Расскажу, как мы собираем логи при работе нашего продукта БИТ.MDT на мобильных приложениях. О самом продукте я рассказывал на конференции Infostart Event 2021 Post-Apocalypse, сейчас немного напомню, чтобы был понятен контекст.

БИТ.MDT – это коробочный продукт, который предназначен для автоматизации на складе товароучетных операций, связанных с маркировкой. Он состоит из:
-
мобильного приложения, которое работает на ТСД;
-
расширения для типовых конфигураций ERP/КА/УТ, которое позволяет интегрироваться с этим мобильным приложением;
-
и различных облачных сервисов.
С точки зрения сбора логов важно, что:
-
Обычно мобильное приложение работает на ТСД, его эксплуатируют кладовщики – люди, которые не сильно понимают, как работать с мобильными приложениями.
-
Часть времени мобильное приложение работает в онлайне, а часть – в офлайне. Причем в офлайне может работать достаточно долго: ушел кладовщик на склад с ТСД, и все – связи с центральной базой нет.
-
У каждого нашего клиента в одной сети на этом мобильном приложении работает, как правило, от 5 до 200 ТСД.
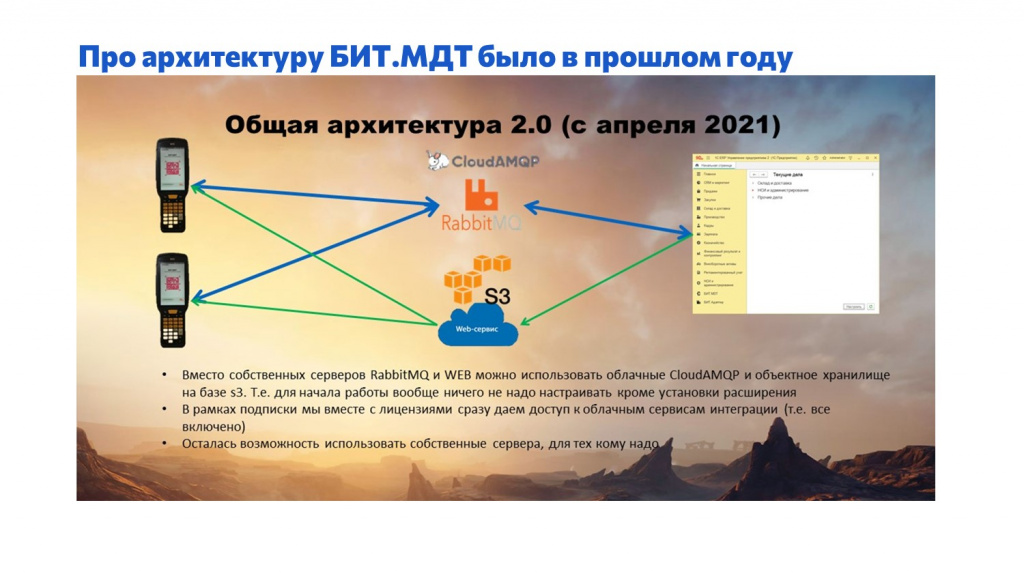
Решение состоит из нескольких частей.
-
мобильное приложение, которое работает на ТСД;
-
расширение для типовой конфигурации ERP/КА/УТ11;
-
и различные сервисы, которые обеспечивают обмен и взаимодействие этих частей между собой.
Текущий обмен реализован с помощью облачного RabbitMQ, а первоначальная инициализация либо обновление – через файловое хранилище формата S3.
Важная особенность: все промежуточные сервисы мы стараемся использовать облачные и готовые. Сами ничего из сервисов у себя стараемся не хостить, чтобы самим ничего не поддерживать и не настраивать.
При этом решение поддерживает и self-hosted вариант – у нас остался один старый клиент, который использует локальный RabbitMQ и веб-сервисы в конфигурации вместо S3 для передачи большого объема файлов. О том, как это работает именно в self-hosted-варианте, можно подробнее посмотреть в презентации прошлого года.
Встроенных средств логирования нет – создаем свой механизм

Теперь о том, почему нам потребовалось организовывать централизованный сбор логов:
-
В мобильной платформе 1С есть особенность – в ней нет журнала регистрации как сущности, и фирма «1С» не обещает его сделать.
-
Если вы хотите собирать логи, вам нужно сделать свой механизм логирования – сохранять информацию в регистре сведений или в каких-то внешних файлах, и дальше их как-то просматривать.
-
Падения платформы в мобильном приложении можно увидеть в logcat.
Но даже если бы платформа решила сделать у себя журнал регистрации в мобильном приложении, это бы не сильно помогло:
-
Мобильных устройств, на которых работает ваше решение, как правило – сотни или тысячи. Смотреть логи на каждом устройстве – неудобно и нереально.
-
А какой-то централизованной системы логов платформа нам не обещает даже для десктопных конфигураций, и в ближайшее время подобного сервиса от вендора, скорее всего, не появится.

Расскажу, как у нас организован централизованный сбор логов.
В мобильном приложении логи собираются в файлы:
-
По структуре эти файлы повторяют записи журнала регистрации.
-
Плюс мы сделали общий модуль с методами, аналогичными платформенным методам записи в журнал регистрации, и везде из кода их вызываем.
Периодически вызывается регламентное задание, которое отправляет файлы с этими логами в облачный сервис сбора логов:
-
Мы собираем логи не только из самого мобильного приложения, но и из используемых внешних компонент.
-
Если связи нет, логи отправляем отложено.
