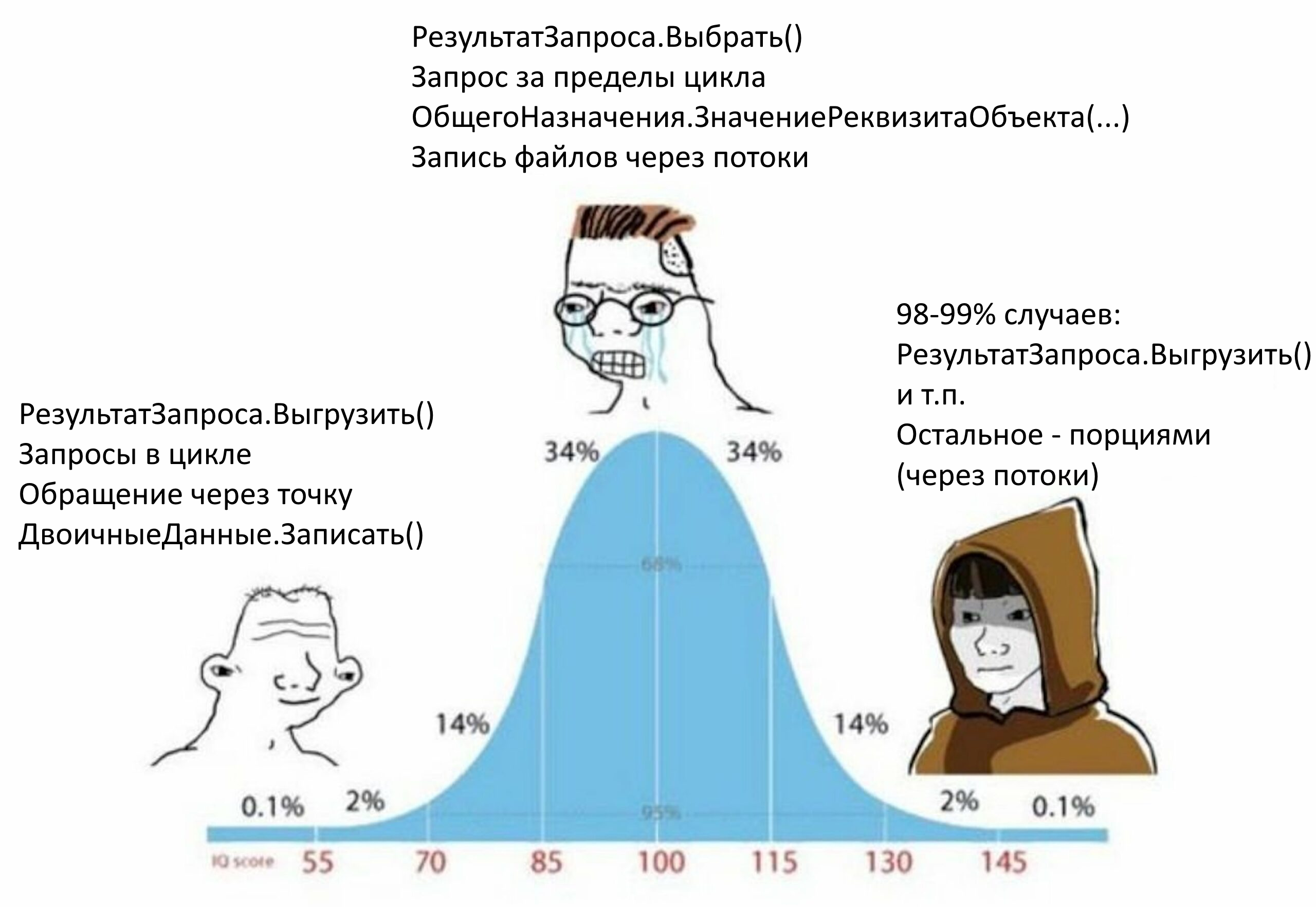
На мой взгляд, механизм работы с данными через файловый поток в 1С недооценен: я редко где-то встречаю его реализацию, а запрос в Google или поиск по Инфостарт не выдает практически никаких результатов - если речь заходит о потоках, то, как правило, о ПотокахВПамяти, которые позволяют в некоторых ситуациях избежать создания временного файла при работе с данными
А ведь по своему опыту могу сказать, что узнав о файловом потоке лишь однажды, ты навсегда начинаешь смотреть на любой объект Записи/Чтения, инициализированный через путь к файлу, как на страшный моветон, вроде запроса в цикле или венгерские нотации
Чем же он так хорош?
