Вместо дисклеймера: Это первая моя статья, поэтому прошу отнестись с пониманием. Цель - попытка показать возможности нового функционала на примере двух конкретных задач.
В ходе работы я столкнулся с двумя задачами, которые меня "зацепили", а их решения позаимствованные из открытых источников показались мне "нелогичными" и все они заключались в использовании временных файлов для преобразования типов данных, связанных с двоичными данными. Потратив немного времени, были найдены более "элегантные" пути решения.
Итак задачи:
- Собственная десериализация объектов из механизма версионирования объектов УПП. Задача - обойтись без временного файла.
- Получение данных из SQL базы с varbinary типом данных. Задача - уйти от использования COM объекта ADODB.Stream и временного файла.
Начнем по порядку.
1. Собственная десериализация объектов из механизма версионирования объектов.
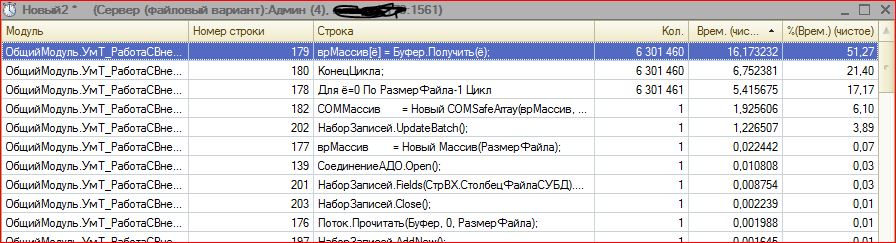
Здесь нет абсолютно никаких проблем. Объекты сериализуются стандартными механизмами и помещаются в регистр с ресурсом типа ХранилищеЗначений. И все хорошо за исключением последующей десериализации объектов. Для основы был взят механизм из отчета "История изменения объектов". Опускаем ненужное и идем к самой функции, которая из ресурса с типом ХранилищеЗначений получает строку для десерализации. Всю функцию приводить не буду, нам нужны строки преобразования двоичных данных в строковый тип:
ИмяВременногоФайла = ПолучитьИмяВременногоФайла();
ВерсияОбъекта.Записать(ИмяВременногоФайла);
ТекстовыйДокумент = Новый ТекстовыйДокумент;
ТекстовыйДокумент.Прочитать(ИмяВременногоФайла, КодировкаТекста.UTF8);
СтрокаXML = ТекстовыйДокумент.ПолучитьТекст();
УдалитьФайлы(ИмяВременногоФайла);
И как мы видим - используется механизм временных файлов. ВерсияОбъекта в данном случае имеет тип ДвоичныеДанные, получаемые из ресурса регистра с типом ХранилищеЗначения.
Сразу вопрос - есть ли возможность обойтись без его использования? Проблема заключается в том, что получив двоичные данные мы не можем преобразовать их в строковый тип для десереализации. Однако это не так. Немного покопавшись в великом СП, было найдено решение.
Собственно нас интересует объект "ЧтениеДанных", а точнее конструктор на основе двоичных данных. У этого объекта широйкий набор свойств и методов. И по СП видно, что нам пригодятся чтение данных в строковые типы - а именно два метода ЧтениеСтроки и ЧтениеСимволов. Первый дает возможность читать построчно, но это цикл и нам сейчас ни к чему. Второй читает количество символов, по умолчанию равное всему потоку. Его мы и будем использовать.
В качестве ремарки - оба метода имеют возможность указания вида кодировки в качестве параметра чтения, однако мы укажем кодировку в конструкторе объекта вторым параметром.
Почитав внимательно мы преобразуем код и получаем всего три строки:
Читатор = новый ЧтениеДанных(ВерсияОбъекта,КодировкаТекста.UTF8);
СтрокаXML = Читатор.ПрочитатьСимволы();
Читатор.Закрыть(); //не забываем чистить за собой
И в общем то все. Никаких временных файлов, на выходе строка для разбора десериализатором.
