Закон слабой связности единый – и в инженерии, и в организации. Основной тезис – что система должна отвечать только за свои данные в общем контексте.

Пару слов о том, почему я имею право говорить об этом.
Я руковожу компанией, которая занимается разработкой и интеграциями. Мы делаем проекты для клиентов и видим зависимость между слабой связностью и интеграциями.
Мы знаем, сколько стоят интеграции. Более того, мы знаем, сколько они нам стоят. Когда мы только начинали строить интеграции, мы делали много ошибок, и переделывали, и даже переделывали по несколько раз.
И эти циклы обратной связи помогли нам пересматривать в целом подход к созданию интеграций. Поделюсь с вами нашим опытом, нашим видением.
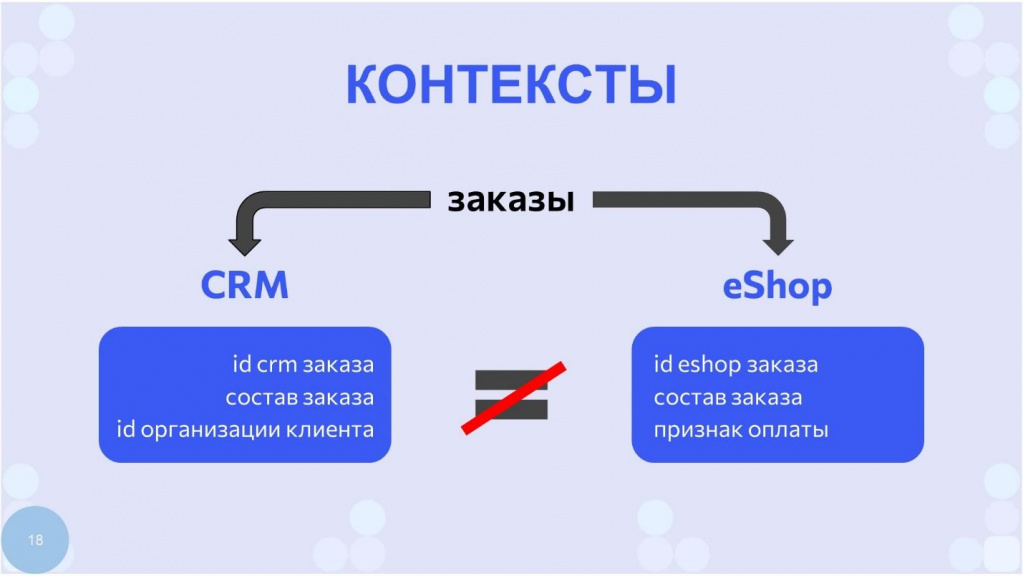
В первую очередь хочу ввести термин «Контекст», потому что в Software Engineering есть два контекста – контекст приложения и контекст предприятия. Сервис-ориентированная архитектура, микросервисная архитектура и монолитная архитектура построены вокруг контекста – одно от другого отличается только контекстом.
Например, заказ в контексте CRM-системы – это же совершенно не то же самое, что заказ в интернет-магазине (e-shop). В CRM-системе у заказа свои атрибуты, которые никому, кроме CRM-системы, не нужны. В интернет-магазине - свои атрибуты, также, как и в любой другой системе.
А для контекста предприятия о заказе важно знать только ограниченный набор параметров – например, идентификатор, клиента и сумму. Все остальные атрибуты CRM-системы контексту предприятия не интересны. С точки зрения менеджмента это называется «Ценный конечный продукт CRM-системы».