-
Для передачи этих файлов в сервис мы используем простейший протокол HTTPS, который поддерживается платформой и вызывает минимум ошибок.
Дальше все логи загружаются в Яндекс – собираются в таблице в ClickHouse для анализа.
-
Причем мы для этого ни строчки кода не написали – мы целиком пользуемся готовыми сервисами в Яндексе.
-
Это у нас получилось недорого.
-
И для анализа логов, когда они уже оказались в ClickHouse, мы используем либо прямые запросы, либо сервис Yandex DataLens – это простейшая BI-система от Яндекса.

Почему мы используем для накопления логов в мобильном приложении файлы, а не регистры сведений?
-
Поскольку в мобильном приложении для работы с базой данных фактически используется файловый движок 1С, он накладывает свои ограничения – например на размер базы данных.
-
Также есть ограничения из-за блокировки всей таблицы в процессе записи. Если бы мы для сбора логов использовали регистр сведений, у нас были бы проблемы с одновременной записью логов из регламентного задания и из текущего сеанса пользователя: таблица бы блокировалась целиком, и мы бы эти логи записать не смогли.
-
Плюс в мобильном приложении было бы неудобно удалять из разбухшего регистра сведений старые записи с логами.
Поэтому мы логи складываем в файлики, которые просто лежат в файловой системе.
По структуре этих файлов:
-
Каждую минуту мы создаем новый файл с логами – имя файла содержит в себе дату, часы, минуты.
-
В файле содержится информация о логах ровно в том формате, как мы потом ее отправим в Яндекс, чтобы никакие дополнительные преобразования при отправке этих логов не требовались.
-
После успешной отправки логов мы эти файлики просто удаляем – это делается достаточно быстро.
Что мы логируем:
-
Мы вставляем запись логов в коде во все возможные места и во все обработчики ошибок. При этом для каждой записи лога мы указываем уровень логирования.
-
В базе есть константа, где мы указываем минимальный уровень логирования, при котором нужно писать логи.
-
Мы пишем в файлы и отправляем в Яндекс только те логи, уровень логирования которых больше или равен тому, что указан в константе.
В результате мы можем в константе поставить, что хотим логировать только ошибки, и у нас будут отправляться в Яндекс только ошибки, а не все места, где мы эти логи вызываем из кода.

С отправкой логов тоже все просто – отправляем просто регл. заданием, но нужно иметь в виду некоторые особенности:
-
Первая особенность в том, что мобильная база у нас фактически файловая. Из-за этого в мобильном приложении не могут одновременно работать два регламентных задания – они работают по очереди.
-
Поэтому при неудачной отправке логов, либо, если сервис приема логов недоступен, нужно прервать регламентное задание, чтобы выполнились другие, и вернуться к отправке логов потом. Регламентное задание отправки логов должно быть таким, чтобы оно не мешало другим полезным регламентным заданиям.
-
И нужно проверять, что мы не пытаемся отправить текущий файл, который наполняется – в нашем случае, это логи за последнюю минуту.
-
И после отправки – не забывать удалять файлы.
Еще одна особенность – это идентификация отправляемых логов.
-
Так как мы все логи собираем централизованно, нам нужно понимать, с какого устройства конкретные логи пришли. Поэтому в те логи, которые мы из кода отправили, мы добавляем информацию о клиенте, идентификаторе устройства и о лицензии.
-
При отправке логов эту же информацию мы используем для авторизации на сервисе приема логов.
Формат логов у нас используется JSONEachRow, но фактически там текстовый файл, каждая строка которого представляет JSON с именами и значениями полей данного лога.
Сервисы Yandex.Cloud: что используем для логирования
Для приема и обработки этих логов мы используем Yandex.Cloud – это облачный провайдер, предоставляющий кучу различных готовых сервисов. На слайде – скриншот со списком всех сервисов, которые есть. Сервисов очень много.
-
Главная фишка сервисов Yandex.Cloud в том, что они готовы – ничего программировать не надо, нужно только настроить и можно использовать.
-
По составу сервисов Yandex.Cloud очень напоминает AWS. Такое ощущение, что они просто взяли концепцию оттуда и перенесли все сервисы к себе.

Для обработки логов мы в Yandex.Cloud используем несколько сервисов:
-
API GW – обеспечивает Rest API интерфейс для других сервисов Yandex.Cloud. Фактически это точка входа, к которой мы обращаемся из 1С, чтобы отправить логи.
-
Data Streams. Нужен для буферизации логов, которые поступают через API GW – когда логи принимаются, они буферизируются, некоторое время хранятся в буфере.
-
Yandex Data Transfer – готовый сервис для преобразования данных из одного вида в другой. В нашем случае он преобразует данные из JSONEachRow в записи в таблице ClickHouse.
-
Managed Service for ClickHouse – сам ClickHouse в виде сервиса. В эту СУБД стекаются логи с разных ТСД.
-
И DataLens – средство визуализации и анализа информации из табличек в ClickHouse.

Подробнее про ClickHouse.
ClickHouse – это классическая колоночная СУБД, где каждая колонка хранится отдельно в отдельном файле, и можно делать таблицы с большим количеством колонок, и потом эффективно из них извлекать данные только из нужных колонок. Быстро их отображать и показывать.
Если кто не знает, что такое ClickHouse и колоночные СУБД, на Infostart Meetup Friends Олег Филиппов рассказывал о том, как с этим работать.
-
Чтобы поместить данные в ClickHouse, мы ни строчки кода не написали, использовали только готовые сервисы. О том, как мы их настраивали, расскажу чуть позже.
