Меня зовут Павел Баркетов, я работаю в компании «Софтпоинт». Мы уже более 10 лет занимаемся решением задач оптимизации производительности. И несмотря на большое количество решенных задач, их количество не уменьшается, а растет в геометрической прогрессии. Объемы данных увеличиваются, и задачи по оптимизации работы с этими данными усложняются. Этот процесс неизбежен.
Тема статьи – нетривиальные подходы к оптимизации. Будут рассмотрены два аспекта:
- Первый – поиск по подстроке. Пользователи часто его используют, и многие, наверное, уже сталкивались со значительным ожиданием, поиск по подстроке выполняется недостаточно быстро.
- Второй – проведение больших документов, таких, как закрытие месяца, расчет себестоимости. Наверняка многие сталкивались с тем, что бухгалтеры проводят эти документы по 5–9 часов, ночью и в нерабочее время. Самое интересное, что классические методы оптимизации здесь не всегда помогают. Если вы при проведении таких документов запустите в отладчике замер производительности, то увидите, что наибольшее количество времени тратится на запись во временные или реальные структуры – таблицы, регистры и т.д. И решить эту задачу классическими методами не получается.
Поиск по подстроке
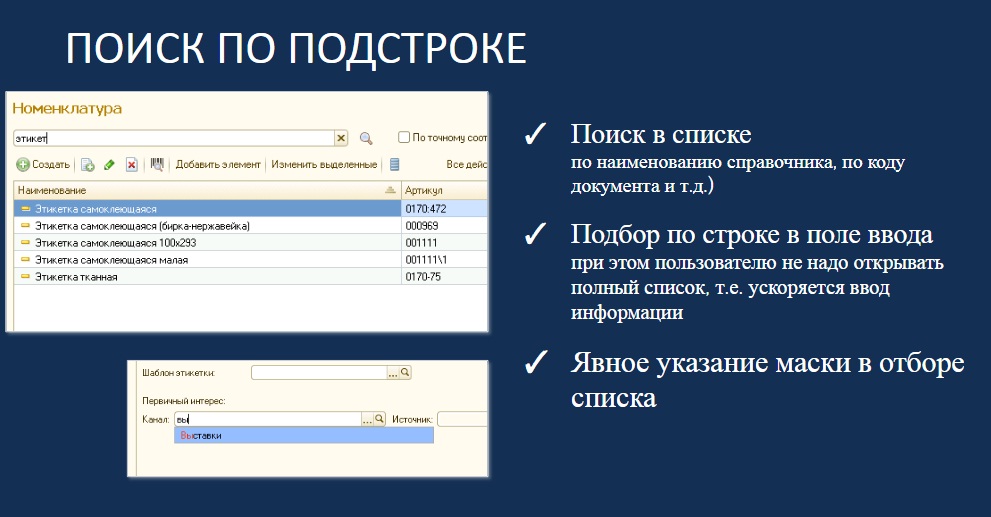
Первая тема – поиск по подстроке. За этот год я сталкивался несколько раз с проблемами по этой операции. Приходишь в страховую компанию за продлением полиса, тебя предлагают найти по номеру телефона. Понятно, что это не классический поиск по полному номеру телефона, потому что пользователь мог завести номер через восьмерку, через семерку или еще как-то, следовательно, ищут по фрагментам номера. При этом используются долговременные операции поиска – в ряде ситуаций задержка может быть несколько секунд, а может доходить и до минут.
Поиск по начальным символам

Начну с первого примера, когда поиск осуществляется по начальным символам. Это – частный случай поиска по подстроке, когда пользователь точно знает, что искомое значение начинается с определенных символов.
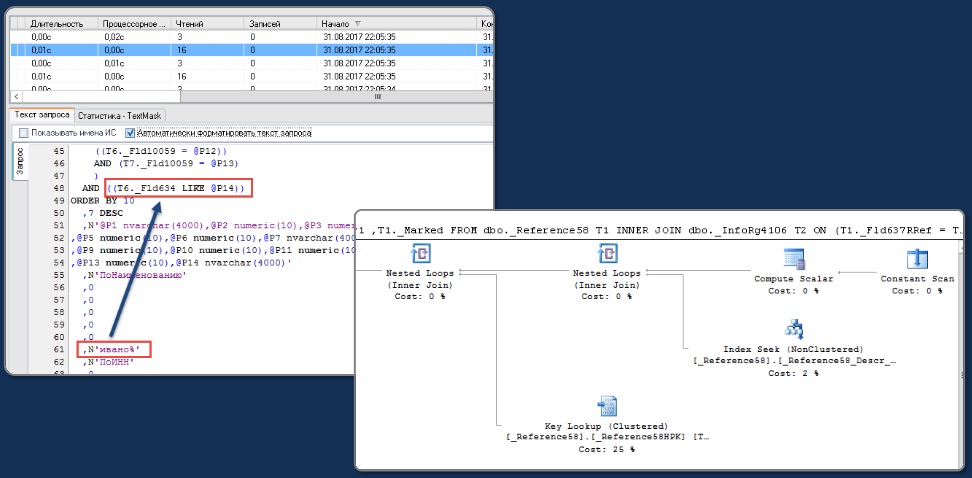
Поиск по начальным символам реализуется в 1С с помощью команды ПОДОБНО (или в английском варианте, LIKE) с указанием значения с «%» в конце («%» обозначает последовательность любых других символов). Например, мы ищем:
Наименование ПОДОБНО "ивано%"
Обратите внимание, что если у вас в системе существует индекс по этому полю, то в SQL-запросе для этого поиска будет использоваться Index Seek – это поиск по индексу.

