Вы помните, как впервые познакомились с большими языковыми моделями? Я помню – это было в начале 2023 года. Я тогда учился на втором курсе бакалавриата, и появилась нейросеть, которая могла генерировать лабораторные работы за нас.
Я подумал: круто. Можно было за один промпт получить за лабораторную пятерку и ничего не делать. Я тогда сказал одногруппникам, что не буду использовать это для своих работ, а вот кому-нибудь на заказ – можно. Но я ошибался, потому что сейчас использую большие языковые модели почти во всех сферах своей жизни.
Проблема выбора среди множества моделей
Сейчас существует большой зоопарк моделей, и новые появляются каждую неделю. Выходит очередная модель и сразу становится лучшей в мире. Непонятно, как выбирать из этого разнообразия.
Чтобы ответить на этот вопрос, я расскажу, что такое бенчмаркинг нейросетей, как он работает и зачем нужен. Разберем, как это можно перенести на 1С: какие задачи нужно давать нейросетям, чтобы объективно оценить их возможности. И напоследок я представлю первый автоматический бенчмарк в 1С.
Субъективность подхода к оценке моделей

Как мы выбираем большую языковую модель для своих задач? Смотрим обзоры, читаем статьи, пробуем сами: открываем чат, пишем промпт, получаем результат, что-то делаем. В большинстве случаев, поскольку этот процесс не стандартизирован, все сводится к субъективной оценке. Кто-то скажет, что для него лучшая модель – ChatGPT, кто-то – Claude, кто-то – Gemini.
Наверняка вы читали статьи, авторы которых тестируют модели на своих задачах. Но все это делается вручную, из-за чего объем данных и выборка получаются маленькими, а выводы – субъективными. Возникает вопрос: как это исправить?
Что такое бенчмарк и зачем он нужен
До нас уже все придумали. Существует понятие бенчмарк – в разработке и программировании это стандартизированный набор тестов, который используется для объективной и воспроизводимой оценки производительности.
Мы помещаем нейросети или языковые модели в одинаковые условия, даем им одни и те же данные и предлагаем выполнить одно и то же задание. Таким образом создается экосистема, в которой можно получить объективные данные о том, какая модель справляется лучше, а какая хуже.
Также с помощью бенчмарков можно отслеживать прогресс и улучшения. Если регулярно проводить бенчмарк-тесты, можно видеть, насколько модель улучшила свои результаты за определенный период.
Эволюция бенчмарков в программировании
В самом начале, когда большие языковые модели только начали развиваться, бенчмарки отвечали на простой вопрос: может ли модель написать элементарную функцию и понимает ли она специфику языка – его синтаксис, структуры, особенности программирования на Python, C++, Assembler и других языках. Примеры тех первых бенчмарков – HumanEval и MBPP от Google.
Позже, когда стало ясно, что модель действительно способна генерировать работающий код, исследователи начали проверять, может ли она решать более сложные, алгоритмические задачи – такие, с которыми сталкиваются участники международных соревнований по программированию.
Главным вопросом стало то, способна ли модель делать это также эффективно, как хороший программист. Именно тогда появились заголовки вроде «ChatGPT вошел в десятку лучших программистов мира» или «AI выиграл международную олимпиаду по программированию». С этого момента начался стремительный рост и развитие бенчмарков.
Современные бенчмарки
Ближе к нашему времени люди начали задаваться вопросом: может ли модель быть инженером, как человек? Это очень интересная тема.
Бенчмарки SWE-bench и LiveCodeBench устроены так: берется Git-репозиторий проекта, в котором есть раздел issues – список задач, требующих решения. У каждой задачи есть описание и unit-тест, который должен быть успешно пройден после исправления.
Такие бенчмарки парсят эти репозитории и собирают issues, передают описание проблемы нейросети, та генерирует код, вставляет его, собирает проект и запускает. Если unit-тест проходит – значит, модель правильно решила задачу.
Сейчас идет еще один этап развития – бенчмарки, проверяющие, может ли модель быть агентом. Это новое направление, где модель самостоятельно строит план действий: «Я зайду в файл такой-то, открою общий модуль общего назначения БСП, посмотрю, как работает функция, попробую применить ее в своем модуле». И такие способности уже начинают оценивать.
А где в этой эволюции находимся мы – 1С? Пока что где-то «в космосе». У нас нет стандартизированной оценки и выборки на больших данных. Мы на уровне понимания, что модель в принципе может писать код. Но может ли она делать это эффективно? Понимает ли все структуры языка 1С? Пока непонятно. До того, как проверять, способна ли модель стать инженером, нужно сначала пройти эти два уровня.
