
В первую очередь хочу поблагодарить за публикацию многоуважаемого awa. А его утилита Tool_1CD спасла уже не одну базу.
Я буду ссылаться на эту публикацию, предварительное ознакомление с ней обязательно. Сподвигло меня на написание то, что 1С выкатила новый формат, описаний которого мне пока не попадалось. Данная статья будет полезна как для понимания ограничений данного формата, так и для создания утилит восстановления испорченных баз.
1. Дополнения и уточнения к описанию от awa
Страницы
Чтобы избежать терминологической путаницы, введем термин "страница" - это блоки, из которых состоит файл базы. До версии платформы 8.3.8 (формат 8.2.14 и младше) размер блока был строго равен 4096 байт, начиная с версии 8.3.8 фирма 1С ввела новый, пока необязательный, формат с возможностью увеличения размера страницы - допустимыми стали значения 4Кб, 8Кб, 16Кб, 32Кб и 64Кб. Страницы в файле нумеруются с нуля четырехбайтным целым числом, предположительно без знака (UINT32). Таким образом, для страницы в 4К теоретический максимум размера файла - 16Тб, но другие ограничения не дадут реализовать этот потенциал. Страницы 0, 1 и 2 имеют специальное назначение: в странице 0 содержится заголовок файла, страница 1 содержит объект, содержащий список свободных страниц файла, страница 2 содержит "корневой" объект базы, ссылающийся на все таблицы.
Потоки
Введем понятие "поток" (Stream) данных - логическая сущность, последовательность данных. Например, пространство для хранения записей таблицы или данных неограниченной длины. Поток размещается на последовательности страниц и имеет размер, не превышающий суммарный размер всех страниц. Данные хранятся в потоках.
Объекты данных
"Объект" в базе представляет собой описание к потоку, содержащему данные. Заголовочная страница содержит среди прочего актуальную длину потока данных и список страниц, содержащих список страниц потока ;). В странице описания объекта первые 24 байта служебные, остальные 1018 32-разрядных значений содержат список страниц (назовем их "таблица размещения"). Каждая из страниц таблицы размещения содержит 4096 / 4 = 1024 32-разрядных целых. Первое значение описывает сколько значений из оставшихся 1023 используется на данной странице. И так для каждой страницы таблицы размещения. Таким образом поток данного объекта может содержать максимум 1018*1023=1041414 страниц по 4К, т.е. чуть меньше 4Гб. Поскольку на каждую таблицу выделяется по отдельному объекту для данных записей, индексов и данных неограниченной длины (BLOBов), следует что каждый из этих составляющих не может занимать больше 4Гб. Если в таблицу попробовать добавить больше данных, платформа выдаст критическую ошибку с вариантами "закрыть" и "перезапустить".
Объект описания свободных страниц
Объект, описывающий список свободных страниц, устроен несколько отличным образом. Отличий два: поле длины потока содержит количество свободных страниц в списке, и каждая страница таблицы размещения не использует первое значение под количество номеров в странице, а использует всё пространство (1024 значения) под список свободных страниц. Таким образом, этот объект может содержать список из максимум 1018*1024=1042432 страниц при размере страницы 4К, т.е. описывает свободное пространство почти в 4Гб. Отсюда следует достаточно занятное следствие - базы, содержащие более 4Гб данных, подвержены "утечкам страниц" и бесконтрольному разбуханию. Например, мы удаляем из базы две таблицы, которые суммарно занимали 5Гб пространства. Допустим, что перед операцией список свободных страниц был пуст, тогда он заполнится максимальным значением номеров (4Гб), а ссылки на остальные страницы (1Гб) будут потеряны. Поскольку при обновлении конфигурации платформа проводит реструктуризацию способом "сделать копию таблиц, перелить данные, старые удалить", то при определенном объеме обрабатываемых таблиц "утечка" становится неизбежной.
