





Ко мне обращались клиенты с просьбой сделать рекомендации при подборе номенклатуры "как в интернет магазине". Небольшое исследование показало что подобные алгоритмы строятся на принципах коллаборативной фильтрации, которая бывает 2х видов "по схожести покупателей" и "по схожести предметов" (также есть гибрид этих методов). Первой мыслью было сделать алгоритм Slope One и выдавать в подборе те товары, которые покупают "похожие" покупатели, но вот Амазон в своей статье указывает на недостатки такого подхода https://www.cs.umd.edu/~samir/498/Amazon-Recommendations.pdf
На этой картинке изображено сравнение 2х подходов:
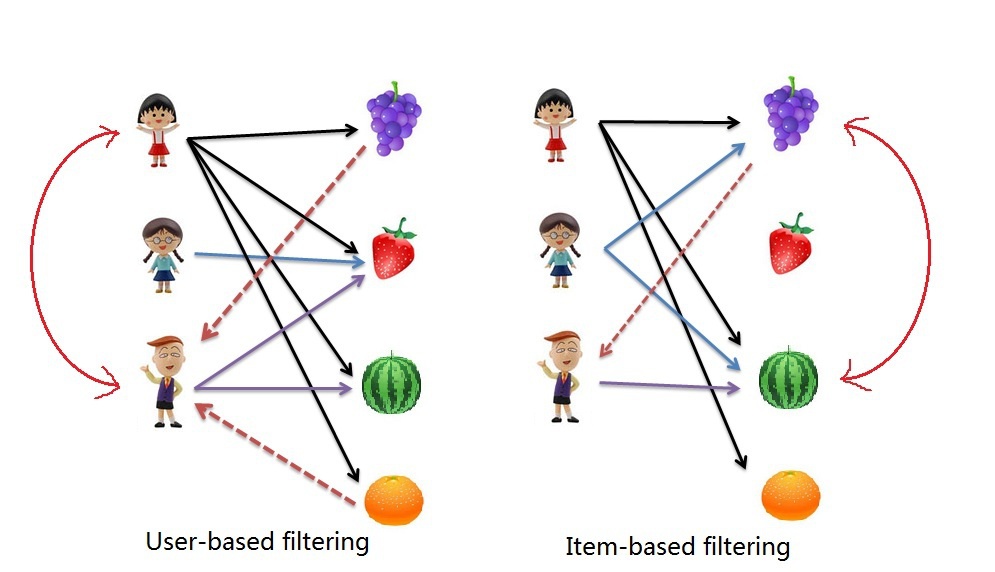
И они используют свой алгоритм в своей интернет платформе - по схожести предметов "Item-to-Item".
В 1С есть механизм поиска ассоциаций, это реализовано в виде расчета регистра "Номенклатура продаваемая совместно", но он имеет некие настройки, которые надо подобрать эмпирическим путем, кроме того метод вычисления оценки недоступен (а он может быть разный). В то же время амазоновский и другие аналогичные методы считают "похожесть" разными способами . Например вот тут приведены различные оценки схожести векторов https://en.m.wikipedia.org/wiki/Cosine_similarity (я сразу извиняюсь за то что привожу в этой и других своих постах англоязычные тексты, но причина по которой я это делаю в том, что в русскоязычных просто недостаточно полная информация - недописанные статьи и просто не все есть. Это как начать смотреть сериал в котором не хватает серий. Проще уж сразу на англоязычных ресурсах все смотреть)
Детального описания "от и до" я не нашел, поэтому пришлось допускать свои вольности чтобы сделать применение.
Исходными данными являются продажи - документы реализации с товарами. На основе их строятся вектора. Если покупатель купил товар то присваивается "1", если не купил - "0". Т.е. количество не учитывается, учитывается только состав товара в корзине. В результате мы получаем набор векторов продаж для каждого товара . Что то типа такого: (0,1,1,0,0), (0,0,1,0,0) - размер векторов одинаковый.
