








.png")
В компании "Тантор Лабс" занимаются разработкой СУБД на базе postgres для 1С - Tantor Special Edition 1C.
При тестировании новой фичи или выпуске нового релиза мы проводим нагрузочные тесты на конфигурациях ЕРП, Документооборот и ЗУП, чтобы убедиться, что ни одна ключевая операция не стала выполняться медленнее и ускорились определенные ключевые операции (о самом процессе тестирования сборки расскажем в следующем году), если дорабатываем, например, планировщик.
Помимо этого, мы периодически разбираем длительные ключевые операции для анализа долго выполняющихся запросов на предмет выбора неоптимального плана запроса. О таком кейсе сегодня я вам и расскажу.
Проблема
Нагрузочный тест показал, что проведение документа "Реализация товаров и услуг" длится в среднем 18 секунд.
Возьмем в одном сеансе проведем 20 документов и будем собирать все запросы длительностью более 1 секунды с помощью модуля "Расширенная аналитика" платформы Tantor.
Видим, что 20 раз выполнялся запрос со средней длительностью 3,5 секунды:


Из плана запроса видно, что идет выборка данных из регистра сведений _inforg37391x1 - выбирается 459 тысяч строк, и только потом выше накладывается отбор по регистратору, который сокращает выборку до 0 записей:
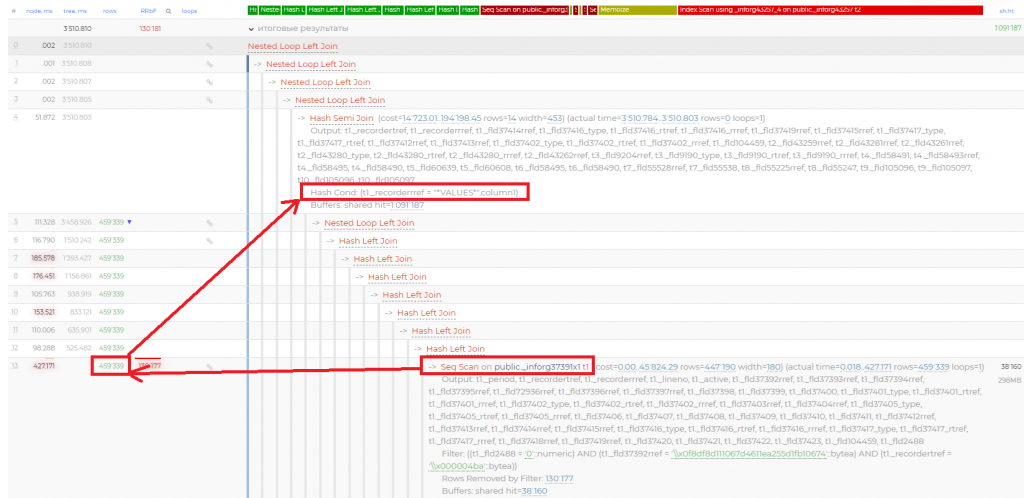

С точки зрения SQL, это обычный отбор по регистратору:
SELECT
...
FROM
_InfoRg37391X1 T1
...
WHERE
... AND (T1._RecorderTRef = '\\000\\000\\004\\272'::bytea AND T1._RecorderRRef IN ( VALUES('\\2041\\030f\\332\\261R\\333\\021\\356\\224%dU\\311('::bytea), ('\\2041\\030f\\332\\261R\\333\\021\\356\\224%dU\\311('::bytea)))
Казалось бы, селективнейший отбор по регистратору, но почему его postgres не применит сразу, чтобы сократить выборку?
Дело в том, что с точки зрения postgres конструкция VALUES это такой же узел плана запроса, как и скан таблицы, например:


После того как он прочитал данные конструкцией VALUES, при планировании запроса перебирает различные варианты соединения узлов плана запроса и повезет, если он решит сразу соединить узел VALUES с узлом выборки данных из регистра сведений, но этого не происходит.
В нашем запросе участвует более 10 таблиц согласно модели плана запроса:
Join
-> Scan Table public._document925
-> Scan Table public._inforg37391x1
-> Scan Table public._inforg43257
-> Scan Table public._reference157
-> Scan Table public._reference157
-> Scan Table public._reference189
-> Scan Table public._reference195
-> Scan Table public._reference302
-> Scan Table public._reference315
-> Scan Table public._reference315
-> Scan Table public._reference315
-> Scan Table public._reference315
-> Scan Table public._reference395
-> Scan Table public._reference395
-> Scan Values "*VALUES*"
|
|
И в данном случае решить проблему можно, увеличив параметры join_collapse_limit и from_collapse_limit с 10 до 20. Сделаем это и получим следующий план:


Был сразу наложен отбор по регистратору, что позволило не выбирать лишние записи и соединять их с другими таблицами, и запрос выполнился менее чем за 1 мс вместо 3,5 секунд.
Но изменение данных параметров не панацея, т.к. соединений в запросах 1С может быть и более 20.. Но не только в количестве соединений дело. Вот пример запроса, в котором всего 3 соединения таблиц, и планировщик все равно не может подобрать оптимальный план:


После применения отбора из VALUES количество выбираемых строк сокращается в 15 раз.
С точки зрения 1С конструкция VALUES это использование отбора в массиве на языке запросов 1С:
|
В 1С такие конструкции используются повсеместно, т.к. использовать в качестве параметра запроса массив из нескольких значений является нормальной практикой.
Совсем недавно эта проблема на связке 1С+postgres была решена.
Tantor Special Edition 1C 16.4.0 (15.8.0)
Начиная с указанных версий в нашей редакции СУБД, предназначенной для работы с 1С, мы решили данную проблему следующим образом: при выполнении запроса планировщик postgres на стадии парсинга текста запроса подменяет конструкцию VALUES на ANY ARRAY.
Выполняется проблемный запрос менее чем 1 мс, план:


А вот каким становится план запроса, который выше, независимо от from_collapse_limit и join_collapse_limit выполнялся плохо:


Как мы и ожидали, количество выбираемых строк сократилось в 15 раз, и запрос ускорился почти в 4 раза.
Таких примеров можно привести очень много, исправление этой проблемы действительно дает отличное ускорение производительности там, где используется VALUES.
Платформа 1С 8.3.24
Начиная с этой версии, платформа больше не использует конструкцию VALUES. Вместо нее используется просто конструкция IN, которая не приводит к формированию отдельного узла плана запроса, а отбор накладывается сразу. Текст запроса SQL теперь будет следующим:
SELECT
...
FROM
_InfoRg37391X1 T1
...
WHERE
... AND (T1._RecorderTRef = '\\000\\000\\004\\272'::bytea AND T1._RecorderRRef IN ('\\2041\\030f\\332\\261R\\333\\021\\356\\224%dU\\311('::bytea, '\\2041\\030f\\332\\261R\\333\\021\\356\\224%dU\\311('::bytea)))
План запроса:
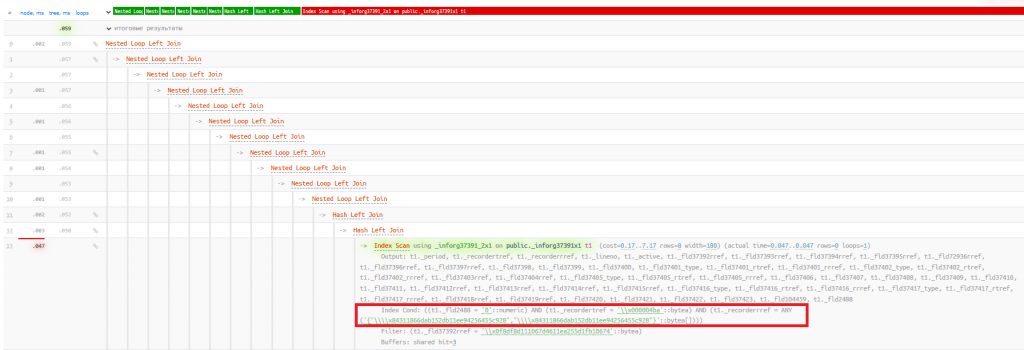
В чем разница между использованием ANY ARRAY и IN?
С точки зрения планировщика обе конструкции в плане запроса преобразуются в оператор ANY, вы можете это увидеть по планам выше. И, следовательно, работают одинаково.
А с точки зрения разработки, то IN может принимать в качестве параметров как массивы, так и подзапросы. Однако, если мы точно знаем, что в качестве параметра будет массив (а в нашем случае именно так), то имеет смысл использовать именно ANY ARRAY, чтобы сделать код более ясным и понятным.
Заключение
Если вы столкнулись с тем, что в вашей информационной системе много неоптимальных запросов, использующих конструкцию VALUES, то решением здесь может быть переход на платформу 8.3.24.
Если вы по каким-то причинам не можете перейти на платформу 8.3.24, то здесь вам поможет наша СУБД Tantor Special Edition 1C. Мы постоянно работаем над улучшением работы планировщика под специфику запросов 1С и далее планируем знакомить вас с внедряемыми оптимизациями.
Вступайте в нашу телеграмм-группу Инфостарт