Продолжим тему предыдущего доклада «15 мифов в платформе 1С» и дополним его еще десятком новых проверок и исследований платформы.
Миф №1. «""+Строка(Ссылка)» медленнее, чем «""+Ссылка»
Подтверждено
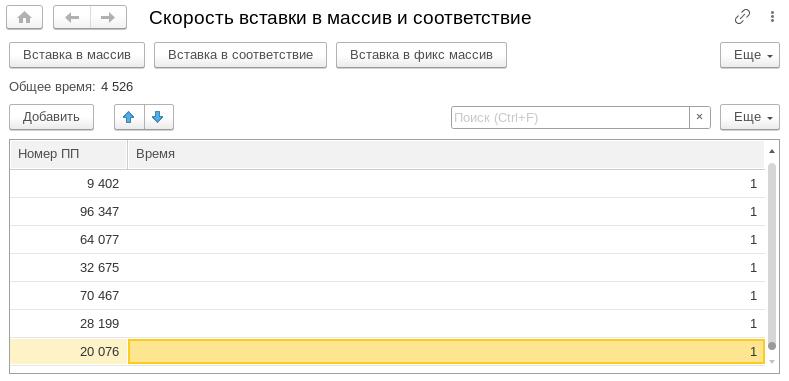
Считается, что за счет двойного преобразования к типу «Строка» вариант «""+Строка(Ссылка)» будет работать медленнее, чем «""+Ссылка».

Давайте разберемся – когда вообще используется конструкция «""» (две кавычки), и для чего она может понадобиться?
Когда 1С обрабатывает сложение значений, она сначала получает первое значение и определяет его тип, а потом пытается привести к тому же типу все остальные суммируемые. То есть, когда мы используем «""+Ссылка» для второго значения происходит неявное преобразование к строке. Таким образом теоретически никакого замедления быть не должно, потому что в обоих случаях происходит преобразование к строке.
Но когда мы проверили время выполнения каждого варианта, результат оказался такой, как на слайде – скорость работы второго варианта незначительно, но все-таки медленнее.
Мы считаем, что это происходит из-за двойного преобразования к строке и наличия в коде дополнительного оператора – на его выполнение тратится время. Небольшое, но, тем не менее.
Миф №2. Расширения работают медленнее
Подтверждено
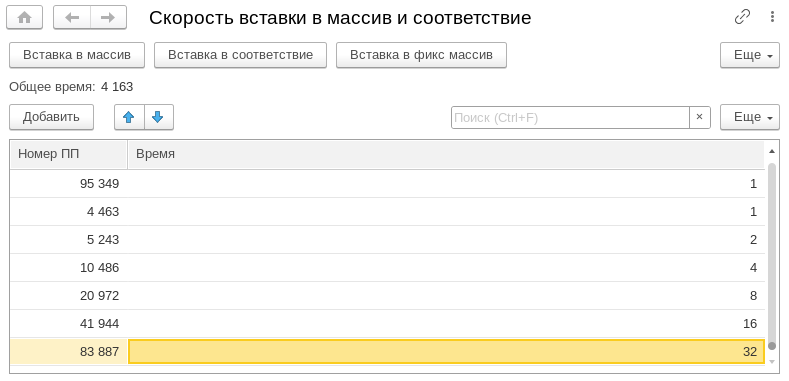
Мы уже обсуждали миф о том, что один и тот же код, вынесенный во внешнюю обработку, работает медленнее, чем в случае его добавления в конфигурацию. И это оказалось действительно так.

Тогда мы это проверяли с помощью вызова простой функции с циклом во внешней обработке и в конфигурации.
А теперь по просьбам сообщества разбираемся, как обстоят дела у расширения.

В первый раз мы запустили этот код в конфигурации, во второй раз – в расширении, а в третий раз – во внешней обработке. И получили такой результат: код в расширении выполняется на 5,78% медленнее, а во внешней обработке – еще медленнее.
И этому есть реальное объяснение, которое дается на сайте ИТС в статье https://its.1c.ru/db/metod8dev/content/5940/hdoc.
Причем там утверждается, что наши данные не вполне соответствуют действительности, потому что мы выполняли тест на одном пользователе и одном компьютере. А при параллельной работе многих пользователей ситуация еще более усугубляется.