Из чего состоит бенчмарк
Как вообще модели проверяют текст или код, который они сгенерировали? Начнем с самого начала – с метрики BLEU.
Она пришла из сферы машинного перевода и работает так: сравнивает сгенерированный текст с эталонным. Например, модель выдала предложение «Кот сидел на ковре», а эталон – «Кот сидел на коврике».
Алгоритм по специальной формуле оценивает, насколько эти два предложения совпадают.

Основной принцип – точность по n-граммам. Что это значит:
-
Униграммы – сравнение по отдельным словам. Берем предложение «Кот сидел на ковре» и считаем, сколько слов совпадает с эталоном «Кот сидел на коврике». Видим, что «ковре» и «коврике» не совпадают.
-
Биграммы – сравнение по парам слов: «Кот сидел», «сидел на», «на ковре». Смотрим, какие из этих пар совпадают с эталонными.
Для такого примера значение BLEU будет около 0,7. Если другая модель получит 0,5, значит, она справилась хуже.
Однако у этого подхода есть очевидный недостаток: код может быть написан по-разному, но выполнять одну и ту же функцию. Поэтому в программировании метрика BLEU не всегда отражает реальное качество решения.
Адаптация метрики под программный код
Эту метрику адаптировали под код и добавили два параметра, которые учитывают структуру и семантику.
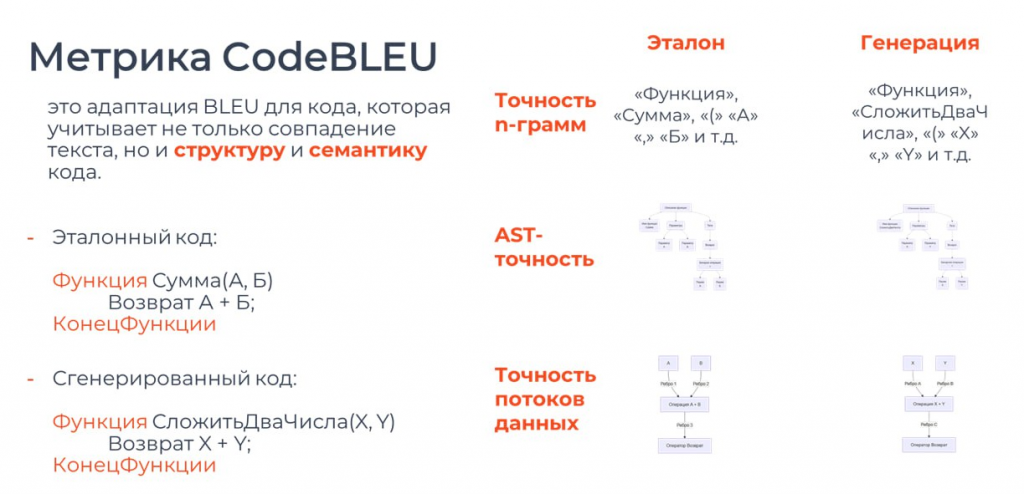
Возьмем пример: эталонный код – функция «Сумма» с двумя параметрами a, b и возвратом a + b. Сгенерированный код – функция «СложитьДваЧисла» с параметрами x, y и возвратом x + y. На прошлой метрике этот пример оценивался бы как некорректный, потому что совпадения по словам почти нет.
Здесь добавляется параметр AST-точность. Строится дерево по структуре кода. Есть блок функции, у него есть название, параметры, тело функции, оператор возврата, бинарная операция и два параметра, которые складываются между собой. Даже не вглядываясь в подписи, видно, что оба дерева идентичны. По сути, сравнивается похожесть этих деревьев, и по этому параметру код совпадает идеально.
Также добавлен параметр точность потоков данных. Он строит не дерево, а граф, где отображаются все данные и переменные, которые взаимодействуют друг с другом в коде. Параметры a и b идут в блок «Сумма», там складываются, и результат возвращается. Абсолютно такой же граф формируется и у сгенерированного кода.
Метрика CodeBLEU значительно лучше работает с кодом, потому что учитывает не только текст, но и смысловую структуру.
Метрика функциональной корректности: pass@k
Код можно написать по-разному. Например, в нем может не хватать точки с запятой или может быть неверно указан возврат. По предыдущим параметрам такой код может считаться подходящим, хотя непонятно, запустится он или нет. Поэтому основной метрикой для проверки того, насколько хорошо нейросеть пишет код, является pass@k.