Кстати, в списке свободных страниц номера страниц совершенно не обязаны идти по порядку. Движок 1С просто добавляет высвобождаемое пространство в конец списка, и страницы для использования берет из конца списка. Отсюда появляется еще один интересный эффект - внутренняя фрагментация потоков данных, т.е. поток может быть размазан по всей базе. Это не может положительно влиять на скорость работы базы, и только выделение больших объемов оперативной памяти для кэширования и размещение базы на SSD может минимизировать негативный эффект. Это же замечание актуально и для свободных блоков в потоках данных неограниченной длины (BLOB-ах). Т.е. если рассматривать фрагментацию файла базы данных на диске как первичную, то фрагментация потоков внутри базы - вторичная, а то что данные в блоках BLOB-ов могут идти непоследовательно внутри потока - третичная. В частности поэтому я размещаю базы с которыми приходится работать на SSD, а в случае каких-то разовых работ (обновление, перенос данных из баз заказчивов) - размещаю базы на RAM-Drive, на виртуальном диске в оперативной памяти.
Организация хранения данных неограниченной длины (BLOBs)
Поток хранения BLOB разбит на блоки по 256 байт, при этом первые 6 байт используются под заголовок блока (ссылка на следующий блок и объем реально используемых данных в блоке). Блоки нумеруются 32-разрядными (беззнаковыми?) целыми, таким образом максимальный размер объекта под BLOB может быть 2^32*256=2^40=1Тб. Первый блок всегда выделен под организацию цепочки свободных блоков потока.
Внимание! Потоки данных и BLOBов свежесозданных таблиц, не содержащих данных, могут быть пустыми, т.е. не иметь в таблице размещения ни одной страницы, даже под первую запись для организации цепочки свободных блоков/записей.
Корневой объект
Корневой объект описывается на странице 2 файла базы. Его поток содержит служебные данные, и список номеров страниц, на которых размещаются объекты с описанием таблиц. Используется текстовое описание таблиц в формате сериализации 1С с использованием двухбайтовой кодировки UCS2. Каждое описание содержит имя таблицы, списки полей и индексов, а так же номера страниц с объектами данных записей таблиц, BLOB-ов и индексов. Подробнее описано в статье awa.
Формат сериализации 1С
1С активно использует текстовый формат сериализованных структурированных данных, идеологически сходный с JSON. Значения в этом формате могут иметь типы:
- Список - последовательность значений (в т.ч. списочных), разделенных запятыми, окруженных фигурными скобками. Например: {1,2,{3,4}}
- Строка - строковое значение заключается в двойные кавычки. Двойные кавычки внутри значения удваиваются. Например: {"Строка1","Строка ""2"" с кавычками "}
- Пустое значение - пропущенное значение, например {1,,3}
- Числовое значение
- GUID - например: {2,e5c73637-e8d6-47e0-9c15-2fa1802ee5b0,76702e9e-fa7a-4b98-befa-f9b37db2dae0}
- Двоичное значение - в виде последовательности шестнадцатиричных знаков: 0123456789abcdef
Возможно существуют и другие типы, но мне пока не встречались. В тексте между синтаксическими элементами могут встречаться переводы строк. Этот формат используется в частности для описания структуры таблиц, конфигурации, пользователей в таблице V8USERS и т.д.
Хранение GUID в записях
1С активно использует GUID в данных, в частности как суррогатные первичные ключи в таблицах. При этом физически они хранятся как двоичные значения длины 16 байт. Но и тут 1С не обошлась без "особенностей": GUID вида AAAAAAAA-BBBB-CCCC-DDDD-EEEEEEEEEEEE хранится как DDDDEEEEEEEEEEEECCCCBBBBAAAAAAAA, т.е. компоненты 4,5,3,2,1
