В 2008 году я разработал собственный веб-клиент для платформы 1С:Предприятие. Его третья версия, которая появилась в 2015-м, оказалась экономически успешной. Последние девять лет на вопрос о том, чем занимается наша компания, я отвечаю: «Мы делаем сайты на 1С». Мы называем их веб-интерфейсами или веб-порталами. Визуально они выглядят как обычные сайты.
Пример нашего решения:
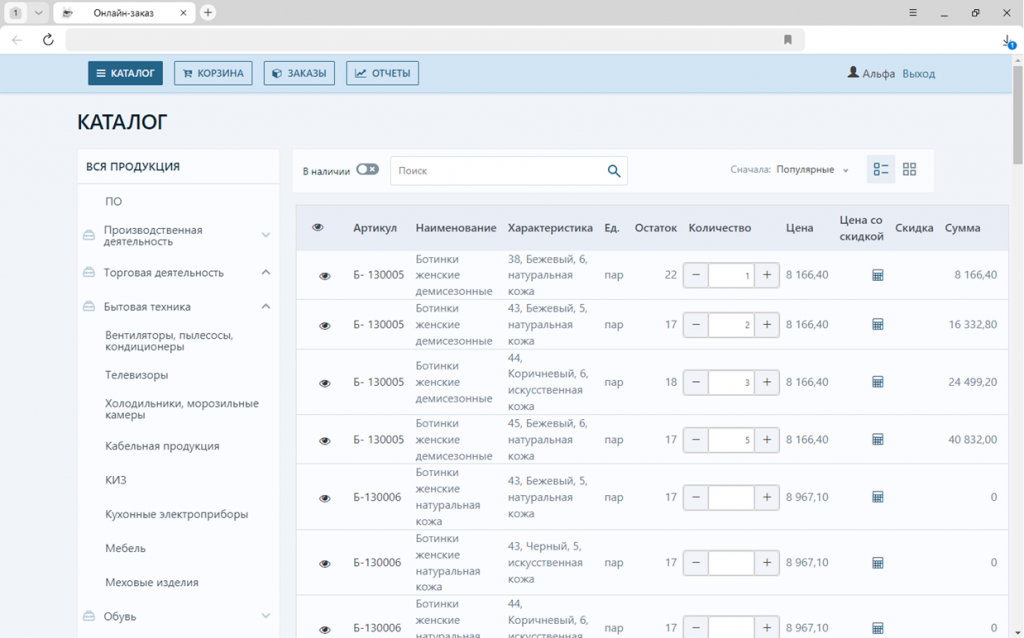
Внешне оно выглядит как обычный сайт. Его преимущество в том, что это интерфейс для заказа товаров дилерами и партнерами, работающий напрямую с 1С:Предприятие. Пользователи видят реальные остатки, актуальные номенклатурные списки, персональные цены и скидки – без ограничений, характерных для сайтов с отдельными СУБД и обменами. Такая интеграция часто невозможна в стандартных интерфейсах. Это ответ на вопрос, зачем создавать сайты на 1С.
В процессе создания собственного веб-клиента для 1С мы столкнулись с необходимостью оптимизации большого количества алгоритмов. Это в обычном интерфейсе 1С пользователи уже привыкли, что форма документа может открываться 5 секунд, а на запись требуется больше 10. Веб-интерфейсы пользователь воспринимает как обычный сайт, а к производительности сайтов предъявляются намного более жесткие требования: открытие страницы – менее чем за секунду, создание заказа – 2-3 секунды. Поэтому нам пришлось долго экспериментировать, чтобы среди нескольких алгоритмов выбрать наиболее быстродействующий. Сайт – это одна большая строка в формате html, которая заполнена данными, извлеченными из СУБД. Именно поэтому среди разобранных мифов будет много тем, связанных с обработкой строк и взаимодействием с базой данных.
Методология проверки мифов
Для тестирования была разработана внешняя обработка для демо-конфигурации «1С:Библиотека стандартных подсистем» (БСП). Она содержит 16 отдельных вкладок – по одной для каждого мифа. В рамках каждой вкладки представлены:
-
наименование проверяемого мифа,
-
код для тестирования утверждения,
-
кнопки запуска тестовых сценариев,
-
область вывода результатов замеров.
Разборы представлены в формате «Тезис -> Тестовый пример -> Подтверждение или опровержение -> Обоснование». В конце по каждому мифу я буду не только подтверждать или опровергать утверждение, но и объяснять, почему платформа работает именно так.
Часть информации была взята с сайтов разработчика платформы, в основном с its.1c.ru – этим источникам можно доверять однозначно. Другая часть – наши выводы. Они могут быть ошибочными. В случае обнаружения неточностей в методологии тестирования или интерпретации результатов мы открыты для дискуссии.
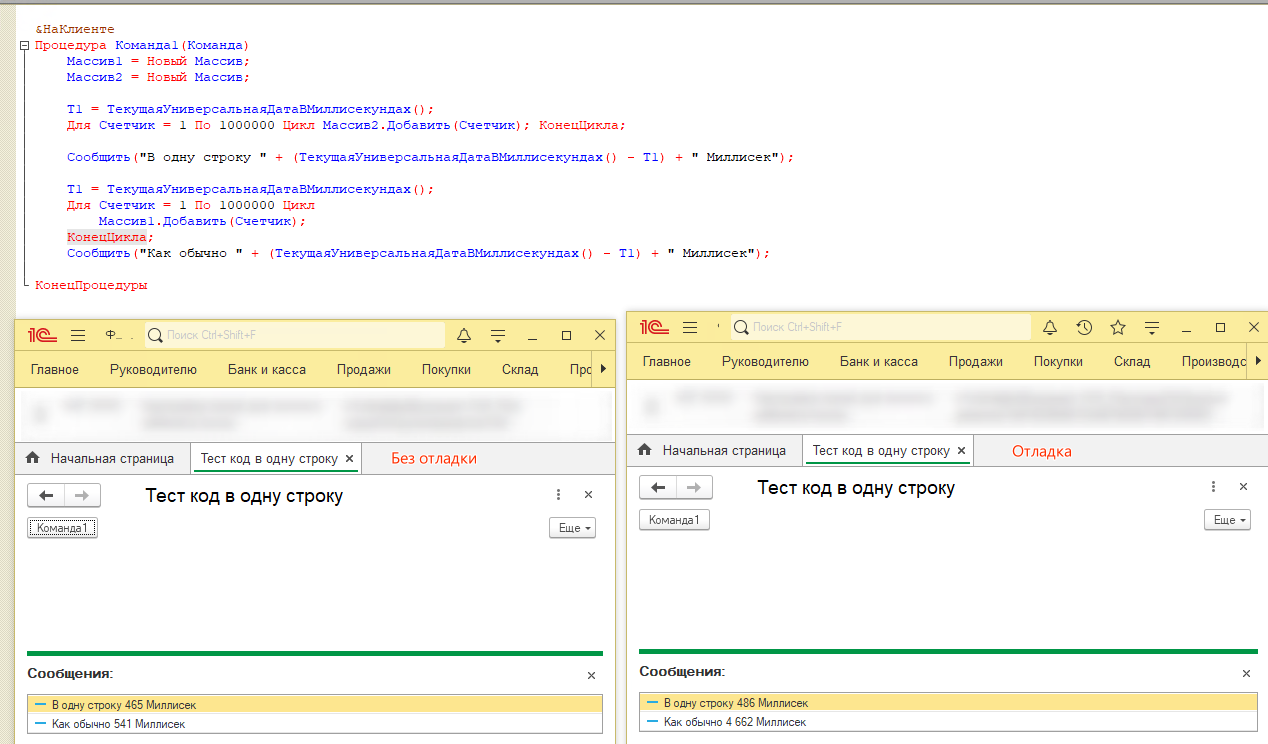
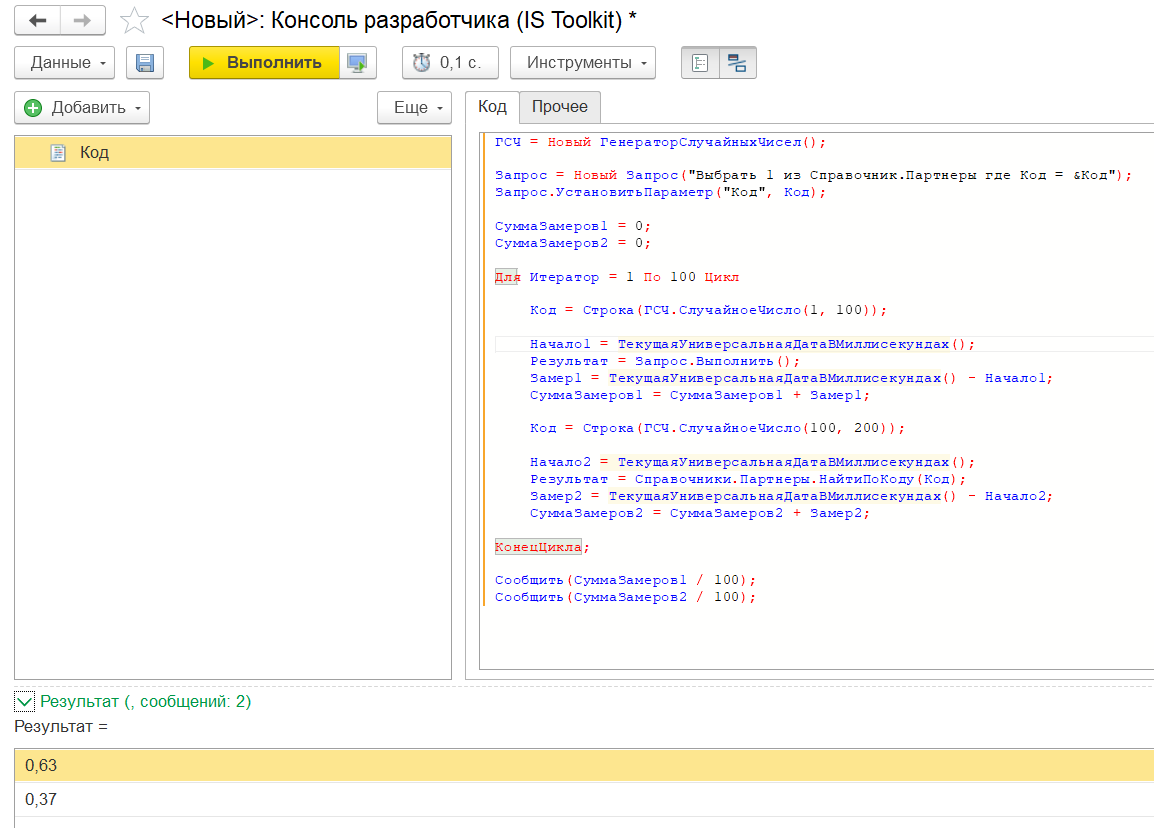
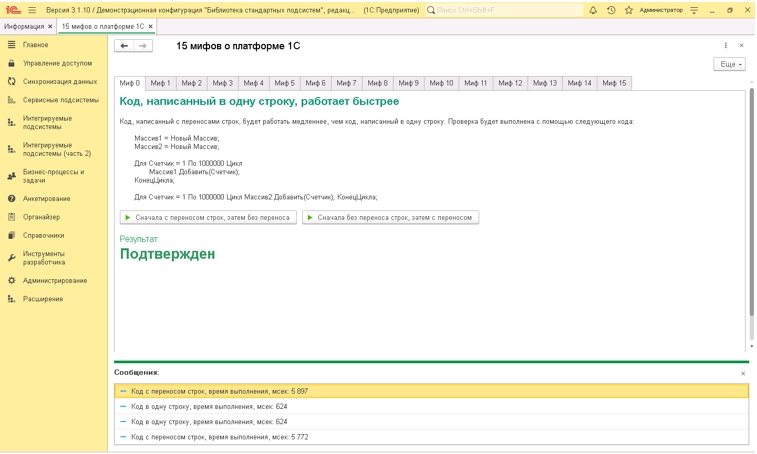
Миф 0. Код, написанный в одну строку, работает быстрее
Все знают об этом мифе. Код действительно работает быстрее. Алгоритм проверки:
|
Есть два массива, каждый из них заполняется миллионом значений в цикле. Функциональность циклов идентична, но первый написан в «человеческом» виде, а второй – в одну строку.
Результат следующий:

Код в одну строку действительно работает значительно быстрее – почти в 10 раз. Это объясняется особенностями алгоритма компиляции кода платформой 1С:Предприятие.
В процессе тестирования возникали вопросы: «А вдруг при первом запуске цикла платформа “разогревается”, происходит кэширование данных? Что будет, если поменять последовательность выполнения тестовых циклов местами?» Естественно, мы сделали дополнительные проверки. Однако результат показал: от перемены мест слагаемых результат не меняется.
|
Стоит отметить: в статье по каждому мифу демонстрируются только один итоговый результат. Но это не значит, что мы ограничились единственной попыткой. Все представленные результаты прошли многократную проверку.

Миф №0 подтвержден. Переходим к следующим.
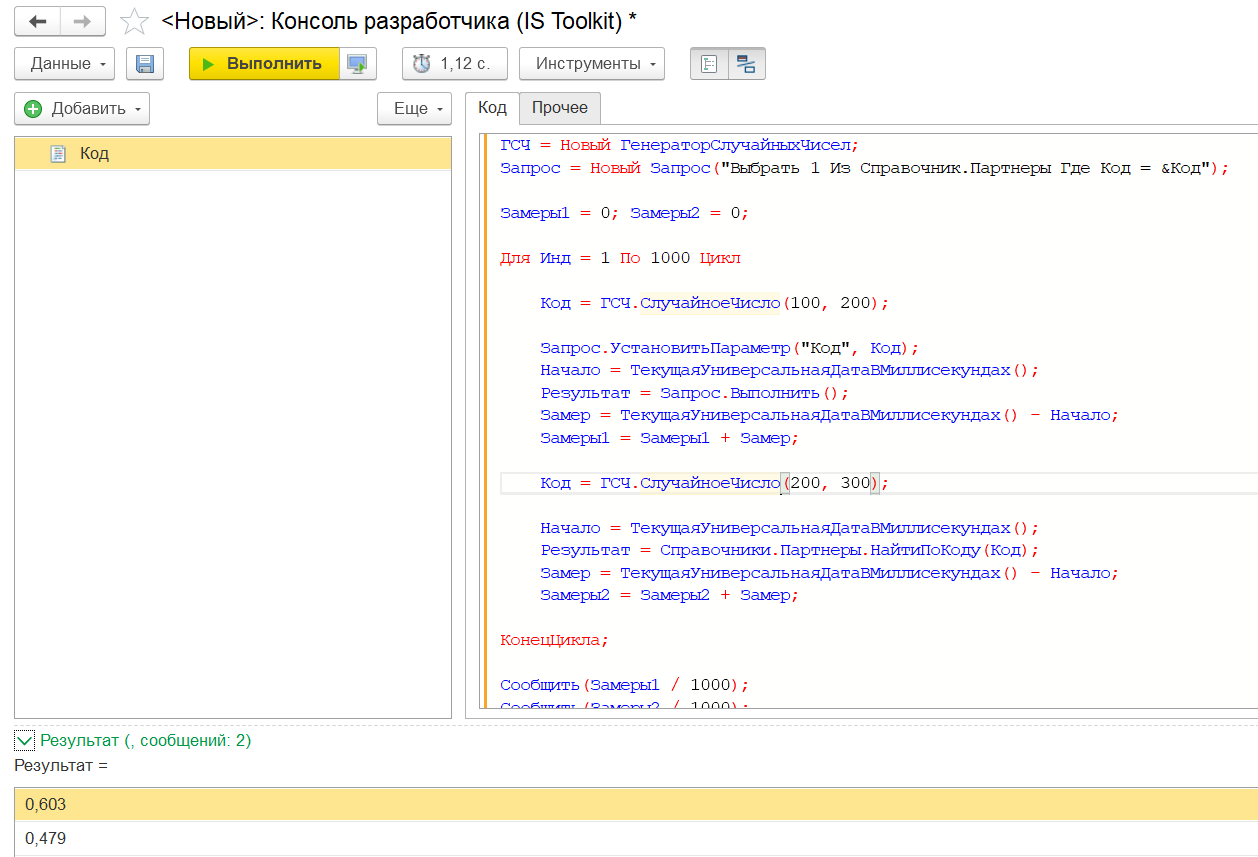
Миф 1. Обфусцированный код работает быстрее
Это утверждение логично вытекает из мифа №0, поскольку обфусцированный код обычно содержит меньше строк.
Методика проверки
За основу взят алгоритм из мифа №0 (заполнение массива). Мы сделали его более «разлапистым», чтобы обфускатору было над чем поработать. В первом случае этот код содержит всего три строки после обфускации:
|
Выполняем замеры и видим, что обфусцированный код действительно работает быстрее, чем обычный код с переносами строк. Но мы дополнительно взяли обычный цикл в одну строку в качестве эталона. В результате мы видим, что он работает быстрее обфусцированного варианта.

