Однозначный ответ на поставленный вопрос может быть дан только в том случае , если два рассматриваемых документа имеют одинаковый тип . Рассмотрим пример.
Если рассматриваемые документы имеют различный тип , то однозначно ответить на поставленный вопрос невозможно.
Пример для конфигурации БП2.0.

Другими словами, в БП 2.0 типовой документ "КорректировкаДолга" созданный в последнюю секунду месяца при проведении никогда не учтет долг по документу "РеализацияТоваровУслуг" с той же "датой-временем". В этом эффекте можно убедиться практическим путем.
Эта особенность в выстраивании последовательности документов по моменту времени явно описана
на сайте http://www.lavelin.ru/index.php/article/1c/54-razrabotka/103-moment-vremeni-i-granica-naznachenie-primery-ispolzovaniya
Момент времени:
Фирма 1С описывает так:
Предназначен для получения и хранения момента времени для объекта в базе данных. Содержит дату и время, а также ссылку на объект базы данных. Используется в качестве значений свойств и параметров методов других объектов, имеющих тип МоментВремени.
Момент времени используется в тех случаях, когда важно различать моменты времени для объектов, имеющих одинаковую дату и время, например для сравнения положений документов на временной оси.
А своими словами:
Момент времени - комбинация даты и ссылки на документ. Позволяет разделить и упорядочить документы в пределах одной секунды, выстраивая все документы в однозначную последовательность. Получение данных при проведении на момент времени гарантирует, что будут учтены движения сделанные в ту же секунду что и проводимый документ, но находящиеся перед ним.
Но есть особенность - документы проведенные в одну и ту же секунду располагаются в произвольном порядке, а не в порядке их физического создания (как было в 7.7).
Последнее выделенное автором предложение , правда, требует уточнения.
На мой взгляд, правильно так :
"Но есть особенность - документы разного типа , записанные в одну и ту же секунду, располагаются в произвольном порядке, а не в порядке их физического создания (как было в 7.7). Документы же одного типа располагаются в порядке их физического создания."
1. Первый посткриптум к статье.
После того как статья была опубликована пользователь Alias в комментарии довольно убедительно опроверг автора статьи . Приведу его комментарий полностью :
Простите, но мне кажется лучше оставить изначальную формулировку без изменений....
Разных типов, одинаковых типов -- неважно. Документы, созданные в одну секунду, располагаются в произвольном порядке независимо от типа. Другое дело что единожды созданные (расположившись на оси времени) они будут сохранять этот порядок всегда, пока ГУИД останется неизменным.
Получение уникального идентификатора гарантирует только его уникальность, но не возрастание.
В большинстве случаев да, документы будут по порядку. Но это только частный случай! В общем же случае они могут быть и в произвольном порядке.
Согласитесь неприятно будет после нескольких месяцев нормальной работы словить ошибку только потому что вы в своих алгоритмах закладывались на постоянное возрастание момента времени. А это оказалось не так.
В конце концов, проверьте сами -- создайте не 10, а 1.000.000 документов в одну секунду и посмотрите, по порядку они будут идти или нет. Если по порядку -- попробуйте в другой базе, увеличьте число документов, и т.д.
На закуску процитирую слова Бориса Нуралиева:
"Механизм генерации ссылок обеспечивает только их уникальность. Возрастающая последовательность при их генерации не обеспечивается."
Всё сказано вполне чётко, не правда ли?
p.s. Думаю, не стОит напоминать что момент времени -- это время + ссылка, то есть если так будет проще, время + тип документа + уид
2. Второй посткриптум к статье
Чтобы прояснить картину и понять механизм генерации ссылок был проведен эксперимент :
Клиент-серверный вариант 1с82(MSSQL2008),БП2.0.
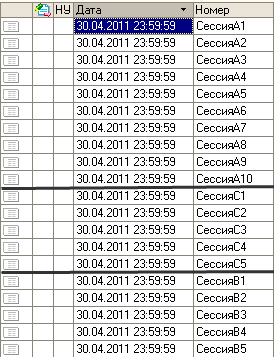
В трех разных сессиях А,В,С почти одновременно запущены обработки создания и записи 10 000 документов "РеализацияТоваровУслуг" с одинаковой датой-временем. В комментарий каждого документа пишется наименование сессии и порядковый номер создания в сессии.
Например, первый созданный в сессии А документ будет иметь комментарий "А1", а последний "А10 000"
Как документы созданные в трех сессиях будут расположены друг относительно друга будем наблюдать в списке соответсвующих документов.
Итак , порядок следующий :
С1 ..С32
А1 ..А32
В1 ..В32
А33 ..А224
В33 ..В96
А225..А288
В97 ..В160
...
С33..С96
... и т.д. до С10000,В10000,А10000.
Из полученного порядка расположения документов можно сделать вывод о "захвате" в каждой сессии диапазона ссылок , размер которого кратен числу 32. Подтверждается вывод в постскриптуме 1 о возможности хронологического невозрастания ссылок , если используется несколько сессий. Действительно , эксперимент убеждает в том , что механизм генерации ссылок для одного типа документов обеспечивает лишь уникальность созданных ссылок и ничего более .
С другой стороны, обнаружено , что документы созданные в одной сессии расположены в строго хронологическом порядке их создания, например отфильтрованный список документов для сессии А выглядит следующим образом : А1,А2,А3.....А9 999, А10 000.
На рисунке отображено начало полученного списка документов:
Вступайте в нашу телеграмм-группу Инфостарт