Условие «ПОДОБНО поисковой строке» эквивалентно поиску в диапазоне значений. В частном случае, когда мы ищем «ивано%» – это эквивалентно поиску в диапазоне фамилий, которые начинаются на «ивано», и, заканчивая «иванп» (потому что символ «п» идет после символа «о»).

Современные оптимизаторы самостоятельно преобразуют запрос LIKE на запрос поиска по диапазону. Следовательно, если у вас в системе существует индекс по этому полю, вы при интерпретации запроса в термины SQL получите именно такой результат – оптимизатор представит запрос с LIKE в виде поиска по диапазону.
Таким образом, можно осуществлять классический быстрый поиск с использованием индекса (Index Seek). С этим проблем нет или решить их можно простым способом.
Поиск по вхождению

Теперь возьмем пример посложнее, когда неизвестно, в каком именно месте строки стоит наше искомое значение, и реализуется поиск по вхождению строки. В этом случае в запросе «ПОДОБНО» «%» стоит с двух сторон.
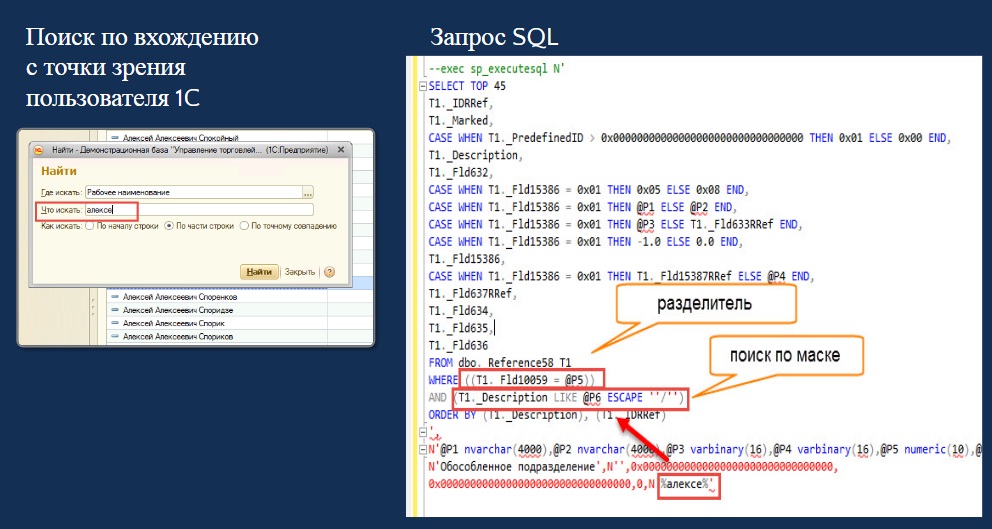
При преобразовании такого запроса в SQL мы видим, что изменяется только команда (в значении используется уже два «%»).
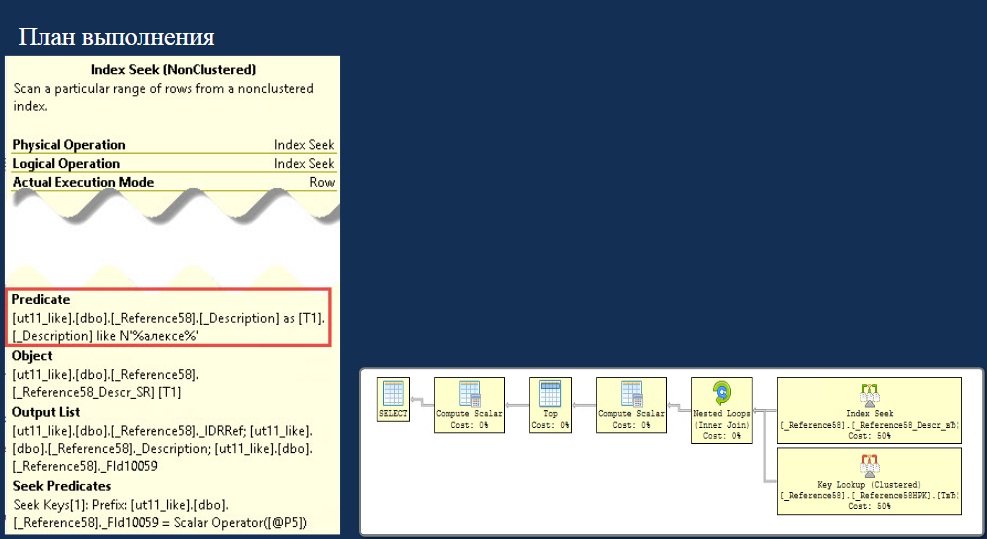
Рассмотрим подробнее план выполнения. Здесь мы видим тот же Index Seek, но в данном случае он не работает эффективно.
Дело в том, что индекс по наименованию справочника, который мы рассматриваем, состоит из нескольких полей.
- Первое из них – это разделитель учета.
- Дальше непосредственно идет поле поиска.
И поэтому, когда в плане выполнения отображается «Index Seek», это означает, что поиск делается по первому полю разделителя – на слайде выше можно увидеть, что поиск по нашему искомому значению Desc абсолютно не используется.
Что делать в этой ситуации? У меня на практике было очень часто, что пользователям запрещали использовать запросы на вхождение. И пользователи в ряде случае сами не использовали этот функционал, потому что время выполнения очень значительное, а надо продолжать работать. Поэтому им приходилось выкручиваться другими способами – выбирали в списках, пытались найти по первым символам и так далее.