Далее мы используем оценку от Амазон в виде косинуса между векторами:
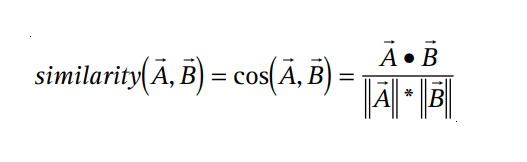
Ну и получается для каждого товара мы получаем набор векторов со своими весовыми коэффициентами "похожести". Я беру для каждого товара не более 3х похожих товаров, сортирую их по убыванию коэффициентов и вывожу как рекомендуемые. Можно брать одного "победителя" для каждого товара. Тут возможны вариации.
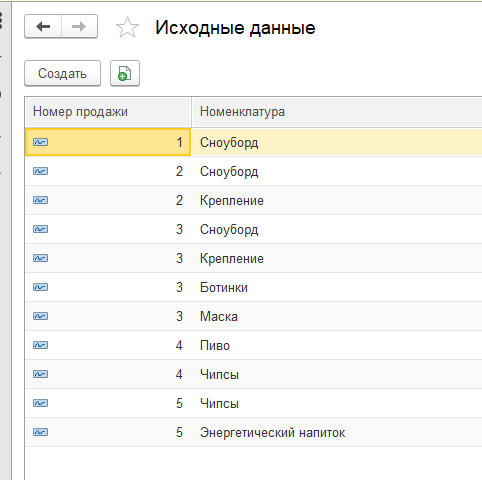
Сначала для разработки я использовал чистую демо базу где сделал такие исходные данные (номер продажи используется как группировка продаж, аналогично документу "Реализация товаров")
И написав алгоритм, получил такие данные в рекомендациях:
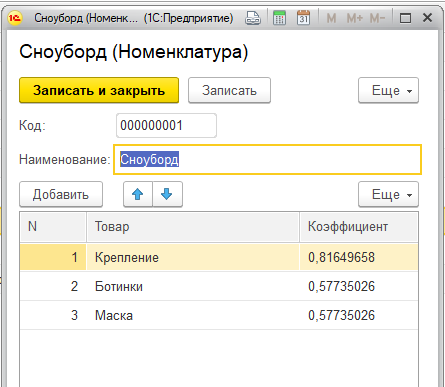
Это показывает что алгоритм работает. Эта демо база есть во вложении к статье по ней возможно будет проще разобраться с алгоритмом так как в базе простая структура и мало данных.