Сильная связность. «Лакмусовые бумажки»
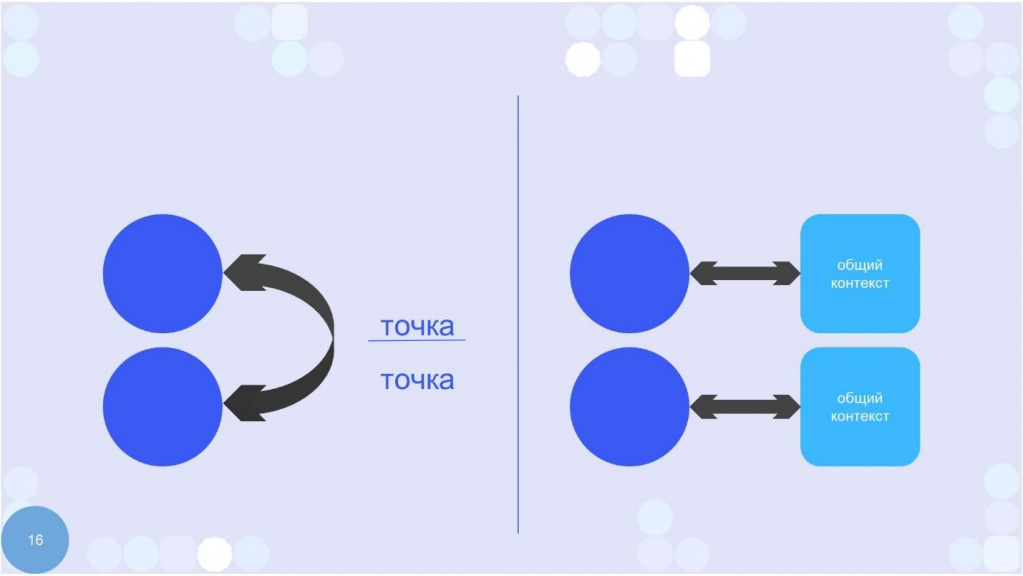
Как будет происходить обмен информацией между сервисами? Давайте рассмотрим два варианта.
Например, CRM-система из прошлого примера у нас общается с интернет-магазином, и ей для этого нужно знать язык интернет-магазина. Если кто знаком с брокерами, мы отправили из интернет-магазина заказ в брокер, а другая система взяла эти атрибуты и перевела в свой собственный внутренний язык – это сильная связность, потому что другой системе нужно знать чужой контекст. Сильная связность – это явное или неявное перемешивание контекстов, интеграция «точка-точка» в аспекте интеграции.
А слабая связность и общий контекст – это когда система думает, что она одна в предприятии. Других систем и их контекстов для нее не существует. Единственное, за что отвечает каждая система – за то, что именно она передает в контекст предприятия. Что имеет смысл для другого абстрактного потребителя.

Теперь рассмотрим варианты: как может выглядеть подключение нового сервиса в контур предприятия.
Сильная связность заключается в том, что в процессе добавления новой системы в контур вашего предприятия настанет такой день, а скорее, даже вечер, когда вашим командам придется проводить кросс-командное тестирование. Если при внедрении новой системы вам нужна полная выгрузка заказов из другой системы – это сильная связность. Это плохая - сильно связанная - архитектура.
В слабой связности у вас никогда не возникает такого вопроса. Другие системы не знают о том, что вы добавили что-то в общий контекст и могут управлять своим бэклогом самостоятельно.
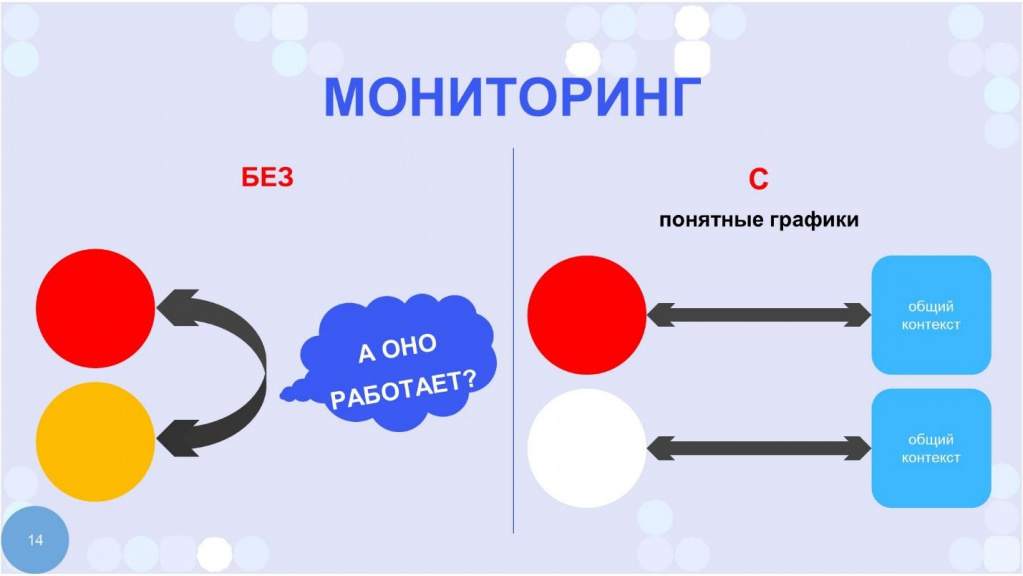
Еще одна лакмусовая бумажка интеграций между системами – мониторинг.
