Необходимые права на установку библиотек и запуск внешних обработок
Интерфейс Vanessa-ADD : запись сценариев
Кнопка подключения тест-клиента
Кнопка "Подготовить сценарий к выполнению"
Кнопка "Добавить известный шаг"
Группа команд "Форма" (получение состояния тестируемой формы)
Пункт "Запомнить состояние формы TestClient" и связанные с ним команды
Пункт "Получить состояние текущего элемента формы" и тестирование отчетов
Пункт "Получить состояние всей формы"
Интерфейс Vanessa-ADD: загрузка, воспроизведение и отладка сценариев
Отображение связи шагов с реализующим их методами внешних обработок
Открытие сценариев на редактирование
Отладка сценариев в Vanessa-ADD и методов, реализующих шаги, в конфигураторе
В комментариях к предыдущей публикации Леонид Паутов предоставил информацию о параллельном для Vanessa-ADD проекте https://github.com/Pr-Mex/vanessa-automation. Большая часть информации, приводимая в этих публикациях, будет справедлива в отношении всех инструментов, основанных на Vanessa-Behavior, но конечно есть и отличия. У меня пока нет возможности рассмотреть особенности параллельного проекта, так как сейчас сосредоточен на использовании и описании возможностей Vanessa-ADD, но возможно вы захотите ознакомиться с ним самостоятельно.
В первой части этого цикла публикаций мы говорили об основах применения Vanessa-ADD, сценарного тестирования и BDD, рассматривали пример создания полноценного сценария и фича-файла. В этой публикации подробно рассмотрим процесс установки минимально необходимого набора инструментов, а затем перейдем к детальному рассмотрению интерфейса и возможностей по записи и воспроизведению сценариев.
Vanessa-ADD поощряет выход специалистов за рамки замкнутой экосистемы 1С. Для комфортной работы с этим фреймворком необходимы другие библиотеки OneScript и многофункциональный редактор Visual Studio Code от Microsoft. Для получения отчетности по результатам выполнения сценариев понадобится также фреймворк Allure 2 от компании Яндекс и один из вспомогательных инструментов для создания скриншотов в момент возникновения ошибок. Если же вы решите идти дальше в направлении совместной работы над сценариями и автоматизации их запуска, то потребуется также git и сервер сборок (Jenkins / TeamCity / Bamboo / Gitlab CI).
По началу это может показаться сложным, но изучив даже малую часть возможностей этих инструментов вы уже не захотите от них отказываться )) Например упомянутая в предыдущей публикации библиотека Vanessa-Runner не только упрощает автоматический запуск тестирования, но и содержит очень удобные возможности управления кластером серверов через службу RAS, как через программный код на OneScript, так и через простые консольные команды. С этой библиотекой упрощается вывод информации о ходе выполнения тестирования в консоль (stdout), а значит и в логи серверов сборок. Для запуска платформы 1С нужной версии из консоли или скрипта OneScript достаточно указать маску версии, путь будет к исполняемым файлам будет определен автоматически подобно тому, как это делает стандартный 1cestart. И это только часть возможностей.
Также важно, что все указанные инструменты являются проектами с открытым исходным кодом и распространяются свободно :
https://github.com/Microsoft/vscode
https://github.com/jenkinsci/jenkins
https://github.com/EvilBeaver/OneScript
https://github.com/silverbulleters/vanessa-runner
https://github.com/allure-framework/allure2
Сейчас ограничимся установкой OneScript , Visual Studio Code и собственно Vanessa-ADD. Именно этого набора будет достаточно, чтобы создавать, редактировать и запускать на выполнение сценарии. Установку других инструментов рассмотрим, когда перейдем к вопросу автоматического запуска сценариев. И возможно к теме отчетности, если получится добраться и до этой темы (если не получится, то посмотрите вебинары, где показаны эти возможности : Обзор возможностей Open Source продукта Vanessa-Behavior и Vanessa-ADD - Продукт для проверки качества поведения системы).
Установка инструментов
OneScript и Vanessa-ADD
Vanessa-ADD может устанавливаться отдельно от OneScript из репозитория проекта https://github.com/silverbulleters/add/releases как zip-архив. Однако гораздо более удобной и правильной установкой будет работа посредством OneScript и его менеджера пакетов opm. В этом случае мы будем устанавливать Vanessa-ADD как одну из библиотек OneScript.
OneScript можно скачать по ссылке http://oscript.io/downloads
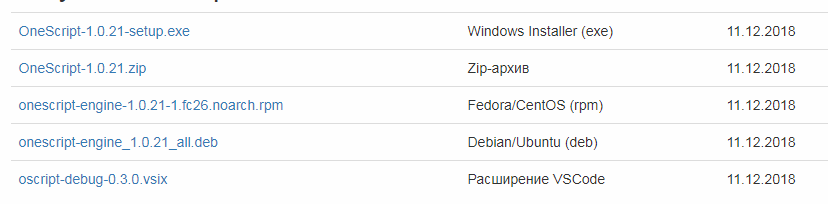
Для Windows нам необходим первый из файлов - на текущий момент это OneScript-1.0.21-setup.exe. Архив OneScript-1.0.21.zip имеет смысл использовать если у вас на компьютере нет прав на установку программ. Этот zip-архив позволит выполнить портативную установку OneScript в домашний каталог пользователя. oscript-debug-0.3.0.vsix - это расширение для Visual Studio Code для отладки скриптов. Его удобнее устанавливать непосредственно из VSC а не отдельным файлом. Кроме того для работы со сценариями Gherkin он не требуется.
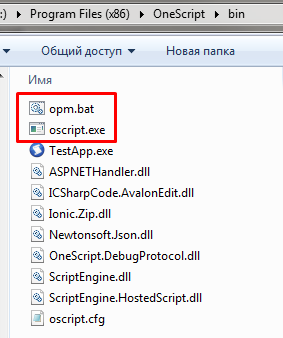
Установив OneScript из файла OneScript-x.x.xx-setup.exe в комплекте с ним мы получим только базовые библиотеки. Управлять установленными библиотеками и устанавливать новые можно с помощью менеджера пакетов opm. Если вы знакомы с концепцией управления пакетов в Linux или c Chocolatey в Windows, то подход к использованию opm покажется знакомым.
После установки, путь к каталогу с исполняемыми файлам OneScript, содержащему файлы opm.bat и oscript.exe, добавляется в переменную окружения PATH. Если этого не произошло, то нужно сделать это самостоятельно. В Windows это каталог C:\Program Files (x86)\OneScript\bin.
Благодаря этому команды opm и oscript можно будет выполнять из консоли не прописывая полный путь. Например можно выполнить команду opm list, получив полный список установленных пакетов:
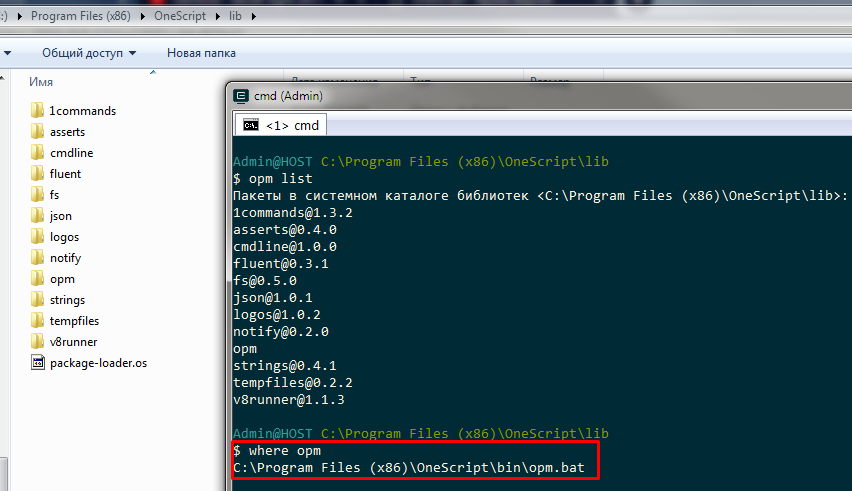
Vanessa-ADD в репозитории OneScript числится под названием add и для ее установки можно выполнив команду opm install add. Также можно установить все известные менеджеру пакетов библиотеки командой opm install --all. В их числе будет и Vanessa-ADD.
При установке библиотеки также автоматически устанавливаются все библиотеки, от которых зависит указанная в команде install:
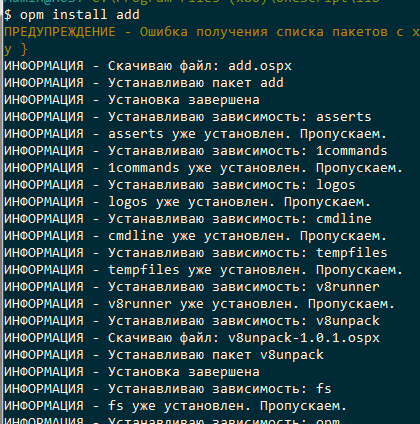
После установки в каталоге библиотек у нас появится новый подкаталог ADD.
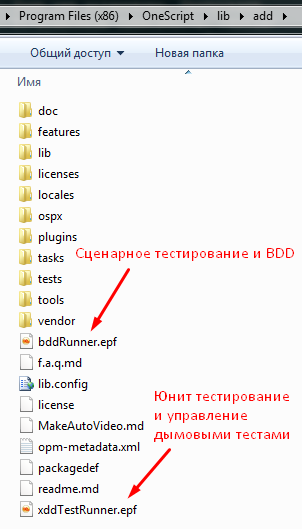
Запускать Vanessa-ADD для работы с фича-файлами и сценариями следует в пользовательском режиме 1С:Предприятия путем открытия внешней обработки bddRunner.epf. Но запускать 1С:Предприятие при этом необходимо в режиме менеджера тестирования. Потому что Vanessa-ADD - это фактически надстройка над менеджером тестирования, которая должна запускать клиент тестирования для того чтобы проиграть сценарий или записать его.
Для этого в настройках информационной базы следуют указать ключ /TESTMANAGER.
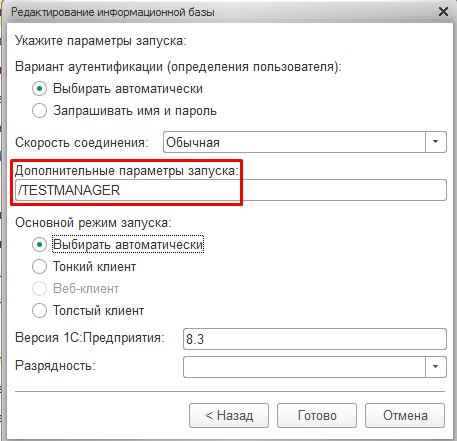
При запуске из конфигуратора этот ключ не работает. Вместо него следует указывать соответствующий переключатель в диалогвом окне дополнительных параметров запуска 1С: Предприятия:
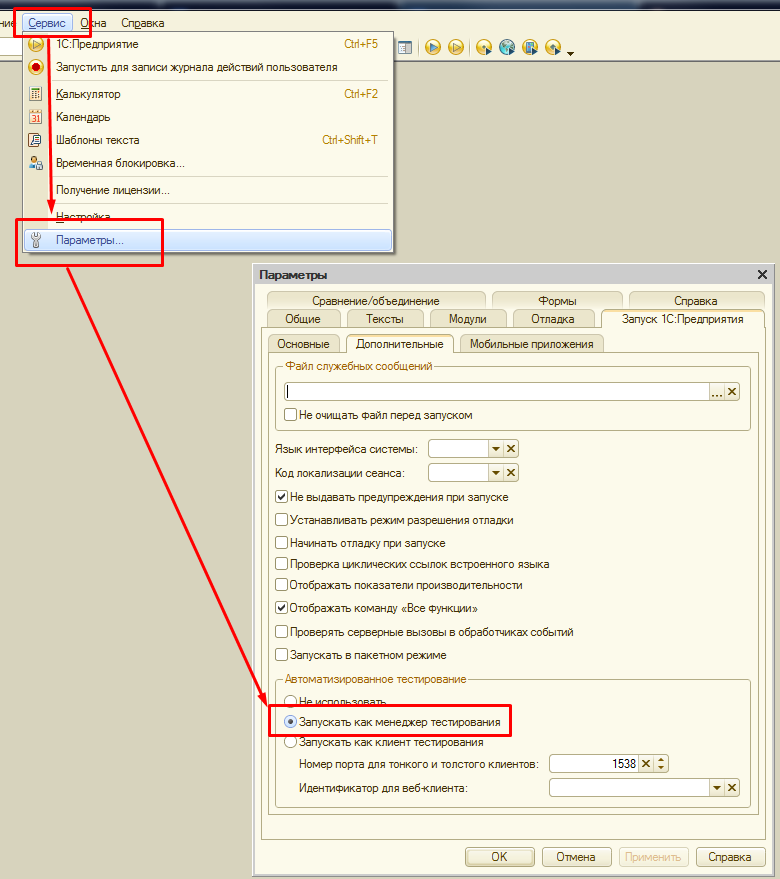
Проверим установку открыв файл bddRunner.epf и выполнив запись действий пользователя :
Visual Studio Code
Для просмотра и редактирования сценариев на языке Gherkin мы будем использовать редактор от Microsoft - Visual Studio Code. Его дистрибутив можно скачать на сайте проекта https://code.visualstudio.com.
Ранее наряду с Vanessa-Behavior для создания сценаривев поставлялся инструмент bdd-editor https://github.com/silverbulleters/vanessa-bdd-editor , но в данный момент он является устаревшим.
В свою очередь VS Code является современным, расширяемым плагинами и широко распространенным редактором. Сейчас именно он предлагает наиболее удобные возможности для работы со сценариями. Есть вероятность, что другим инструментом для написания сценарных тестов может стать СППР. Но сейчас для Vanessa-ADD рекомендуемым редактором является VS Code.
Будьте осторожны! Не привыкайте к VSC. Освоив его возможности (поиск по регулярным выражениям, быстрая навигация мышью, плагины, интеграция с git, фон от которого не устают глаза), конфигуратор может показаться деревянным и вызывать боль при использовании ))
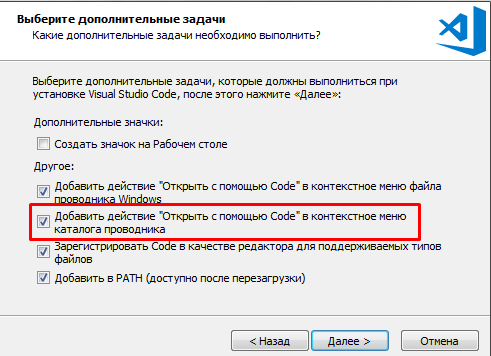
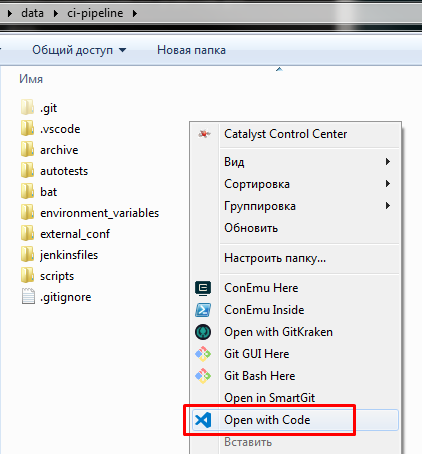
Установка VS Code возможна как в домашний каталог пользователя, так и для всех пользователей системы. Функциональность будет одинаковой. Что действительно важно - при установке не снимать флаг интеграции в меню проводника в контекстное меню каталога. Это сэкономит много нервов и движений мышью в будущем, так как и при работе со сценариями и при работе с git-репозиториями и при работе с OneScript чаще всего приходится работать с каталогом целиком :
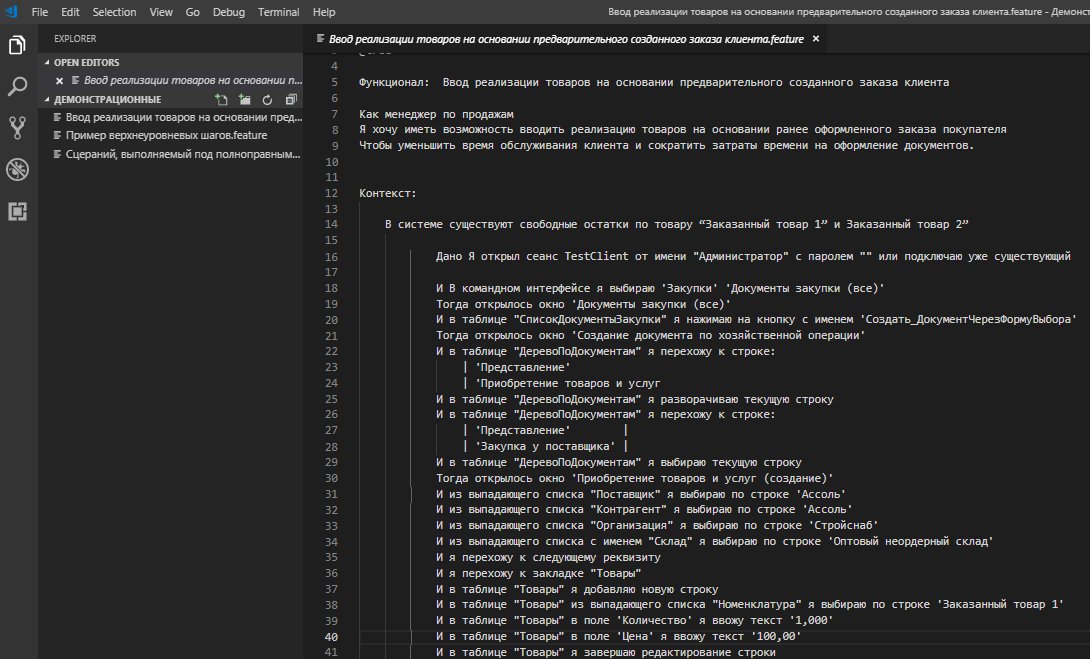
Открыв какой либо фича-файл в VSC сразу после установки можно увидеть неприглядную картину:
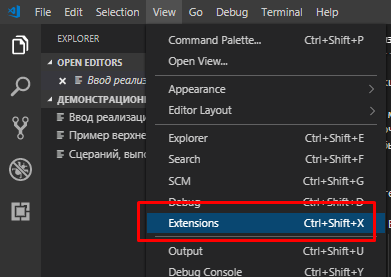
Дело в том, что сразу после установки VSC поддерживает подсветку синтаксиса далеко не всех возможных языков программирования, и уж тем более языков написания спецификаций. Для работы с языком Gherkin необходимо установить одно из подходящий расширений. В меню расширений можно перейти нажав Ctrl + Shift + X или выбрав меню View → Extensions.
Произведем поиск в расширениях по ключевому слову Gherkin. В самом верху отобразятся наиболее популярные расширения связанные с этим ключевым словом. Для подсветки синтаксиса нам подойдет либо Cucumber (Gherkin) Full Support либо Snippets and Syntax Highlighting for Gherkin (Cucumber). Раньше возможности этих расширений различались, но теперь они равнозначны и подойдет любое из них:
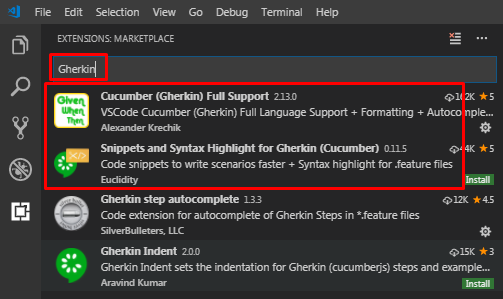
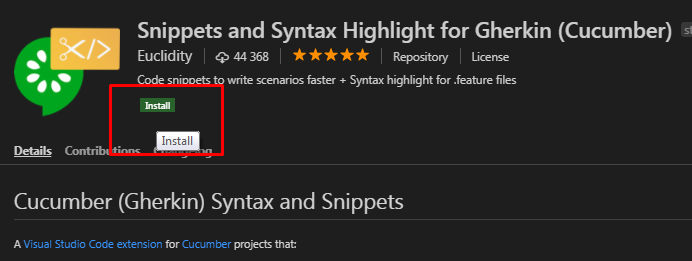
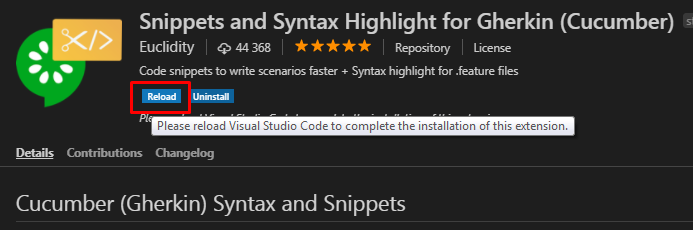
Выбрав расширение из списка для его установки необходимо нажать маленькую кнопку Install под его заголовком, а затем кнопку Reload, появившуюся на ее месте. Это приведет к перезагрузке VSC и активации установленного расширения :
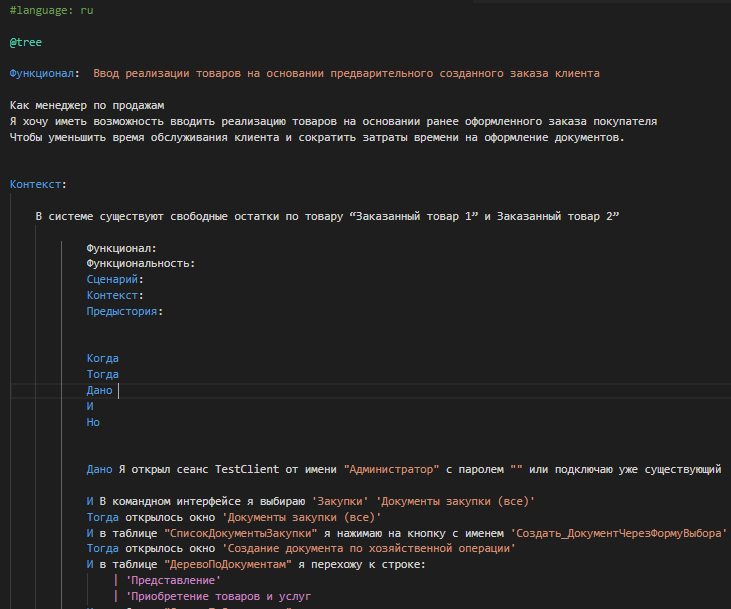
В результате установки получим подсветку , которую мы уже видели в первой части публикации :
Для VSC есть еще одно нужное нам расширение - Gherkin step autocomplete. С краткой документацией по нему можно ознакомиться по ссылке https://github.com/silverbulleters/gherkin-autocomplete. Этот плагин, несмотря на его нестабильную работу, может быть полезен при при ручном редактировании сценариев и адаптации сценариев к изменениям в тестируемой системе. Поэтому дополним его документацию разбором настроек и примерами. Устанавливается он так же как и другие плагины :
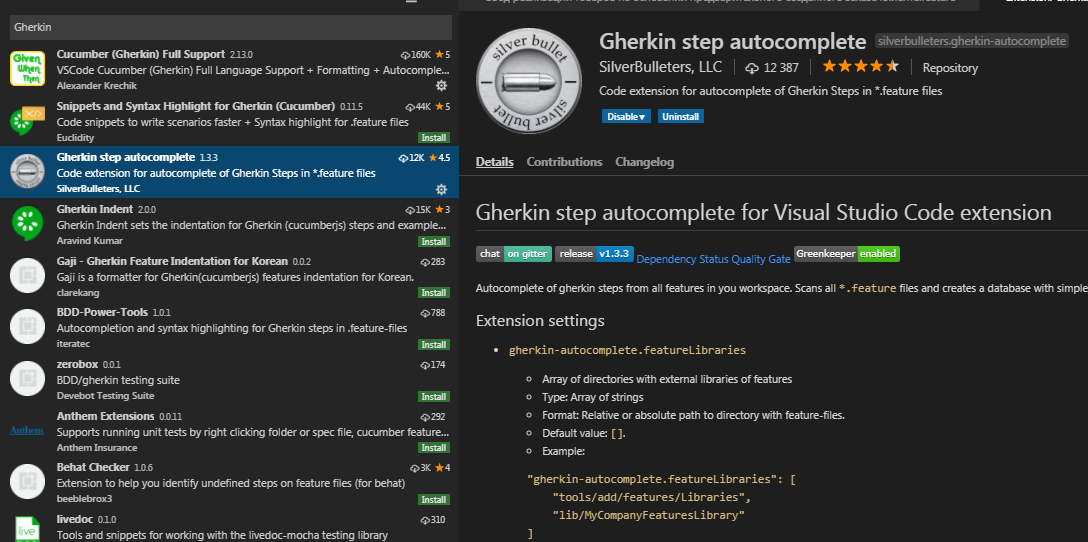
После установки необходимо выполнить настройки. Для этого в разделе настроек необходимо перейти в блок "Extensions" и затем к блоку с именем плагина :
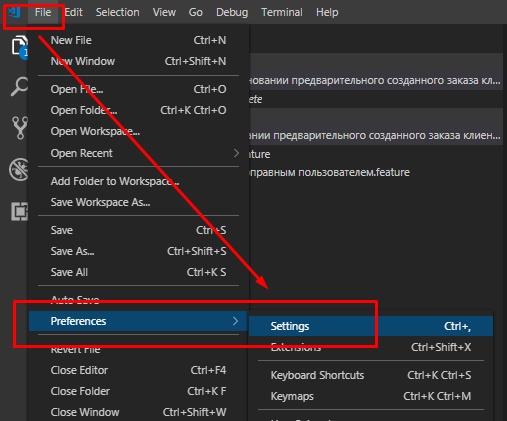
Редактирование настроек приводит к появлению подкаталога .vscode в каталоге проекта с файлом settings.json в нем.