Зачем вообще мы проверяли обфусцированный код? Дело в том, что чаще всего его используют для защиты собственных решений. Мы тоже вынуждены применять этот подход, потому что пиратство у нас, к сожалению, имеет место. Наши клиенты регулярно спрашивают: «Обфусцированный код обычно содержит больше операций, не увеличивает ли его использование время выполнения кода ваших решений? Ведь он должен работать медленнее». Нет, как видите, не увеличивает.
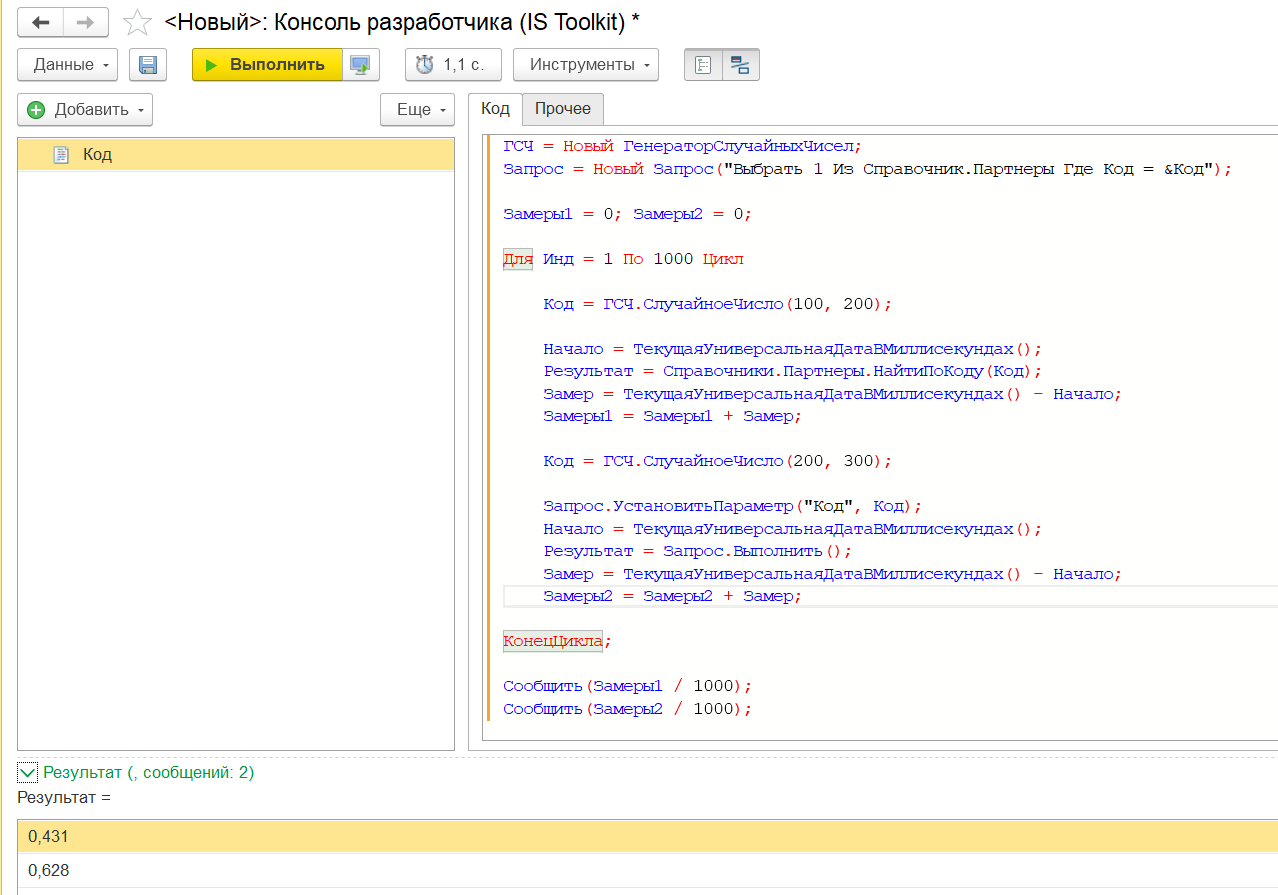
Мы решили еще немного оптимизировать этот алгоритм: обфусцированный код привели вручную к одной строке, после чего проверили, будет ли результат еще быстрее.
|
Оказалось, что производительность действительно повысилась. В строках результатов №2 и №3 представлено сравнение обычного кода и обфусцированного: вы видите, что по умолчанию обфускация дает эффект ускорения выполнения. Но, тем не менее, обфусцированный код в одну строку работает медленнее, чем обычный код в одну строку. Причина этого вполне понятна: в обфусцированном коде больше операторов.
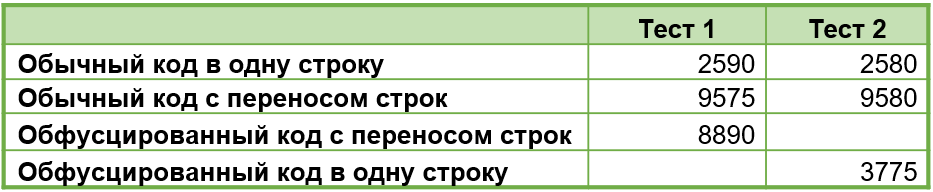
Поэтому мы считаем, что этот миф подтвержден, но с оговорками: по умолчанию обфусцированный код работает быстрее. Однако можно добиться того, что обычный код будет работать быстрее обфусцированного.
Миф 2. Функция СтрШаблон() быстрее, чем СтрЗамена()
Почему эта проверка важна для нас? Потому что при разработке веб-порталов мы постоянно работаем с шаблонами, которые необходимо заполнять данными из базы. Особенно это критично при обработке списков, где дополнительно подключаются циклы. Необходимо в цикле заполнить несколько десятков или сотен шаблонов данными.
Мы подумали: если функцию СтрШаблон() можно вызвать один раз, а функцию СтрЗамена() надо вызывать несколько раз, значит, СтрЗамена() должна работать значительно медленнее. Для проверки мы создали два функционально идентичных алгоритма: первый использует СтрШаблон(), второй – последовательность вызовов СтрЗаменить():
|
Результат: время выполнения вообще не различается.

Тогда возникла новая мысль: а что если поместить алгоритм заполнения в цикл? Количество строк кода уменьшится (было восемь отдельных вызовов СтрЗаменить(). Останется тоже восемь, но в более компактной форме). Ведь мы выяснили, что количество строк влияет на производительность.
|
Оказалось, влияние есть, но в обратную сторону. Когда мы поместили несколько СтрЗаменить() в цикл, время выполнения увеличилось вдвое. Это наводит на мысль, что дело не просто в количестве строк в коде, а в строках, связанных именно с циклическими операциями.
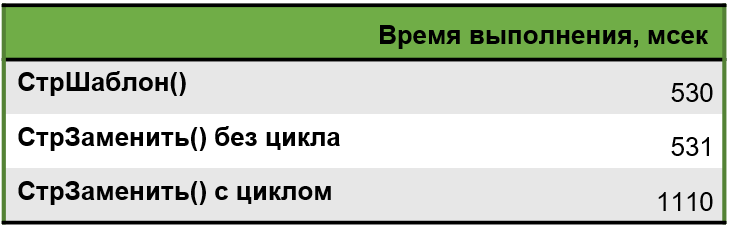
Мы провели дополнительный тест: оформили цикл с СтрЗаменить() в одну строку.
|
Результат сохранился на прежнем уровне – 560 миллисекунд.