-
В сильно связанных системах мониторинг может понять только некий супер-синьор. Только он знает, как все системы связаны между собой, и по показателям мониторинга может понять, где искать причину ошибки.
-
В слабо связанных системах – наоборот. Мониторинг настолько прост, что его можно делегировать операторам колл-центра, которые по простому графику могут понять, где аномалия. Более того, в слабо связанных системах могут работать даже автоматические срабатывания по превышению каких-то параметров. При этом они не фальсифицируют свои алерты – не говорят, что что-то сломалось, когда все в порядке.

Какие варианты при внедрении BI-системы?
Если для вашей архитектуры внедрение BI-системы – это проект на месяцы, значит, у вас сильная связность. Потому что в слабой связности у вас все уже есть в общем контексте – от начала разработки BI-системы до настройки дашбордов проходит примерно 1 час. Вам нужно просто подключиться к хранилищу, и просто собрать из данных в общем контексте необходимые BI-отчеты.
Паутина интеграций «точка-точка» = монолит
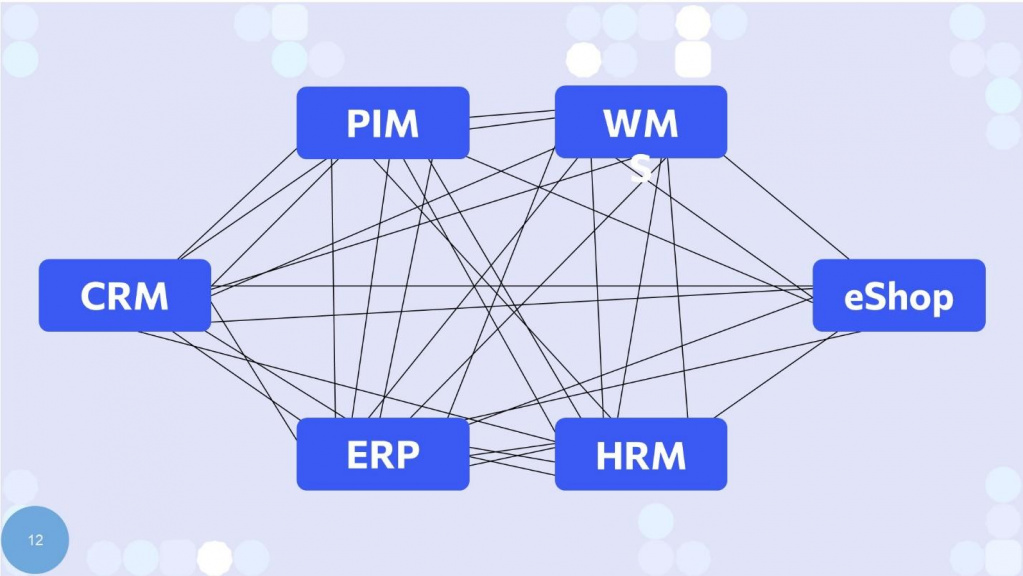
В результате мы явно или неявно получаем паутину плохой архитектуры «точка-точка».
Разработчики обычно говорят: «Мы знаем, что слабая связность в интеграции – это брокеры. О чем тут еще говорить?»
По нашему опыту, и с брокерами, и с шинами очень легко получается сильная связность. Когда вам кажется, что у вас слабая связанность, но с каждой интеграцией эта связь становится все более и более сильной.
