В то время как разработчики на других языках активно используют инструменты тестирования, в 1С часто полагаются на пользователей для выявления ошибок. В результате новые релизы нередко содержат множество багов, которые приходится оперативно исправлять. Иногда пользователям даже приходится доказывать, что это именно ошибка, а не задуманная функциональность.

Однако ситуация меняется, в том числе и в мире 1С. Многие компании уже внедряют технологии тестирования, давно используемые в других стеках. Тем не менее, фокус на качество релизов, на мой взгляд, пока еще не сформирован.
3 подхода к работе с ошибками
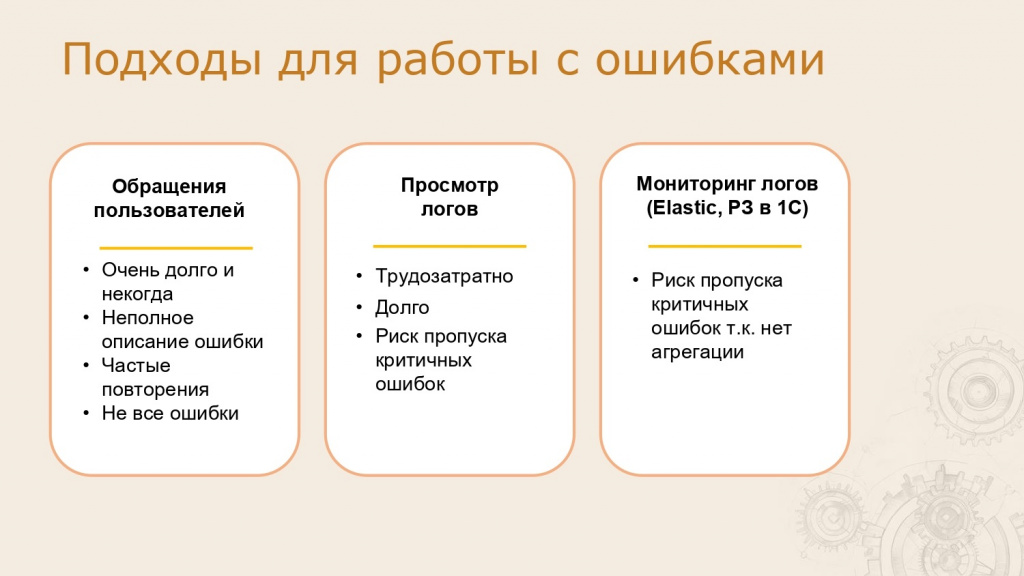
Первый и самый распространенный подход — обратная связь от пользователей. Мы ждем, пока пользователи сообщат об ошибке, после чего начинаем ее исправлять. Обычно для этого создаются отделы поддержки, которые взаимодействуют с пользователями. У этого подхода есть несколько существенных недостатков.
Во-первых, это долгий процесс. Между возникновением ошибки и моментом, когда она дойдет до разработчиков, может пройти значительное время, которое можно было бы использовать для оперативного исправления. Кроме того, в службах поддержки происходит сортировка и обработка обращений, часть из которых не связана с ошибками. Но даже те обращения, которые касаются разработки, проходят долгий путь, что также отнимает время.
Второй недостаток — неполное описание ошибок. Обычно пользователи присылают краткое сообщение, и нам приходится уточнять детали: что именно произошло, какие действия выполнялись и так далее. Либо анализировать логи, что также требует времени.
Еще одна проблема — массовые инциденты, когда множество пользователей одновременно сталкиваются с одной и той же ошибкой. Они начинают писать в поддержку, обращаться к разработчикам, что отвлекает от решения проблемы и замедляет процесс исправления.
Следующий подход — анализ логов. На одном из проектов пять лет назад мы осознали необходимость быстрого реагирования на ошибки, так как даже небольшая проблема могла привести к значительным финансовым потерям. Время на исправление в таких случаях исчисляется минутами. Тогда мы начали регулярно анализировать логи, в первую очередь — журнал регистрации.
Однако этот процесс крайне трудоемок: большой объем данных, множество повторяющихся ошибок, среди которых можно пропустить критичные. Кроме того, такой анализ занимает много времени.
Третий подход — автоматизированный мониторинг логов. Он предполагает использование скриптов или регламентных заданий, которые раз в несколько минут проверять журналы регистрации и отправляют уведомления разработчикам или аналитикам. Этот метод лучше, но имеет такие недостатки, как:
-
Сложность организации и управления,
-
Риск спама в почтовых ящиках из-за большого количества уведомлений.
Эти проблемы актуальны не только для 1С, но и для других языков программирования. Команда Sentry разработала продукт, который эффективно их решает. О нем я и хочу рассказать.
Что такое Sentry
Начну с определения. Sentry — это система для сбора и отслеживания событий, а также последующей отправки ошибок заинтересованным лицам.

Какими возможностями обладает Sentry
Первая возможность — это агрегация ошибок. Если вы обратили внимание, в определении упоминаются два ключевых понятия: событие и ошибка. В нашем случае события — это записи в журнале регистрации, а Sentry агрегирует их, группируя в ошибки. Благодаря этому нам удобно отслеживать проблемы. Кроме того, в рамках каждой ошибки собирается дополнительная информация из связанных событий: количество затронутых пользователей, общее число событий и так далее.
Также Sentry обладает гибкой системой оповещений.
Какие виды оповещений поддерживаются
-
По новым ошибкам — это самый распространенный тип. Оповещение формируется в момент возникновения ошибки. Данный механизм используется во всех наших информационных системах.