Эта метрика оценивает функциональную корректность кода. Она показывает, какой процент из k сгенерированных решений проходит все заданные тесты.
Для примера: мы просим большую языковую модель сгенерировать 10 различных решений для одной задачи. Из них 6 решений компилируются и проходят все тесты, 2 решения компилируются, но не проходят тесты, и 2 решения вообще не компилируются.
Метрика pass@10 для одной задачи будет равна 60%, потому что 6 решений оказались рабочими. Для набора из n задач она будет равна 100%, если для каждой задачи хотя бы одно из десяти решений проходит все тесты (т.е. значение метрики больше нуля). Это означает, что если запустить по 10 решений для каждой задачи, то хотя бы одно из них обязательно сработает.
Метрики pass@k и CodeBLEU применяются в большинстве бенчмарков, о которых я рассказывал выше.
Применение бенчмаркинга в 1С: специфика и задачи
Как все это применить в 1С? Какие метрики использовать? Главная метрика – чтобы код работал и выполнял свою функцию.
Так как язык у нас специфичный, нужно проверять семантическую корректность и соответствие стандартам разработки 1С. Метрику можно считать по количеству нарушений стандарта на определенное число строк кода – например, 2 ошибки на 100 строк.
Чтобы объективно оценить возможности нейросети в работе с 1С, я выделил 6 типов задач. По сути, это основа нашей работы как программистов 1С:
-
Простые функции. Например, FizzBuzz, сортировка пузырьком, выгрузки в Excel. Это базовые задачи, с которых можно начать.
-
Исправление ошибок. Берем модуль, где есть ошибка, и просим нейросеть ее исправить.
-
Написание запросов. Здесь можно проверять не только правильность результата, но и эффективность структуры запроса, который потом преобразуется в SQL. Это интересное направление для анализа.
-
Доработка форм. Пока работает очень нестабильно. Нейросети почти не понимают формы 1С, все ломается, но это можно использовать для оценки прогресса.
-
Работа с метаданными. Создание справочников, настройка связей, назначение типов данных.
-
Рефакторинг кода. Проверка и исправление по стандартам.
Разработка автоматического бенчмарка для 1С
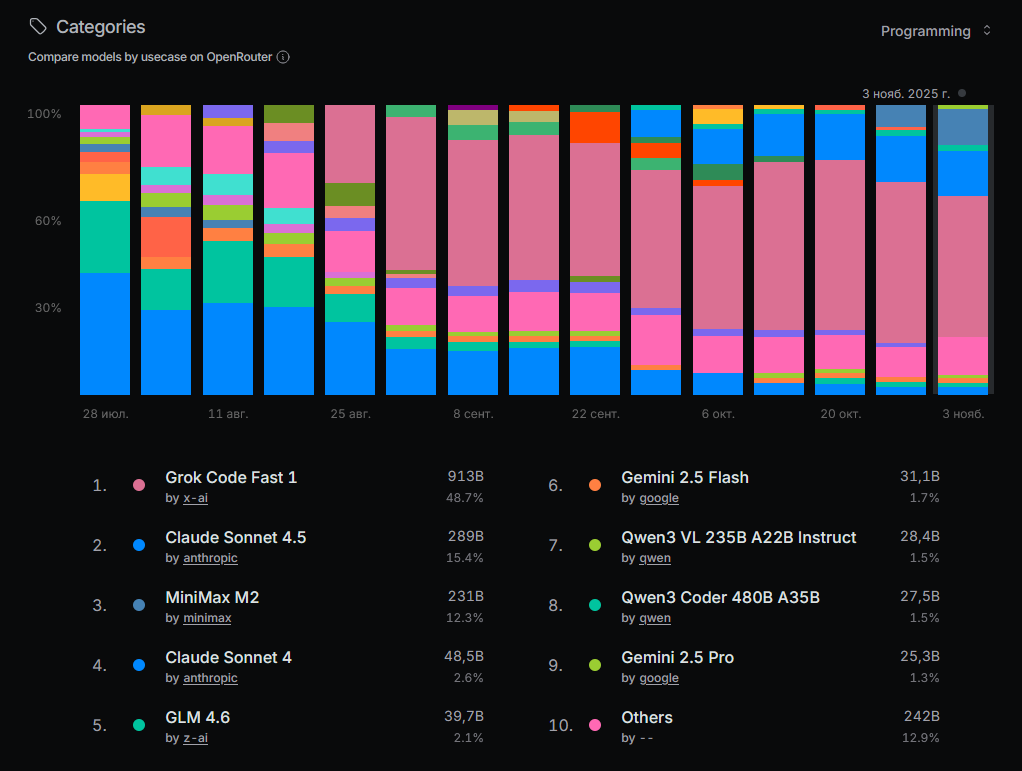
Мы начали разрабатывать свой сервис 1С LLM Бенчмарк, который автоматически сравнивает нейросети по качеству генерации кода. У нас есть таблица лидеров, где показаны результаты протестированных моделей, проверенных на двадцати тестовых заданиях из категории «простые функции».
