В сегодняшней статье мы рассмотрим еще один интересный пример, связанный с эффективной работой динамических списков. Также я добавлю небольшую теоретическую вставку, которая поможет лучше понять суть проблемы. Уверен, что этот разбор будет полезен и интересен коллегам.
Структура статьи
- Обсуждение проблемы
- Демонстрация теории на простом примере
- Анализ текущей ситуации
- Исправление
- Вариант 1
- Вариант 2
- Это еще не все, дополнительные действия
- Заключение
1) Обсуждение проблемы
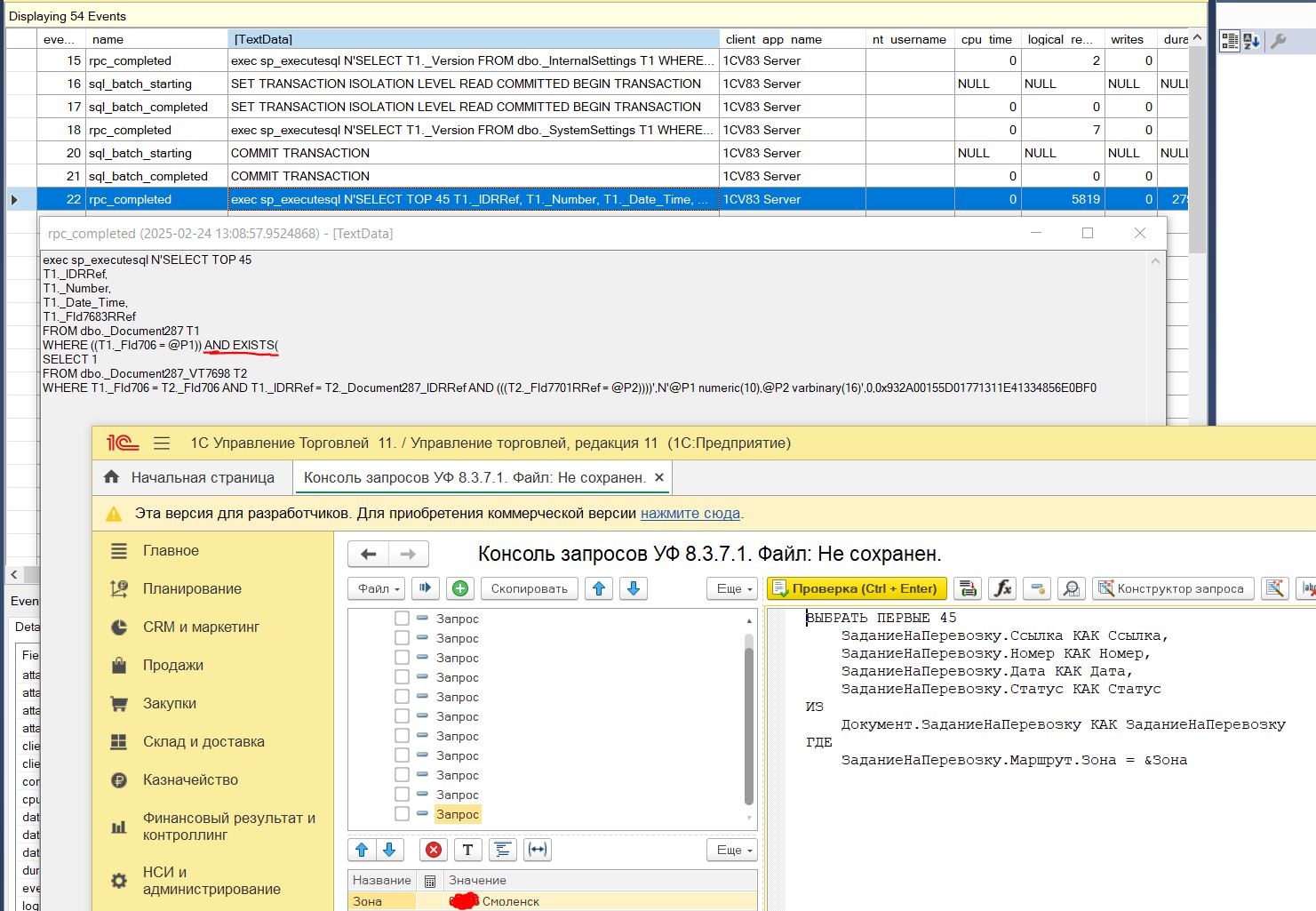
Во время очередного анализа проблем с производительностью мы обнаружили ряд длительных запросов. В процессе изучения выяснилось, что проблема связана с АРМ "РабочееМестоМенеджераПоДоставке" и динамическим списком на основной форме "ЗаданияНаПеревозкуВРаботе".
Как всегда вы можете воспользоваться нашей замечательной конфигурацией "Мониторинг производительности" или любыми другими инструментами для поиска подобных ситуаций.
Рис. Изображение АРМ Доставка
Давайте разберемся в чем именно заключается проблема. Для этого откроем свойства динамического списка и изучим текст запроса, который используется для его формирования.