-
Это у нас получилось недорого.
-
И для анализа мы используем прямые запросы либо DataLens – о нем тоже чуть позже.

Давайте поговорим про экономику сервиса для приема логов. Сколько стоят сервисы в Яндексе:
-
API GW стоит 120 рублей за миллион REST-запросов к сервису. Этого миллиона запросов вам хватит на несколько десятков ТСД, которые вы к нему подключите, даже если вы будете отправлять логи каждую минуту.
-
Data Streams – тут мы платим за трафик, который через него проходит. Мы платим чуть меньше 70 рублей в месяц за 256 килобайт в секунду – этого вполне достаточно для десятков, а то и сотен ТСД.
-
Yandex Data Transfer уже больше года бесплатный, и, скорее всего, останется бесплатным и в ближайшее время.
-
Самый дорогой тут сервис – это сам ClickHouse. Но у нас для приема большого объема логов используется достаточно мощный сервер – мы за него платим 5856 рублей в месяц. Самый дешевый, по-моему, от 600 рублей в месяц получается.
-
DataLens тоже бесплатный.
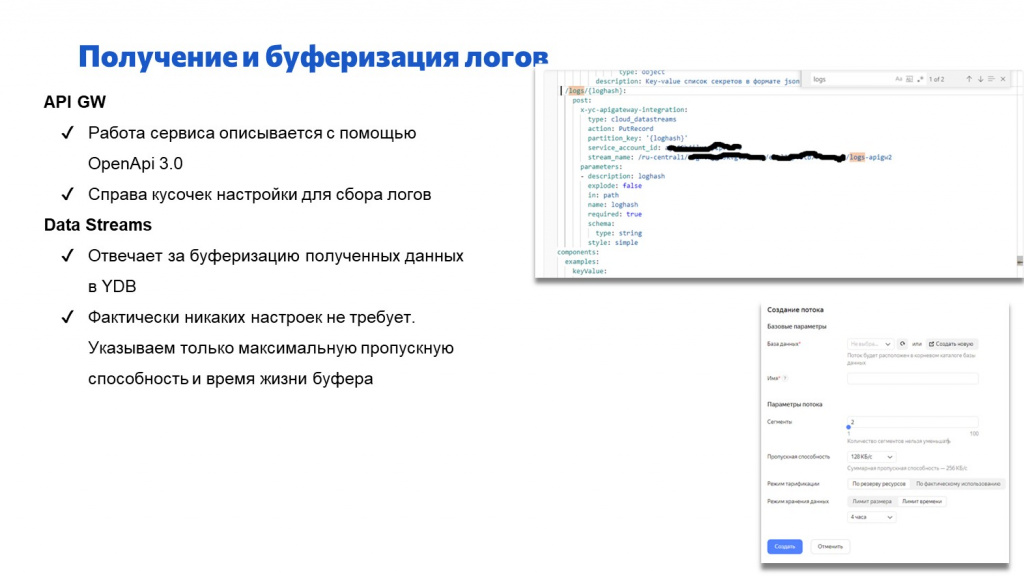
По моей оценке, любой программист 1С может настроить все эти сервисы по документации за 2-3 часа. При этом никаких специальных знаний, чтобы настроить цепочку, не требуется. Расскажу подробнее, как настраивать каждый сервис.
Первая часть – это API GW.
-
Работа сервиса описывается в формате OpenAPI 3.0 – это способ описания REST-сервисов в виде YAML-файла. В некоторых языках программирования – не в 1С – есть возможность по OpenAPI сразу генерировать код, который будет взаимодействие с этим сервисом обрабатывать.
-
На слайде я привел кусочек этого YAML, который описывает прием логов. Чтобы начать принимать логи снаружи, достаточно нескольких строк, где мы прописываем: обращаясь к API GW через слэш, указывай logs, и все, что придет, переадресовывай на Data Stream по указанному адресу.
Следующий сервис – Data Stream – отвечает за буферизацию логов.
-
Логов параллельно может приходить много – перед их обработкой нам нужно их где-то хранить и буферизировать.
-
Настройки у него элементарные. Фактически мы указываем в настройках максимальную пропускную способность, количество потоков и глубину буфера, которая будет храниться. Как он там дальше будет их хранить и принимать – это все проблемы Яндекса.
-
Хранит он их в YDB (это Yandex Data Base) – базе данных Яндекса. Работает этот сервис достаточно стабильно.