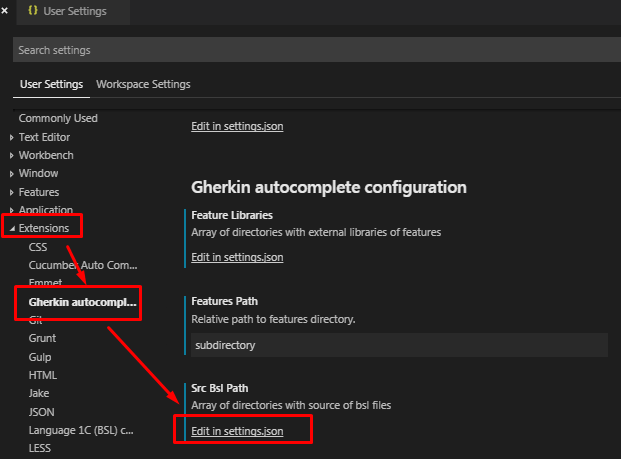
Нажимая на "Edit in settings.json" мы получаем возможность выполнить редактирование этого файла, но только тех строк, которые относятся к настройкам выбранного плагина, в нашем случае "Gherkin step autocomplete". Это удобнее чем редактировать файл settings.json напрямую.
Редактировать рекомендую настройки в блоке "Workspace settings". Это наиболее "точечные" настройки, которые переопределяют настройки по умолчанию для всего VSC и настройки для пользователя в целом.
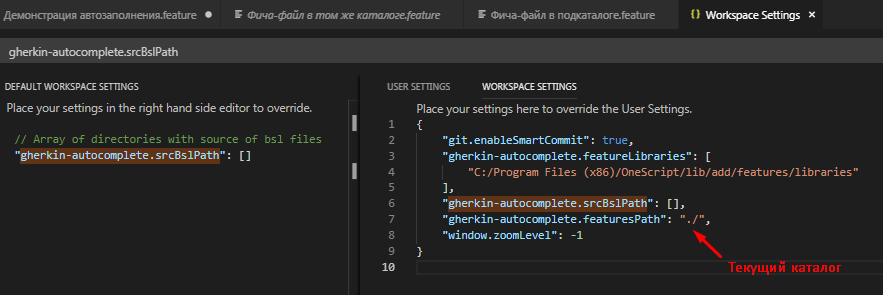
Пути к библиотекам шагов "gherkin-autocomplete.featureLibraries" - это массив. Пути здесь можно перечислить через запятую так, как это позволяет делать синтаксис json-файла. На скриншоте ниже здесь указан только один путь "C:/Program Files (x86)/OneScript/lib/add/features/libraries".
Путь к подкаталогу шагов текущего рабочего пространства "gherkin-autocomplete.featuresPath" это абсолютный или относительный путь к файлам из которых мы хотим читать шаги Gherkin. Разумеется если мы говорим о нашем рабочем каталоге, то лучше задавать здесь относительный путь , а не абсолютный. Это упростит перемещение каталога с фича-файлами при необходимости. Во избежание путаницы и неоднозначной трактовки путей в VS Code относительные пути лучше начинать в Linux-стиле с точки со слешем ./
Также это файл настроек в формате JSON и поэтому в качестве разделителей каталогов в путях удобнее использовать прямые слэши. Такие слэши в JSON не нужно экранировать и кроме того файл настроек получается более универсальным - прямые слэши в путях уже давно понимает не только Linux но и Windows :
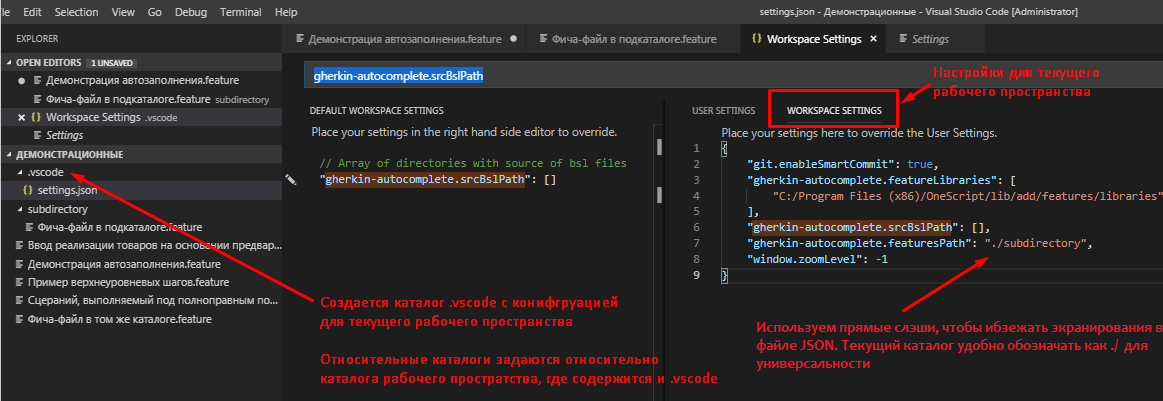
Разберем пример. Путь наши настройки заданы как на скриншоте выше. В подкаталоге subdirectory , указанном для плагина как каталог фич, мы создаем файл Фича-файл в подкаталоге.feature и в нем запишем шаг "И Я выполняю какой-нибудь шаг в подкаталоге"
Аналогично создадим файл Фича-файл в том же каталоге.feature в корне рабочей директории и пропишем в нем шаг "И Я выполняю какой-нибудь шаг в том же каталоге"
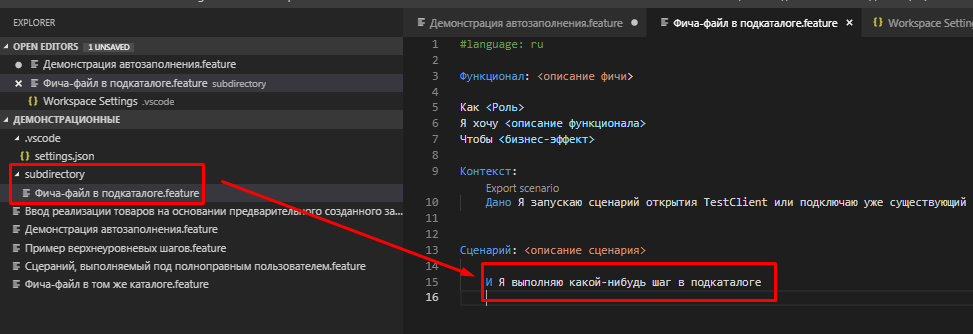
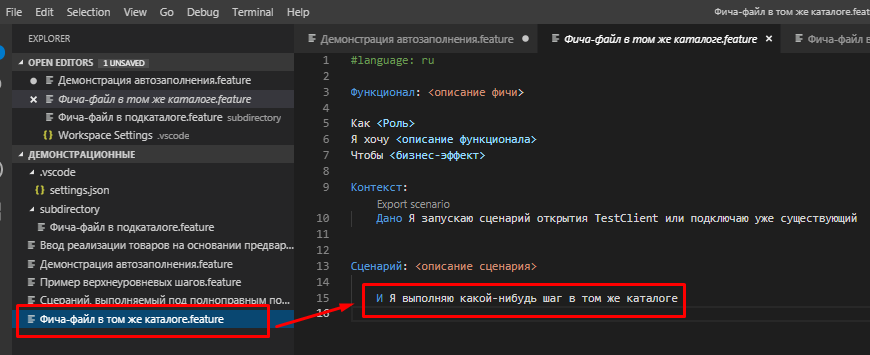
Посмотрим как в этом случае будет работать автодополнение в файле из корневого каталога пространства Демонстрация автозаполнения.feature.
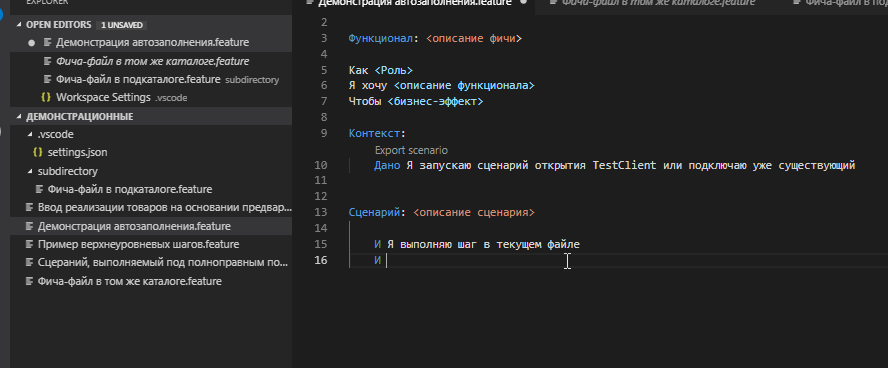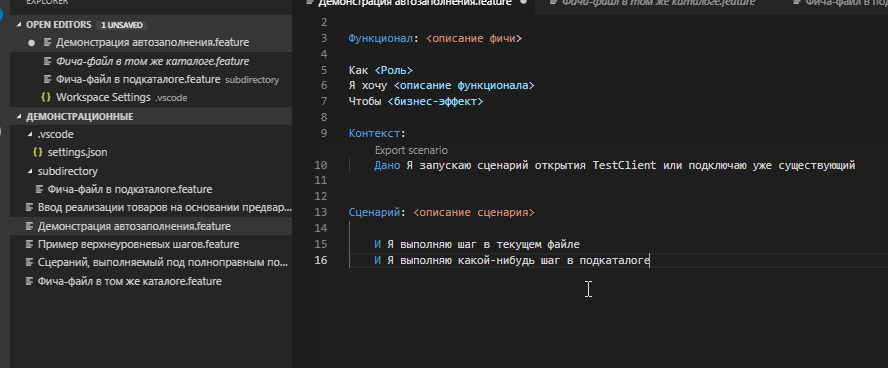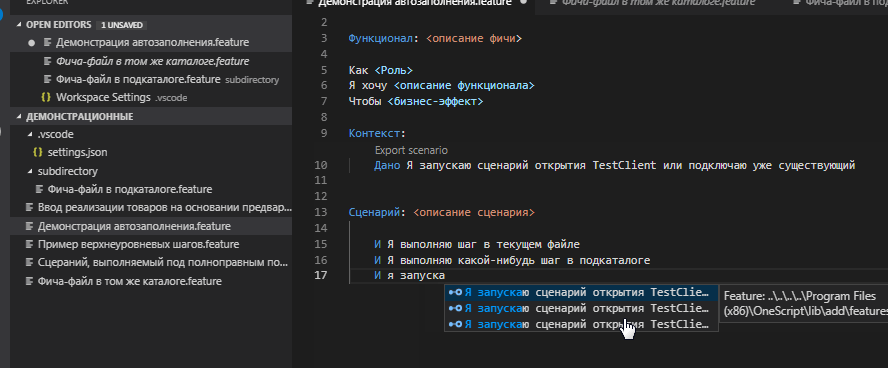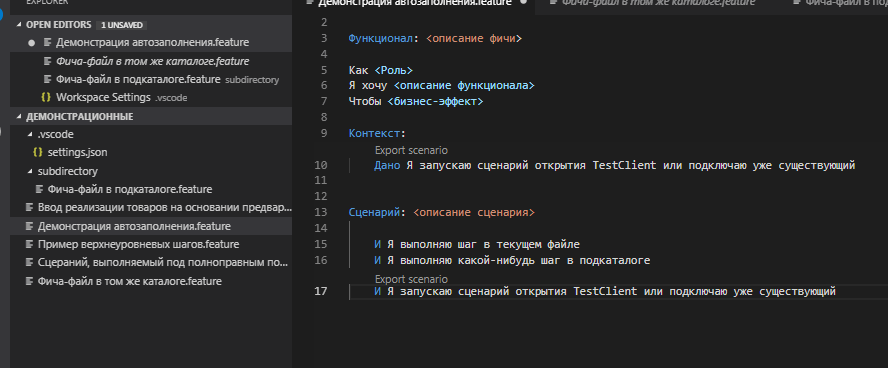
Видно что подтянулись шаги
- Из текущего файла (это стандартный функционал VSC не требующий плагинов)
- Из библиотеки "C:\Program Files (x86)\OneScript\lib\add\features\libraries". Это результат задания настройки "gherkin-autocomplete.featureLibraries"
- Из файла , расположенного в каталоге subdirectory. Это результат задания настройки "gherkin-autocomplete.featuresPath"
Однако не были предложены шаги их файлов того же каталога, в котором находится файл "Демонстрация автозаполнения.feature".
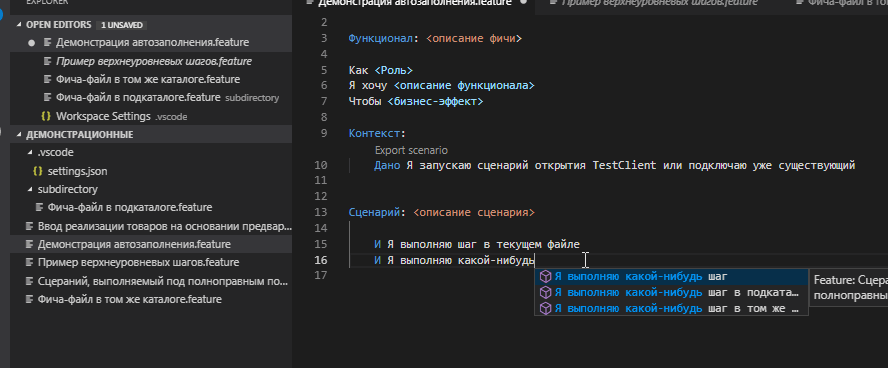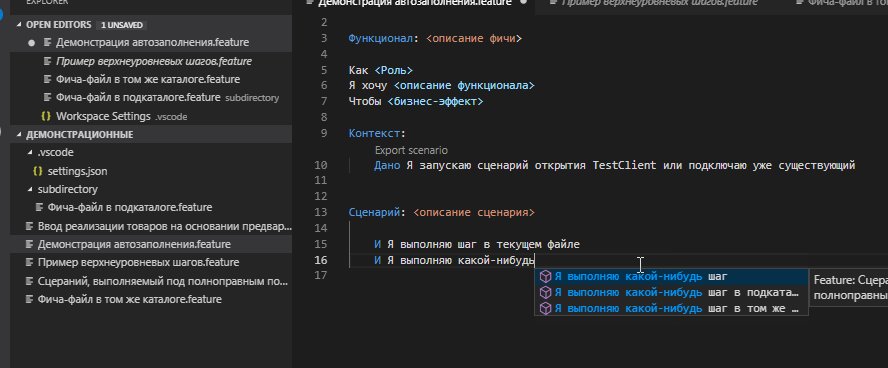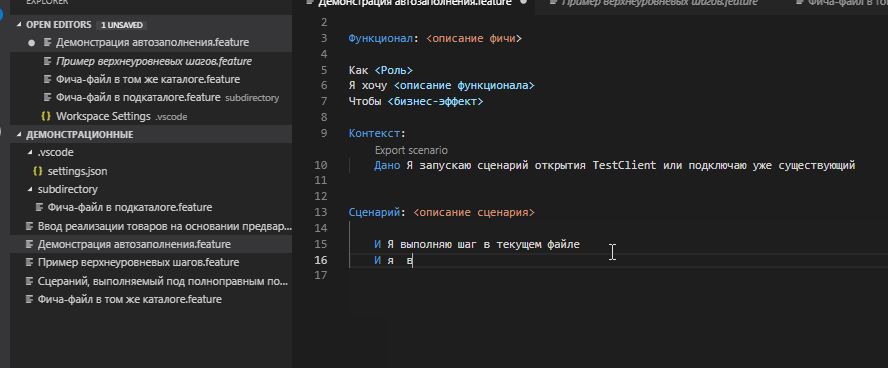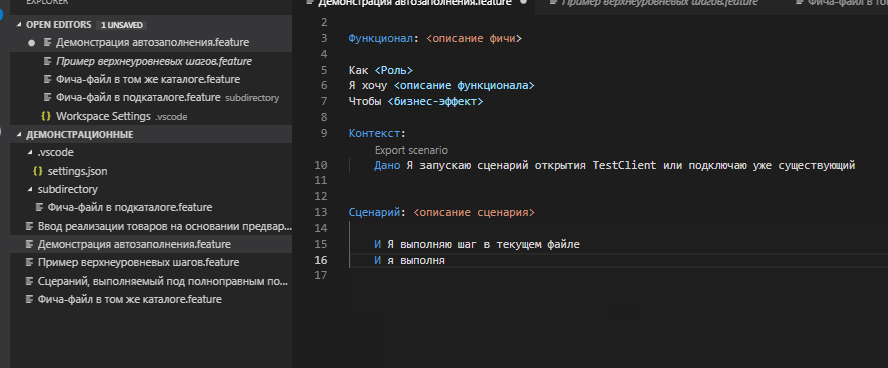
Теперь укажем в качестве каталога фич сам корневой каталог - нашу текущую рабочую директорию:
Теперь при автозаполнении иногда начнут предлагаться шаги и из файлов текущего каталога. Проблема в том, что это происходит иногда , то есть работа далеко не такая стабильная как хотелось бы :
Необходимые права на установку библиотек OneScript и настройка прав на запуск внешних обработок
Установка через команду opm install требует прав администратора. Если нет возможности выполнить установку под администратором или, например, закрыт доступ в интернет с сервера, на котором происходит установка, то мы получим сообщения об ошибках вроде таких:

Если подобная ошибка возникла и нет возможности обеспечить необходимый доступ для пользователя операционной системы то самый простой способ - это установить OneScript и нужные библиотеки на машину, где необходимые права есть. Затем перенести каталог OneScript на целевую машину и прописать путь к его подкаталогу bin в переменную окружения PATH. Другим способом является установка как OneScript так и Vanessa-ADD из zip-архивов.
Так как это очень редкий случай, то останавливаться на нём подробно не будем. Если вы с ним столкнётесь - предлагаю подробнее обсудить конкретные случаи в комментариях.
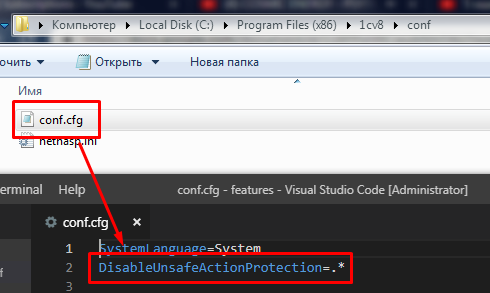
Vanessa-ADD в процессе выполнения сценариев запускает другие внешние обработки. Также в случае автоматического запуска сценариев необходимо чтобы открытие самой обработки bddRunner.epf не блокировалось настройками безопасности. Поэтому пользователю, под которым запускается обработка bddRunner.epf следует дать не только полные права, но и явно разрешить ему запуск внешних обработок :
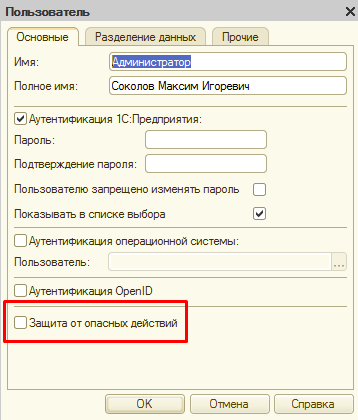
При автоматизации запуска сценариев и при построении CI-контура лучше делать это либо программно, либо разрешить запуск внешних обработок без предупреждения для баз, строка соединения которых подходит под заданную маску регулярного выражения. Подробно это описано на ИТС по ссылке https://its.1c.ru/db/v838doc#bookmark:dev:TI000001873
Например чтобы разрешить открытие внешних обработок для всех баз без ограничения нужно в файл conf.cfg внести строку DisableUnsafeActionProtection=.*
А как же Git?
Git будет необходим в двух случаях развития BDD и/или сценарного тестирования :
1) Построение CI-контура на основе какого-либо из серверов сборок. Сервера сборок очень дружат с VCS-системами и особенно с git. Код скриптов того же Jenkins очень удобно хранить в репозитории, редактировать в Visual Studio Code, вместо встроенного редактора Jenkins и настроить Jenkins на получение этого кода. Даже в этом случае применение git не обязательно, просто его использование совместно с Visual Studio Code делает работу удобной и менее трудозатратной.
2) Командная работа со множеством фича-файлов. В этом случае git позволяет делать то же, что и с любыми другими тестовыми файлами - версионировать, объединять изменения, быстро распространять изменения среди всех участников команд. В этом случае приемы применения git для фича-файлов не имеют никаких особенностей и отличий от других простейших случаев применения git. Но важно понимать, что это потребует освоения git всеми членами команды.
Сейчас мы рассматриваем простые случаи индивидуальной работы, поэтому в установке git сейчас нет необходимости. Если у вас есть потребность разобраться с работой с фича-файлами или скриптами для CI-контура через git , то рекомендую следующие публикации, где рассматривается установка git и взаимодействие OneScript с ним. А также рассматривается подход gitflow для командной работы с текстовыми файлами :
https://www.atlassian.com/git/tutorials/comparing-workflows/gitflow-workflow
Интерфейс Vanessa-ADD : запись сценариев
Vanessa-ADD при запуске bddRunner.epf направляет нас сначала на вкладку "Запуск сценариев". Но чтобы иметь возможность запустить сценарий на исполнение его нужно сначала записать. Поэтому начнем знакомство с вкладок, позволяющих осуществить запись сценария : "Библиотеки", "Работа с UI" и "Test clients". Вкладка "Запуск сценариев" будет рассмотрена далее в этой части публикации.
Вкладка "Генератор EPF" будет рассмотрена в части, посвященной созданию собственных шагов и библиотек. Вкладка "Сервис" будет описываться в контексте рассмотрения остальных возможностей Vanessa-ADD так как она связана со всеми остальными вкладками, является служебной и не предоставляет собственной функциональности.
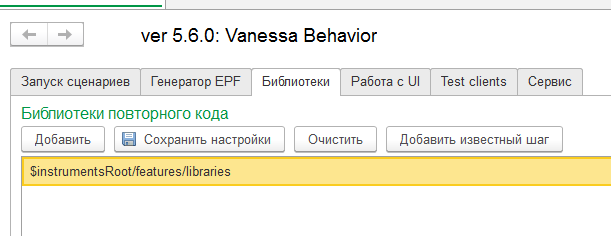
Вкладка "Библиотеки"
Здесь определяются пути к библиотекам шагов Vanessa-ADD. По умолчанию здесь прописан путь только к стандартной библиотеке шагов. Именно благодаря наличию этой библиотеки мы можем использовать такие шаги как
И я подключаю TestClient "ИмяКлиента" логин "Пользователь1" пароль "1"
Затем я сохраняю имя файла из переменной "ПолноеИмяФайла" как "ИмяФайла"
и так далее. Все эти шаги находятся в стандартной библиотеке Vanessa-ADD. Если же вы создадите свои библиотеки шагов, то здесь их также можно будет подключить :
В списке библиотек можно использовать как абсолютные пути, так и заданные относительно каталога инструментов $instrumentsRoot. При этом путь к самому каталогу $instrumentsRoot указывается на вкладке "Сервис" и по умолчанию установлен в C:\Program Files (x86)\OneScript\lib\add. Менять его потребуется только в том случае, если вы выполняли установку OneScript и ADD в нестандартные каталоги:
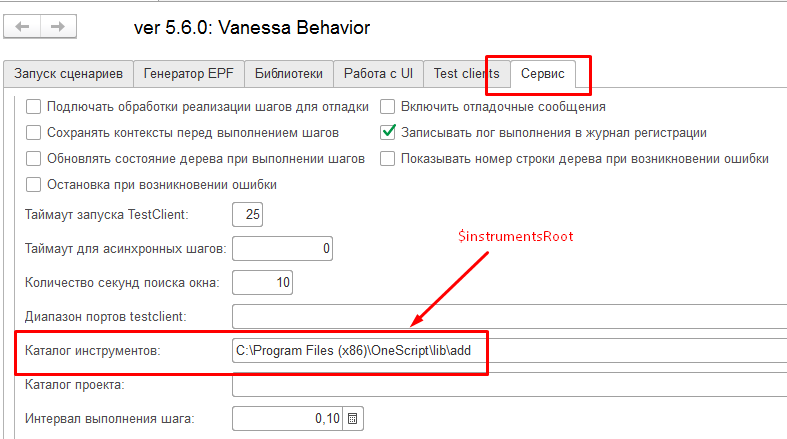
Важно не забывать нажимать на кнопку "Сохранить настройки" при изменении настроек (на каждой вкладке своя кнопка для сохранения).
Помимо шаблона каталога $instrumentsRoot в Vanessa-ADD в зависимости от места применения есть возможность использовать и другие шаблоны подстановки:
- $КаталогПроекта или $КаталогПроекта$ в тексте фича-файлов,
- $workspaceRoot для настроек автозапуска.