Мы сделали сервис таким, чтобы можно было добавлять собственные задания, присваивать им типы и прописывать внутренние тесты.
Архитектура сервиса автоматического бенчмарка
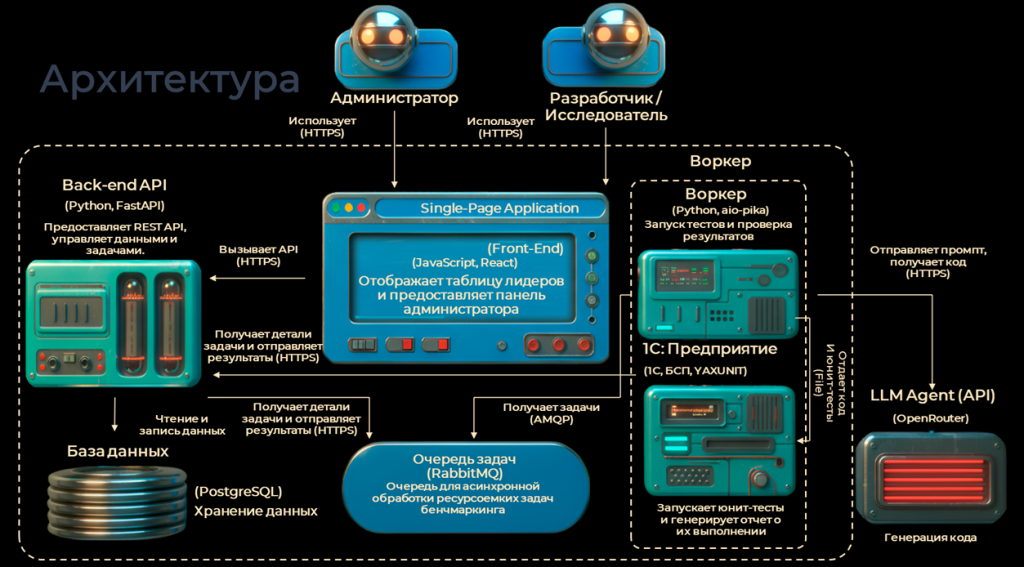
У нас есть веб-приложение – FrontEnd. Помимо таблицы лидеров, которую я упоминал выше, там есть админ-панель, доступная администратору. Администратор заполняет справочник LLM-агентов, справочник тестов и заданий, пишет юнит-тесты.
Back-End отвечает за хранение данных. Есть очередь задач, она нужна для оптимизации и поддержания стабильности работы всего сервиса. Есть воркер – отдельный компонент, который запускает тесты и проверяет результаты.
Все эти сервисы обернуты в Docker-контейнеры. Сейчас я работаю над тем, чтобы и воркер, и 1С тоже были обернуты в Docker.
Алгоритм работы бенчмарка
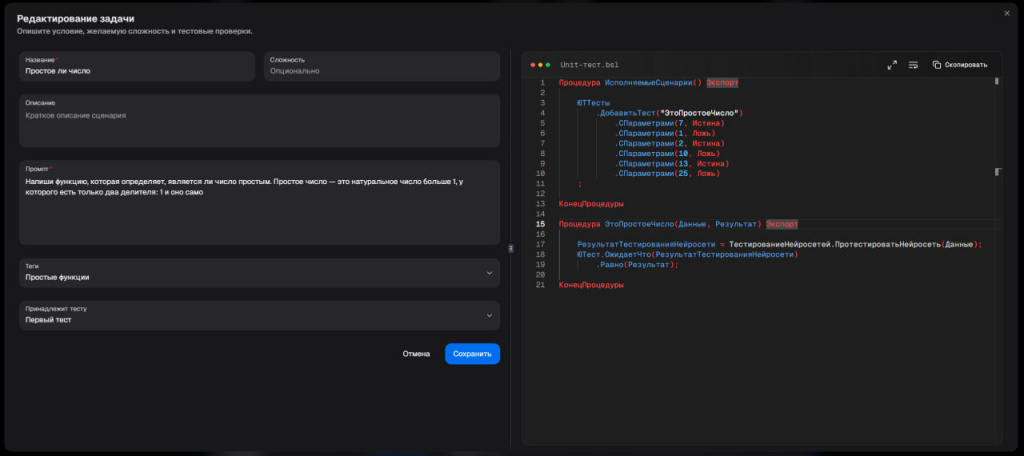
Сначала я в сервисе заполняю задачу. Например, «простое ли число». Указываю промпт, который будет отправляться всем нейросетям для проверки: «Напиши функцию, которая определяет, является ли число простым». Далее добавляю описание – что такое простое число. Здесь же я пишу unit-тест на YAXUnit.
