
Под статистикой в контексте доклада подразумевается статистика распределения данных в таблицах и индексах – на ее основе планировщик запросов строит оптимальные планы.
Но чтобы планировщик построил оптимальный план, нужна актуальная статистика. Если статистика по какой-либо причине устарела – допустим, в базе произошла массовая вставка или еще что-то – планировщик строит план запросов, по которому запрос начинает выполняться в неадекватное время вплоть до вечности. Поэтому и нужно держать статистику в актуальном состоянии.
Опции обновления статистики

В своем докладе я буду оперировать следующими опциями обновления статистики:
-
FULLSCAN – как понятно из названия, эта опция позволяет вычислять статистику с полной выборкой данных из всей таблицы. Когда оптимизатор обновляет статистику с этой опцией, он опирается на все строки в таблице.
-
SAMPLE – эта опция дает уже вычисление статистики с ограничением по выборке: либо по количеству строк, либо по процентному соотношению.
-
FULLSCAN и SAMPLE, как несложно догадаться – взаимоисключающие опции, нельзя обновлять статистику сразу в двух режимах – и FULLSCAN, и SAMPLE.
-
И последняя опция – это MAXDOP, переопределение степени параллелизма, чтобы некоторые операторы обновления статистики выполнялись параллельно сразу на нескольких ядрах.

Итак, почему же FULLSCAN, а не SAMPLE?
-
Для начала – так рекомендует вендор, а кто мы такие, чтобы не прислушиваться к этим рекомендациям?
-
Следующий момент – при использовании инструкции SAMPLE может не хватать статистических данных для построения корректного оптимального плана запросов. Такая ситуация может возникнуть, когда у вас большое количество данных в таблице и большая вариативность этих данных – если данные распределены не нормально, а очень разнообразно.
-
И последняя причина, почему выбираем FULLSCAN – потому что при увеличении выборки SAMPLE время обновления статистики может сравняться с временем обновления статистики с инструкцией FULLSCAN. А зачем обновлять статистику, опираясь на какую-то ограниченную выборку, если можно обновиться по всей таблице?
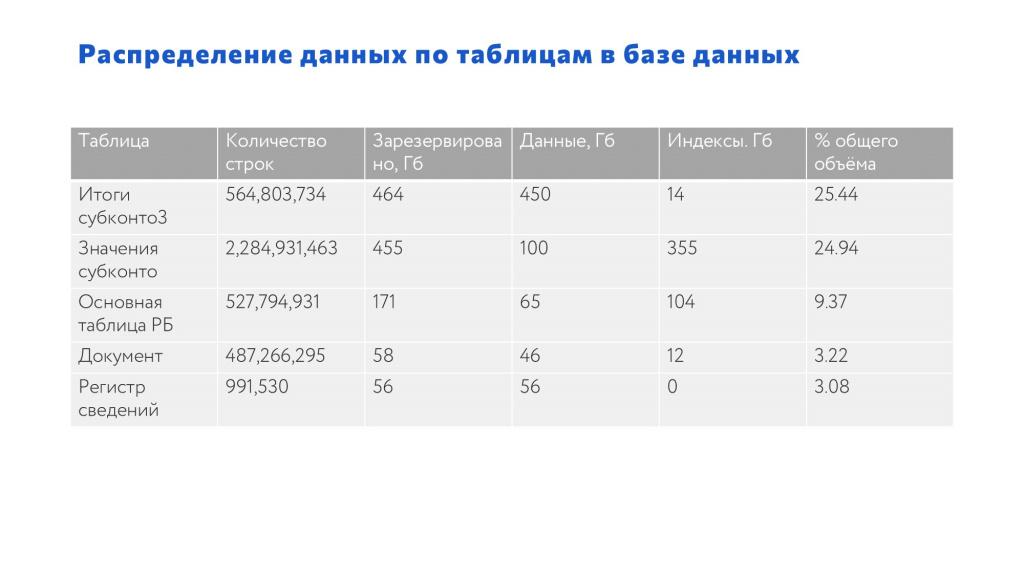
Сразу скажу, что мы не везде используем обновление статистики с FULLSCAN, единственная база, где мы это делаем – это 1С:Бухгалтерия КОРП. Там этот подход оправдан, потому что весь учет в базе построен вокруг одного регистра – бухгалтерии.
Параметры базы показаны на слайде:
-
Первые три таблицы из топа по размеру занимают 60% базы данных.
-
Количество строк в двух таблицах – по 500 миллионов, в третьей – 2,3 миллиарда.
-
Остальные таблицы уже не настолько большие.
В других базах, где таблицы более-менее адекватно сложены, и нет таких громоздких таблиц, как регистр 1С:Бухгалтерии, можно и нужно использовать частичное обновление статистики – через частичные выборки.