Запрос выглядит вот так:
ВЫБРАТЬ РАЗЛИЧНЫЕ
ДокументЗаданиеНаПеревозку.Ссылка,
ДокументЗаданиеНаПеревозку.ПометкаУдаления,
ДокументЗаданиеНаПеревозку.Номер,
ДокументЗаданиеНаПеревозку.Дата,
ДокументЗаданиеНаПеревозку.Проведен,
ВЫРАЗИТЬ(ДокументЗаданиеНаПеревозку.ДополнительнаяИнформация КАК СТРОКА(1000)) КАК ДополнительнаяИнформация,
ДокументЗаданиеНаПеревозку.Статус,
ВЫРАЗИТЬ(ДокументЗаданиеНаПеревозку.Комментарий КАК СТРОКА(1000)) КАК Комментарий,
ДокументЗаданиеНаПеревозку.Ответственный,
ДокументЗаданиеНаПеревозку.ДатаВремяРейсаПланС,
ДокументЗаданиеНаПеревозку.ДатаВремяРейсаПланПо,
ДокументЗаданиеНаПеревозку.ДатаВремяРейсаФактС,
ДокументЗаданиеНаПеревозку.ДатаВремяРейсаФактПо,
ДокументЗаданиеНаПеревозку.ТранспортноеСредство,
ДокументЗаданиеНаПеревозку.КурьерЭкспедитор,
ДокументЗаданиеНаПеревозку.Водитель,
ДокументЗаданиеНаПеревозку.Склад,
ДокументЗаданиеНаПеревозку.Вес,
ДокументЗаданиеНаПеревозку.Объем,
ДокументЗаданиеНаПеревозку.КоличествоПунктов,
ДокументЗаданиеНаПеревозку.Приоритет,
ДокументЗаданиеНаПеревозку.Операция,
ВЫБОР
КОГДА ДокументЗаданиеНаПеревозку.ЗаданиеВыполняет = ЗНАЧЕНИЕ(Перечисление.ТипыИсполнителейЗаданийНаПеревозку.НашаТранспортнаяСлужба)
ТОГДА 1
ИНАЧЕ 0
КОНЕЦ КАК ЭтоНашаДоставка,
ДокументЗаданиеНаПеревозку.ЗаданиеВыполняет
ИЗ
Документ.ЗаданиеНаПеревозку КАК ДокументЗаданиеНаПеревозку
ЛЕВОЕ СОЕДИНЕНИЕ Документ.ЗаданиеНаПеревозку.Маршрут КАК ЗаданиеНаПеревозкуМаршрут
ПО (ЗаданиеНаПеревозкуМаршрут.Ссылка = ДокументЗаданиеНаПеревозку.Ссылка)
{ГДЕ
ЗаданиеНаПеревозкуМаршрут.Зона.*}
В данном запросе меня смущает использование ключевого слова РАЗЛИЧНЫЕ. Зачем разработчики его добавили? Давайте разберемся.
Если внимательно изучить запрос и форму АРМ, можно заметить, что на форме реализован отбор по зоне. Однако поле "Зона" отсутствует в шапке документа "Задание на перевозку" — оно находится в табличной части "Маршрут". Именно поэтому разработчики добавили соединение с этой табличной частью.
Но здесь возникает проблема: после соединения с табличной частью высока вероятность появления дублей по ключевому полю "Ссылка". Это, в свою очередь, может привести к некорректной работе динамического списка. Чтобы избежать дублирования строк и обеспечить корректное функционирование списка, необходимо исключить дубли. Именно для этой цели и используется ключевое слово РАЗЛИЧНЫЕ.
На первый взгляд, в коде запроса явного отбора нет, но он добавляется динамически в процессе работы системы.
Если ЗонаГруппаИлиПустая Тогда
ОбщегоНазначенияКлиентСервер.УстановитьЭлементОтбораДинамическогоСписка(ЗаданияНаПеревозкуВРаботе,
"Зона", Зона, ВидСравненияКомпоновкиДанных.ВИерархии,,ЗначениеЗаполнено(Зона));
Иначе
ОбщегоНазначенияКлиентСервер.УстановитьЭлементОтбораДинамическогоСписка(ЗаданияНаПеревозкуВРаботе,
"Зона", Зона, ВидСравненияКомпоновкиДанных.Равно,,Истина);
КонецЕсли;
Однако прежде чем двигаться дальше, давайте разберемся на простом примере, почему такой запрос может работать не оптимально.
2) Демонстрация теории на простом примере
Прежде чем двигаться дальше, давайте рассмотрим проблему на примере произвольного динамического списка. Эта небольшая вставка, я уверен, позволит лучше понять всю глубину существующей проблемы.
Одно из замечательных свойств динамического списка — это возможность получения данных небольшими порциями. Платформа 1С автоматически добавляет ограничение на количество записей при формировании SQL-запроса. Например, для MS SQL она добавляет TOP 45, а для PostgreSQL — LIMIT 45 (в динамических списках с динамическим считыванием). Если динамическое считывание отключено, то по умолчанию выбираются первые 1000 записей.
Чем это полезно? Такое ограничение позволяет получать данные небольшими порциями, что значительно снижает нагрузку на канал передачи данных и ускоряет время выполнения запроса.
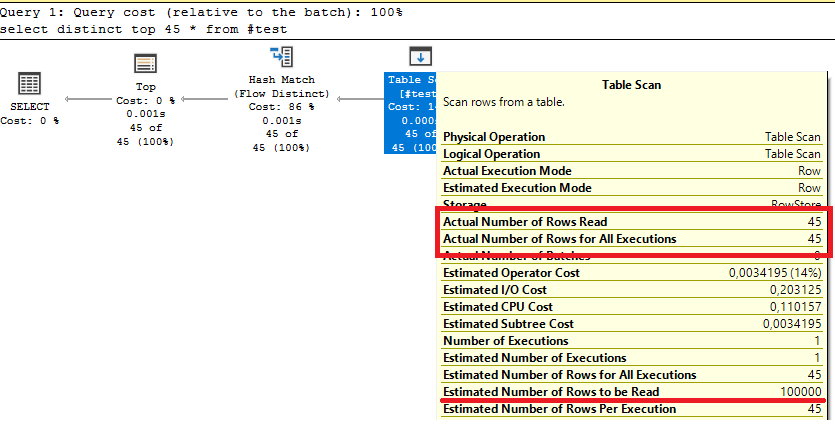
Рассмотрим это на примере. Предположим, в моей демонстрационной базе данных находится около 800 тысяч заказов клиентов. Я могу выполнить простой запрос.