-
При превышении порога по количеству ошибок — этот вид оповещения мы тоже активно применяем. О нем я расскажу подробнее далее в статье.
-
При превышении порога по числу затронутых пользователей — это помогает оперативно выявлять массовые проблемы и быстро на них реагировать.
Помимо этого, Sentry предоставляет широкие возможности для аналитики. В событиях можно указывать произвольные свойства (так называемые теги). Мы можем заполнять их при отправке ошибок в Sentry, а затем использовать для построения аналитических отчетов.
Какие инструменты интеграции есть в Sentry
REST API и различные SDK. Для 1С SDK недоступны, но REST API полностью покрывает наши потребности.
Sentry может интегрироваться с Jira, GitLab, Teams, Grafana и многими другими системами.
О режимах работы
Раньше был доступен SaaS-режим, но на данный момент эта возможность отсутствует. То есть подключение к провайдеру Sentry через HTTP-интерфейс и работа через браузер сейчас недоступны. На текущий момент доступ возможен только через VPN.
Также существует On-Premise-режим — когда Sentry разворачивается на собственных мощностях (например, на вашем сервере) и работает полностью автономно.
Лицензирование Sentry позволяет развернуть текущую версию на своих серверах. Для версий старше двух лет доступно даже размещение в виде SaaS-решения. Теперь любая компания может развернуть у себя Sentry и предоставлять доступ к нему через веб-интерфейс.
Знакомство с интерфейсом
Начнем с меню проекта. Каждый проект в Sentry соответствует отдельной информационной системе. На рисунке видно два проекта — это, по сути, две разные информационные базы.
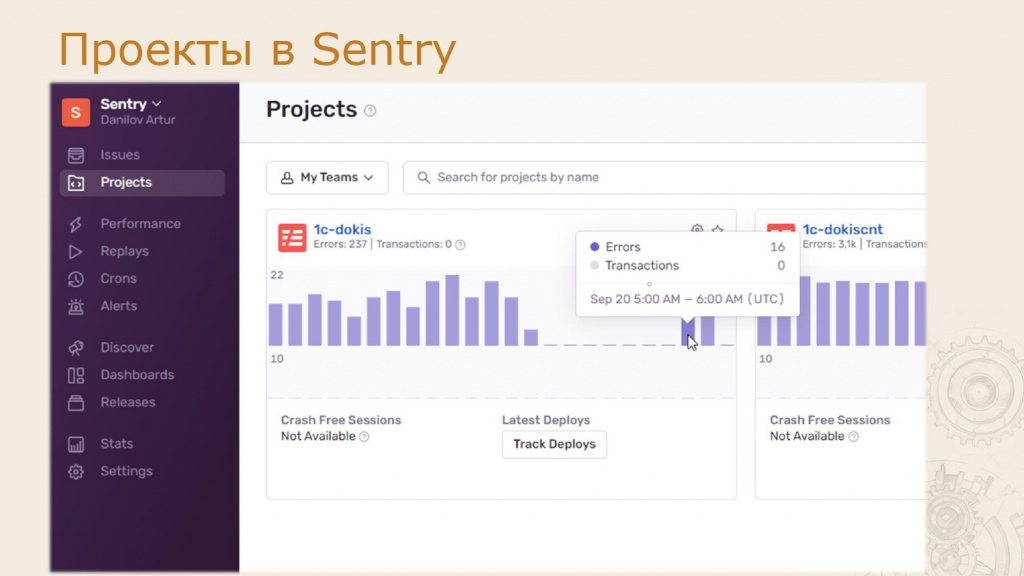
Здесь отображается дашборд с почасовой статистикой за сутки. Если навести курсор на столбец графика, можно увидеть, сколько ошибок произошло в конкретный час.
Также для проекта можно настраивать команды и группы. Это позволяет гибко настраивать оповещения и управлять правами доступа к просмотру ошибок.
Список ошибок
Здесь отображаются агрегированные события. Например, мы видим 47 событий, относящихся к одной ошибке. Возьмем верхнюю запись — “Изменение свойства УЦН”. Здесь указано, что ошибка возникла у семи пользователей. Также в этом интерфейсе можно назначить ответственного за исправление.
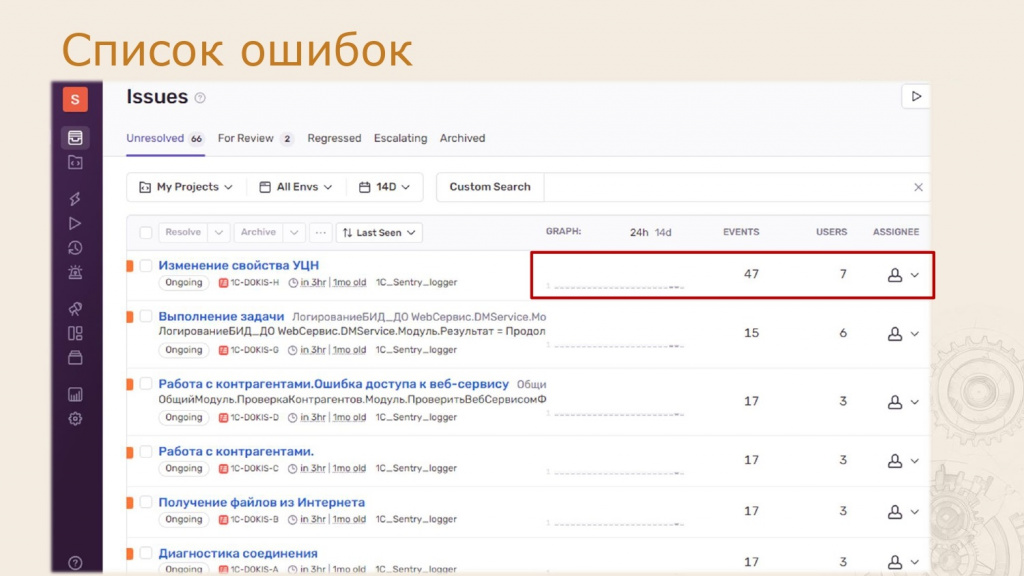
Если интегрировать Sentry, например, с Jira, можно синхронизировать статусы между системами. При закрытии задачи в одной системе она автоматически закроется и в другой.