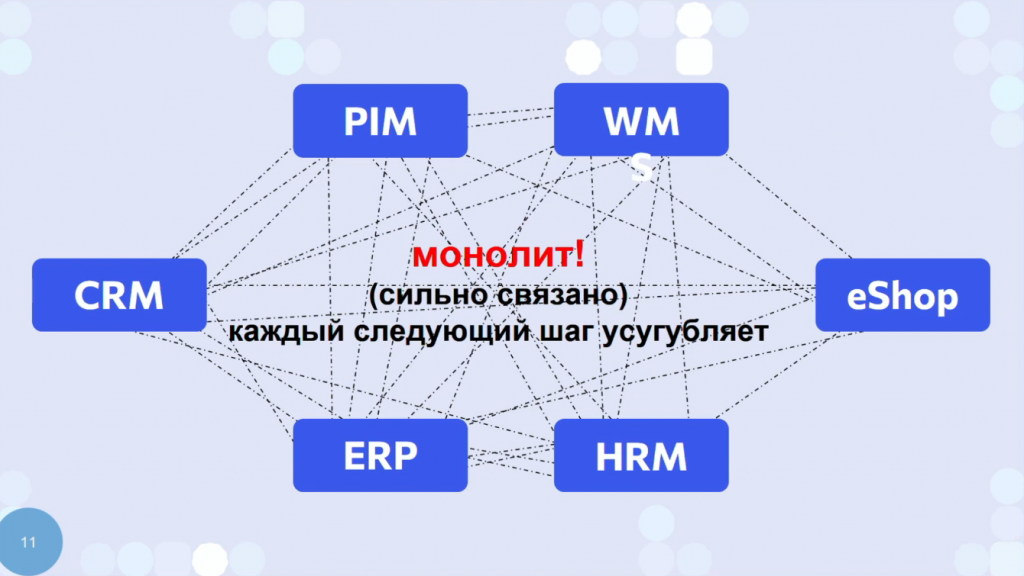
Поэтому вне зависимости от того, брокеры у вас или нет, если какое-то приложение знает контекст другого приложения – это монолит. А монолит запускает отрицательную селекцию всех архитектурных решений.
Отрицательная селекция означает, что каждое следующее решение будет хуже, потому что в такой системе разработчики всегда перегружены. Всегда есть кто-то, кто ночами не спит и в отпуск не может сходить. Даже заболеть или на туалете долго посидеть не может – он всегда нужен, всегда при делах. Айтишник в отпуске с ноутбуком – это еще один индикатор сильной связанности вашего контура.
Когда в таких условиях нужно добавить в контур какую-то новую систему – времени подумать о качестве архитектуры нет.
И это запускает отрицательную селекцию, потому что человек думает: «Вообще-то данные о товаре у меня есть в WMS-системе. Ну и что, что WMS-система за товары не отвечает. У меня же с ней есть интеграция, я возьму данные оттуда. Так проще». И приводит к основной проблеме монолита.
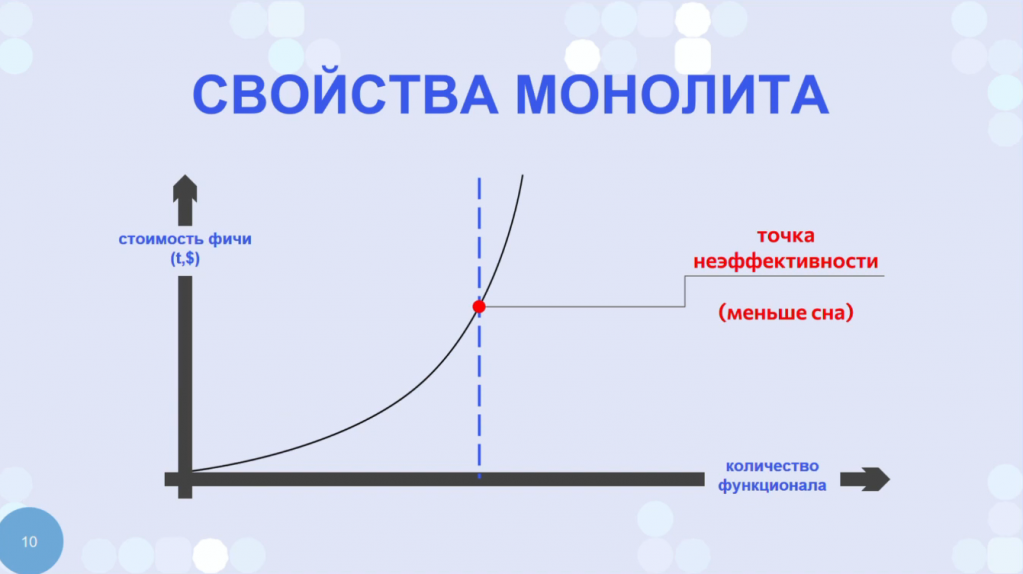
Основное свойство монолита - каждый монолит рано или поздно приходит в точку, где изменения становятся экономически невыгодными. Когда добавление любой маленькой фичи - это огромные затраты, связанные не с разработкой этой фичи, а с внесением изменений во все сервисы и интеграции, которые задевает это обновление.
