Подготовка скрипта на Python
Для решения задачи извлечения текста из PDF файла был использован движок распознавания Google Tesseract OCR. Ссылка на статью, которой я руководствовался при написании скрипта на python: Извлечение текста из файлов PDF при помощи Python. Повторяться не буду, так как она довольно подробная и понятная.
Итоговый код, получившийся на python:
import PyPDF2
from pdfminer.high_level import extract_pages, extract_text
from pdfminer.layout import LTTextContainer, LTChar, LTRect, LTFigure, LTImage
from PIL import Image
import pdfplumber
from pdf2image import convert_from_path
import pytesseract
import os
import argparse
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'
def text_extraction(element):
line_text=element.get_text()
line_format = []
for text_line in element:
if isinstance(text_line, LTTextContainer):
for character in text_line:
if isinstance(character, LTChar):
line_format.append(character.fontname)
line_format.append(character.size)
format_per_line = list(set(line_format))
return (line_text, format_per_line)
def crop_image(element, pageIMAGE):
[list_x0,list_y0,list_x1,list_y1]=[element.x0,element.y0,element.x1,element.y1]
pageIMAGE.mediabox.lower_left=(list_x1,list_y0)
pageIMAGE.mediabox.right=(list_x0,list_y1)
cropped_pdf_writer=PyPDF2.PdfWriter()
cropped_pdf_writer.add_page(pageIMAGE)
with open('cropped_image.pdf','wb') as cropped_pdf_file:
cropped_pdf_writer.write(cropped_pdf_file)
def convert_to_Image(input_file,):
images=convert_from_path(input_file, poppler_path=r'poppler-24.07.0\Library\bin')
image=images[0]
output_file="PDF_Image.png"
image.save(output_file, format='PNG')
def image_to_text(image_path):
image=Image.open(image_path)
text=pytesseract.image_to_string(image)
return text
def extract_table(pdf,page_number,table_number):
pdf=pdfplumber.open(pdf)
table_page=pdf.pages[page_number]
table=table_page.extract_tables()[table_number]
return table
def table_converter(table):
table_string = ''
# Итеративно обходим каждую строку в таблице
for row_num in range(len(table)):
row = table[row_num]
# Удаляем разрыв строки из текста с переносом
cleaned_row = [item.replace('\n', ' ') if item is not None and '\n' in item else 'None' if item is None else item for item in row]
# Преобразуем таблицу в строку
table_string+=('|'+'|'.join(cleaned_row)+'|'+'\n')
# Удаляем последний разрыв строки
table_string = table_string[:-1]
return table_string
def main():
parser = argparse.ArgumentParser(description="Конвертация pdf УПД в Excel")
parser.add_argument("input_file", type = str, help = "Путь к входному файлу")
args = parser.parse_args()
#pdf_path = ('upd2.pdf')
pdf_path = (args.input_file)
pdfFile = open(pdf_path, 'rb')
pdfReader = PyPDF2.PdfReader(pdfFile)
text_per_page = {}
for pagenum, page in enumerate(extract_pages(pdf_path)):
pageIMAGE = pdfReader.pages[pagenum]
page_text = []
line_format = []
text_from_Image = []
text_from_Table = []
page_content = []
table_number = 0
first_element = True
table_extraction_flag = False
pdf = pdfplumber.open(pdf_path)
page_tables = pdf.pages[pagenum]
tables = page_tables.find_tables()
page_elements = [(element.y1, element) for element in page._objs]
page_elements.sort(key=lambda a: a[0], reverse=True)
for i, component in enumerate(page_elements):
pos = component[0]
element = component[1]
if isinstance(element, LTTextContainer):
if (table_extraction_flag == False):
(line_text, format_per_line) = text_extraction(element)
page_text.append(line_text)
line_format.append(format_per_line)
page_content.append(line_text)
else:
pass
if isinstance(element, LTFigure):
crop_image(element, pageIMAGE)
# Преобразуем обрезанный pdf в изображение
convert_to_Image('cropped_image.pdf')
# Извлекаем текст из изображения
image_text = image_to_text('PDF_image.png')
text_from_Image.append(image_text)
page_content.append(image_text)
# Добавляем условное обозначение в списки текста и формата
page_text.append('image')
line_format.append('image')
if isinstance(element, LTRect):
if (first_element == True and (table_number + 1) <= len(tables)):
lower_side = page.bbox[3] - tables[table_number].bbox[3]
upper_side = element.y1
table = extract_table(pdfFile, pagenum, table_number)
table_string = table_converter(table)
text_from_Table.append(table_string)
page_content.append(table_string)
table_element = False
page_text.append('table')
line_format.append('table')
if (element.y0 >= lower_side) and (element.y1 <= upper_side):
pass
elif not isinstance(page_elements[i + 1][1], LTRect):
table_extraction_flag = False
first_element = True
table_number += 1
dctkey = 'Page_' + str(pagenum)
text_per_page[dctkey] = [page_text, line_format, text_from_Image, text_from_Table, page_content]
pdfFile.close()
if os.path.exists('cropped_image.pdf'):
os.remove('cropped_image.pdf')
if os.path.exists('PDF_image.png'):
os.remove('PDF_image.png')
result = ''.join(text_per_page['Page_0'][4])
file = open("test.txt", "w")
file.write(result)
file.close()
if __name__ == "__main__":
main()
Выделю следующие строки:
import argparse
Здесь я импортирую модуль argparse, который предназначен для работы с аргументами командной строки.
parser = argparse.ArgumentParser(description="Конвертация pdf УПД в Excel")
parser.add_argument("input_file", type = str, help = "Путь к входному файлу")
args = parser.parse_args()
pdf_path = (args.input_file)
Здесь я инициализирую аргумент "Путь к входному файлу" и прокидываю его в качестве пути к pdf файлу.
