Содержание:
- Пользовательская история
- Критерии оценки вариантов
- Событийная модель и RMQ
- Маршрутизация в RMQ
- Принцип работы БСП по обработке сообщений в формате Enterprise Data
- Моделирование
- Механизм оповещения об ошибках
- Коллективная работа с КД3 и с универсальным форматом
- Механизм автотестирования
- Итоги проекта
- Полезные ссылки
Пользовательская история
Зайдя на проект, мы услышали следующую историю:
Исходное состояние:
Сложный ландшафт производственной компании, состоящий из нескольких территориально-распределенных систем на базе 1С:УПП, одну из которых планируется заменить на 1С:ERP в качестве основного результата проекта. Параллельно с ERP планируется внедрить новую версию PLM взамен старой. Кроме УПП есть другие 1С-системы: MDM, WMS, ТОИР и ЗУП2.5, которые по возможности надо оставить без изменений. Система MDM является основным, но не единственным поставщиком НСИ: например, физические лица рождаются в ЗУПе, полуфабрикаты в PLM, договоры в ERP. Между всеми системами действует обмен типа точка-точка, написанный на "1С:Конвертация данных 2.0", транспорт - XML-файлы через общие папки. Все конфигурации сильно кастомизированы.
Требования к результатам проекта в части интеграции:
- сократить время синхронизации данных между системами с 15-60 минут до нескольких секунд
- систематизировать и сделать прозрачной разработку и хранение правил обмена, чтобы облегчить работу службы поддержки и минимизировать трудозатраты разработчиков в будущем при добавлении в обмен новых объектов или даже новых информационных систем
- по факту возникновения ошибок обмена уведомлять систему Help Desk о каждом недоставленном объекте. После устранения причин сбоя недоставленные объекты должны быть переотправлены автоматически, чтобы исключить любые потери
- новый релиз правил обмена должен предварительно проходить автоматическое регрессионное тестирование, чтобы гарантировать целостность работающих правил
- применение нового релиза правил обмена не должно вынуждать пользователей переподключаться к системе
- в качестве потенциальных решений транспортного механизма рассматриваются:
-- web-сервисы,
-- Axelot Datareon ESB
-- БИТ:Адаптер, в котором используется внешняя компонента YellowRabbitMQ для работы с RabbitMQ от "Серебряной пули".
- времени на принятие концепции и ее реализацию - 5 месяцев
ОК, прежде чем генерить идеи, команда сформулировала:
Критерии оценки вариантов
- Тестируемость
- Скорость
- Оптимальность потоков
- Независимость от обновления
- Трудоёмкость
- Централизация правил обменов (унификация)
- Поддержка событийной модели
Мы отлично понимали две вещи:
1. Действующие правила на КД2 представляют большую ценность, неплохо бы их сохранить или максимально использовать. С одной стороны они учитывают нюансы всех доработанных конфигураций, в них заложено много человеко-часов. Но с другой стороны правила эволюционировали вместе с конфигурациями в течении 5 лет, писались разными людьми, одна волна накладывалась на другую, накопилось много противоречий и костылей, поэтому оптимальность кода скорее всего низкая.
2. Кроме того на выходе проекта одна УПП должна быть заменена на ERP, а ERP обменивается со всеми остальными системами, значит придется переписать все правила как минимум в части загрузки-выгрузки на стороне ERP.
Далее идут варианты решений, вынесенные на обсуждение, в самом конце будет победитель:
Вариант №1. Вариант с Datareon сразу не прошел ни по срокам, ни по бюджету. Когда знакомишься с такими предложениями, на ум приходит треугольник качества имени Артемия Лебедева: "Долго, дорого, ах...нно!". Интересно, но не в этот раз, возможно когда интеграция будет единственным результатом проекта.
Вариант №2. Во всех информационных системах обновить версию БСП до последней, в которой появились web-сервисы в качестве транспорта для синхронизации данных, и продолжить использование существующие правила КД2. В принципе идея неплохая, учитывая, что 1С в последних версиях платформы 8.3 потрудился над кешированием открытия WS-сессий и заставил их работать реально быстро. Но в нашем проекте мы имели пять ИБ под 8.2, две из которых аж с уровнем совместимости 8.2.13, повышать который еще то развлечение. Следуя древнему принципу "работает - не трогай", мы решили не ворошить мамонтов.
Вариант №3. Создать 1С-базу в роли посредника обмена (аналог шины данных), архитектура данных которой будет похожа на заменяемую УПП и содержать объекты с максимальным количеством реквизитов, участвующих во всём обмене. Правила для обмена будут создаваться в КД2. Потоки данных будут входить в нее и расходиться в соответствии с правилами маршрутизации, заложенными внутри нее. Т.е. базам-отправителям необязательно знать обо всех получателях, их задача передать данные в одну эту базу. Плюсы: больше половины существующих правил КД2 удастся сохранить и использовать. Минусы: оперативность доставки будет недостаточная, потому что файл сообщения КД2 несет в себе схему данных и правила всех преобразований на стороне Получателя, а в рамках событийной модели каждый объект будет отправляться отдельным сообщением, даже если использовать web-сервисы или RMQ, каждое сообщение будет перегружено лишней информацией и накладные расходы на доставку будут чувствительны. Кроме того, еще одна 1С-база будет отжирать серверные ресурсы.
Вариант №4. Сымитировать в конфигурации КД2 концепцию КД3. Если представить универсальный формат Enterprise Data в виде реально существующей конфигурации и написать пару правил Источник->ED и ED->Получатель, при этом программные преобразования на стороне ED как получателя и отправителя свести к нулю, то для каждого направления обмена можно сложить, как из мозаики свой набор правил. Например, можно написать правила для MDM-ED, ED-ERP, ED-УПП, а на выходе получить скомпонованные правила для MDM-ERP и MDM-УПП. Конечно потребуется доработка КД2. Этот вариант по плюсам схож с №3, но в нем нет главного минуса - базы посредника, значит обмен будет идти быстрее. Но все равно недостаточно быстро из-за КД2-сообщения, перегруженного служебными данными.