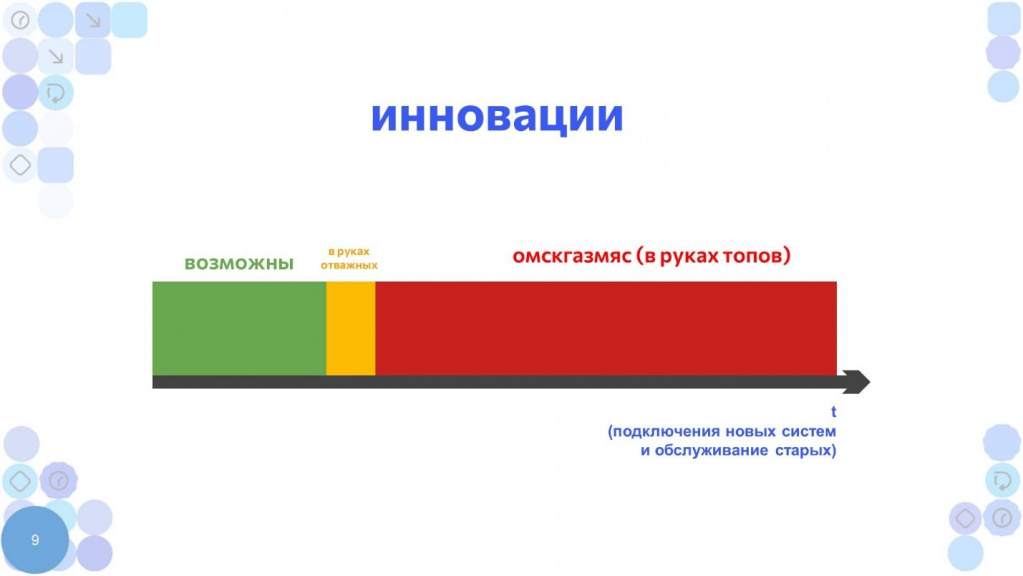
Проанализируйте, быстро ли вы меняетесь.
Если время на изменение очень большое, вы в конечном итоге оказываетесь в «ОмскГазМясе» – т.е. в руках топов.
В таких системах никогда не бывает мотивированных product-owner’ов. Даже если у вас есть мотивированный product-owner, он понимает, что ради маленькой зеленой кнопочки ему надо целый спринт выбивать. При этом он еще не знает – нужна эта зеленая кнопочка или нет. У него есть гипотеза, что, наверное, нужна. Но нужно ад пройти, чтобы она появилась. А пока она будет появляться, другая кнопочка упадет, отвалится.
Какова мотивация таких product-owner’ов что-то менять? «Работает – не трожь! Не дыши».
Это ОмскГазМяс - ручное управление. Ничего не имею против Омска, прекрасный город.
Шины – инструмент для слабой связности
Многие думают, что достаточно внедрить шину – и все проблемы исчезнут.
И шины могут помочь решить проблему сильной связности, если вы понимаете суть проблемы. И также с помощью шины можно сделать ситуацию только хуже. Мы такие примеры видели и даже сами такие примеры делали – за первые пару лет работы с интеграциями мы, кажется, собрали все возможные грабли.