Я хотел накидать на слайде причины, почему нужно ускорять обновление статистики. Но одной причины, мне кажется, хватает – потому что в один поток статистика обновляется 35 часов.
Такого техокна ни один адекватный человек не выдаст и, я думаю, ни один адекватный человек не запросит такое техокно. Поэтому обновление статистики надо ускорять. И сейчас поговорим о способах этого ускорения.
Способы ускорения обновления статистики

Перечислю известные мне способы ускорения обновления статистики:
-
Первый способ – обновление только изменившейся статистики. Плюс у такого способа один – оптимизатор не делает лишней работы, он обновляет только ту статистику, которая, по его мнению, устарела. За счет этого происходит ускорение. Но, как показывает практика, это ускорение мизерное, потому что основные временные затраты связаны с крупными таблицами, с которыми пользователи постоянно работают. Получается, что этот вариант нам не подходит.
-
Следующий вариант – это использование параметра MAXDOP. Переопределение степени параллелизма бывает полезным, но только на больших таблицах – выигрыш от использования 8 потоков параллелизма на больших статистиках примерно в два раза. А на малых статистиках параллелизм, наоборот, вредит, потому что затраты на использование параллелизма (на распределение потоков и сбор всего результата) на малых объектах гораздо больше, чем сам эффект от параллелизма. Получается, что этот вариант нам тоже не подходит.
-
Следующий вариант – это многопоточное обновление статистики в разных таблицах. Отличный вариант, им можно пользоваться, когда у вас в базе данных нормальное распределение. А у нас, как видите, две таблицы занимают по 25% от общего объема базы, одна – 10%. Здесь мы максимум можем сделать 4 равномерных потока, но там тоже есть свои нюансы.
-