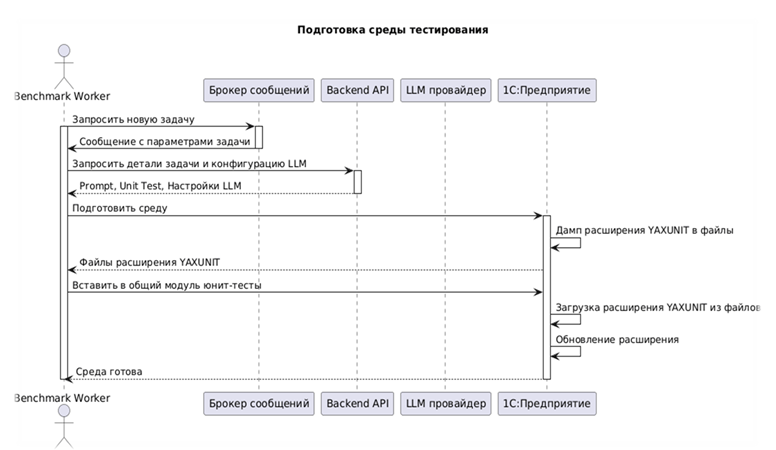
Воркер забирает задачу из очереди, наполняет себя данными, которые хранятся в бэкенде и базе данных, после чего подготавливает среду для тестирования.
Он запускается в 1С, делает дамп расширения YAXUnit в файлы, затем вставляет в общий модуль тот юнит-тест, который был написан в задаче. После этого расширение загружается обратно в конфигурацию, обновляется – и среда готова. Можно переходить к тестированию нейросети.
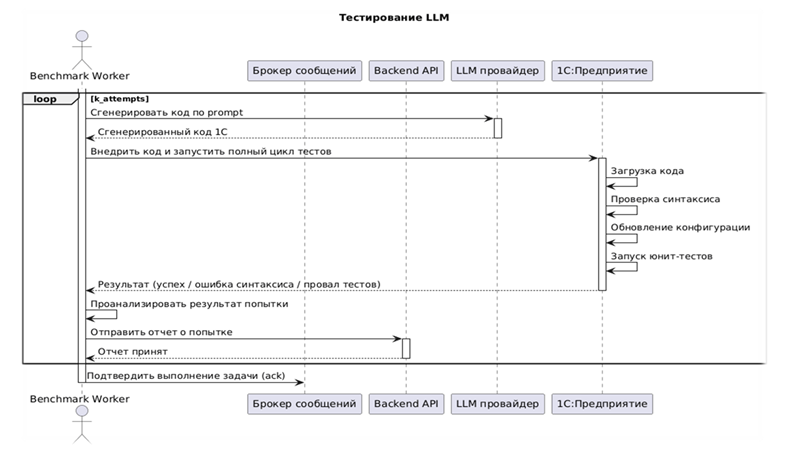
Воркер отправляет запрос к провайдеру большой языковой модели – в большинстве случаев я использую OpenRouter, там собраны все основные модели. Приходит ответ от нейросети, я обрабатываю его и извлекаю сгенерированный код. Этот код загружается в файл общего модуля специальной конфигурации.
После этого конфигурация обновляется, проводится стандартная проверка синтаксиса – та самая, которую мы делаем в конфигураторе через Ctrl+F7. Если проверка проходит успешно, запускаются юнит-тесты YAXUnit.
Затем YAXUnit формирует отчет в формате JSON. Я обрабатываю его, отправляю результаты в сервис, и они выводятся в таблицу лидеров. На момент написания этой статьи было протестировано около 320 задач.