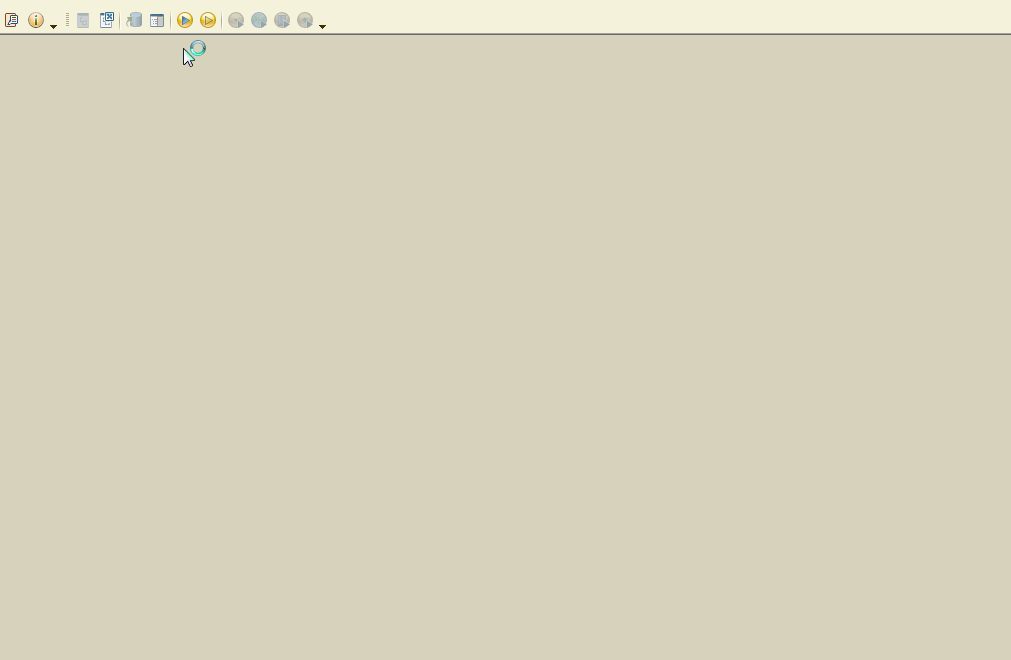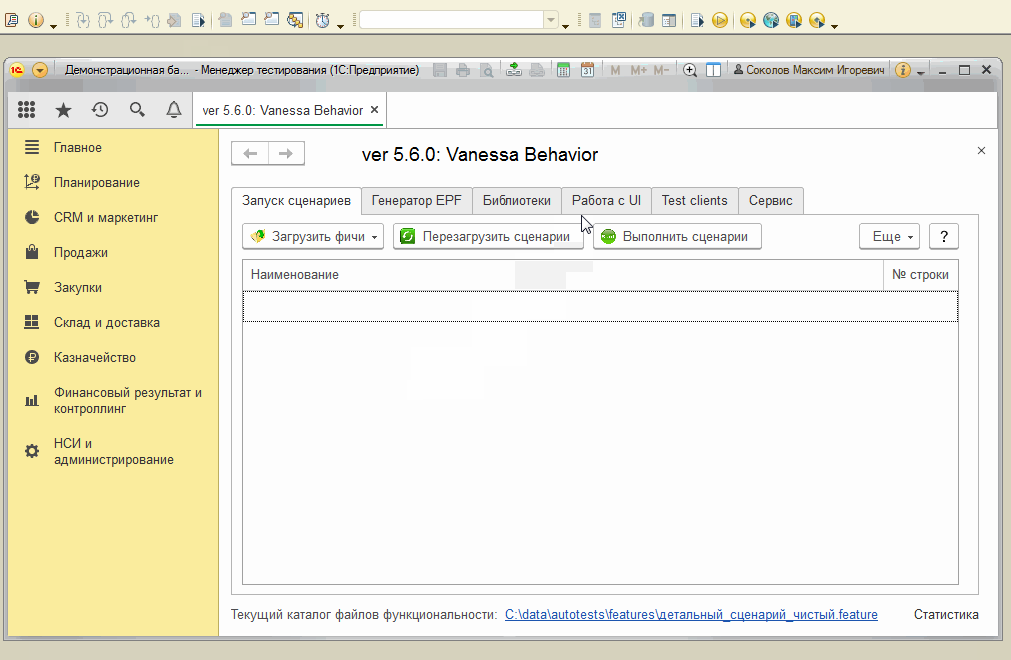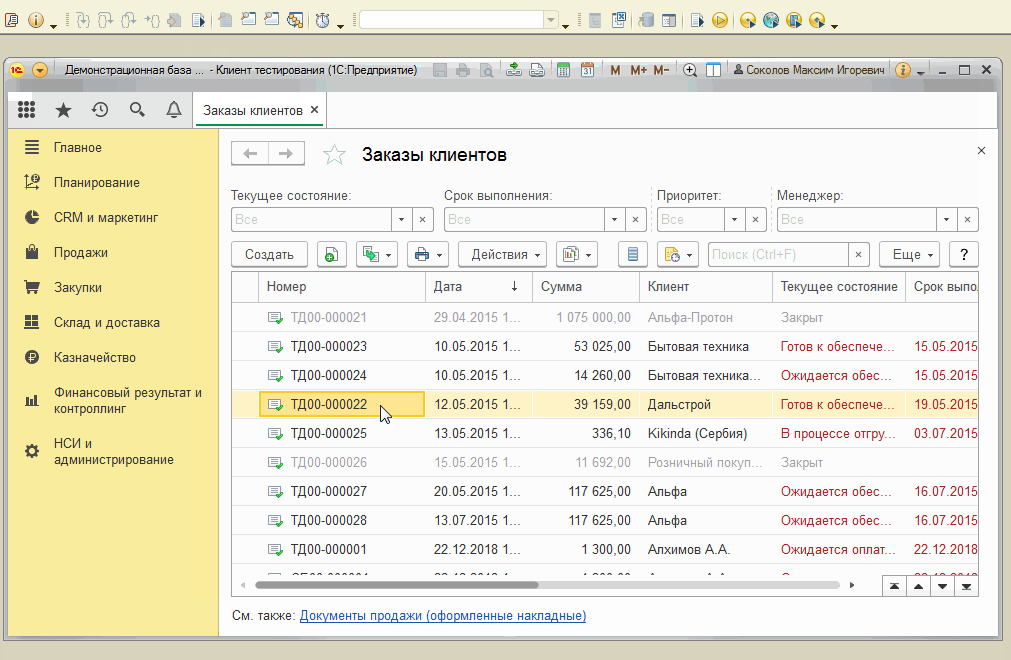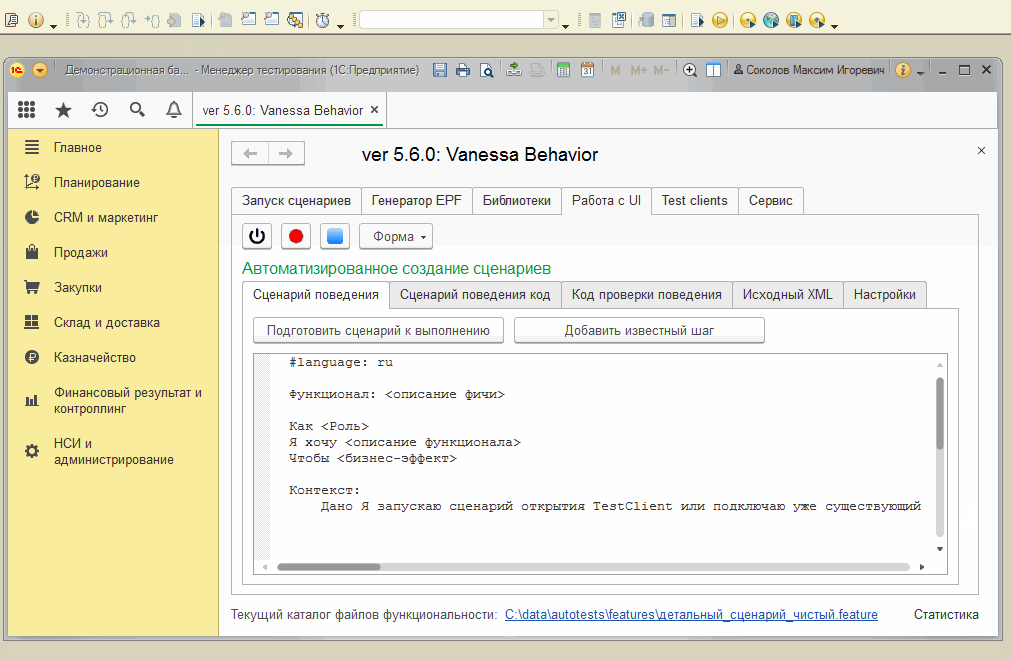
Вкладка "Работа с UI"
Здесь выполняется работа по записи действий пользователя и редактированию полученного списка шагов, если это редактирование выполняется непосредственно в Vanessa-ADD, а не в Visual Studio Code.
Кнопка подключения тест-клиента
В примерах ранее мы уже видели как работают кнопки начала записи действий пользователя и остановки записи действий пользователя. Кнопка подключения тест-клиента отличается от кнопки записи тем, что только запускает тест-клиент или подключает к Vanessa-ADD уже запущенный. При этом запись действий пользователя сразу не начинается.
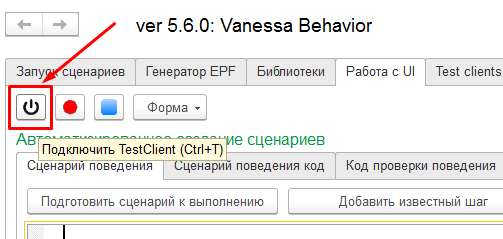
Это бывает очень полезно, если необходимо проиграть сценарий, открытый в Vanessa-ADD начиная с определенного шага, а не с самого начала. Например с целью отладки сценария или чтобы посмотреть как сценарий поведет себя в какой-то иной ситуации, чем предусмотрена в самом сценарии.
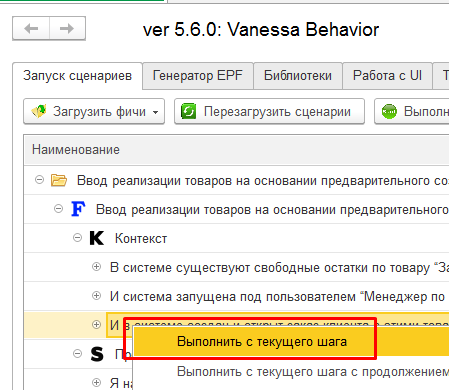
При этом выполнение с определенного шага обычно предполагает, что в тестируемой системе уже проведены какие-то действия, открыты формы, заполнены данные. Можно воспользоваться следующим приемом. Сначала запустить тест-клиент указанной выше кнопкой. Подготовить в нем формы и данные вручную, а уже после этого выполнить сценарий с нужного нам шага.
Например в прошлой части публикации мы создали сценарий, создающий в том числе документ поступления товаров. Но что если мы хотим по проверить, как поведет себя сценарий если в документе будет выбрана иная номенклатура, нежели заданная в сценарии? Или например при выполнении операций от другого пользователя? Можно временно изменить сам сценарий, проверить работу и затем вернуть исходный текст. Но можно сделать проще - не изменяя сценарий, вручную запустить тест клиент, подготовить в нем данные и начать выполнение с определенного шага :
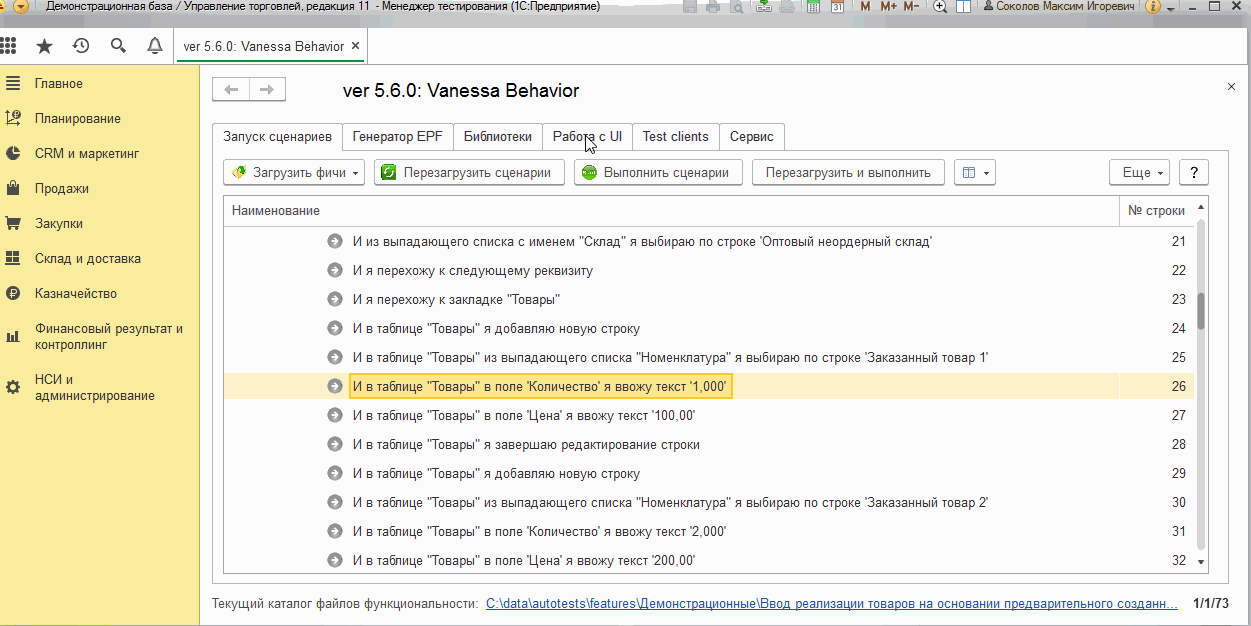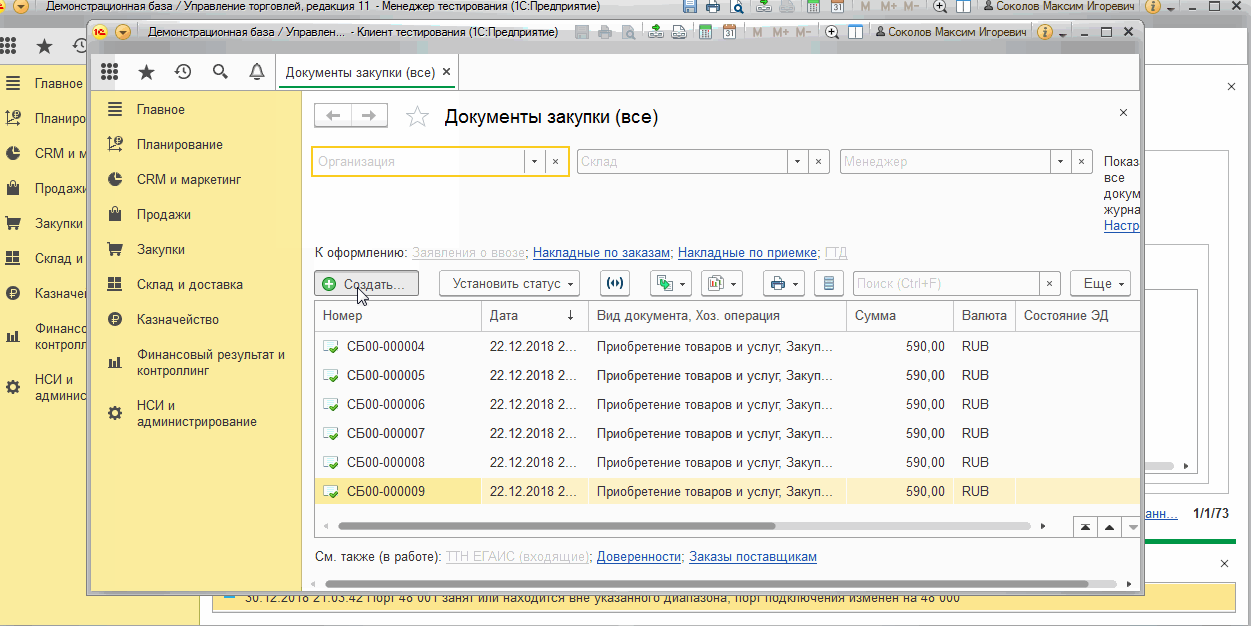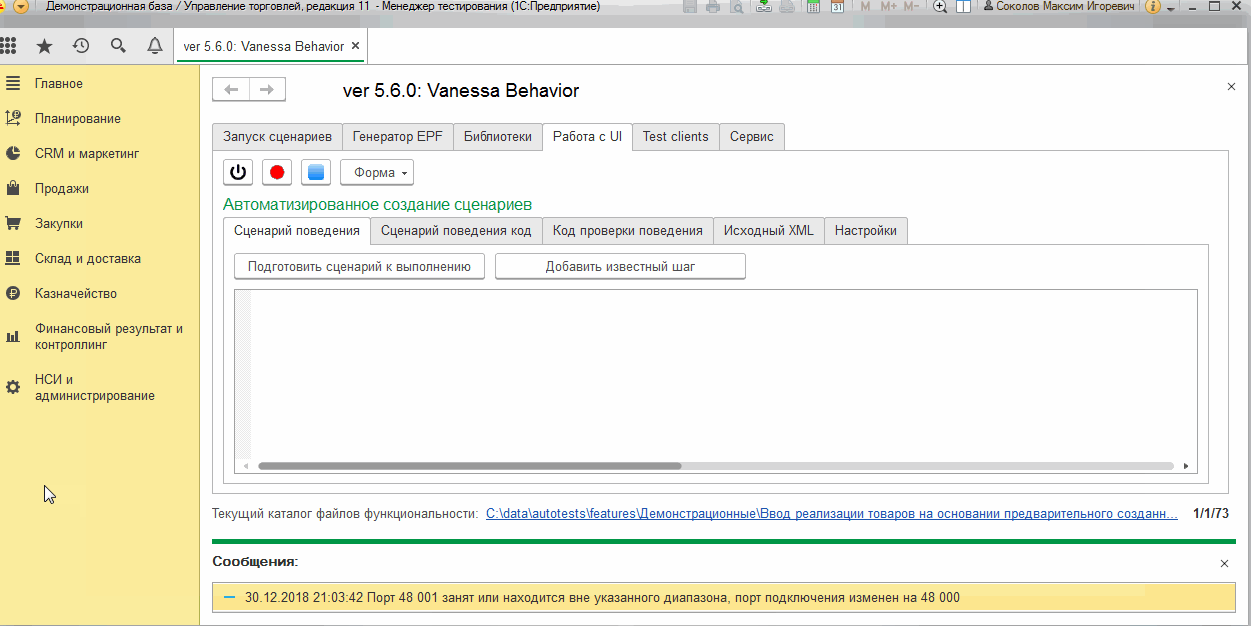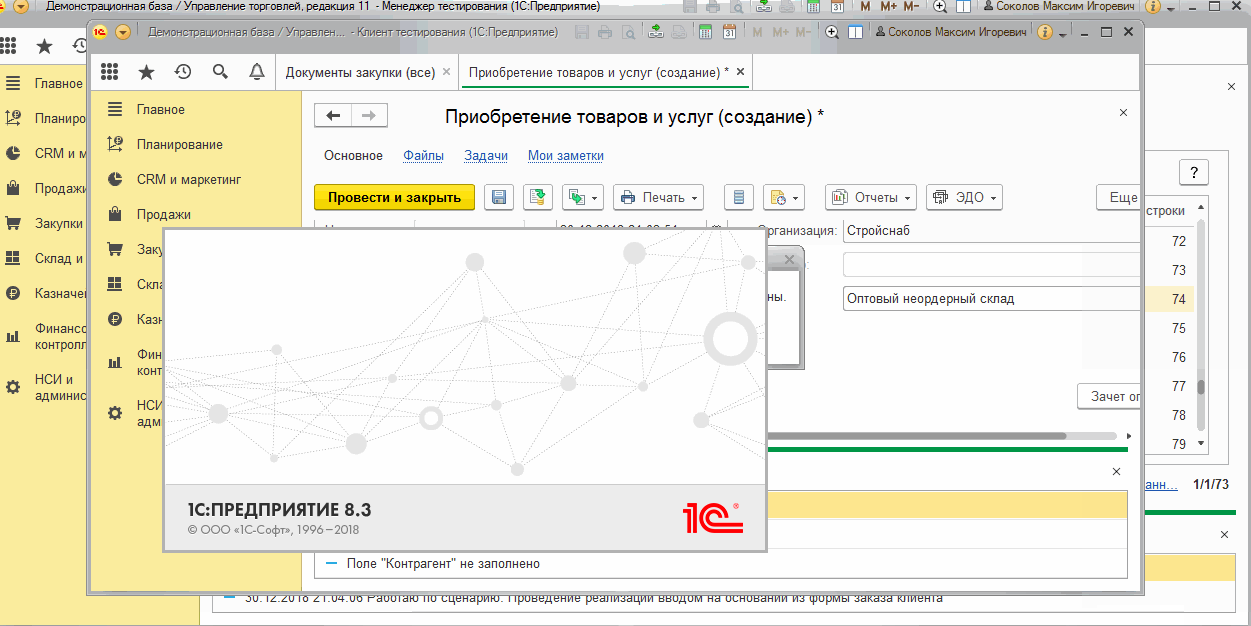
Вложенные вкладки : Сценарий поведения, Исходный XML , Код проверки поведения , Сценарий поведения код
Помимо представления записанных действий в виде шагов Gherkin Vanessa-ADD также предлагает несколько других представлений. Маловероятно, что ими придется часто пользоваться, но информация представленная на них позволяет лучше понять механизм работы Vanessa-ADD и самого взаимодействия между тест-клиентом и тест-менеджером.
Если на вкладке Сценарий поведения представлены шаги в виде кода Gherkin,
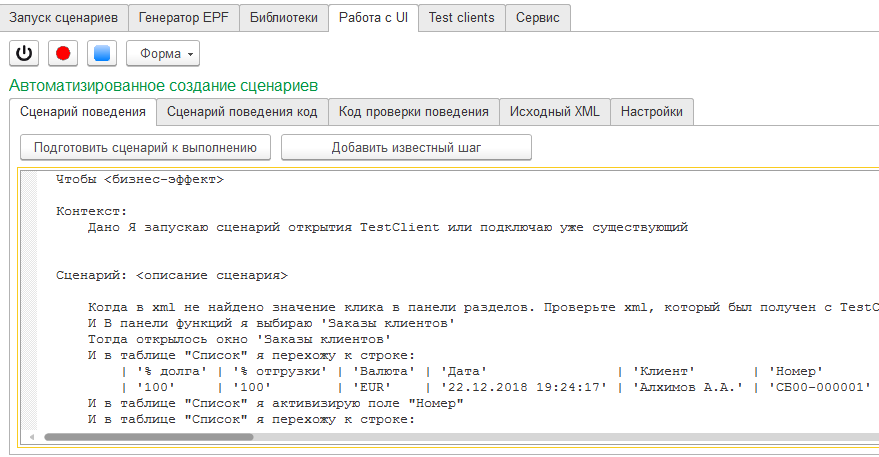
то на вкладке "Исходный XML" представлена информация, которая в том виде в котором она передается из тест-клиента в тест-менеджер. Это структурированная в виде XML запись действий пользователя, именно она является первоначальным результатом записи действий пользователя, которая уже затем преобразуется в код на встроенном языке 1С:Предприятия или шаги сценария Gherkin :
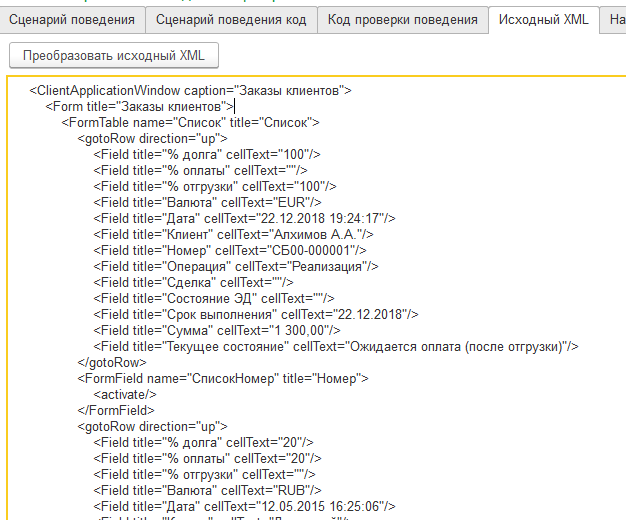
На вкладке "Код проверки поведения" мы можем увидеть тот код, который во времена зарождения механизма автоматизированного тестирования мы были бы вынуждены использовать, чтобы получить тот же результат, который сейчас нам выдает Vanessa-ADD. Сама Vanessa-ADD использует аналогичные методы платформы при трансляции шагов Gherkin в исполняемый код 1С. Но она не использует именно этот код, а использует для этого свои внутренние механизмы.