Но это приводит к недовольству функционалом и неправильному восприятию системы. Пользователь понимает, что система с чем-то не может справиться и не работает как положено. Это неправильно.
Нетривиальный подход к решению задачи поиска по подстроке

Давайте теперь рассмотрим нетривиальный подход к решению этой задачи.
Обозначим ряд допусков:
- Первое – поскольку современные диски имеют неограниченный размер, допустим, что пространство на диске, которое вы можете использовать, у вас есть достаточно большое.
- Второе – пользователь ищет не по одному-двум символам, а по какому-то фрагменту. Например, никто из нас не ищет по «ал» – это слишком маленькая селективность. Ищут какую-то значимую последовательность символов. Здесь мы для примера выбрали поиск по шести символам.
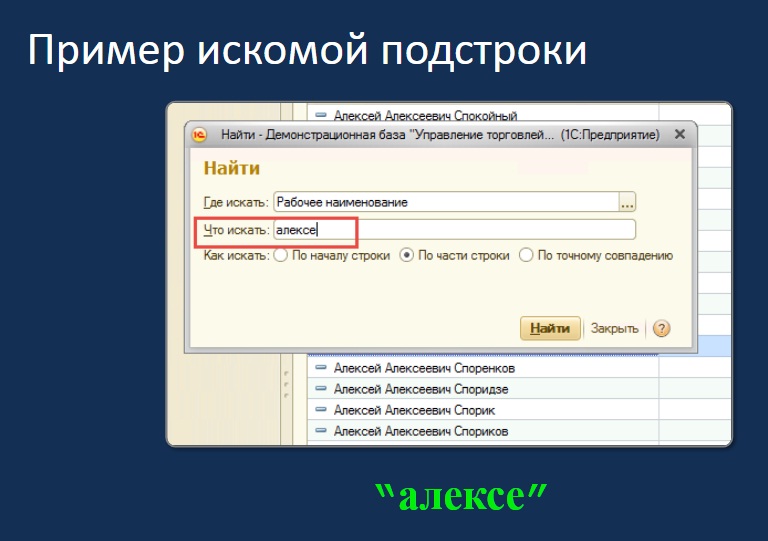
Пример искомой строки «алексе» записали в форму и будем с ее помощью тестировать.

Дальше пойдет подробное описание, как это можно сделать:
- Предположим, у нас есть поле с фамилией, именем и отчеством клиента. Первым шагом мы автоматически раскладываем это значение на фрагменты из шести символов со сдвигом «1» и получаем массив фрагментов (см. выше), которые одновременно всегда принадлежат искомому значению. Мы получили фрагменты, которые теоретически может вводить пользователь. А именно, на прошлом слайде определили, что мы ищем шесть символов. Их может быть и пять, и четыре, просто размер структуры будет больше.
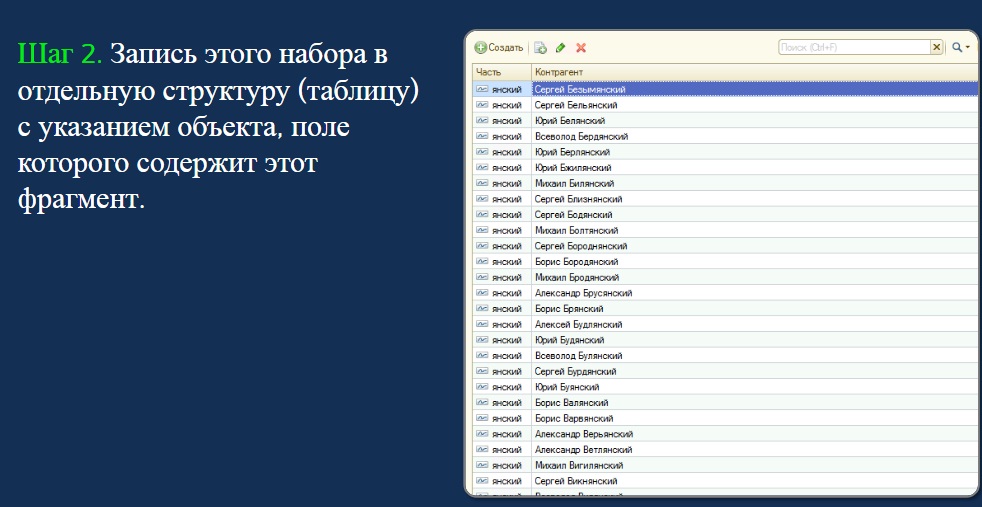
- На втором шаге мы записываем эти наборы в отдельную структуру (это может быть таблица, регистр сведений и т.д.) и получаем выборку, в которой определенный фрагмент принадлежит разным значениям.
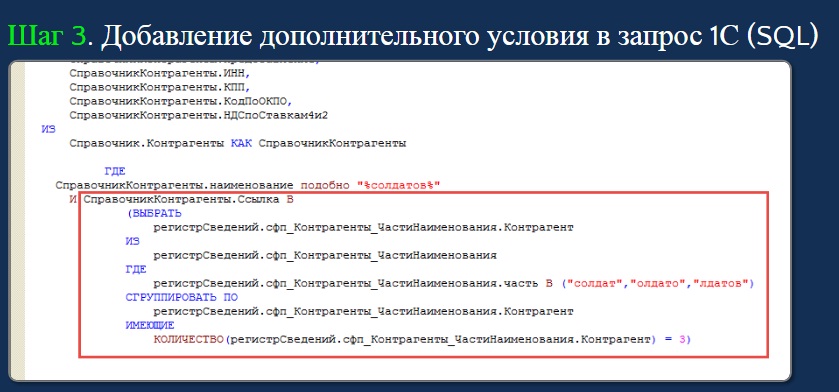
- И на третьем шаге, мы при поиске по подстроке к конструкции запроса 1С «ПОДОБНО» добавляем дополнительное условие «И», которое фильтрует количество возможных комбинаций, и вытаскиваем из этой дополнительной структуры (это может быть регистр сведений) все элементы, которым принадлежат нужные фрагменты строк.