Вариант №5. Реализовать концепцию, предлагаемую БИТ:Адаптером - база-отправитель является источником XSD-схемы данных, преобразования при отправке практически минимальны, основное преобразование происходит непосредственно на стороне получателей. Эта модель победила во всех номинациях, кроме "Унификация" и "Централизация". Мы увидели в ней много низкоуровневого кода - как потенциального источника ошибок и непрозрачности. Роль разработчиков выходит на первый план. Но концепция действительно рабочая в тех проектах, где нет строгих требований к централизации, и количество объектов обмена и сложность их преобразований невысокая. По мнению БИТа, она является эволюционной с точки зрения развития интеграционного контура предприятия: встраивание новых информационных систем происходит в основном силами разработчиков, ответственных за новые системы.
Вариант №6. Идея универсального формата и КД3 была принята большинством голосов. Как ни странно, она тоже является эволюционной при определенных обстоятельствах. Нет, когда в интеграционном контуре всего две-три информационные базы с сильно непохожими конфигурациями, кажется избыточным выполнение двойной работы по написанию правил выгрузки из источника в универсальный формат и из универсального формата в получателя. Но когда у каждой из трех непохожих баз есть очень похожие родственники, как в нашем случае два семейства: пять УПП-образных баз, две ERP-образных, и одиноко стоящий ЗУП2.5 по сути осколок УПП; и когда из любой базы данные могут передаваться в любые другие базы, идея с универсальным форматом уже не кажется дикой, напротив вполне рабочей. Ведь по сути типовые конфигурации 1С делятся на старые и новые архитектурные поколения, если в информационном ландшафте организации присутствует оба поколения, и для обоих написаны правила преобразования к универсальному формату, то никаких сюрпризов больше не будет. Отраслевые решения, такие как Axelot:WMS или Appius:PLM вынуждены архитектурно подстраиваются под современные типовые конфигурации. А если в ландшафт зайдет не 1С-система, типа SAP, никто не мешает договориться с сапёрами использовать существующий универсальный формат, или если сапёры упрутся, инкапсулировать их формат в существующий универсальный формат. Выбирая вариант №6, мы сознательно отказываемся от тяжёлого наследия КД2-правил и переходим к полноценным КД3-правилам. Конечно мы будем использовать код из старых правил КД2, и конечно мы будем подглядывать в типовые правила КД3. И мы сознательно идем на реформацию старых правил, т.к. это часть требований проекта.
Итоговый подсчет очков по 5-бальной шкале:
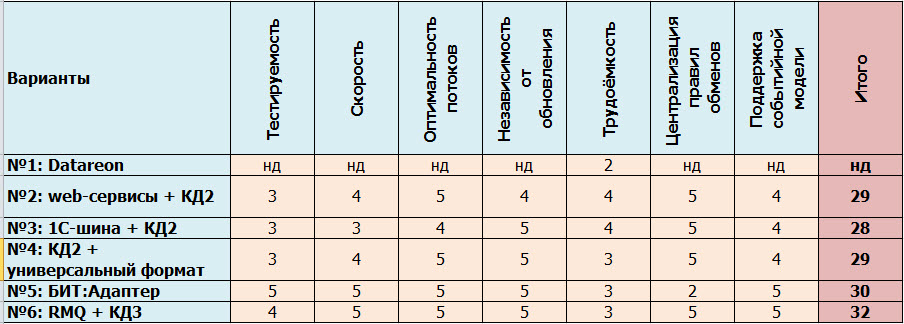
Все шесть вариантов были про концепцию правил обмена. Время поговорить про обмен в режиме on-line, событийную модель и способы доставки сообщений.
Событийная модель и RMQ
Тут всё просто. Событийная модель позволяет забыть про планы обмена и связанные с ними пакетные выгрузки. Проще говоря, больше нет необходимости накапливать ссылки на измененные объекты, а потом в условленный час отправлять большую телегу, в которую попадают только последние версии объектов. Теперь мы можем отдавать миру объект атомарно, столько раз, сколько успешно завершилась транзакция при его изменении. При этом отправитель не обязан ждать подтверждения доставки, его миссия закончилась, когда сообщение ушло за его пределы. За доставку и обработку сообщений отвечают другие системы. Безошибочная доставка и обработка сообщений - это нормальное поведение интеграционного контура, не надо тратить ресурсы на уведомление об этом. Извещать отправителя надо только в случае ненормального поведения.
Считается, что основная ценность событийной модели - не столько в оперативности доставки, сколько в соблюдении хронологии событий. У типичного брокера сообщений типа RabbitMQ три главные задачи: быстро получать сообщения из разных источников, быстро перенаправлять сообщения в одну или несколько очередей согласно правилам маршрутизации, и обеспечивать быстрое чтение очередей по методу FIFO. Фишка RMQ еще и в том, что он принципиально не хранит прочитанные сообщения, что делает его слегка безалаберным, но в то же время не слишком требовательным к файловым ресурсам, что радует.
Собственно чтение очереди по FIFO и даёт гарантию соблюдения хроники. Это ключевая функция RMQ, которая гарантирует правильное соблюдение цепочки бизнес-процессов на стороне получателя. Например, сначала должен появиться договор, а затем проведен инвойс по этому договору. Но бывают ситуации, когда допускается несоблюдение последовательности действий, если это не влияет на бизнес. Например, многие типовые конфигурации в пределах одной транзакции сначала создают подчиненный элемент, а потом самого владельца. С точки зрения событийной модели - это два разных события, которые будут воспроизведены на стороне получателя в такой же последовательности, и подчиненный элемент поживет какое-то время с битой ссылкой на владельца. Если это не повлияло на проведение документов, то бизнес ничего не заметит и все будут счастливы. Но если доставка новой номенклатуры задержалась на 15 минут или вообще остановилась, а через 15 минут начали поступать накладные с этой номенклатурой и их проведение остановились, то бизнес это почувствует и встанет на дыбы. Поэтому событийная модель должна быть обогащена системой приоритизации ошибок. Если упаковка прилетела без номенклатуры, мы позволяем ее записать с битой ссылкой и не считаем за ошибку. Если накладная прилетела без номенклатуры, то считаем это ошибкой и фиксируем ее в Help Desk как критический инцидент.