Поэтому последний вариант, который мы рассматривали, и мы им пользуемся – это многопоточное обновление различных статистик одной таблицы. У таблицы не одна статистика, а их может быть несколько. В таком варианте мы можем задания обновления статистики складывать в какие-то равномерные потоки и получать от ускорения максимальную эффективность.
Сейчас опишу то же самое, но уже с картинками – покажу некий сферический опыт в вакууме на примере картинок из документации к Microsoft SQL, как раз о многопоточном обновлении разных статистик в одной таблице.
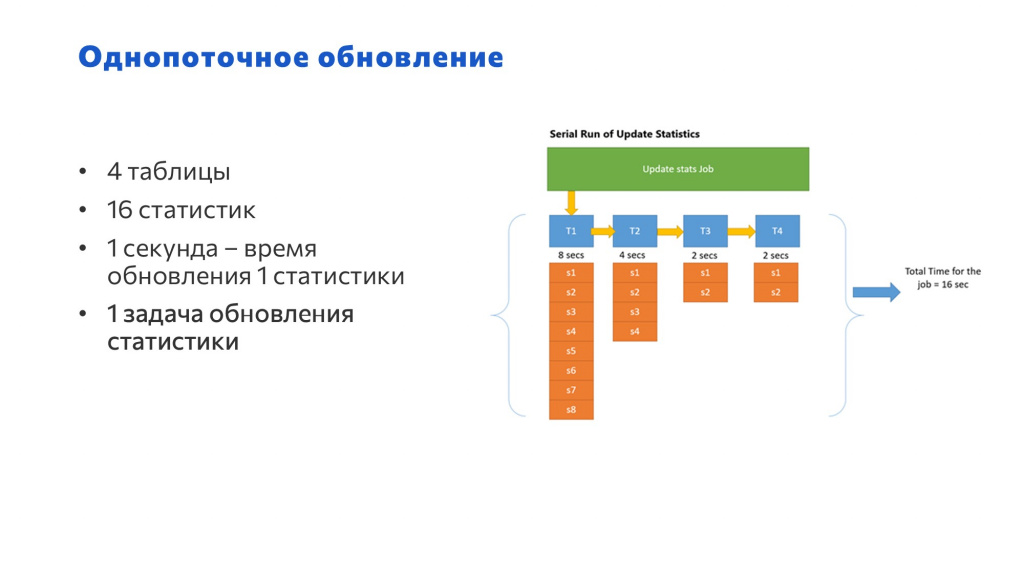
Однопоточное обновление статистик. Исходные данные:
-
у нас есть 4 таблицы;
-
в первой таблице – 8 статистик, во второй – 4, в третьей и четвертой – по 2; т.е. всего 16 статистик;
-
каждая статистика обновляется одну секунду;
Если у нас всего одно задание, которое обновляет эти статистики – мы обновляем статистики сначала по первой табличке, потом по второй, третьей и четвертой – последовательно на все это уходит 16 секунд.
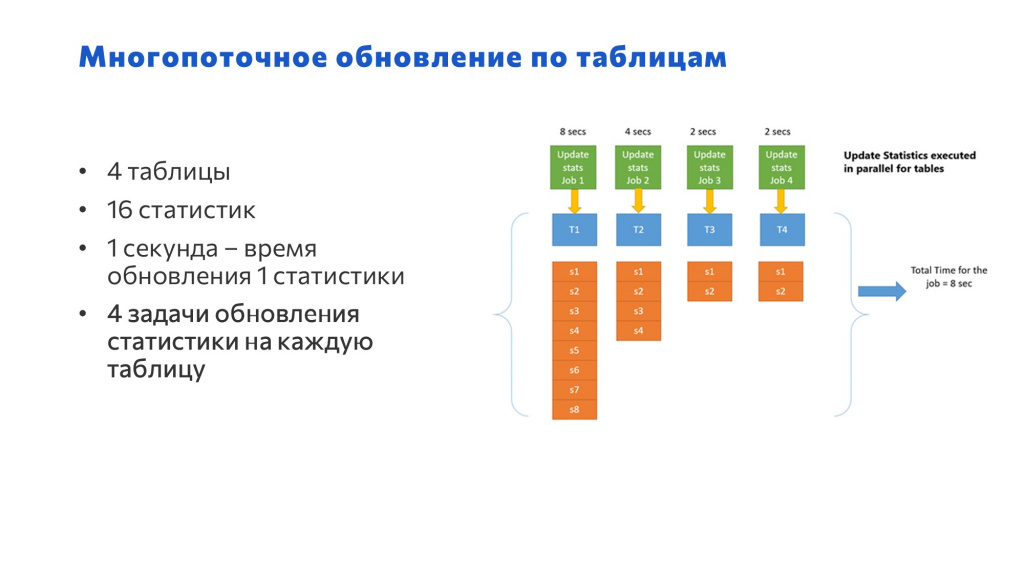
Следующий вариант – это многопоточное обновление по таблицам.
-
те же 4 таблицы;
-
те же 16 статистик;
-
та же секунда на обновление каждой статистики;
-
но уже 4 задания – по одному на каждую табличку.
Здесь уже общее время, затраченное на обновление статистики, будет равняться времени обработки максимальной таблицы – у нас есть таблица, где обновляется 8 статистик, это 8 секунд.
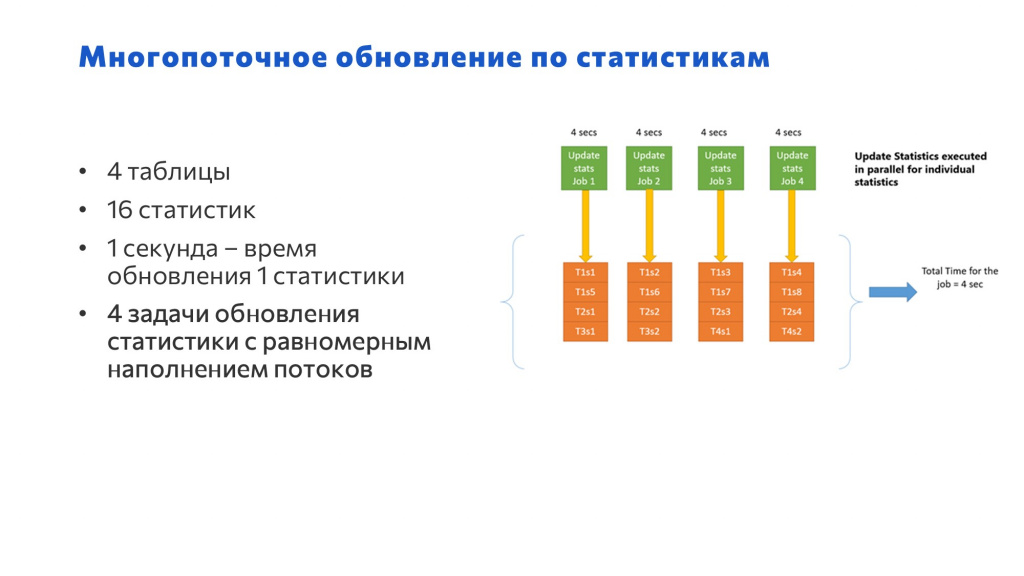
И последний вариант – это многопоточное обновление различных статистик.
Здесь мы уже равномерно скомпоновали статистики по потокам – обновляем четыре потока параллельно и получаем результат за 4 секунды.
Мы ускорили обновление с 16 секунд до 4 – все отлично. Но сразу так работать не будет.
Как включить