В голову приходит логичная мысль - для собственных целей мы получаем объект десереализацией по нашему новому алгоритму без временных файлов, но это не частая операция. А как выглядят дела с механизмом версионирования в принципе? Как происходит запись в регистр? Точнее нас интересует как происходит помещение данных в ХранилищеЗначения. Идем в общий модуль УПП реализующий версионирование и ищем то что нам нужно:
ИмяВременногоФайла = ПолучитьИмяВременногоФайла();
ЗаписьXML = Новый ЗаписьXML;
ЗаписьXML.ОткрытьФайл(ИмяВременногоФайла);
ЗаписьXML.ЗаписатьОбъявлениеXML();
ЗаписатьXML(ЗаписьXML, Источник, НазначениеТипаXML.Явное);
ЗаписьXML.Закрыть();
ДвоичныеДанные = Новый ДвоичныеДанные(ИмяВременногоФайла);
ХранилищеДанных = Новый ХранилищеЗначения(ДвоичныеДанные, Новый СжатиеДанных(9));
Бинго! В регистр уходит ХранилищеДанных, но используются временные файлы для формирования ДовичныхДанных. И это понятно конфигурация УПП должна иметь и обратную совместимость. Но у нас уже в руках новые технологии и мы хотим их использовать. В базе с 3000 активными пользователями каждую минуту формируются огромное количество объектов подлежащих версионированию, а значит здесь уже мы имеем возможность практического применения потоков для ускорения и удаления "слабого звена".
Абсолютно справедливо механизм работает и в обратную сторону при помощи объекта ЗаписьДанных. Однако если при чтении мы уже имеем двоичные данные, которые по сути являются потоком данных и нам нет необходимости его формировать, то при записи нам потребуется поток который мы затем и выгрузим как двоичные данные, а запись в этот поток осуществляется объектом ЗаписьДанных:
ЗаписьXML = новый ЗаписьXML();
ЗаписьXML.УстановитьСтроку();
ЗаписьXML.ЗаписатьОбъявлениеXML();
ЗаписатьXML(ЗаписьXML, Источник, НазначениеТипаXML.Явное);
СтрокаXML = ЗаписьXML.Закрыть();
Поток = новый ПотокВПамяти();
Запись = новый ЗаписьДанных(Поток,КодировкаТекста.UTF8);
Запись.ЗаписатьСимволы(СтрокаXML);
Запись.Закрыть(); //не забываем чистить за собой
ДвоичныеДанные = Поток.ЗакрытьИПолучитьДвоичныеДанные();
ХранилищеДанных = Новый ХранилищеЗначения(ДвоичныеДанные, Новый СжатиеДанных(9));
И опять никаких временных файлов. На что стоит обратить внимание - кодировка как и в первом случае может указываться в конструкторе объекта ЗаписьДанных, так и в его методах при непосредственной записи. Кроме того кодировка может указываться и в сериализации, но это уже другая история. Мы снова используем метод записи символов, но можем так же использовать и построчную "порционную" запись.
Код вышел чуть длиннее, но у нас нет временных файлов, все происходит в памяти. Вот так бесхитростно мы оптимизировали версионирование объектов в УПП.
Все выше перечисленное - очевидное использование Потоков. Теперь же сладкое - неочевидное использование потоков, а именно конкретная задача по чтению данных из SQL.
2. Получение данных из SQL базы с varbinary типом данных.
Возникла задача - создать обработку, которая будет обращаться к внешней базе данных на MS SQL и хранить в ней макеты текущих версий разрабатываемых внешних обработок. Такой некий совсем простой аналог GIT. Это обработки начального заполнения данных из разных источников, а необходимость хранения во внешнем источнике так как в процессе разработки параллельно тестируется около 20 баз и потребовался единый источник обработок заполнения. Возможно подход и неправильный, но речь сейчас не об этом.
В ходе работы с ADODB возникла проблема получения двоичных данных из varbinary типа SQL. Все кто работал и сталкивался понимают о чем идет речь - при получении значения из базы через ADODB.Recordset нам вываливается значение типа COMSafeArray с целочисленными элементами.