Маршрутизация в RMQ
Немного про маршрутизацию сообщений в RMQ. Сообщение RMQ состоит из шапки (Header) и доставляемых данных (Payload). В Header есть свойства:
Exchange - точка обмена, в нее отправители передают сообщения. Exchange бывают разных типов по способам маршрутизации. Мы использовали тип topic. Exchange хранит правила маршрутизации (Bindings), в соответствии с Bindings RMQ перенаправляет сообщение в очереди (Queues)
Routing Key - ключ маршрутизации
Properties - произвольный набор служебных параметров, которые помимо самого XML-объекта мы хотим показать получателям
Например, мы хотим, чтобы сообщение с XML-образом нового элемента номенклатуры было доставлено из MDM в PLM и ERP. Создаем в RMQ:
- две очереди Data_PLM и Data_ERP
- точку обмена Data
- в точке обмена Data создаем правила маршрутизации:
-- Если Routing Key содержит #.PLM.# - перенаправлять в очередь Data_PLM
-- Если Routing Key содержит #.ERP.# - перенаправлять в очередь Data_ERP
Здесь точка - это разделитель между словами, решётка - это маска для любого количества произвольных символов.
Теперь если мы из MDM отправим в RMQ сообщение, в котором Exchange = Data и Routing Key = .PLM.ERP., то RMQ переправит такое сообщение в две очереди Data_PLM и Data_ERP. Т.е. за формирование строки Routing Key отвечает база-источник, а за выполнение самой маршрутизации отвечает RMQ, при этом из базы источника в RMQ отправляется всего одно сообщение, а размножение этого сообщения на нужное количество сообщений и помещение их в очереди происходит в RMQ.
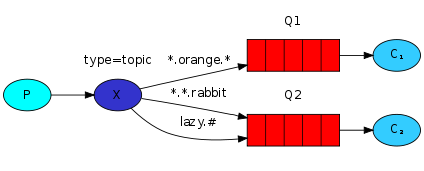
Разумеется Exchanges, Bindings и Queues в RMQ надо создать заранее, перед началом обмена.
Более подробно про маршрутизацию RMQ можно почитать тут или найти описание протокола AMQP, он реализован не только в RMQ.
RabbitMQ является свободным программным обеспечением, мануал по установке на CentOS тут. За внешнюю компоненту конечно придется заплатить. Мануал ВК YellowRabbitMQ можно почитать тут. Форум Пули про YellowRabbitMQ тут. При покупке компоненты вам подскажут адрес облака. Но не спешите делать выводы о производительности, у бесплатного сервиса ограничена пропускная способность, лучше заведите Кролика в своей локальной сети. У него достаточно скромные аппетиты к железу, мы использовали такую машину: vCPU (Core) / vRAM Gb / vSSD Total Gb - 2 / 4 / 100.
Принцип работы БСП по обработке сообщений в формате Enterprise Data
Первый релиз КД3 вышел 30.04.2015, в том же году в БСП 2.2 в подсистеме "ОбменДанными" появилась возможность обрабатывать сообщения через универсальный формат. Технология достаточно старая, 1С не собирается от нее отказываться и активно развивает, выпуская готовые правила для большинства современных типовых конфигураций, доведя количество релизов ED до шести.
КД3 обновляется не так часто, как хотелось бы. Последний релиз датируется 27.04.17, и там есть что дорабатывать. Но то что уже есть вполне пригодно, в том числе для коллективной разработки. Сердце КД3 - генератор кода - очень удобная фича: в визуальном конструкторе КД3 можно просто накликать передаваемые свойства и тут же получить модуль с кодом, что само по себе уменьшает трудозатраты и вероятность появления ошибок. Наполнение и отладку обработчиков "При отправке", "При конвертации данных XDTO", "Перед записью полученных данных" можно продолжить уже в целевой конфигурации. Модуль с кодом правил в типовых конфигурациях называется МенеджерОбменаЧерезУниверсальныйФормат. Кто помнит танцы с бубнами для отладки правил КД2, тот возрадуется!
Модуль БСП, формирующий XML-сообщение из выборки данных и получающий данные из XML-сообщения, называется ОбменДаннымиXDTOСервер. Описание универсального формата хранится в типовых конфигурациях в XDTO-пакетах с именами типа EnterpriseData_1_X. Мы возьмем за основу версию 1.5, т.к. на момент проекта она была последней.
Формат сообщения хранится в XDTO-пакете ExchangeMessage. Сообщение в универсальном формате имеет такую же структуру, как и в RMQ: шапка Header и тело сообщения Body. Body не является частью какого либо формата, это искусственный XML-элемент, поэтому оставим его для эстетики. Шапку для RMQ будем формировать сами, поэтому от ExchangeMessage надо избавляться. Но ExchangeMessage хранит в себе тип значения Ref, который используется как базовый тип в EnterpriseData, а в модуле ОбменДаннымиXDTOСервер используется в функции ЭтоСсылкаXDTO(). Значит тип Ref надо перенести в EnterpriseData, переписать ссылки на него, и доработать функцию ЭтоСсылкаXDTO().
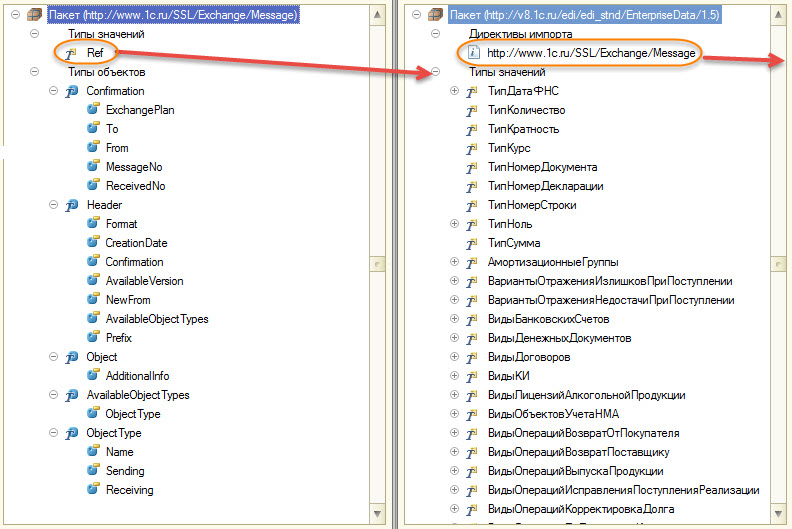
Конечно это не единственная доработка модуля ОбменДаннымиXDTOСервер и XDTO-схемы EnterpriseData. Нам предстоит сделать обособленную подсистему, со своими префиксами имен объектов конфигурации и своим URI пространства имен, чтобы они не пересекались с типовыми, когда будем встраивать их в целевые конфигурации информационных баз, участвующих в обмене.