Например, пользователь ищет клиента с фамилией «Солдатов». Это – восемь символов, значит, будет три фрагмента длиной в шесть символов, которые мы ищем в служебной структуре. Далее объединяем это все в запросе. Таким образом, получается дополнительная фильтрация.
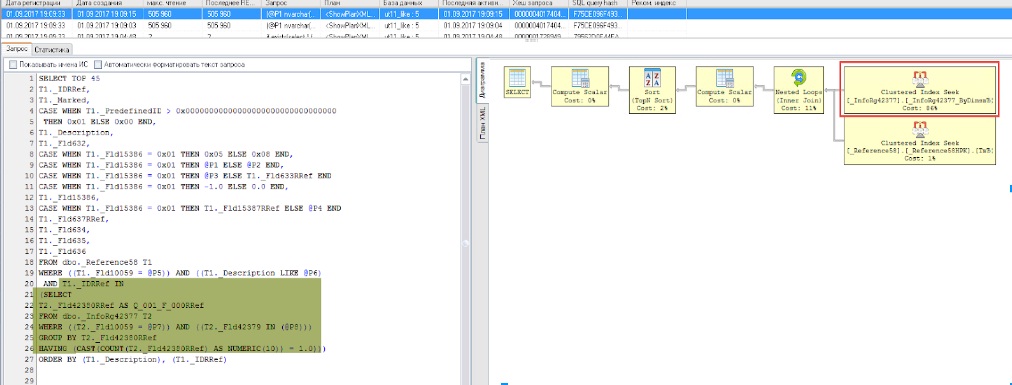
В результате мы избавляемся от знака «%» (т.е. впереди этих фрагментов всегда будет нужный нам символ), и при выполнении внутреннего запроса будет идти Index Seek, за который мы и боролись.
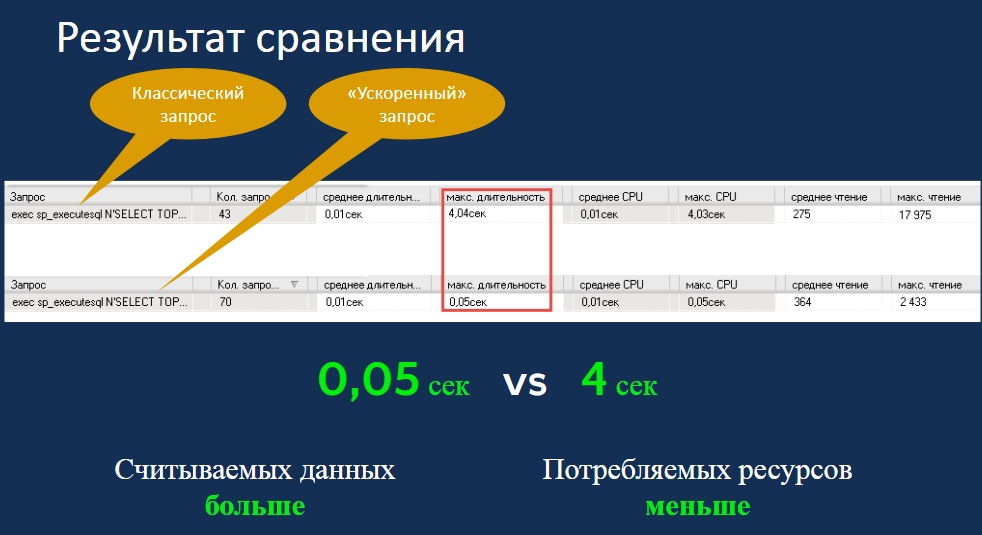
На практике получается очень интересная история – ускорение в десятки, в сотни раз. Причем, все это можно сделать средствами 1С, что очень приятно. Переписывать логику не потребуется, пользователь порадуется, что у него ускорился запрос поиска. В примере ускорение с 4 секунд до 0,05 секунды, а если бы у нас изначально запрос выполнялся две минуты, он стал бы исполняться менее секунды.
Механизм, что я вам показал, не является каким-то экспериментальным примером, это уже работает у реальных клиентов.
Подготовительные мероприятия для внедрения
Теперь я расскажу кратко о подготовительных мероприятиях.
- Сначала необходимо заполнить регистр начальными значениями. Для этого мы должны запланировать регламентное окно.
- Далее мы должны соблюсти консистентность данных – это значит, должна быть подписка на изменение значения, чтобы эта Фрагменты автоматически перестраивались.
- И последнее – дописать стандартную форму поиска.