ВЫБРАТЬ
ЗаказКлиента.Ссылка КАК Ссылка,
ЗаказКлиента.Номер КАК Номер,
ЗаказКлиента.Дата КАК Дата
ИЗ
Документ.ЗаказКлиента КАК ЗаказКлиента
В результате я получу на клиенте огромную таблицу данных, которая, по сути, мне не нужна. Сложно представить человека, который будет вручную просматривать все 800 тысяч записей. Скорее всего, вы воспользуетесь фильтром или отбором, чтобы найти нужную информацию. Именно поэтому использование таких «голых» запросов без ограничений в реальной практике не имеет смысла — это неэффективно и создает излишнюю нагрузку на систему.
План запроса: https://explain.tensor.ru/archive/explain/5aedc4e3813f6f6b13325321e3637163:0:2025-02-15#visio
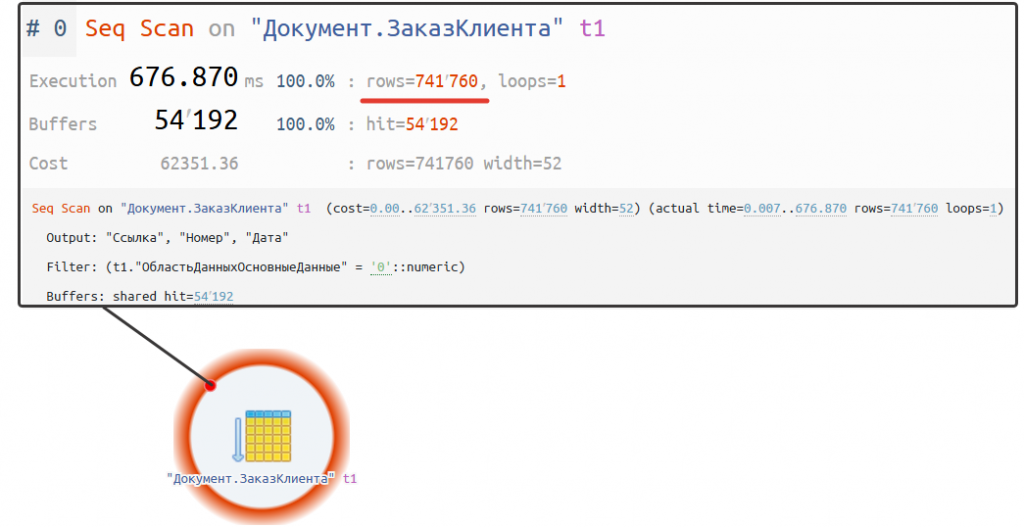
План выполнения запроса выглядит достаточно просто. Мы видим, что данные выбираются из источника — таблицы заказов клиентов, причем выбираются все строки (см. rows). На первый взгляд, это может показаться быстрым, но в реальной жизни обычно на процесс выборки накладываются ограничения RLS (Row-Level Security — безопасность на уровне строк), что значительно увеличивает время выполнения запроса.
Об особенностях работы RLS и его влиянии на производительность я расскажу в отдельной статье, так что оставайтесь на связи!
Теперь, если я добавлю в запрос ограничение как в динамическом списке (например, ПЕРВЫЕ 45), то получу только небольшую порцию данных. В этом случае запрос будет выглядеть следующим образом:
ВЫБРАТЬ ПЕРВЫЕ 45
ЗаказКлиента.Ссылка КАК Ссылка,
ЗаказКлиента.Номер КАК Номер,
ЗаказКлиента.Дата КАК Дата
ИЗ
Документ.ЗаказКлиента КАК ЗаказКлиента
Такой запрос выполняется практически мгновенно. Теперь давайте взглянем на план выполнения этого запроса.
План запроса: https://explain.tensor.ru/archive/explain/e4a61626ee6f9a1b5b5ba7b038be558c:0:2025-02-15#visio
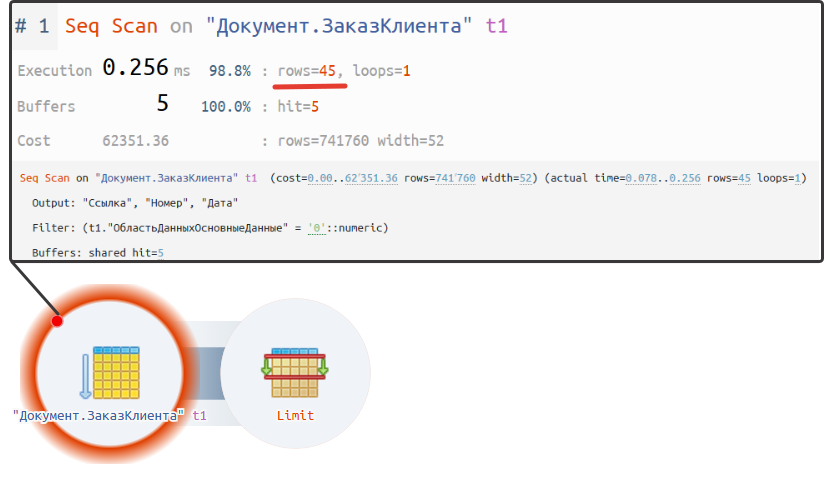
Как мы видим, из источника данных выбирается ровно 45 записей, что выполняется крайне быстро. По сравнению с предыдущим запросом, где выбирались все данные, разница в производительности составляет почти 3 000 раз. Выглядит это действительно впечатляюще.