И если запустить нагрузочный тест на 100 пользователях, для каждого из которых последовательно вызываются пустые методы модуля обработки (32000 строк) и модулей 120 ее различных форм, расширение покажет на 39% больше загрузку процессора и замедление времени выполнения на 26%. Поэтому миф считается подтвержденным.
Фирма «1С» исходя из этого дает следующую рекомендацию:
Не следует выносить во внешние обработки функционал, который может одновременно использоваться большим количеством пользователей. Такой код следует встраивать в конфигурацию, либо, в крайнем случае, использовать механизм расширений
Миф №3. Использование http-сервисов снижает нагрузку на сервер
Подтверждено

Когда пользователи подключаются к 1С через обычный тонкий клиент, на каждого из них создается по отдельному сеансу, имеющему определенные числовые характеристики – количество переданных данных, объем занятой памяти, время вызовов и т.д.

Но если такой же пользователь зайдет через HTTP-сервис, для него будет создан сеанс с видом «Модуль расширения веб-сервиса», у которого потребление данных на одного пользователя значительно меньше.
Но гораздо более интересно здесь то, что этот сеанс может обслуживать сразу нескольких пользователей. Поясню, как это работает, на простом примере.

Представьте, что ваш сервер – это кафе, в котором есть всего четыре места под кассы.
Кассиров там изначально нет.

В кафе заходит первый посетитель – он подходит к кассе и вызывает кассира. Чтобы кассир вышел и касса заработала, необходимо некоторое время.

Кассир обслужил посетителя, но не уходит, а остается на кассе в ожидании следующих гостей.

И когда приходит другой клиент, касса готова его обслужить сразу.
Получается, что один кассир обслуживает по очереди нескольких пользователей. Точно так же к одному и тому же сеансу веб-сервиса могут подключаться разные пользователи.

Если посетителей становится больше, открываются новые кассы.

Так происходит до тех пор, пока все кассы не будут заняты.

Но если количество посетителей продолжит расти, вновь прибывшим придется ждать, пока одна из касс не освободится.

С точки зрения пользователя компьютера это выглядит так: вы пытаетесь выполнить команду, на экране крутится индикатор загрузки, но никаких действий не происходит.

Теперь давайте посмотрим, как это можно визуально изобразить уже применительно к HTTP-сервисам. Представим, что у нас есть некий сервер, который способен одновременно обслуживать не более 4 сеансов.
Когда к HTTP-сервису обращается пользователь или внешний сервис, выполняется запрос, длительность выполнения которого составляет, допустим, 6 единиц времени.
Какое-то время пользователь ждет, а затем выполняет к сервису второй и третий запрос.
То есть, в случае, когда с сервисом работает один пользователь, загрузка сервера распределяется так: запрос-пауза-запрос-пауза-запрос и так далее.

Работа с сервисом нескольких пользователей будет выглядеть примерно так.
Пока запросы от разных пользователей не пересекаются по времени, они все будут обслуживаться одним сеансом сервиса. То есть, на одном сеансе может работать несколько человек, и таких пользователей может быть много.

Если же несколько пользователей отправляют запросы сервису одновременно, то поднимается второй сеанс, третий и так далее.
Количество сеансов в диспетчере задач начинает увеличиваться. И когда “придет пятый посетитель”, он просто не поместится. Ему придется подождать, пока один из сеансов не освободится, и тогда за тем сеансом, который закончил работу быстрее других, следом пойдет сеанс пятого пользователя.
То есть, все запросы выстраиваются в очередь. Это важно. И время, обозначенное здесь черным квадратиком – это время, которое ему придется подождать, в это время у него там будет отображаться индикатор загрузки.