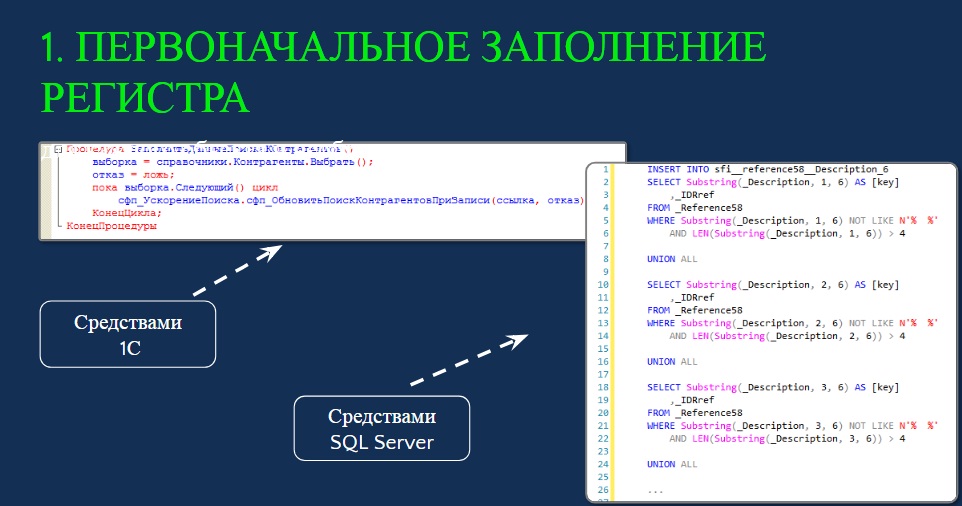
Заполнение регистра можно делать как средствами 1С, так и с помощью SQL.
Могу сказать, что заполнение такой структуры для 17-ти миллионов значений занимает где-то 20-25 минут. Естественно, пользователи в этот момент не должны изменять значения справочника.

Далее можно добавить либо триггер, либо 1С подписки, которые позволяют синхронизировать фрагменты с реальным значением поля.

Можно и нужно рассчитать необходимое дисковое пространство. Здесь все зависит от того, сколько символов в наименовании, какую мы взяли длину фрагмента, и какой размер ссылки на искомый объект.

Если мы рассчитаем для одного миллиона значений где-то 100 символов по 6 во фрагменте, получится где-то 4,7 Гб. Нужно запланировать, чтобы это место у вас было. Если у вас в справочнике, например, 100 миллионов значений, то вы должны запланировать место, которое будет доступно на диске.
Необходимость учета статистики популярности фрагментов
Всегда ли этот метод будет работать быстро?
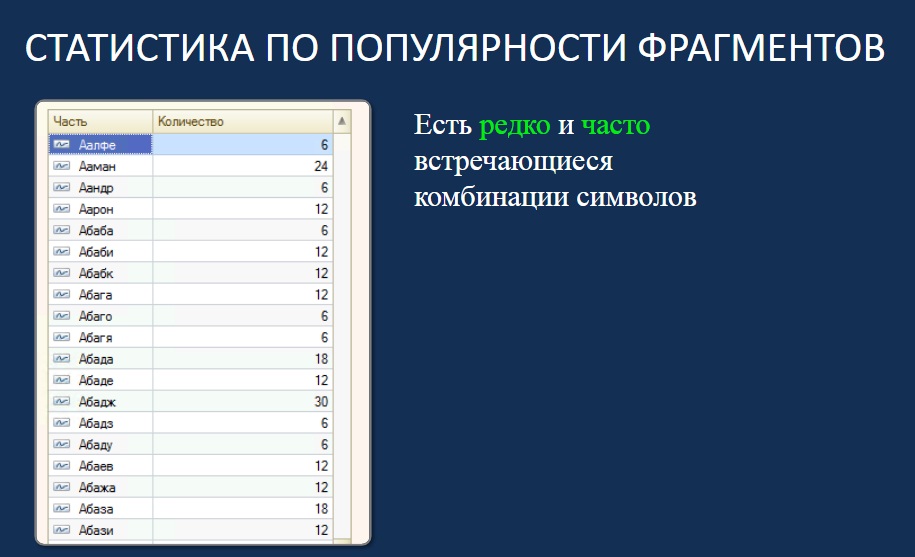
На это влияет статистика популярности фрагментов.
- Например, у вас есть фрагмент «алексе», который может входить в имя Алексей, в отчество Алексеевич, в фамилию Алексеенко и т.д. Этот фрагмент может входить в 50-100 тысяч записей.
- А есть редко используемые фрагменты.
Таким образом, появляется статистика популярности по фрагментам.
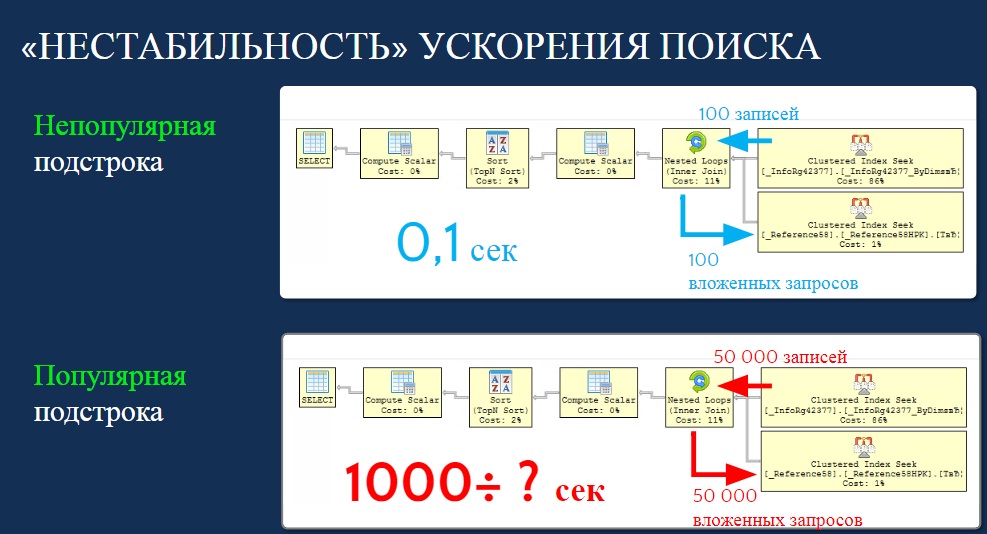
Обратите внимание, что если популярность фрагментов низкая (100 элементов), то мы получаем ускорение – 0,1 секунду.