Если говорить точнее, такой подход с использованием ключевого слова ПЕРВЫЕ работает следующим образом: система начинает выбирать записи из таблицы, и как только количество выбранных записей достигает установленного ограничения (в нашем случае — 45), выполнение запроса в СУБД завершается. Это позволяет значительно сократить время выполнения и снизить нагрузку на систему.
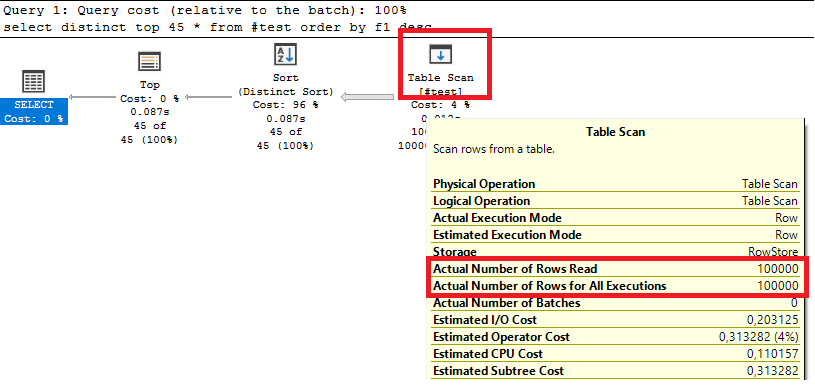
Теперь добавим ключевое слово РАЗЛИЧНЫЕ в исходный запрос. Не стоит искать в этом какого-то глубокого смысла — это просто шаг для нашего расследования.
ВЫБРАТЬ РАЗЛИЧНЫЕ ПЕРВЫЕ 45
ЗаказКлиента.Ссылка КАК Ссылка,
ЗаказКлиента.Номер КАК Номер,
ЗаказКлиента.Дата КАК Дата
ИЗ
Документ.ЗаказКлиента КАК ЗаказКлиента
План запроса: https://explain.tensor.ru/archive/explain/f1a8d36ec88be5a94e0fd6019f83e792:0:2025-02-15#visio

Как мы видим, в результате выбирается 45 записей (операторы #1 и #3, см. rows), но при этом СУБД вынуждена прочитать всю таблицу заказов клиентов (оператор #2) чтобы найти различные. В итоге такой запрос выполняется даже дольше, чем первый вариант, — примерно в 3 раза, несмотря на то что мы получили всего 45 записей.
Почему это происходит? Чтобы наглядно объяснить, приведу пример. Представим, что у нас есть таблица с миллионом записей (или даже больше), и все записи в ней содержат всего три слова: «мяч», «лопата» и «собака».
Если мы просто выберем первые 45 записей без каких-либо преобразований, операция выполнится очень быстро. Однако в результате мы получим дублирующиеся данные, так как все записи содержат одни и те же три значения.
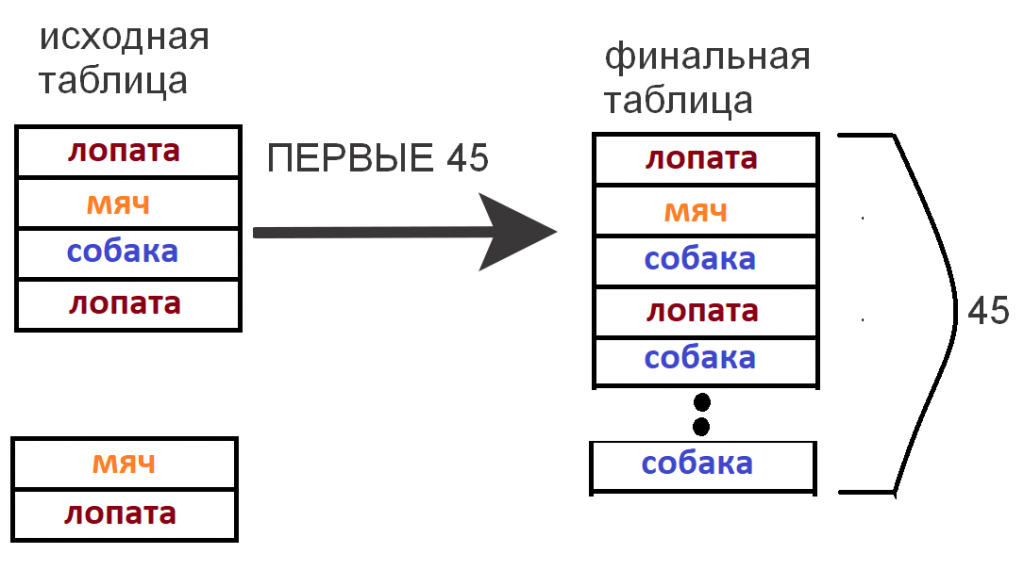
Но нам не нужны дубли. Для этого мы должны использовать РАЗЛИЧНЫЕ. В результате получим не более трех уникальных значений: «мяч», «лопата» и «собака». На рисунке ниже показана схема работы ключевого слова РАЗЛИЧНЫЕ и то, как оно фильтрует дублирующиеся данные.