Соответственно для обратного преобразования требуется разбить двоичные данные на группы и 4,12,4,4,8 шестнадцатеричных знаков и соединить как группы {$5-$4-$3-$1-$2}
2. Новое в формате 8.3.8
Заголовок базы
Страница 0 почти не изменилась. В качестве версии формата используется 8,3,8,0, в отличие от предшественника 8,2,14,0. Добавилось поле типа UINT32 с описанием размера страницы, и теперь структура выглядит так:
struct {
char sig[8]; // сигнатура “1CDBMSV8”
char ver1;
char ver2;
char ver3;
char ver4;
unsigned int length;
int unknown;
unsigned int pagesize;
}
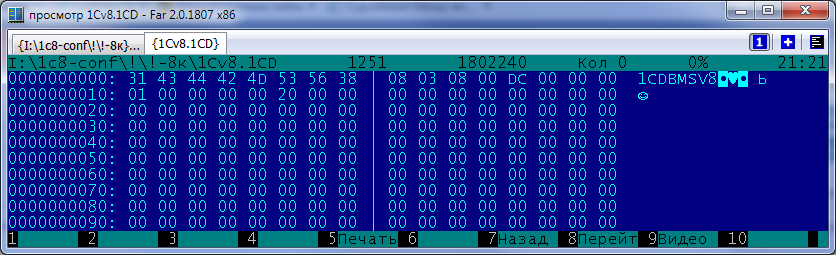
Заголовок базы формата 8.3.8 с размером страницы 8К
Объект - описатель свободных блоков
Структура описания объектов в новом формате заметно поменялась и теперь выглядит так:
struct {
unsigned int object_type; //0xFF1C
unsigned int pages_count;
int version;
unsigned int pages[];
}
Во-первых, изменились "магические символы" - теперь тип блока определяется 32-разрядным целым числом. Для типа "список свободных блоков" используется константа 0x0000FF1C. Следом идет количество свободных страниц в списке, затем нечто служебное, а затем список страниц таблицы размещения списка свободных блоков. Для размера страницы 4К в новом формате теперь под список страниц таблицы размешения отводится 1021 значение. Принципиально же склонность крупных баз к утечке свободных страниц новый формат не решает, точнее решает экстенсивным путем - за счет возможности увеличить размер страницы. Так, для размера страницы 8К в базе может храниться информация о (2048-3)*2048=4188160 свободных страницах, что соответствует примерно 32Гб свободного пространства. Таким образом если размер вашей базы заметно больше условно 5-6Гб имеет смысл попробовать перейти на новую платформу с увеличенным размером страницы.
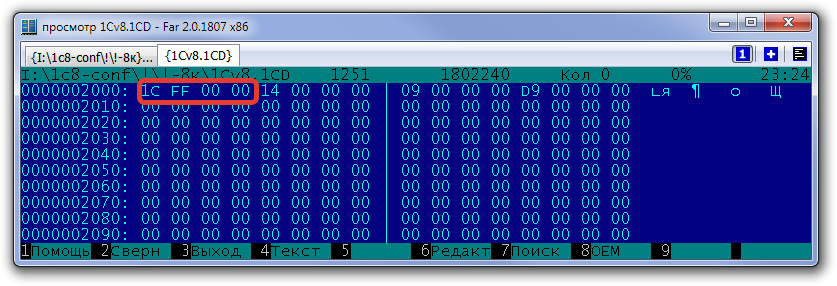
Описание объекта - списка свободных страниц в базе формата 8.3.8 с размером страницы 8К. В данном случае имеется только одна страница в таблице размещения - 0xD9, количество актуальных записей в списке - 0x14=20.
Прочие объекты
Структура объектов теперь выглядит следующим образом:
struct {
unsigned int object_type; //0xFD1C или 0x01FD1C
unsigned int version1;
unsigned int version2;
unsigned int version3;
unsigned long int length; //64-разрядное целое!
unsigned int pages[];
}
Следует обратить внимание на два момента. Первое - размер потока данных теперь описывается 64-разрядным (8-байтовым) значением. При размере страницы 8К или больше это становится актуальным.
Второе - на самом деле используется две версии такой структуры, сокращенная и полная. Сокращенная версия использует код типа объект 0xFD1C, и предназначена для небольших объектов, когда содержимое таблицы размещения может полностью поместиться в массив pages. Для размера страницы 4К это 1018 значений. В этом случае отдельная таблица размещения не используется. Как только количество страниц таблицы размещения превышают доступный размер массива pages, описание объекта конвертируется в полный формат - код объекта меняется на 0x01FD1C, содержимое массива pages выносится в отдельную таблицу размещения, а в массив pages помещаются номера страниц таблицы размещения. Для страницы в 4К сокращенный вариант используется для объектов с размером потока не более 1018*4096=4169728 байт. Для страницы в 8К это будет (2048-6)*8192=16728064 байт. Содержимое страниц таблицы размещения для полного формата тоже немного изменилось - теперь первое значение не используется для описания количества значений в странице, и для 4К страницы могут использоваться все 1024 значения.