Если подстрока достаточно популярная (50 тысяч элементов), то мы получаем деградацию, причем гораздо большую, чем если бы не было оптимизации.
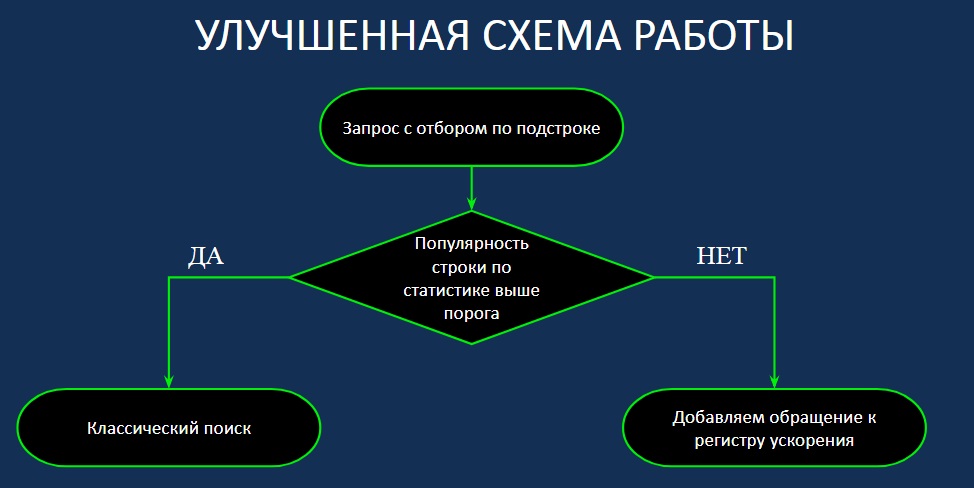
Таким образом, необходимо сделать улучшенную схему выполнения запроса, в которой мы сначала бы получили значение популярности подзапроса. Это делается тремя-пятью строчками в 1С. При этом мы точно знаем, что если строка непопулярная, то идет по первой ветке, а если популярная, то по второй.
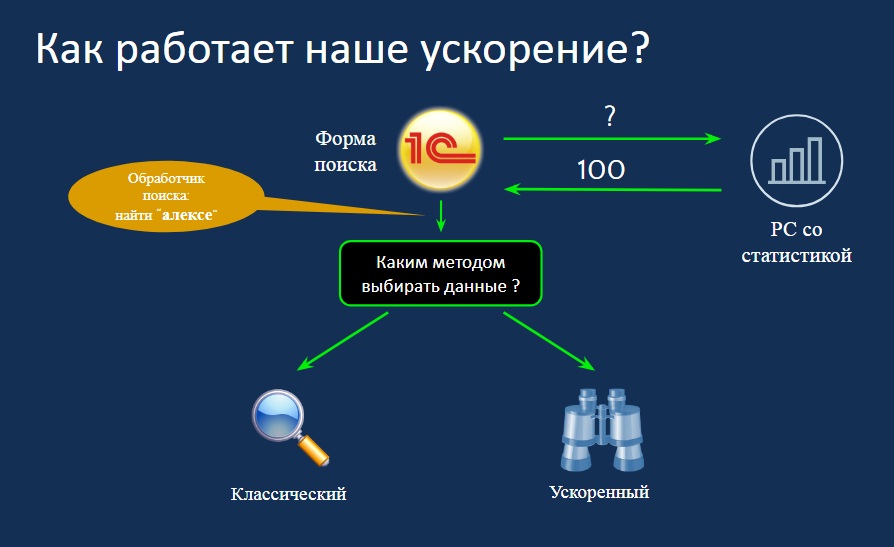
Как работает ускорение? Идет запрос поиска из формы, далее мы обращаемся к регистру сведений со статистикой, получаем элемент и дальше выбираем, что использовать – классический или ускоренный запрос.
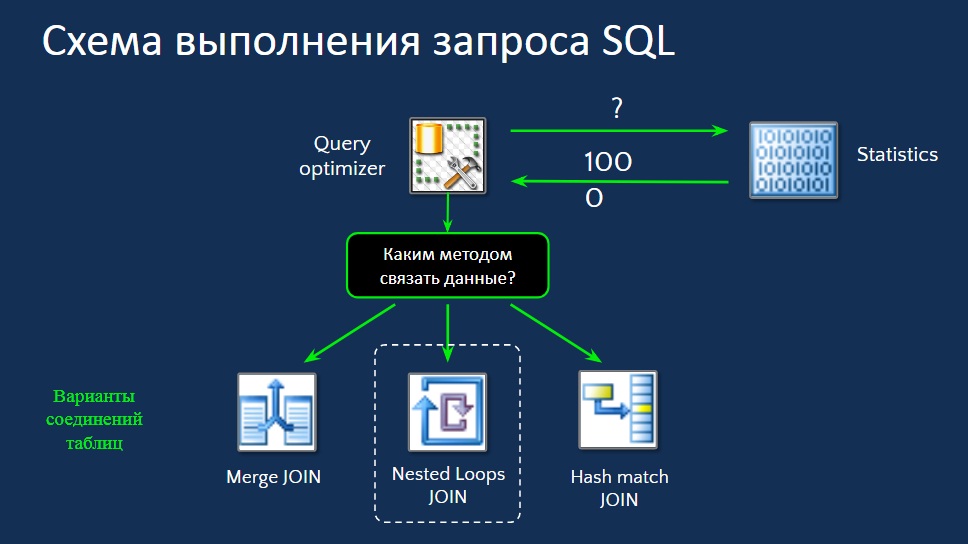
А теперь давайте рассмотрим, как выполняется SQL-запрос на SQL-сервере.