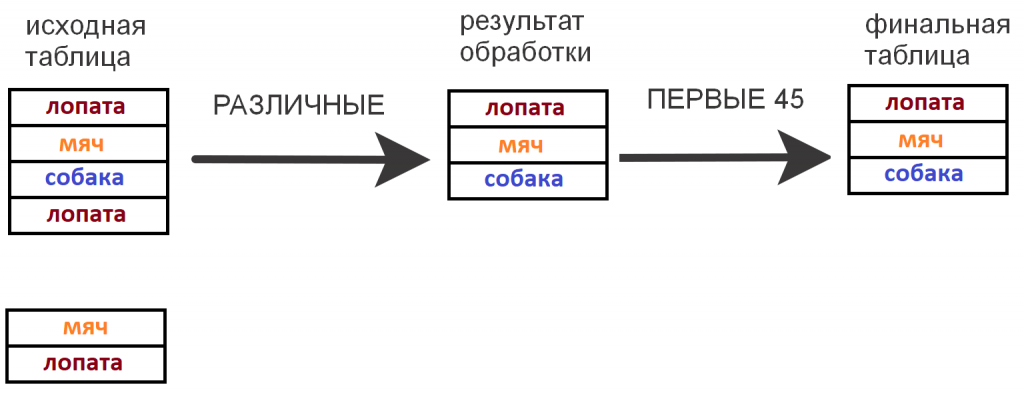
Мы можем сделать вывод, что при использовании ключевого слова РАЗЛИЧНЫЕ, даже несмотря на ограничение выборки (ПЕРВЫЕ), система все равно вынуждена просматривать всю исходную таблицу. Это происходит потому, что для определения уникальности значений необходимо проанализировать все данные.
Таким образом, эффективность использования ПЕРВЫХ теряется, так как СУБД все равно выполняет полное сканирование таблицы. Единственное, чего мы достигаем, — это уменьшение количества передаваемых записей на клиент, что лишь частично снижает нагрузку на канал передачи данных.
В некоторых случаях, когда вы используете ключевое слово РАЗЛИЧНЫЕ для получения уникальных записей, это может указывать на наличие проблемы — либо в самом запросе, либо в архитектуре приложения.
3) Анализ текущей проблемы
Продолжим разбор нашей проблемы. Исходя из вышесказанного, мы понимаем, что использование оператора РАЗЛИЧНЫЕ снижает эффективность работы динамического списка. Чтобы лучше понять масштаб проблемы, давайте посмотрим на время выполнения и план запроса. Эти данные понадобятся нам для сравнения с результатами оптимизации.
Для выполнения анализа воспользуемся консолью запросов. Чтобы приблизить условия к реальным, добавим в запрос ключевое слово ПЕРВЫЕ 45.
ВЫБРАТЬ РАЗЛИЧНЫЕ ПЕРВЫЕ 45
ДокументЗаданиеНаПеревозку.Ссылка,
ДокументЗаданиеНаПеревозку.ПометкаУдаления,
ДокументЗаданиеНаПеревозку.Номер,
ДокументЗаданиеНаПеревозку.Дата,
ДокументЗаданиеНаПеревозку.Статус
ИЗ
Документ.ЗаданиеНаПеревозку КАК ДокументЗаданиеНаПеревозку
ЛЕВОЕ СОЕДИНЕНИЕ Документ.ЗаданиеНаПеревозку.Маршрут КАК ЗаданиеНаПеревозкуМаршрут
ПО (ЗаданиеНаПеревозкуМаршрут.Ссылка = ДокументЗаданиеНаПеревозку.Ссылка)
{ГДЕ
ЗаданиеНаПеревозкуМаршрут.Зона.*}
Время выполнения этого запроса на демонстрационной базе заняло около 5 с.
План запроса: https://explain.tensor.ru/archive/explain/320bd4aca448011918865a3310b77591:0:2025-02-12#visio
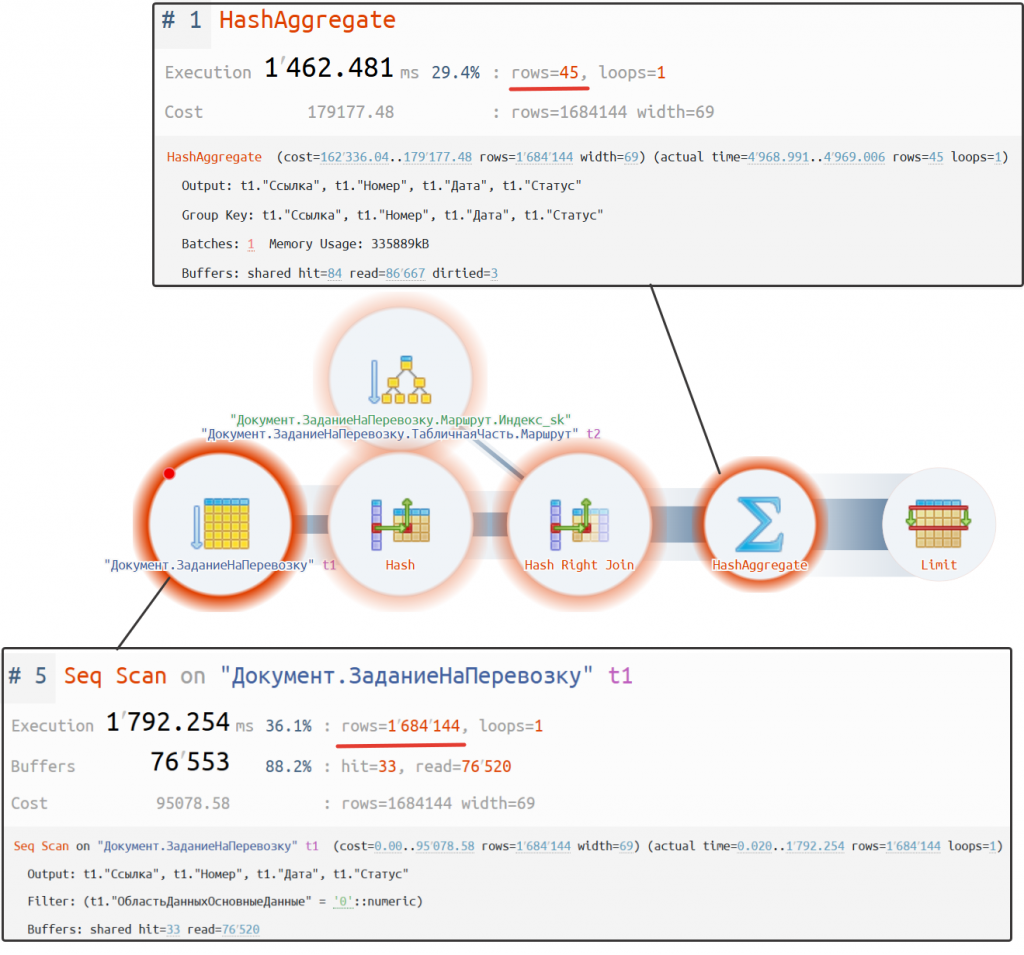
Как мы видим из плана запроса, происходит полное сканирование таблицы заданий на перевозку, затем выполняется агрегация данных, и только после этого выбираются 45 строк. Теперь перейдем к оптимизации запроса.