Вот так выглядит диспетчер задач, когда в базе, где доступно всего пять сеансов, одновременно работает тысяча пользователей.
А теперь представьте, что будет, если тысяча пользователей просто зайдет в обычный тонкий клиент, даже ничего там не делая – сколько они займут при этом памяти на сервере. Поэтому, однозначно, миф считается подтвержденным.
Причем работу HTTP-сервисов можно ускорить еще сильнее, если:
-
увеличить ресурсы сервера;
-
сократить количество запросов;
-
уменьшить время выполнения каждого запроса

Наиболее доступный вариант – увеличить ресурсы сервера, потому что когда мы добавляем память, появляется возможность выполнить пятый и шестой сеансы.
Сокращение количества запросов также дает ощутимый эффект, потому что каждый Http-запрос, помимо передачи полезных данных, тратит время на установку соединения – оно здесь помечено заштрихованными промежутками. То есть, если пользователь записывает документ и относящиеся к нему файл с картинкой отдельными запросами, это создает избыточные задержки. А если объединить эти три запроса в один, можно сэкономить время на соединении – в приведенном примере выигрыш составил две единицы времени. На первый взгляд это немного, но именно этих двух единиц не хватило предыдущему клиенту, чтобы получить результат без ожидания. Поэтому такая оптимизация тоже позволяет ускорить запросы и улучшить удобство работы пользователей.
Миф №4. Http-сервисы оптимальнее web-сервисов
Подтверждено с оговорками

Нельзя однозначно сказать, что http-сервисы лучше web-сервисов. Это равнозначно ответу на вопрос: «Что вкуснее – пельмени или торт Наполеон?» Мне нравится и то, и другое: пельмени на второе, торт – на десерт. То же самое и с сервисами.

Web-сервисы и http-сервисы обычно используют различные форматы данных. Из-за этого http-сервисы чаще бывают немного быстрее, так как через них чаще всего передаются меньшие объемы данных.
Но в web-сервисах есть проверка параметров и возвращаемых значений, там можно установить запрет возврата пустых значений – анализируется, что подано в качестве параметров и что будет получено в качестве результата. В http-сервисах этого нет.
Поэтому:
-
Web-сервисы нужно использовать, когда требуется поддержка стандартов и строгая структура, а также при взаимодействии 1С с другими базами на 1С.
-
А http-сервисы – при работе с внешними веб-приложениями

Допустим, у нас есть web-сервис, который просто возвращает значение, принимая на вход один параметр указанного типа. Причем мы прямо в конфигурации можем указать, какого типа должен быть параметр и возвращаемое значение.
Дальше мы из другой базы вызываем этот сервис с помощью простого кода, подавая ему на вход строковый параметр. Фактически работа с этим web-сервисом выглядит так же, как с обычной функцией, но в другой базе: мы передаем в качестве параметра обязательные данные определенного типа, и нам тоже возвращаются данные определенного типа.
Это удобно для обычных 1С-ников – именно поэтому они любят использовать web-сервисы. Если выставить наружу веб-сервис, можно быть уверенным, что в него на вход не попадет ничего неподходящего: платформа сама проверяет корректность параметров и избавляет от необходимости писать дополнительный код для их валидации и обработки.

Если подать на вход такому методу web-сервиса два параметра, мы получим сообщение об ошибке.

А если попытаться вернуть из web-сервиса значение другого типа, мы тоже получим сообщение об ошибке. Все эти проверки платформа сделает сама, и это значительно упрощает работу разработчика.

На слайде приведена цитата с одного из форумов, где четко описано, в чем состоит различие между web-сервисами и http-сервисами. Обратите внимание на важное замечание в конце: «Web-сервис – это всего лишь частный случай http-сервиса, а именно - это POST-запрос строго определенного формата».

А вот так выглядит работа с http-сервисами: все данные, которые нам попадают на вход, мы должны проверять сами. Собираем всю информацию из параметров, из тела запроса, из заголовков – и потом с этим работаем. Да, при работе с внешними приложениями это дает интеграции определенную гибкость в качестве преимущества.
Но важно помнить: нельзя однозначно утверждать, что http-сервисы оптимальнее web-сервисов. Преимущество http-сервисов только в объеме передаваемых данных. А реальная оптимальность метода обмена информацией определяется не только скоростью, но и другими зачастую более значимыми факторами. Поэтому здесь решение остается за разработчиком: в одних случаях удобнее применять web-сервисы, в других – http-сервисы.
Миф №5. При передаче данных между базами 1С через http и web-сервисы обязательно преобразование данных в тип «Строка»
Не подтверждено
Считается, что при обмене данными между базами 1С через http- и web-сервисы обязательно преобразовывать все значения в строковый тип. Давайте разберемся, правда ли это необходимо.