Как вы понимаете, мы собираемся разрабатывать свой универсальный формат, а EnterpriseData_1_5 возьмем в качестве отправной точки. Согласно условиям проекта мы должны применять новые версии правил бесшовно, не изменяя конфигурации и не прерывая сессии пользователей, поэтому хранить XSD-схему формата и модуль менеджера обмена будем в виде бинарных данных в служебных справочниках, которые будем быстро обновлять непосредственно из КД3 по мере выпуска новых версий формата и правил, используя свой же механизм синхронизации.
Модуль с кодом правил будем хранить в модуле внешней обработки, файл которой будем компоновать автоматически из КД3, запуская конфигуратор в пакетном режиме с параметром LoadExternalDataProcessorOrReportFromFiles.
Впрочем, обо всем по порядку.
Моделирование
Выше мы приняли решение применять концепцию событийной модели, формировать правила обмена в КД3, использовать универсальный формат ED, доставлять сообщения через RabbitMQ, оповещать базы-отправители только об ошибках. Опишем поведенческую модель механизма обмена. По нашей практике моделирование позволяет увидеть и учесть все нюансы прежде чем приступать к выработке архитектурного решения.
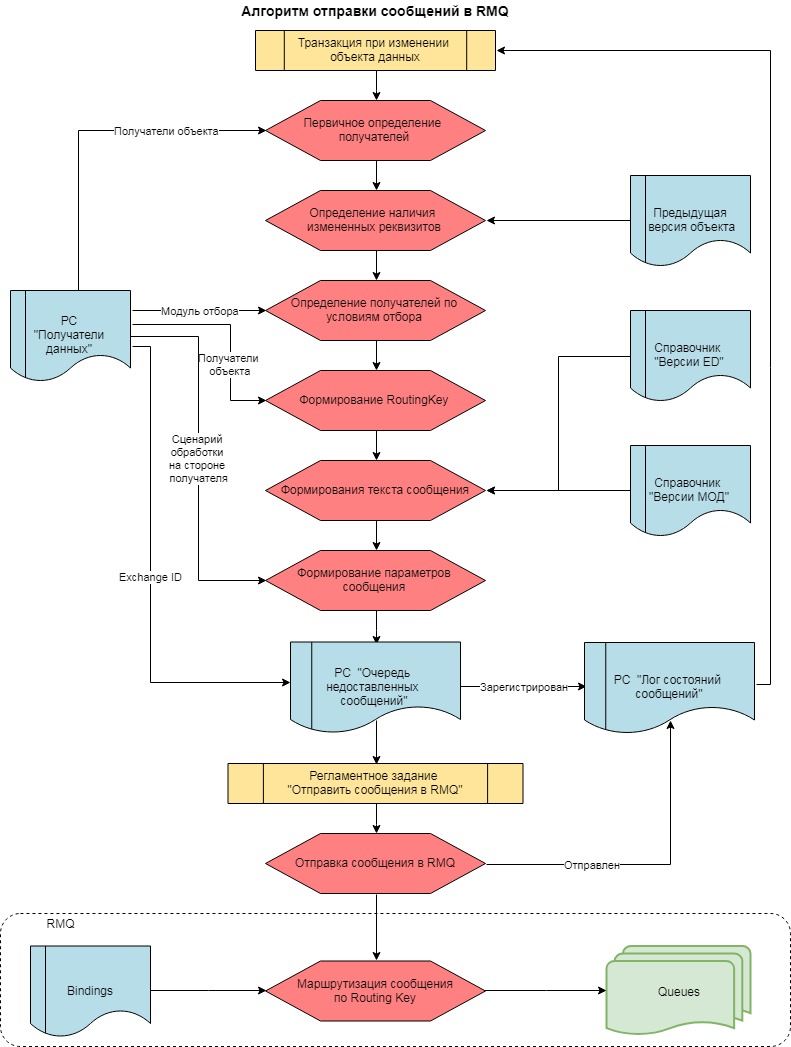
Шаг №1 "Регистрация"
При записи объекта данных на стороне отправителя:
Шаг 1.1. Определяем, участвует ли объект метаданных в обмене
Шаг 1.2. Определяем наличие изменений в сравнении с последней версией объекта. Это опциональная фича - защита от повторной передачи одинаковых данных с целью экономии трафика. В КД2 это называлось "Фильтр выборочной регистрации объектов". Это не просто сравнение двух XML-текстов, полученных методом СериализаторXDTO.ЗаписатьXML. Правильно сравнивать только те реквизиты, которые участвуют в обмене. Ну или хотя бы исключить общие реквизиты, типа "Дата изменения", опять же если они не участвуют в обмене.
Шаг 1.3. На основании правил регистрации данных определяем, каким получателям этот объект должен быть доставлен, и формируем строку Routing Key. Правила регистрации хранятся в РС "Получатели данных". Сами правила - это произвольный текст с кодом, или другими словами "Модуль отбора", цель которого - определить булево значение переменной "Отказ". В каждой базе-отправителе, для каждого типа данных, участвующего в обмене, для каждого получателя этого типа данных надо создать отдельную запись РС "Получатели данных". Если в каком-то направлении при определенных условиях данные не должны передаваться - тогда пишем код для этого условия в модуле отбора.