Считаем, что данный миф не подтвержден: функция СтрШаблон() не быстрее, чем СтрЗамена(). При этом, код с несколькими вызовами в цикле выполняется значительно медленнее – это важное наблюдение. Можно предположить, что на уровне платформы функция СтрШаблон() использует несколько вызовов функции СтрЗаменить() в цикле.
Миф 3. Текстовый документ быстрее, чем переменная типа «Строка»
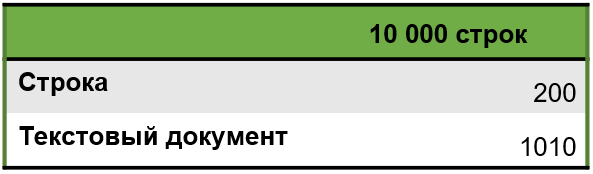
Логично предположить, что если текстовый документ специально создан для работы с большими объемами текста, значит, он должен быть эффективнее. Для проверки мы использовали код, который 10 000 раз добавляет новую строку в пустую переменную типа «Строка» и в пустой текстовый документ.
|
Результат замера: текстовый документ работал в 5 раз медленнее.
Мы предположили, что, возможно, 10 000 строк недостаточно для раскрытия потенциала текстового документа. Увеличили объем текста до 100 000 строк.
|
Результат не улучшился: текстовый документ по-прежнему значительно отставал.

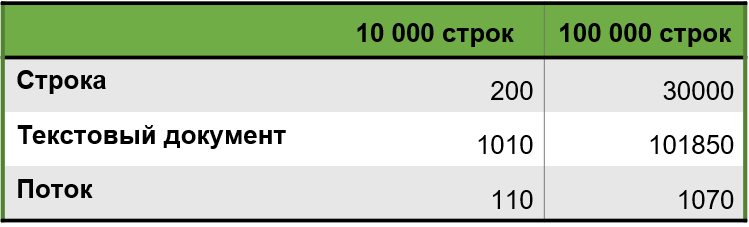
При этом в относительном выражении производительность переменной типа «Строка» тоже ухудшилась, причем нелинейно: хотя количество строк увеличилось в 10 раз, текстовый документ замедлился в 100 раз, а работа со строкой – в 150 раз. Это показывает, что текстовый документ может быть чуть более оптимизированным, но все равно остается слишком медленным. Для работы с большими текстами мы рекомендуем использовать потоки. Повторили тот же тест, используя потоки вместо строки и текстового документа. Сначала проверили на 10 000 строк, затем – на 100 000.
|
Результаты стали значительно интереснее: 110 миллисекунд и 1 секунда соответственно.
Учитывая наше открытие о преимуществе однострочных циклов (миф №0), мы преобразовали код в однострочный формат и добавили тест для миллиона строк.
|
Получили совсем интересные результаты: 33 миллисекунды, 375 миллисекунд и 3760 миллисекунд. Четко видна линейная зависимость: при десятикратном увеличении объема данных время обработки возрастает в 10 раз, при стократном – в 100 раз.
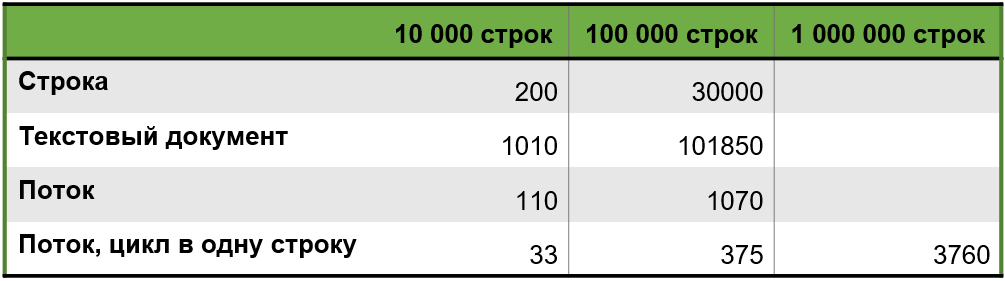
Таким образом, миф опровергнут: текстовый документ не быстрее переменной типа «Строка». Сборка текста через текстовый документ требует больше времени. При этом потоки демонстрируют стабильную производительность без замедления при росте объемов.
Как работают потоки? Когда мне необходимо объяснить что-то сложное на примере чего-то простого, я стараюсь прибегать к примерам с автомобилями.
Представьте, что вас четыре человека и вам дали задачу переместить данные из СУБД в файловую систему. СУБД – это автомобиль с арбузами, а файловая система – это магазин. Вам необходимо переместить данные в магазин.
В чем особенность работы текстовых документов и строк при обычном программировании? Неискушенный человек сначала попытается передать сразу все арбузы (данные) людям в руки, чтобы они за один раз перенесли их в магазин. Но это получится только если люди возьмут арбузов не больше, чем способны удержать. А арбузов на самом деле больше.

Получается, что человек забирает каждый новый арбуз, накапливая их в руках. В этом случае выборка каждого нового арбуза занимает все больше и больше времени, потому что «арбузы» складываются в оперативную память и занимают ее. Рано или поздно ресурсы сервера заканчиваются и наступает следующая ситуация:

Впечатлительным можно продолжать чтение: красная жидкость – это арбузный сок.
Чтобы такая ситуация не происходила, следует организовывать цепочку из людей. Каждый взял бы по арбузу: первый человек берет первый арбуз и передает его второму; второй человек передает первый арбуз третьему и так далее до места назначения. Таким образом работает поток:

Преимущества потокового подхода очевидны: в оперативной памяти всегда максимум четыре «арбуза», а выборка каждого следующего «арбуза» занимает столько же времени, сколько выборка первого «арбуза». Это доказано цифрами: 33 мс, 375 мс, 3760 мс. Вы можете обрабатывать неограниченное количество информации с предсказуемым линейным ростом времени выполнения алгоритма и без увеличения нагрузки на систему.
Используйте потоки не только для файловых операций, но и для работы с данными в памяти. Миф о скорости текстового документа развеян, а потоки заслуживают вашего внимания.
Миф 4. «ЗаполнитьЗначенияСвойств()» может работать медленно
Миф звучит так: «Функция ЗаполнитьЗначенияСвойств() может работать медленно, если в источнике намного больше ключей, чем в приемнике». Мы многократно запускали функцию, передавая в параметрах количество ключей в структуре-источнике и структуре-приемнике. При этом в приемнике значения свойств не заполнены (Неопределено), а в источнике содержат числа.
|
Результаты показали, что при фиксированных 10 ключах в источнике время заполнения оставалось одинаковым независимо от количества ключей в приемнике (10, 100 или 500). Однако при увеличении количества ключей в источнике производительность заметно снижалась – с 500 ключами в источнике и всего 10 в приемнике время выполнения увеличилось в 6 раз.
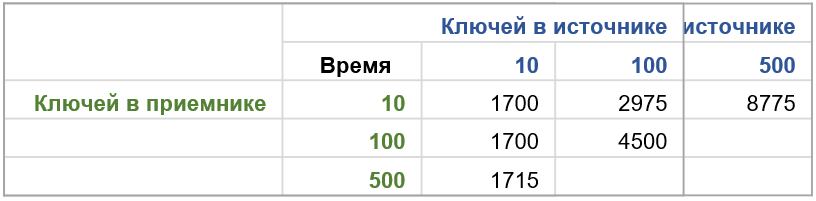
У функции «СтрЗаполнить» есть третий необязательный параметр – «СписокЗаполняемыхСвойств». Если указать в нем максимальное количество свойств приемника, то время будет одинаковым для любого размера источника. Однако это время будет больше, чем без использования третьего параметра.
|
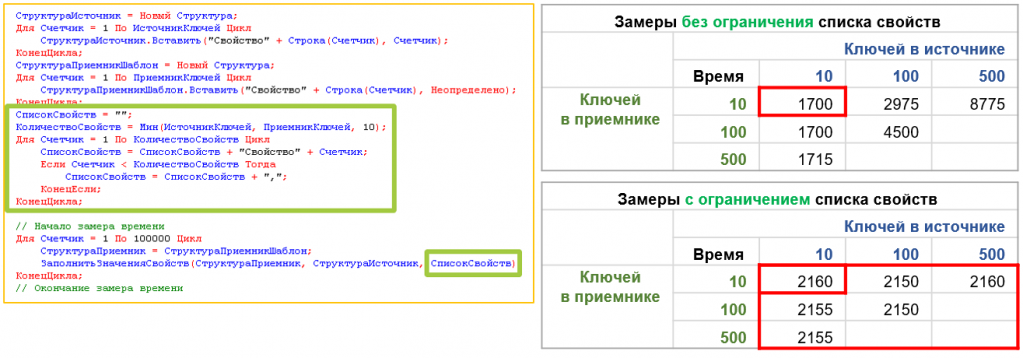
Миф считаем подтвержденным. Важно помнить: время работы функции значительно растет при увеличении числа свойств в источнике. Эту проблему можно решить с помощью третьего параметра «СписокЗаполняемыхСвойств». Однако его не рекомендуется применять, если количество ключей или свойств одинаковое, потому что это приведет к замедлению алгоритма.
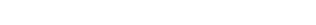
Скачивайте готовые доработки в Базе знаний Инфостарт
Приобретайте подписку и пользуйтесь готовыми решениями от сообщества Инфостарт
Миф 5. «ЗначениеЗаполнено()» работает медленнее, чем проверка на пустое значение определенного типа
Проверяли следующим образом: создали два цикла, в первом взяли заполненное значение (например, число 10) и пустое значение (число 0). Смотрели, за какое время выполняется этот цикл. Во втором цикле проверяли то же самое с помощью функции «ЗначениеЗаполнено()». После множества замеров установили, что функция «ЗначениеЗаполнено()» выполняется стабильно медленнее прямой проверки на 1.5-2%.
|
Технически миф подтвержден, но на практике мы продолжаем использовать «ЗначениеЗаполнено()» из-за ее универсальности, поскольку замедление незначительное. Дополнительно выяснилось: скорость проверки заполнения значений примитивных типов (строк, чисел) и скорость проверки заполнения ссылочных типов не различается, проверка на заполнение ссылки занимает столько же времени, сколько примитивный тип.
Миф 6. Для колонок таблицы значений необходимо указывать тип
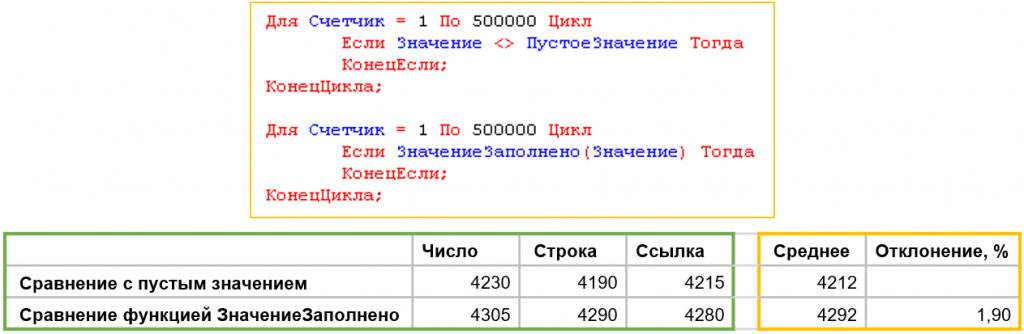
Операции сортировки и отборов должны работать медленнее без указания типов колонок, что кажется логичным. Для проверки мы создали две таблицы значений с колонками «Строка», «Число» и «Ссылка». Для второй таблицы были заданы типы значений для колонок.
|
Обе таблицы заполнили идентичными данными из базы: строковые значения в колонку «Строка», числа в «Число», ссылочные значения в «Ссылка».
|
Результат показал абсолютно одинаковое время выполнения операций.