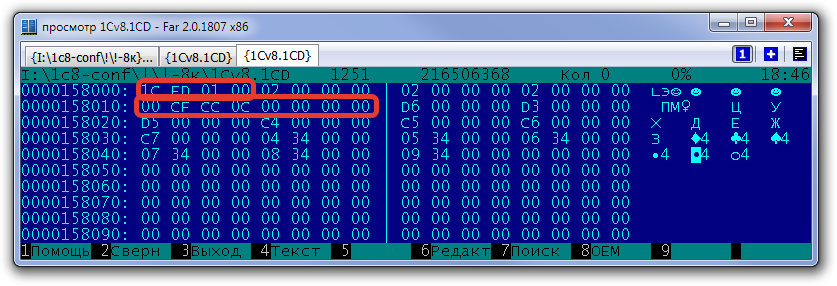
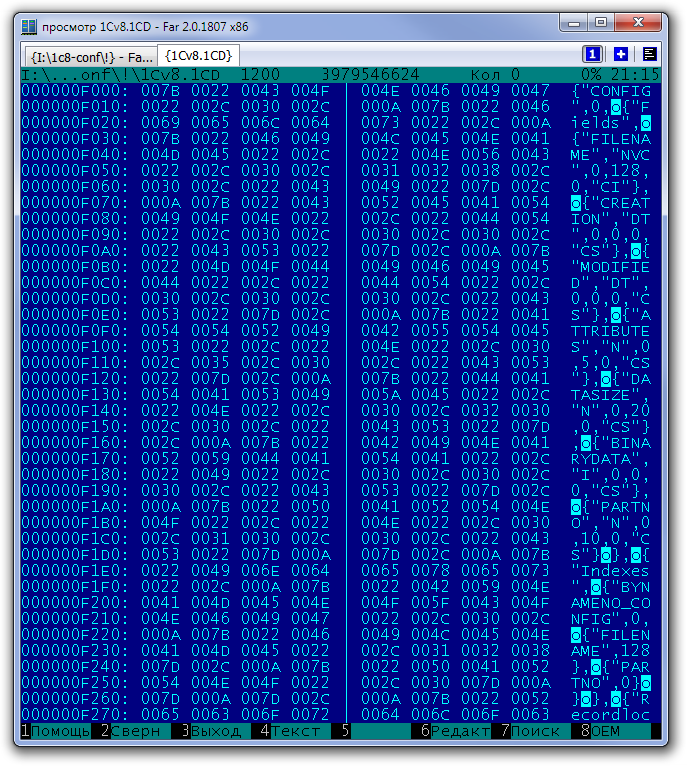
Пример описания полноформатного объекта в базе формата 8.3.8. Выделены поля с кодом типа объекта и размером объекта.
Рассмотрим максимальные размеры потоков объектов (или "внутренних файлов" называет их 1С в некоторых сообщениях об ошибках):
Под таблицу размещения отводится (РазмерСтраницы-24)/4 номеров страниц, каждый содержит до РазмерСтраницы/4 номеров страниц по РазмерСтраницы каждый. Если РазмерСтраницы=2^n, тогда максимальный размер объекта будет немного меньше 2^(3*n-4). Таким образом получаем:
| Размер страницы | Максимальный размер объекта |
|---|---|
| 4К | 4Гб |
| 8К | 32Гб |
| 16К | 256Гб |
| 32К | 2Тб |
| 64К | 16Тб |
Формат корневого объекта
Существенно изменился формат корневого объекта, содержащего ссылки на описания таблиц. Ранее описания таблиц размещались в отдельных объектах, а корневой объект содержал только ссылки на номера страниц этих объектов. В формате 8.3.8 структура потока корневого объекта полностью совпадает со структурой потока BLOB-а, поток так же разбит на блоки по 256 байт, каждый блок так же содержит 6-байтовый заголовок со ссылкой на блок с продолжением данных, а нулевой блок начинает цепочку свободных блоков в потоке.
Данные в первом блоке имеют формат (за исключением 6-байтового заголовка блока) корневого потока из формата 8.2.14:
struct {
char lang[32];
int numblocks;
int tableblocks[numblocks];
}
Но массив tableblocks содержит теперь не номера страниц в файле, а номера блоков в этом же потоке, в которых размещено описание таблиц. Таблицы описываются такой же структурой как и раньше, но используют однобайтовую кодировку (возможно UTF-8, на используемом наборе символов она не отличима от Win-1251 или ANSI).