Возьмем предыдущий пример и немного его модифицируем: поменяем тип возвращаемого значения для функции GetVersion со строки на ValueStorage – теперь функция GetVersion возвращает массив, в котором есть строка, число и ссылка на справочник «Номенклатура».

Обратите внимание, при попытке вызвать этот метод из другой базы, мы получаем абсолютно корректный массив, элементами которого являются строка, число и ссылка.
Конечно, чтобы ссылка была передана корректно, базы должны быть идентичными (например, копии одной и той же базы). Если в другой базе уже есть эта ссылка, мы ее получим, и нам не потребуется никакого преобразования значений. А это очень большой плюс для обменов между базами 1С – достаточно просто поднять web-сервис и передавать данные напрямую.

То же самое работает и в обратную сторону – через хранилище значения мы можем передать в качестве параметра структуру или массив, практически что угодно. Потому что хранилище значения можно использовать в 1С для того, чтобы не приводить данные к строковому типу. Преобразование там в любом случае происходит, но делает это уже сама платформа неявно. Поэтому миф о необходимости при передаче данных через http- и web-сервисы всегда преобразовывать их в строку считаем неподтвержденным.
Здесь, естественно, есть определенные ограничения, описанные на ИТС в статье https://its.1c.ru/db/metod8dev/content/2597/hdoc. Передавать через веб-сервис объекты с типом ХранилищеЗначения (ValueStorage) можно только для тех данных, которые сериализуются. При этом поддерживается передача объектов типа Картинка и Двоичные данные, а также таблиц значений и структур.
Но важно понимать, что такое преобразование – ресурсоемкая операция. Поэтому данную технологию рекомендуется применять в крайних случаях, если отсутствует альтернатива, не стоит этим пользоваться часто и в циклах, лучше оптимизировать такой код.
Миф №6. JSON оптимальнее XML
Подтверждено с оговорками
Выбор между JSON и XML вызывает у меня точно такую же ассоциацию выбора между пельменями и тортом, о которой я говорил ранее.

На первый взгляд JSON действительно выглядит привлекательнее: он проще читается и визуально воспринимается лучше, чем XML. Видно, что объем передаваемых данных в JSON меньше, поэтому веб-разработчики чаще выбирают JSON, а 1С-ники – почему-то XML. Давайте разберемся, почему.

Если сравнить основные параметры сообщения, упакованного в JSON и XML, первые три строки – все в пользу JSON. Но последние три – все в пользу XML.
Дело в том, что XML – это не только формат передачи данных, это еще и полноценный инструмент для их обработки. XML можно загрузить в объектную модель DOM и поработать с его элементами – добавить или переименовать узлы, найти нужные данные по идентификаторам, используя XPath и другие механизмы. Поэтому в платформе 1С XML применяется гораздо шире.

Пример из практики – нужно передать между базами 1С сложную структуру, внутри которой есть код запроса с различными символами.

С точки зрения метаданных структура выгрузки представляет собой дерево значений. Как его сохранить?

С помощью XML мы это делаем несколькими строками готового кода, найденного в интернете. А попытка реализовать то же самое через JSON приводит к ошибкам, потому что JSON ругается на недопустимые данные, требует указания кодировки и так далее. То есть, применять XML при работе с данными в конфигурации 1C однозначно удобнее.

Поэтому JSON мы используем при взаимодействии с внешними приложениями, а XML – при взаимодействии с другими конфигурациями 1С.
Таким образом, JSON действительно оптимальнее, и это подтверждено, но с оговорками. Все зависит от случая.
Миф №7. Методы GET, POST и прочие путать нельзя
Не подтверждено с оговорками

Согласно стандартам, метод GET необходимо использовать только для получения информации, POST – только для добавления, DELETE – для удаления и так далее. Если перепутаешь – тебя ждет кара. Но на практике все не так однозначно.

Рассмотрим стандартный пример GET-запроса для поиска картинок.

GET-запрос состоит из адреса и набора параметров в формате «ключ=значение», упакованных в одну строку.