4) Исправления запроса
Нам необходимо исправить запрос. А именно — избавиться от ключевого слова РАЗЛИЧНЫЕ. Исходя из логики предыдущего запроса, нам нужно получить список заданий на перевозку, в которые входит выбранная зона. Другими словами, мы добавили РАЗЛИЧНЫЕ и соединение с табличной частью Маршруты только для того, чтобы реализовать возможность отбора по зоне.
Избавиться от РАЗЛИЧНЫЕ и при этом сохранить отбор можно несколькими способами. Что интересно, тексты запросов на языке 1С будут различаться, но их преобразование в SQL-текст окажется одинаковым.
Первый вариант
Мы удаляем соединение с табличной частью Маршруты, но добавляем в секцию ГДЕ отбор по условию, связанному с табличной частью через ссылку. Пример такого запроса приведен ниже.
ВЫБРАТЬ ПЕРВЫЕ 45
ДокументЗаданиеНаПеревозку.Ссылка КАК Ссылка,
ДокументЗаданиеНаПеревозку.Номер КАК Номер,
ДокументЗаданиеНаПеревозку.Дата КАК Дата,
ДокументЗаданиеНаПеревозку.Статус КАК Статус
ИЗ
Документ.ЗаданиеНаПеревозку КАК ДокументЗаданиеНаПеревозку
ГДЕ
ДокументЗаданиеНаПеревозку.Маршрут.Зона В(&Зона)
SELECT
T1.Ссылка,
T1.Номер,
T1.Дата,
T1.Статус
FROM Документ.ЗаданиеНаПеревозку T1
WHERE ((T1.ОбластьДанныхОсновныеДанные = CAST(0 AS NUMERIC))) AND (EXISTS(SELECT
CAST(42 AS NUMERIC) AS Q_002_F_000_
FROM Документ.ЗаданиеНаПеревозку.Маршрут T2
WHERE ((T2.ОбластьДанныхОсновныеДанные = CAST(0 AS NUMERIC))) AND ((T2.Ссылка = T1.Ссылка) AND (T2.Зона IN ('\\000\\000\\000\\000\\000\\000\\000\\000\\000\\000\\000\\000\\000\\000\\000\\000'::bytea))))) LIMIT 45
План запроса: https://explain.tensor.ru/archive/explain/ff019c7079075007f0da4dbdf746bdda:0:2025-02-12#visio
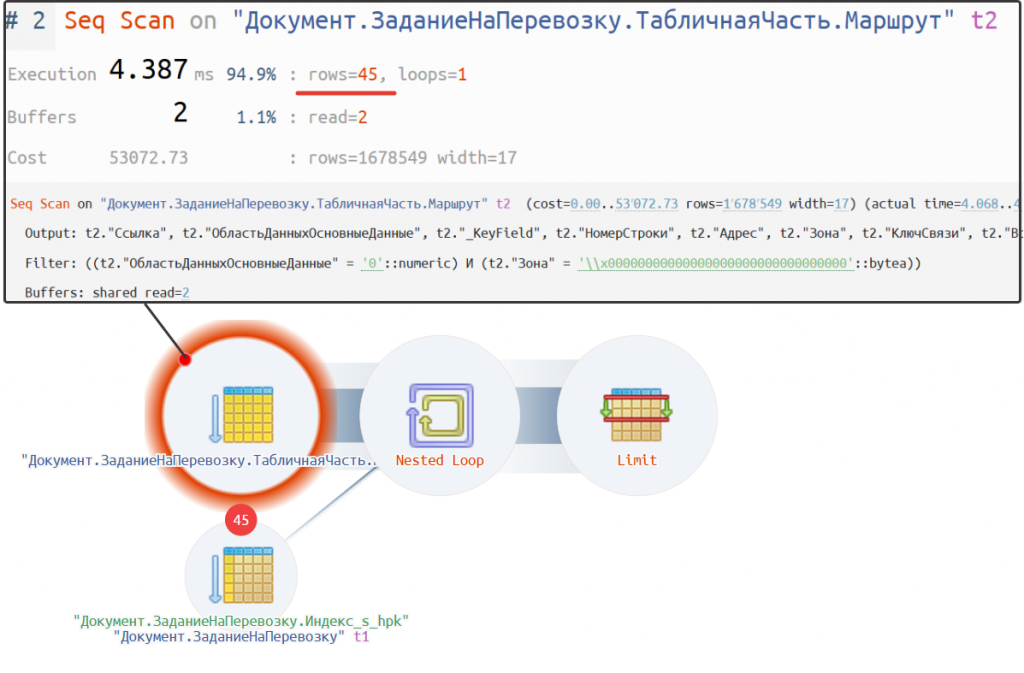
Время выполнения запроса составило около 4 мс. Выбирается 45 записей, и план запроса выглядит достаточно оптимально. В итоге запрос выполняется в 1 000 раз быстрее. Но, это не единственное решение, есть еще один вариант. Его рассмотрим чуть ниже.
