



Как то отвечая на комментарии предыдущей статьи (//infostart.ru/public/857978/) родилась идея следующей, которая позволит развернуто ответить на некоторые вопросы.
Основной комментарий, подтолкнувший к ниженаписанному таков:
Чудны дела, твои.... зависшие фоновые задания, сеансы и/или блокировки - известный бич, все его знают и в случае глюков сервера - чистят сеансовые данные. А вы говорите "не сталкивался". Поделитесь опытом, чтоль - как так пролучается у вас?
Я начну, пожалуй, с конца, то есть с вывода. Чудес не бывает. Да, именно так, астрология лженаука, благодатный огонь зажигают сами монахи, используя несложные химические фокусы, молния — это не гнев Зевса, а всего лишь электрический разряд.
В нашей, ИТ среде всё то же самое, чудес не бывает. К любой проблеме есть рациональное объяснение, поэтому, когда мы в Компании сталкиваемся с какой-то проблемой, первое, что мы делаем – стараемся максимально окружить её красными флажками, чтобы никто, не дай бог не нарушил шаткое равновесие работающей проблемы, после чего начинаем тщательно рассматривать её со всех сторон.
Немного отступлю от темы, так как текст данной статьи не согласован ни с моим руководством ни с компанией 1С я извещаю, что все нижеописанные примеры являются выдуманными от начала до конца.
Итак, что именно зацепило меня во фразе – «как вы боретесь с зависаниями системы». Но что такое зависания системы? Зависания клиента? Сервера? Медленно открывается форма — это зависание? Если да – то с какого момента мы начинаем считать зависание проблемой?