Если открыть детали ошибки, мы увидим сообщение об ошибке (выделено красным) и произвольные теги. Эти теги можно настроить на этапе выгрузки событий из журнала регистрации.
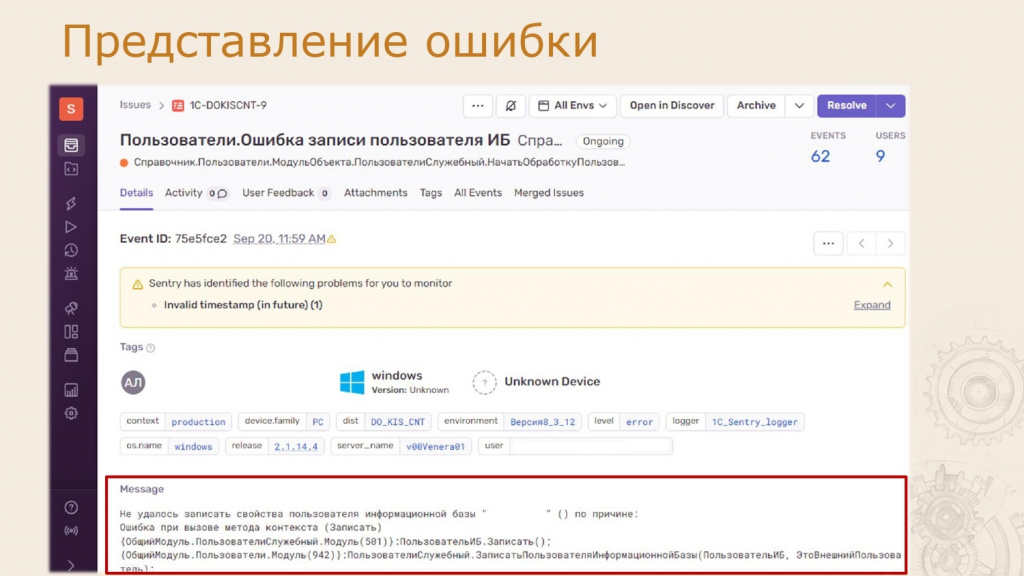
В нашем случае мы используем такие данные, как:
-
Номер релиза,
-
Сервер приложений,
-
Номер платформы,
-
Операционная система.
Sentry умеет группировать ошибки по двум критериям: стек вызовов и текст сообщения.
На рисунке видны индикаторы, показывающие степень схожести ошибок. Также есть возможность вручную исключить ошибку из группы.
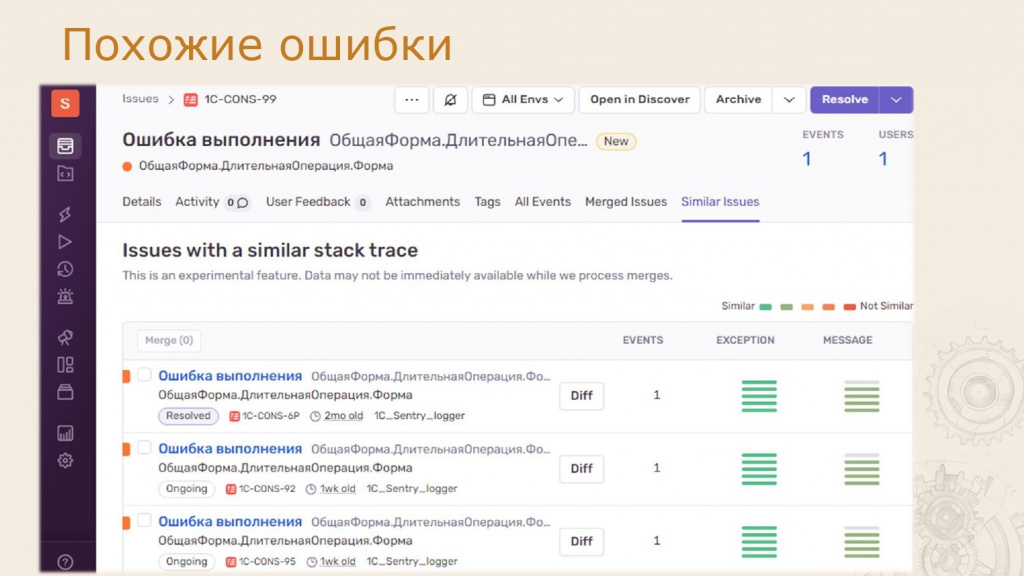
Кнопка Diff позволяет указать, что ошибка не относится к текущей. У нас был общий модуль с ошибкой, на который ссылались разные обработки. Исправив его, мы автоматически закрыли все связанные задачи. Это очень удобно.