Второй вариант
Теперь рассмотрим второй вариант формирования отбора с использованием оператора EXISTS. Для этого нам нужно добавить нестандартный отбор, основанный на связи основной таблицы с таблицей Маршруты внутри оператора В. Пример такого запроса вы можете увидеть ниже.
ВЫБРАТЬ ПЕРВЫЕ 45
ДокументЗаданиеНаПеревозку.Ссылка КАК Ссылка,
ДокументЗаданиеНаПеревозку.Номер КАК Номер,
ДокументЗаданиеНаПеревозку.Дата КАК Дата,
ДокументЗаданиеНаПеревозку.Статус КАК Статус
ИЗ
Документ.ЗаданиеНаПеревозку КАК ДокументЗаданиеНаПеревозку
ГДЕ
42 В
(ВЫБРАТЬ ПЕРВЫЕ 1
42
ИЗ
Документ.ЗаданиеНаПеревозку.Маршрут КАК ЗаданиеНаПеревозкуМаршрут
ГДЕ
ЗаданиеНаПеревозкуМаршрут.Ссылка = ДокументЗаданиеНаПеревозку.Ссылка
И ЗаданиеНаПеревозкуМаршрут.Зона В (&Зона))
SELECT
T1.Ссылка,
T1.Номер,
T1.Дата,
T1.Статус
FROM Документ.ЗаданиеНаПеревозку T1
WHERE ((T1.ОбластьДанныхОсновныеДанные = CAST(0 AS NUMERIC))) AND (EXISTS(SELECT
CAST(42 AS NUMERIC) AS Q_002_F_000_
FROM Документ.ЗаданиеНаПеревозку.Маршрут T2
WHERE ((T2.ОбластьДанныхОсновныеДанные = CAST(0 AS NUMERIC))) AND ((T2.Ссылка = T1.Ссылка) AND (T2.Зона IN ('\\000\\000\\000\\000\\000\\000\\000\\000\\000\\000\\000\\000\\000\\000\\000\\000'::bytea))))) LIMIT 45
Обратите внимание: несмотря на то что оба запроса на языке 1С выглядят по-разному, их преобразование в SQL-синтаксис оказывается одинаковым. Соответственно и планы запросов получились одинаковые.
План запроса: https://explain.tensor.ru/archive/explain/54de1f45f58d83a7a5f5835de1426def:0:2025-02-12#visio
Это еще не окончательное решение!
Мы должны проверить различные условия отборов, чтобы понять, как они влияют на запрос. Однако в результате мы можем столкнуться с неожиданным поведением. Например, если в качестве значения отбора выбрать что-то отличное от пустого, скажем, "Москва", то план выполнения запроса значительно изменится и станет таким:
https://explain.tensor.ru/archive/explain/f5360593bd779aa63b3975ad1bd22aad:0:2025-02-12#visio
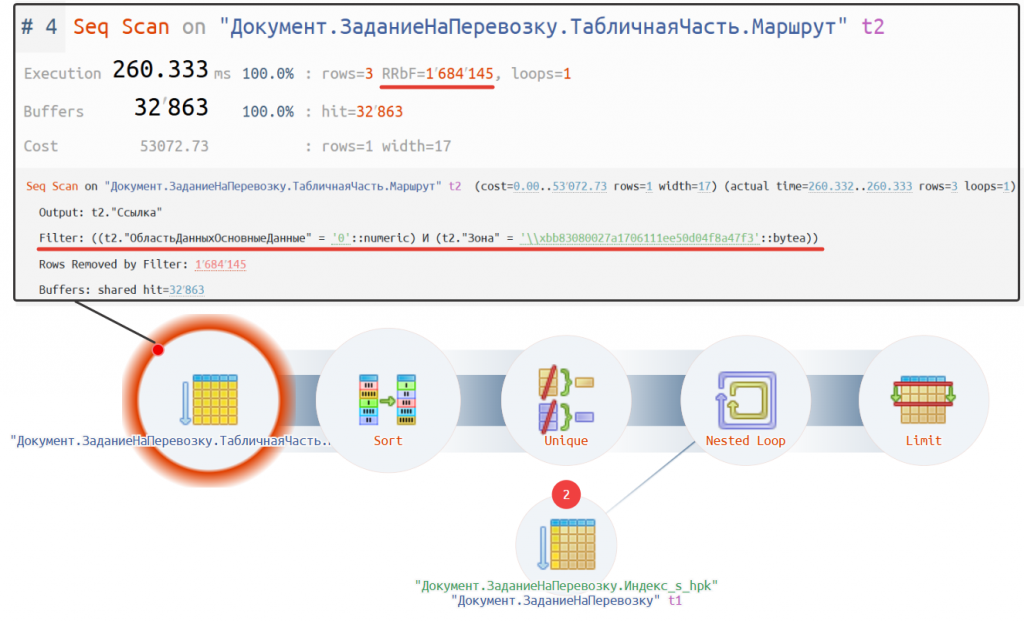
Если сейчас мы сравним время выполнения неоптимизированного запроса с оптимизированными, то увидим, что существенного прироста производительности не наблюдается. В чем же причина?
С одной стороны, дело в статистике данных. Когда я заполнял базу, то пропустил указание зоны, и в результате большинство заданий на перевозку оказались с пустым значением зоны. Позже я перезаполнил небольшую часть записей другими значениями.
В случае, когда значение зоны было пустым, планировщик запросов использовал в качестве источника данных кластерный индекс табличной части "Маршруты". Пустые значения составляли около 90% данных.