В части проблем я стойкий приверженец ITIL, несмотря на всю его академичность написан он исходя из реального опыта тысяч людей. Не буду вдаваться в теорию, просто скажу, что, по моему мнению, нельзя задавать вопрос – как вы боретесь с зависаниями. Правильней спросить – какое обходное решение вы используете для проблемы №739. Да, не все проблемные ситуации 1С фиксирует как дефекты, зачастую мы получаем сообщение – данная ситуация не является проблемной, но наша задача, как технических специалистов доказать в том числе и тех поддержке 1С то, что та проблема, которую мы зафиксировали именно проблема и её надо устранить, сначала предложив обходное решение.
Ладно, хватит теории, примеры.
История первая.
Всем работающим в сезонной рознице известно, что декабрь год кормит, так что любой сбой системы в декабре, особенно в заключительной декаде, зачастую приводил к увольнению даже топ-менеджеров от ИТ, что уж говорить об обычных админах. Так что, когда мы заметили, что наш application сервер уходит в 100% нагрузку началась лёгкая паника.
Итак, развитие событий.
1 декабря.
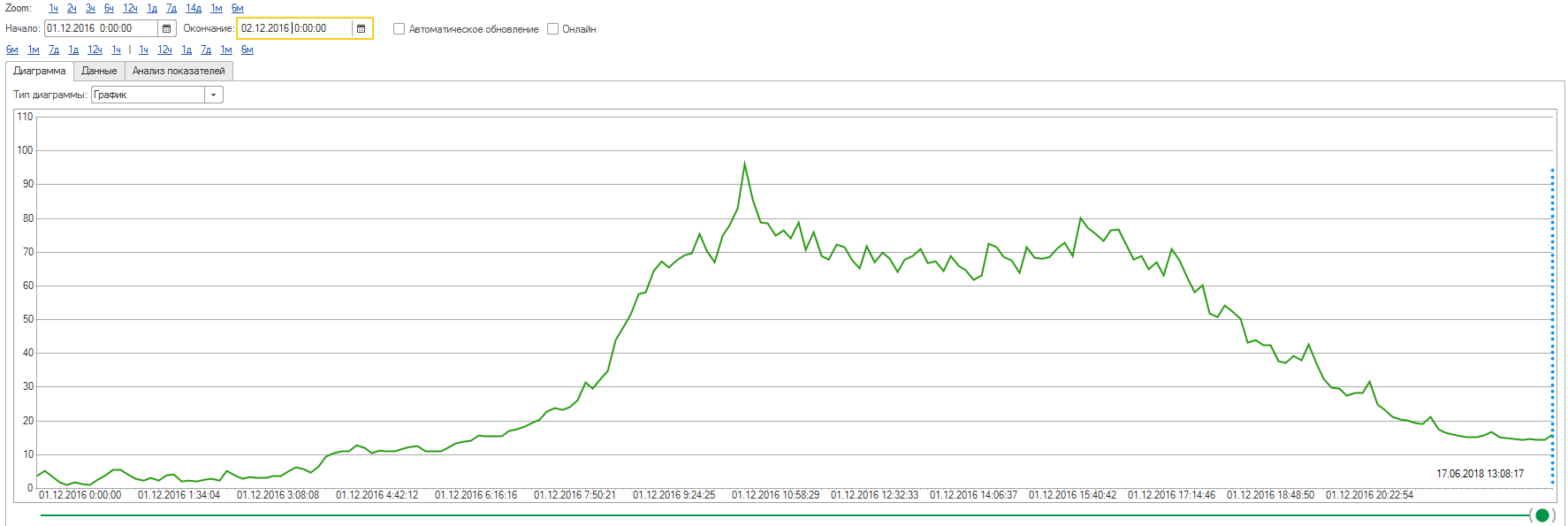
Небольшой пик, всё нормально, средняя нагрузка на уровне 80 процентов, нечего беспокоиться.
5 декабря. Нагрузка уже на уровне 90%.
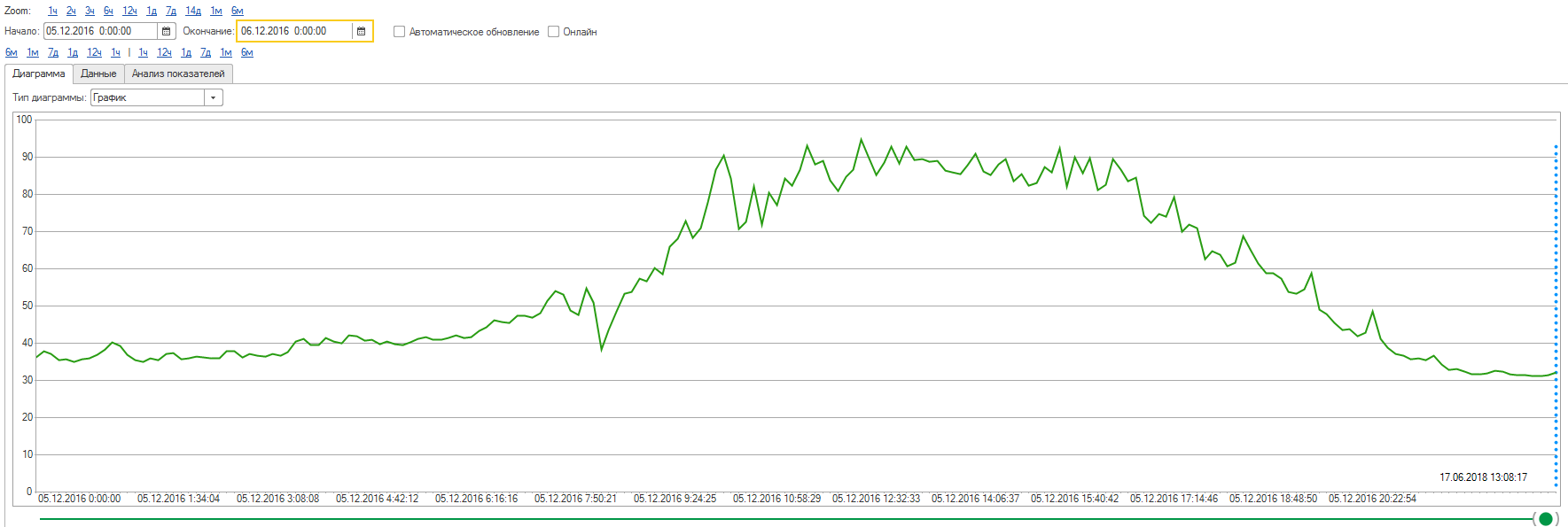
10 декабря. Всё, мы уже в 100% и пользователи начинают испытывать проблемы с производительностью.