Но иногда эта строка может быть очень большая. Например, если попытаться передать через метод GET комплексный запрос, в котором содержится тема обращения, картинка и файл, длина этой строки будет 195 килобайтов.
Мы с этим в свое время столкнулись. Пробовали все запросы отправлять в свою систему 1С через GET-запрос, и в какой-то момент обратили внимание, что без вложений файлов запрос выполняется без проблем, а с вложениями – ломается.

Это происходило потому, что у GET-запросов есть ограничение по длине – 4 килобайта. А у нас запрос получился длиной 195 килобайт.
Поэтому мы решили, что будем использовать POST-запросы везде. Тем более, что сама 1С при работе web-сервисов использует только этот метод.

Вот так теперь выглядит применяемые у нас методы HTTP-запросов – везде POST и все.

И затем мы исследовали интернет и убедились, что большинство разработчиков пришло к этому же выводу – что для решения большинства задач достаточно использования метода POST.
У GET-запросов еще и с безопасностью могут быть проблемы, потому что они иногда кэшируются браузерами. А если мы передаем через GET-запрос логин и пароль, то, даже несмотря на HTTPS, их потом оттуда можно извлечь, что является большим минусом.
Миф №8. Файловая база виснет при работе через веб-сервер
Не подтверждено с оговорками
Считается, что когда база опубликована на веб-сервере, то стоит одному пользователю запустить формирование отчета - и остальные уже не смогут работать.

На стороне сервера это выглядит вот так: одно ядро загружено на 100%, а остальные простаивают, но запросы от других пользователей не обрабатываются.

С точки зрения пользователя это выглядит примерно вот так.

Причем даже тот, кто формирует отчет, тоже не может выполнять другие действия.

Причина в том, что база 1С, работая через веб-сервер (Apache, IIS и др.) использует единую точку входа для всех запросов. Попадая туда, «тяжелый» запрос занимает очередь и блокирует работу остальных, пока не завершится.

Но это лечится. На Инфостарте есть разработка, которая так и называется – «Решение проблемы однопоточности модуля веб-сервера при работе с файловой базой».
Эта разработка предоставляет cmd-файл, позволяющий создать дополнительные точки входа, публикуя базу на нескольких портах одного веб-сервера.

В результате у вас появится несколько служб Apache, и каждый пользователь будет работать со своей службой. Нагрузка перераспределится, и система продолжит работать стабильно
Поэтому миф не подтвержден с оговорками – т.е. проблема есть, но она решается.
Миф №9. 32-битный клиент медленнее 64-битного
Подтверждено


Здесь мы опять использовали алгоритм, с помощью которого уже сравнивали скорость выполнения кода в расширении и конфигурации, и запустили его в 32 и 64-битном клиенте.
Получилось, что 32 бита действительно медленнее.

Здесь перечислены причины, почему так происходит.

Особенно ярко эта разница проявляется на сервере:
-
Слева – результаты тестирования на 32 битах, с файловой базой без проблем могли работать только 6 пользователей. Как только заходил седьмой, система начинала тормозить. На SQL базе максимальное количество пользователей – 30.
-
Справа – на той же версии платформы, но уже в версии приложения 64 бит, уже могло без проблем работать 170 и 1000 пользователей в файловом и SQL варианте – просто потому что поменяли версию приложения.
Поэтому данный миф считается подтвержденным.

Кроме этого, мы еще сравнивали расход памяти: был момент, когда 32-битное приложение больше памяти занимало, но чаще всего больше памяти отъедает все-таки 64-битное приложение. Это тоже факт.
Итого: миф подтвержден – 64-битный клиент работает быстрее, хотя и может расходовать больше ресурсов.
Миф №10. В платформе 1С нет модульности
Не подтверждено
Считается, что микросервисная архитектура и независимая доработка отдельных подсистем – это не про 1С. На самом деле это не так, просто многие разработчики не хотят этим пользоваться.

Обычная конфигурация 1С содержит несколько подсистем, и все это хранится в одной СУБД.
Но мы в какой-то момент решили выделять некоторые подсистемы в отдельные конфигурации.