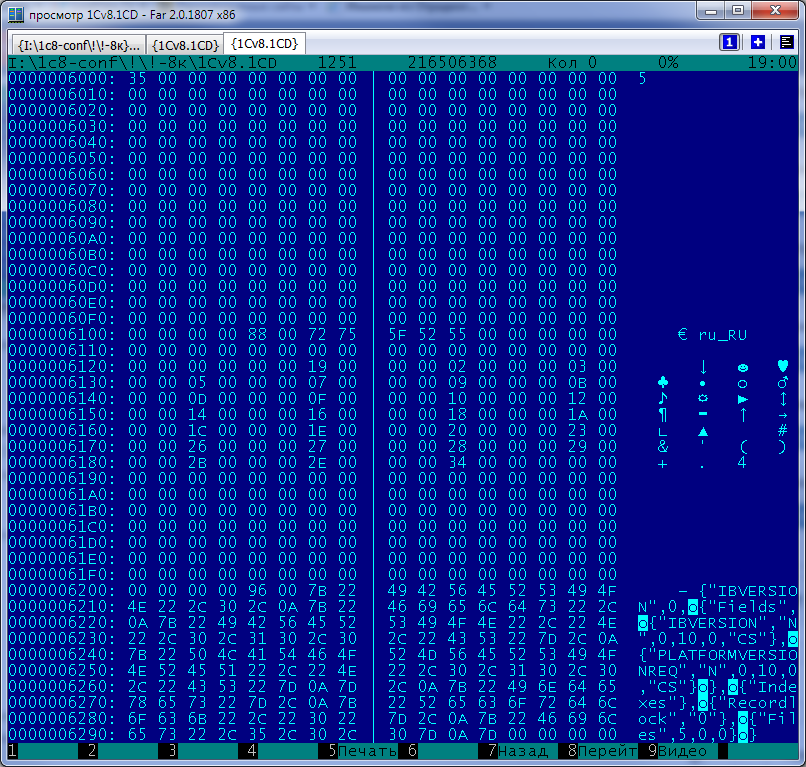
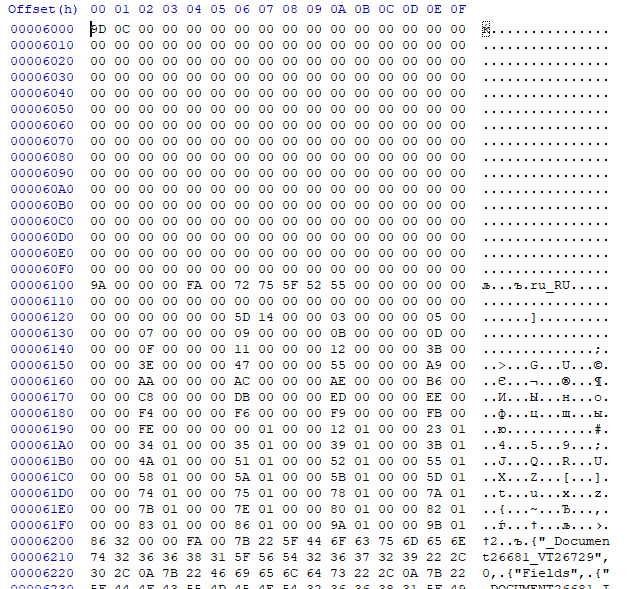
Начало корневого объекта
На приведенном рисунке виден пустой блок 0, ссылающийся на следующий пустой блок в этом потоке номер 0x35, содержимое блока 1 размером 0x0088 байт с идентификатором кодовой страницы ru_RU, размером таблицы 0x00000019 и 25 значений - номера блоков описаний 25 таблиц, в частности таблицы IBVERSION, размещенной в блоке 2.
3. Заключение
В новом формате 1С предусмотрела возможность увеличения размера страницы, что позволяет увеличить размер одного объекта более 4Гб и снизить вероятность самораспухания баз, содержащих более 4Гб данных. Были оптимизированы структуры описаний объектов и таблиц, что вряд ли даст заметный прирост производительности, но, в какой-то степени упрощает работу с базой на низком уровне.
Если есть замечания и дополнения, прошу писать в комментариях и я дополню статью
Вступайте в нашу телеграмм-группу Инфостарт

{kind=link}