Кроме того, Sentry предоставляет статистику по ошибкам в разрезе релизов. Здесь видно, сколько ошибок содержится в каждом релизе.
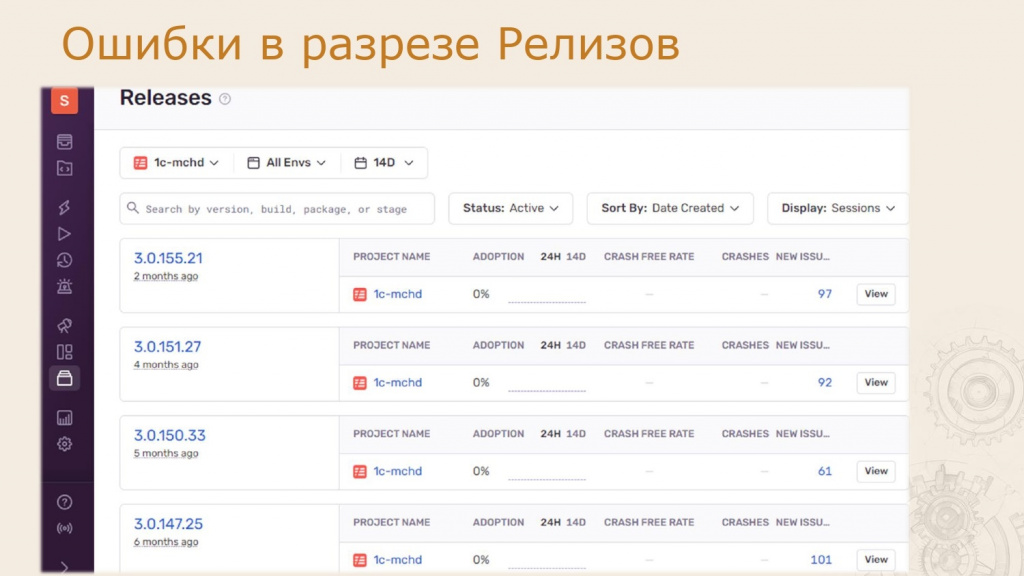
Сейчас активно развивается направление автоматических тестов, и эта статистика помогает оценить, насколько хорошо новые тесты покрывают наш код.
Сбор метрик производительности
Это еще одна интересная возможность Sentry. На экране проведения документа видно, что он состоит из нескольких частей. Здесь отображается стек вызовов, который показывает, сколько времени заняло выполнение каждого этапа транзакции. Это позволяет легко находить узкие места в производительности.
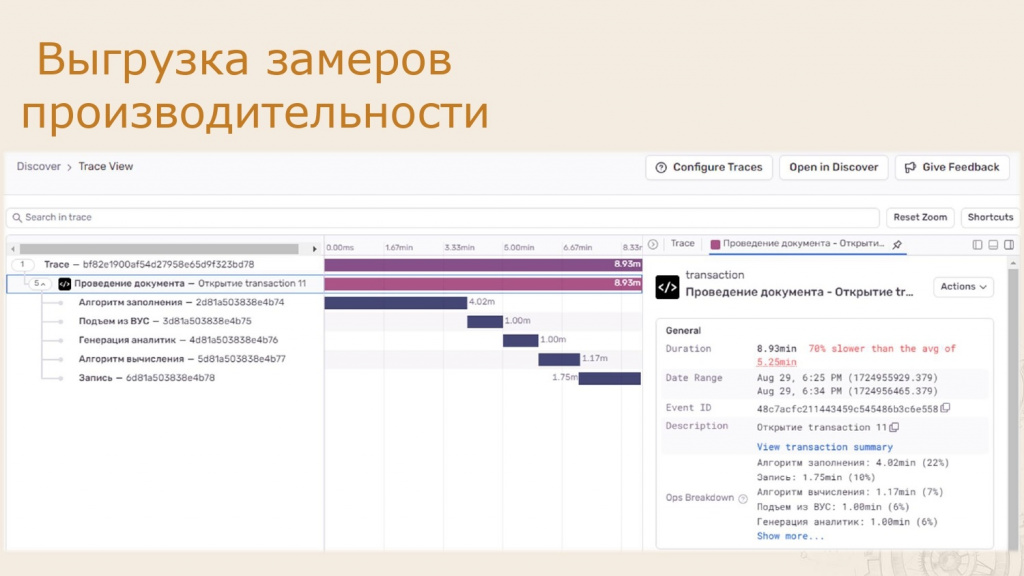
Данные загружаются из стандартного реестра замеров производительности и легко интегрируются в Sentry. Часто подобные метрики выгружают в Prometheus, но Sentry предлагает более широкий функционал, включая детализированный стек вызовов, который, например, недоступен в Prometheus.
Критически важные функции и алертинг
Мы также используем Sentry для мониторинга критически важных функций — тех, на которые нужно реагировать максимально оперативно.
Sentry предоставляет мощный инструмент для настройки алертинга.

Поделюсь нашими настройками, которыми позволяют минимизировать количество уведомлений и писем для разработчиков:
-
Оповещение о новой ошибке
-
Применяется во всех проектах: как только создается проект, настраивается это правило.
-
Срабатывает при появлении нового типа ошибки.
-
-
Регрессии исправленных ошибок
-
Ошибку можно вручную пометить как исправленную. Если она возникает снова, Sentry уведомляет о регрессии.
-
Мы автоматизировали этот процесс: через заданное время ошибка помечается как исправленная. Если она повторяется — приходит новое оповещение. Это помогает не упускать из виду важные проблемы.