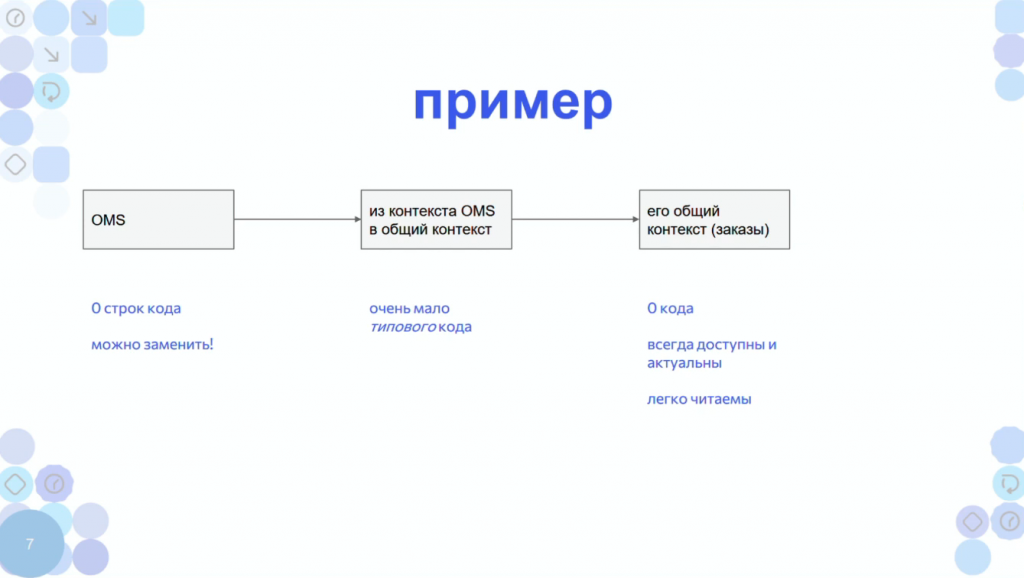
Маленький пример того, как система может содержать меньше кода.
-
Есть OMS-система, у которой есть общий контекст – это некие справочники. Сразу скажу, что это не брокеры, хотя и там могут быть брокеры, но в основном это справочники. В этой OMS-системе вообще нет отдельного кода для интеграции. Но у нее есть API. Вообще у любой современной системы есть API. Даже у фреймворков есть API. Я не знаю приложений, у которых нет API или другого способа взаимодействия – хотя бы через FTP или выгрузку.
-
Есть общий контекст (ОК) – отдельная база с заказами, в которой тоже ноль логики.
-
Код есть только в промежуточном ETL-слое – Extract, Transform, Load (обратите внимание, в микросервисах есть только E и L – Т нет). И код здесь очень типовой. Потому что нам надо из стандартного API OMS-системы взять заказы и положить их в таком виде, в котором их другие системы предприятия могут понять.
За все эти три составляющие отвечает одна команда – она здесь обозначается серым цветом.
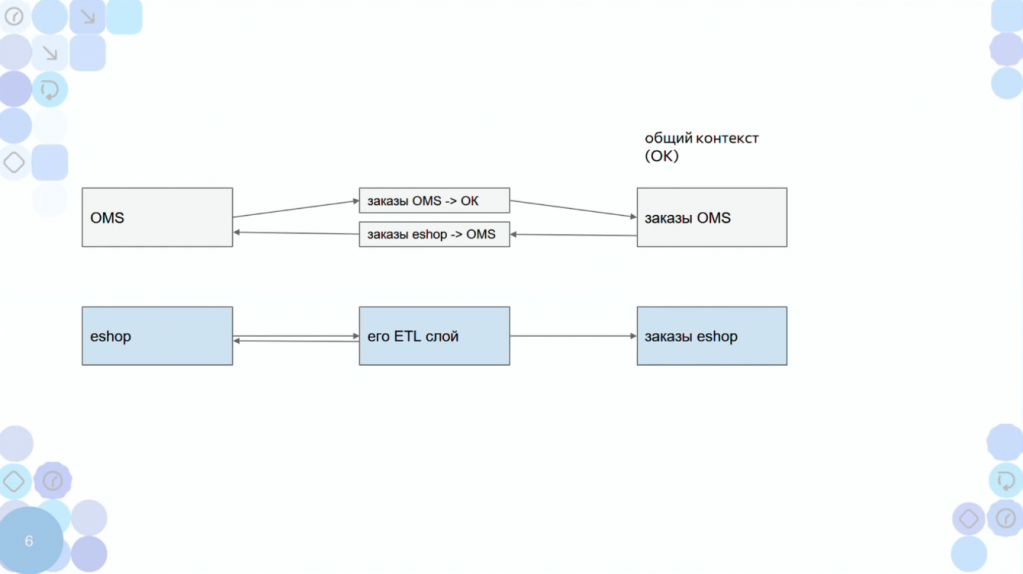
Теперь появляется вторая команда – команда интернет-магазина она обозначена голубым. И это две разные команды – у них два разные product-owner’ы и разный бэклог. Они не знают друг про друга.