Очевидно, что такой код сложно показать аналитику, консультанту и интегрировать его с человеческим описанием поведения пользователя - это код только для виртуальной машины 1С и программиста:
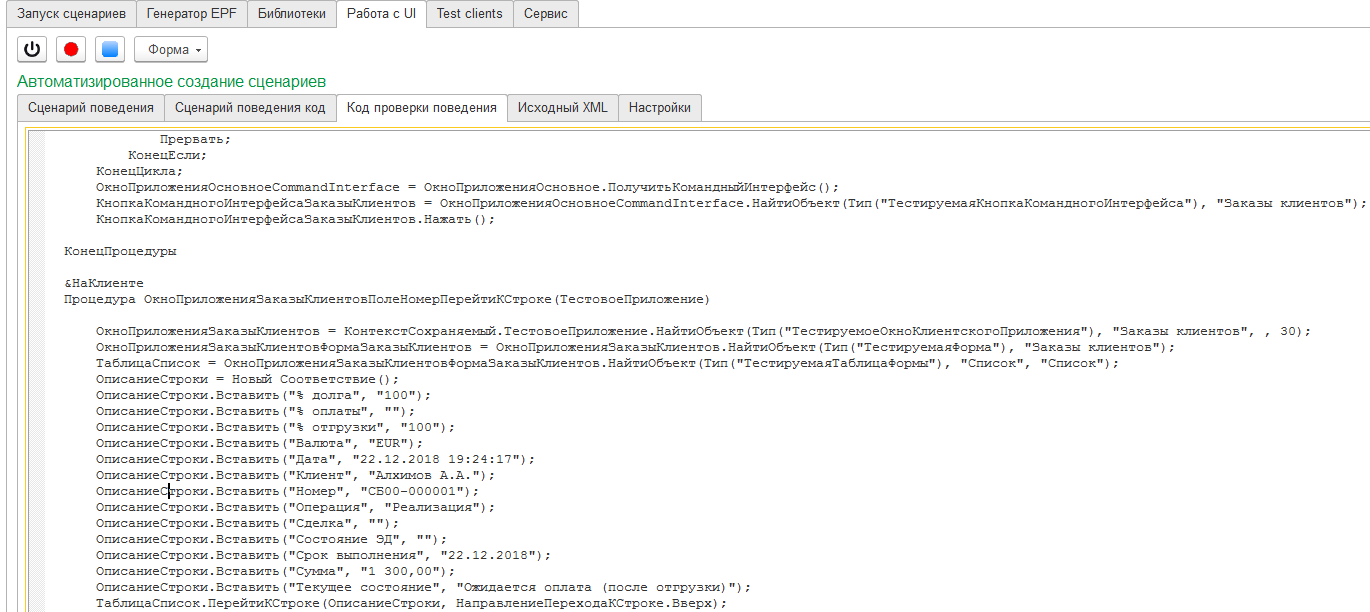
На вкладке "Сценарий поведения код" фигурирует код, который исполняет Vanessa-ADD чтобы передать записанный сценарий (в виде шагов Gherkin) в очередь на исполнение. Информацию с этой вкладки можно использовать для сложных случаев отладки сценариев:

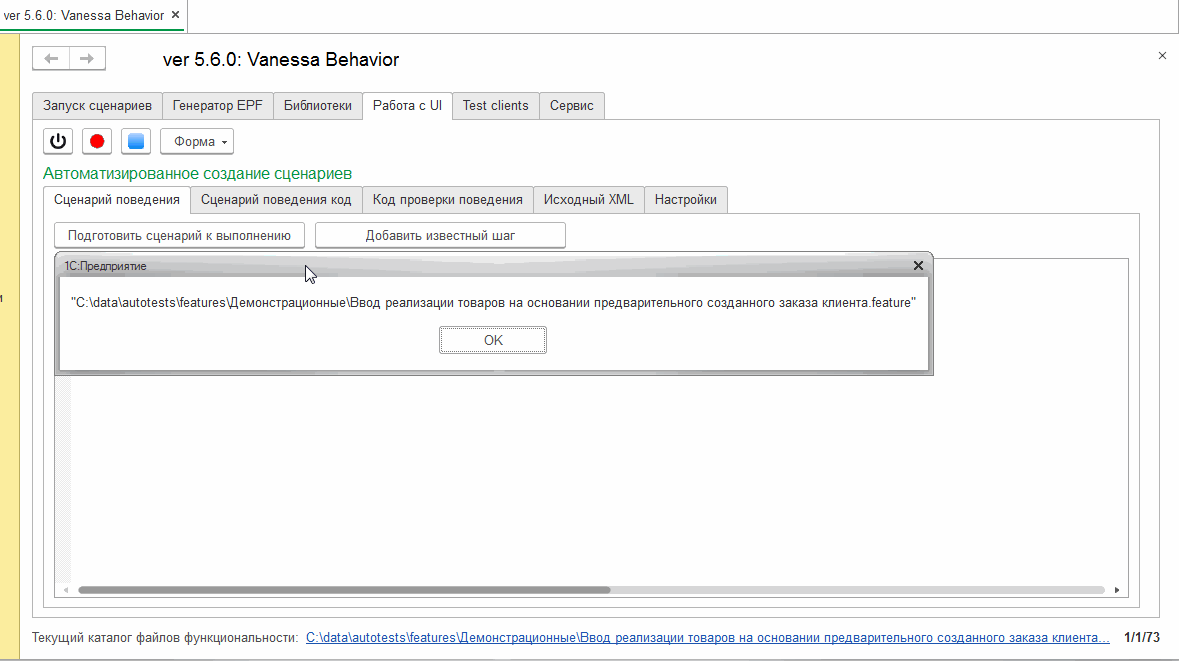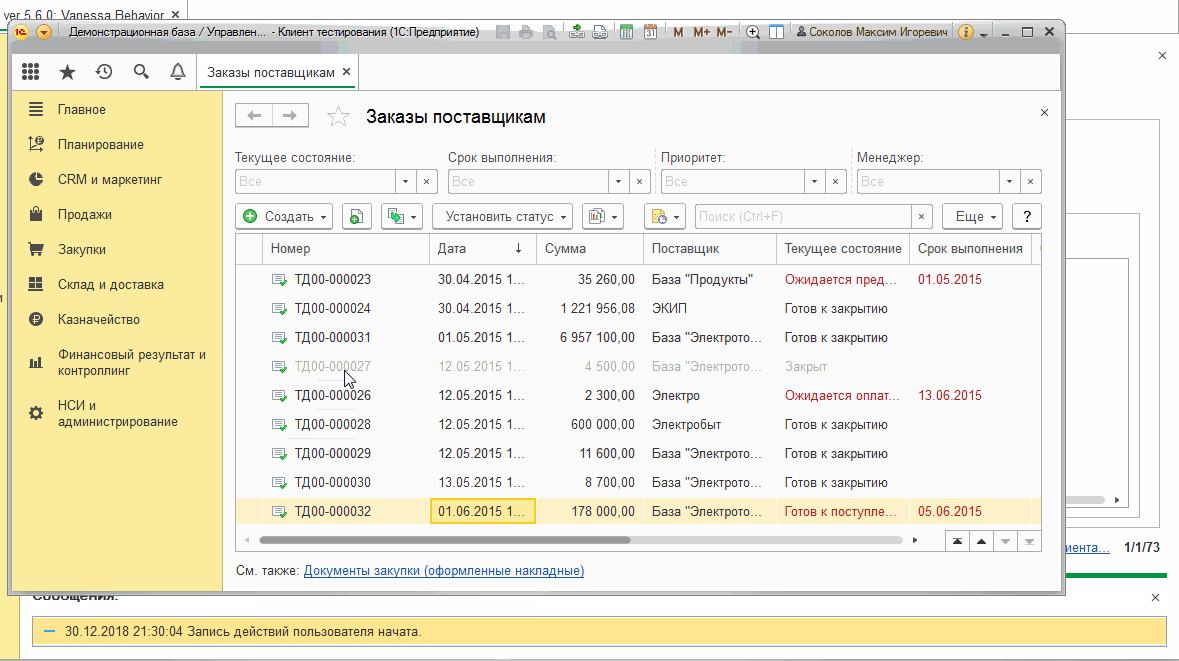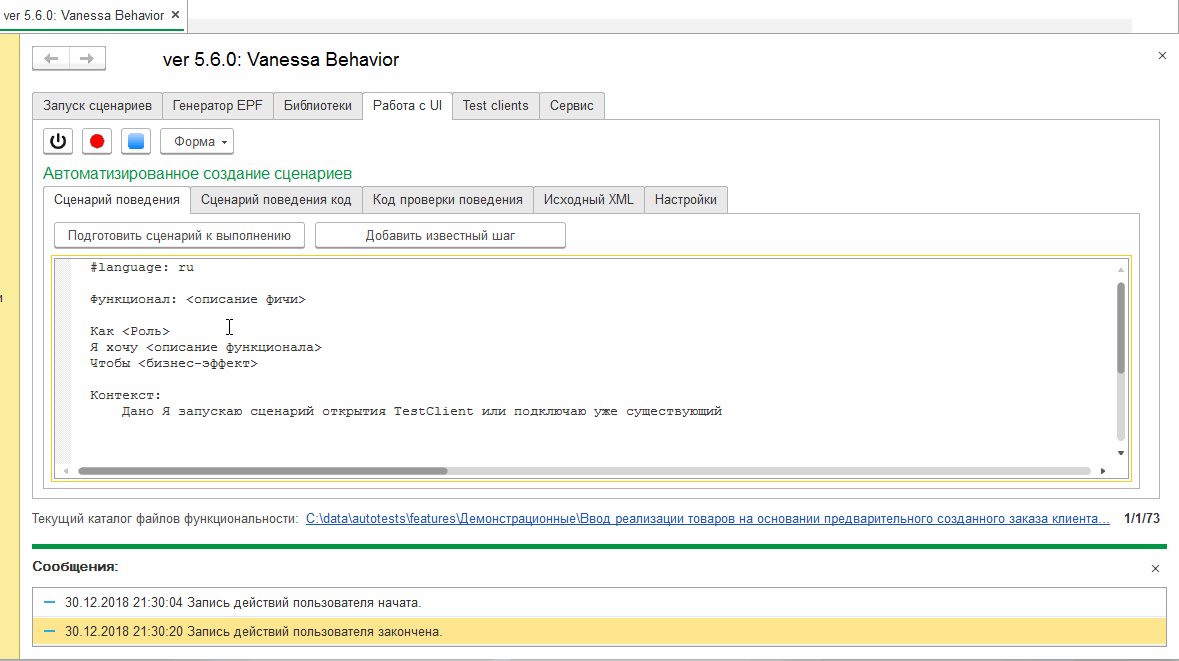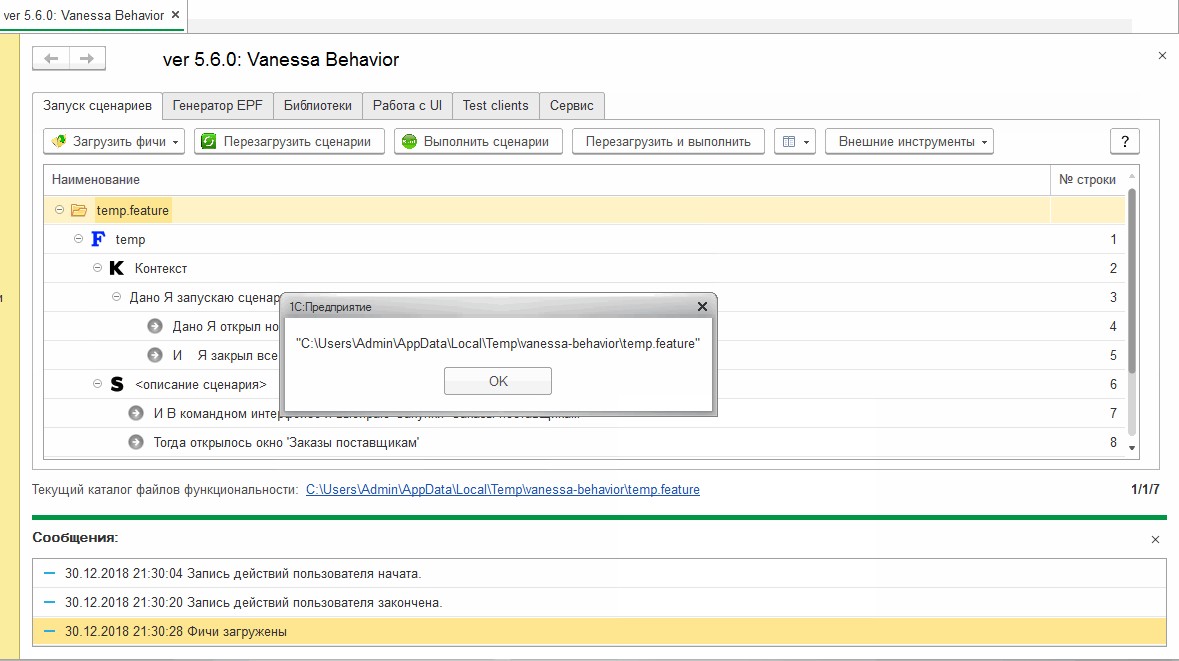
Кнопка "Подготовить сценарий к выполнению"
Эта команда позволяет выполнить записанный сценарий без предварительного сохранения его в файл и открытия этого файла в Vanessa-ADD или же выполнить сценарий, код которого просто вставлен в текстовое поле на вкладке "Сценарий поведения".
Механизм работы этой кнопки следующий : вставленный / записанный сценарий помещается во временный файл. И этот временный файл автоматически открывается в Vanessa-ADD на вкладке "Запуск сценариев". Если ранее на этой вкладке был открыт другой файл или каталог, то он закрывается и сценарий из него замещается на содержимое только что созданного / перезаписанного временного файла:
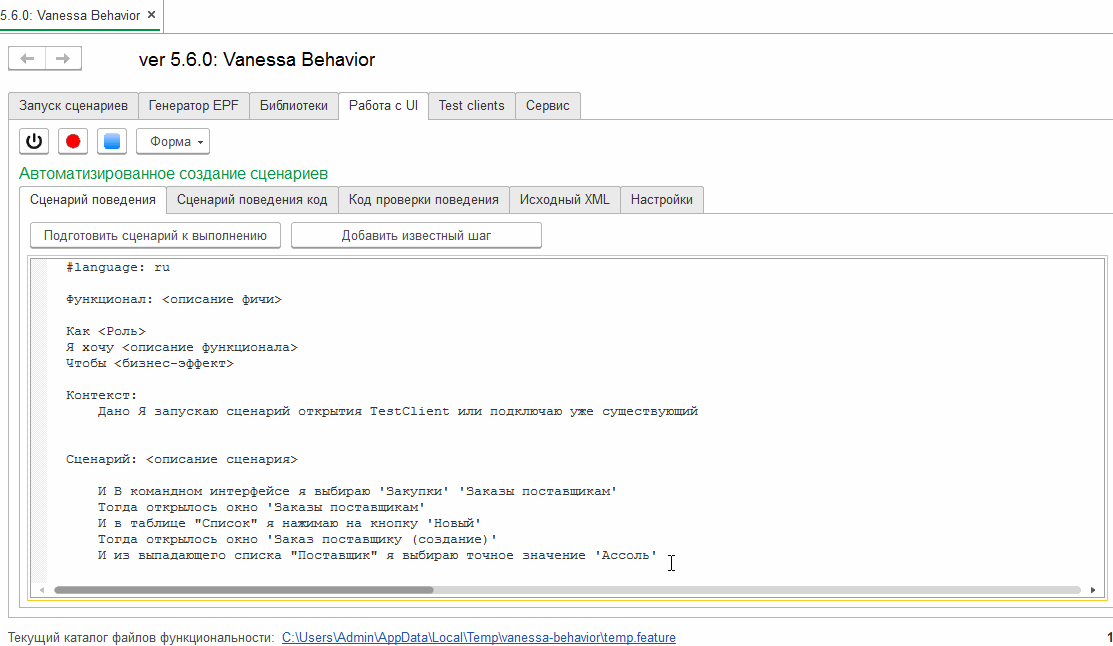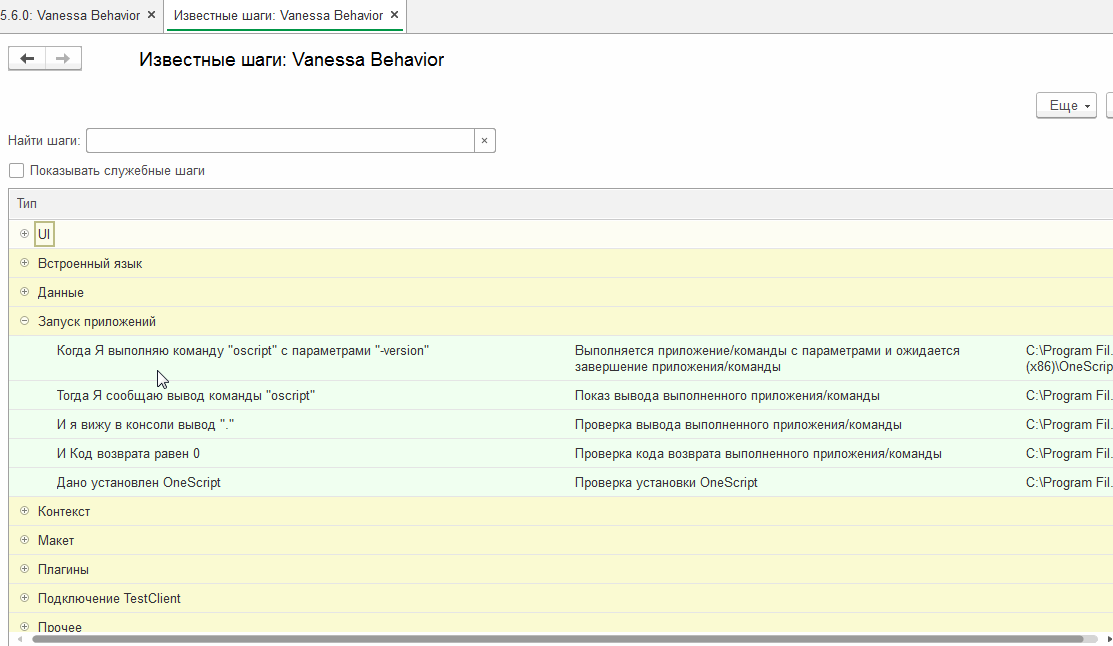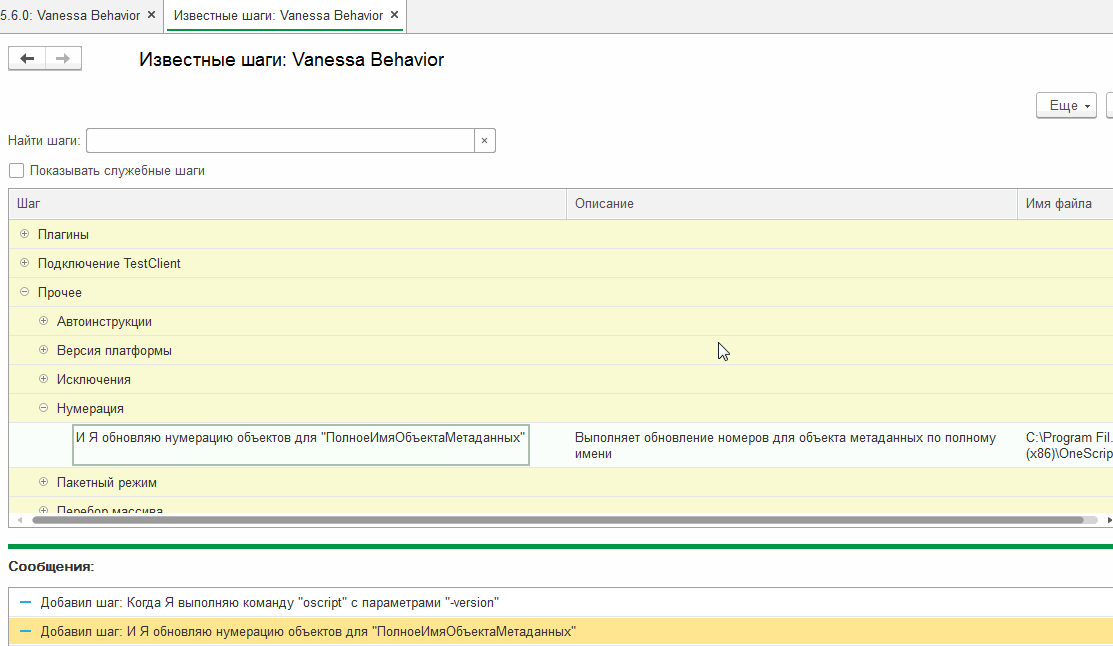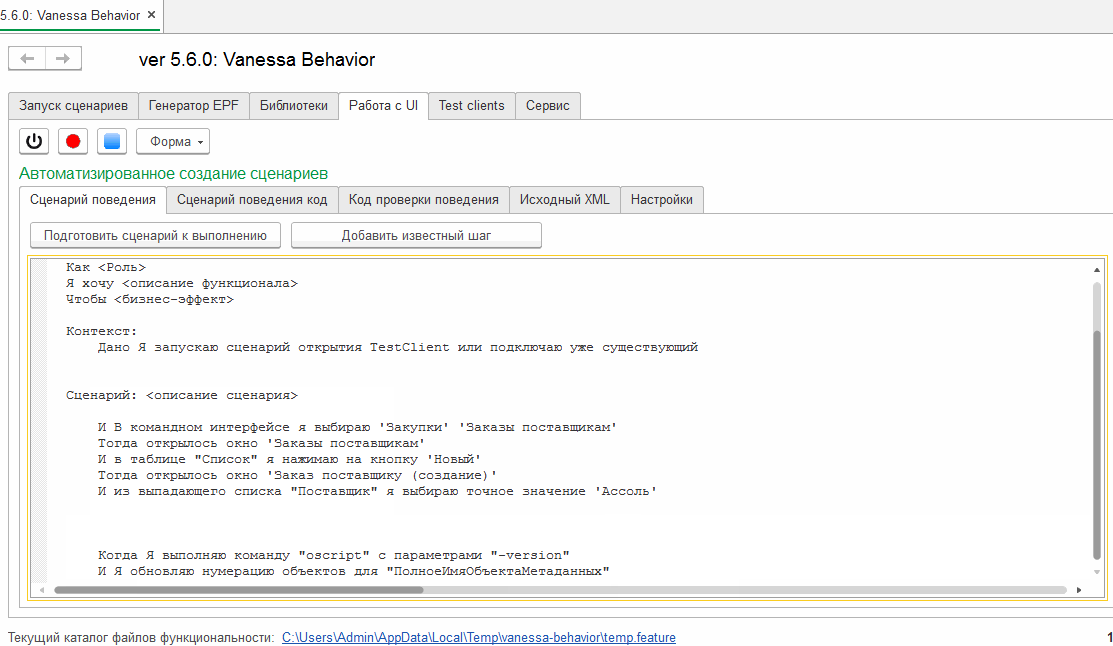
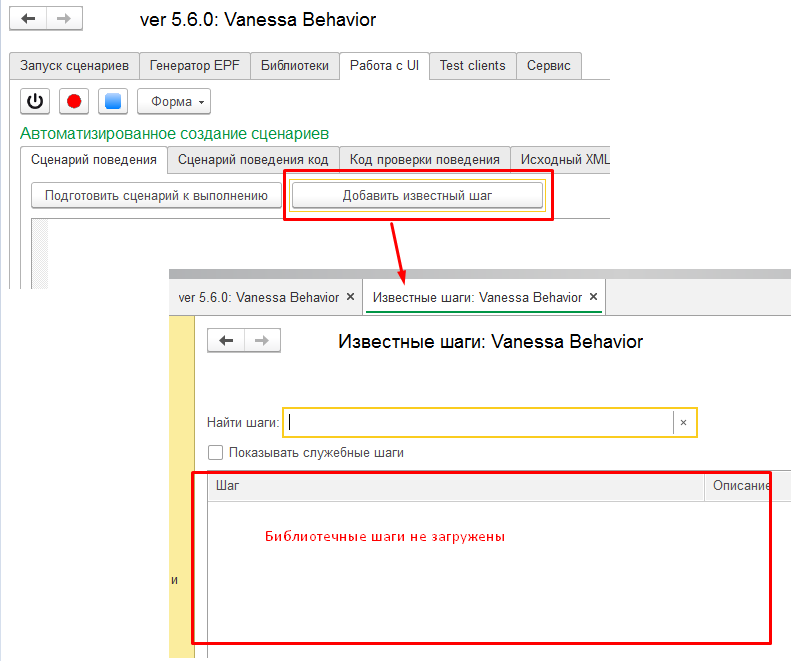
Кнопка "Добавить известный шаг"
Правильнее было бы назвать эту кнопку "Добавить библиотечный шаг" , потому она выполняет именно эту функцию. Будем надеяться что в одной из следующих версий Vanessa-ADD ей будет дано более адекватное название.