Таким образом, миф не подтвердился: указание типов колонок не влияет на скорость обработки данных. Однако в процессе мы обнаружили важную особенность. Ниже представлен изначальный код:
|
Мы попробовали в таблицы записать значение несоответствующего типа: в колонку «Строка» первой таблицы положили число, в колонку «Число» – ссылку, в колонку «Ссылка» добавили строку.
Результат:
-
В таблице №1 (где типы не заданы) данные сохранялись без преобразований.
-
В таблице №2 с заданными типами происходило автоматическое преобразование: строка в числовой колонке конвертировалась в число, число автоматически становилось строкой, ссылочные типы никак не преобразовывались.
Хотя указание типов колонок не ускоряет операции, они дают важное свойство: обеспечивают контроль данных через автоматическое приведение значений.
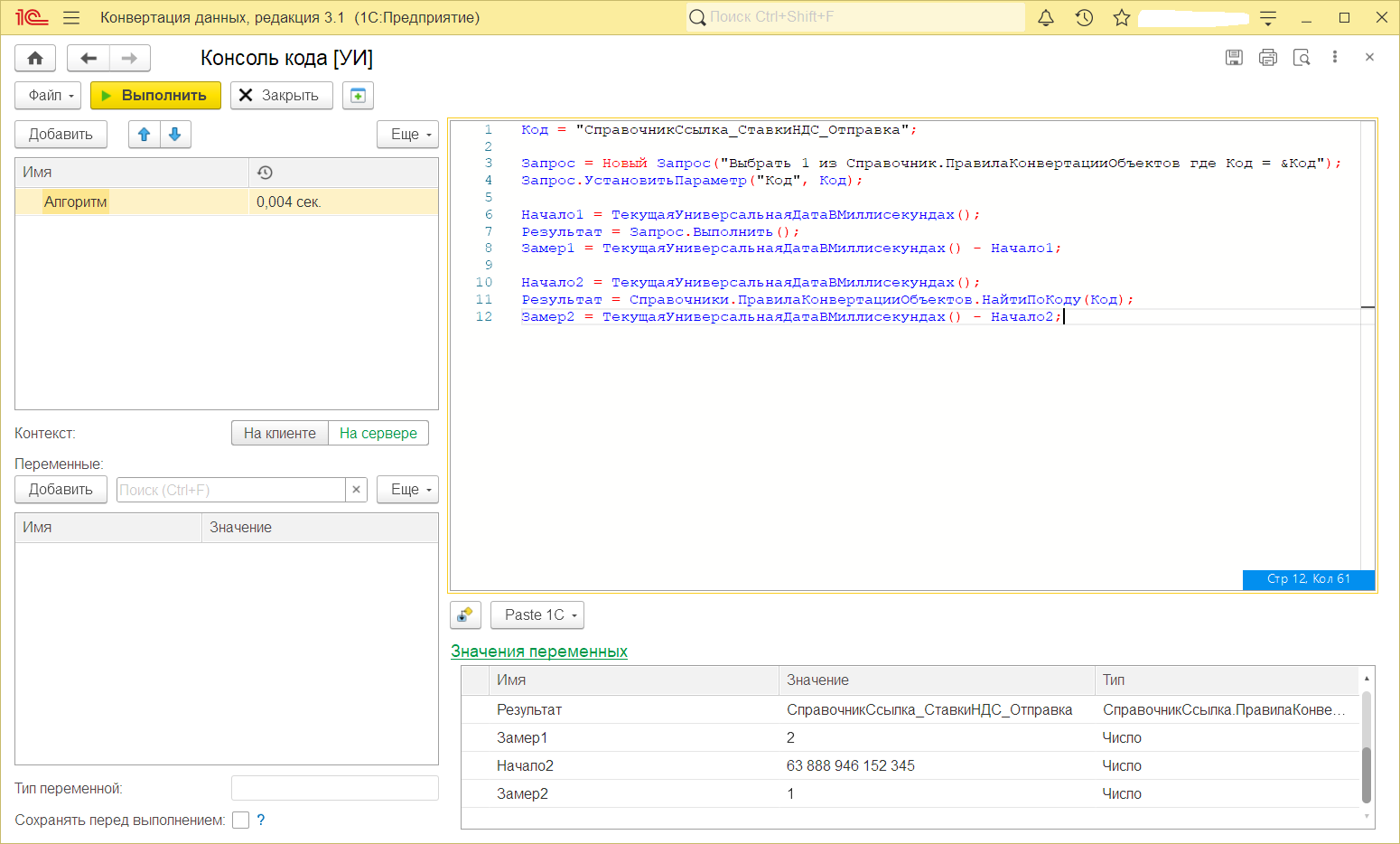
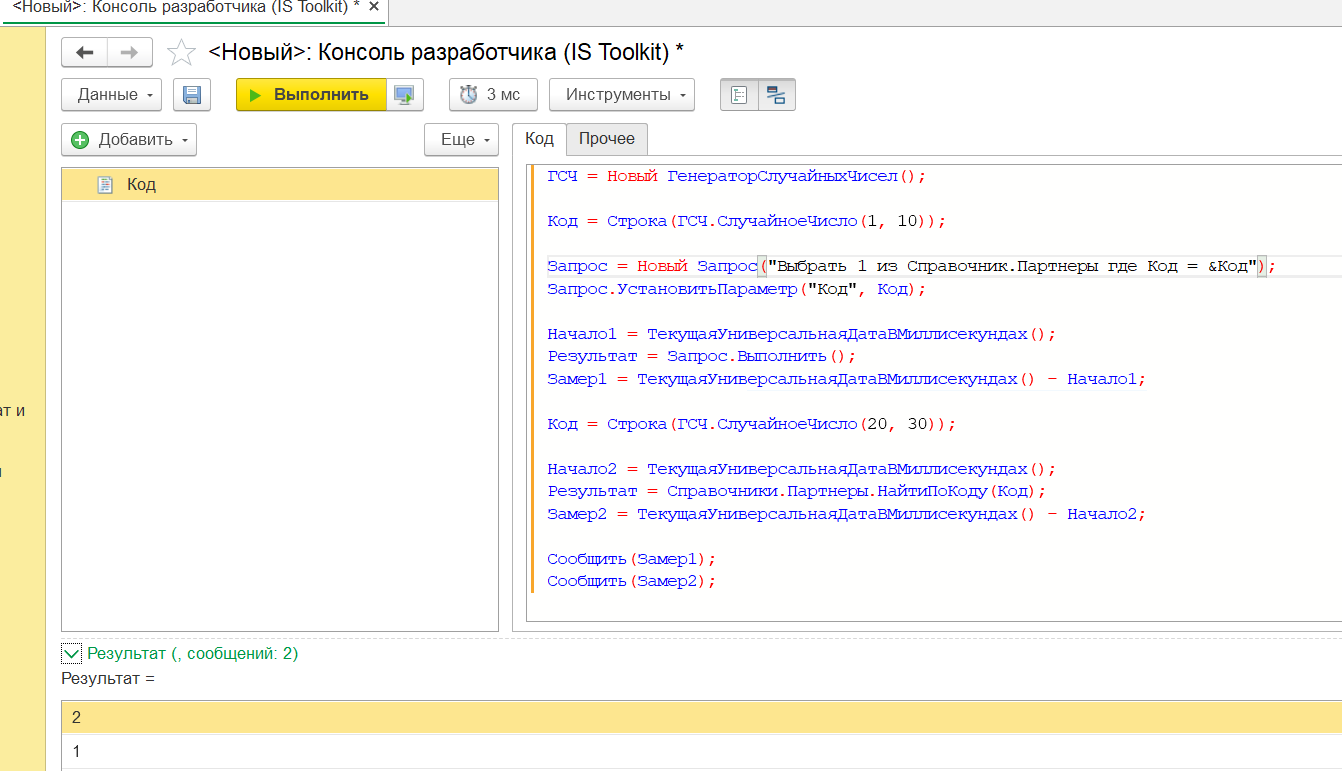
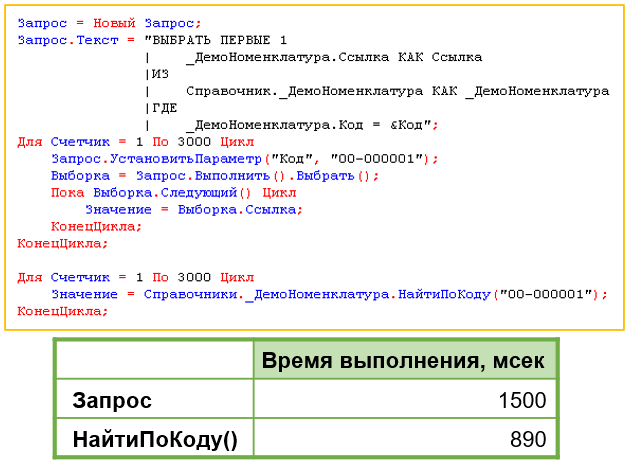
Миф 7. Запрос эффективнее, чем «НайтиПоКоду()»
Существует мнение, что получение ссылки на элемент с помощью запроса будет выполняться быстрее, чем с помощью функции «НайтиПоКоду()», особенно учитывая, что везде рекомендуется использовать запросы. Действительно, в практике в текстах модулей много мест, где используется запрос для получения ссылок.
Для проверки мы реализовали функционал поиска элемента с кодом «00001» двумя способами: через запрос и с помощью функции «НайтиПоКоду()». Результат оказался не в пользу запроса.
|

У нас возникла гипотеза: возможно, само конструирование запроса в цикле отнимает много времени? Мы попробовали вынести конструктор запроса за пределы цикла, а внутри цикла только устанавливать параметр запроса. Да, это дало эффект ускорения, но все равно производительность запроса не превысила производительность функции «НайтиПоКоду()».
|
На сайте its.1c.ru указано, что с точки зрения поиска объектов нет существенных отличий в реализации этих методов на уровне платформы. Методы менеджеров объектов удобны тем, что позволяют одной строкой произвести поиск. Для себя мы отмечаем, что конструктор запроса – более ресурсоемкая операция. Есть и положительный момент: конструктор запроса можно кэшировать, что дает ускорение в определенных сценариях использования.
Миф 8. Выборка из результата запроса эффективнее, чем выгрузка в таблицу значений
Часто озвучивается тезис: «Никогда не выгружайте результат запроса в таблицу значений, всегда используйте выборку». Для его проверки мы выполнили идентичный предыдущему тест двумя способами: в первом случае обошли результат запроса через выборку, во втором – выгрузили данные в таблицу значений. Результат показал, что выборка действительно эффективнее выгрузки в таблицу значений, причем разница существенная и заметная. Миф подтвержден.
|
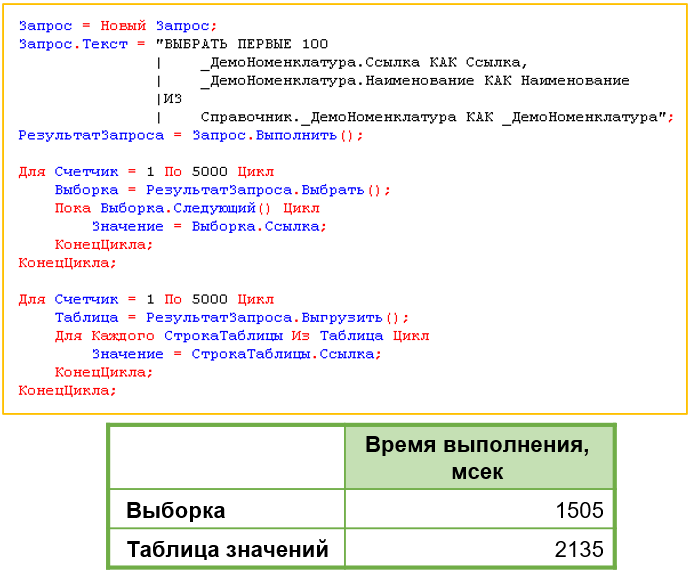
Важное уточнение: согласно документации its.1c.ru при выполнении запроса вся считанная информация сразу передается на клиент и размещается в оперативной памяти (аналогия с «арбузами»). Выборка предпочтительнее, поскольку позволяет считывать данные порциями. Однако обратите внимание: в документации its.1c.ru речь идет не о выборке из результата запроса, а о выборке через менеджер объектов (например, Справочник.Номенклатура.Выбрать()). Именно такая выборка работает порционно. Результат обычного запроса всегда загружается в память целиком. Тем не менее, выборка из результата запроса остается быстрее выгрузки в таблицу значений.
Миф 9. СКД медленнее запроса
Для проверки сравнили два подхода:
-
Выборка 100 элементов справочника «Номенклатура» через Систему компоновки данных (СКД);
-
Та же выборка через запрос.
|
Результат оказался категорически не в пользу СКД – запрос выполнился более чем в 10 раз быстрее. Миф подтвержден.

