результатами исследований производительности при переходе на эту СУБД я и хочу поделиться с вами в этой статье.
Итак, начнем с целей, которые перед нами стояли:
- Познакомиться в рамках документации с архитектурой Clickhouse, созданием, хранением, резервным копированием баз данных; работой и особенностями индексов; специфических особенностях языка SQL.
- Подготовка тестового стенда.
- Найти механизм переноса существующих данных по замерам из PostgreSQL в Clickhouse. Выбрать и протестировать механизм пополнения базы данных новыми записями.
- Сравнение объема, занимаемого таблицей на диске в Clickhouse и PostgreSQL.
- Выбрать несколько запросов к БД разного уровня сложности для оценки производительности.
- Оценить деградацию производительности запросов из п.4 с ростом количества записей в таблице.
- Научиться работать с Clickhouse из-под 1С и использовать результаты запросов для построения отчетов.
- Выводы, возможные направления дальнейшей оптимизации.
1. Первое знакомство.
После чтения нескольких статей по Clickhouse, был воодушевлен и оптимистичен. Начал читать документацию, которая оказалась шикарно написана. Довольно быстро понял, как работают колоночные СУБД, в чем отличие от обычных, как работают индексы и какие они могут быть в Clickhouse.
Основная идея колоночных СУБД — это хранение данных не по строкам, как это делают традиционные СУБД, а по колонкам. Это означает, что с точки зрения SQL-клиента данные представлены как обычно в виде таблиц, но физически эти таблицы являются совокупностью колонок, каждая из которых по сути представляет собой таблицу из одного поля.
В обычной, обычной, «строковой», СУБД, данные хранятся в таком порядке:
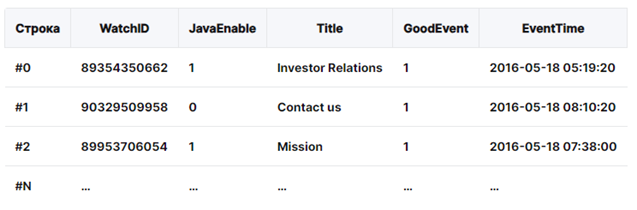
То есть, значения, относящиеся к одной строке, физически хранятся рядом. В столбцовых СУБД данные хранятся в таком порядке:
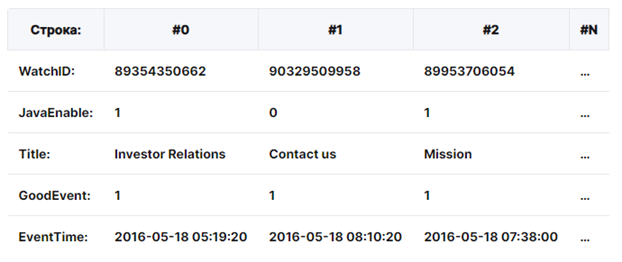
В примерах изображён только порядок расположения данных. То есть значения из разных столбцов хранятся отдельно, а данные одного столбца — вместе. Такая организация данных приводит к тому, что при выполнении select в котором фигурируют только 3 поля из условных 50 полей таблицы, с диска физически будут прочитаны только 3 колонки. Это означает что нагрузка на канал ввода-вывода будет приблизительно в 50/3=17 раз меньше, чем при выполнении такого же запроса в традиционной СУБД.
Кроме того, при поколоночном хранении данных появляется замечательная возможность сильно компрессировать данные, так как в одной колонке таблицы данные как правило однотипные, чего не скажешь о строке. Например, если у нас есть таблица со 100 млн записей, сделанных в течение одного года, то в колонке «Дата» на самом деле будет храниться не более 366 возможных значений, так как в году не более 366 дней (включая високосные года). Поэтому мы можем 100 млн отсортированных значений в этом поле заменить на 366 пар значений вида <дата, количество раз> и хранить их на диске в таком виде. При этом они будут занимать приблизительно в 100 тыс. раз меньше места, что также способствует повышению скорости выполнения запросов.
Из особенностей языка SQL, очень порадовало огромное количество функций работы с датами и методы соединения таблиц, исключающих задвоение строк. В особенности, соединение ASOF (https://clickhouse.com/docs/ru/sql-reference/statements/select/join#asof-join-usage) – аналог среза последних/первых из 1С без необходимости строить агрегаты и подзапросы. Более подробно по различным аспектам работы колоночной СУБД на примере Clickhouse можно узнать из справки по адресу: https://clickhouse.com/docs/ru
2. Подготовка тестового стенда.
Тестирование проводилось на локальном компьютере: Ryzen 7 5800X, 64 Gb DDR4-3200, M.2 Samsung 980 Pro 1 Tb. Сервер PostgreSQL развернут локально под Windows 10. Clickhouse – в виртуальной машине Hyper-V с 8 процессорными ядрами, 36 Gb выделенной памяти и установленной Ubuntu 22.4 desktop. Производительность дисковой подсистемы тестового стенда сравнима с той, что используется в рабочей среде. Мощности по процессорным ядрам и ОЗУ в рабочей среде значительно выше.
Было принято решение сравнить производительность на трех наборах данных:
- Малом. С количеством записей меньше миллиона. Оценить на сколько заметна разница по скорости работы с относительно небольшими таблицами.
- Среднем. По количеству записей и составу измерений сопоставимым с текущим состоянием рабочей среды. Для оценки выигрыша при переходе на Clickhouse в ближайшее время.
- Большом. С количеством записей в таблице, которое можно прогнозировать в рабочей среде через несколько лет с хорошим запасом.
Для целей тестирования был экспортирован сравнительно небольшой объем информации из рабочей базы. Было отобрано несколько станций с резервуарами с разным типом топлива. По ним были взяты замеры за 1 месяц (май 2023 г.). Этот набор был импортирован в PostgreSQL. Далее началось наполнение тестовых таблиц путем генерации данных на базе этой выборки.
- Для малой базы была увеличена частота записей путем усреднения соседних записей + увеличено количество станций путем генерации новых номеров станций. В результате была получена таблица "tank_measures_small" с количеством записей примерно 890 тысяч и распределением по измерениям с перекосом в большее количество различных моментов времени.
- Для средней базы в первоначальной выборке было искусственно увеличено число станций так, чтобы быть сопоставимым с количеством в реальной базе. После этого единственный месяц в первоначальной выборке был растиражирован «в прошлое» так, чтобы результирующее количество записей было примерно равно текущему количеству записей в рабочей среде. Получилась таблица "tank_measures" с 66.87 миллионами записей.
- Для большой базы была взята «средняя база», в ней удвоено количество станций для имитации роста числа АЗС и после этого выполнено тиражирование результирующего набора записей «в будущее» так, чтобы объем таблицы стал х10 от средней. Получилась таблица "tank_measures_big" с почти 670 миллионами записей.
Результатом тиражирования данных должно стать чуть более эффективное сжатие данных в Clickhouse, но думаю, что эффект будет незначителен и им можно пренебречь.
3. Перенос существующей БД.
Текущая конфигурация таблицы в PostgreSQL приведена на скрине. Несколько колонок, primary key на колонке с автоинкременацией, ограничение на уникальность записей по набору «станция, резервуар, момент времени». Единственный индекс Станция – резервуар – момент времени. Этот индекс позволяет быстро строить наиболее часто используемые запросы: срез остатков с отбором по станции и резервуару. Большая часть других запросов использует отбор по станции, так что этот индекс так же используется. Раньше был индекс, где первым полем шла дата замера. Но с ростом количества строк условия типа «datetime < &ДатаСреза» без использования других отборов приводило к table scan, а не использованию индекса по дате.
