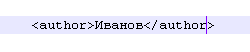
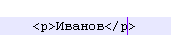

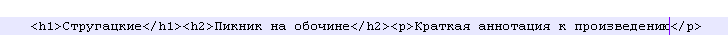










{kind=link}
В продолжение статьи Использование регулярных выражений (RegExp) в 1С8.х. Углубляемся в практику использования регулярных выражений в 1С. Основы работы с регулярными выражениями хорошо описаны в указанной публикации. А я попробую ответить на вопрос "почему именно регулярные выражения?" на примере конкретной рабочей задачи.
Удобный и неудобный
Прежде чем приступить к непосредственному разбору практической задачи хотелось бы внести ясность в понятия "удобный" и "неудобный" формат на примере xml и html. Первый (xml - расширяемый язык разметки) предназначен именно для хранения информации, в то время как последний (html - язык разметки гипертекста) предназначен для структурированного отображения информации.
"В чем же такая большая разница? И там и там язык разметки." - резонно заметите вы. Все дело в значимых тегах. Теги xml предназначены для идентификации определенного в них содержимого. Например:

Слово "Иванов", заключенное в тег для читающей xml-файл системы будет означать, что Иванов - автор, со всеми вытекающими последствиями. xml потому и называется "расширяемым", что названия тегов разработчик вводит сам с учетом потребностей по хранению/передаче определенной информации.
Теги html служат для того, чтобы сказать читающей системе (браузеру), как нужно визуализировать (отобразить в окне браузера) те или иные данные. Теги html конечны, т.е. разработчик сам не может придумать свой тег, иначе браузер его не поймет. Например:
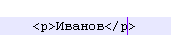
Для браузера будет означать, что слово "Иванов" отображается в окне браузера как новый параграф с соответствующими отступами и т.п. Из этого мы вовсе не знаем, что Иванов - автор. Очевидно, что html - неудобный для парсинга (разбора) формат.
Справедливости ради надо заметить, что html может стать частично удобным форматом если тегам начать присваивать классы или идентификаторы. Если в нашем случае будет написано например так:

то в принципе из этого можно конечно заключить, что Иванов - автор, но все-таки это скорее ухищрение, т.к. классы в html естественно не предназначены для идентификации данных - они предназначены для конкретизации визуализации (отображения) и лишь косвенно могут служить для идентификации. Поэтому давайте считать html неудобным форматом для хранения/передачи информации.
Все было бы хорошо, НО на практике иногда приходится сталкиваться с задачами, когда данные нужно извлечь именно из таких вот неудобных форматов, как html. Приведу пример (который собственно дальше и разберу). У меня есть разработка Анализатор мобильной связи. Один из клиентов предоствил для извлечения детальных расходов по трафику именно html, в котором у тегов напрочь отсутствуют идентификаторы или классы, т.е. никакого намека на возможность идентификации. Однако не все потеряно, даже наоборот, все очень даже интересно получается с помощью регулярных выражений. Ведь html - это вовсе не набор бессвязной информации, а вполне себе структурированное содержимое, отдельные части которого имеют зависимости друг между другом.
Почему регулярные выражения?
Суть работы с регулярными выражениями сводится к элементарному разбору строк и поиску в них совпадений и субсовпадений. Прелесть метода последовательного построчного разбора очевидна - низкие требования к ресурсам компьютера.
"Почему именно регулярные выражения?" - сросите вы. Ведь можно использовать штатные средства платформы 1С "Найти", "СтрДлина", "СтрЗаменить" и пр. Да, можно, но программный код с использованием регулярных выражений локоничнее и понятнее. Для того, чтобы идентифицировать определенные данные в строке, нужно будет написать кучу "Если", "Найти", "СтрЗаменить" и т.д. В регулярных выражениях весь этот массив кода можно заменить одним шаблоном (паттерном).
Ключевым моментом при работе с регулярными выражениями является выявление уникальной комбинации строковых выражений. Именно комбинация определенных строковых выражений и служит идентификацирующим признаком значимых данных. Поясню. Например, встречая в разбираемом файле такую комбинацию тегов:

знаем, что в первом теге h1 содержится название автора произведения, во втором теге h2 содержится название произведения, а в третьем теге p содержится аннотация к произведению. Т.е. каждый раз встречая в файле набор этих тегов я заранее знаю что находится в первом, втором и третьем тегах. Повторюсь - здесь важно знать, что комбинация уникальна, т.е. не должно быть другой такой же комбинации тегов, в которых содержится какая-то другая информация или присутствует другой порядок данных. Это знание и регулярные выражения позволяют извлекать из таких вот уникальных комбинаций нужные данные.
Практика
Ничто так не позволяет усваивать материал, как практика.
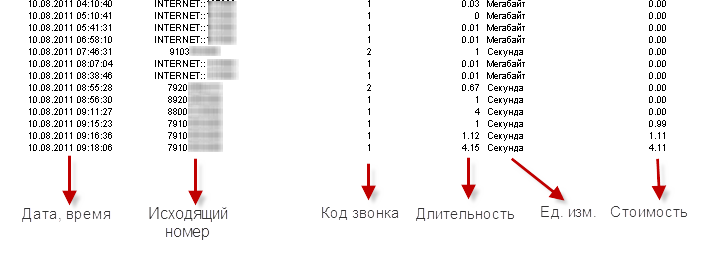
Ниже на скриншоте вы можете наблюдать фрагмент отрисованного в браузере счета, присланного в формате html:

"Чудесно, это же всего-навсего таблица и распарсить ее не составит труда" - подумаете вы. Как бы не так. Не стоит забывать, что это всего лишь фрагмент, до и после которого есть уйма всякой сопутствующей информации, как-то разрывы строк, колонтитулы, итоги, заголовки страниц и пр. и пр., вобщем структурированный хаос информации. И такого хаоса мегабайт на 200.
А теперь вот как одна из строк выглядит в html коде (строка длинная, поэтому я сделал перенос строк и обозначил места переносов символом "|"):

Кто разбирается в HTML знает, что тег tr обозначает строку в таблице, а td обозначает колонку, точнее ячейку в определенной колонке определенной строки.
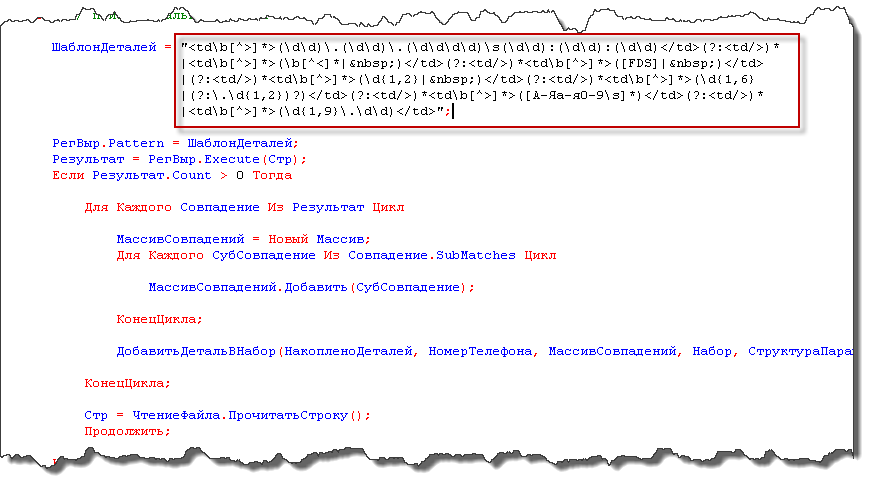
Парсить такое штатными средствами 1С весьма затруднительно, проще написать шаблон на языке регулярных выражений и текст исходного кода сокращается в разы. Ниже пример разбора в 1С такого кода с помощью регулярных выражений (обращаю внимание, что это лишь фрагмент кода и я не акцентирую внимание на создание в 1С объекта для работы с регулярными выражениями - это итак хорошо описано в обозначенной мной выше статье):

Это собственно весь разбор. Далее уже следует работа с извлеченными данными.
Если при разборе строки все условия регулярного выражения выполнены - это значит, что мы разбирали именно строку детализации, а значит в МассивеСовпадений располагаются в порядке очередности нужные данные (дата/время, номер собеседника, количество, стоимость и т.д.)
Давайте теперь пройдемся по регулярному выражению и переведем на русский язык условия, заданные с помощью самого него.

- Ищется тег td внутри которого может присутствовать описание классов, атрибутов и т.п.
- Ищется последовательность цифр и символов: 2 цифры, точка, 2 цифры, точка, 4 цифры, пробел, 2 цифры, двоеточие, 2 цифры, двоеточие, 2 цифры. Это ничто иное как дата и время. Причем все, что находится в круглых скобках запоминается и затем попадет в МассивСовпадений, за исключением тех скобок, в которых сначала идет ?:.
- Ищется закрывающий тег td, после которого идет произвольное количество тегов td до выполнения следующего по выражению условия.
- Далее по условию следует либо любой символ, кроме символа >, либо символ "пусто". Пусто, потому что в ячейке может быть пусто, что будет обозначено специальным символом. Здесь производится поиск номера собеседника.
- Далее по условию должны встретиться одна из букв F, D, S либо знак "пусто" - это тип звонка.
- Далее по условию должны встретиться либо 1 цифра, либо 2 цифры, либо знак "пусто" - это код звонка.
- Далее по условию следует от 1 до 6 цифр, точка, 1 или 2 цифры. Причем последние две цифры необязательные. Это длительность звонка (количество).
- Далее по условию должны встиретиться любое количество русских букв, цифр или пробелов до выполенения следующего условия выражения. Это строковое представление единицы измерения длительности звонка.
- Далее по условию следуют от 1 до 9 цифр и в обязательном порядке точка и 2 цифры. Это стоимость звонка.
- Ну и напоследок закрывающий тег td.
Вступайте в нашу телеграмм-группу Инфостарт