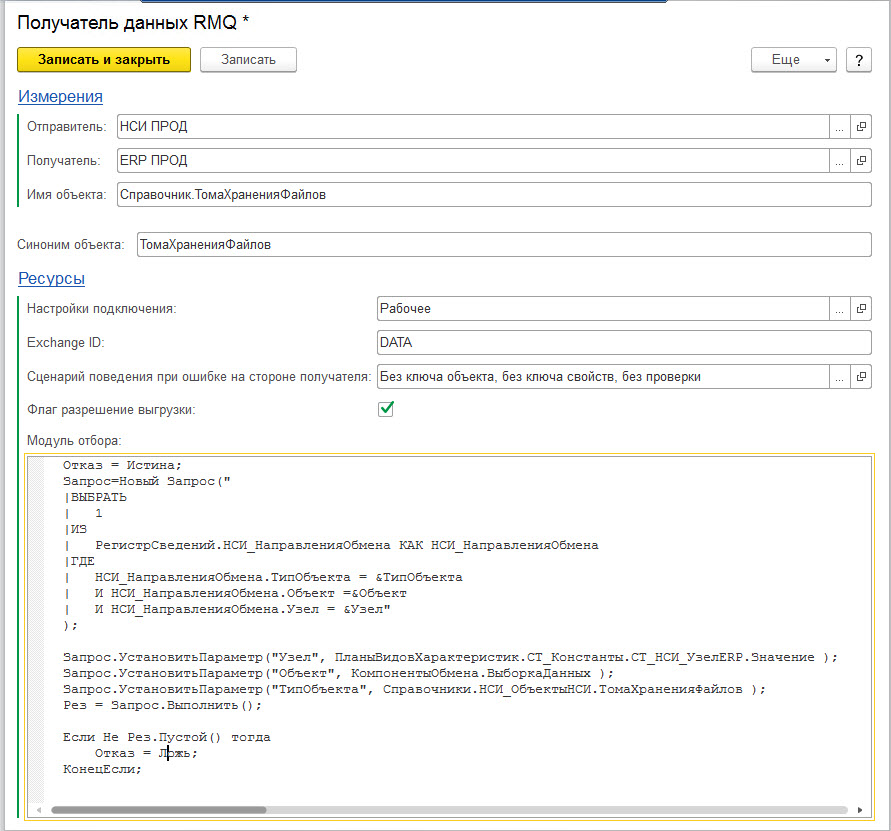
Шаг 1.4. Определяем последнюю версии формата и модуля менеджера обмена. Зачем вообще версионировать формат и менеджер обмена? Допустим мы обновили версию формата одновременно во всех базах, но в очередях остались непрочитанные сообщения, сформированные с помощью предыдущей версии формата. Значит получатели должны иметь доступ ко всем предыдущим версиям формата и к последней версии менеджера каждой версии формата. Кроме того на случай отказа последней версии менеджера (если модуль не проходит проверку при компиляции из-за малейшей синтаксической ошибки - останавливается работа всех правил!) мы всегда должны иметь возможность откатиться на предыдущую стабильно работающую версию менеджера, хотя бы для передачи служебных данных (тех же версий форматов и менеджеров). В идеале мы конечно исключаем вероятность помещения в продуктив не протестированных версий, но разработчики в тестовом контуре должны иметь право на ошибку.
Шаг 1.5. С помощью доработанного модуля ОбменДаннымиXDTOСервер формируем текст XML-сообщения в формате Enterprise Data.
Шаг 1.6. Формируем параметры сообщения:
-- Exchange ID: это обязательный параметр, он указывает RMQ какая точка обмена будет обрабатывать сообщение. У каждой точки обмена свой набор правил маршрутизации. Наличие разных точек обмена расширяет возможности маршрутизации. Мы создали три точки обмена: XSD (для версий форматов и менеджеров обмена), DATA (для пользовательских данных) и LOG (для РС "Состояния сообщений" и "Ошибки обмена"). Сообщение с Exchange = XSD и RoutingKey = .ERP.PLM., будет переправлено в очереди XSD_ERP м XSD_PLM. Сообщение c Exchange = DATA и RoutingKey = .ERP.PLM. будет переправлено в очереди DATA_ERP и DATA_PLM. Хотя обе очереди XSD_ERP и DATA_ERP читает одна база ERP, приоритет обработки у них разный. Служебные данные надо доставлять в первую очередь. Получатели должны сначала выбрать все сообщения из очереди XSD, и только после этого приступить к очереди DATA.
-- идентификатор сообщения (Message ID): для облегчения отслеживания маршрута сообщения при разборе полетов
-- системное время события - время в миллисекундах завершения транзакции для соблюдения событийной модели (результат функции ТекущаяУниверсальнаяДатаВМиллисекундах)
-- сценарий обработки на стороне получателя: здесь может быть раздолье для творчества. Например, сколько раз делать попытку записи при конфликте блокировок транзакций, или что делать с документом, если он проводится с ошибкой, или снимать ли контроль при записи (ОбменДанными.Загрузка = Истина)
-- указатель на объект данных: сериализованный в XML однозначный идентификатор объекта данных, пригодится при разборе сбойных ситуаций, в частности для повторной отправки недоставленных сообщений. Для ссылочных типов - это пара "тип метаданных" и GUID ссылки, для регистров сведений - набор измерений.
-- HASH указателя на объект данных: его будем использовать на этапе записи объекта на стороне получателя: на случай если один и тот же объект передаётся в коротком интервале времени - будем использовать последовательную, а не параллельную обработку сообщений, но об этом чуть ниже. Сам HASH будет иметь тип УникальныйИдентификатор, полученный из предыдущего параметра (указатель на объект данных) по алгоритму MD5. Для совместимости с 8.2 алгоритм MD5 придётся брать из Windows, а не из платформы 1С, платформа .NET Framework обязательно должна стоять на машине с сервером 1С, чтобы обеспечить вызов COM-объектов:
Crypt = Новый COMОбъект("System.Security.Cryptography.MD5CryptoServiceProvider");
Text = Новый COMОбъект("System.Text.UTF8Encoding");
Шаг 1.7. Записываем полученное сообщение в регистре "Лог недоставленных сообщений"
Шаг 1.8. Записываем событие "Зарегистрирован" в регистр "Состояния сообщений"
Все механизмы шага №1 должны выполняться с максимальной скоростью, и защищены от каких либо падений по ошибкам, так как происходят на глазах у пользователя внутри транзакции записи данных. Нам удалось добиться длительности выполнения шага "Регистрация" не более 0,4 сек.
Шаг №2 "Отправка"
Шаг 2.1. Регламентное задание "Отправить сообщения в RMQ" отправляет в RMQ сообщения, накопившиеся в РС "Очередь недоставленных сообщений". После успешной отправки сообщения в RMQ запись из РС удаляется. Периодичность регл задания мы выбрали эмпирическим путём: каждые три секунды. Регл задание должно иметь уникальный ключ, чтобы исключить параллельное выполнение, что при такой частоте запуска не исключено. Результат запроса должен быть отсортирован по реквизиту СистемноеВремяСобытия, чтобы соблюсти событийную модель.