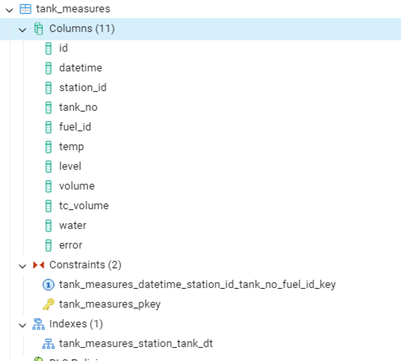
Для целей тестирования было принято решение перенести структуру таблицы в Clickhouse с минимумом изменений:
- id не будет иметь ограничений на значение, будет импортировано из PostgreSQL и использовано для синхронизации изменений.
- использовать тип FixedString для строковых полей, длина которых известна и фиксирована;
- из-за особенностей Clickhouse, Primary key не обеспечивает уникальность записей. Но это нас устроит.
Primary key будет выбран такой же как в PostgreSQL для сравнения результатов на БД с одинаковой архитектурой. Оптимизация индексов и архитектуры БД Clickhouse в рамках данной работы производиться не будет.
Запрос для создания таблицы в Clickhouse получился следующий:
CREATE TABLE tank_measures
(
id Int64,
datetime DateTime,
station_id FixedString(5),
tank_no String,
fuel_id FixedString(36),
temp Float32,
level Float32,
volume Float32,
tc_volume Float32,
water Float32,
error String
)
ENGINE = MergeTree
PRIMARY KEY (station_id, tank_no, datetime)
Для импорта данных в Clickhouse воспользуюсь табличной функций postgresql(), которая позволяет подключиться к серверу PostgreSQL и читать данные напрямую. Запрос импорта получился следующий:
INSERT INTO tank_measures
(id, datetime, station_id, tank_no, fuel_id, temp, level, volume, tc_volume, water, error)
SELECT
id,
datetime,
station_id,
tank_no,
fuel_id,
temp,
level,
volume,
tc_volume,
water,
error
FROM postgresql('<host>:<port>', '<DB name>', '<table name>', '<user name>', '<password>')
Скорость импорта была примерно равна 90 Мб/сек и время импорта для «большой» таблицы составило примерно 18 минут.
После импорта данных была выполнена оптимизация таблиц командой (для каждой таблицы свое имя)
OPTIMIZE TABLE tank_measures_big FINAL;
Исходя из того, что:
- Резервное копирование предполагается на уровне резервного копирования виртуальной машины с Clickhouse.
- Разность между резервными копиями ВМ будет храниться в БД на PostgreSQL.
Получаем следующие условия использования Clickhouse как основной системы аналитики:
- Сервис на Python, отвечающий за прием сообщений от станций не требуется дорабатывать для работы с Clickhouse.
- На виртуальной машине с PostgreSQL требуется организация регламентной процедуры удаления записей из таблицы tank_measures старше одного месяца путем запуска SQL-скрипта один раз в сутки.
- На виртуальной машине с Clickhouse требуется организация регламентной процедуры на добавление в таблицу записей, которые есть в PostgreSQL, но отсутствуют в Clickhouse. Запуск скрипта предполагается каждые 2-3 минуты. Для определения записей, которые отсутствуют в Clickhouse используется автоинкрементируемое поле id. Текст SQL-скрипта:
INSERT INTO tank_measures
(id, datetime, station_id, tank_no, fuel_id, temp, level, volume, tc_volume, water, error)
SELECT
id,
datetime,
station_id,
tank_no,
fuel_id,
temp,
level,
volume,
tc_volume,
water,
error
FROM postgresql('<host>:<port>', '<DB name>', '<table name>', '<user name>', '<password>')
WHERE id > (select max(id) from tank_measures)
Тесты показали, что данный запрос работает не больше 1 секунды даже для «большой» тестовой таблицы.
- На виртуальной машине с Clickhouse требуется организация регламентной процедуры оптимизации БД один раз в месяц с командой «OPTIMIZE TABLE tank_measures FINAL». Для «большой таблицы» время выполнения оптимизации не превышает 100 сек.
4. Объем данных.
Известно, что Clickhouse – колоночная база данных и обеспечивает хорошую компрессию данных, т.к. данные сжимаются в рамках каждого столбца отдельно. То есть учитывают типы сжимаемых данных, множество различных значений в разных строках, порядок следования значений в строках, упорядоченных по primary key и прочее. Ожидается, что в случае с таблицей замеров резервуаров сжатие будет очень хорошим, так как количество уникальных станций не большое, а количество уникальных номеров резервуаров и видов топлива вообще не превышает 10. Давайте посмотрим, что у нас получилось.
Для получения сведений о размере таблиц в PostgreSQL был использован запрос:
SELECT C.relname AS "relation",
pg_size_pretty (pg_relation_size(C.oid)) as table,
pg_size_pretty (pg_total_relation_size (C.oid)
-pg_relation_size(C.oid)) as index,
pg_size_pretty (pg_total_relation_size (C.oid)) as table_index
FROM pg_class C
LEFT JOIN pg_namespace N ON (N.oid = C.relnamespace)
LEFT JOIN pg_stat_user_tables A ON C.relname = A.relname
WHERE nspname NOT IN ('pg_catalog', 'information_schema')
AND C.relkind <> 'i'
AND nspname !~ '^pg_toast'
AND C.relname like '%tank%'
AND schemaname is not NULL
ORDER BY pg_total_relation_size (C.oid) DESC
Для получения сведений о размере таблиц в Clickhouse был использован запрос:
SELECT
table,
part_type,
formatReadableQuantity(rows) AS rows,
formatReadableSize(data_uncompressed_bytes) AS data_uncompressed_bytes,
formatReadableSize(data_compressed_bytes) AS data_compressed_bytes,
formatReadableSize(primary_key_bytes_in_memory) AS primary_key_bytes_in_memory,
marks,
formatReadableSize(bytes_on_disk) AS bytes_on_disk
FROM system.parts
WHERE (table LIKE '%tank%') AND (active = 1)
FORMAT Vertical
Результаты сравнения приведены в таблице ниже.
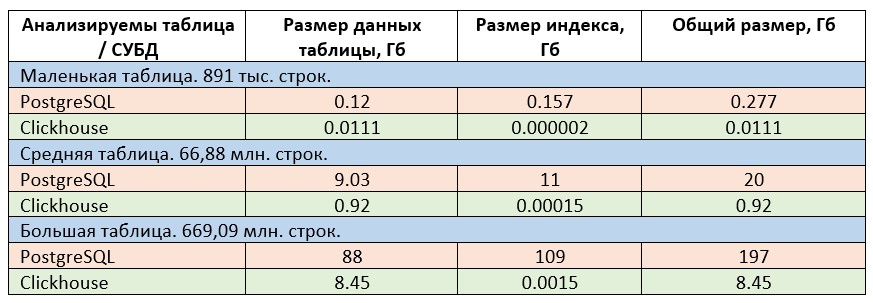
Как видно, Clickhouse крайне успешно справляется со сжатием данных. Плюс хранение Primary Key у Clickhouse чрезвычайно оптимизировано и фактически размером индекса можно пренебрегать. Исходя из результатов, приведенных в таблице, Clickhouse обеспечивает экономию в месте хранения в 23 раза по сравнению в PostrgeSQL.
5. Контрольные запросы для оценки производительности.
При выборе контрольных запросов исходил из реальных практик. Было выбрано 3 практических кейса для анализа. Каждый имеет 2 уровня сложности: с отбором по станции/резервуару и по всей сети АЗС. Отбор по станции попадает в индекс, поэтому работает довольно быстро на существующей архитектуре. Без отбора по станции во всех запросах используются отборы по периодам. Для их ускорения как будто нужен отдельный индекс с датой первым полем, но, как говорил в начале статьи, PostgreSQL при большом количестве строк перестает использовать такой индекс и переходит к Table scan. Поэтому для сравнения результатов PostgreSQL и Clickhouse в рамках данной задачи считаю отсутствие такого индекса в базе данных PostgreSQL допустимым. Так же это позволит оценить производительность СУБД для «необычных» запросов, которые по каким-то причинам не попадают в индекс. Для базы на Clickhouse дополнительного индексирования не выполнялось.