- Файловый поток позволяет читать и записывать файлы любого размера. В отличии от объекта ДвоичныеДанные, при использовании которого весь файл помещается в оперативную память, данный механизм обрабатывает данные частями, практически не напрягая железо
- При помощи потока данные можно записывать кусками в цикле или даже дописывать их к информации, уже существующей в файле на данный момент
При этом, вся эта благодать поддерживается большинством записывающих/читающих объектов, работающих с двоичными данными по умолчанию: Запись/ЧтениеДанных, Запись/ЧтениJSON, Запись/ЧтениеТекста и др.
Но показать проще всего на примерах, некоторые из которых мы сейчас рассмотрим:
Запись данных любого размера
Как уже было сказано ранее, данные можно записывать в цикле частями. Это позволяет не только не положить сервер на непосредственной записи, но и разделить выборку больших данных на несколько кусков: например запрос, возвращающий огромный массив информации, может быть разбит на несколько поменьше по отборам, а механизм записи, при этом, останется прежним, не повышая нагрузку.
Запись в данном случае выглядит следующим образом
РезультатЗапроса = Запрос.Выполнить();
ВыборкаДетальныеЗаписи = РезультатЗапроса.Выбрать();
Поток = Новый ФайловыйПоток("C:/1.csv", РежимОткрытияФайла.Дописать); // Открываем файловый поток по пути
ЗаписьТекста = Новый ЗаписьТекста(Поток); // Передаем поток в запись текста
Пока ВыборкаДетальныеЗаписи.Следующий() Цикл
МассивДанных = Новый Массив;
// Проходим все колонки и записываем значения в массив
Для Каждого Колонка Из РезультатЗапроса.Колонки Цикл
МассивДанных.Добавить(ВыборкаДетальныеЗаписи[Колонка.Имя]);
КонецЦикла;
// Соединяем массив в строку через запятые (формат CSV)
СтрокаДанных = СтрСоединить(МассивДанных, ",");
ЗаписьТекста.ЗаписатьСтроку(СтрокаДанных);
КонецЦикла;
ЗаписьТекста.Закрыть(); // Закрываем поток
Здесь идет выполнение запроса, текст которого остался за кадром. Далее мы, при помощи объекта ФайловыйПоток, открываем поток на основе пути к файлу. Для нас тут более всего интересен второй параметр - режим открытия файла, который может принимать следующие значения:
- Дописать - открывает существующий файл и начинает запись с его конца или создает новый, в случае отсутствия
- Обрезать - открывает существующий файл и очищает его, начиная запись с начала. Исключение, если файл не существует
- Открыть - просто открывает существующий файл. Исключение, если файл не существует
- ОткрытьИлиСоздать - то же, что и Обрезать, но создает новый файл, если он не существует
- Создать - я так и не нашел отличия от ОткрытьИлиСоздать
- СоздатьНовый - создает новый файл, исключение, если уже существует
Нас, в данном случае, интересует вариант Дописать, так как только он подразумевает сохранение данных, уже существующих в файле на момент записи туда новой информации.
Единственный нюанс: необходимо не забывать удалять/очищать файл, когда подразумевается запись абсолютно новых данных с нуля
Так как работать с потоком напрямую сложно и неудобно, нам необходим объект-помощник. В данном случае это ЗаписьТекста, но в зависимости от ситуации это также могут быть, например, ЗаписьДанных или ЗаписьJSON
Для записи текста мы формируем из полученных в запросе данных строку с запятыми в качестве разделителей - CSV формат, после чего записываем её в файл. Запись одной строки не создает практически никакой нагрузки на сервер - регулировать остается лишь размер выборки данных из базы. Если оперативы для нее хватает - писать можно хоть пока не закончится место на диске