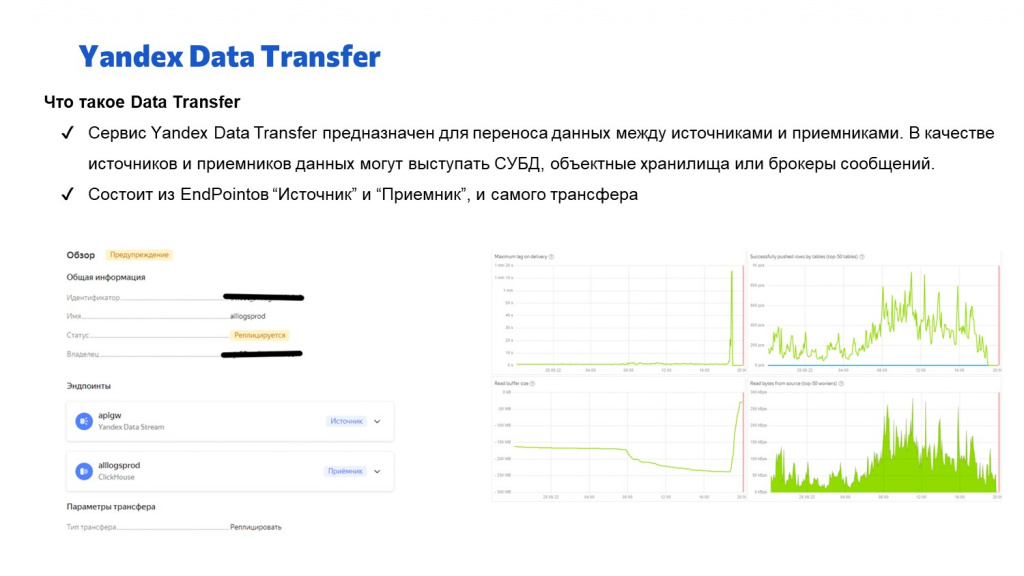
Когда мы приняли логи, их буферизировали, дальше нам нужно их конвертировать – перенести в ClickHouse. Для этого мы используем сервис Yandex Data Transfer:
-
Он предназначен для конвертации данных из всего во все – умеет конвертировать данные между СУБД, между объектами, хранилищами СУБД, из брокеров сообщений забирать данные и класть в СУБД. В нашем случае он конвертирует текстовые данные из Data Stream и кладет их в базу данных.
-
Yandex Data Transfer фактически состоит из трех частей: «Источник», «Приемник» и сам трансфер, который связывает этот источник с приемником.
На слайде показаны некоторые графики этого трансфера – о том, как выглядит входящий и исходящий поток в килобайтах.
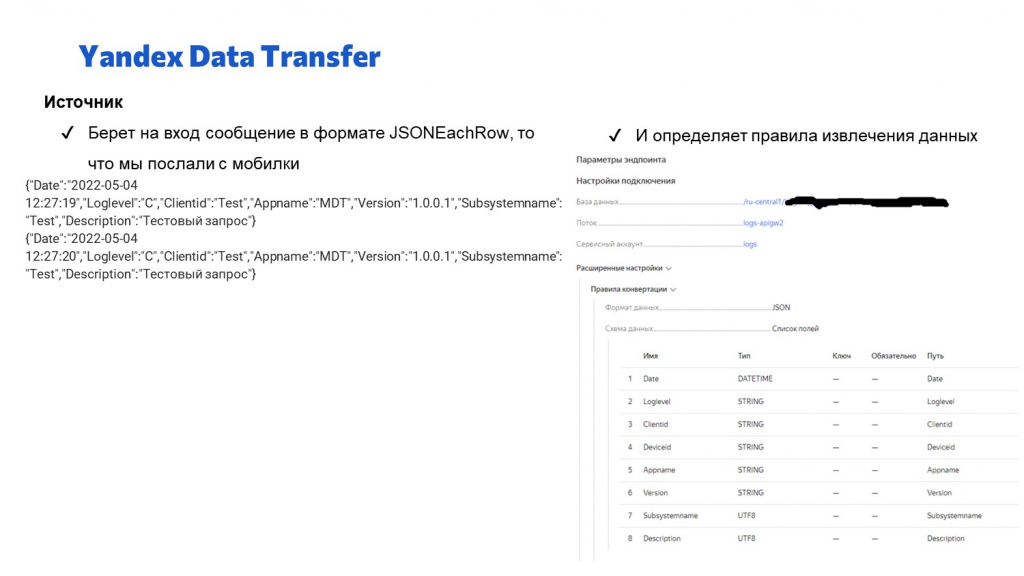
А здесь видно, как настраивается источник для Yandex Data Transfer – в источнике мы указываем, в каком формате и откуда мы данные должны забрать, и как эти данные структурируются.
-
Например, здесь слева показано, как мы на вход с мобильного приложения подаем две записи логов в формате JSONEachRow – в каждой строке JSON с именами и значениями полей.
-
А в настройке источника мы указываем: какие поля нужно оттуда извлечь, какого они типа, и с каким псевдонимом их сделать.
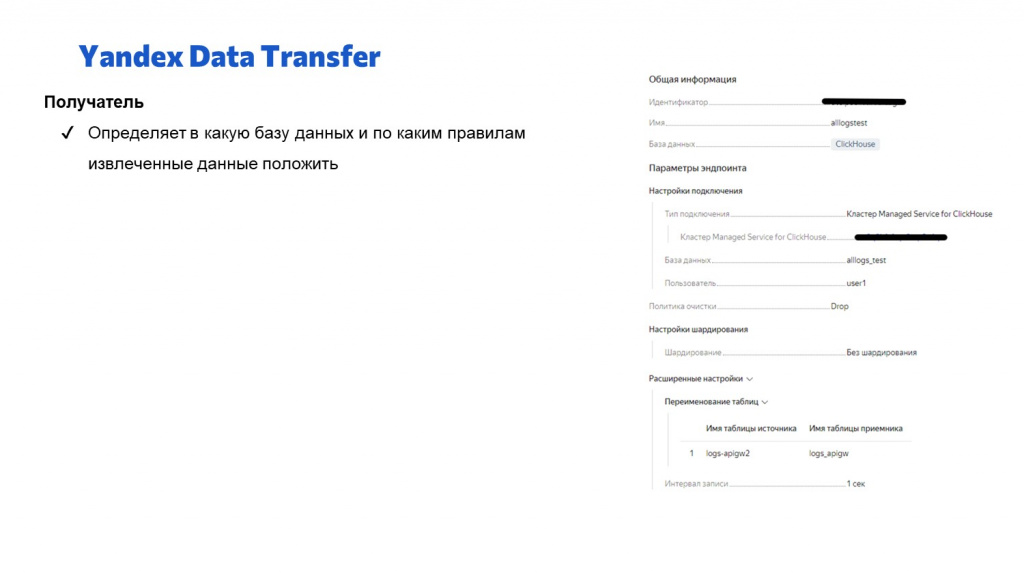
Настройка получателя для Yandex Data Transfer еще проще:
-
Мы просто указываем базу данных и таблицу, куда эти данные нужно сложить.