Для написания SQL-запросов использовал функционал СУБД, который напрямую не поддерживается 1С. Т.е. данные запросы нельзя напрямую перевести на язык 1С при использовании внешнего источника данных в виде базы PostgreSQL. Это сделано намеренно, так как, во-первых, целевая система (Clickhouse) не может быть подключена как внешний источник данных, во-вторых, конструкции типа оконных функций и CTE позволяют оптимизировать запрос и повысить скорость его работы.
Перехожу к описанию тестовых запросов и задач, которые они решают. Для каждой задачи приведен текст SQL-запроса. Если запрос для Clickhouse отличается от запроса для PostgreSQL, то они приведены оба.
- Остаток топлива в резервуарах на дату. Необходимо получить остаток топлива в конкретном резервуаре конкретной станции на определенную дату. Текст запроса:
select station_id, tank_no, volume, datetime from
(
select
station_id, tank_no, volume, datetime,
max(datetime) over (partition by station_id, tank_no) as max_dt
from tank_measures
where station_id = '<station_id>'
and tank_no = '<tank_no>'
and datetime < '2023-05-15'
) as slice_ready
where datetime = max_dt
- Для усложненного варианта по всей сети АСЗ используется тот же запрос, но без условий по station_id и tank_no.
- Время, проведенное станцией с низким остатком в каком-либо резервуаре. Максимальный объем резервуара принимаем равным максимальным показаниям датчика за весь период наблюдения. Если объем топлива в резервуаре становится ниже 10% от определенного максимума, то считается, что уровень топлива низкий. В данной задаче требуется исключить ошибочные замеры (поле error не заполнено). Т.к. замеры приходят один раз в 5 минут и считается, что «пробелов» в замерах нет, то принимаем, что одна запись в таблице с уровнем топлива < 10% от определенного максимума для резервуара = 5 минутам времени, проведенным с низким уровнем запасов. Требуется определить, сколько суммарно минут уровень топлива в резервуаре был ниже минимума на протяжении определенного промежутка времени. В данном примере промежуток времени равен одному месяцу – маю 2023 г. Вариант запроса для определения времени, проведенного станцией ниже минимума по каждому из резервуаров на протяжении определенного периода:
select station_id, tank_no, sum(minutes_under_min) minutes_under_min from
(
select
m.station_id, m.tank_no, m.datetime,
case when volume < lvls.low_level then 5
else 0
end minutes_under_min
from tank_measures as m
inner join
(
select station_id, tank_no, 0.1 * max(volume) as low_level
from tank_measures
where error = ''
and station_id = '<station_id>'
group by station_id, tank_no
) as lvls
on lvls.station_id = m.station_id
and lvls.tank_no = m.tank_no
where error = ''
and m.station_id = '<station_id>'
and datetime >= '2023-05-01'
and datetime < '2023-06-01'
) as mins
group by station_id, tank_no
having sum(minutes_under_min) > 0
Текст запроса без отбора по станции будет аналогичный, но без условий по station_id.
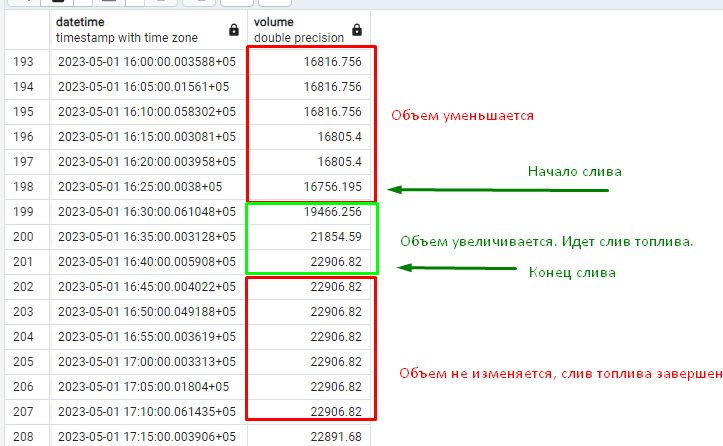
- Пополнения резервуаров. Когда бензовоз приезжает на АЗС и начинает сливать топливо в резервуар, объем в последнем начинает расти. Считается, что скорость слива топлива бензовозом кратно выше максимальной скорости продажи топлива в розницу и объемом продаж для данной задачи пренебрегаем. Когда очередная запись в таблице имеет больший объем, чем предыдущая, то считаем, что предыдущая запись – это начало слива топлива бензовозом (начальные дата + объем). Бензовоз сливает топливо дольше 5 минут и меньше 2 часов. Считается, что слив топлива завершен, когда очередная запись в таблице имеет объем ниже либо равный, чем предыдущая. Т.е. слив топлива характерен последовательным увеличением объема от строки к строке и заканчивается на последней записи, когда объем рос. Следует учесть изменение объема топлива в зависимости от температуры: показания могут расти при росте температуры. Для простоты считается, что увеличение объема менее, чем на 1000 литров сливом бензовоза не является. Для данной задачи так же требуется исключить ошибочные показания (поле error не заполнено).
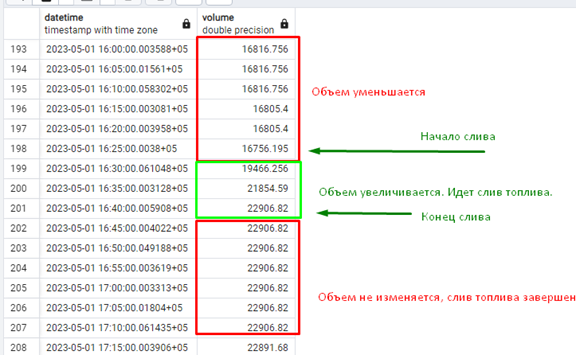
Задача: вывести все пополнения запасов станции (всех резервуаров) за период времени. С указанием начала пополнения, окончания пополнения, объемом пополнения, длительностью работы бензовоза. В данном примере промежуток времени для анализа пополнений равен одному месяцу – маю 2023.
Решение задачи для конкретной АЗС. Текст запроса сложен и отличается для PostgreSQL и Clickhouse. Для Clickhouse было использовано упомянутое выше соединение ASOF JOIN, что уже можно считать хорошей оптимизацией на уровне запроса.
Текст PostrgeSQL:
with refuelments as (
select * from
( select
tm.datetime, tm.station_id, tm.tank_no,tm.volume as v,
prev.volume as pv, prev.datetime as p_dt,
max(prev.datetime) over (partition by tm.station_id, tm.tank_no, tm.datetime) as prev_dt
from tank_measures as tm
inner join tank_measures as prev
on prev.station_id = tm.station_id
and prev.tank_no = tm.tank_no
and prev.datetime < tm.datetime
and prev.datetime > tm.datetime - INTERVAL '2 hour'
and prev.error = ''
where
tm.error = ''
and tm.datetime >= '2023-05-01'
and tm.datetime < '2023-06-01'
and tm.station_id = '<station_id>'
) as cur_prev
where v > pv + 1000 and p_dt = prev_dt
)
select
station_id, tank_no, prev_prev_dt as refuelment_start,
sum(v - pv) as refuelmet_v,
min(pv) as lowest_v,
max(datetime) as refuelment_end,
max(datetime) - prev_prev_dt as refuelment_lenght
from
(
select refuelments.*, prev.prev_dt as prev_prev_dt,
min(prev.prev_dt) over (partition by refuelments.station_id, refuelments.tank_no, refuelments.datetime) as refuel_starts
from refuelments
inner join refuelments as prev
on prev.station_id = refuelments.station_id
and prev.tank_no = refuelments.tank_no
and prev.prev_dt <= refuelments.prev_dt
and DATE_PART('day', refuelments.prev_dt – prev.prev_dt) * 24 + DATE_PART('hour', refuelments.prev_dt - prev.prev_dt) < 2
) as starts
where refuel_starts = prev_prev_dt
group by station_id, tank_no, prev_prev_dt
Текст Clickhouse. Запрос адаптирован под особенности использования этой СУБД.