На слайде представлена упрощенная схема:
- идет запрос к оптимизатору;
- мы смотрим статистику по полям, которые используются в запросе;
- выбираем, какой план выполнения использовать, то есть выбираем стратегию выполнения запроса (например, вложенный цикл).
На что похожа реализованная нами схема?
- Мы сделали свой индекс. Не стандартный индекс SQL, не индекс 1С, а свой индекс, который нужен для решения этой задачи;
- Более того, столкнулись с тем, что нужна своя статистика;
- И нужен собственный оптимизатор, который по этой статистике решает, какую ветку выбрать.
Исходя из этой логики, можно сказать, что этот процесс раскрывает смысл того, для чего нам индексы, статистика и оптимизатор.
Кто не знал, для чего нужно обслуживать статистику в SQL, загляните в эту логику, и вы поймете, что если она неправильная или неактуальная, то мы пойдем по неправильной ветке. Запрос будет тормозить. Понимаем, для чего качественно и правильно обслуживать статистику – это влияет на производительность, на индекс.
Если индекса нет – будем сканировать все значения.
Таким образом, мы создали хоть примитивный, но свой оптимизатор. Можно сказать, что прощупали «на пальцах» то, как это делает MS SQL и другие СУБД, причем создав свои структуры.
Ускорение «больших» документов
Перейду ко второй теме – ускорение больших документов.
Мы в производственных задачах часто сталкиваемся с какими-то регламентными процедурами, как: закрытие месяца, отчет агенту, расчет себестоимости. Эти тяжелые, массивные документы проводятся и заполняются значительное количество времени. А когда мы заглядываем в отладчик и делаем на этих операциях трассировку, то видим, что 1С построчно вставляет значения в какую-то таблицу и на это уходит основное время. И ничего с этим поделать нельзя. Единственная рекомендация, которую можно предложить – это ускорить диск (эффективность этого решения очень сомнительная и требует предварительного анализа).
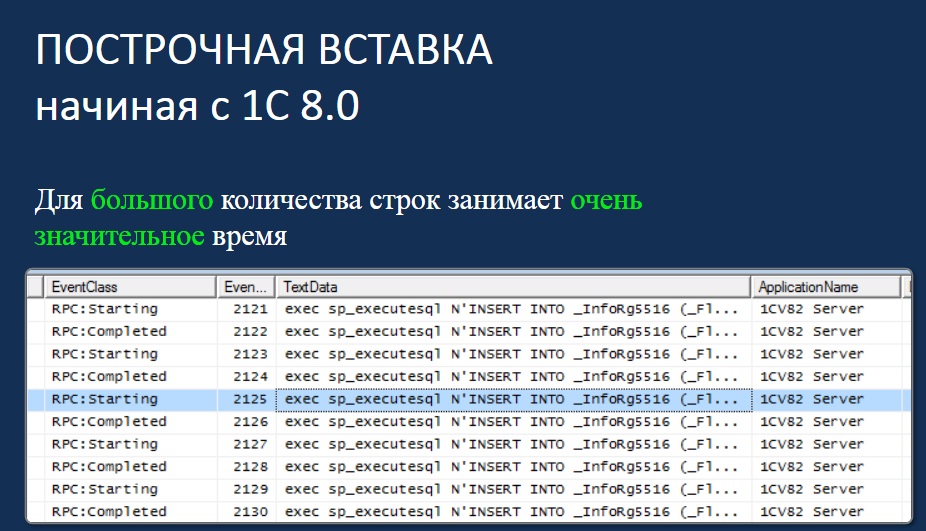
Предлагаю вернуться в историю и рассмотреть, как это делалось в 1С, начиная с 8.0 до 8.3 – это делалось построчно. SQL-сервер каждый раз анализировал запрос, его обрабатывал, создавал план выполнения, добавлял, отправлял команду в сторону 1С об успешности и получал следующий запрос. И такими step by step шли запросы от 1С сервера приложения к MS SQL.
Понятно, что если у вас 40 записей в документе, то проблем возникнуть не должно. Если записей у вас становится 10 тысяч и более (бывают организации, где в регламентных документах миллион записей), то этот процесс занимает очень длительное время. Одна запись обрабатывается очень быстро, но в документе их слишком много. На что уходят накладные расходы? На сеть, на выполнение запроса, на обратный сигнал, на обработку этого сигнала в системе 1С – итого, сумма четырех этапов. Все этапы суммируются, умножаются на миллион строк, и получаются наши длительные ожидания. Понятно, что это не ужасно.