-
Оповещения по количеству событий
Это второй вид оповещения, который мы используем. На нем я хотел бы остановиться подробнее.
У нас есть информационная система — МЧД (машиночитаемая доверенность). Она обменивается данными с провайдерами через HTTP-сервисы по различным шинам. Иногда от провайдера может прийти ошибка, на которую мы не можем повлиять, но обязаны ее обрабатывать.
Если такие ошибки происходят редко, это считается нормальным поведением системы, и оповещать разработчиков не требуется. Но тогда возникает вопрос: как отличить штатную работу системы от сбоя, когда обмен данными нарушен и нужно срочно уведомить ответственных?
Для этого мы как раз и используем оповещение по количеству событий. Мы установили суточный порог: если за день приходит более 100 сообщений об ошибках, система генерирует оповещение.
В этом виде оповещения предусмотрено три порога:
-
Критический
-
Предупреждение
-
Нормальный (все в порядке)
Для каждого порога можно настроить разных получателей, что сокращает количество уведомлений для конкретных сотрудников.
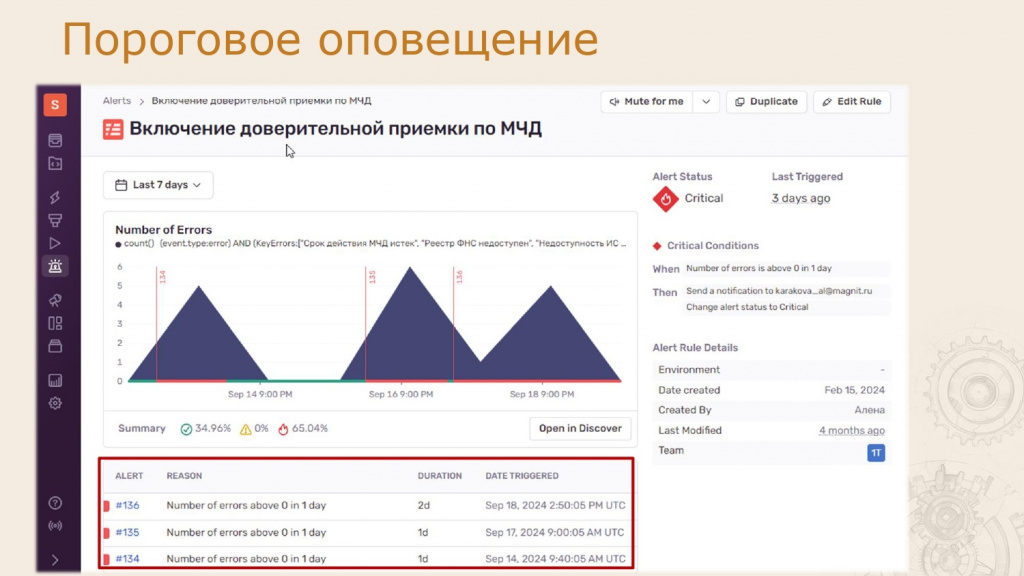
На рисунке показан другой вариант оповещения по количеству событий — с порогом в ноль. Это значит, что даже одно событие в день запускает уведомление.
Справа вы видите текущий статус — «Критично» (сработал критический порог). Красным выделены периоды срабатывания, а внизу отображаются все отправленные оповещения с датами.
Оповещение, которое приходит на почту, содержит краткое описание ошибки и ссылки для перехода в Sentry.
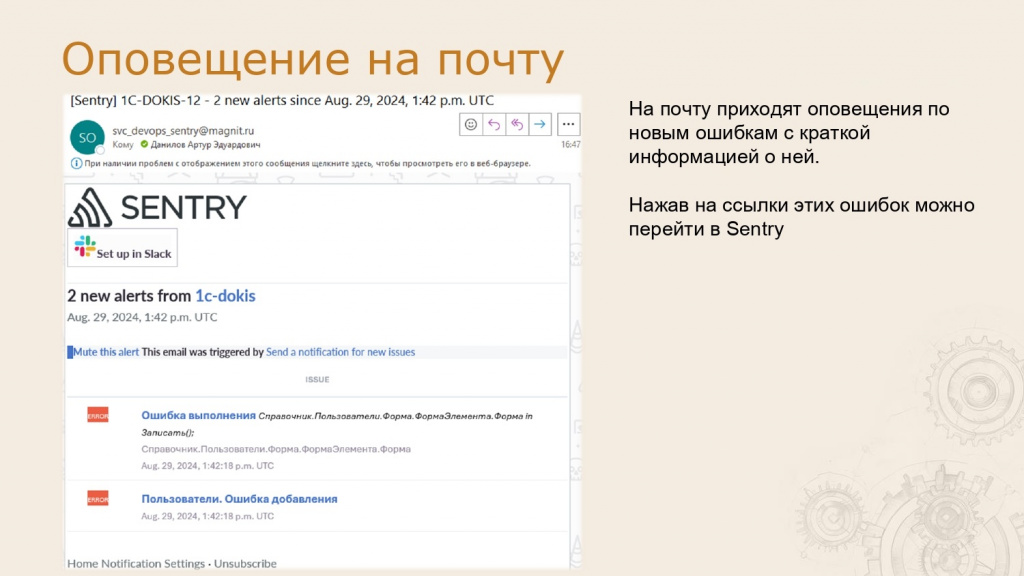
Sentry полезно использовать не только в продуктивной среде, но и в тестовой. Это упрощает работу аналитиков и тестировщиков — они могут оставлять комментарии и рекомендации прямо в системе. Разработчик, открывая ошибку, сразу видит всю информацию.