WITH refuelments AS
(
SELECT
m.station_id, m.tank_no, m.datetime,
m.volume AS v, p.volume AS pv, p.datetime AS prev_dt
FROM tank_measures AS m
ASOF INNER JOIN tank_measures AS p
ON (p.station_id = m.station_id)
AND (p.station_id = '<station_id>')
AND (p.tank_no = m.tank_no)
AND (p.datetime < '2023-06-01')
AND (p.datetime > '2023-04-30')
AND (p.datetime < m.datetime)
AND (p.error = '')
WHERE (m.station_id = '<station_id>')
AND (m.error = '')
AND (m.datetime >= '2023-05-01')
AND (m.datetime < '2023-06-01')
AND (m.volume > (p.volume + 1000))
)
SELECT
station_id, tank_no,
prev_prev_dt AS refuelment_start,
sum(v - pv) AS refuelment_v,
min(pv) AS lowest_v,
max(datetime) AS refuelment_end,
addSeconds('0001-01-1', max(datetime) – prev_prev_dt) AS refuelment_lenght
FROM
(
SELECT
refuelments.*,
prev.prev_dt AS prev_prev_dt,
min(prev.prev_dt) OVER (PARTITION BY refuelments.station_id, refuelments.tank_no, refuelments.datetime) AS refuel_starts
FROM refuelments
INNER JOIN refuelments AS prev
ON (prev.station_id = refuelments.station_id)
AND (prev.tank_no = refuelments.tank_no)
WHERE
(dateDiff('hour', prev.prev_dt, refuelments.prev_dt) < 2)
AND (dateDiff('hour', prev.prev_dt, refuelments.prev_dt) >= 0)
) AS starts
WHERE refuel_starts = prev_prev_dt
GROUP BY station_id, tank_no, prev_prev_dt
6. Сравнение производительности запросов на разных СУБД и разном количестве записей в таблице.
Немного про технологию замеров. Они выполнялись внутри клиентов для СУБД. Для PostgreSQL – это pgAdmin. Для Clickhouse – нативный клиент Clickhouse-client. При выполнении замеров предпринимались меры по очистке кешированных данных. Показатель времени брался из данных используемого клиента СУБД.
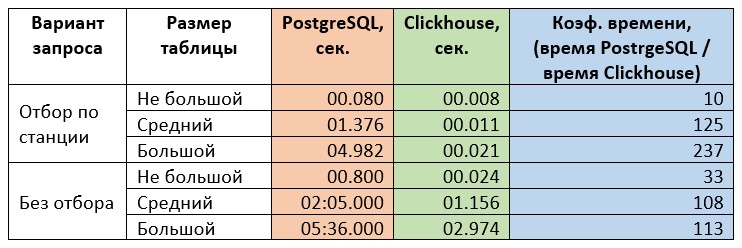
Первая задача. Вариант с отбором характерен очень точным попаданием индекс. Поэтому производительность ожидается высокой для любой СУБД. Сам отчет имеет только одну оконную функцию и для варианта запроса без отбора не должен представлять сложности в вычислении результата. Эту задачу, в случае использования отборов, можно характеризовать как «простой запрос, пригодный для вычисления значений, отображаемых в пользовательском интерфейсе». То есть можно результат показывать на формах, не в отдельных отчетах. Сравнение результатов замеров приведено в таблице ниже.
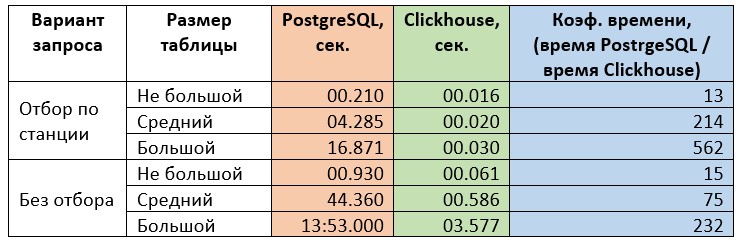
Вторая задача. Вариант с отбором характерен попаданием в индекс с отбором по станции. Плюс используется подзапрос без отбора по дате для вычисления максимального показателя наполненности резервуара за весь период наблюдений. На PostgreSQL без отбора по станции этот подзапрос 100% приведет к Table scan с агрегированием. Запрос так же характерен левым соединением, т.е. на уровне СУБД будет выполнена или сортировка или хеширование. В результате запрос уже имеет двойное чтение таблицы, плюс левое соединение, плюс пару операций агрегации данных. Это создает больше нагрузки на СУБД для вычисления результата. Такой запрос можно характеризовать как «не сложный аналитический отчет». То есть время его выполнения ожидается уже достаточно большим. Для использования на экранных формах он, скорее всего, не подойдет. Замеры по второму запросу приведены в таблице ниже.
Третья задача. Это уже сложная аналитическая задача, которая, очевидно, должна быть представлена в виде отдельного отчета для пользователей. При вычислении результата СУБД нужно не только проводить чтение таблиц, но и большую и «тяжелую» пост-обработку результатов. Замеры по третьему запросу приведены в таблице ниже.
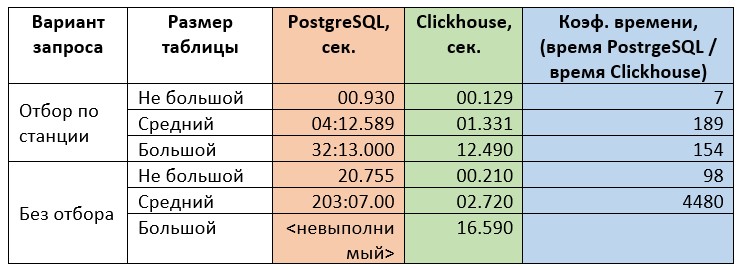
Как видно из замеров, скорость выполнения запросов на Clickhouse на 1-2 порядка выше, чем в PostgreSQL. Что является фантастическим результатом. Хотя замеры и не были ориентированы на оценку деградации производительности с ростом числа записей, но можно проследить тенденцию, что скорость работы Clickhouse значительно меньше падает с ростом таблиц, чем в PostgreSQL.
Напомню, что в «средней» таблице примерно в 60 раз больше записей, чем в «не большой». А в «большой» таблице – в 10 раз больше записей, чем в «средней». «Средняя» таблица – это примерный объем данных в текущей базе, а «большая» таблица – это оценка объема данных через несколько лет.
Опираясь на проведенный эксперимент, можно ожидать, что через несколько лет производительность PostgreSQL на текущей архитектуре упадет на столько, что даже построение не сложного аналитического отчета за не большой период будет занимать минуты. Про построение сложных аналитических отчетов придется забыть. А использование результатов небольших запросов с попаданием в индекс на экранных формах будет вызывать существенные задержки.
Другое дело – Clickhouse. Согласно проведенным замерам, можно ожидать, что использование простых запросов не окажет заметного влияния на производительность экранных форм и интерфейс пользователя. Не сложная аналитика будет доступна за секунды. А сложные отчеты будут строиться в разы быстрее, чем сейчас на PostgreSQL. И с временем выполнения, скорее всего, не превышающим 1 минуту.
7. Работа с Clickhouse из 1С.