-
Все остальное трансфер сделает сам – он добавит в эту таблицу колонки в соответствии с источником и будет сам складывать туда данные.
-
Обратите внимание, здесь у получателя в правом нижнем углу интересный параметр – интервал записи. Он позволяет перекладывать записи не по одной штуке, а группировать их и помещать пачками. Для быстродействия ClickHouse это важно – он гораздо быстрее работает, когда мы записи добавляем не по одной, а более-менее большими кусками.

После того как вы сделали настройки в Yandex Data Transfer, в ClickHouse уже появится табличка с данными логов – на слайде показано, как выглядят логи внутри этой таблицы.
-
Мы используем Managed Service for ClickHouse – это ClickHouse, который Яндекс сам администрирует, настраивает.
-
Мы только указываем нужную нам мощность сервера – дальнейшим занимается сам Яндекс.
-
Чтобы настроить импорт логов в ClickHouse, фактически нужно только создать табличку и указать в Yandex Data Transfer, чтобы данные помещались в эту табличку. Структуру, индексы и прочее – все это делает сам Yandex Data Transfer. И данные туда в реальном времени перемещает тоже Yandex Data Transfer.
Если у вас небольшое количество ТСД, больше ничего делать не нужно – этих настроек достаточно, чтобы увидеть централизованные логи.
На стороне 1С отправку логов сделать тоже несложно – там кодировать тоже часа на два.

В случае, если у вас устройств больше, чем десятки, потребуется сделать некоторые продвинутые настройки – в первую очередь, на стороне ClickHouse.
Первая задача – это сбор данных из разных источников.
-
Например, мы хотим собирать данные не только с ТСД, но и из центральной базы 1С, с которой эти ТСД интегрируются – хотим видеть общие логи по всей системе.
-
Но в центральной базе 1С формат логов чуть-чуть другой – там нам удобнее сделать немного другой состав полей. Соответственно, для логов, которые приходят из центральной базы, мы немного по-другому настраиваем Yandex Data Transfer, и создаем другую таблицу в ClickHouse.
-
В результате у нас в ClickHouse появится несколько таблиц разной структуры.
-
При этом мы бы хотели видеть сводные данные по логам – в одной таблице с быстрыми индексами
Чтобы собрать данные из разных источников, в Clickhouse можно использовать materialized view:
-
Задается Materialized view с помощью SQL-запроса.
-
С помощью Materialized view можно исходные разнородные логи, собранные в разных таблицах, сложить в одну общую физическую таблицу.
Способ с Materialized view позволяет нам делать более быстрые и удобные индексы для отображения потом в отчетах данных этих логов.
-
В таблицах, которые делает Yandex Data Transfer, он делает индексы, удобные ему – чтобы данные можно было эффективно загружать, подгружать, заменять.
-
А мы можем создать отдельную таблицу с удобными нам индексами и перекладывать туда данные автоматически.
Следующий лайфхак помогает решить такую проблему как размер данных.
Поскольку логов у нас будет много, нам нужно с этими большими логами что-то делать. Причем чаще всего нам нужны логи только оперативные – допустим, за последний месяц. За прошлый месяц их тоже надо хранить, но мы их не смотрим каждый день.
В ClickHouse есть готовые средства, как с этой проблемой бороться.
-
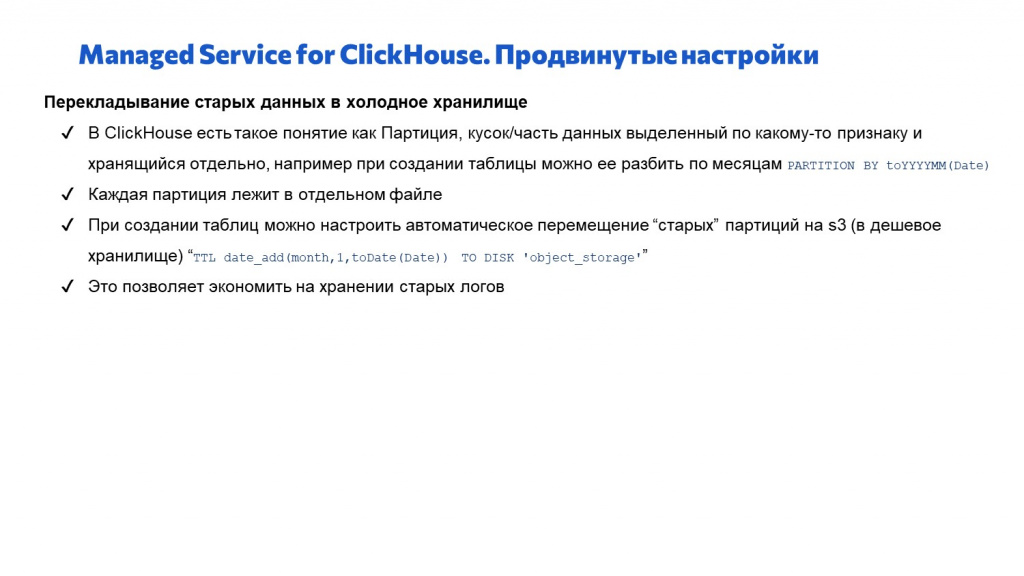
В первую очередь нам поможет такое понятие как партиция – это часть данных, выделенных по какому-то признаку. Мы можем при создании таблицы написать некое условие, и ClickHouse автоматически разобьет все данные по выбранному признаку. При выборе
PARTITION BY toYYYYMM(Date)данные будут разбиты на партиции по месяцам. -
Каждую партицию ClickHouse будет хранить в отдельных файлах. За текущий месяц – в одном файле, за прошлый месяц – в другом файле и так далее.