Когда добавляется новая система, добавляется ее ETL-слой – маленький и типовой. И добавляется какая-то информация в общий контекст.
При этом OMS-система и любая другая система может использовать данные другого приложения общего контекста, не обращаясь напрямую в саму систему.
Это и есть слабая связность.
Слабая связность означает, что, как только команде потребуется этот контекст – информация о заказах – она сама примет решение, в какой спринт добавить эту таску.
Никакого кросс-тестирования. Данные в контексте уже лежат – и команда забирает, используя стандартный API.
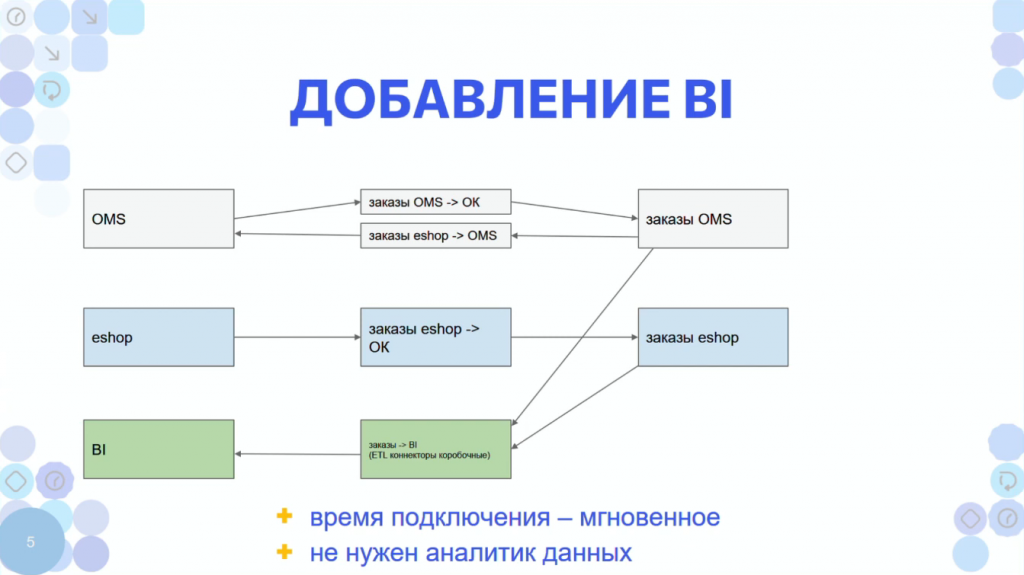
Выше мы рассматривали пример, как внедряется BI-система при сильной связности.
А теперь о том, как BI-система внедряется в слабой связности. Вы подключаетесь к хранилищу, а там уже есть все нужные данные - просто бери и настраивай дашборд.
Условно, если этот дашборд нужен финансовому отделу, сам финансовый отдел может сконфигурировать себе этот дашборд – для этого не нужно быть специалистом по бизнес-аналитике.
Мифы

Пару слов про мифы.
Про шины много мифов. Мы и сами даже, может быть, были причастны к появлению некоторых из них.