Во втором случае, когда я выбрал зону "Москва", документов с таким значением оказалось значительно меньше. В результате планировщик выбрал в качестве лидирующей таблицы "Маршруты". Однако поле "Зона" в этой таблице не проиндексировано, поэтому планировщик вынужден сначала сканировать всю таблицу (см. оператор #4) для отбора подходящих записей, и только потом выполнять соединение с другими таблицами. А это естественно не эффективно.
Внимание! Должна быть индексация по полям, которые находятся в отборах. Не обязательно для всех полей, а только для наиболее релевантных. Это отдельная большая тема, поэтому оставим за рамками этой статьи.
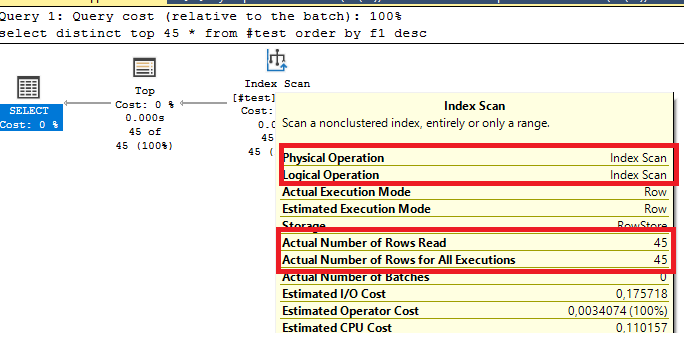
Нам нужно установить индексирование. Добавим индексацию на поле "Зона". После этого запрос начинает выполняться практически мгновенно.
План запроса: https://explain.tensor.ru/archive/explain/57a102297fba4dd0cfecdd68b359622b:0:2025-02-12#visio
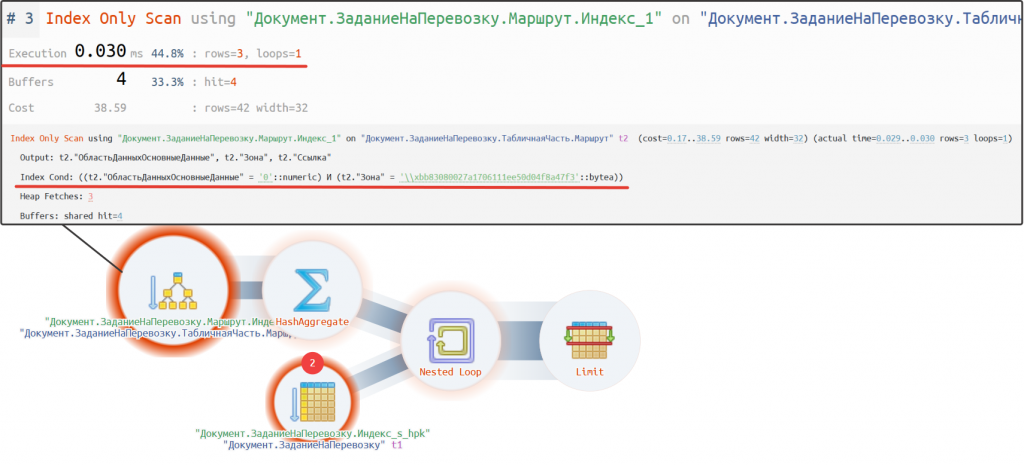
Как мы видим, теперь используется индекс (см. оператор #3), и выборка данных выполняется наиболее оптимальным способом. В результате наш запрос стал выполняться практически в 75 000 раз быстрее.
Однако самое интересное заключается в том, что на практике запросы часто выполняются с учетом RLS (Row-Level Security), и в таких случаях добавление индекса становится еще более критичным. Конечно, степень улучшения производительности зависит от конкретных данных, которые хранятся в вашей базе.
Исходный запрос с учетом ограничений RLS – время выполнения 6,5 с
https://explain.tensor.ru/archive/explain/9d932e050003b374b1edcd148b2b9fc5:0:2025-02-15#visio
Оптимизированный запрос с RLS - время выполнения 1,4 мс
https://explain.tensor.ru/archive/explain/d5dc33888cc4b5fc72f83aeef5dcc431:0:2025-02-15#visio
5) Заключение
Использование ключевого слова РАЗЛИЧНЫЕ в динамических списках может быть полезным для устранения дубликатов, однако оно часто приводит к значительному снижению производительности. Основная проблема заключается в том, что для определения уникальности записей система вынуждена сканировать всю таблицу или её значительную часть, даже если в запросе указано ограничение на количество строк (например, ПЕРВЫЕ 45). Это сводит на нет преимущества динамической загрузки данных небольшими порциями.
Кроме того, использование РАЗЛИЧНЫЕ может указывать на проблемы в архитектуре запроса или данных. Однако бывают случаи, когда подобный подход действительно необходим для решения конкретной задачи. В таких ситуациях все же стоит тщательно пересмотреть своё решение и оценить, можно ли достичь цели более эффективным способом.
В общем, запрос в динамическом списке должен быть максимально простым и оптимизированным. Избегайте излишней сложности и необоснованного использования операторов, которые могут негативно сказаться на производительности.
Думаю, Вам будет интересно ознакомиться с другими моими статьями по исправлению ошибок и повышению производительности - другие публикации.
P.S. К сожалению, складывается впечатление, что разработчики конфигурации не читают статьи на этом замечательном сайте и, судя по всему, вообще не интересуются проблемами высокопроизводительных систем. Я давно разочаровался в личном общении с поддержкой — кроме лишней и бессмысленной работы с моей стороны, это редко приводит к каким-то результатам.
С другой стороны, при каждой новой встрече с "замечательной" конфигурацией ERP выполнять одни и те же оптимизационные мероприятия уже порядком надоело.
Вступайте в нашу телеграмм-группу Инфостарт