Что нужно сделать, чтобы так заработало?
Сначала нужно включить флаг трассировки под номером 7471. Это глобальный флаг.
Он доступен по умолчанию, если у вас MS SQL 2019. Если у вас MS SQL 2016 или MS SQL 2014, нужно сначала накатить накопительные обновления.
Единственное, что я здесь не добавил: в документации к Microsoft SQL разработчики предупреждают, что этот флаг трассировки может приводить к взаимоблокировкам на заданиях обновления статистики. Если вы используете автоматическое обновление статистики и производите обновления статистики с этим флагом трассировки в рабочее время, могут возникнуть взаимоблокировки.
У нас такое возникло всего один раз на этапе проектирования на тестовой базе. Промолчать об этом было бы неправильно.

Мы включили флаг трассировки, но нам надо как-то собрать потоки и запустить задания.
Для этого мы создали служебную базу данных, в которой есть:
-
две таблички: таблица потоков и таблица заданий,
-
пять хранимых процедур:
-
для создания заданий;
-
для удаления заданий;
-
для сбора потоков;
-
для запуска заданий;
-
и комплексная хранимка, которая выполняет полный цикл обновления статистики.
-

На слайде показан состав колонок для этих таблиц.
В табличке потоков есть:
-
rowid – номер строки;
-
threadid – номер обрабатываемого потока, по которому будут запускаться и собираться задания;
-
databasename – название базы данных; мы планируем, что возможно нам когда-нибудь понадобится это все делать в нескольких базах на одном инстансе;
-
object – объект, это непосредственно таблица, для которой будем обновлять статистику;
-
starttime, endtime – это время начала и завершения задания конкретного обновления конкретной статистики;
-
duration – длительность этого обновления;
-
скрипт обновления – то, что мы будем запускать и как мы будем обновлять конкретную статистику;
-
errorinfo – в случае каких-то проблем записываем еще и ошибку.
На второй табличке с заданиями тоже есть:
-
rowid – номер строки;
-
databasename – название базы данных;
-
job – название самого задания, чтобы иметь возможность контролировать его выполнение и впоследствии удалять;
-
status – и статус активности: если задание выполняется, там 1, если не выполняется, то 0.
Еще на этой табличке есть триггер, который отключает флаг трассировки. Поскольку вендор MS SQL не рекомендует держать флаг трассировки постоянно включенным на проде, а советует включать его только на регламентное обслуживание, мы его сначала включаем, а потом выключаем, когда все задания завершатся.
Листинги хранимых процедур
Дальше пойдут листинги хранимок. Но поскольку самая интересная хранимая процедура по подготовке потоков довольно обширная и ни на какие слайды не влезет, я постараюсь просто рассказать логику ее работы:
-
Для начала мы собираем все объекты статистики, которые нам надо обновлять в базе, и запихиваем их в таблицу потоков
-
И потом каждой строке таблицы выдаем свои определенные номера потоков – в зависимости от максимального количества потоков, на которые мы можем рассчитывать.