Нажав на нее можно перейти к списку библиотечных шагов и выбрать наиболее подходящий. Этот шаг по двойному клику переносится в текстовое поле, находящееся на вкладке "Сценарий поведения" :
Мы уже рассматривали пример применения этого механизма при модификации существующего сценария здесь : //infostart.ru/public/969637
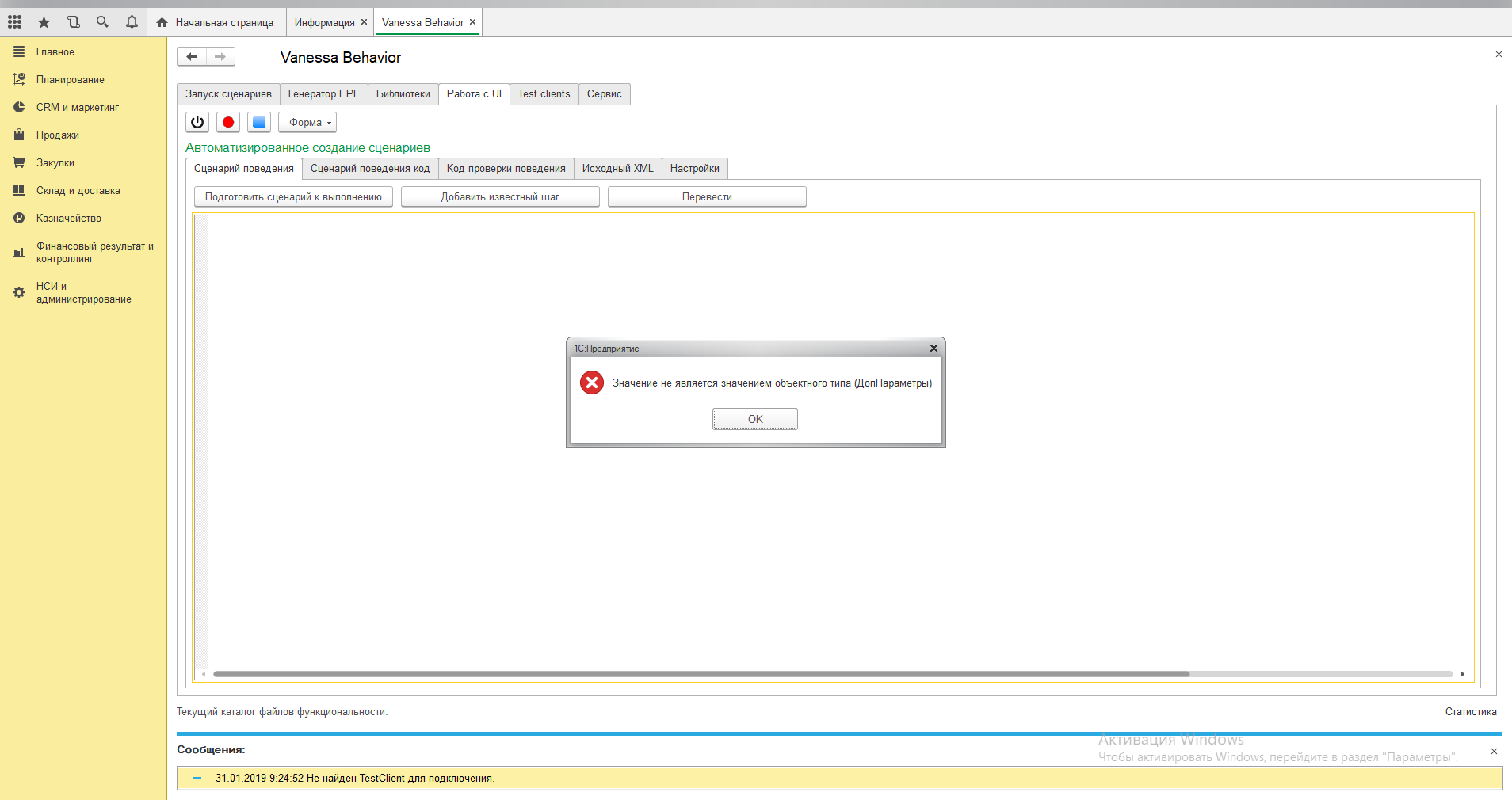
Сейчас Vanessa-ADD обладает одной неприятной особенностью. Если сценарий не загружен во вкладку "Запуск сценариев" или для загрузки указан несуществующий файл :
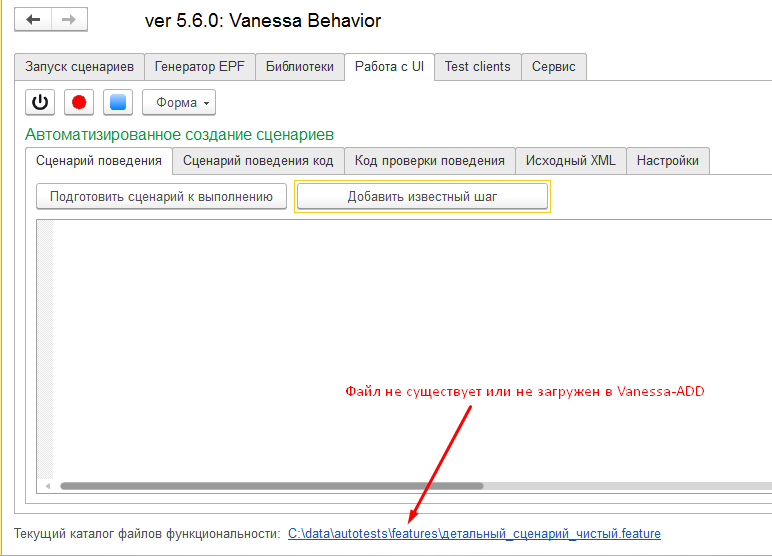
то в этом случае попытка добавить библиотечный шаг будет неудачна - окно библиотечных шагов просто будет пустым. Библиотечные шаги читаются системой только при подготовке сценария к выполнению и загрузки на вкладку "Запуск сценариев". До того как это произошло шаги нельзя добавлять командой "Добавить известный шаг". Возможно это поведение будет исправлено в одной из следующих версий Vanessa-ADD :
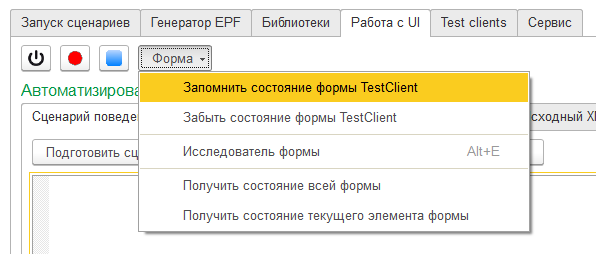
Группа команд "Форма" (получение состояния тестируемой формы)
Это меню скрывает удивительно мощные инструменты, позволяющие узнать, что поменялось в форме в результате действий пользователя, даже если мы не видим этих изменений. Позволяющие изучить форму, подобно тому, как разработчик может сделать это в конфигураторе. Сократить объем ручной работы на создание шагов, выполняющих проверку того, что элементы формы заполнены нужными значениями :
Рассмотрим каждую из этих команд в отдельности.
Пункт "Запомнить состояние формы TestClient" и связанные с ним команды
Очень часто при написании сценариев необходимо после выполнения каких-то действий в форме проверить, установились ли в связанные элементы формы нужные значения. Это выполняется с помощью шага
И элемент формы с именем "ИмяЭлемента" стал равен 'ТекстовоеПредставлениеЗначения'
Автоматически эти шаги в генерируемый "кнопконажималкой" в сценарий не записываются. И это правильно, ведь иначе каждый записанный сценарий содержал бы десятки лишних шагов-проверок, от которых пришлось бы избавляться подобно тому, как мы ранее избавлялись от лишних шагов "И я перехожу к следующему элементу" для уменьшения простыни кода на Gherkin.
Но когда они всё таки необходимы, вручную набирать подобные шаги-проверки очень трудоемко. Чтобы избавить нас от этих ручных действий и существует эта команда. Она запоминает состояние элементов формы и затем автоматически генерирует шаги-проверки (точнее шаги-утверждения), только для изменившихся элементов. При этом для использования этой команды даже не нужно начинать запись действий пользователя.
Эта команда работает вместе с двумя другими - "Забыть состояние формы TestClient" и "Получить изменения формы".
После нажатия на кнопку "Запомнить состояние формы TestClient" команда "Получить состояние всей формы" становится недоступной и вместо нее появляется команда "Получить изменения формы". И команда "Получить состояние всей формы" не вернётся в меню до тех пор, пока мы не выполним команду "Забыть состояние формы TestClient".
Вызов же команды "Получить изменения формы" будет всегда получать изменения между ранее запомненным состоянием и её текущим состоянием :
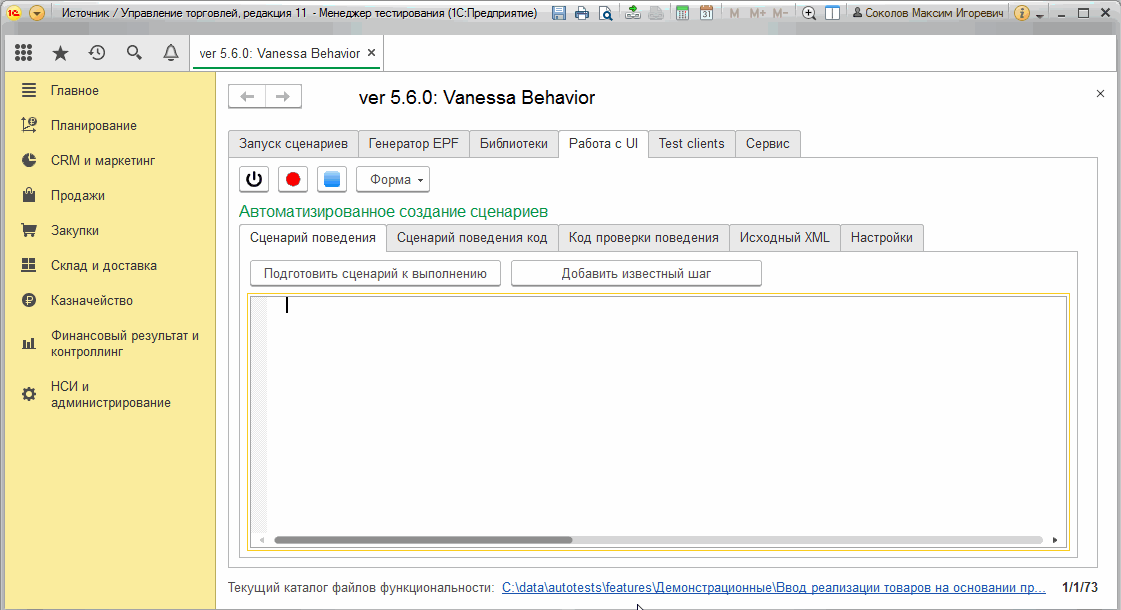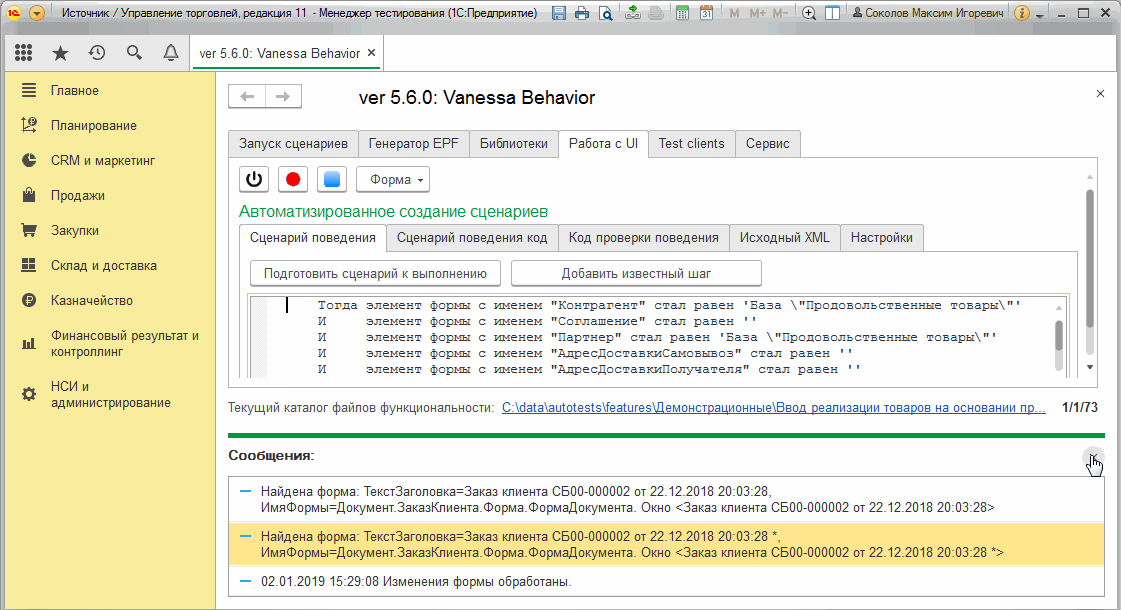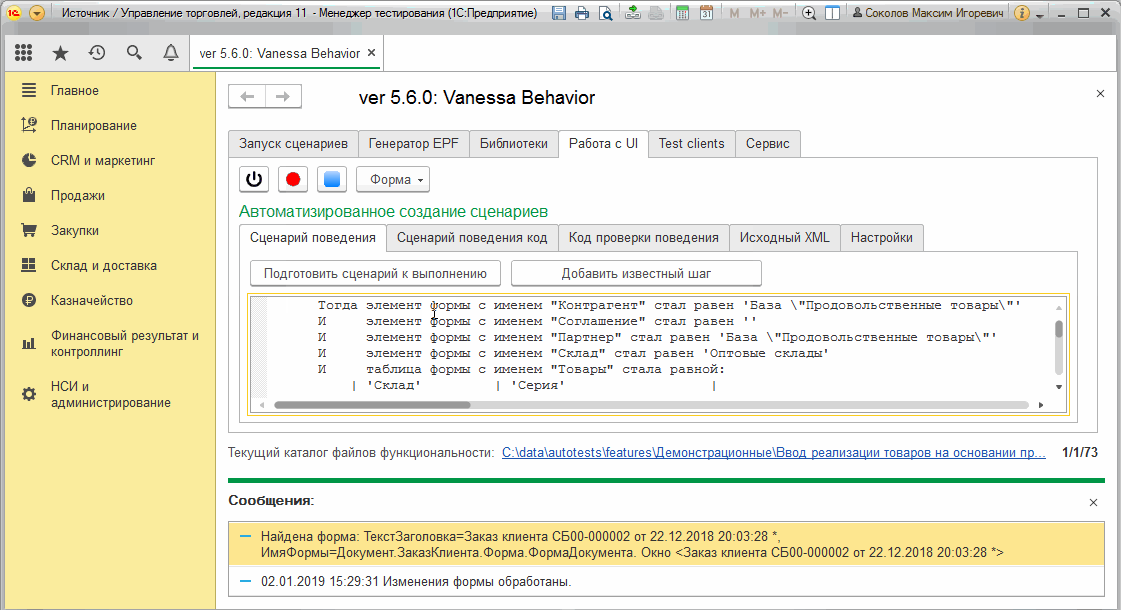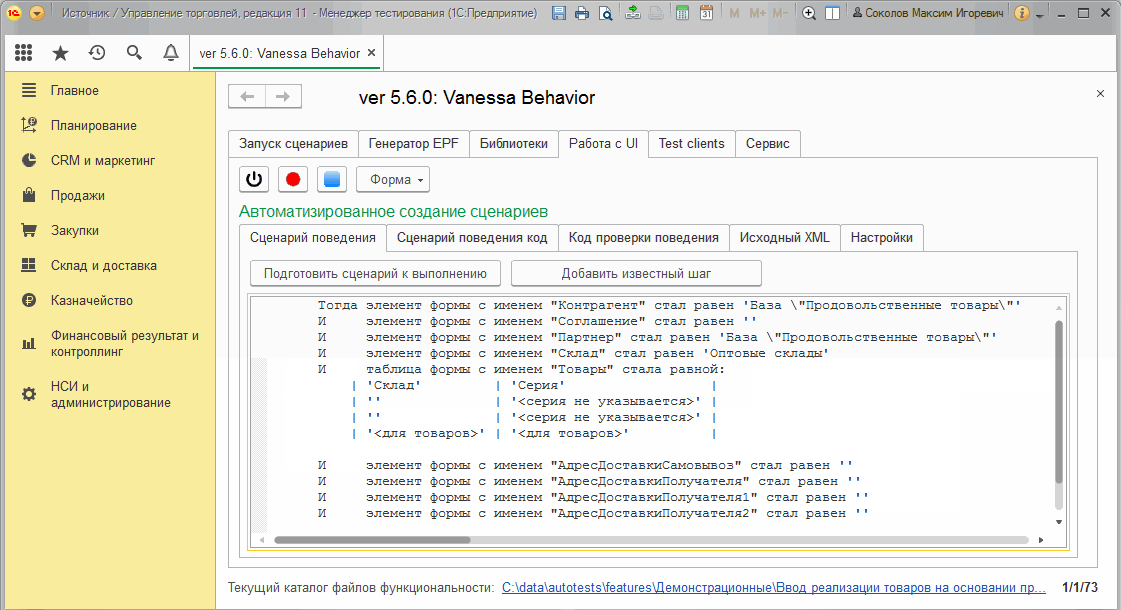
Пункт "Получить состояние текущего элемента формы" и тестирование отчетов
Эта команда действует похожим образом, но более точечно - она работает в отношении только одного активного элемента формы и не требует предварительной записи состояния формы :
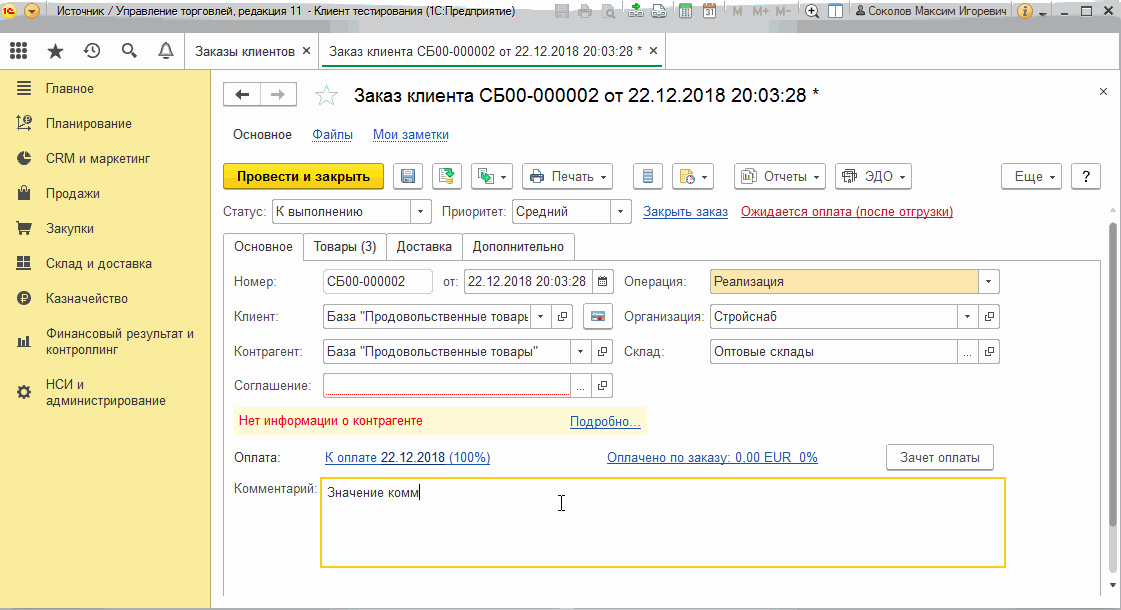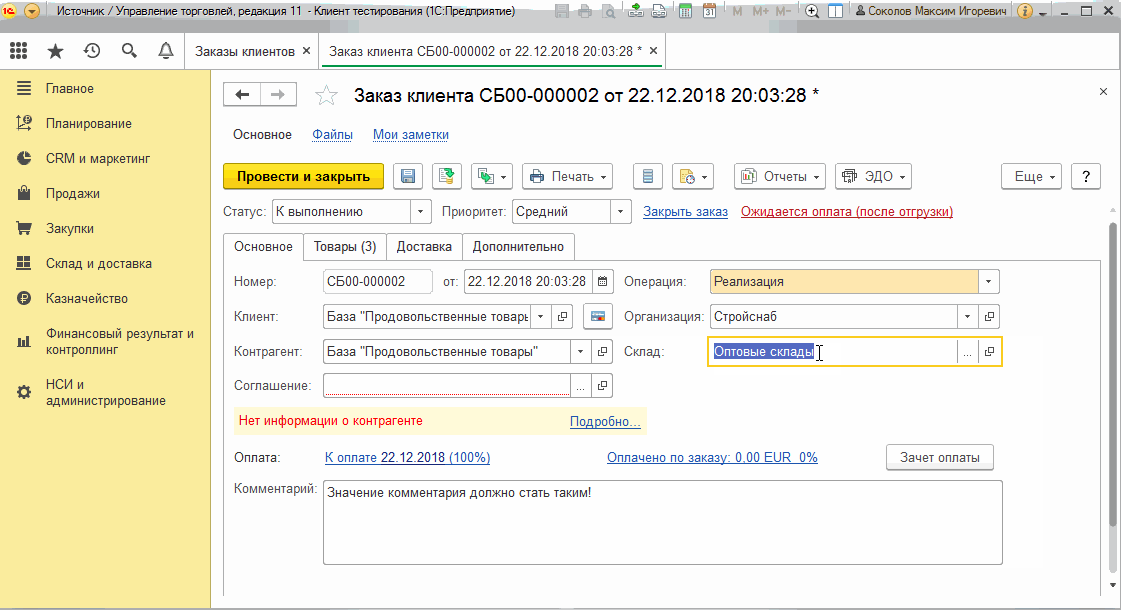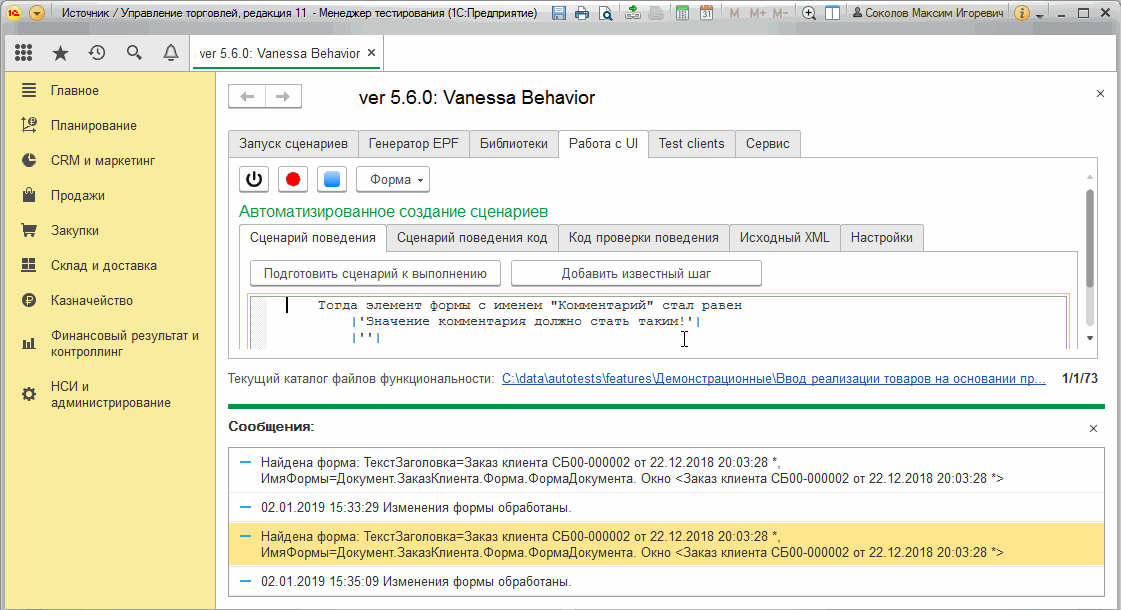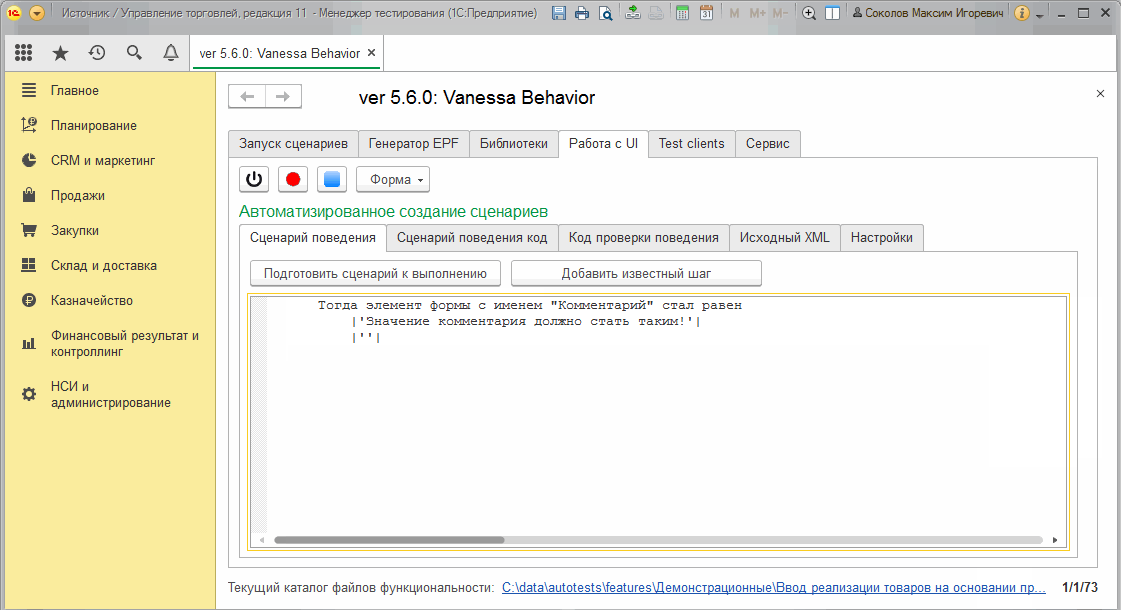
Это полезная возможность. Но она становится по настоящему незаменимой при тестировании отчетов!
Дело в том, что при тестировании отчетов невозможно вручную определить в Vanessa-ADD состояние печатной формы. Это можно сделать только с помощью этой команды.
Суть метода тестирования отчетов в следующем:
1) Мы выводим отчет и активируем табличный документ
2) Получаем состояние текущего элемента формы - табличного документа.
3) Оставляем в описании состояния только значимые для нас строки.
4) Заменяем шаг Тогда табличный документ формы с именем "ТабличныйДокумент" стал равен на шаг И табличный документ формы с именем "ТабличныйДокумент" содержит строки.
При этом важно помнить, что в отличие от операциями с таблицами формы , при работе с табличными документами нельзя оставить только значимые для нас колонки. Сравнивать придется строки целиком, как они есть, со всеми колонками.