Более жизненный вариант: те же данные но в формате JSON:
РезультатЗапроса = Запрос.Выполнить();
ВыборкаДетальныеЗаписи = РезультатЗапроса.Выбрать();
Поток = Новый ФайловыйПоток("C:/2.json", РежимОткрытияФайла.Дописать); // Открываем файловый поток по пути
JSON = Новый ЗаписьJSON();
JSON.ОткрытьПоток(Поток);
JSON.ЗаписатьНачалоМассива();
Пока ВыборкаДетальныеЗаписи.Следующий() Цикл
СтруктураДанных = Новый Структура;
// Проходим все колонки и записываем значения в структуру
Для Каждого Колонка Из РезультатЗапроса.Колонки Цикл
Поле = Колонка.Имя;
СтруктураДанных.Вставить(Поле, XMLСтрока(ВыборкаДетальныеЗаписи[Поле]));
КонецЦикла;
ЗаписатьJSON(JSON, СтруктураДанных);
КонецЦикла;
JSON.ЗаписатьКонецМассива();
JSON.Закрыть();
Здесь вместо записи текста мы уже используем запись JSON: для того, чтобы JSON был валиден, мы добавляем дополнительно запись начала и конца массива ('[' и ']' в начале и конце файла), а потом, в цикле, при помощи функции ЗаписатьJSON записываем в файл сформированную структуру - функция сама определит, как это должно выглядеть в виде текста JSON, а также, что очень приятно, сама поставит запятую перед новой строкой, для разделения элементов JSON-массива при дописывании данных
Отдельно хочется выделить популярный сейчас формат NDJSON, который может использоваться как источник данных в некоторых БД. Для его формирования, в нашем случае, мы можем скомбинировать ЗаписьJSON и ЗаписьТекста, чтобы автоматические механизмы работы с JSON не наставили лишних запятых и скобок
ФайловыйПоток = Новый ФайловыйПоток("C:/2.json", РежимОткрытияФайла.Дописать);
ЗаписьТекста = Новый ЗаписьТекста(ФайловыйПоток);
Для Каждого Запрос Из МассивЗапросов Цикл
РезультатЗапроса = Запрос.Выполнить();
Выборка = РезультатЗапроса.Выбрать();
Пока Выборка.Следующий() Цикл
СтруктураДанных = Новый Структура;
// Проходим все колонки и записываем значения в структуру
Для Каждого Колонка Из РезультатЗапроса.Колонки Цикл
Поле = Колонка.Имя;
СтруктураДанных.Вставить(Поле, XMLСтрока(Выборка[Поле]));
КонецЦикла;
ЗаписьJSON = Новый ЗаписьJSON();
ПараметрыJSON = Новый ПараметрыЗаписиJSON(ПереносСтрокJSON.Нет);
ЗаписьJSON.УстановитьСтроку(ПараметрыJSON);
ЗаписатьJSON(ЗаписьJSON, СтруктураДанных);
СтрокаJSON = ЗаписьJSON.Закрыть();
ЗаписьТекста.ЗаписатьСтроку(СтрокаJSON);
КонецЦикла;
КонецЦикла;
ЗаписьТекста.Закрыть();
В данном случае мы проходим в цикле несколько запросов, формируя на каждый элемент выборки JSON-строку, которая в последствии записывается просто через объект ЗаписьТекста
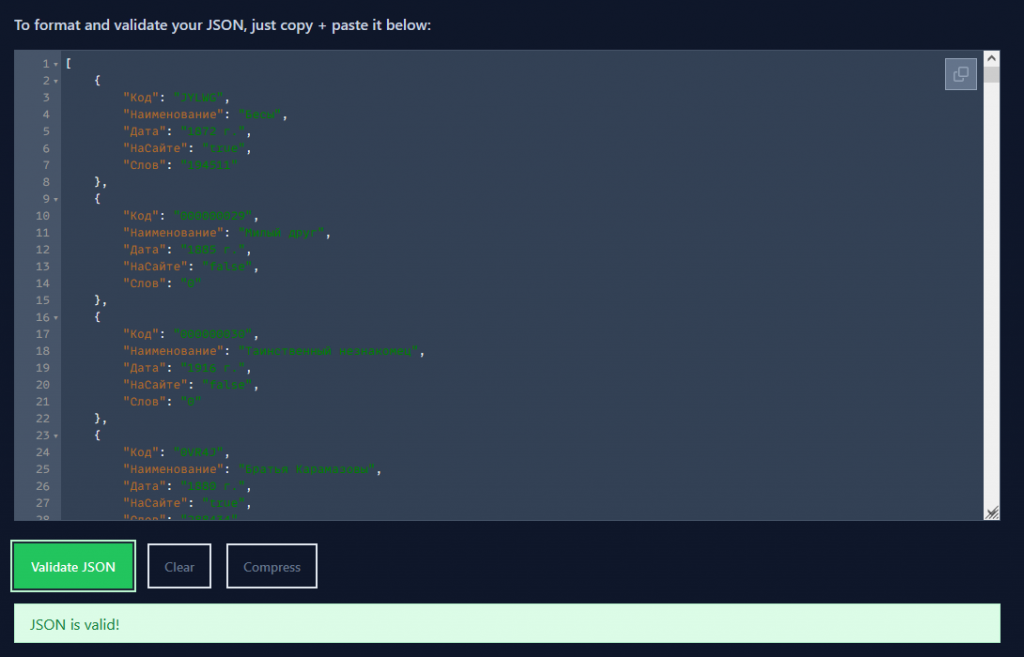
Итоговый файл выглядит следующим образом:
{"Код":"JYLWG","Наименование":"Бесы","Дата":"1872 г.","НаСайте":"true","Слов":"194511"}
{"Код":"000000029","Наименование":"Милый друг","Дата":"1885 г.","НаСайте":"false","Слов":"0"}
{"Код":"000000030","Наименование":"Таинственный незнакомец","Дата":"1916 г.","НаСайте":"false","Слов":"0"}
{"Код":"0VR4J","Наименование":"Братья Карамазовы","Дата":"1880 г.","НаСайте":"true","Слов":"288434"}
{"Код":"UDUMD","Наименование":"Преступление и наказание","Дата":"1866 г.","НаСайте":"true","Слов":"168997"}
{"Код":"PW125","Наименование":"Дон Кихот","Дата":"1605 г.","НаСайте":"true","Слов":"345759"}
{"Код":"WA7J1","Наименование":"Критика чистого разума","Дата":"1781 г.","НаСайте":"true","Слов":"172208"}
...