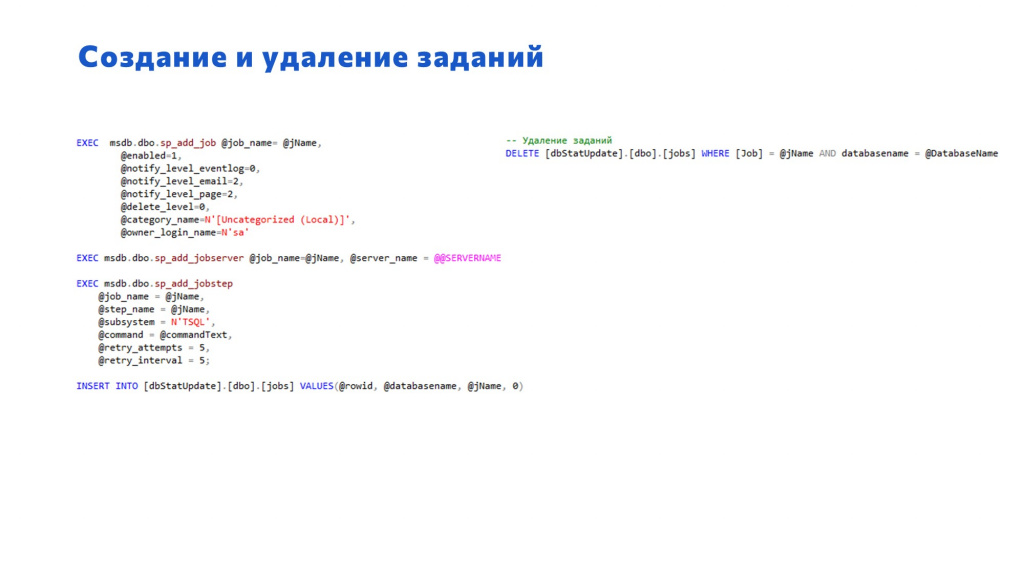
Следующие два листинга – довольно простенькие процедуры для создания и удаления заданий.
-
Слева – процедура для создания задания. Здесь простенькое задание с одним шагом и выполнением SQL-ного скрипта.
-
Справа – процедура удаления, которое происходит по названию самого задания и по фильтру с базой данных.

Запуск задания – это процедура, которая непосредственно запускает все задания. Мы выбираем все задания, которые создали, и запускаем их. И еще для каждого задания проставляем статус, что оно работает.

Это скрипт задания, который обрабатывает потоки.
-
Мы обходим таблицу потоков.
-
Выбираем свой поток – в каждом задании будет свой номер потока.
-
По этому фильтру и базе данных мы выбираем нужные скрипты и выполняем их.
-
В случае ошибки мы ее ловим и тоже записываем в соответствующее поле.
-
Когда задание завершилось, мы в таблицу заданий пишем признак, что задание завершилось.
-
Потом на этот апдейт сработает триггер, и если у нас в текущий момент нет выполняемых заданий, флаг трассировки отключается.

Вот так выглядит триггер TRACEOFF – он ищет все задания со статусом «Выполняемое».
Мы уже не опираемся на фильтр по базе данных, нас интересует сам факт, что у нас есть какое-то задание, которое требует многопоточного обновления статистик.
Если такое задание есть, мы флаг трассировки не выключаем.

Приблизительно так выглядит скрипт для комплексного запуска процесса.
-
Сначала мы выполняем подготовку потоков. Обратите внимание, в конце есть параметр @FullScan = 1, т.е. этот инструмент можно использовать не только для обновления статистики через FULLSCAN, но и для обновления частичной выборкой.
-
Причем шаг подготовки потоков необязательно выполнять каждый раз. Мы можем один раз создать эти потоки, подготовить их, создать задания обновления статистики и потом постоянно их запускать, а задание по подготовке потоков выполнять, только когда у нас поменялась структура метаданных – появились какие-то новые таблицы или статистики.
-
Удаление и Создание новых заданий тоже актуально только в случае, если у нас поменялось количество потоков. Потому что такие скрипты отличаются друг от друга только номером потока. Если потоки никогда не меняются, можно просто оставлять эти задания и видеть по ним историю – смотреть, как они выполнялись, с какой скоростью и так далее. Поэтому после обновления статистики мы задания не удаляем – удаляем только перед созданием новых заданий.
Результаты

Напомню:
-
Время обновления статистики в один поток – 35 часов.
-
Когда мы запустили обновление статистики в 12 потоков:
-
последнее завершенное задание завершилось за 3 часа 24 минуты;
-
а первое – за 2 часа 6 минут.
-
Мы повысили производительность в 10 раз, и видно, что это не предел, потому что между первым и последним потоками у нас разлет – практически полтора часа (1 час 20 минут).
Это пока то, чего мы добились. А о том, как это можно сделать еще более полезно, я расскажу чуть позже.