Также я сделал расширение для УТ11. Что оно делает:
1) там есть расчет рекомендаций по алгоритму написанному выше. Это длительная операция. Можно повесить на регл задание вызов этой функции в принципе. В результате у каждой номенклатуры вычисляются до 3-х рекомендованных товаров
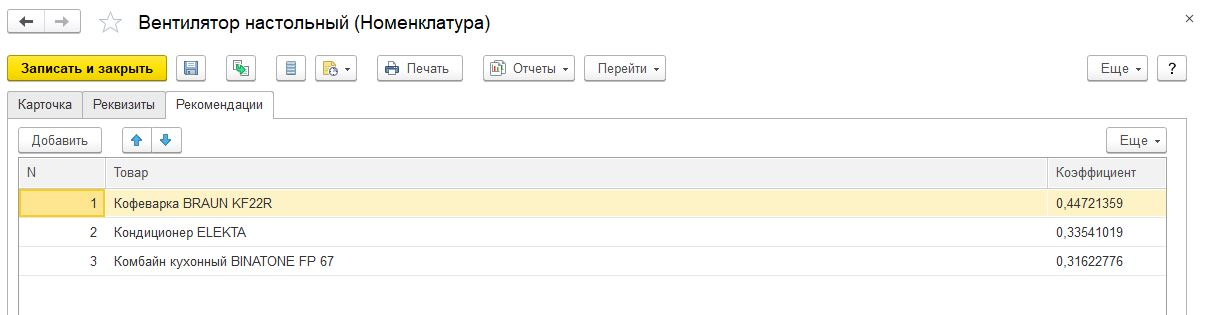
2) изменена форма подбора: алгоритм смотрит на корзину, и по корзине заполняет табличная часть Рекомендации. Из рекомендаций также можно добавлять товары в корзину
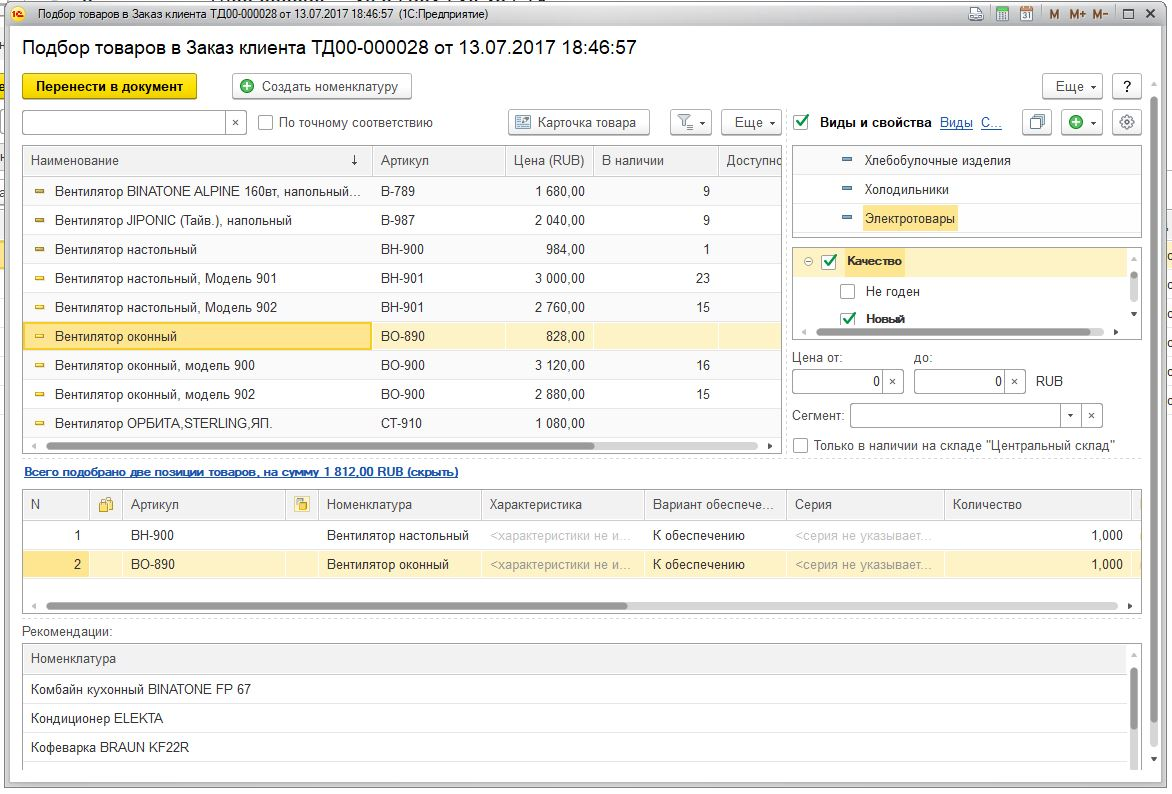
На типовой тестовой базе работает несколько однобоко, так как там данных мало. А вот в рабочих базах уже интереснее. Внимание! В расширении в подборе, в рекомендациях не учитываются доступные остатки - я это не делал, в связи со спецификой задачи. Также расчет рекомендаций не работает по характеристикам - тут уже надо менять алгоритм, сейчас он только по товарам.
Вступайте в нашу телеграмм-группу Инфостарт