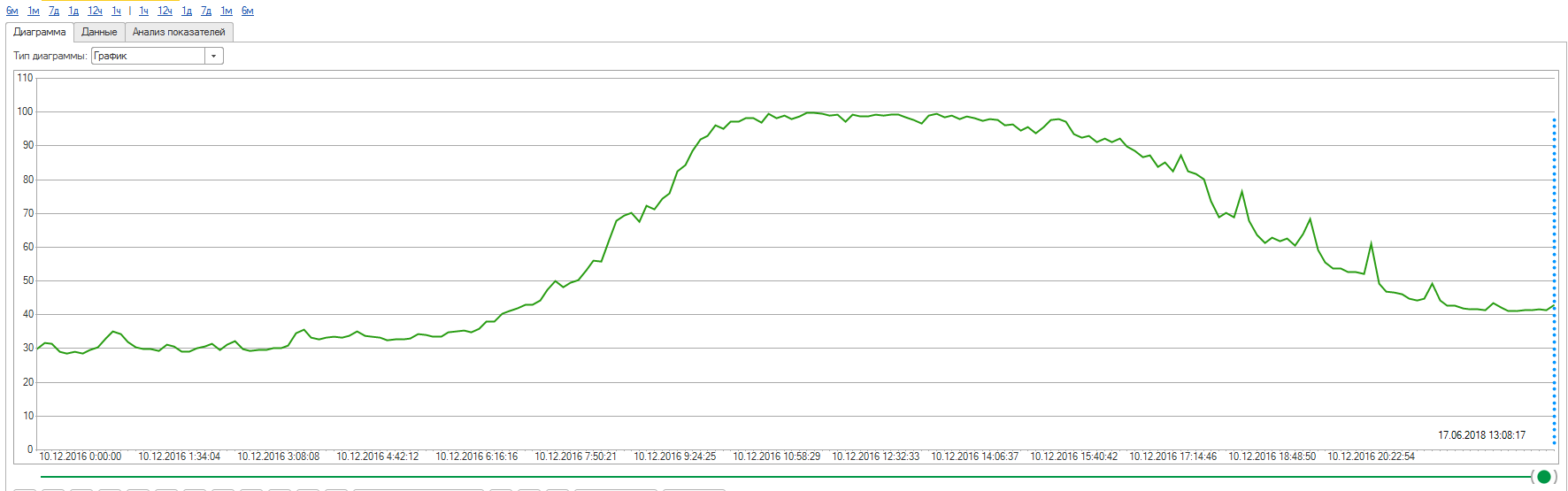
Сразу скажу, та авария многому меня научила и об этом в конце, а пока – что делать? Известно, что понять, чем занимается application-сервер невозможно, нет таких метрик ни в ТЖ ни в консоли (напомню, это 8.3.6). Принимаем единственно возможное решение, подключаем топов, выходим на специалистов из 1С, начинаем работать непосредственно с ними. Снимаем дампы, отправляем на анализ. Выясняется, что у нас есть кусок кода, в котором формируется текст запроса. Ну что то вроде: ТекстЗапроса = «Первая часть запроса» + «Вторая часть запроса» + «Третья часть запроса». Как мне потом говорили разработчики – это еще из типовой нам досталось, кусок по акционной механике, то есть данный код вызывается при каждом пробитии чека, причем несколько раз. Рекомендация 1С – заменить данный код на СтрСоединить.