(upd.) В комментариях мне указали на промашку в статье. Да, Clickhouse можно подключить как внешний источник, поигравшись с настройками драйверов. Не рассматривал такое подключение опираясь на отзывы в интернете, которые прочел. Отзывы эти в двух словах выглядят как "все не очень надежно". Т.к. не хотелось тратить время на то, что не очень надежно, в итоге совсем про это забыл и упустил при подготовке статьи.
Для работы с Clickhouse будем использовать HTTP-интерфейс, который предоставляет сервер. Существует возможность использования протокол HTTPS, но для простоты на этапе тестирования не стал его настраивать. Для доступа по HTTP необходимо:
- В файле \etc\clickhouse-server\config.xml найти и раскомментировать строку
<listen_host>0.0.0.0</listen_host>
После чего перезапустить службу clickhouse-server.
- На виртуальной машине с Clickhouse открыть порт 8123.
Для проверки доступности сервера можно использовать HTTP-запрос: http://<IP address>:8123/ping
Для работы с Clickhouse можно использовать GET и POST запросы на HTTP-сервис сервера. Если немного упростить, то текст запроса для выполнения отправляется в виде параметра URL с именем query при использовании GET-запросов и в теле запроса при использовании POST-запросов. При использовании GET запросов сервер устанавливает режим read-only, т.е. модификация данных через GET не доступна. В данной статье буду рассматривать только GET запросы.
Параметры аутентификации могут быть указаны с использованием HTTP Basic Authentication (например, http://user:password@localhost:8123/), с использованием параметров URL (например, http://localhost:8123/?user=user&password=password) или путем передачи заголовков запросов X-ClickHouse-User и X-ClickHouse-Key для пользователя и пароля соответственно. Если пользователь не был создан, то следует использовать default. Если пароль не задан, то используется пустой пароль. Мне привычней работать с заголовками запросов, на них и остановлюсь.
В запросах по умолчанию используется основная база данных. По умолчанию это база default. Если нужно использовать другую базу, то ее имя можно указать перед именем таблиц. Например, запрос
select max(datetime) from tank_measures
и запрос
select max(datetime) from default.tank_measures
– это одно и то же. Так как база данных у меня одна, то default. в запросах буду опускать.
Результат обработки запроса SELECT возвращается в виде строки в теле ответа. Формат строки по умолчанию – CSV, разделенный табуляциями, без заголовков. В рамках этой статьи предполагается, что результат запроса из Clickhouse должен быть выведен в отчете на СКД. Все остальные случаи использования результатов выборки считаю значительно более простыми в реализации. Чтобы строить отчеты на СКД, нужно уметь преобразовывать ответ от Clickhouse из текста в таблицу значений. Для формата CSV сделать что-то универсальное проблематично, т.к. для каждого запроса придется писать собственный алгоритм парсинга результата. К счастью, у Clickhouse есть несколько форматов представления таблиц, которые можно применять, используя ключевое слово FORMAT в конце выборки SELECT. Список поддерживаемых форматов тут: https://clickhouse.com/docs/ru/interfaces/formats
Для универсальной процедуры парсинга ответа в виде ТЗ хорошо подходит формат JSON. При его использовании СУБД вернет строку JSON, которую можно типовыми методами преобразовать в объекты 1С (массивы и структуры), а далее создать и наполнить ТЗ. В структуре ответа будут следующие интересные объекты:
- meta – массив с описанием метаданных результирующей выборки. С указанием имени столбца и типа данных, который он содержит. Идеально для подготовки колонок ТЗ.
- date – массив объектов. Каждый элемент – строка выборки в виде структуры, где ключ – имя колонки, а значение – ее значение для текущей строки.
- rows – количество строк в выборке.
- rows_before_limit_at_least – оценка размера выборки без использования ограничения LIMIT.
- statistics – статистика выполнения запроса. Может быть использована для логирования длительности выполнения запросов разных типов. Объект с полями:
- elapsed – время выполнения запроса
- rows_read – количество обработанных строк.
- bytes_read – количество прочитанных байт.
Для построения отчета с использованием СКД так же следует задуматься над приведением строк из выборки к объектам базы 1С. Например, для тестовой таблицы необходимо будет преобразовать номера станций в элементы справочника Склады, номера резервуаров – в элементы справочника Резервуары. Тут что-то универсальное уже предложить не получится, конечное решение будет зависеть от структуры базы и данных в ней. Но общая рекомендация одна – избегать построчного заполнения таблицы сопоставленными данными. На много эффективнее это делать в запросе.
Итак. В общих чертах алгоритм построения отчета на СКД для базы данных на Clickhouse выглядит следующим:
- В модуле объекта отчета в процедуре ПриКомпоновкеРезультата установить СтандартнаяОбработка = Ложь. Получение данных из Clickhouse и дальнейшая их обработка будет выполняться внутри этой процедуры.
- Генерация SQL-запроса. Под генерацией в первую очередь понимаю анализ сделанных отборов в отчете и их интерпретация в тексте SQL-запроса. Например, отбор по периоду добавить в секцию запроса WHERE для поля datetime. Или отбор по складу в той же секции для station_id. Это необходимо для того, чтобы максимально ограничить объем выборки из базы данных для целей отчета. Не дело читать всю таблицу полностью каждый раз, когда результат нужен за 1 день по 1 станции.
- Установить соединение с сервером Clickhouse, отправить запрос на выполнение, получить результат в виде строки.
- Преобразовать ответ от сервера в типизированную таблицу значений.
- Выполнить приведение типов Clickhouse к типам 1С. Это может быть дополнение таблицы новыми колонками с их заполнением. Но лучше, если это возможно, выполнить этот этап в тексте запроса СКД. В данном примере я так и поступлю.
- Поместить полученную ТЗ во временную таблицу с сохранением менеджера временных таблиц.
- Передать менеджер временных таблиц в параметрах инициализации процессора компоновки данных. Скомпоновать результат.
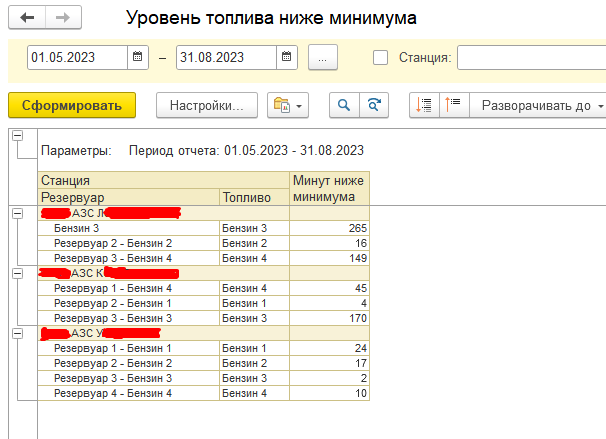
Начнем подготовку отчета. (проверен на УТ 11.5.15.96). Отчет буду делать на базе задачи номер 2 из тестовых примеров – количество времени внутри заданного периода, проведенных станцией с остатком топлива ниже 10% от максимально зарегистрированного. В качестве источника данных СКД будет запрос, приведенный ниже.
ВЫБРАТЬ
ВТ_ДанныеCH.station_id КАК НомерСтанции,
ВТ_ДанныеCH.tank_no КАК НомерРезервуара,
ВТ_ДанныеCH.minutes_under_min КАК МинутНижеМинимума,
Склады.Ссылка КАК Станция,
ас_ТопливныеРезервуары.Ссылка КАК Резервуар,
ас_ТопливныеРезервуары.Топливо КАК Топливо
ИЗ
ВТ_ДанныеCH КАК ВТ_ДанныеCH
ВНУТРЕННЕЕ СОЕДИНЕНИЕ Справочник.Склады КАК Склады
ВНУТРЕННЕЕ СОЕДИНЕНИЕ Справочник.ас_ТопливныеРезервуары КАК ас_ТопливныеРезервуары
ПО (ас_ТопливныеРезервуары.Станция = Склады.Ссылка)
ПО ВТ_ДанныеCH.station_id = Склады.ас_НомерСтанции
ГДЕ
ас_ТопливныеРезервуары.POSНомер = ВТ_ДанныеCH.tank_no
Здесь ВТ_ДанныеCH – временная таблица, куда позже будет помещена ТЗ с результатами выполнения запроса на Clickhouse. Внутреннее соединение использовано осознано. Считается, что в таблице замеров не может быть данных, которым не соответствует какой-то элемент в базе 1С. На практике у нас это закреплено рядом архитектурных решений.