Однако отказываться от СКД не стоит: во многих случаях она предоставляет возможности, которые через запросы реализовать значительно сложнее или вовсе невозможно.
Миф 10. Обработка коллекции объектов в транзакции выполняется быстрее, чем без транзакции
Проверяли на выборке элементов справочника «Номенклатура»: модифицировали комментарии и записывали изменения дважды – с транзакцией и без нее. Результат показал, что обработка в транзакции действительно выполняется быстрее. Миф подтвержден.
|

За счет чего это происходит? Основной эффект транзакций при создании/изменении/удалении данных – замена множества мелких операций с файловой системой на одну крупную. Вместо 100 отдельных обращений к файловой системе с записью элементов выполняется одна групповая операция. Однако важно помнить: применение транзакции – это тоже лишний алгоритм (аналогично конструктору запроса). Объявление транзакции отнимает время. При слишком малом объеме данных эффект нивелируется, а при чрезмерно большом – получится, что парней раздавило арбузами. Поэтому для каждой задачи необходимо подбирать оптимальный размер порции данных для одной транзакции.
Миф 11: Файловая база медленнее клиент-серверной
Проверяли на ненагруженном компьютере в идентичных условиях (стандартные настройки сервера и платформы). Код из мифа №10 запускали параллельно в файловой и клиент-серверной базе. Результат: файловая база работала заметно быстрее.
|
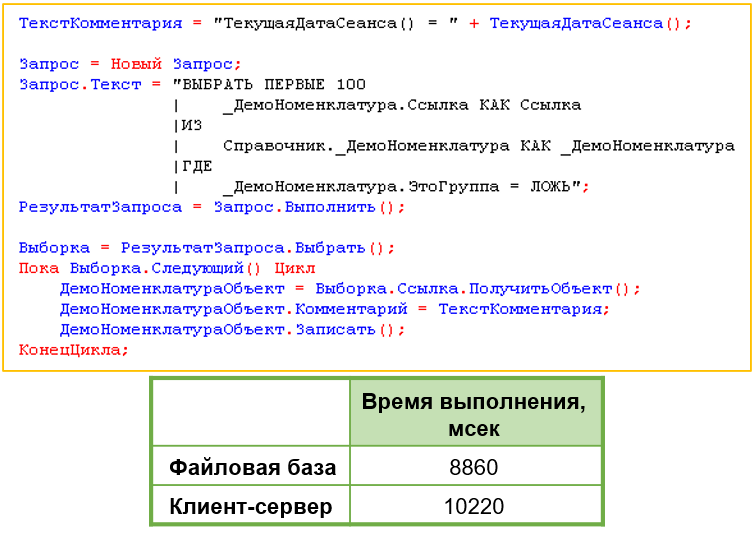
Дополнительная проверка по предыдущим мифам показала стабильное преимущество файловой базы, кроме мифа №6 – клиент-серверный вариант там всегда был быстрее.
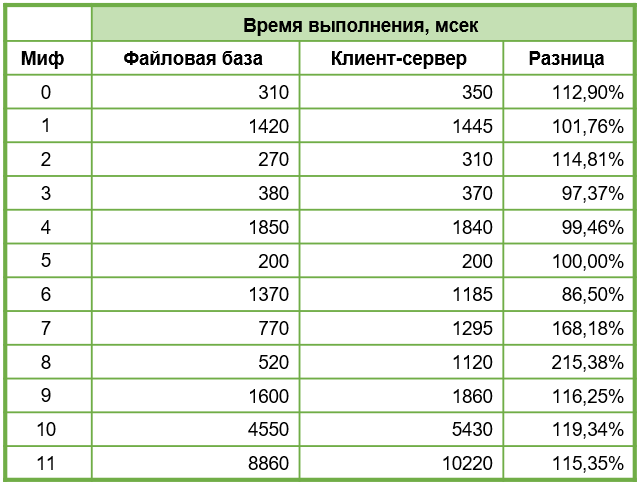
Миф не подтвержден, но с оговорками. Клиент-серверный вариант подразумевает выполнение дополнительных действий на пути данных из базы к пользователю Устанавливается дополнительное программное обеспечение. Это замедляет время работы клиент-серверной базы. Но в то же время данное ПО ускоряет клиент-серверный вариант. Все зависит от условия использования.
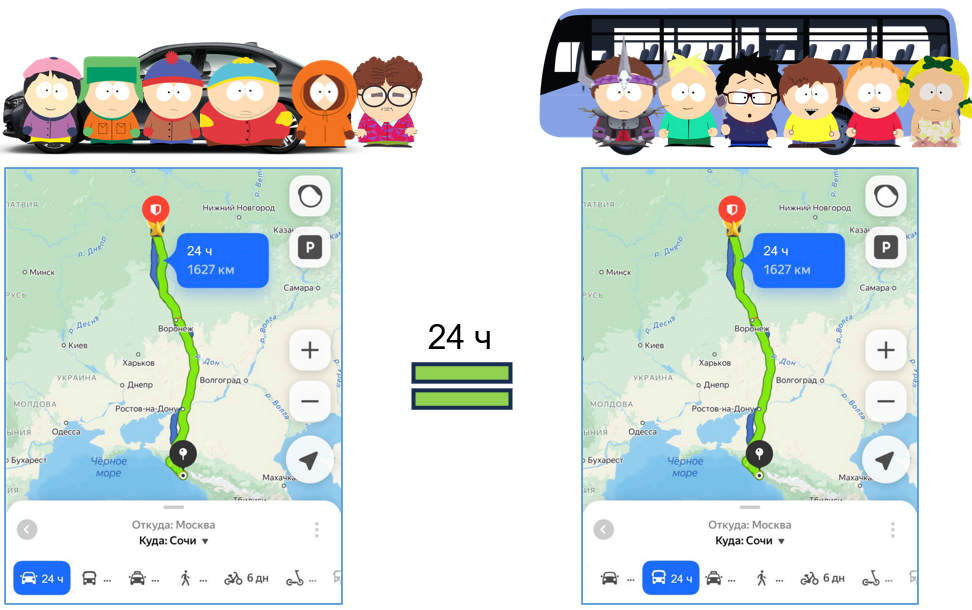
Вернемся к нашей метафоре с парнями. На этот раз группа друзей планирует поездку на юг. Представим, что легковая машина – это файловая база данных. Автобус же символизирует клиент-серверный вариант, который изначально предназначен для одновременной работы большого количества пользователей. Однако, когда в поездке участвуют всего два человека, автобус вынужден везти все свое лишнее железо (дополнительное ПО) независимо от необходимости в нем. Поэтому парни в машине, прокладывая маршрут, радостно замечают: «О, класс, мы доедем за 20 часов!». Парни в автобусе, выполнив те же расчеты, констатируют: «Мы доедем за 24 часа». В итоге обе группы благополучно прибывают на место, и у всех все складывается отлично.
Через год условия немного меняются: теперь в каждой группе по четыре человека. Парни в легковой машине (файловой базе) по-прежнему добираются за 20 часов. Группа в автобусе (клиент-сервер) – также за 24 часа.
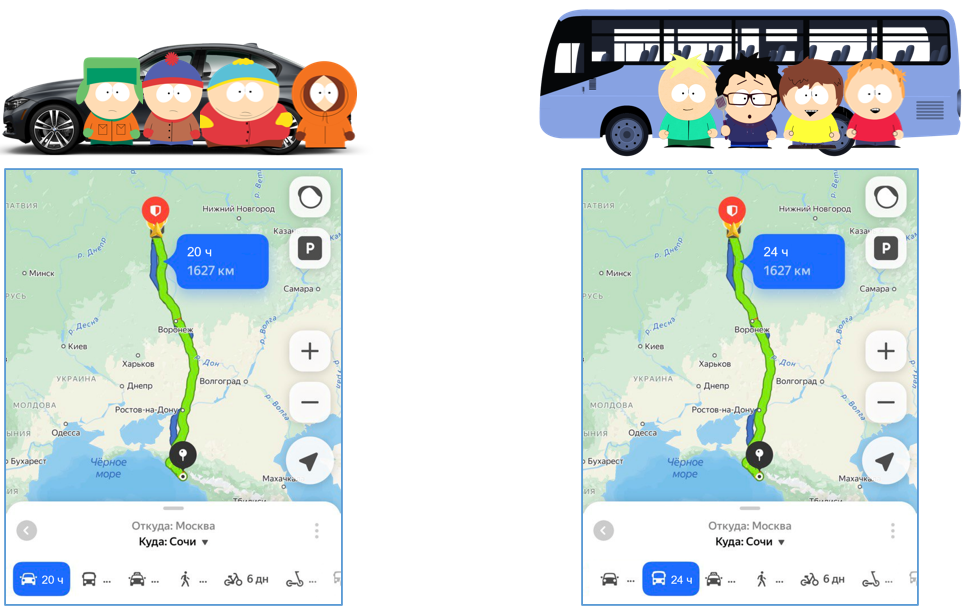
Но у каждой системы есть свой предел возможностей. Этот предел проявляется при шестерых участниках. Шесть человек в машине начинают толкаться локтями, им становится тесно и некомфортно. Один из пассажиров говорит: «Ребята, срочно нужно остановиться – требуется перепровести документы». Пока он выполняет эту задачу, остальные вынуждены бездействовать. В результате обе группы прибывают одновременно – за 24 часа. Но уже заметна разница в комфорте: в автобусе просторно, а в машине – крайне тесно.
Теперь представим, что в базе одновременно работает 50 пользователей. Парни в автобусе спокойно рассаживаются по местам и без проблем продолжают путь. А вот группа в легковой машине (файловой базе) сталкивается с катастрофической ситуацией.
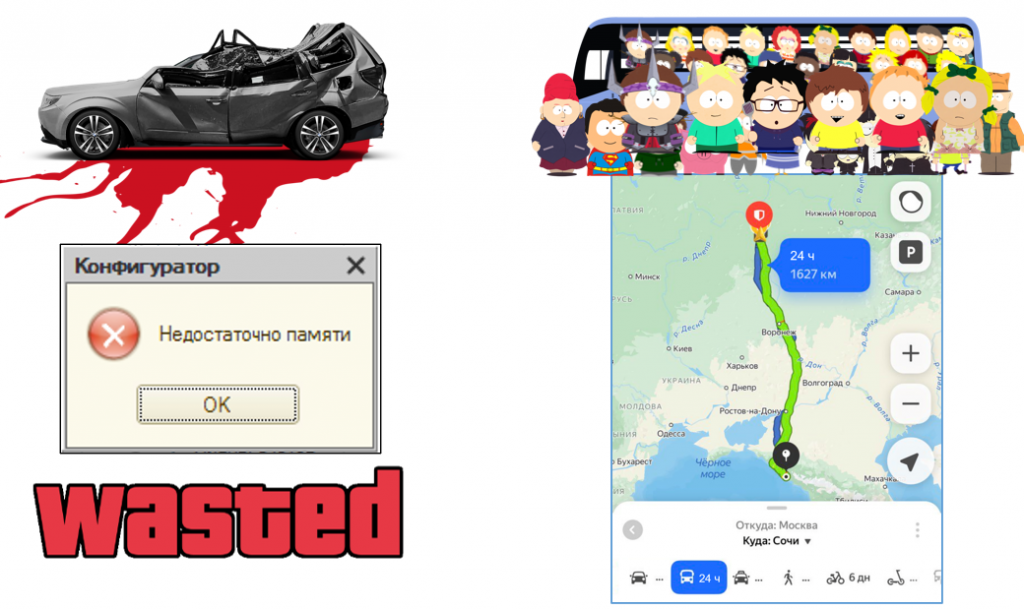
Впечатлительные могут не волноваться: красная жидкость на изображении – это антифриз, ни один человек не пострадал.
Поэтому, если вам объективно не требуется клиент-сервер и вы от него не зависите (например, у вас всего три постоянных пользователя) – смело работайте в файловой базе. Безусловно, у клиент-серверного решения есть определенные преимущества, но не стоит его внедрять, когда в нем нет реальной необходимости. Мы же не ездим по городу на автобусе каждый день.
Миф 12. Внешние обработки медленнее встроенных
Проверяли на примере тестовой внешней обработки: сначала запустили ее через «Файл ? Открыть», затем встроили в конфигурацию. Выполнили идентичный код для внешней и встроенной версий. Результат показал, что внешние обработки работают медленнее встроенных. Миф подтвержден.
|

