Продолжаем цикл статей по совместному докладу Алены Генераловой и Александра Симонова «Как мы провели этим летом нагрузочный тест на 30 тысяч пользователей». В первой части рассказали, как ускорить подготовку теста и настроить шаблон для 180 виртуальных машин (ВМ) с помощью Ansible. В этом материале рассмотрим запуск теста и сбор артефактов, а также поговорим про архитектуру кластера 1С и настройку свойств СУБД.

После успешной автоматизации процесса создания и настройки виртуальных машин, сократившей время развертывания стенда до 1 часа, перешли к следующему этапу – автоматизации подготовки стенда, запуска тестов и сбора результатов. Мы выполнили несколько запусков этого НТ. И здесь важно понимать: для получения достоверных результатов каждый запуск должен проходить в абсолютно одинаковых условиях. Для экономии времени автоматизировали процесс подготовки стенда. Перед каждым запуском теста нужно было выполнять ряд последовательных шагов, а именно:
- Восстановить настройки СУБД
- Остановить сервисы и службы: 1С, atop, iostat, ras, собственные службы и сборщики, если они есть
- Удалить Журнал регистрации 1С (ЖР 1С, ЖР)
- Остановить все серверные процессы: rphost, rmngr, ragent, если к этому моменту они не завершились
- Остановить все клиентские процессы 1cv8c на нагрузчиках
- Удалить Технологический журнал 1С (ТЖ 1С, ТЖ), дампы, сеансовые данные, данные atop и iostat, логи наших сборщиков
- Выполнить бенчмарки fio и SysBench
- Скопировать шаблон настройки ТЖ 1С на все сервера приложений и на терминальные сервера
- Запустить сервисы: 1С, iostat, ras, собственные службы и сборщики
- Запустить xrdp
Итак, агенты запущены, стенд готов к очередному нагрузочному тестированию.
* * *
После выполнения теста нужно собрать все артефакты, логи и данные для последующего анализа. Для этого автоматизируем следующие действия:
- Сбор данных о размере сеансовых данных, копирование к себе реестра кластера 1CV8Clst.lst
- Выполнение бэкапа всех собранных логов на серверах приложений и терминалах
- Выполнение бэкапа данных ЖР 1С
- Выполнение бэкапа данных atop, iostat
- Закрытие всех сессий RDP
- Выгрузку к себе замеров времени
- Выгрузку к себе отчета об APDEX
После этого переходим к настройке кластера 1С – по ссылке доступен плейбук Ansible, который использовался нами для разворачивания кластера. В используемой нами конфигурации центральный сервер и рабочие сервера по сайзингу были равны, и через несколько итераций тестирования мы остановились на следующих параметрах проведения НТ:
- на центральном сервере размещается фоновое задание теста и основные сервисы менеджера кластера
- три рабочих сервера обслуживают клиентские соединения и сеансовые данные
Как это выглядело – на слайде ниже.

Рассмотрим подробнее требования для сеансовых данных – почему именно так мы настроили параметры. Если не указать в явном виде его размещение на рабочих серверах, он был бы запущен только на центральном сервере. В этом случае все клиентские соединения с рабочих серверов обращались бы за сеансовыми данными к центральному серверу, что создало бы лишнее сетевое взаимодействие.
Поэтому в требованиях назначения функциональности (ТНФ) для сервиса сеансовых данных настроили распределение следующим образом:
- не назначать (запретить) размещение на центральном сервере
- разрешить размещение сервисам сеансовых данных на рабочих серверах Это позволило добиться оптимального распределения нагрузки в кластере 1С
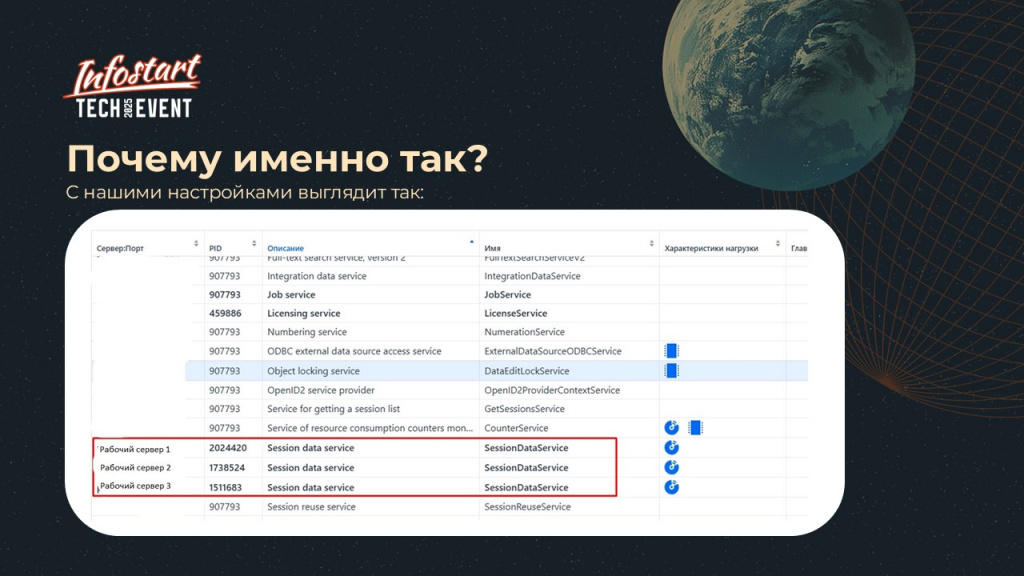
Переходим к настройке свойств базы данных.
В данном кейсе включили свойство резервирования рабочих процессов – это важно при одновременном запуске 30000 виртуальных рабочих мест (ВРМ). Когда в активном рабочем процессе заканчиваются доступные соединения, требуется создать новый рабочий процесс – соединения будут ждать, когда он запустится, и тратить время на это. А так как у системы ERP большой контекст, то его полная загрузка требовала значительного времени.
Поэтому для обеспечения бесперебойной работы всегда использовали резервный рабочий процесс. Как только в активном процессе заканчивался лимит подключений, резервный процесс немедленно становился активными и начинал принимать новые соединения. Параллельно с этим запускался очередной резервный процесс. Благодаря такому подходу открытие всех 30 000 ВРМ занимало всего порядка 50 минут.
Еще одно полезное свойство, которое снижает накладные расходы на серверы приложений – это задержка выгрузки конфигурации рабочим процессом. Этот параметр определяет время, через которое данные информационной базы будут выгружены из памяти рабочего процесса, когда количество активных соединений в этом рабочем процессе станет равным нулю.
Ключевые параметры подсвечены на слайде ниже:

Следующий этап – подготовка базы 1С к тестированию; он включает несколько шагов:
- Создание виртуальных пользователей. Лайфхак: запускайте тест без агентов тестирования (подробнее – ниже)
- Расчет прав доступа: обязательно проводите после генерации виртуальных пользователей
- Проверка справочников «Виртуальные пользователи» и «Агенты»
- Настройка клиента для Linux. Команда запуска: /opt/1cv8/x86_64/8.3.27.1529/1cv8c /UseHwLicenses /DisableStartupMessages
- Создание бэкапа настроенной базы!
* * *
Теперь подробности. Время этапа выполнения одной итерации теста занимало у нас около 11 часов, что не позволяло проводить более одного теста в день.
Наиболее длительный этап – само выполнение теста. При этом в общем процессе НТ есть этап, где можно существенно сократить время – это подготовка, в процессе которой открывались все виртуальные рабочие места. При этом, каждое из 30 тысяч ВРМ работает под уникальным пользователем, что требует создания 30 тысяч элементов в одноименном справочнике!
При запуске теста система начинает создавать эти записи, что занимает несколько часов. Для ускорения процесса применили следующий подход, который вполне можно считать лайфхаком – предварительно запустили тест без агентов, что позволило заранее и быстро заполнить справочник пользователей. Дополнительную сложность создавала настройка информационной базы (ИБ) ERP-системы с ограничением доступа на уровне записей. Права доступа для каждого нового пользователя рассчитываются аналогично на этапе подготовки, и это тоже занимает длительное время.
Поэтому настоятельно рекомендуем: для проведения НТ с большим количеством пользователей 1С заранее заполните справочник «Пользователи» и рассчитайте права доступа. Это избавит систему от лишней нагрузки во время самого теста и обеспечит точность результатов. На картинке – ускоренный в 50 раз процесс запуска 30 000 ВРМ:

Но и это еще не все: перед каждым тестом нужно убедиться, что справочники «Виртуальные пользователи» и «Агенты» полностью очищены. Так как из-за «агентов-призраков» тест может попросту не запуститься.
Напоминаем: важно правильно настроить клиентов в справочнике тест-центра и в обязательном порядке:
- указать путь к бинарным файлам
- установить параметр, запрещающий использование аппаратных лицензий
- отключить стартовые сообщения
Подробно этот момент мы разобрали в первой статье, но важно помнить об этом постоянно, чтобы нагрузочное тестирование не было сорвано. И обязательно сделайте бэкап настроенной описанным выше способом базы 1С. Итераций у серьезного НТ всегда несколько и здесь вы сэкономите себе существенное время на этапе подготовки, избежав необходимости повторно заполнять справочник пользователей, рассчитывать права доступа и очищать технические справочники.
В следующей части расскажем, как прошли первые запуски НТ, с какими проблемами пришлось столкнуться и как мы их решали.
Вступайте в нашу телеграмм-группу Инфостарт