Изменения в код были внесены 29 декабря. Результат виден на графике:
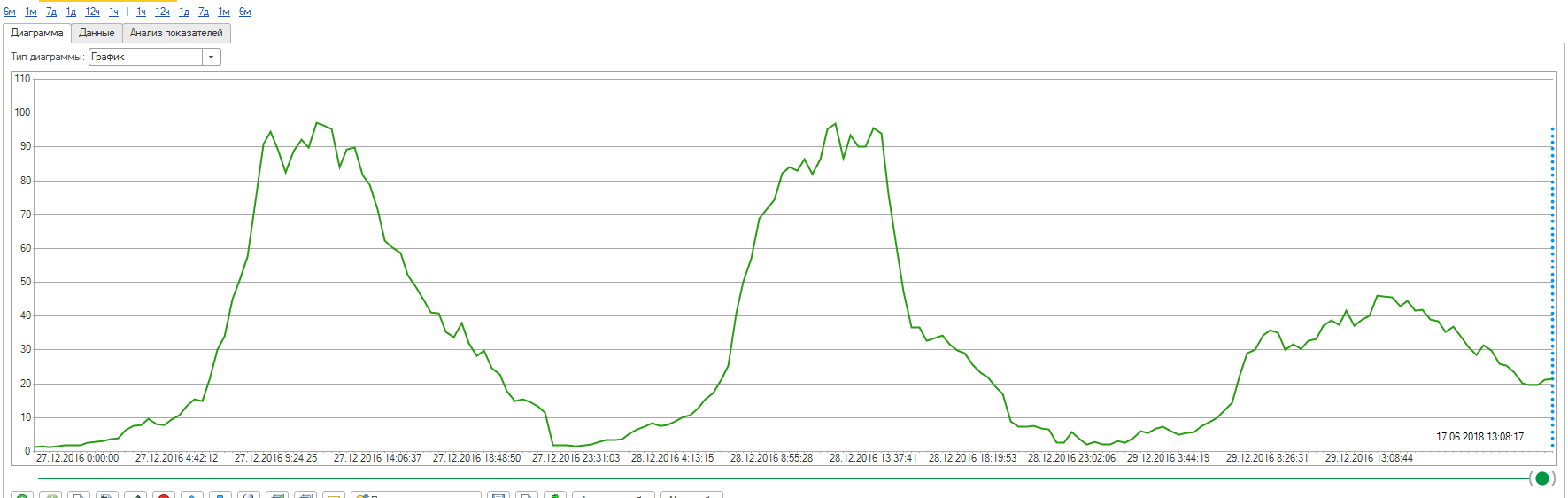
Выводы, которые мы сделали после той аварии:
- Запас мощности системы должен быть минимум 50%, лучше 100%, то есть система должна спокойно переживать двукратный рост нагрузки. Если какие-либо показатели превышают 50% от максимального значения – начинайте нервничать.
- У проблемы есть причина, при решении идите двумя путями, устраняйте последствия (поставьте еще один сервер, увольте 50% пользователей чтобы снизить нагрузку и т.п.), но параллельно ищите причину. Часто, устранив последствия, пропадает мотивация искать причину, всё же уже хорошо, поэтому иногда мы запрещаем устранять последствия обходным путём, если это стоит бизнесу не слишком дорого, а ищем причину сразу, не отходя от кассы.
- Если вам 10 человек сказали, что причина неизвестна и найти её не представляется возможным – ищите одиннадцатого.
История вторая.
Зависающее фоновое задание.
Появилось некое фоновое задание, которое могло длиться часами и не завершиться ничем. Причем судя по косвенным данным оно чем то занималось, причем весьма активно, так как после удаления сеанса нагрузка на application падала сразу на 10-20%, на SQL сессии естественно не было, иначе мы легко могли бы понять, что оно делает, что то крутилось именно внутри app.