В качестве примера, предположим, что нам необходимо проверить движения документа "Заказ клиента" только по регистру "Заказы клиентов". Согласно алгоритму описанному выше наши действия будут следующими :
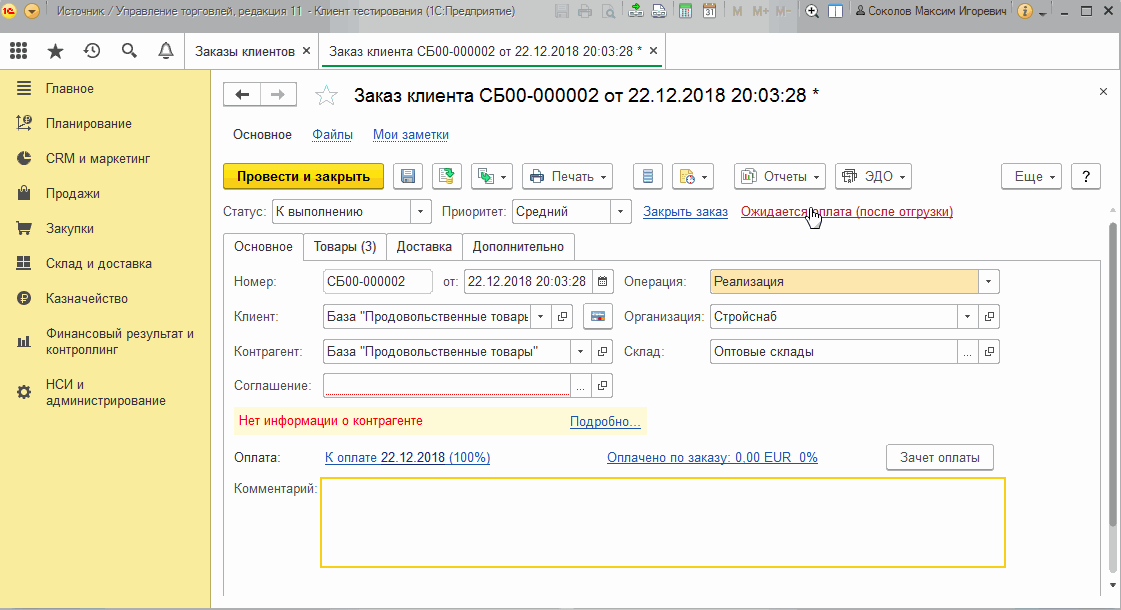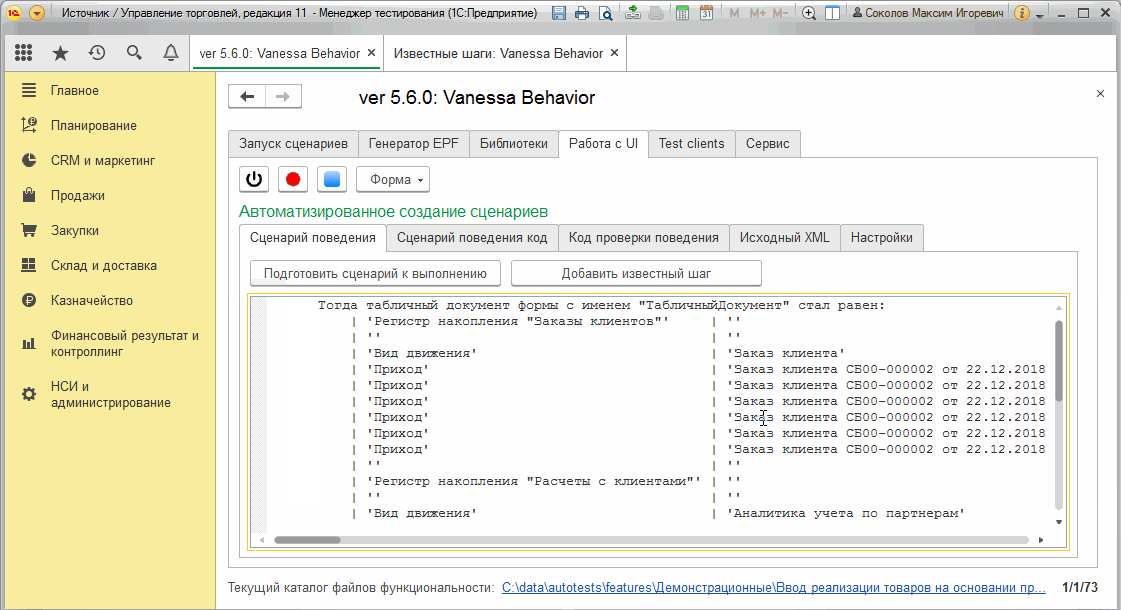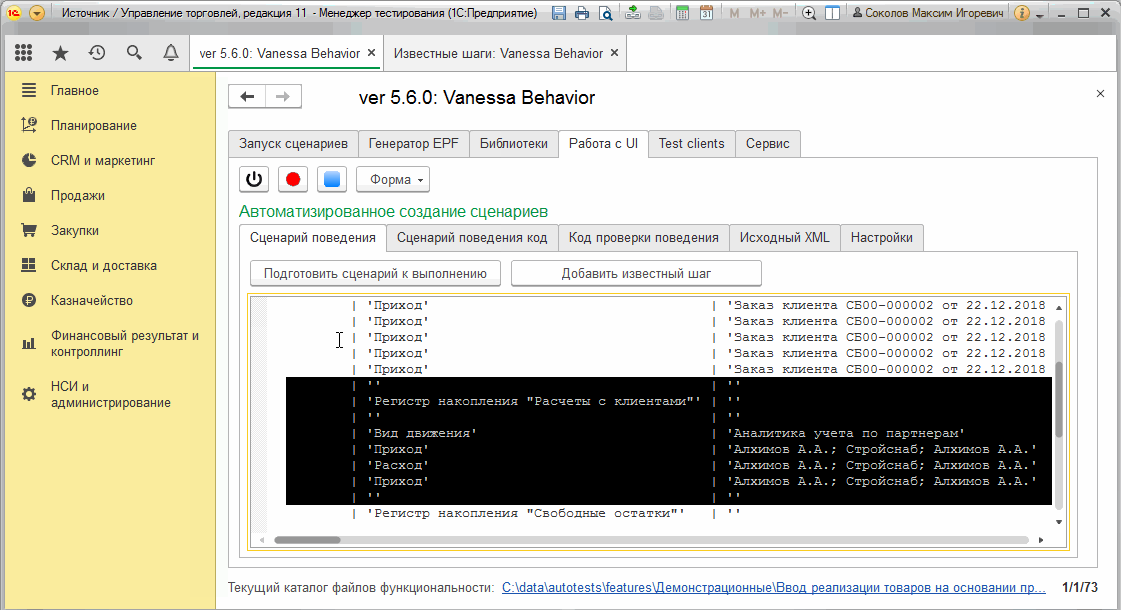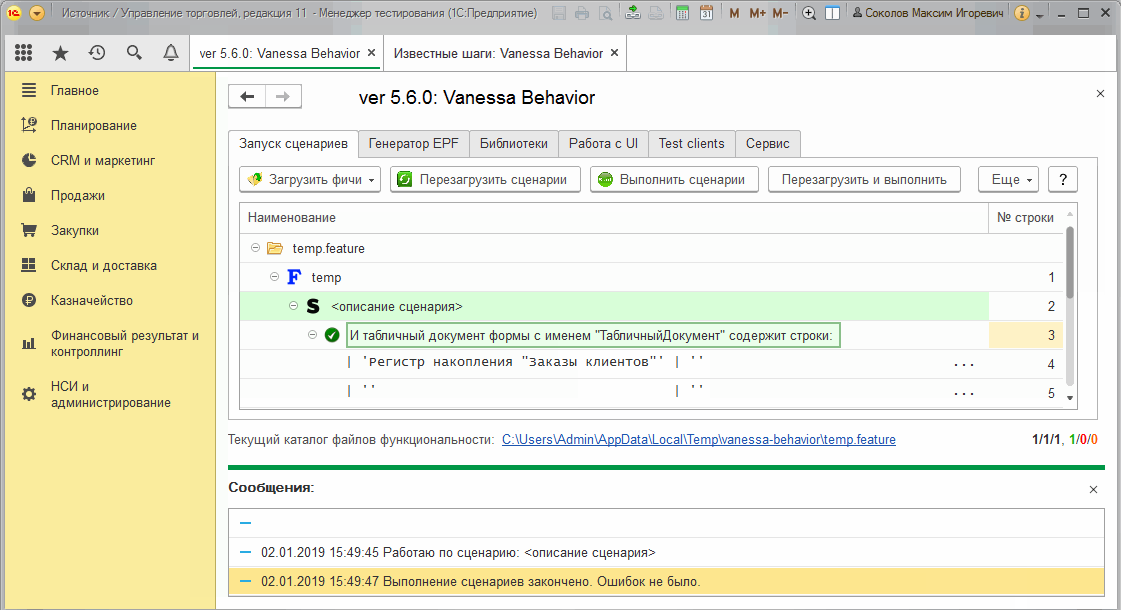
Разумеется для корректной проверки вывод движений должен выполняться "Горизонтально" и в рабочем сценарии это нужно учитывать. Анимация выше просто демонстрирует то, как получить состояние отчета, как выделить из него нужные нам строки и убедиться, что шаг действительно не падает при выполнении.
Пункт "Получить состояние всей формы"
Этот пункт активен только если ранее мы не запомнили состояние формы для получения только изменений (см.выше).
Работает аналогично команде "Получить состояние текущего элемента формы", но считывает состояние всех элементов формы, включая табличные части. Думаю что в иллюстрации здесь нет необходимости ))
Исследователь формы
Инструмент крайне полезный в случае если с записью сценариев работает не программист, а например QA-инженер, которому комфортнее работать только в режиме 1С:Предприятие, не заглядывая в конфигуратор. Инструмент будет полезен и программисту в том случае, если тестируемая форма изменяется программно и требуется работа с программно созданными или программно измененными элементами.
Многие шаги Vanessa-ADD требуют указания в качестве параметров не заголовков элементов формы, а их имен, как они заданы в конфигураторе. Бывают и случаи, когда разные элементы на форме имеют один и тот же заголовок. Или заголовок видимого элемента совпадает с заголовком скрытого. Из-за такой неоднозначности может возникнуть ошибка вида "Элемент не доступен пользователю" или "Нельзя изменить значение недоступного элемента". В этом случае следует использовать шаги, принимающие в качестве параметров именно имена элементов, а не заголовки.
Исследователь формы позволяет не заходя в конфигуратор узнать имена элементов формы, их заголовки, увидеть текущее дерево элементов с учетом в том числе программно созданных и измененных элементов. Более того, при установке флага "Получать активный элемент из TestClient" вслед за движением мышки на форме в тест-клиенте исследователь форм в тест-менеджере переходит в дереве элементов к активному элементу :
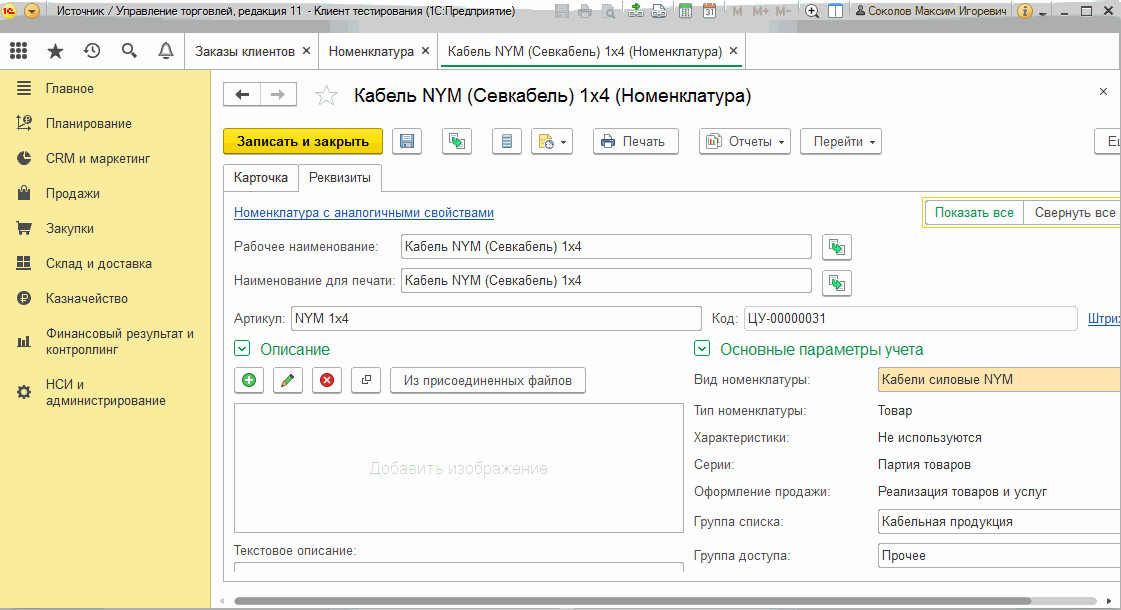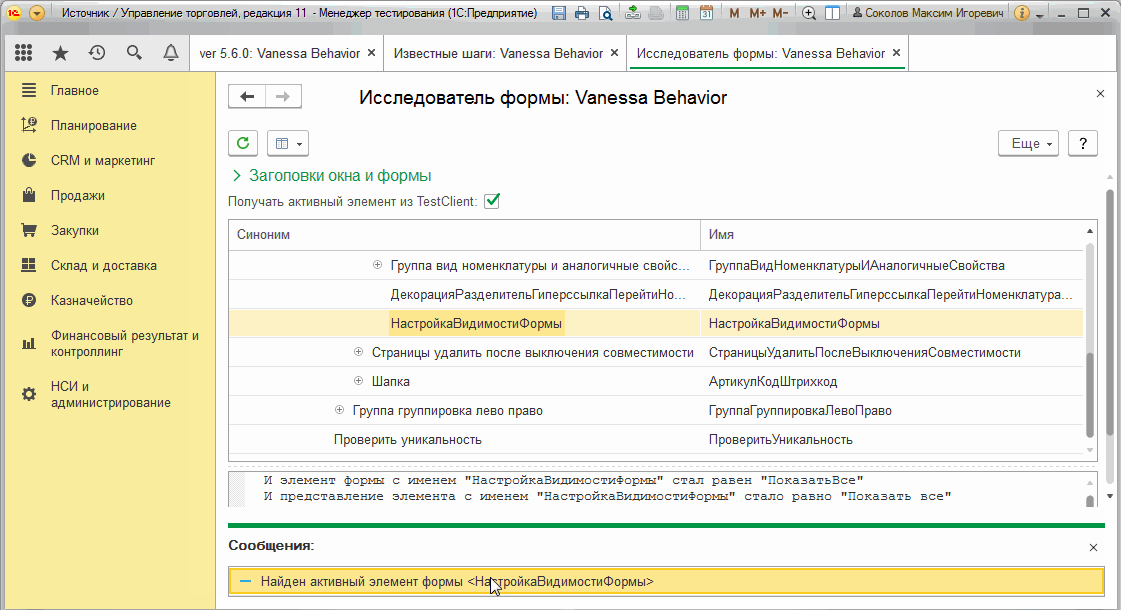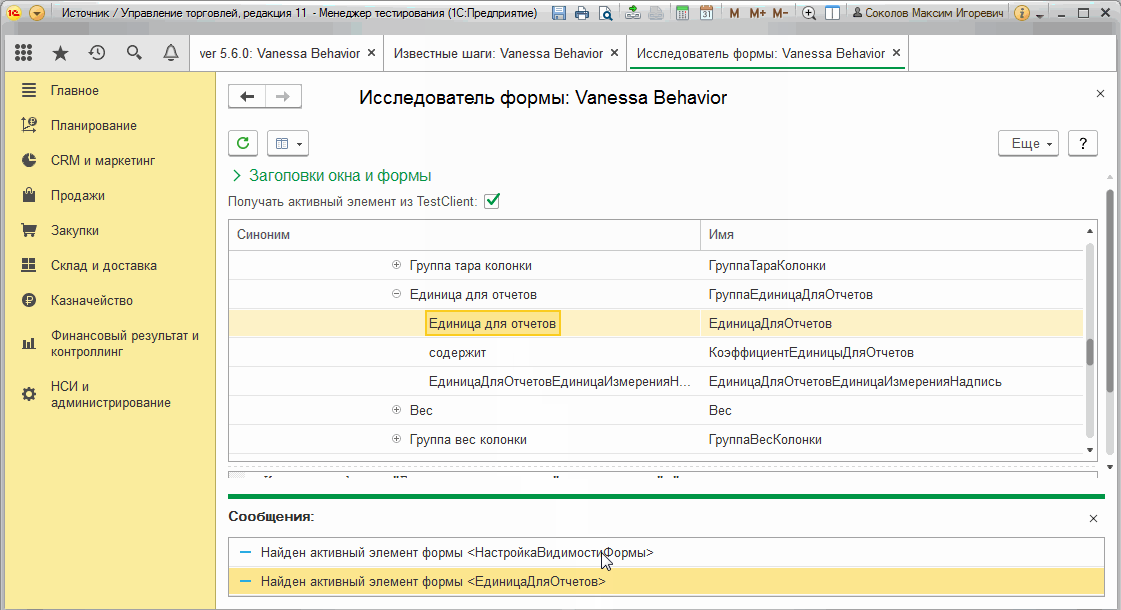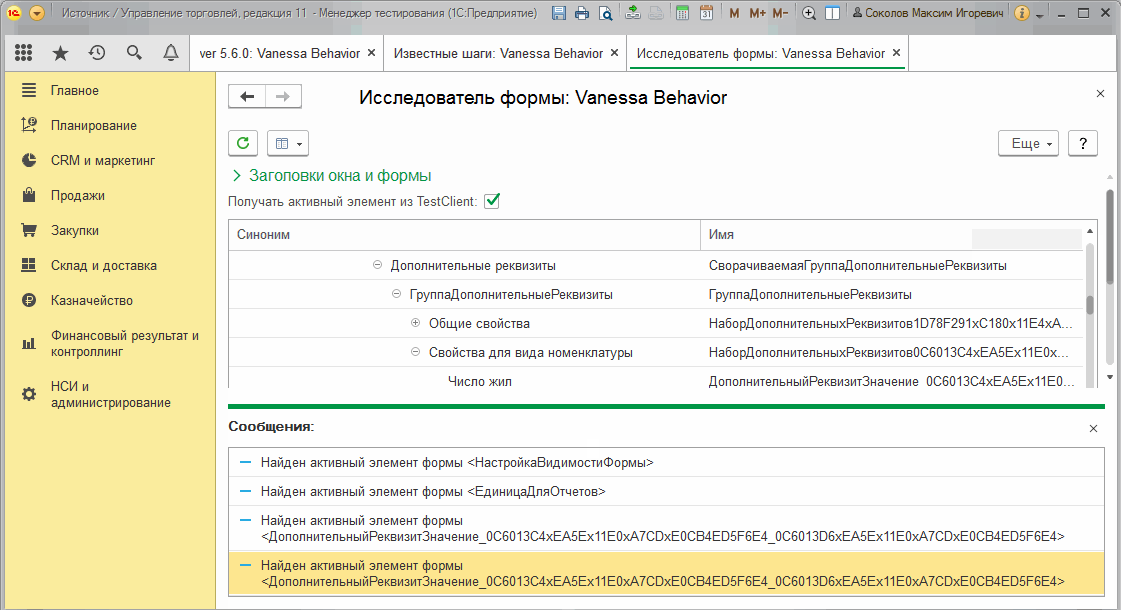
В следующей части этого руководства по Vanessa-ADD мы увидим еще одну важную особенность исследователя форм - возможность работать с системными окнами 1С, такими как форма вопроса, предупреждения, выбора типа и т.д.
Вкладка "Test clients"
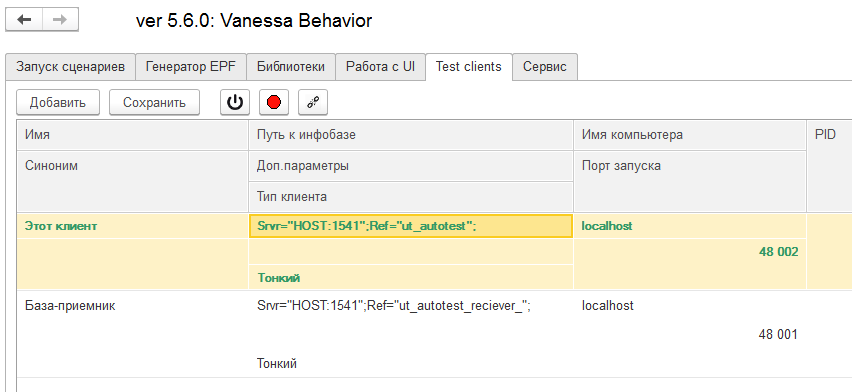
Очень интересна с технической точки зрения вкладка. На ней можно задать возможность подключения одного тест менеджера (текущего сеанса с Vanessa-ADD) к нескольким тест-клиентам. При этом тест-клиенты могут запускаться из разных баз и даже иметь совершенно разные конфигурации. Например один тест-менеджер может одновременно работать с тест-клиентами УТ 11 , БП 3 и ERP 2.
Порты для подключения не обязательно указывать вручную. Они будут определены и изменены при необходимости автоматически.