С какими системами и сервисами может взаимодействовать Sentry
На рисунке перечислены сервисы, с которыми работает Sentry.

Эти сервисы предназначены в первую очередь для оповещений — через них отправляются уведомления. Однако Sentry может интегрироваться не только с сервисами оповещений.
В качестве пилотного проекта мы решили подключить Sentry к Telegram. Для этого использовали Webhook: написали небольшой сервис на Python, который принимал данные от Sentry через Webhook, преобразовывал их в нужный формат и отправлял в Telegram.
Система работала вполне стабильно, но для наших задач почтовых уведомлений оказалось достаточно, поэтому интеграцию с Telegram пока не используем.
Более полезными оказались интеграции Sentry с GitLab и GitHub. Они позволяют:
-
Связать код в репозитории с ошибками в Sentry,
-
Анализировать статистику по коммитам,
-
Автоматически закрывать ошибки при коммитах,
-
Создавать прямые ссылки из Sentry в репозиторий, чтобы быстро перейти к проблемному участку кода,
-
Автоматически определять автора ошибки.
Таким образом, эти интеграции значительно расширяют возможности Sentry для работы с кодом.
Интеграция с Grafana
Еще одна интеграция, о которой стоит упомянуть. Она позволяет сопоставлять ошибки из Sentry с данными из других источников, например, с ошибками, связанными с оборудованием. Благодаря этому можно определить, влияет ли состояние железа на ошибки в Sentry.
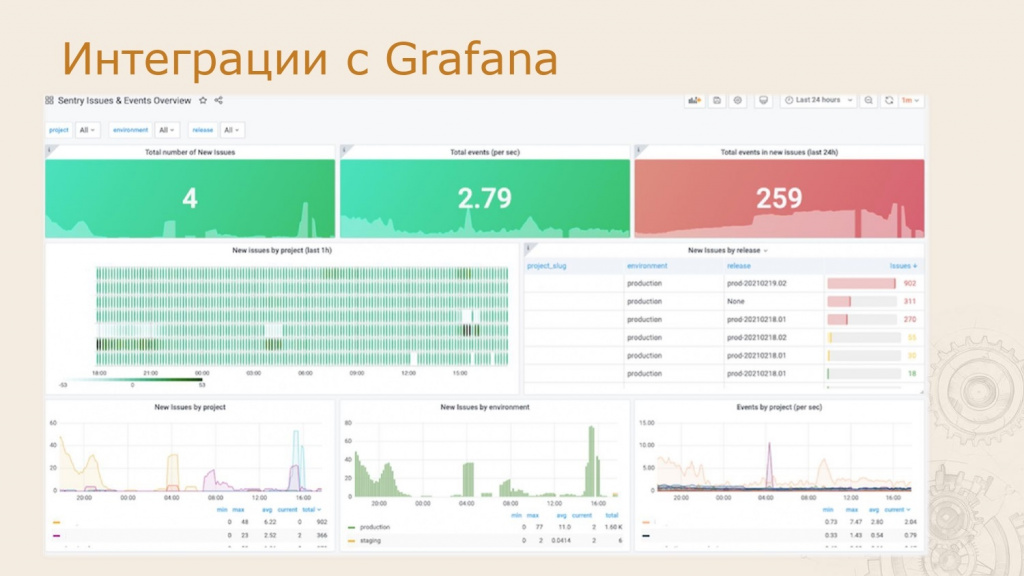
На рисунке вы видите стандартный дашборд Grafana.
-
Вариант интеграции через Prometheus
-
Данные экспортируются в Grafana, что упрощает настройку интерфейса, так как Grafana из коробки предоставляет множество инструментов для визуализации.
-
Настройка занимает считанные минуты.
-
-
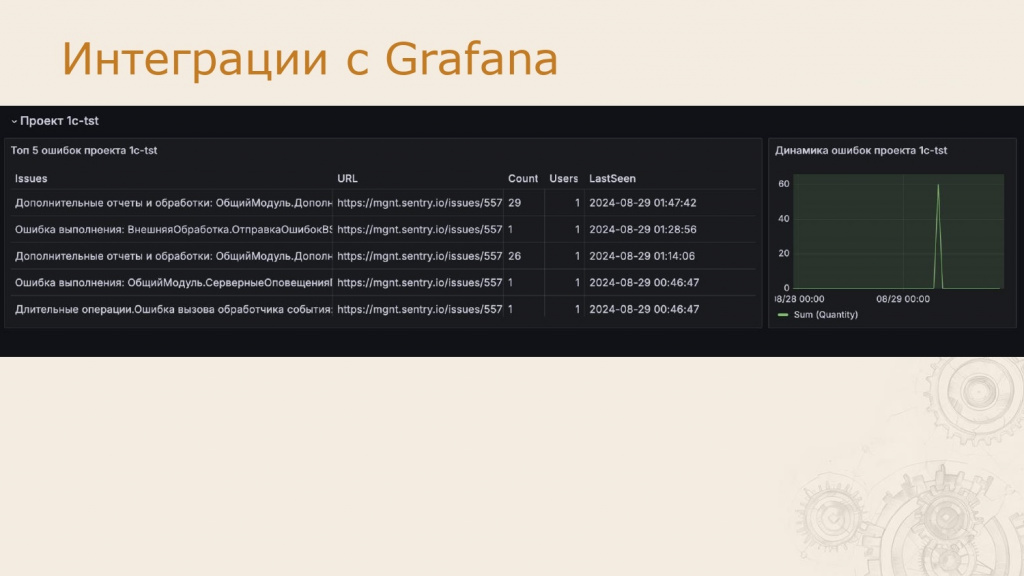
Вариант интеграции через DataSource-плагины (напрямую из Sentry)
-
В этом случае данные менее детализированы: есть ограничения по количеству событий, а интерфейс приходится настраивать вручную.