Результат работы скрипта является строкой. Эту строку я записываю в обычный текстовый файл.
После написания скрипта на python необходимо скомпилировать скрип в exe файл.
Для этого необходимо установить pyinstaller.
Прописываем в командной строке
pip install pyinstaller
cd путь/к/вашему/скрипту
pyinstaller --onefile script.py
Параметр --onefile указывает PyInstaller упаковать все файлы в один исполняемый файл.
После выполнения команды PyInstaller, в директории вашего проекта появятся несколько новых папок и файлов:
build – временная папка для файлов сборки.
dist – папка, в которой находится ваш .exe файл.
.spec файл – спецификация сборки, которую можно использовать для дальнейших настроек.
Перейдите в папку dist и найдите там файл script.exe. Это и есть ваш исполняемый файл.
Интеграция с 1С
ТабличныйДокумент = Новый ТабличныйДокумент;
Путь = СтрЗаменить(ПутьКPDFФайлу, "\", "\\");
МассивПапок = СтрРазделить(ПутьКИсполняемомуФайлу, "\", Ложь);
ПутьКТекстовомуФайлу = "";
Для Счетчик = 0 По МассивПапок.Количество() - 2 Цикл
ПутьКТекстовомуФайлу = ПутьКТекстовомуФайлу + МассивПапок[Счетчик] + "\";
КонецЦикла;
КомандаСистемы("main.exe " + Путь, ПутьКТекстовомуФайлу);
Сек = 5;
КонДата = ТекущаяДата() + сек;
Пока ТекущаяДата() < КонДата Цикл
// ждемссс....
КонецЦикла;
ТекстовыйФайл = Новый ТекстовыйДокумент;
ТекстовыйФайл.Прочитать(ПутьКТекстовомуФайлу + "test.txt",
КодировкаТекста.Системная,
Символы.ПС
);
ТекстФайла = ТекстовыйФайл.ПолучитьТекст();
КонвертироватьНаСервере(ТабличныйДокумент, ТекстФайла);
ТабличныйДокумент.Записать(ПутьКExcelФайлу, ТипФайлаТабличногоДокумента.XLSX);
ЗапуститьПриложение(ПутьКExcelФайлу);
Теперь этот скрипт необходимо запустить из 1С.
В данном примере я считываю текстовый файл, созданный скриптом на python, заполняю с помощью него табличный документ, записываю этот табличный документ в excel и открываю его.
Скрипт запускает следующая строка:
КомандаСистемы("main.exe " + Путь, ПутьКТекстовомуФайлу);
Она принимает в качестве первого аргумента имя exe-файла вместе с аргументами (в нашем случае это путь к pdf файлу), а в качестве второго аргумента - каталог, в котором находится exe.
Переменные ПутьКPDFФайлу и ПутьКИсполняемомуФайлу задаются на форме.
При этом в пути к pdf файлу необходимо экранировать символ "\", поэтому заменяем его на "\\".
Далее ждём 5 секунд, чтобы исполняемый файл точно успел выполнить свою функцию и производим считывание текстового файла.
Сам текстовый файл уже парсим как душе угодно через СтрРазделить() или СтрНайти().
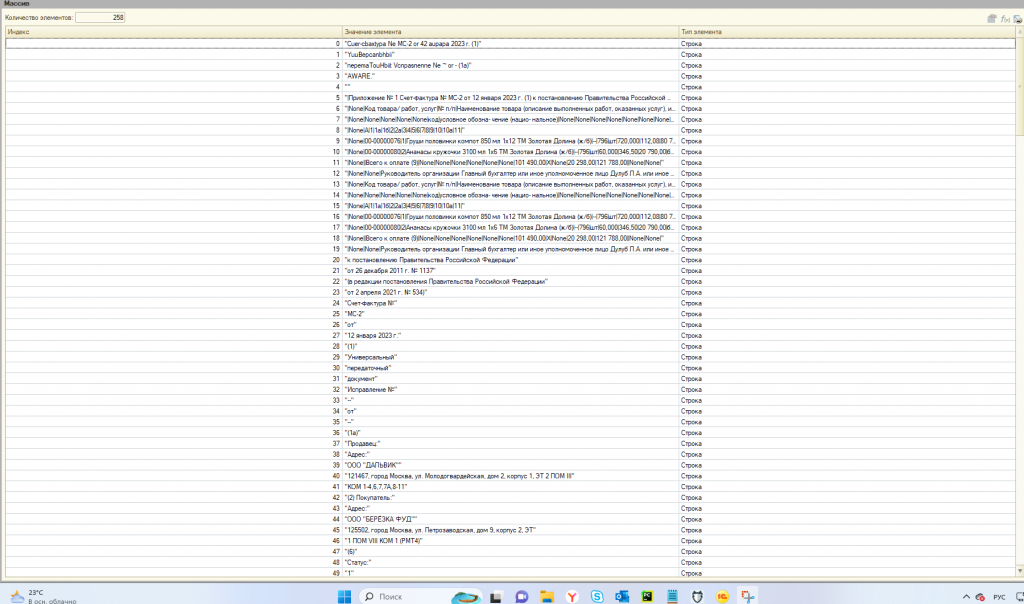
В моем примере я считывал документ УПД и вот, что я получил на выходе:
И разделив его следующим образом
МассивСтрок = СтрРазделить(ТекстФайла, Символы.ПС, Ложь);
Получил массив, с которым уже вполне можно работать.
Спасибо за внимание! Если остались вопросы - жду в комментариях.
Вступайте в нашу телеграмм-группу Инфостарт