Плюсы и минусы данного подхода.
Плюсы:
-
Обновление FULLSCAN стабильнее. У вас не возникнет ситуации, что статистика внезапно протухла из-за массовой вставки, потому что для FULLSCAN в рабочей базе даже от большой вставки распределение данных сильно не поменяется, потому что база уже в рабочем состоянии. А если частичная выборка, то распределение данных вполне может повлиять, и тогда планировщик начнет строить какие-то неоптимальные планы.
-
Еще один плюс – это адекватное время выполнения. 3,5 часа – это влезает в какие-то адекватные рамки. Явно уже не 35 часов.
Минусы:
-
Все еще долго;
-
Возможны взаимоблокировки на заданиях обновления статистики. Мы такое словили всего один раз, но они могут быть.
Планы развития

Теперь немного о планах развития данного инструмента.
-
Для начала хочется добавить возможность тонкой настройки. Под этим стоит понимать, что не всю статистику надо обновлять FULLSCAN, некоторую можно обновлять и SAMPLE. FULLSCAN даже маленькие статистики довольно долго могут обновляться, а это бессмысленно. И бывают иногда задачи обновить какие-то конкретные статистики либо статистики по конкретным таблицам. Сейчас такой возможности в этом инструменте нет, но в планах есть. Планы, правда, долгоиграющие, не в первом приоритете.
-
Следующий план – это изменение скрипта формирования потока. Как я сказал ранее, у нас самый быстрый поток завершился за два часа с лишним, а второй – за три с половиной. Такой разлет – это очень плохо, потенциально мы можем еще больше ускорить обновление статистики, если перераспределим потоки более равномерно.
-
И последний план – универсальность инструмента. При обслуживании баз данных возникает большое количество операций, которые поддаются распараллеливанию. Одна из таких операций – это сжатие данных. В данный момент этот инструмент умеет только обновлять статистику в многопотоке, но никто не мешает использовать запуск, создание и удаление заданий для каких-то других задач.
Вопросы и ответы
Чем ваш подход отличается от того, что есть у Brent Ozar или Ola Hallengren?
Они как раз обновляют только измененную статистику либо обновляют статистику по таблицам, если говорить о параллельности. Их вариант работает когда угодно на любых коробках, когда время обновления статистик по разным таблицам приблизительно одинаково. Вы развернули, обновили, и это заработало.
У нас обновление статистики по трём таблицам занимает 80% времени. Так же мы включаем флаг трассировки. А те инструменты, о которых вы говорите, включение флага трассировки никак не проконтролируют.
Я думал, что в одной базе есть куча статистик, и при одном FULLSCAN она сразу их всех по умолчанию обновляет. А здесь, получается, она каждую статистику отдельно обновляет?
Статистики относятся не в целом к базе, а к определенной ее таблице. У каждой таблицы есть некоторое количество статистик:
-
для каждого индекса есть своя отдельная статистика;
-
и если у вас нагруженная база, у вас наверняка включена опция автоматического создания статистик, которые создает само ядро СУБД. Сам оптимизатор говорит, что ему не хватает этой статистики, и ее надо создать. Он создает такую статистику через распределение данных в этой таблице по конкретному полю, либо по сочетанию полей, которые ему надо.
Например, в нашей базе порядка 80 тысяч объектов статистик.
Я говорю о том, что есть табличка с миллионом записей, у которой 10 статистик. Когда мы обновляем 10 статистик разными потоками, он разве не делает 10 раз FULLSCAN этой таблички?
Он в любом случае будет делать FULLSCAN 10 раз, даже когда будет обновлять статистики одним потоком.
А MAXDOP, MS SQL-евское обновление статистики в несколько потоков – чем оно плохо?
Потому что у параллелизма есть свои затраты.
Получается, что это такой же параллелизм, только реализован по-другому? В чем разница?
MAXDOP – это параллельность, а не многопоточность. Параллелизм – это когда один поток можно разбить еще на параллельное выполнение плана запроса по обновлению статистик. Там издержки на то, чтобы потом собрать результирующее со всех этих потоков, могут превышать выигрыш от того, что мы вообще включили параллелизм. Особенно эти затраты влияют на маленьких операциях.