-
Для примера мы создали такой дашборд — видно, что информации здесь меньше, интерфейс проще, но функционал работает.
-
Статистика и требования к серверу
Это данные по одной из наших информационных систем:
-
13 млн событий за 14 дней,
-
1,5 млн событий в час (пиковая нагрузка),
-
968 оповещений за весь период.
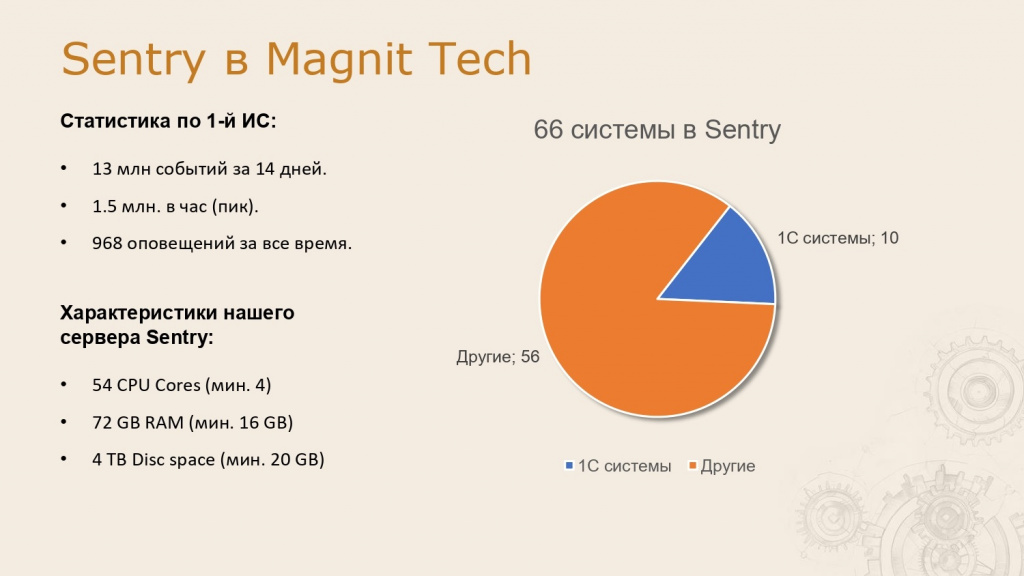
Сейчас в системе зарегистрировано 66 информационных систем, из них 10 — 1С.
Возникает вопрос: какие ресурсы необходимы для такой нагрузки? Приведу наши текущие характеристики сервера (в скобках — минимальные рекомендуемые значения от Sentry):
-
54 ядра CPU (мин. 4),
-
72 ГБ ОЗУ (мин. 16 ГБ),
-
4 ТБ свободного дискового пространства (мин. 20 ГБ).
При этом основную нагрузку создают не системы 1С, а другие сервисы, выгружающие транзакции.
Какие варианты интеграции с Sentry можно выделить
Первый вариант — отправка ошибки непосредственно при ее возникновении из кода 1С.
Для этого необходимо найти все места в коде, где могут возникать ошибки, и добавить в них вызов метода отправки данных в Sentry. Однако это довольно трудоемкая задача, так как требует значительных изменений в конфигурации.

Преимущества этого подхода: мгновенная отправка ошибок в Sentry сразу после их возникновения, а также возможность дополнить сообщение пользовательскими данными — например, вывести диалоговое окно, где пользователь может описать свои действия, что повысит информативность ошибки.
Недостаток — не все ошибки обрабатываются автоматически. Например, можно использовать обработчик из модуля приложения (доступен с версии 8.3.17), но он перехватывает только необработанные исключения.
Второй вариант — отправка ошибок из внешних источников, таких как логи, технологический журнал.
У этого подхода есть проблемы:
-
Неполное покрытие — например, технологический журнал содержит не все ошибки.
-
Задержка в обработке: данные сначала выгружаются в промежуточное хранилище (например, Elastic), а затем отправляются в Sentry.
-
Дополнительные накладные расходы на выгрузку и обработку данных.
Третий вариант (который мы выбрали) — отправка ошибок из журнала регистрации 1С. Он покрывает все ошибки, так как журнал регистрации фиксирует все возникающие проблемы.
Его особенность в том, что не все события в журнале являются критическими ошибками (например, статусы обменов или информационные сообщения). Нужно либо выгружать такие события в отдельный сервис Sentry, чтобы не перегружать разработчиков, либо понижать уровень записи в журнале (например, отмечать их как Информация вместо Ошибка), исключая их из выгрузки в Sentry.
Проблемы качества прикладных данных. Существуют также проблемы, связанные с качеством прикладных данных. Например, в некоторых обменах могут частично отсутствовать реквизиты документов. Это происходит не из-за ошибок в коде, а из-за нехватки самих данных. Такая информация обычно не представляет интереса для разработчиков.
Эти данные можно либо выгружать в отдельный контур как самостоятельный проект для аналитиков, либо понижать статус записей в журнале регистрации.