Выполнение запроса к РС надо выполнять внутри программной транзакции, чтобы исключить грязное чтение, т.к. запись в РС происходит внутри транзакций записи объекта данных, значит есть вероятность отката транзакции. Согласно теории, на объекты, записанные внутри транзакции накладывается блокировка типа X, которая запрещает другим транзакциям накладывать на этот объект любые другие блокировки. А при чтении внутри транзакции на объекты накладывается блокировка типа S. Значит запрос внутри транзакции ко всей таблице РС выполнится тогда, когда завершатся все начатые до этого транзакции, что и защищает от грязного чтения. Если база данных SQL переведена в режим READ COMMITTED SNAPSHOT, то будет еще проще - запрос в транзакции всегда будет возвращать записи только завершенных транзакций и не будет зависать на блокировках.
Почему нельзя было отправить сообщение на шаге "Регистрация" и тем самым ускорить процесс обмена? Честно говоря мы испугались оптимистичного сценария: что транзакция записи объекта данных после отправки не будет прервана, и что не будет коммуникационных проблем с сервером RMQ. Разработчики 1С-платформы не гарантируют очередности выполнения подписок на события в порядке следования в конфигураторе. Но даже если это и так, нет гарантии, что в будущем какой-то внедренец не вставит в конец списка свою подписку и она не будет прерывать транзакцию. Что касается коммуникационных проблем - как показала практика сам Кролик работает стабильно, и сообщения уходят быстро, потому что мы не передавали тяжелые бинарные данные, и вообще старались не помещать в сообщение больше одного объекта. Но опять же нет гарантии что в будущем не найдется внедренец, который нарушит эти правила.
Шаг 2.2.- записываем событие "Отправлен" в регистр "Состояния сообщений"
При желании передачи записей регистра "Состояния сообщений" в отдельную базу с целью логирования - можно рассматривать этот регистр как объект обмена (на диаграмме отправки он закольцован на вход алгоритма), но тут главное вовремя прервать бесконечную рекурсию - отключить запись состояний "Зарегистрирован" и "Отправлен" при передаче самого регистра "Состояния сообщений"!
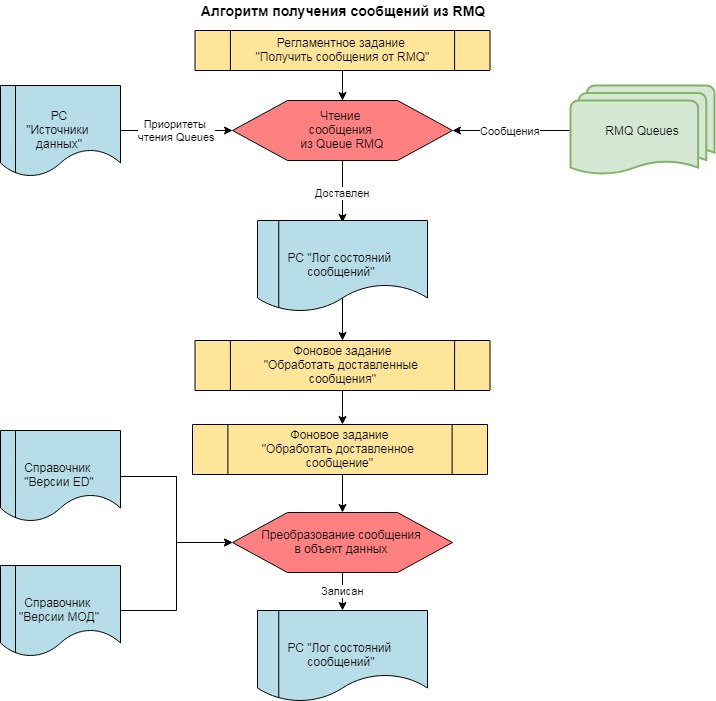
Шаг №3. "Доставка"
Шаг 3.1. На стороне получателя регламентное задание "Получить сообщение от RMQ" читает содержимое очередей RMQ и записывает их в РС "Лог состояний сообщений" со статусом "Доставлен". РС хранит не только статус сообщений, но и содержимое, чтобы на следующем шаге можно было их преобразовать из универсального формата в объект получателя и записать.
Имена очередей и их приоритетность хранится в справочнике "Источники данных". Сначала выбираем все сообщения из очереди с приоритетом 0. После этого читаем одно сообщение из очереди с приоритетом 1, возвращаемся к нулевой очереди и так далее. Почему так? Через очередь XSD мы передаем служебные данные (версии форматов и версии менеджеров обмена), их мы должны получить как можно быстрее и быть во всеоружии, т.к. в очереди DATA могут быть сообщения с обновленной версией формата.
Периодичность регл задания мы выбрали эмпирическим путем: каждые три секунды. Регл задание должно иметь уникальный ключ, чтобы исключить параллельное выполнение, что при такой частоте запуска не исключено.
Регламентное задание "Получить сообщение от RMQ" в циклах чтения сообщений проверяет работу фонового задания следующего шага "Обработать доставленные сообщения". Если оно не запущено, то запускает его. Это позволяет не прерывая процесса получения сообщений приступить к их обработке.
Шаг №4. "Запись"
Шаг 4.1. Фоновое задание "Обработать доставленные сообщения" читает из РС "Лог состояний сообщений" необработанные сообщения, разумеется в порядке системного времени события, полученного на шаге 1.6.
Шаг 4.2. Для каждого сообщения запускается отдельное фоновое задание "Обработать доставленное сообщение", которое производит преобразование и запись объекта, а так же снимает признак "Не обработано" с полученных сообщений и записывает в РС состояние "Записан".
Фоновое задание "Обработать доставленные сообщения" выполняет две важные функции:
- регулирует максимальное количество одновременно запущенных заданий "Обработать доставленное сообщение"
- выстраивает сообщения с одинаковым HASH указателя на объект данных (полученного в шаге 1.6) в последовательную цепочку, чтобы не получить взаимных блокировок.
Для чего нужны все эти сложности с параллельностью обработки полученных сообщений? Для производительности. Шаг Записи из всех четырех шагов (Регистрация, Отправка, Доставка, Запись) самый медленный, а быстродействие всего механизма обмена определяется суммой всех шагов.
Опытным путем мы установили оптимальное число фоновых заданий - пять. Это то число, которое в реалиях заказчика обеспечивало скорость доставки в среднем 4 секунды, и в то же время не мешало работе пользователей на стороне получателя. При 50 параллельных заданиях пару раз в день мы наблюдали картину, как вся база вставала колом. Изоляция фоновых заданий в отдельные рабочие процессы на сервере 1С не сильно помогала. Причем это была именно деградация производительности сервера, а не эскалация блокировок.