Этот факт также официально признан компанией 1С. Причина в компиляции: модуль, встроенный в конфигурацию, компилируется однократно при инициализации для всех пользователей (точный уровень – серверный или процессный – не уточняется). Мы тестировали только время выполнения для одного пользователя. Кроме времени выполнения, есть также показатель – загрузка процессора. Компания 1С проводила замеры в условиях, приближенных к реальным: время выполнения увеличивается в 1,5 раза (~59%), а загрузка процессора – почти в 2,5 раза. Поэтому не рекомендуется выносить во внешние обработки функционал, активно используемый многими пользователями или вызываемый очень часто.
Миф 13. Вызов функции «&НаСервере» из функции «&НаСервере» инициирует вызов сервера
Некоторые полагают, что вызов серверной функции из другой серверной функции увеличивает счетчик вызовов сервера. Проверили с помощью кода: количество вызовов сервера действительно не увеличивается. Однако заметили, что при разбивке кода на две функции время выполнения возросло. Возможно, это связано с особенностями компиляции циклов платформой. Миф не подтвержден.
|
|
|
|
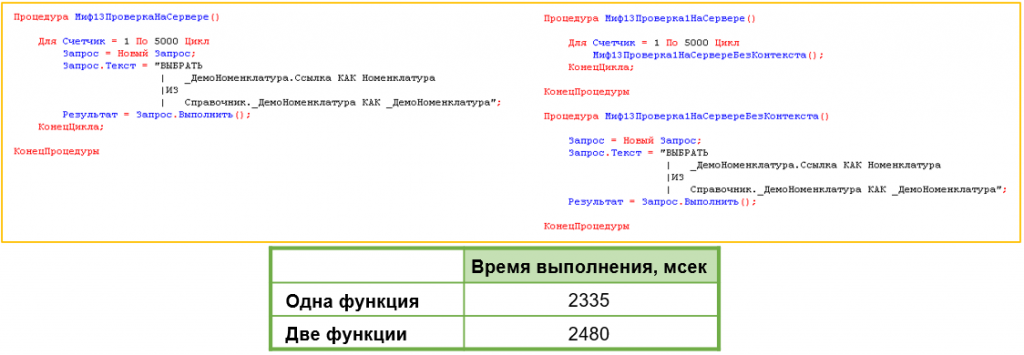
Вызов серверной функции из серверной функции не создает новый вызов сервера. Но функционально идентичный код, написанный в одной функции, может выполняться быстрее, чем разбитый на несколько функций.
Миф 14. Получение представления объекта в запросе замедляет его выполнение
Использование свойства «Представление» или функции «Представление()» вместо объекта «Наименование» замедляет запрос. Проверили с помощью четырех идентичных циклов:
-
Выбор ссылки;
-
Выбор «Наименование»;
-
Выбор «Представление»;
-
Выбор через «Представление()».
Результат: использование свойства «Представление» незначительно замедляет запрос по сравнению с «Наименование», а функция «Представление()» – значительно. Миф подтвержден.
|

Эксперименты показывают, что ручное формирование представления путем конкатенации разных полей с данными объекта иногда вдвое быстрее использования встроенного свойства или функции.
Миф 15. Использование представления объектов в коде замедляет его выполнение
К предыдущему тесту добавили выгрузку результата запроса в таблицу значений. Результат: использование «Представление» потребовало в десятки раз больше времени. Миф подтвержден.
|

Согласно its.1c.ru:
-
Для выборки данных предпочтительнее «Наименование» (если не требуется расшифровка);
-
При выводе в табличный документ происходит замедление работы системы в десятки раз из-за вызова менеджеров объектов (включая возможные переопределения «Представления()»);
-
Аналогичный эффект наблюдается для объектов «ТаблицаЗначений» и «ДеревоЗначений».
Как только вы выгружаете представление из запроса в таблицу значений, операция потребует непропорционально много времени.
Скачивайте проверенные решения в Базе знаний и экономьте время на доработках
*************
Статья написана по итогам доклада (видео), прочитанного на конференции INFOSTART TECH EVENT.

Вступайте в нашу телеграмм-группу Инфостарт