Не надо быть гением чтобы понять, что нам вываливают байты в десятиричном исчислении. Просто попытавшись перевести их в 16-тиричный формат это становится очевидным, а сам массив и есть наша последовательность байтов - по сути поток двоичных данных. Все решения найденные в "этих ваших интернетах" сводятся к одному - использовать ADODB.Stream, в котором как раз таки есть функция преобразования такого потока данных в файл, который нам и предлагают затем читать. Полное описание и способы работы не буду приводить, так как не в этом цель. Главное что следует понять ADODB.Stream есть ничто иное как обертка работы с потоками, а если у нас теперь есть возможность работать с потоками в 1С, значит все что делает эта обертка, мы можем сделать штатными средствами.
Начинаем копать и думать. Первая мысль - преобразовать каждый элемент в 16-тиричный формат и попытаться сформировать двоичные данные по символьным значениям. Но через 30 секунд отметаем идею - она тупиковая так как налицо избыточность используемых объемов памяти, и "детскость" в подходе. Вывод - смотрим в сторону потоков в 1С. Мы понимаем что наш COMSafeArray это и есть поток данных, но в "особом" виде. Курим СП выискивая возможность формирования потока в 1С на основе нашего. Основной объект который мы смотрим ПотокВПамяти. Понятно что нам надо формировать его, однако не очевиден способ.
Вертим объект Поток со всех сторон и не находим методов нас удовлетворяющих. Однако находим зацепку - поток данных можно сформировать конструктором на основе буфера. Курим объект БуферДвоичныхДан
ных в СП и выясняем что БуферДвоичныхДанных согласно СП это:
Описание:
Коллекция байтов фиксированного размера с возможностью произвольного доступа и изменения по месту.
Дак это то что надо! Это и есть словесное описание того результата, что мы получаем из SQL. Смотрим методы и находим то, что нужно:
Синтаксис:
Параметры:
<Позиция> (обязательный)
Позиция, на которую требуется поместить новое значение.
<Значение> (обязательный)
Значение, которое требуется установить в заданную позицию буфера.
Если значение больше 255 или меньше 0, будет выдана ошибка о неверном значении параметра.
Описание:
Устанавливает значение элемента на заданной позиции (нумерация начинается с 0).