Чтение из файла любого размера
Если записать можно что угодно, то и прочитать можно что угодно. Принцип схож: мы инициализируем поток и дополнительный объект чтения в зависимости от типа данных, после чего обрабатываем все по частям в цикле
Поток = Новый ФайловыйПоток("C:/2.json", РежимОткрытияФайла.Открыть); // Открываем файловый поток по пути
ЧтениеJSON = Новый ЧтениеJSON;
ЧтениеJSON.ОткрытьПоток(Поток);
Структура = Новый Структура;
МассивЧтения = Новый Массив;
Пока ЧтениеJSON.Прочитать() Цикл
Если ЧтениеJSON.ТипТекущегоЗначения = ТипЗначенияJSON.ИмяСвойства Тогда
Имя = ЧтениеJSON.ТекущееЗначение;
ИначеЕсли ЧтениеJSON.ТипТекущегоЗначения = ТипЗначенияJSON.Булево
Или ЧтениеJSON.ТипТекущегоЗначения = ТипЗначенияJSON.Строка
Или ЧтениеJSON.ТипТекущегоЗначения = ТипЗначенияJSON.Число Тогда
Структура.Вставить(Имя, ЧтениеJSON.ТекущееЗначение);
ИначеЕсли ЧтениеJSON.ТипТекущегоЗначения = ТипЗначенияJSON.КонецОбъекта Тогда
МассивЧтения.Добавить(Структура);
Структура = Новый Структура;
КонецЕсли;
КонецЦикла;
В данном случае запись идет в массив, так что, по итогу, все данные все равно окажутся в памяти. Но это для примера: в действительности, вместо добавления в массив, скорее всего будет запись в базу. Следовательно, память будет заниматься только в рамках одного объекта
Немного про HTTP-запросы
Часто проблема работы с большими объемами данных возникает при использовании HTTP-запросов - причем как во время создания своего запроса, так и при получении большого объема данных в ответе. У самих объектов HttpЗапрос и HttpОтвет есть, конечно, методы для установки и получения тела из потока, но нам это здесь не поможет, так как речь идет про потоки в памяти
Однако, вариант потокового чтения и записи в файловом потоке для тела Http-запроса/ответа есть. Заключается он в использовании функции УстановитьИмяФайлаТела (для запроса)...
Запрос = Новый HTTPЗапрос("/");
Запрос.УстановитьИмяФайлаТела("C:/2.json");
...и параметра ИмяВыходногоФайла у функций отправки запроса Http-соединения (для ответа)
Соединение = Новый HTTPСоединение("exemple.com");
Соединение.ВызватьHTTPМетод("GET", Запрос, "C:/reponse.json");
Т.е. для запроса данные не формируются целиком в оперативную память, а пишутся в файл через поток, после чего путь к этому файлу устанавливается как путь к файлу тела. Для ответа же, данные сохраняются сразу в файл на диск, а уже потом могут быть обработаны из файлового потока, как это показано во втором разделе
В общем говоря, использование файловых потоков позволяет очень сильно сократить потребление оперативной памяти при работе с файлами - как на чтение, так и на запись. В частности, они идеально подходят для реализации различных обменов между системами с использованием файлов стандартных форматов, вроде CSV, JSON или XML
Спасибо за внимание!
Мой GitHub: https://gitub.com/Bayselonarrend Лицензия MIT: https://mit-license.org

DatabaseCompressionTool — сжатие и свертка любой базы 1С
Инструмент DatabaseCompressionTool (DCT) позволяет безопасно сжать и свернуть любую базу 1С, освободив сотни гигабайт и увеличив производительность системы. Доступна демо-версия для оценки эффективности.
Вступайте в нашу телеграмм-группу Инфостарт