Допустим у нас есть две базы со строками подключений
Srvr="HOST:1541";Ref="ut_autotest";
Srvr="HOST:1541";Ref="ut_autotest_reciever_";
Тогда список тест-клиентов можно задать следующим образом :
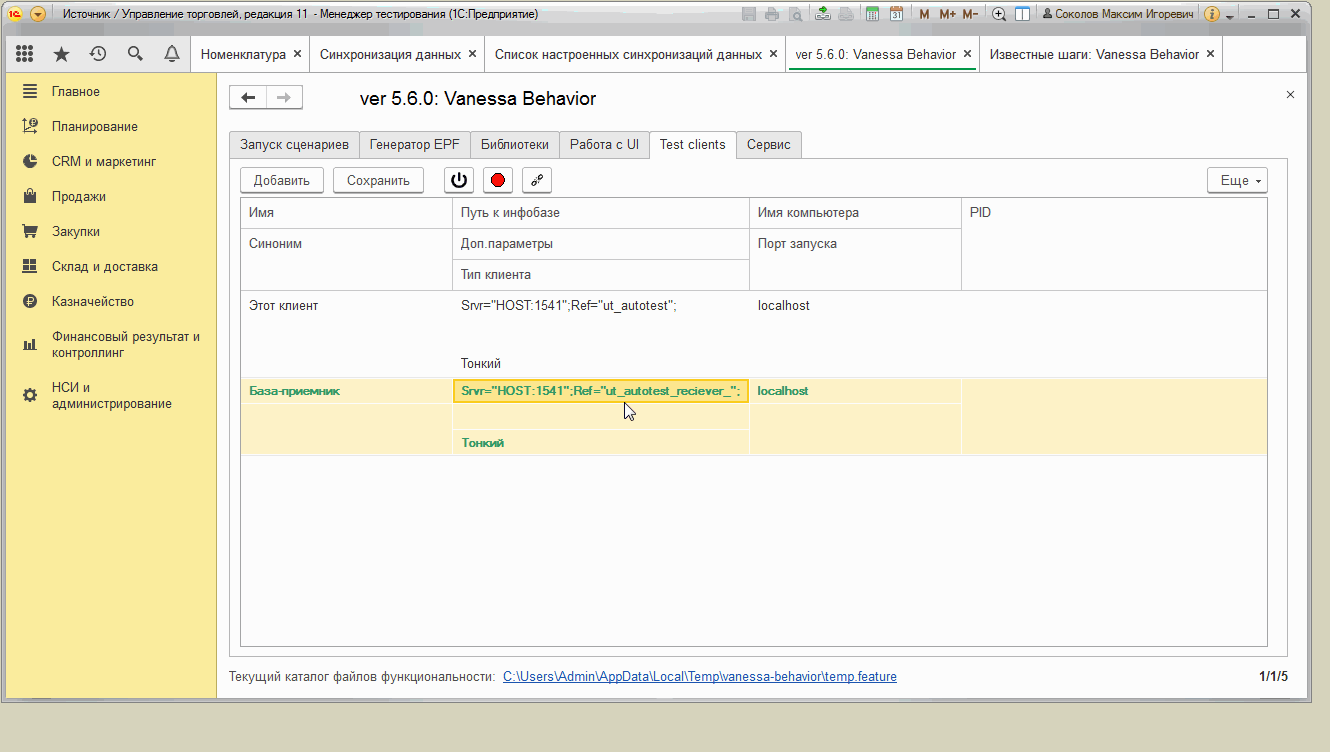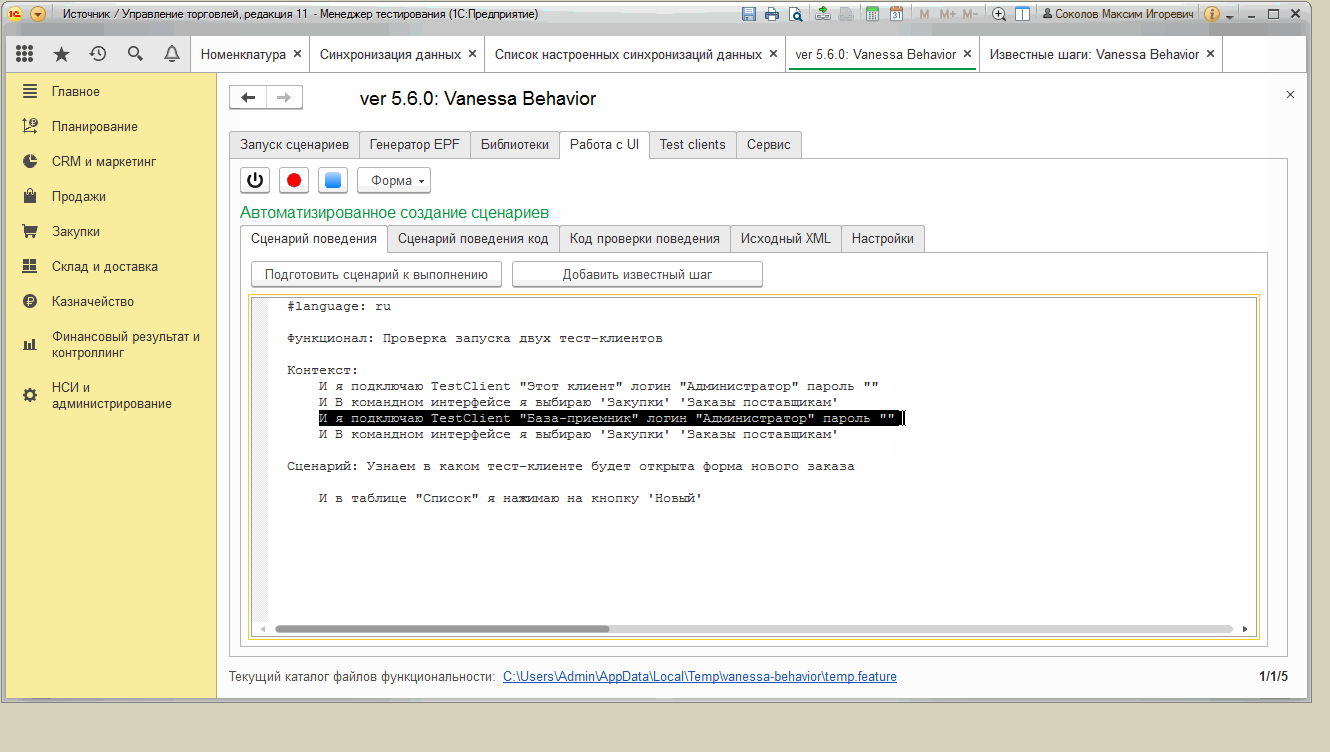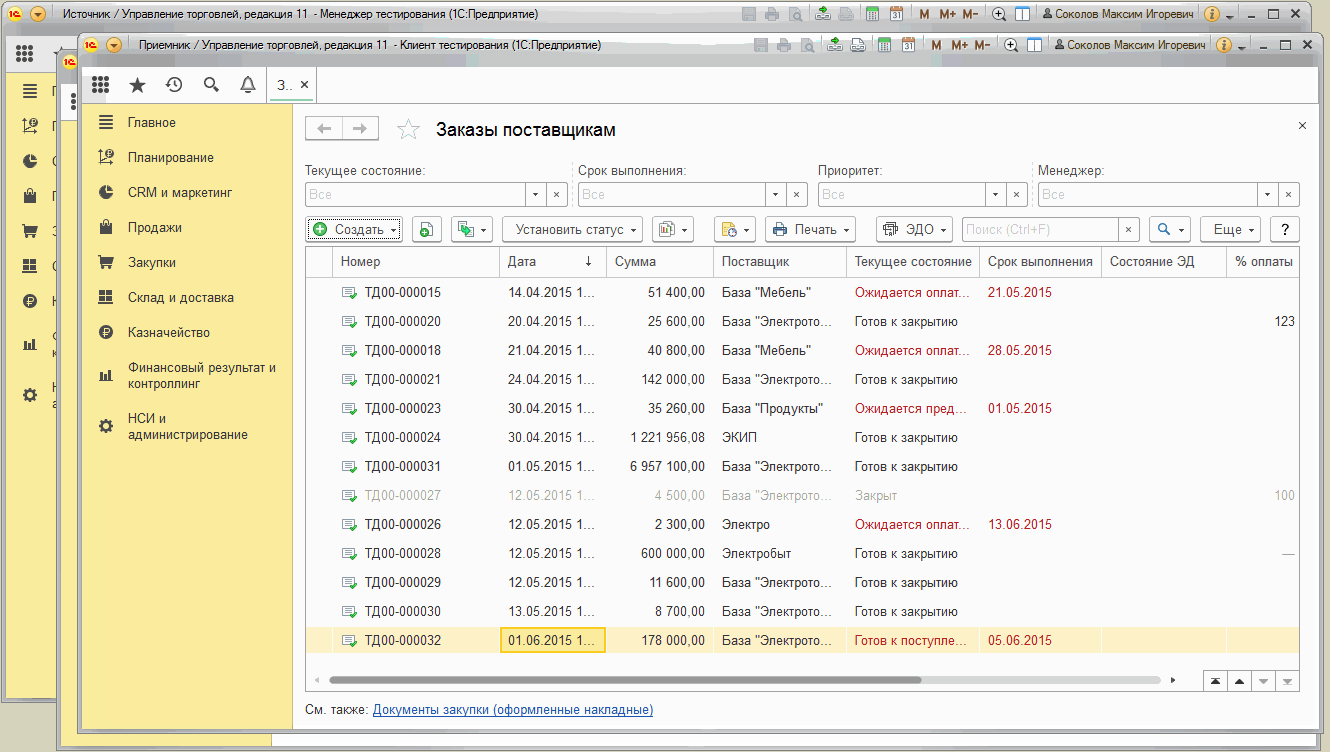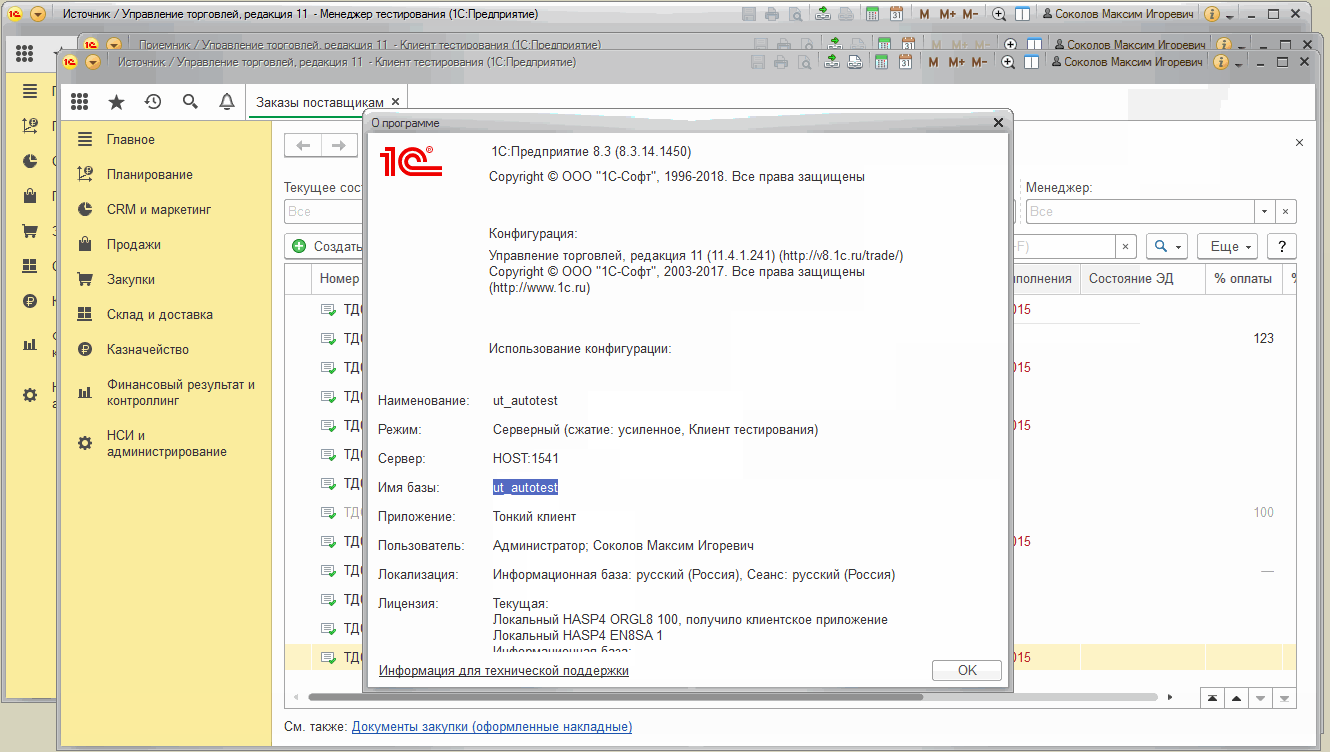
Фича-файл для проверки возможностей этой вкладки в этом случае можно написать такой :
#language: ru
Функционал: Проверка запуска двух тест-клиентов
Контекст:
И я подключаю TestClient "Этот клиент" логин "Администратор" пароль ""
И В командном интерфейсе я выбираю 'Закупки' 'Заказы поставщикам'
И я подключаю TestClient "База-приемник" логин "Администратор" пароль ""
И В командном интерфейсе я выбираю 'Закупки' 'Заказы поставщикам'
Сценарий: Узнаем в каком тест-клиенте будет открыта форма нового заказа
И в таблице "Список" я нажимаю на кнопку 'Новый'
Выполним его. Можно заметить , что второй тест клиент запускается значительно дольше, чем первый. Также в нем дольше читаются списки документов. Это объясняется тем, что база данных другая, отличная от базы тест-менеджера и первого тест-клиента. Данные этой базы еще не закэшированы ни на клиенте ни на сервере :
В следующей части руководства мы будем подробно разбирать этот функционал подключения к нескольким тест-клиентам на примере обмена между двумя базами УТ 11.
Интерфейс Vanessa-ADD :
загрузка, воспроизведение и отладка сценариев
В этом разделе рассмотрим функционал вкладки "Запуск сценариев" за исключением группы команд "Внешние инструменты". В этой группе ценность на мой взгляд имеет только команда отображения отчета Allure в браузере и ее возможность мы будем рассматривать, когда будем говорить про отчетность по результатам выполнения сценариев.
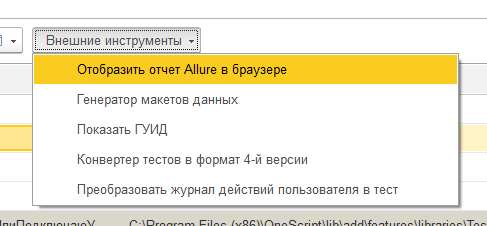
Загрузка фич
Vanessa-ADD позволяет загрузить для выполнения как отдельный файл, так и рекурсивно загрузить каталог с фича-файлами. Будь то каталог или отдельный файл, то, что было загружено отображается в нижней части окна как текущий каталог файлов функциональности :
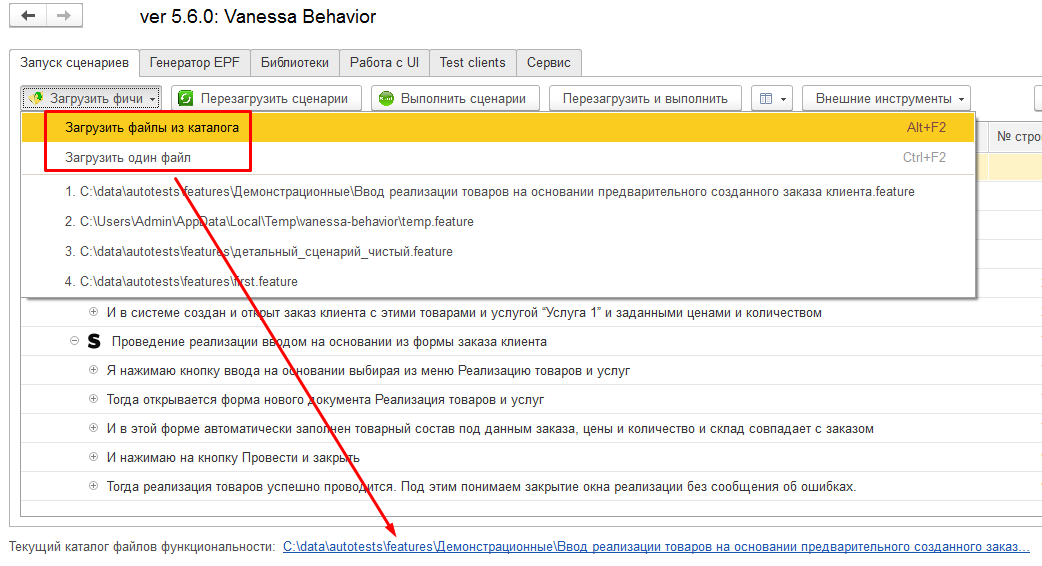
Команда "Перезагрузить сценарии" выполняет повторную загрузку из файла или каталога, что необходимо если файлы были отредактированы. Автоматически при старте выполнения сценариев Vanessa-ADD их с диска не перечитывает и для загрузки изменений из файлов необходимо вызывать команду перечитывания файлов. Аналогично действует команда "Перезагрузки и выполнить".
Если после закрытия Vanessa-ADD заново открыть ее, то файлы, с которыми велась работа перед закрытием, могут быть загружены автоматически. Этим поведением управляет настройка "Загрузка фичи при открытии" на вкладке "Сервис" :
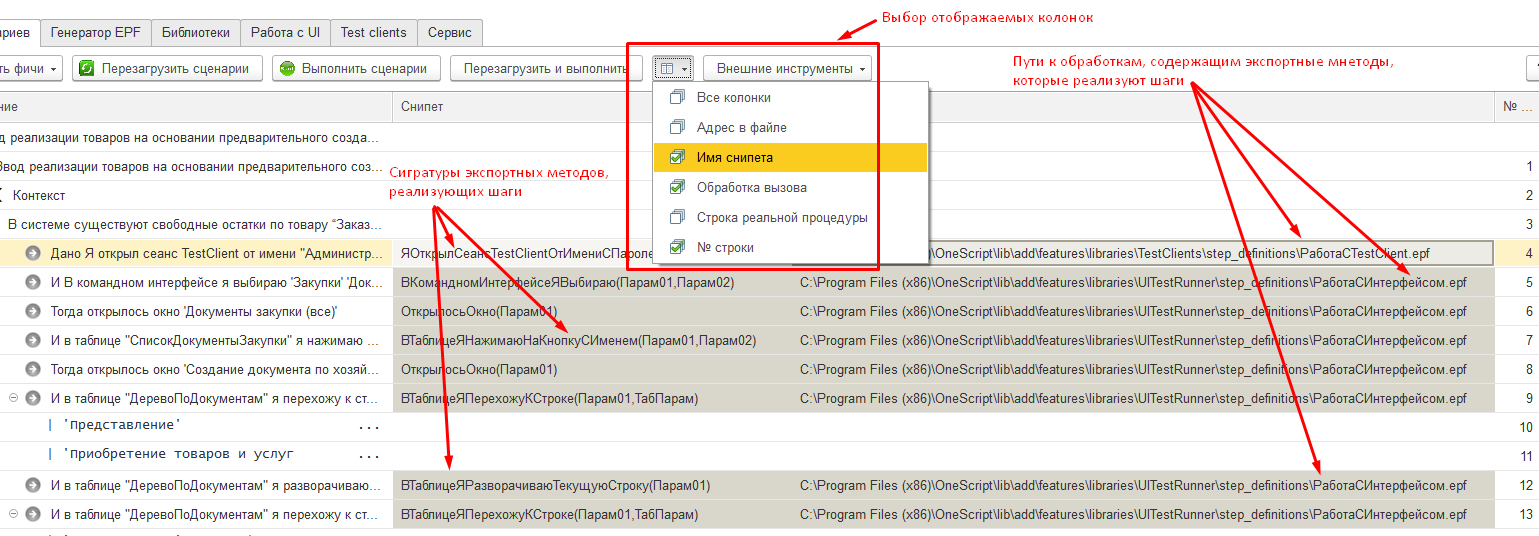
Отображение связи шагов с реализующим их методами внешних обработок
Шаги сценариев исполняются в Vanessa-ADD благодаря наличию их обработчиков - экспортных методов внешних обработок.
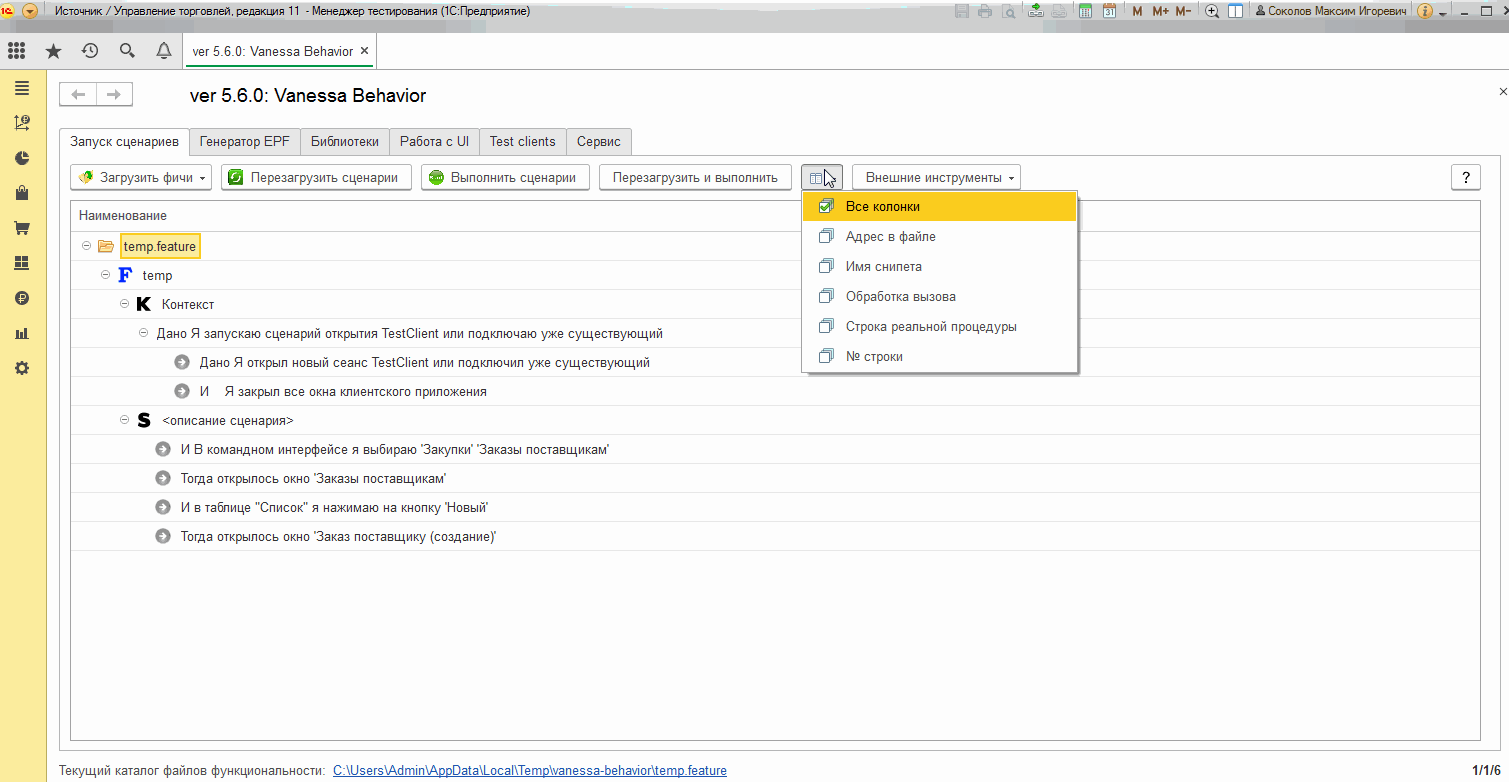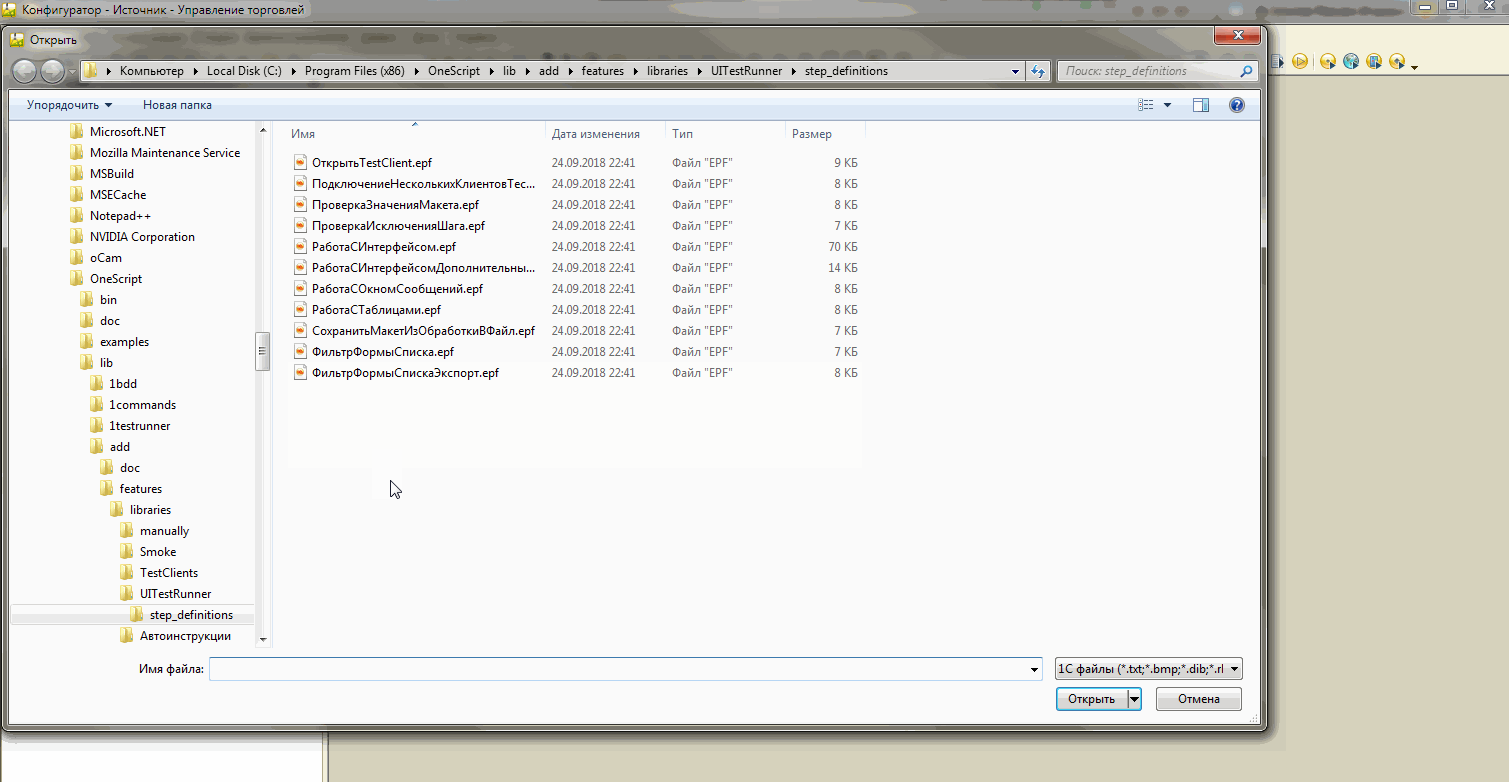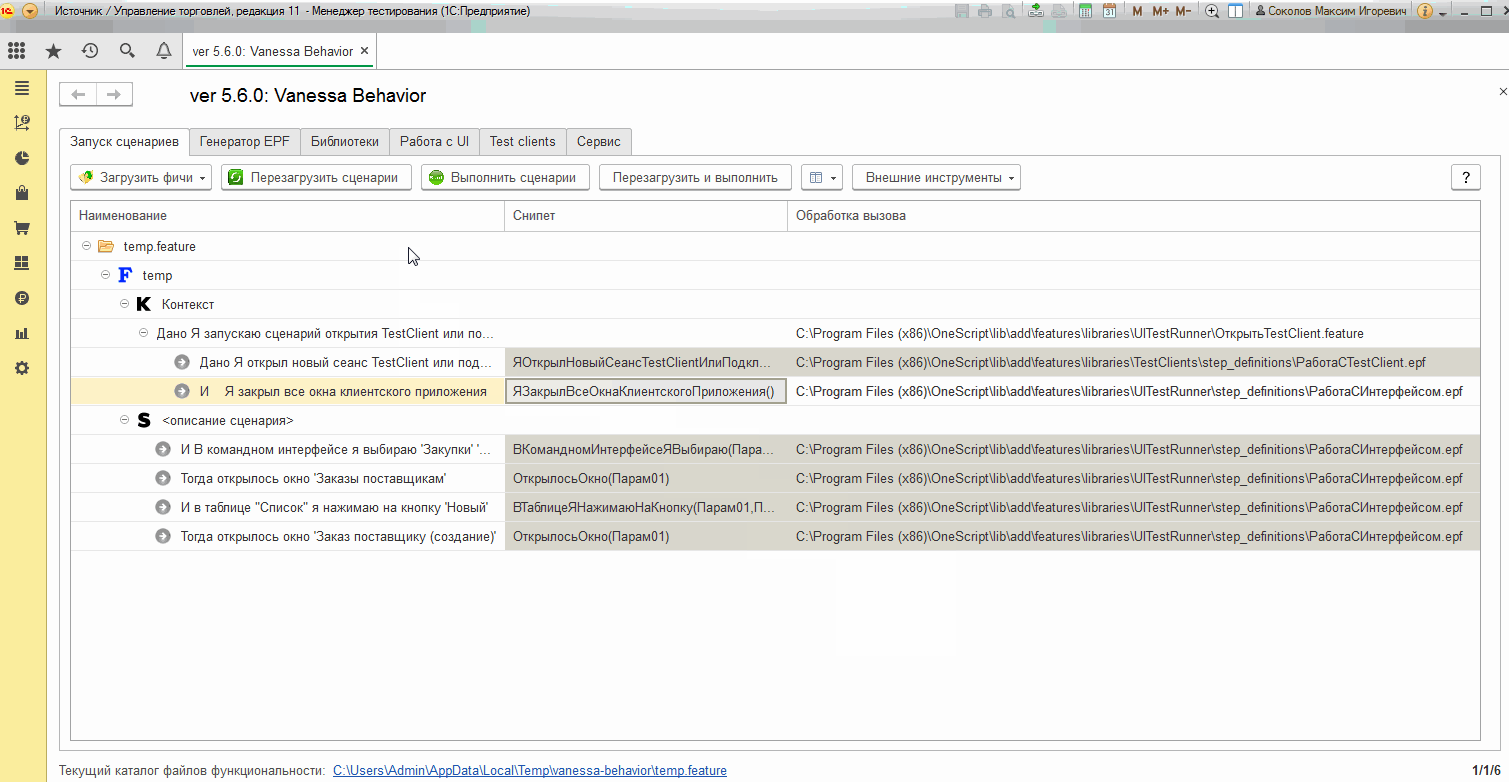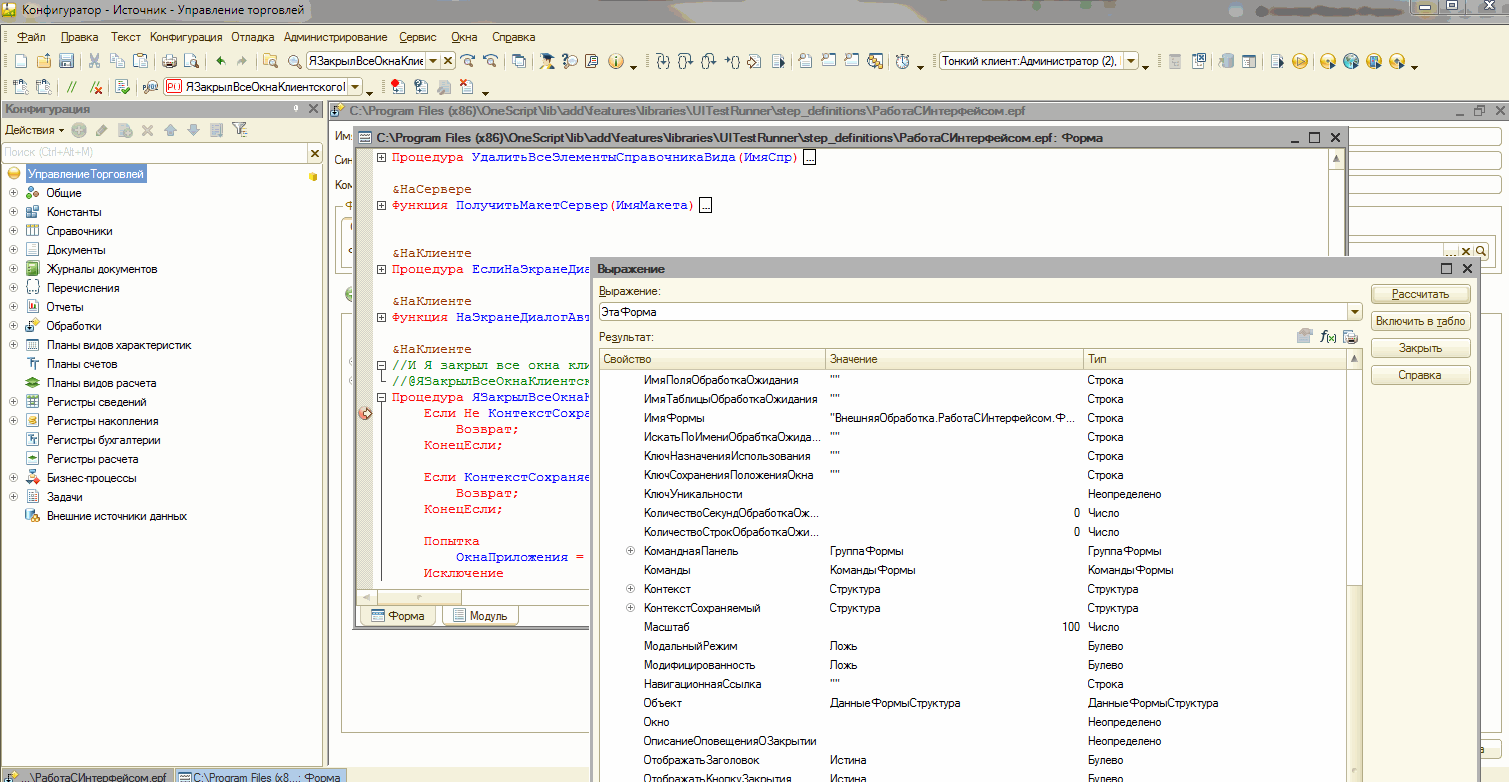
По умолчанию отображение связи шагов с реализующими их методами скрыто. Отобразить эту информацию можно настроив видимость колонок. Колонка "Снипет" отображает сигнатуру реализующего шаг экспертного метода. Параметры метода соответствуют параметрам шага - тому, что в шаге мы указываем в кавычках. Порядок и количество параметров у шага и у сниппета совпадают :

Если мы создаем свой собственный шаг, но еще не создали внешнюю обработку, содержащую реализующий шаг экспортный метод, то в табличной части шагов он будет выделяться особым образом, сигнализирующим о том, что Vanessa-ADD даже не сможет предпринять попытки выполнения такого шага.