Так же 5 параллельных заданий обработки полученных сообщений не сильно удаляют нас от событийной модели. Если мы и нарушаем хронологию, то в пределах разницы времени записи самого быстрого и самого медленного объекта.
Механизм оповещения об ошибках
На тему ошибок есть две важные установки:
- Вовремя исправленная ошибка не считается ошибкой!
- Правильное отчуждение результата проекта - это когда в возникающих ошибках начинают разбираться не только авторы-разработчики, но и служба поддержки заказчика
Чем точнее сообщение об ошибке, тем быстрее она будет исправлена, поэтому мы в течении всего проекта пополняли базу знаний об ошибках и вставляли в код точки оповещения.
Поведенческая модель механизма следующая:
- сообщение об ошибке попадает в РС "Ошибки обмена". У него заполняется три измерения "HASH указателя на объект данных", "ИБ возникновения ошибки", "ИБ источник объекта". Соответственно если ошибка возникает в том же месте, по тому же объекту, то информация о ней актуализируется, а не множится.
- каждый раз при успешном выполнении одного из шагов обмена удаляется запись из РС "Ошибки обмена", если она там есть. Т.е. РС "Ошибки обмена" служит для отображения неисправленных ошибок в текущем моменте. Если ошибка исправлена, то запись о ней удаляется автоматически.
- все записи РС "Ошибки обмена" передаются на сторону ИБ-отправителя. В форме списка РС есть две кнопки: "Переотправить выделенные сообщения" и "Переотправить все сообщения". Поиск объекта для переотправки происходит с помощью реквизита "Указатель на объект данных". Для ссылочных типов - это пара "тип метаданных" и GUID ссылки, для регистров сведений - набор измерений. Таким образом, после устранения причины ошибки у службы поддержки есть возможность одним нажатием переотправить все недоставленные объекты из ИБ-отправителя.
- каждые 15 минут запускается регламентное задание по отправке сообщений о текущих ошибках в Help Desk. Оповещения об ошибках отправляется непосредственно из ИБ возникновения ошибки. В Help Desk по виду объекта и месту возникновения определяется уровень критичности ошибки.
С какими ошибками мы столкнулись за время проекта:
- Внешняя компонента V8RMQClient вдруг перестала работать, причем метод ПодключитьВнешнююКомпоненту("ОбщийМакет.V8RMQClient", "V8RMQClient", ТипВнешнейКомпоненты.Native) выполняется успешно, но любые другие действия приводят к ошибке "не найден файл внешней компоненты". Выяснилось что айтишники периодически в папках сервера 1С чистят кэш. 1С-платформа само действие по записи файла компоненты из общего макета на диск выполняет лишь раз, а при повторном обращении сразу берет файл с диска. В общем договорились с айтишниками, что они чистку кэша будут совмещают с перезагрузкой сервера 1С и проблема исчезла.
- В самом начале мы забыли про защиту запуска регл заданий от копирования базы, и с удивлением наблюдали, как из очередей стали пропадать сообщения - одну очредь читали разные базы! Сделали стандартный механизм сравнение со строкой подключения ИБ, и заодно сценарий поведения при разоваричивании копии продуктовой базы в тестовом контуре - автоматическое переподключение к другому серверу RMQ и отключение оповещений Help Desk.
- Про периодический ступор базы ERP при 50 параллельных фоновых заданиях обработки полученных сообщений выше уже упоминалось. Шутки пользователей в стиле "Угомоните кролика, дайте поработать" в конце концов заставили снизить это число до 5.
- Это даже не ошибка, а фича. Все наверное уже забыли, что в СУБД платформы 8.2.13 константы хранились в одной таблице в виде одной строки с кучей колонок. И в языке запросов обращение к ним было "Выбрать К.ИмяКонстанты Из Константы КАК К", а не "Выбрать К.Значение Из Константа.ИмяКонстанты КАК К". Мы это "вспоминали" каждый раз, когда обновляли нашу подсистему в конфигурациях 8.2.13. Вообще, написание универсальной подсистемы, совместимой со всеми версиями платформы, начиная с 8.2.13 и выше - сильно взбодрило! Пришлось вспомнить многие хорошо забытые вещи. И все равно в итоге при обновлении каждой конфигурации приходилось идти по внушительному чек-листу, чтобы не забыть учесть все локальные нюансы.
Коллективная работа с КД3 и с универсальным форматом
Большая часть времени проекта была посвящена написанию правил обмена в КД3 и обогащению универсального формата Enterprise Data новыми объектами. Временами количество одновременных разработчиков доходило до 5. Как мы решили проблему коллективной разработки:
- в состав типовой конфигурация КД3 включен план обмена "Рабочие места" с правилами обмена на КД2. Каждому разработчику создали распределенную базу КД3
- так же в составе конфигурация КД3 есть иерархический справочник "Группы правил", он прошивает все правила обработки данных, правила конвертации объектов, правила конвертации предопределенных данных и алгоритмы. В нем мы создали группу "Разработка" и под ним имена разработчиков. Мы договорились, что пока идет разработка и тестирование новых правил, разработчик помещает правила в свою папку. Это служит сигналом для других разработчиков, что правила захвачены и их трогать нельзя.
- доработку XDTO-объекта EnterpriseData каждый разработчик вел в конфигураторе своей базы КД3. Базы КД3 подключены к хранилищу конфигурации. Разработчик захватывает XDTO-пакет, вносит изменения, выгружает пакет в XSD-файл, загружает файл в структуру формата в своей базе КД3, проверяет, помещает XDTO-пакет в хранилище, извещает остальных разработчиков, если были затронуты чужие объекты.