Проблемы связи с внешними ресурсами. Еще одна категория проблем — взаимодействие с внешними ресурсами, например, HTTP-запросы (как упоминалось в МЧД). В данном случае мы решили вопрос через систему оповещений, но альтернативным решением может быть понижение уровня журналирования.
Дополнительно стоит отметить некорректное заполнение полей журнала регистрации. При фиксации событий в журнале могут указываться различные константы: номера документов, реквизиты, пользователи и т. д. Это затрудняет группировку ошибок, из-за чего вместо одной сводной ошибки приходит множество уведомлений, что неудобно. Кроме того, это увеличивает объем журнала.
Какую интеграцию с Sentry мы используем
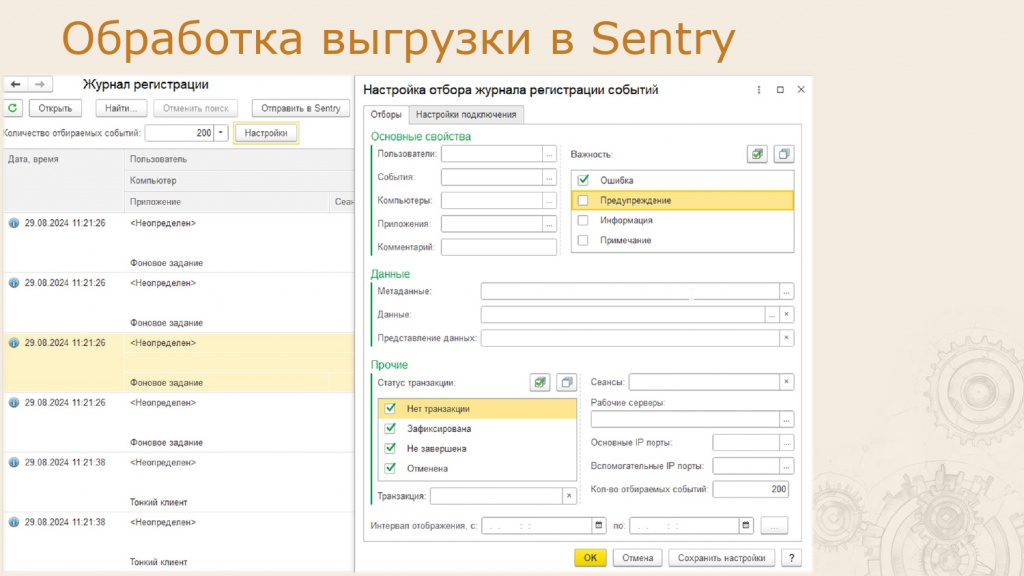
На основе типовой обработки просмотра журнала регистрации мы разработали собственную обработку, добавив модуль интеграции из статьи на Инфостарте, а также модуль для подключения конфигурации на базе БСП.
Настройки интеграции:
-
Выгружаются только ошибки.
-
Обработка работает как регламентное задание с интервалом 30 секунд.
-
Выгрузка происходит только для событий, появившихся после предыдущей выгрузки.
Аналоги Sentry
Среди SaaS-решений можно выделить: Gauge, Raygun и Bugsnag. Среди On-Premise решений — GlitchTip. По функционалу они с Sentry схожи. GlitchTip более легковесен, имеет более компактный интерфейс и проще в администрировании. Но он предлагает меньше возможностей и имеет менее удобные фильтры.
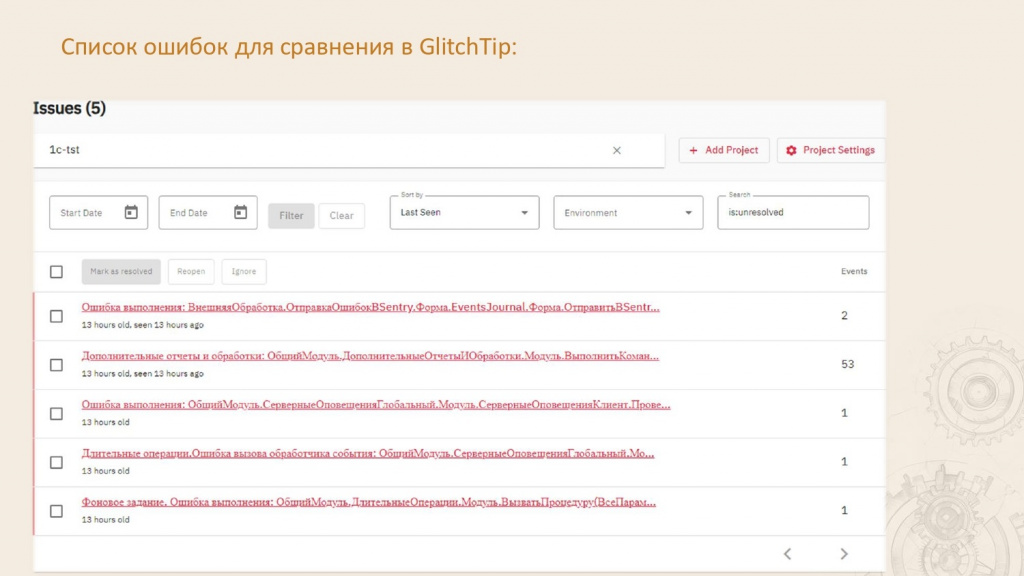
При этом наша обработка поддерживает интеграцию как с Sentry, так и с GlitchTip, что позволяет быстро переключаться между системами.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции INFOSTART TECH EVENT.

Вступайте в нашу телеграмм-группу Инфостарт