Сталкиваясь с таким шагов в процессе исполнения Vanessa-ADD просто прекращает выполнение сценария, сообщает об этом, но не воспринимает это как ошибку :
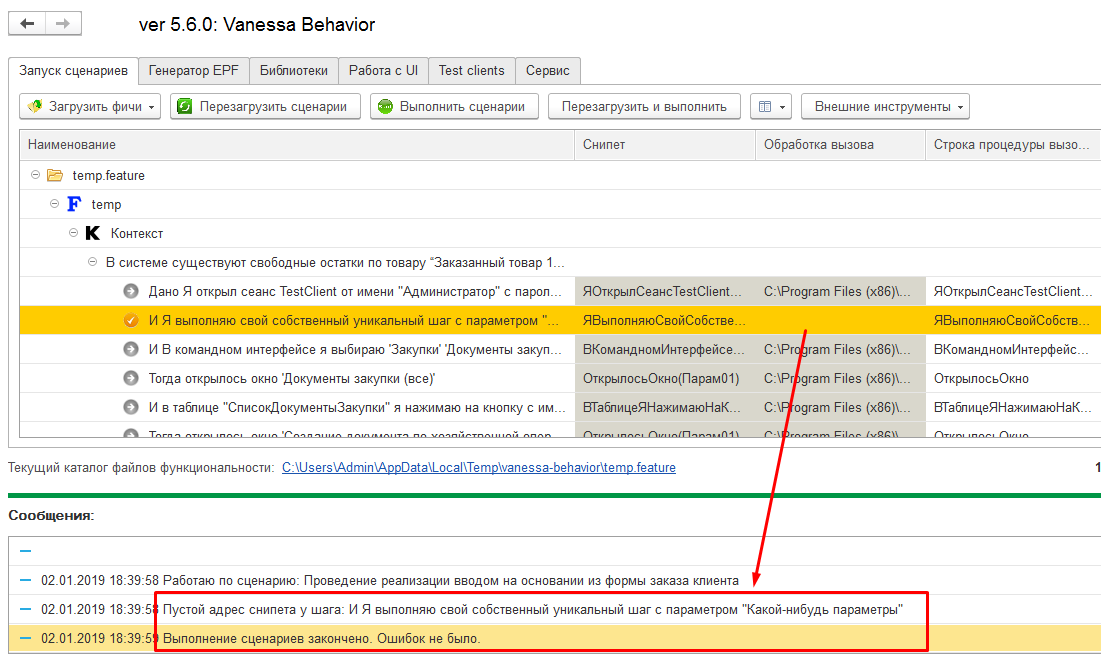
Открытие сценариев на редактирование
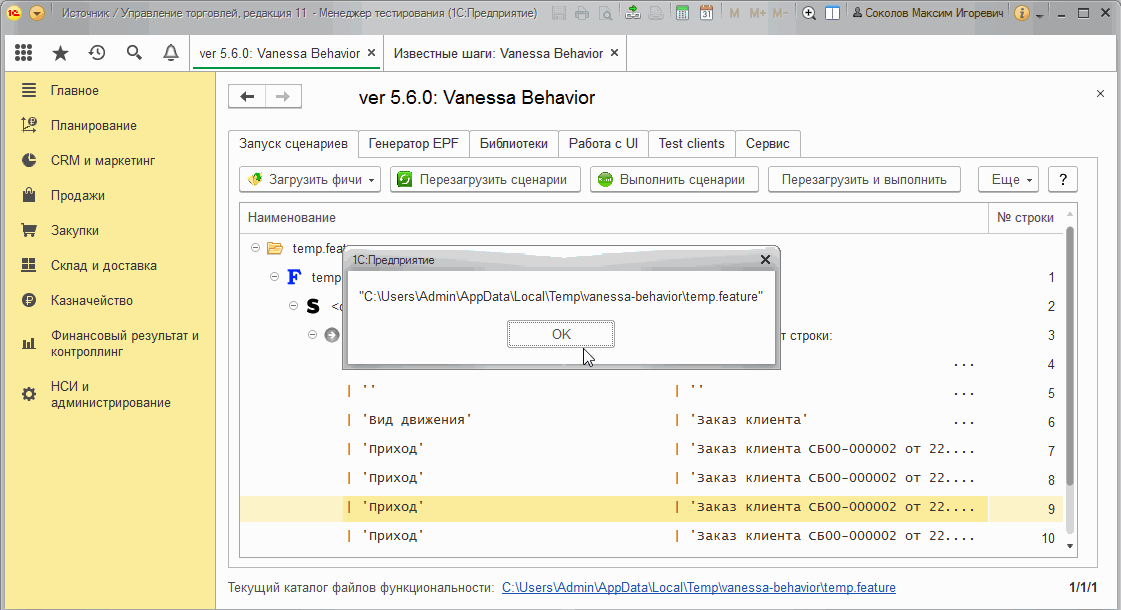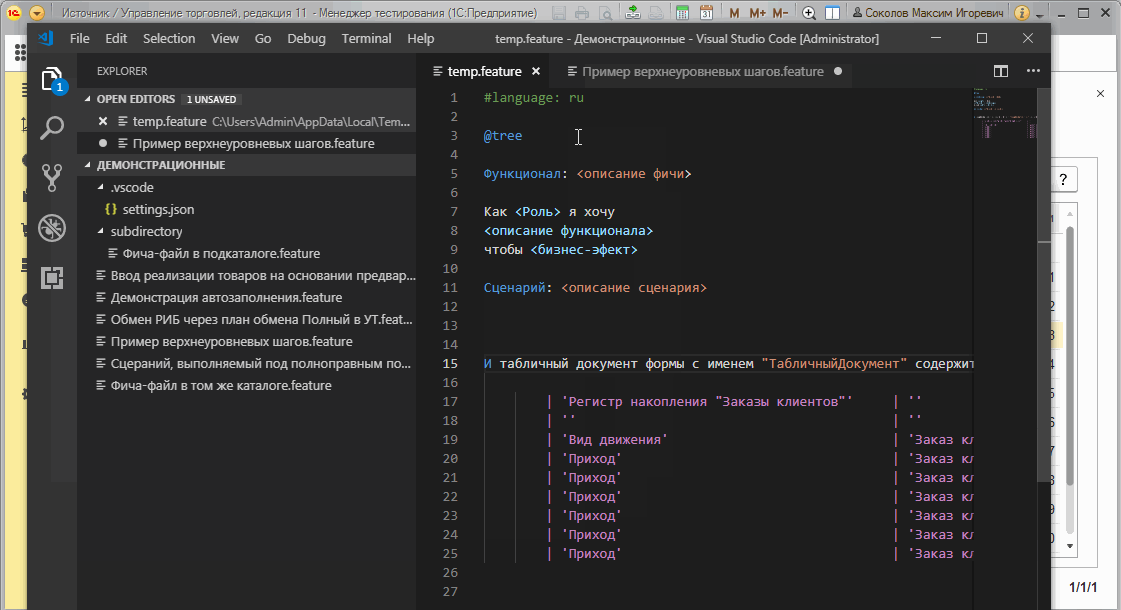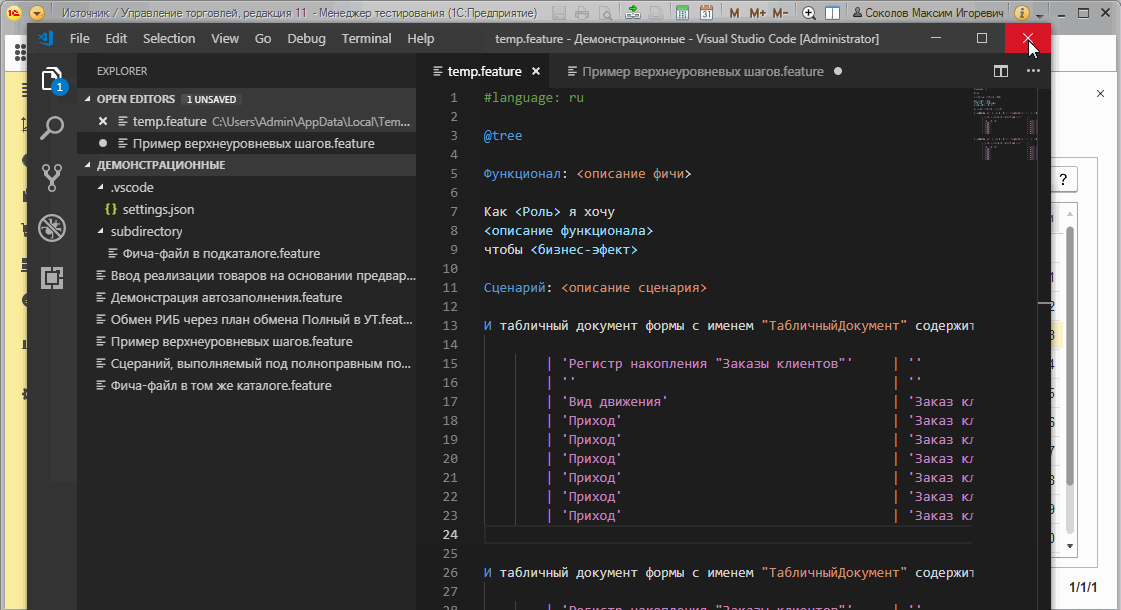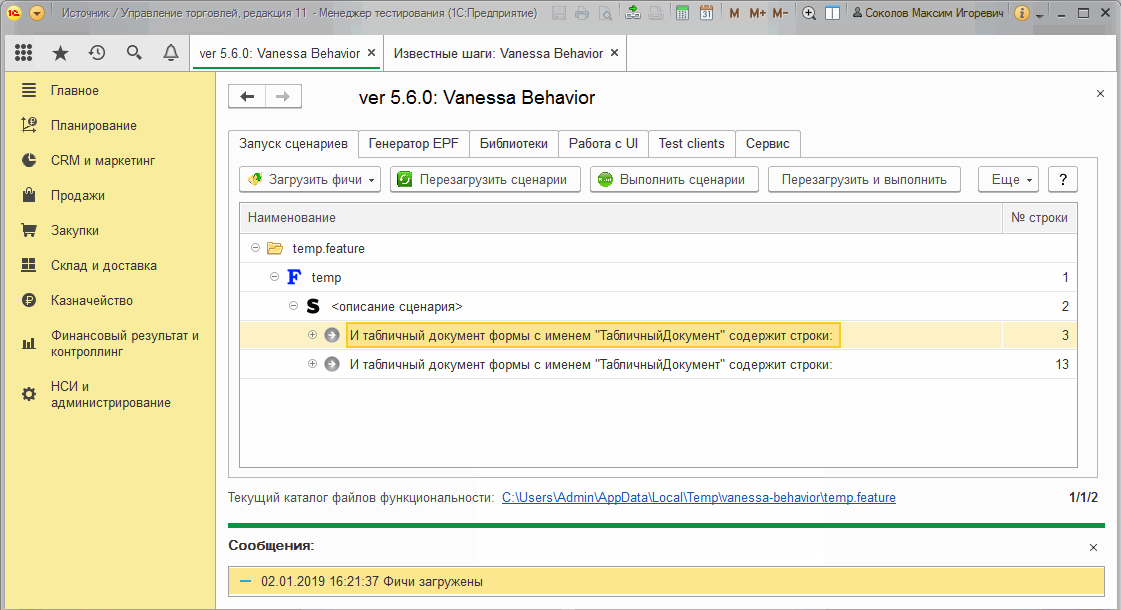
Открыть фича-файл на редактирование можно командой "Редактировать файл фичи" из контекстного меню. Для редактирования необходимо, чтобы расширение .feature было ассоциировано с Visual Studio Code. В этом случае можно будет редактировать и затем перечитывать даже фича-файлы, находящиеся во временном каталоге операционной системы :
Выполнение сценариев
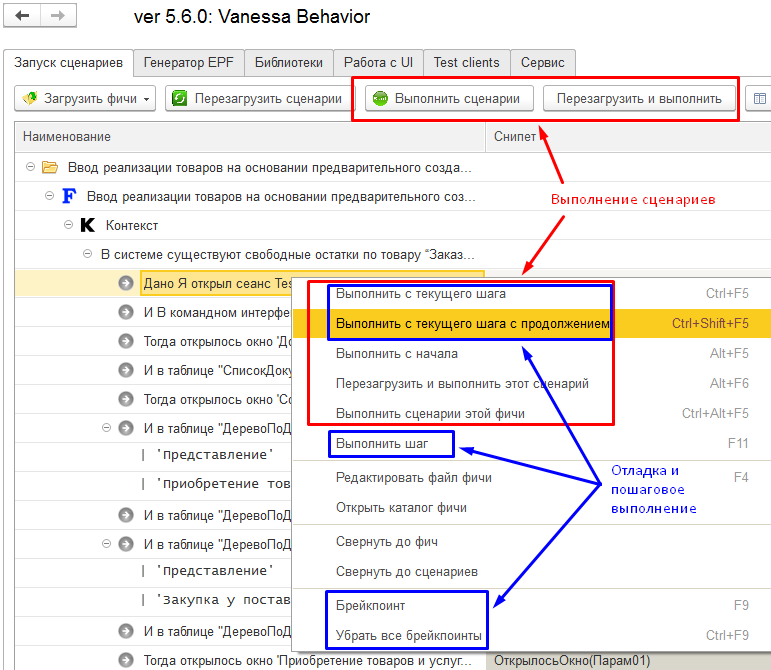
Функционал обычного выполнения сценариев достаточно прост - последовательно исполняются все шаги до тех пор пока они все не будут исполнены или не произойдет исключительная ситуация. Команды, отвечающие за исполнение разделены между командной панелью и контекстным меню. Среди них есть как команды выполнения уже загруженных фич, так и команды перезагрузки и отправки на выполнение.
Часть команд выполнения можно отнести к функционалу отладки, который мы разберем ниже :
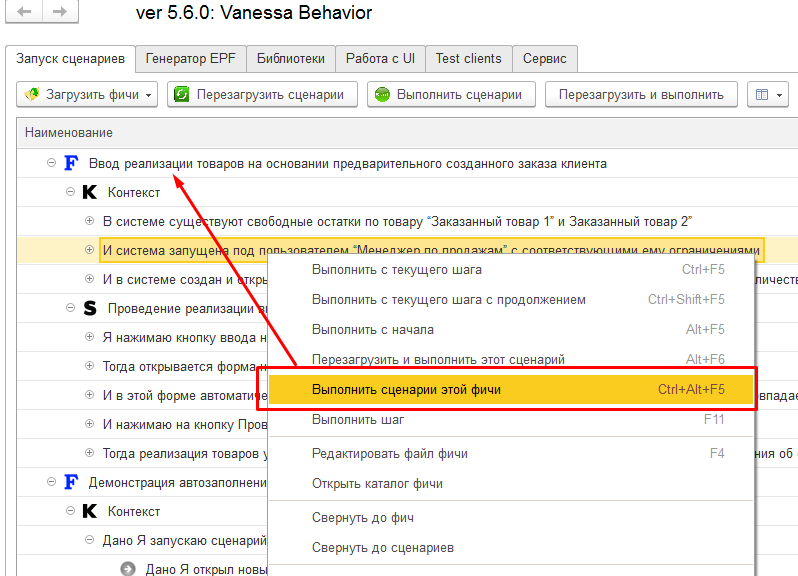
В случае если мы загрузили не один файл, а каталог, содержащий несколько фича-файлов, то в контекстном меню также появится пункт “Выполнить сценарии этой фичи”. В процессе разработки и отладки сразу нескольких сценариев эта команда бывает удобна. Например мы работаем над каталогом фич и хотим посмотреть как они ведут себя при поочередном выполнении, но в процессе работы находим ошибку в одном файле. После исправления файла и перезагрузки сценариев можно посмотреть, как выполнится только исправленный файл. Это избавит от необходимости лишний раз загружать для проверки только один файл, а после окончания проверки снова загружать весь каталог :
Отладка сценариев в Vanessa-ADD и методов, реализующих шаги, в конфигураторе
Один из приемов отладки мы уже видели, когда говорили про команду подключения тест-клиента . Это была возможность начать выполнение сценариев с произвольного шага , предварительно подготовив нужные формы и данные в тест-клиенте. Эта возможность реализуется командами "Выполнить с текущего шага" (в данный момент на моей инсталляции она не работает) и "Выполнить с текущего шага с продолжением". Так можно посмотреть, как сценарий поведет себя в иных условиях, чем создаваемые предыдущими шагами.
К другим приемам относится возможность установить точки останова и пошагового исполнения сценариев.
Отличительной особенностью пошаговой отладки в Vanessa-ADD является то, что тест-клиент всё время остаётся доступным для интерактивной работы. Поэтому после остановки на каждом шаге мы можем произвольным образом вносить изменения в тестируемые формы и смотреть реакцию сценария на эти изменения. Очень удобная возможность, она аналогична возможности поменять значение переменной в процессе отладки в Конфигураторе ))
В прошлой части мы подготовили сценарий, который среди прочего создает документ "Заказ клиента". Применим к нему точку останова и посмотрим как сценарий отреагирует на вмешательство в данные формы. Для демонстрации особенности поведения Vanessa-ADD при прохождении от одной точки останова до другой установим две точки останова - на запуске тест-клиента и на проведении заказа клиента.
Анимация ниже показывает, что дойдя до первой точки останова мы попытались продолжить выполнение командой "Выполнить с текущего шага с продолжением", но это не привело к ожидаемому результату. Попытавшись запустить последовательное выполнение шагов, система увидела точку останова и опять сказала нам, что выполнение приостановлено.
Чтобы продолжить выполнение после точки останова нужно либо отключить ее, либо сначала пройти этот шаг командой "Выполнить шаг (F11)". Затем уже можно вызвать команду "Выполнить с текущего шага с продолжением", которая приведет к последовательному выполнению следующих шагов вплоть до следующей точки останова.
Остановившись на второй точке останова мы заходим в тест-клиент и свободно меняем данные формы. После чего продолжаем пошагово выполнять сценарий пока не наталкиваемся на шаг-утверждение "Тогда открылось окно 'Реализация товаров и услуг (создание)'" :
Форма реализации товаров у нас не открылась, так как документ заказа не был проведен - мы в нем очистили обязательные реквизиты. При этом с падением теста мы столкнулись не в момент проведения самого заказа. Ведь шаг "И я нажимаю на кнопку 'Провести'" выполнен успешно - пользователь вполне может нажать на эту кнопку без каких либо ошибок. И более того, после этого может попытаться ввести реализацию товаров. Отклонением от ожидаемого поведения с точки зрения сценарного тестирования является отсутствие формы нового документа реализации товаров - вместо него появилось другое окно, сообщающее о невозможности ввода на основании. Вот так и работает проверка поведения! ))
Теперь перейдем к вопросу отладки в конфигураторе самих экспортных методов, реализующих шаги. Подходы несколько различаются для старых версий Vanessa-ADD и для последних версий, где процесс отладки сделан проще.
Для версий Vanessa-ADD до 5.1.0 и ранних версий параллельного проекта Vanessa-Auotmation применим общий прием отладки внешних обработок, подключаемых программно. Как мы видели выше, каждый шаг реализуется за счет внешней обработки и ее экспортного метода. Для исполнения шага bddRunner.epf создает и подключает объект внешней обработки средствами встроенного языка 1С, затем вызывает экспортный метод формы этой обработки.
Для отладки экспортного метода внешней обработки, подключаемой программно, необходимо запустить тест-менеджер из конфигуратора. До самого первого исполнения шага открыть реализующую его внешнюю обработку в этом сеансе тест-менеджера через "Файл → Открыть". Затем открыть эту обработку в конфигураторе, найти нужный метод в форме обработки и поставить в нём точку останова. Затем можно выполнять сценарий в bddRunner.epf - точка останова сработает.
Если открыть реализующую шаг обработку в сеансе тест-менеджера не до, а после после первого исполнения шага в bddRunner.epf, или вовсе не сделать этого, то платформа может особым образом закэшировать внешнюю обработку в том виде, который не позволяет выполнять отладку и точка останова не сработает. В этом случае чтобы получить возможность отлаживать метод, реализующий шаг, придётся перезапустить сеанс тест-менеджера из конфигуратора и выполнить в нём перечисленные выше действия.
Посмотрим как это сделать на примере :
Разумеется этот приём отладки сработает всегда. Но начиная с версии Vanessa-ADD 5.1.0 и в новых версиях параллельного проекта Vanessa-Automation отладка упрощается. Если база файловая или база серверная, но тест-менеджер и тест-клиент запускаются на том же компьютере, на котором запущен сервер 1С, то не обязательно перед началом отладки открывать внешнюю обработку через "Файл → Открыть" в тест-менеджере. Достаточно просто открыть реализующую шаг обработку в конфигураторе, поставить в ней нужную точку останова и она сработает.
Если же база клиент-серверная и тест-менеджер запускается на машине, отличной от той, на которой запущен сервер 1С, то правила остаются прежними.
В более формальном виде правила отладки приведены в документации на github: https://github.com/silverbulleters/add/blob/master/F.A.Q.MD
В следующей части этого цикла публикаций рассмотрим ряд практических сквозных примеров, нетривиальных приемов работы и применения встроенных библиотечных шагов :
- тестирование обмена в РИБ,
- сценарии проверки движений документа,
- прикрепление файлов,
- выполнение произвольного кода 1С,
- запуск нескольких тест-клиентов и т.д.
Не забывайте отмечать публикацию звёздочкой и делиться ссылкой - так вы поможете привлечь внимание сообщества к теме сценарного тестирования и окажете поддержку в выпуске следующих публикаций на эту тему.
Вступайте в нашу телеграмм-группу Инфостарт