-
Дальше при создании таблицы мы можем сказать, чтобы старые партиции автоматически переносились на s3 – в холодное хранилище, которое стоит в 10 раз дешевле и лежит отдельно. Добавляем простейшее условие:
TTL date_add(month,1,toDate(Date)) TO DISK 'object_storage'Оно говорит о том, что нам надо перенести все партиции, которые старше 1 месяца, в Yandex Object Storage. И все. В текущей основной таблице у нас лежат данные только за последний месяц, она относительно небольшого размера, быстро работает, старые партиции автоматически переносятся в холодное хранилище. Если мы вдруг хотим посмотреть какие-то логи за прошлый-позапрошлый месяц, мы можем партицию с s3 вернуть обратно на сервер ClickHouse и посмотреть данные за прошлый период. Но размер текущей таблички – небольшой. -
Этот метод позволяет экономить место и деньги.
Не только расследуем проблемы, но и собираем аналитику
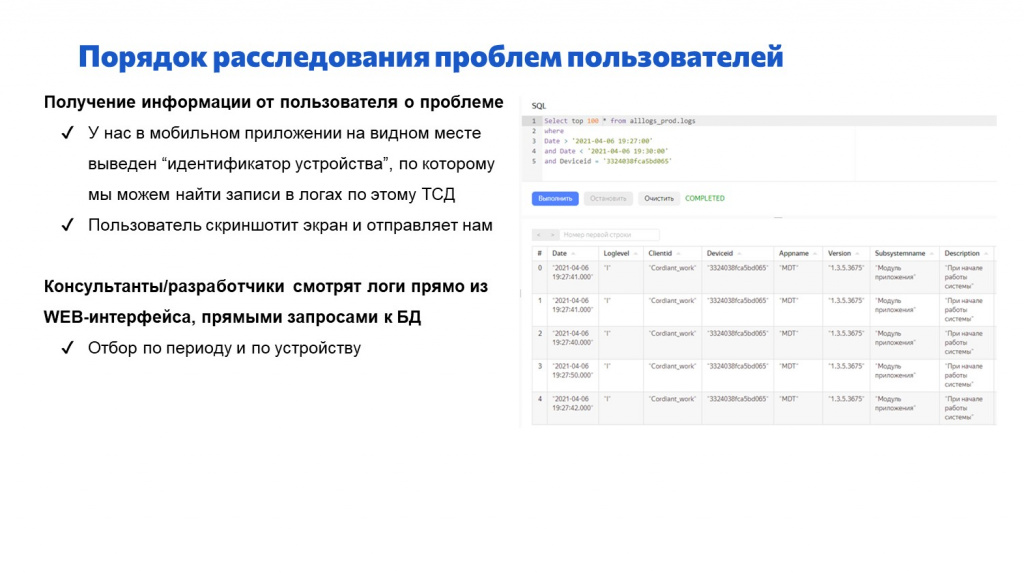
Как мы расследуем реальные проблемы пользователей с помощью этого механизма?
-
В мобильном приложении мы на самое видное место вывели идентификатор устройства, с которым работает конкретный пользователь.
-
Когда у пользователя возникает какая-то проблема, он делает скриншот экрана и отправляет нам, говорит: «У меня такая-то проблема, скриншот с идентификатором устройства прикладываю».
Дальше консультант или разработчик обращается к нашей общей базе логов по всем ТСД всех клиентов:
-
Прямо в веб-консоли ClickHouse он строит запрос с отбором по периоду и по device ID этого конкретного устройства и видит все логи с этого устройства в одном месте. Ему не нужно подключаться к каждому ТСД, смотреть логи там – он смотрит их в одном месте централизованно.
-
Работает эта штука достаточно быстро.

Какие альтернативные системы сбора логов мы рассматривали:
В первую очередь, мы рассматривали вариант отправки логов в центральную базу 1С. Тем более, что наше решение БИТ MDT состоит из расширения к центральной базе и мобильных баз.
-
Но, во-первых, это лишний трафик. А логи – это большой лишний трафик.
-
Если у нас ломается обмен центральной базы, и мы через логи захотим расследовать этот обмен, у нас это не получится. Если обмен сломался, логи не передадутся, и мы не узнаем, почему обмен сломался.
-
И в 1С нам бы все равно пришлось бы придумывать в центральной базе какое-то самодельное средство анализа логов, что не хочется делать – это лишняя работа.
Мы могли бы использовать какие-то стандартные системы для анализа логов – ELK, Graylog и так далее.
-
Но первая проблема – у нас все равно нет готовых блоков, чтобы вытягивать логи из мобильного приложения. Нам все равно пришлось бы писать в мобильном приложении какой-то код, чтобы отправить логи во внешнюю систему.