Почему именно тут мы танцуем джигу? Потому что мы изначально работаем с набором байтов в виде массива чисел от 0 до 255, и тут без каких либо преобразований нам предлагают установку этих байтов в виде этих же самых чисел от 0 до 255. На что обращаем внимание - конструктор буфера подразумевает заранее известную длину, а методом придется писать однозначно в цикле. Остальное - дело техники, поток сформировать по буферу и выгрузить в двоичные данные мы уже пробовали.
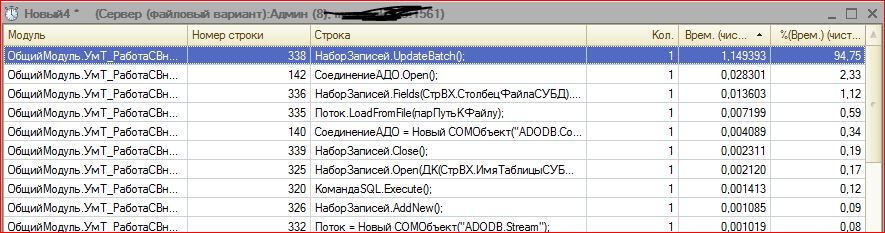
Вот код с использованием ADODB.Stream:
Функция ПолучитьФайлАДО_Stream(Value)
Файл = Неопределено;
Stream = Новый COMОбъект("ADODB.Stream");
Stream.Type = 1;
Stream.Open();
Stream.Write(Value);
ИмяФайла = ПолучитьИмяВременногоФайла();
Stream.SaveToFile(ИмяФайла);
Stream.Close();
Файл = Новый ДвоичныеДанные(ИмяФайла);
УдалитьФайлы(ИмяФайла);
Возврат Файл;
КонецФункции
Пример вызова:
Файл = ПолучитьФайлАДО_Stream(АДОНаборДанных.Fields(2).Value);
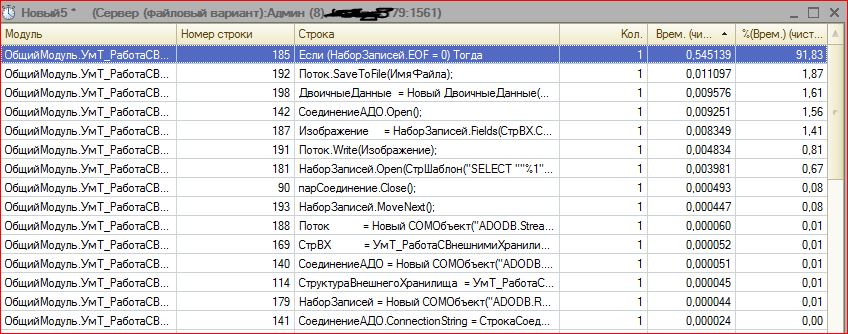
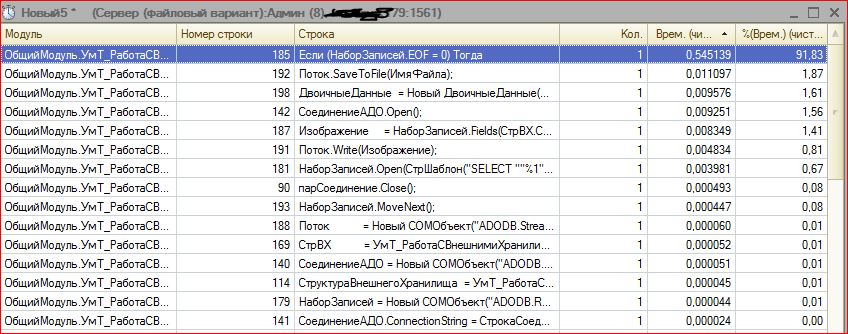
Итак, код функции получения файла без использования ADODB.Stream и временных файлов.
Функция ПолучитьФайлАДО(Массив)
Длинна = Массив.Количество();
Буфер = новый БуферДвоичныхДанных(Длинна);
Для индекс = 0 по Длинна - 1 Цикл
Буфер.Установить(индекс,Массив[индекс]);
КонецЦикла;
Поток = новый ПотокВПамяти(Буфер);
ДвоичныеДанные = Поток.ЗакрытьИПолучитьДвоичныеДанные();
Возврат ДвоичныеДанные;
КонецФункции // ПолучитьФайлАДО()
И вызов этой функции при чтении данных (выдержка из кода моей функции):
Пока не АДОНаборДанных.eof() Цикл
Строка = ТЧОбработки.Добавить();
Строка.ИмяОбработки = АДОНаборДанных.Fields(1).Value;
Если ТипЗнч(АДОНаборДанных.Fields(2).Value) = Тип("COMSafeArray") Тогда
Строка.Макет = ПолучитьФайлАДО(АДОНаборДанных.Fields(2).Value.Выгрузить());
Строка.Запустить = "Запустить";
КонецЕсли;
АДОНаборДанных.MoveNext();
КонецЦикла;
В качестве пояснения - проверка на тип COMSafeArray нужна для исключения NULL. Ну и с помощью Выгрузить() делаем сразу преобразование в обычный массив. Зачем? Просто так захотелось. Можно работать и без выгрузки прямиком с COMSafeArray.
Итого - мы получили двоичные данные без временных файлов и дополнительной внешней компоненты.
Все выше описанное - лишь верхушка айсберга в виде мощного инструмента работы с двоичными данным. Не затронуты темы порядка чтения и записи, частичного чтения и записи и многих других аспектов.
В качестве вывода - об использовании временных файлов в 1С можно забыть.
Upd: Исправил орфографические ошибки. Спасибо всем, кто обратил внимание.
Вступайте в нашу телеграмм-группу Инфостарт