Урок, который я извлек из этой истории таков. Любую (!!!) проблему с зависаниями можно решить с помощью технологического журнала. Если её нельзя решить с помощью ТЖ – значит её смогут решить только сотрудники 1С, так как тут требуется анализ дампов и доступ к исходникам. В нашем случае всё оказалось достаточно банально, в коде была ошибка, в результате которой задание уходило в пустой бесконечный цикл. Поправили код, еще одной загадкой стало меньше.
История третья.
Зависающие rphost-ы.
Периодически в системе возникала странная ошибка, пользователи не могли войти в неё, текст ошибки уже точно не помню, то ли «Нет доступных серверов» то ли что-то похожее, надо в почте порыться, но ситуация была странна тем, что те, кто уже зашёл в систему успешно продолжали работать. Некоторые пользователи всё-таки заходили, иногда с первого раза, иногда с пятого. Поиск ошибок по ТЖ показал, что все «неудачники» пытались подключиться к одному и тому же процессу, если этот процесс убить – проблема исчезала. Дальше схема уже стандартная по решению проблем. Ищем обходное решение и ищем причину проблемы. Ждать жалоб от пользователей, а потом убивать зависший процесс решение так себе. В итоге выяснили, что в ТЖ есть четкие записи – «вот плохой процесс, менеджер, убей его». Если в ТЖ одна такая запись – всё хорошо, менеджеру приказали, он убил, а вот если записей больше одной – это означает что менеджер попытался убить процесс, но у него не удалось и агент снова и снова приказывает убить отщепенца. Обходное решение – ставим данный процесс на мониторинг, в почту сообщаем о зависшем процессе, убиваем руками. Причина – дефект в движке, исправлено в 8.3.12. Справедливости ради скажу, что воспроизводится данный дефект по моей информации только у нас. У нас вообще в связи с объемами много такого, что не воспроизводится больше нигде, поэтому на всякий случай напоминаю – все случаи выдуманы!
История четвертая.
Зависающий клиент.
У нас порядка 8 тысяч работающих клиентов и вот появился ОН. При запуске система зависает. Висит окно запуска и всё, ни в какую, переустановка платформы не помогла, очистка кеша не помогла. В ТЖ всё очень аскетично.
17:25.704000-0,EXCP,0,process=1cv8c,OSThread=7856,setTerminateHandler=setTerminateHandler
17:26.297001-1,LIC,1,process=1cv8c,OSThread=7212,Func=initialize,txt='local Application, hasp HL SOFT local, ORGL8 local net, ORG8A local net, ORG8B local netBase local net'
17:26.297003-1,LIC,1,process=1cv8c,OSThread=7212,Func=getLicense,res=error,txt='0, client, error, local Application;
hard, local, Base, absent;
hard, net, Base, absent'
Делаем дамп процесса, отправляем в 1С – результат – система не может определить принтер по умолчанию. Проблема в драйвере принтера, попробуйте его переустановить.
Переустанавливаем, всё начинает работать. Что это было и почему в ТЖ пустота — это проблема, но мы сейчас пытаемся доказать, что это дефект в движке и зафиксировать его.
Как видите, все выше приведенные примеры разные, есть проблемы в движке, есть в коде, но на вопрос «что делать с зависаниями системы» у меня ответ один – разбираться, что именно зависает. Начните с анализа ТЖ, в 99% случаев вы найдете ответ там. Если ответа нет, нужно либо искать специалиста, обладающего достаточной квалификацией чтобы докопаться до причины либо передавать запрос в техподдержку 1С.
Чудес не бывает.
P.S. Начал перечитывать статью и понял, что не ответил на сам вопрос. Да. Мы чистим сеансовые данные, но не из-за глюков системы, а просто потому, что, когда 7 тысяч пользователей одновременно пытаются их прочитать, дисковая подсистема проседает и вместо запуска в течение 1 минуты пользователям приходится ждать по 10-15 минут. Когда обновление плановое, ночью, очищать сеансовые данные нет необходимости, нагрузка растет постепенно.
Вступайте в нашу телеграмм-группу Инфостарт