Отборы в СКД сделаны в виде отборов по объектам 1С. Сделанные отборы по станциям будут транслированы в отбор для запроса Clickhouse. Для указания периода вручную добавил параметр СКД «ПериодОтчета» с типом «Стандартный период».
- Переходим к модулю отчета. Добавляем процедуру «ПриКомпоновкеРезультата», сразу выключаем стандартную обработку.
- Добавляем текст запроса на SQL. Параметры запроса будут позже заменены текстами соответствующих отборов.
Процедура ПриКомпоновкеРезультата(ДокументРезультат, ДанныеРасшифровки, СтандартнаяОбработка)
//1. Отключить стандартную обработку
СтандартнаяОбработка = Ложь;
//2. Подготовка запроса в соответствии с параметрами
ТекстЗапроса =
"SELECT
| station_id,
| toInt8(tank_no) as tank_no,
| sumIf(volume < low_level, 5) AS minutes_under_min
|FROM
|(
| SELECT
| m.station_id,
| m.tank_no,
| m.datetime,
| volume,
| lvls.low_level
| FROM tank_measures_big AS m
| INNER JOIN
| (
| SELECT
| station_id,
| tank_no,
| 0.1 * max(volume) AS low_level
| FROM tank_measures_big
| WHERE error = ''
| AND &УсловиеПоСтанцииВложенный
| GROUP BY
| station_id,
| tank_no
| ) AS lvls ON (lvls.station_id = m.station_id) AND (lvls.tank_no = m.tank_no)
| WHERE (error = '')
| AND (datetime >= '&ДатаНачала')
| AND (datetime < '&ДатаОкончания')
| AND &УсловиеПоСтанцииОбщий
|) AS mins
|GROUP BY
| station_id,
| tank_no
|HAVING sumIf(volume < low_level, 5) > 0
|FORMAT JSON";
Теперь необходимо достать из настроек СКД период отчета, привести даты к формату, используемому в Clickhouse. Для простоты добавлено условие, что границы периода должны быть заполнены. Для получения массива станций у меня реализована функция, которая анализирует отборы СКД и по ним строит запрос к справочнику Склады с условиями, которые наложил пользователь. В результате получается массив номеров станций, который преобразуется в условие запроса SQL. Если отборов по станции не было задано, то условие по станции будет передано всегда верное (1 = 1). Если отборы по станции были такие, что ни одна из них им не соответствует, то условие по станции для SQL будет указано заведомо ложное (1 = 0). Текст этого участка модуля приведен ниже.
//возвращает Неопределено, если условие в отборах не задано
//Иначе возвращает массив.
//Пустой массив - признак того, что условию отборов ни одна станция не удовлетворяет
ОтборПоСтанциям = ПолучитьФильтрПоНастройкам("Станция");
Настройки = КомпоновщикНастроек.ПолучитьНастройки();
ПериодОтчета = Настройки.ПараметрыДанных.Элементы.Найти("ПериодОтчета").Значение;
Если не ЗначениеЗаполнено(ПериодОтчета.ДатаНачала) или
не ЗначениеЗаполнено(ПериодОтчета.ДатаОкончания) тогда
ВызватьИсключение "Необходимо указать конечный период для построения отчета";
КонецЕсли;
ДатаНачала = Формат(ПериодОтчета.ДатаНачала, "ДФ=гггг-ММ-дд");
ДатаОкончания = Формат(ПериодОтчета.ДатаОкончания + 24*3600, "ДФ=гггг-ММ-дд");
ТекстЗапроса = СтрЗаменить(ТекстЗапроса, "&ДатаНачала", ДатаНачала);
ТекстЗапроса = СтрЗаменить(ТекстЗапроса, "&ДатаОкончания", ДатаОкончания);
Если ОтборПоСтанциям = Неопределено тогда
ТекстЗапроса = СтрЗаменить(ТекстЗапроса, "&УсловиеПоСтанцииВложенный", "1=1");
ТекстЗапроса = СтрЗаменить(ТекстЗапроса, "&УсловиеПоСтанцииОбщий", "1=1");
ИначеЕсли ОтборПоСтанциям.количество() = 0 тогда
//задано такое условие, что ни одна станция в него не попала
ТекстЗапроса = СтрЗаменить(ТекстЗапроса, "&УсловиеПоСтанцииВложенный", "1=0");
ТекстЗапроса = СтрЗаменить(ТекстЗапроса, "&УсловиеПоСтанцииОбщий", "1=0");
Иначе
УсловиеСтанций = "station_id IN (";
Для каждого станция из ОтборПоСтанциям цикл
УсловиеСтанций = УсловиеСтанций + "'" + станция + "',";
КонецЦикла;
УсловиеСтанций = лев(УсловиеСтанций, СтрДлина(УсловиеСтанций) - 1) + ")";
ТекстЗапроса = СтрЗаменить(ТекстЗапроса, "&УсловиеПоСтанцииВложенный", УсловиеСтанций);
ТекстЗапроса = СтрЗаменить(ТекстЗапроса, "&УсловиеПоСтанцииОбщий", "m." + УсловиеСтанций);
КонецЕсли;
- Запрос готов к отправке. Для работы с Clickhouse сразу сделал более-менее универсальный программный интерфейс. Есть очень большой запас для его усовершенствования, но для целей тестов оставлю пока так. Результат выполнения запроса на сервере будет возвращаться в виде структуры, которая описана в следующей функции:
//Возвращает структуру с полями:
//Успех - Булево. Если Истина, то запрос выполнен успешно
//Ошибка - Строка. Заполнено описанием ошибки, если при выполнении запроса возникла ошибка
//Результат - Строка. Результат, полученный от сервера
Функция НовыйРезультатВыполненияЗапроса()
Результат = новый Структура;
Результат.Вставить("Успех", Истина);
Результат.Вставить("Ошибка", "");
Результат.Вставить("Результат", "");
Возврат Результат;
КонецФункции
Параметры подключения к серверу Clickhouse возвращает следующая функция:
//Возвращает структуру с параметрами подключения к серверу Clickhouse
Функция ПараметрыПодключенияClickhose()
Результат = новый Структура;
Результат.Вставить("Сервер", "192.168.70.114");
Результат.Вставить("Порт", 8123);
Результат.Вставить("ИмяПользователя", "default");
Результат.Вставить("Пароль", "PASS");
возврат Результат;
КонецФункции
Наконец основная функция, которая устанавливает соединение с сервером, готовит запрос для него по переданным параметрам и настройкам подключения, обрабатывает базовые ошибки и возвращает результат. Заголовки по старой привычке готовлю отдельной функцией.