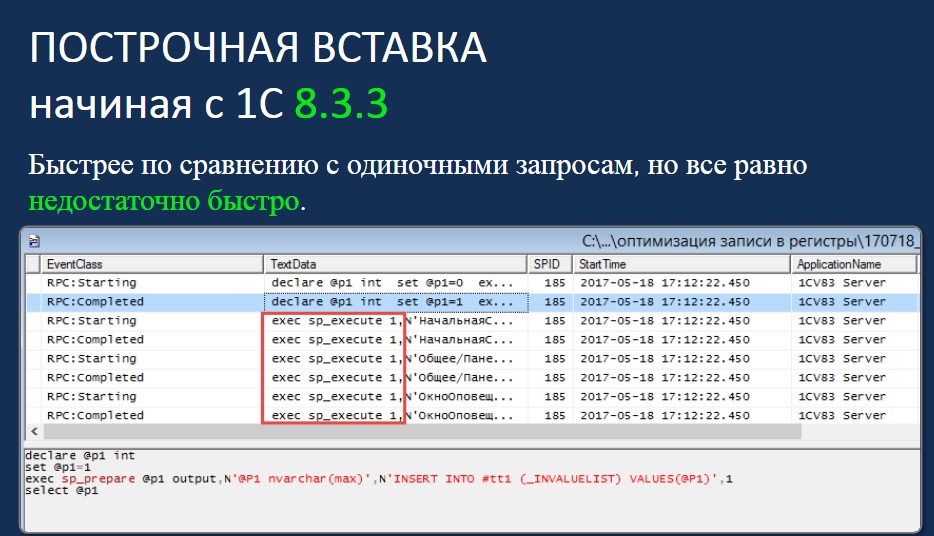
В 1С, начиная с 8.3, сделаны улучшения. Теперь запрос для вставки во временные таблицы и в регистры сведений подготавливается на SQL-сервере, и его дальнейшее выполнение происходит с помощью классических RPC-вызовов, где сам провайдер доступа 1С (Native или OLE DB) группирует записи и вставляет их по N строк (как правило 100 строк).
Таким образом, достигается ускорение от 30% до 300%. Но это все равно недостаточно, потому что сегодня у вас 10 тысяч строк, завтра 20 тысяч строк. Это не принципиальное решение проблемы, вы все равно с ней столкнетесь, но только через полгода/год.
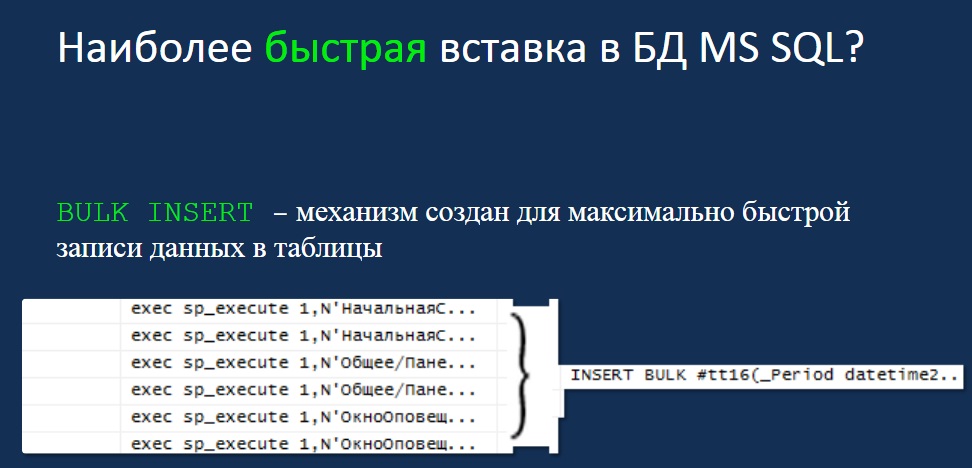
Какая наиболее быстрая вставка в SQL-сервер, да и вообще в любую СУБД?
Это BULK INSERT. В 1С BULK INSERT используется, но для других задач. Работу с «большими» документами также хотелось бы ускорить путем укрупнения вставок INSERT и добавления записей единым массивом в базу данных SQL-сервера.

Посмотрим, какой достигается эффект. В рассматриваемом примере получено ускорение где-то в 5 раз, но можно ускориться и в 10 раз. Теоретически основная проблема для того, чтобы это ускорялось значительно сильнее – это скорость диска. Диск может является узким местом.
Также важно помнить про такой критерий, как индексы. Если бы мы вставляли BULK INSERT в таблицу без обновления индексов, то мы бы получили значительное ускорение (результат менее чем за секунду). Здесь мы получаем 69 секунд за счет того, что каждая вставка в таблицу требует REFRESH индекса.
В любом случае, этот способ позволяет достичь эффекта в 5-10 раз.
Плюс здесь не рассматриваются такие возможности, как партиционирование, секционирование. Можно было бы улучшить ситуацию, если бы мы знали, что BULK INSERT вставляется в актуальный период, а неактуальный мы вынесли бы в другую партицию. Это был бы еще больший эффект. Получается, что ускорение очень хорошее.
Возможности оптимизации безграничны
Таким образом, возможности оптимизации безграничны. Единственное – не увлекаться. До оптимизации всегда имеет смысл посчитать, будет ли предполагаемый эффект или нет. Также я бы советовал в каких-то ситуациях «подниматься» над проблемой, использовать не классические методы оптимизации запроса, а какие-то совсем иные, которые могут принести более значительный результат.
Данная статья написана по итогам доклада, прочитанного на конференции INFOSTART EVENT 2017 COMMUNITY.


Вступайте в нашу телеграмм-группу Инфостарт