-
А вторая проблема – в том, что мы любим разные сервисы и не любим ничего у себя хостить. Мы не нашли дешевого или бесплатного облачного решения для того, чтобы собирать там логи и самим при этом ничего не админить.
-
Плюс в Clickhouse у нас логи – это не просто логи. Об этом я еще расскажу чуть позже.
И последний вариант, совсем бредовый – можно было бы использовать сервисы статистики. У нас везде Android, а платформа 1С поддерживает работу с сервисами статистики, но:
-
Сервисы статистики для логов не предназначены.
-
И ручная отправка событий платформой явно не рекомендуется.

Для чего мы еще используем логи?
В команде разработки БИТ.MDT есть владелец продукта, которого интересуют некоторые другие вопросы. Например, ему интересно:
-
какие версии нашего БИТ.MDT у каких клиентов стоят на скольких мобильных устройствах;
-
сколько мобильных устройств у каждого клиента за последнюю неделю реально работает;
-
и интересна статистика ошибок по периодам, по клиентам, по версиям.
Вся эта информация у нас в логах есть – нам нужно только ее сгруппировать оттуда и собрать.
-
Для группировки и отображения этой информации мы используем DataLens – она хорошо интегрируется с ClickHouse.
-
А так как мы все логи собираем в одну табличку с кучей колонок, по ней достаточно просто строить запросы, отчеты и дашборды – ничего кодить для этого не надо, и любой справится.
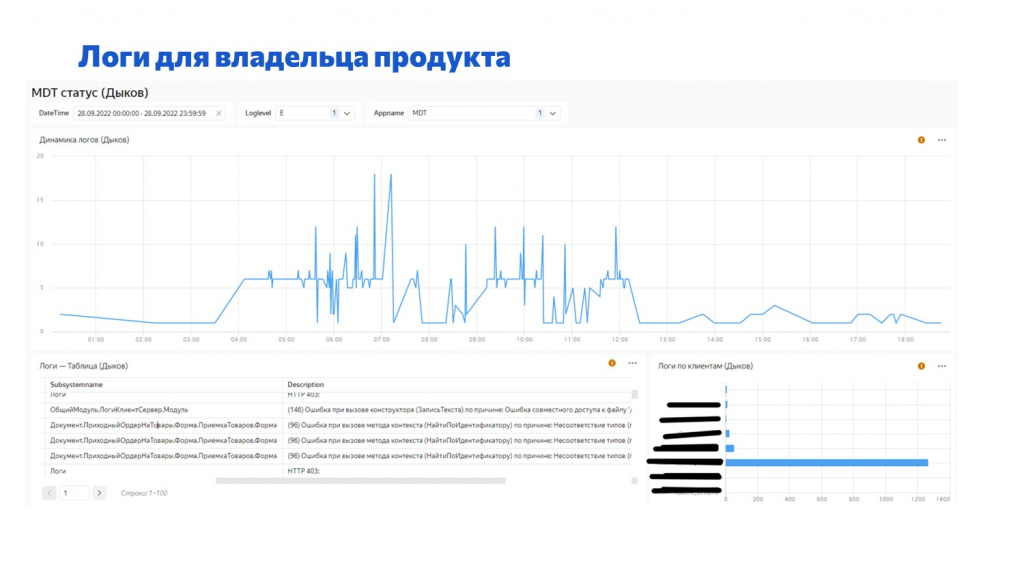
На слайде пример такого дашборда в DataLens.
Мы тут видим, что:
-
Отобраны логи только по ошибкам и только по продукту БИТ.MDT.
-
График вверху – это динамика ошибок, количество ошибок в минуту,
-
Ниже идут сами логи и их расшифровка.
-
И справа – динамика по клиентам за день, сколько ошибок возникло на мобильных устройствах данного клиента каждый день.
Такие дашборды легко строить по тем логам, которые мы собираем в Clickhouse, и это быстро работает.
Централизованный сбор логов мобильного приложения в облаке – это удобно

Перейдем к выводам.
Для сбора логов в мобильном приложении вам в любом случае придется писать свою логику, потому что штатных средств нет.
-
Может быть, и лучше, что штатных нет, потому что мы можем сделать более удобно;
-
Логи лучше собирать централизованно, а не хранить на каждом устройстве, потому что доступ к каждому устройству у вас может быть ограничен, и устройств много;
Для централизованного сбора логов можно использовать Яндекс.Облако.
-
У нас это получилось дешево.
-
Не пришлось ничего кодить и поддерживать – не было написано ни одной строчки кода для такого сбора в Яндекс.Облаке, только интерактивная настройка;
Централизованный сбор логов, помимо самих логов, дает дополнительные «плюшки».
-
Можно собирать не только логи, но и статистику.
-
А современные колоночные СУБД по таким таблицам с большим количеством колонок, умеют быстро строить аналитику, удобную для пользователей.
Вопросы и ответы
Почему для передачи данных между мобильным приложением ТСД и центральной базой был выбран RabbitMQ?
Тут несколько причин.
-
Первое – это режим работы онлайн и офлайн.
-
Второе – необходимость передачи данных не только в центральную базу, но и между ТСД. Т.е. у нас предусмотрена передача данных через RabbitMQ не только из мобилки в центральную базу, и из центральной базы в мобилку, но и между мобилками мимо центральной базы.
Классический пример: нужно разгрузить КАМАЗ, и стоят два или три товарища с ТСД и пикают марки – товар, который с КАМАЗа выгружается.