//Возвращает результат в виде структуры. см. НовыйРезультатВыполненияЗапроса()
Функция ВыполнитьЗапросClickhouse(ТекстЗапроса)
Результат = НовыйРезультатВыполненияЗапроса();
ПараметрыСоединения = ПараметрыПодключенияClickhose();
Попытка
Соединение = новый HTTPСоединение(ПараметрыСоединения.Сервер, ПараметрыСоединения.Порт);
Исключение
Результат.Успех = Ложь;
Результат.Ошибка = "Не удалось установить соединение с сервером Clickhouse. " + ОписаниеОшибки();
Возврат Результат;
КонецПопытки;
Заголовки = ПодготовитьЗаголовки(ПараметрыСоединения);
Запрос = новый HTTPЗапрос("?query=" + ТекстЗапроса, Заголовки);
Попытка
Ответ = Соединение.Получить(Запрос);
Исключение
Результат.Успех = Ложь;
Результат.Ошибка = "Ошибка отправки запроса. " + ОписаниеОшибки();
Возврат Результат;
КонецПопытки;
Если Ответ.КодСостояния <> 200 тогда
Результат.Успех = Ложь;
Результат.Ошибка = "Сервер сообщил об ошибке. Код " + Ответ.КодСостояния + ". Ответ: " + Ответ.ПолучитьТелоКакСтроку();
Возврат Результат;
КонецЕсли;
Результат.Результат = Ответ.ПолучитьТелоКакСтроку();
Возврат Результат;
КонецФункции
//Возвращает соответствие, которое может быть использовано как заголовки HTTP-запроса
Функция ПодготовитьЗаголовки(ПараметрыСоединения)
Результат = новый Соответствие;
если ЗначениеЗаполнено(ПараметрыСоединения.ИмяПользователя) тогда
Результат.Вставить("X-ClickHouse-User", "" + ПараметрыСоединения.ИмяПользователя);
КонецЕсли;
если ЗначениеЗаполнено(ПараметрыСоединения.Пароль) тогда
Результат.Вставить("X-ClickHouse-Key", "" + ПараметрыСоединения.Пароль);
КонецЕсли;
Возврат Результат;
КонецФункции
Все готово к отправке запроса. В процедуру «ПриКомпоновкеРезультата» добавляю строки вызова сервера Clickhouse и обработку ошибки.
//3. Выполнение запроса.
РезультатЗапроса = ВыполнитьЗапросClickhouse(ТекстЗапроса);
Если не РезультатЗапроса.Успех тогда
ВызватьИсключение РезультатЗапроса.Ошибка;
КонецЕсли;
- Теперь необходимо преобразовать текст JSON к таблице значений. Для начала выполню парсинг JSON в объекты 1С (структуры, массивы и т.п.). Для этого воспользуюсь следующей функцией:
//Возвращает объект, прочитанный из строки JSON. При ошибке - возвращает Неопределено
Функция ДесериализоватьОбъект(СтрокаJSON) Экспорт
Чтение = новый ЧтениеJSON;
Чтение.УстановитьСтроку(СтрокаJSON);
попытка
Объект = ПрочитатьJSON(Чтение,Ложь);
исключение
Возврат Неопределено;
КонецПопытки;
возврат Объект;
КонецФункции
Теперь можно из объекта meta получившейся структуры получить состав и описание колонок результата запроса. Для этого соберу соответствие, где для имени колонки будут параметры работы с ней. Т.к. десериализация JSON, скорее всего, не приведет строки к числам и датам, то потребуется преобразование значений. Для этого использую или метод «ПривестиЗначение» у описания типов или внешнюю функцию обработки. Такая, например, наверняка понадобится для работы с датами, полученными из Clickhouse. Текст функции получения описания колонок приведен на скрине ниже. При дальнейшем развитии надо будет добавить дополнительные условия для других типов Clickhouse и прописать работу с ними.
//Возвращает соответствие, где
//Ключ - имя колонки
//Значение - структура. см НовыйСведенияОКолонкеРезультатаClickhouse()
Функция ПодготовитьСоответвиеКолонок(Мета)
Результат = новый Соответствие;
Для Каждого Колонка из Мета цикл
СведенияОКолонке = НовыйСведенияОКолонкеРезультатаClickhouse();
ТипClickhouse = Колонка.type;
Если ТипClickhouse = "String" тогда
//СведенияОКолонке уже подготовлены под строку по умолчанию
ИначеЕсли Найти(ТипClickhouse, "Int") > 0 тогда
СведенияОКолонке.ОписаниеТипов = новый ОписаниеТипов("Число",,
,новый КвалификаторыЧисла(20,0));
СведенияОКолонке.НужноПреобразование = Истина;
ИначеЕсли ТипClickhouse = "Datetime" тогда
//приведено для примера типа, для которого потребуется функция преобразования
//СведенияОКолонке.ОписаниеТипов = новый ОписаниеТипов("Дата",,,,
// ,новый КвалификаторыДаты(ЧастиДаты.ДатаВремя));
//СведенияОКолонке.НужноПреобразование = Истина;
//СведенияОКолонке.ФункцияПреобразования = "ПреобразоватьDatetime";
ИначеЕсли Найти(ТипClickhouse, "FixedString") > 0 тогда
ДлинаСтроки = СтрЗаменить(ТипClickhouse, "FixedString(", "");
ДлинаСтроки = Число(СтрЗаменить(ДлинаСтроки, ")", ""));
СведенияОКолонке.ОписаниеТипов = новый ОписаниеТипов("Строка",,,
,Новый КвалификаторыСтроки(ДлинаСтроки));
Иначе
ВызватьИсключение "Тип " + ТипClickhouse + " не поддерживается";
КонецЕсли;
Результат.Вставить(Колонка.name, СведенияОКолонке);
КонецЦикла;
Возврат Результат;
КонецФункции
//Возвращает структуру с полями:
//ОпиваниеТипов - объект ОписаниеТипов, подходящий для создания этой колонки
//НужноПреобразование - Булево. Истина, если нужно приведение строкового выражения из
// ответа сервера к типу колонки ТЗ.
//ФункцияПреобразования - Имя функции, выполяющей преобразование значения.
// Функция должна иметь один параметр, в который будет передано
// строковое значение поля. Возвращать функция должна результат
// преобразования
//
//Если НужноПреобразование = Истина, а ФункцияПреобразования не заполнена,
//то будет выполнена попытка привести значение Clickhouse у типу, указанному в
//поле ОпиваниеТипов путем ОпиваниеТипов.ПривестиЗначение().
Функция НовыйСведенияОКолонкеРезультатаClickhouse()
Результат = новый Структура;
Результат.Вставить("ОписаниеТипов", Новый ОписаниеТипов("Строка"));
Результат.Вставить("НужноПреобразование", Ложь);
Результат.Вставить("ФункцияПреобразования", "");
Возврат Результат;
КонецФункции
Осталось собрать все эти механизмы воедино, добавить строки таблицы из ответа сервера и ТЗ готова. Итоговая функция получения ТЗ из строкового ответа Clickhouse ниже. В функции не хватает обработки ошибок преобразования типов. В дальнейшем, в случае работы с большими выборками, необходимо будет выполнить замеры производительности и, вероятно, подумать над оптимизацией кода.