-
Шины – это не брокеры. Задача шины – сделать удобный инструмент в ETL-слое. Этот маленький коннектор должен быть простым. И шина обычно упрощает создание этого ETL-слоя. Если это LowCode или no-code приложение, нужный коннектор накликивается мышкой. А если это CodeFirst – там куча библиотек, которые упрощают взаимодействие с e-mail, с FTP и разными API через различные преобразования и выгрузки в XML, JSON и т.д.
-
Хранилище – это тоже не брокеры. В event-driven архитектуре или в микросервисном приложении вы можете использовать брокер с чистым сердцем, потому что у вас там контекст один – приложение. А в контексте предприятия использовать брокеры не рекомендуем – лучше все выгружать в справочники. Брокер вам может упрощать некоторые моменты потребления. Например, вам нужно знать, какие товары изменились – тогда добавляйте в брокер идентификаторы товаров, которые изменились. Но в подавляющем большинстве случаев этого не нужно – вам справочников хватит в каких угодно высоконагруженных таблицах.
-
И еще один миф по поводу микросервисной архитектуры. Очень часто люди говорят: «Нам не нужны шины, у нас микросервисная архитектура». Но микросервисная архитектура может быть только в контексте одного приложения. CRM-система может быть микросервисной, интернет-магазин может быть микросервисным, но предприятие в целом – не микросервисное, потому что контексты разные. Контекст бухгалтерии и контекст логистики – очевидно, разные, они не могут работать в одних и тех же микросервисах. Потому что если они работают в одних и тех же микросервисах – это монолит, а не микросервисы. Там будут все те же самые проблемы монолитной архитектуры – вы будете выкладывать один микросервис и проверять еще 25 других.
Как выбрать шину

В заключение – по поводу того, как выбрать шину.
-
В 2022 году на конференции Инфостарта я говорил, что использовать для ETL-слоя Codefirst-решение неоптимально, потому что командам периодически приходится дорабатывать свои коннекторы – менять маппинг или добавлять при необходимости поля. Но появился Copilot X и GPT-4, и теперь вообще непонятно, зачем нужен LowCode, если можно попросить ИИ написать коннектор на любом языке. Даже если я их сам писать не умею, я попросил написать скриптик, он мне написал, я чуть-чуть поправил, и все. Теряется преимущество LowCode-инструментов для визуализации того, что есть, и разъяснения, какие опции могли бы быть. Теперь у Codefirst это получается, наоборот, лучше, потому что ИИ текстом лучше отвечает. И это тоже некоторый вызов для современной инженерии. Мне кажется, что на сегодняшний момент, если сравнивать с LowCode, Codefirst-решения лучше.
-
Второй аспект – это cloud-native. Если вы заинтересованы, чтобы спали не только вы, но и ваши DevOps-специалисты, выбирайте Cloud-native-решения. Как вообще возможно, что в 2023 году (прим. ред. доклад от 25 мая 2023 года) шины могут быть не cloud-native? Но такие решения на рынке появляются.
-
Третий аспект – no-code. No-code прекрасно работает и прекрасно делегируется конечным пользователям. Если бухгалтеру нужно скопировать одну табличку в другую iPaaS-решения легко этот вопрос решают. Например, у себя в компании мы используем make.com и n8n – бухгалтер может зайти в make.com и сам поправить то, что нужно.
-
И важно: не забывайте про наличие API Gateway. Он полезен не только в разработке приложений, когда у вас через него фронт с бэком общаются – в этом случае бэк становится микросервисным, и фронт тоже. API Gateway нужен, если вам нужны данные поставщиков или еще чего-нибудь, а в ETL-слое нет Extract. В основном все API Gateway сейчас в cloud-native. У того же Яндекса это копейки стоит: миллион запросов – тысяча рублей. Поэтому не забывайте про его наличие.
Тема слабой связности обманчиво простая. Тезис понятный – система должна отвечать только за свои данные в общем контексте. Но по нашему опыту мы знаем, что это достаточно сложно дается. Поэтому если у вас есть любые вопросы, возражения или критика – пишите в комментариях.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции INFOSTART Анализ & Управление в ИТ-проектах.

Вступайте в нашу телеграмм-группу Инфостарт