Первые результаты и наблюдения
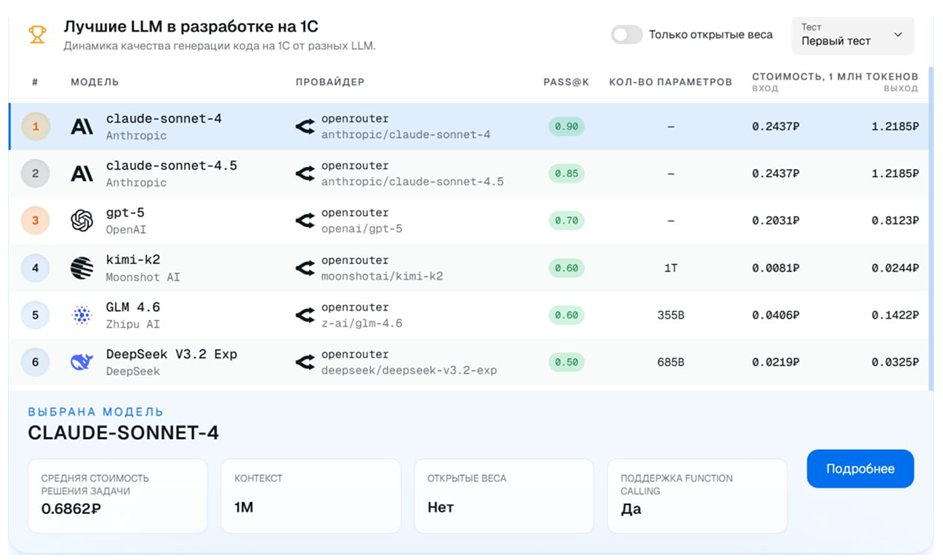
По результатам на первом месте Claude Sonnet 4. Для меня это было немного неожиданно. Как можно было определить, что Claude Sonnet 4.5 хуже, чем Claude Sonnet 4, на тех же заданиях, которые я выставил? Визуально – никак. Мы бы все посчитали, что Sonnet 4.5 программирует лучше, чем 4. Но оказалось, что Sonnet 4 решил 90% заданий. А Claude Sonnet 4.5 начал ошибаться в циклах, писать их неправильно, добавлять лишние символы, из-за чего все ломалось.
Можно выбрать любую модель и посмотреть дополнительные данные. Например, у Claude Sonnet 4 средняя стоимость решения одной задачи из набора тестов составила 68 копеек. Столько это будет стоить, если вы захотите использовать нейросети для программирования.
Если нажать «Подробнее», откроется страница с графиками аналитики по типам задач.
Планы по развитию проекта
Этот проект мы разрабатываем вместе с друзьями и планируем развивать дальше. У нас есть несколько целей.
Во-первых, расширить типы задач – добавить проверку запросов, проверку исправления ошибок, доработку форм, работу с метаданными и, в целом, обогатить тестовый набор. Сделать не 20 задач, а 100, чтобы получились действительно большие данные, на основе которых можно принимать решения.
Сейчас популярна тема MCP-серверов. Их используют нейросети, чтобы обогащать себя данными и узнавать, например, как работать с таблицами значений в 1С, какие методы доступны. Это позволяет нейросети понимать контекст и самой себе подсказывать. Мы планируем внедрить Tool-Use – то есть сравнивать не только сами модели, но и MCP-серверы, с которыми они работают. Например, сравнивать набор задач без MCP, и те же задачи, но уже с разными MCP-серверами. Это позволит собрать интересную статистику и понять, какие связки дают лучший результат. Такой подход поможет сообществу бесплатно выявлять и определять лучшие решения, повышать конкуренцию, производительность и качество.
Следующим шагом станет добавление тестирования ИИ-агентов – чтобы проверить, как они смогут ориентироваться в наших конфигурациях, данных и специфике 1С.
Также есть идея превратить статичную таблицу лидеров в платформу пользовательского тестирования, где пользователи смогут сами создавать тесты и задачи, а затем отправлять их на проверку тем нейросетям, которые хотят протестировать на своих кейсах.
Другая идея – развитие направления сравнения нейросетей именно в сфере 1С, но не только в части написания кода, а в оценке экспертных знаний. Проверять, насколько модель способна консультировать пользователя по разработкам, по вопросам бухгалтерии, казначейства, логистики и других областей, с которыми мы работаем.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции INFOSTART TECH EVENT.

Вступайте в нашу телеграмм-группу Инфостарт