Центральная база в этот момент может быть недоступна по тем или иным причинам, но нужно добиться того, чтобы марки, которые пропикал один товарищ, увидел другой товарищ.
Для этого нужен был какой-то отдельный сервис не в 1С, который позволяет связать между собой мобилки, а также центральную базу с этими мобилками. Это либо брокер, либо какая-то шина данных. Но шина нам не нужна – нам не нужно никак конвертировать сообщения. Следовательно, лучшего всего подходил брокер сообщений.
А если брокер сообщений, то почему бы не RabbitMQ? Можно было бы использовать Apache Kafka, но RabbitMQ – это легковесный брокер сообщений, который удобно использовать. Мы его и используем.
Получается, что можно было бы обойтись инструментарием платформы 1С?
Нельзя было обойтись, иначе нам пришлось бы сделать на 1С отдельную базу, которая занималась бы именно администрированием сообщений и их пересылкой, и была бы всегда доступна между мобильными приложениями и центральной базой.
Но можно было бы сделать 1С как один из узлов – как в RabbitMQ.
Да, можно было бы так сделать, но нам бы пришлось написать конфигурацию, которая занималась только пересылкой сообщений.
Плюс HTTP-запросы гораздо более тяжеловесны, чем AMQP-запросы. Возможно, мы бы это тоже как-то победили, но зачем писать конфигурацию на 1С с нуля, если использовать готовое решение проще?
Это не тренд в пользу RabbitMQ, это именно для технологий?
Это не тренд, просто так удобней. Это готовое работающее решение, для которого мы можем обеспечить высокую доступность.
Оно есть как готовый сервис в облаке – мы можем его сами не админить, не следить за доступностью – этим занимаются другие люди. Мы просто платим за его использование, и все.
Используете ли вы эту практику хранения логов при расследовании ошибок самой 1С – для анализа ошибок в коде или мониторинга обмена с сайтом?
Мы в первую очередь используем это именно для расследования ошибок самой 1С – смотрим ошибки падения 1С, и как она себя ведет. Пишем: Попытка… Исключение, и в исключении шлем логи.
Какие самые распространенные ошибки по вашим логам?
Самые распространенные ошибки связаны с тем, что на данном устройстве нет связи.
Что делать, если источниками логов могут быть два отдельных потока в 1С – непосредственно пользовательская работа и фоновое задание, которое, например, в данный момент загружает данные с сервера. И там, и там могут происходить какие-то события, которые надо логировать – обращение будет в одну минуту к одному файлу.
Во-первых, 1С умеет дописывать файлы – никаких блокировок при этом не происходит, ошибок, что файл занят, не выдается.
Во-вторых, можно делать отдельные файлы. Подход с файлами позволяет нам делать сколько угодно файлов, относящихся к одной минуте – мы никак не ограничены в их количестве.
Нам главное иметь способ их потом выбрать и упорядочить, например, по времени.
Как у вас организован контроль целостности логов, которые приходят с устройств? Например, при загрузке файла через WiFi файл может быть поврежден. И сами логи, которые передаются, тоже могут быть битые. Как вы эти моменты отлавливаете?
Мы никак отдельно целостность логов не контролируем. Пока не было ни одного случая, чтобы файл передался, но JSON внутри оказался битый, хотя мы эту систему используем уже полгода.
У нас бывают ситуации, когда какой-то ТСД не смог передать свои логи по каким-то причинам – например, центральная база 1С не работает, и ТСД в принципе свои логи не передал. В этом случае получаются «дырки».
Я имею в виду, что в момент передачи файла человек может уйти из зоны передачи.
В этом случае отправка файла в 1С оборвется, и мы увидим сообщение, что файл не отправился. Тогда мы на устройстве этот лог удалять не будем и отправим его в следующий раз. Мы сначала дожидаемся, что файл отправится в 1С, и только после этого удаляем файл с логами.
А с целостностью логов у вас тоже проблем нет?
Ни разу пока не возникло. Наверное, 1С может упасть посреди записи логов, но мы с таким пока ни разу не столкнулись.
Вы логируете только то, что в исключениях или как-то еще журнал регистрации дополнительно парсите?
По умолчанию – то, что в исключениях.
Плюс когда разработчик пишет код, он явно пишет в тех местах, где ему нужно, вызов метода, который пишет в лог. Например, если мы разрабатываем сложный механизм, и нам, чтобы потом разобраться, почему это работает не так, как задумывалось, нужно вывести какую-то отладочную информацию.
Наверное, это самая трудоемкая часть всей этой разработки – вставить точки перехвата во все места, которые вы отлаживаете?
Почему же трудоемкая? Когда вы программируете на Python, вы же запись в логи явно вызываете везде, где вам нужно – это не вызывает сложности.
Когда у нас разработчики убедились, что расследовать ошибки гораздо проще, если напихать в код как можно больше логов, все стали пользоваться.
Какие логеры вы брали за основу, когда разрабатывали свой?
Мы смотрели Graylog и ELK – у меня был об этом слайд. Нам все понравилось, и мы бы и для десктопных приложений их тоже использовали.
Но код для передачи логов мобильного приложения в эти системы нужно писать в любом случае. А раз мы его написали, то дальнейший процесс сбора анализа на Яндексе получился у нас быстро, дешево, плюс удалось еще и BI прикрутить.
Мы сделали выбор в пользу готовой системы, которая предоставляет дополнительные плюшки и не требует от нас что-то писать и поддерживать дополнительно.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции Infostart Event.


Вступайте в нашу телеграмм-группу Инфостарт