А здесь реализована многопоточность: мы берем и считаем статистики одновременно.
Многопоточность и параллелизм – это разное. Это то же самое, что вы в 1С проводите 100000 документов. От того, что вы включите на СУБД параллелизм MAXDOP 10, у вас не будет десяти потоков. Это не значит, что у вас все в 10 раз быстрее пройдет. Да, там что-то параллельно выполняется, но она себе потоки не разбила.
Чтобы у вас документы проводились многопоточно, надо запустить 10 фоновых заданий, и каждому дать пачку.
А скрипт, о котором я говорю, может сделать 10 фоновых заданий для обновления статистики, а там уже MS SQL может еще и на параллелизм разбить, но это дорого.
А с индексами вы что-то подобное пытались сделать, чтобы их ребилдить?
Не надо так делать с индексами, там все хорошо – вы же не на SATA-дисках работаете, а на SSD.
Лучше послушайте Александра Денисова, он в своем докладе рассказывал, когда индексы нужно ребилдить, а когда – нет.
Почему 12 потоков и насколько увеличит нагрузку на железо такая многопоточность? Как подобрать правильное количество потоков в многопоточной системе?
Во-первых, потоков должно быть не больше, чем половины ядер.
Во-вторых, можно смотреть эмпирическим путем – запустить и проверить, что так сработало побыстрее.
Третий момент – это распределение данных в таблицах: количество статистик и так далее. Если на нашей базе использовать классическую многопоточность обновления статистик по таблицам, нет смысла использовать больше 4 потоков, потому что у нас в двух верхних таблицах по 25% объема от всей базы. Обновление статистик по каждой из этих таблиц будут занимать какое-то определенное время. А остальные статистики мы быстрее обновить не сможем.
При этом мы обновляем статистики не по таблицам, а уже в конкретно по статистикам. Поэтому мы использовали 12 потоков, чтобы более равномерно распределять их в потоке.
Нужно еще учитывать ваши ресурсы. Вы же делаете обновление статистик каждый день в определенное время? Посмотрите, сколько вообще свободных ресурсов на ЦПУ есть в это время, потом поделите это значение на 4, запустите, и потом эмпирическим путем определите, сколько вам нужно. В какой-то момент у вас график скорости перестанет расти, а потом начнет падать. В точке, где он перестал расти – оптимальное значение распределения данных потоков для вашего железа, для вашей базы. Определить можно только методом научного тыка.
Мне интересен ваш опыт в контексте высоконагруженных баз. Какую периодичность обслуживания статистик вы выбрали – раз в неделю, раз в сутки или еще чаще? И второй вопрос: контролируете ли вы как-то в продакшене, например, если какая-то статистика протухла? Если контролируете, то как?
Такой подход для обновления статистики мы делаем приблизительно раз в неделю. Причина понятна: FULLSCAN, как я уже говорил ранее, обновляет статистику по всей таблице. И какие бы изменения не были, даже существенные, они не сильно поломают статистику распределения данных. Поэтому мы можем позволить себе раз в неделю взять техокно на 3,5 часа раз и обновить статистику.
Тут деваться некуда. Если у вас есть техокно, вы на него ориентируетесь. Если техокна нет вообще, то даже этот подход особо не поможет. Тогда следим за APDEX – по каким документам он выпадает и из каких таблиц эти документы состоят. Зная таблицы, обновляешь по ним статистику в ближайшую ночь, несмотря на то, что техокна нет. Чуть-чуть потерпят. Или мы можем обновление размазать на каждый день, но по чуть-чуть.
А автоапдейт статистики используете?
Отключен, потому что автоапдейт обновляет частично. Если установить параметр RESAMPLE, чтобы он в автоматическом режиме обновлял статистику тоже FULLSCAN, это будет занимать большое количество времени и ресурсов.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции Infostart Event 2022 Saint Petersburg.
Вступайте в нашу телеграмм-группу Инфостарт