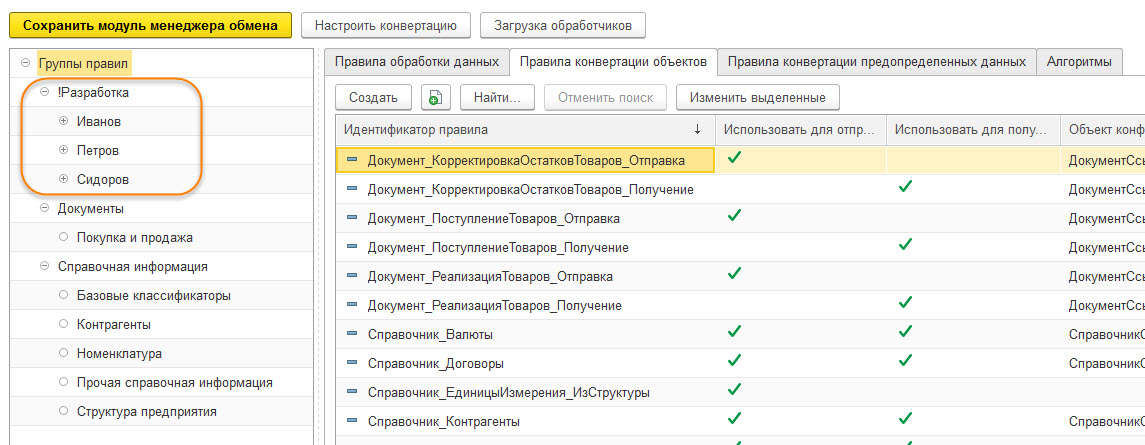
Жизненный путь релиза с правилами в итоге получился такой:
- разработка и тестирование правил в контуре разработчика
- автотестирование релиза правил в тестовом контуре
- разворачивание в продуктивном контуре копии КД3 из тестового контура
- распространение правил из КД3 по информационным базам продуктового контура
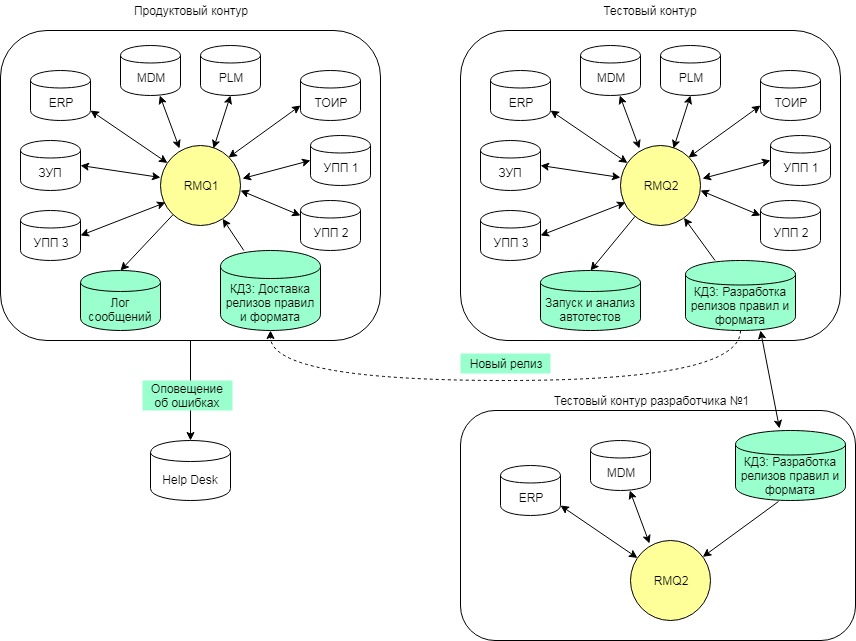
Механизм автотестирования
Когда кода становится много, при разработке нового функционала повышается вероятность повреждения функционала смежных подсистем. То же касается разработки правил обмена. Выявлять такие повреждения помогает регрессионное тестирование в тестовом контуре.
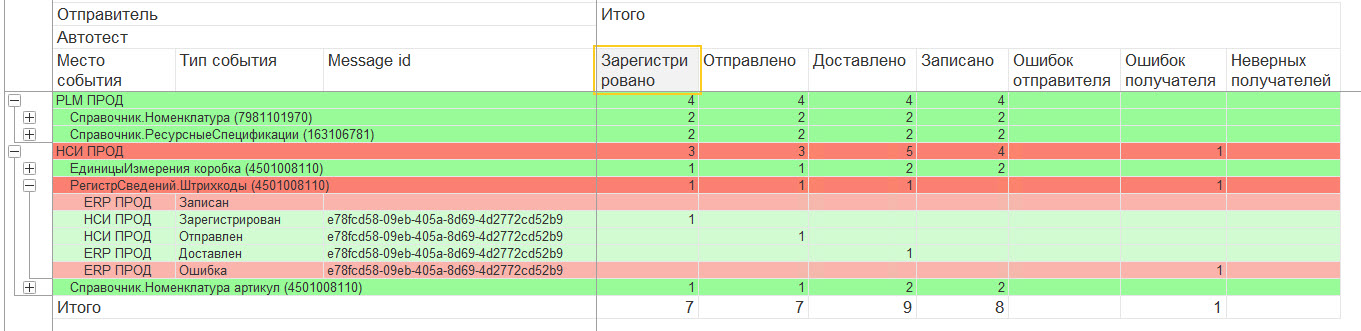
Мы разработали справочник "Шаблоны автотестирования" и регламентное задание, которое выполняет на стороне ИБ-отправителей создание и удаление объектов данных по шаблонам. Далее вся информация о результатах обмена стекается в базу анализа результатов автотестирования.
На первом уровне анализа проверяется сам факт передачи объектов в нужных направлениях.
На втором уровне проверяется качество передачи - сравниваем подготовленные заранее XML-эталоны: с XML объекта данных на стороне отправителя, c XML текстом сообщения в формате ED, и с XML объекта данных на стороне получателей.
На скриншоте показан отчет первого уровня анализа. Очевидно, что тест "Штрихкоды" не выполнился, т.к. на стороне получателя была ошибка.
Итоги проекта
- Все исходные требования к результатам проекта в части интеграции были выполнены
- Появился прецедент синтеза двух современных механизмов интеграции - КД3 и RMQ
Другие итоги будем дописывать сюда по мере обсуждения в форуме под публикацией.
Полезные ссылки:
- Описание БИТ:Адаптера: bit-erp.ru/adapter
- Описание механизма маршрутизации Rabbit MQ: www.rabbitmq.com/tutorials/tutorial-five-python.html
- Инструкция по установке Rabbit MQ: www.rabbitmq.com/install-rpm.html
- Описание методов компоненты YellowRabbitMQ: 1c-e.ru/подсистема-интеграции-реального-вре/
- Форум Серебряной пули про YellowRabbitMQ: xdd.silverbulleters.org/c/integracziya/yrabbitmq
Авторы:
Рецензенты:
Вступайте в нашу телеграмм-группу Инфостарт