У нас был клиент, у которого база весила 500 гигабайт, причем 95% занимали присоединенные файлы, 3% – документы «Электронное письмо», и только 2% – остальные данные. Мы просто вынесли документы «Электронное письмо» и присоединенные файлы в отдельную базу и настроили работу с этой базой через http-сервисы: пользователи подключаются в основную мастер-базу, а дополнительная информация получается из других баз через http-запросы.

На слайде – пример работы такого подхода. В этот веб-интерфейс кабинета сотрудника выведены данные из баз Документооборот и ЗУП:
-
Из Документооборота – задачи.
-
А из ЗУП мы берем информацию об остатках отпусков и все остальные данные.
У распределенной конфигурации 1С есть особенности:
-
Скорость разработки и ее удобство снижаются, причем существенно.
-
Но работать такая система будет быстро, как минимум, не медленнее. Проверяли.
-
Необязательно сразу всю конфигурацию делать распределенной. Можно выносить ее в такой формат частями.
-
Зато у такой базы существенно повышается живучесть: недоступность одного сервера не всегда влечет за собой полный отказ системы

Пример: вот так выглядит в нашем кабинете карточка сотрудника.
Обратите внимание: база ЗУП в данный момент временно недоступна, но пользователь все равно видит 90% другой нужной ему информации. Как только мы восстановим доступ к базе ЗУП, пользователь вернется и посмотрит то, что ему нужно.
То есть, даже если что-то сломалось, это не ведет к падению всей системы, потому что большинство ее составляющих продолжает функционировать. Поэтому миф считаем неподтвержденным.

Получайте 15% бонусами
при покупке лицензий и конфигураций 1С!
Индивидуальная консультация, демо и готовое КП с учетом бонуса
Вопросы и ответы
Можно ли настроить время ожидания http-сеансов – сколько времени сеанс открывается, и через какое время он потом закроется?
На то, чтобы поднять сеанс http-сервиса, обычно тратится 2-3 секунды – это время зависит от используемой конфигурации.
А после того, как сеанс выполнил первый http-запрос, он обычно живет 20 минут – эту настройку можно поменять в конфигураторе: «Администрирование» – «Публикация на веб-сервере». Там в параметре «Время жизни соединения» по умолчанию установлено значение 1200 секунд. Это оно и есть. Вы его можете менять – как в сторону уменьшения, так и в сторону увеличения.
Параметр «Таймаут проверки» не влияет на создание http-соединения?
Не влияет. «Таймаут проверки» значит, что если мы в течение какого-то времени до сервера не достучались, запрос просто отвалится.
Есть ли разница с точки зрения ресурсов сервера у стандартного веб-клиента и тонкого клиента?
С точки зрения ресурсов сервера – скорее всего, нет. Это наше предположение, но скорее всего, нет.
Однако мы предполагаем, что с точки зрения нагрузки на клиентскую машину веб-клиент более ресурсоемкий, потому что весь исполняемый код нужно преобразовать в JavaScript – нарисовать интерфейс, дополнить его обработчиками, все это на JS.
А тонкий клиент работает на нативных функциях, которые намного быстрее выполняются и более компактные.
Мы в свое время исследовали, что и веб-клиент, и тонкий клиент, подключенный к веб-серверу через http отправляют на сервер одни и те же запросы и получают одни и те же данные. Поэтому для сервера с высокой долей вероятности разницы нет, а для клиента есть и существенная.
Тонкий клиент однозначно лучше и быстрее. По сути, тонкий клиент – это специализированный браузер, который 1С написала для своего решения. На нем ничего, кроме 1С не запустишь, но суть у него такая же.
Есть ли разница между тонким клиентом, подключенным к серверу через http, и тонким клиентом, который подключен к серверу напрямую?
Здесь точно есть различия, потому что у прямого подключения нет промежуточного звена в виде веб-сервера.
Вероятно, что тонкий клиент, подключенный напрямую, использует более низкоуровневый протокол передачи данных. Возможно, там местами даже UDP используется в каких-то случаях – например, для системы взаимодействия. Различия могут быть значительными.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции INFOSTART TEAMLEAD & CIO EVENT.

Вступайте в нашу телеграмм-группу Инфостарт