Функция ПреобразоватьClickhouse_JSON_В_ТЗ(ТекстJSON)
ОтветСервера = ДесериализоватьОбъект(ТекстJSON);
Если ОтветСервера = Неопределено тогда
ВызватьИсключение "Неожиданный ответ сервера СУБД. " + Символы.ПС + ТекстJSON;
КонецЕсли;
Результат = новый ТаблицаЗначений;
//Подготовка колонок ТЗ
Колонки = ПодготовитьСоответвиеКолонок(ОтветСервера.meta);
КолонкиПрямогоЗаполнения = ""; //строка, которая будет использована для "ЗаполнитьЗначенияСвойств"
Для каждого КлючЗначение из Колонки цикл
Результат.Колонки.Добавить(КлючЗначение.Ключ, КлючЗначение.Значение.ОписаниеТипов);
Если не КлючЗначение.Значение.НужноПреобразование тогда
КолонкиПрямогоЗаполнения = КолонкиПрямогоЗаполнения + КлючЗначение.Ключ + ",";
КонецЕсли;
КонецЦикла;
КолонкиПрямогоЗаполнения = ?(СтрДлина(КолонкиПрямогоЗаполнения) = 0, "",
лев(КолонкиПрямогоЗаполнения, СтрДлина(КолонкиПрямогоЗаполнения) - 1));
//Наполнение ТЗ
Для каждого СтрокаОтвета из ОтветСервера.data цикл
НовСтрока = Результат.Добавить();
ЗаполнитьЗначенияСвойств(НовСтрока, СтрокаОтвета, КолонкиПрямогоЗаполнения);
Для каждого КлючЗначение из Колонки цикл
ПараметрыКолонки = КлючЗначение.Значение;
Если не ПараметрыКолонки.НужноПреобразование тогда
Продолжить;
КонецЕсли;
Если ПараметрыКолонки.ФункцияПреобразования = "" тогда
//не хватает обработки ошибки
НовСтрока[КлючЗначение.Ключ] = ПараметрыКолонки.ОписаниеТипов.ПривестиЗначение(СтрокаОтвета[КлючЗначение.Ключ]);
Иначе
СтрокаВызова = ПараметрыКолонки.ФункцияПреобразования + "(" + СтрокаОтвета[КлючЗначение.Ключ] + ")";
//не хватает обработки ошибки
НовСтрока[КлючЗначение.Ключ] = Вычислить(СтрокаВызова);
КонецЕсли;
КонецЦикла;
КонецЦикла;
Возврат Результат;
КонецФункции
Теперь вызовем ее из процедуры «ПриКомпоновкеРезультата»
//4. Преобразование результата в ТЗ
ТЗ_Clickhouse = ПреобразоватьClickhouse_JSON_В_ТЗ(РезультатЗапроса.Результат);
- На этом шаге для таблицы «ТЗ_Clickhouse» можно добавить специфические для набора данных колонки и прописать их заполнение. Я этого делать не буду. Преобразование идентификаторов к типам 1С у меня реализовано в рамках запроса СКД.
- Подготовим менеджер временных таблиц и поместим ВТ с именем ВТ_ДанныеCH с данными из ТЗ_Clickhouse.
//6. Подготовка ВТ с результатами выборки
МенеджерВТ = Новый МенеджерВременныхТаблиц;
Запрос = Новый запрос;
Запрос.МенеджерВременныхТаблиц = МенеджерВТ;
Запрос.Текст =
"ВЫБРАТЬ
| ВТ.station_id КАК station_id,
| ВТ.tank_no КАК tank_no,
| ВТ.minutes_under_min КАК minutes_under_min
|ПОМЕСТИТЬ ВТ_ДанныеCH
|ИЗ
| &ТЗ КАК ВТ";
Запрос.УстановитьПараметр("ТЗ", ТЗ_Clickhouse);
Запрос.Выполнить();
- Готовим программный вывод СКД. В параметрах инициализации процессора компоновки передаем менеджер временных таблиц.
//7. Вывод СКД
КомпМакета = Новый КомпоновщикМакетаКомпоновкиДанных;
МакетКомпоновки = КомпМакета.Выполнить(СхемаКомпоновкиДанных, Настройки, ДанныеРасшифровки);
ПроцессорКомпДанных = Новый ПроцессорКомпоновкиДанных;
ПроцессорКомпДанных.Инициализировать(МакетКомпоновки, , ДанныеРасшифровки,,,МенеджерВТ);
Вывод = Новый ПроцессорВыводаРезультатаКомпоновкиДанныхВТабличныйДокумент;
Вывод.УстановитьДокумент(ДокументРезультат);
Вывод.Вывести(ПроцессорКомпДанных, Истина);
Все, осталось только настроить структуру отчета и еще парочку косметических мелочей в СКД. Заходим в 1С, открываем отчет, формируем. Красота!
8. Выводы и возможные направления оптимизации.
В ходе тестов был подготовлен тестовый стенд, проведена генерация тестовых наборов данных, выполнено сравнение объема баз на дисках, сравнение скорости выполнения запросов, реализована процедура обращения к Clickhouse из 1С для целей построения отчета на СКД. По сути, проделан полный путь от чистой системы до конечной реализации отчета в 1С с анализом производительности на каждом шаге. Из всего перечисленного можно сделать следующие выводы:
- Clickhouse очень быстрая СУБД. Превосходит PostgreSQL по скорости выполнения запросов на 2-3 порядка. По объему, занимаемому базой, выигрывает примерно в 20 раз. Все это обеспечивает запас по производительности на несколько лет для решения задачи хранения показаний датчиков резервуаров.
- Для целей хранения логов и метрик Clickhouse подходит значительно лучше, чем любая другая, знакомая мне, СУБД.
- Плохо подходит или совсем не пригодна для баз данных, которые в своей логике требуют транзакционной модели работы, большого количества обновлений или удалений данных.
- Имеет богатый набор расширений и функций для языка SQL, за счет чего можно строить более оптимальные и компактные запросы.
- Clickhouse требовательна к объему оперативной памяти. Изначально на тестовом стенде виртуальная машина была развернута с 16 Гб памяти. Но для выполнения сложного аналитического запроса на большой базе данных этого не хватило. Потребовалось увеличение памяти до 36 Гб (потребление памяти СУБД в пике составило 32.6 Гб). Так же не стоит забывать, что в рекомендациях указано требование минимум 8 процессорных ядер.
- Clickhouse менее требовательна к дисковой подсистеме, в отличии от PostgreSQL. При выполнении запросов из задачи №2 PostgreSQL забивал диск на 100% чтением данных на очень большие промежутки времени (минуты). При одновременной работе нескольких пользователей такая нагрузка приведет к еще большей деградации производительности из-за очередей в дисковой подсистеме.
- Работать с Clickhouse из-под 1С можно, но не очень удобно. Требуется написание универсальных программных интерфейсов.
- Clickhouse не подключается как внешний источник данных к 1С. (upd) Подключается, но, по отзывам в интеренете, с этим возможны проблемы. На сколько серьезные и мешающие жить - не исследовал. Ребята из Инфостарта говорят, что успешно используют такое подключение. Оснований им не доверять нет.
- Из двух предыдущих выводов следует, что при обработке больших выборок на тысячи и десятки тысяч строк можно ожидать просадки производительности на этапе парсинга результата и приведения значений из выборки к ссылкам 1С.
В ходе работы выявил много перспективных направлений, над которыми стоит потрудиться в дальнейшем. Например:
- Оптимизация индексов. Т.к. Clickhouse может иметь только один Primary key это накладывает некоторые ограничения. Но существует механизмы партиционирования и так называемых projection – копий таблиц с автоматическим реплицированием и с другим набором индексных полей. Так же есть еще много других «фишек», которые можно изучить, проанализировать и оценить их применяемость для решения конкретных задач.
- Clickhouse имеет интерфейсы, на которых он «притворяется» MySQL и PostrgeSQL. Необходимо поэкспериментировать, не получится ли подключиться к Clickhouse по одному из этих интерфейсов и добавить базу как внешний источник данных в 1С.
- Необходимо провести исследования и тесты, связанные с резервным копированием. Необходимо будет совместно с системным администратором подготовить тестовый стенд на серверах, настроить резервное копирование, проверить корректность его работы и выполнить тренировочную процедуру восстановления из резервной копии.
- Clickhouse должен очень хорошо подойти для хранения журнала регистрации 1С, а так же замеров APDEX. Нужно проработать эти направления в рамках отдельных задач.
- Clickhouse – нативная СУБД для BI-системы Yandex.Datalens, которая не так давно стала доступна в open source. Необходимо провести исследования по разворачиванию этих двух систем, наполнению данными Clickhouse и настройки дашбордов в Datalens. Вариант с мониторингом APDEX на данный момент мне кажется достаточно простой задачей для исследований в этом направлении.
Проверено на следующих конфигурациях и релизах:
- Управление торговлей, редакция 11, релизы 11.5.15.96
Вступайте в нашу телеграмм-группу Инфостарт