




ВАЖНО
Не смотря на все "нехорошее" поведение Atlassian по отношению к нашей стране, все таки продукт Confluence у них неплох. И многие им пользуются. А еще, отечественные "аналоги" как то не спешат с публичными API для доступа к информации из базы знаний. Поэтому публикация актуальна и в 2025м году.
Сама статья
Если кто-то следит за мной, ну или по крайней мере хотя бы немного смотрел мои доклады на Инфостарт, то он знает, тема управления знаниями в компании меня так или иначе беспокоит давно. В основном, это из-за моей должности. Как руководитель я должен настраивать процессы, минимизировать затраты, оптимизировать взаимодействия с заказчиками и много другого (маленькая компания, многое объясняет).
Предыстория
Внедрение для нас не такой частый кейс был, до 2020 года. Мы сознательно отходили от внедрения в сторону разработки. А внедрение наших решений выполнялось руками заказчиков, с нашим "шеф-надзором". Но в 2020-м мы подписались на внедрение комплекса программных продуктов в местном водоканале. Для меня этот проект принес много неприятных открытий, бОльшая часть была не связана с нами (а связана с тем, что такое гос-компании). Но кое-что было и у нас организовано не лучшим образом.
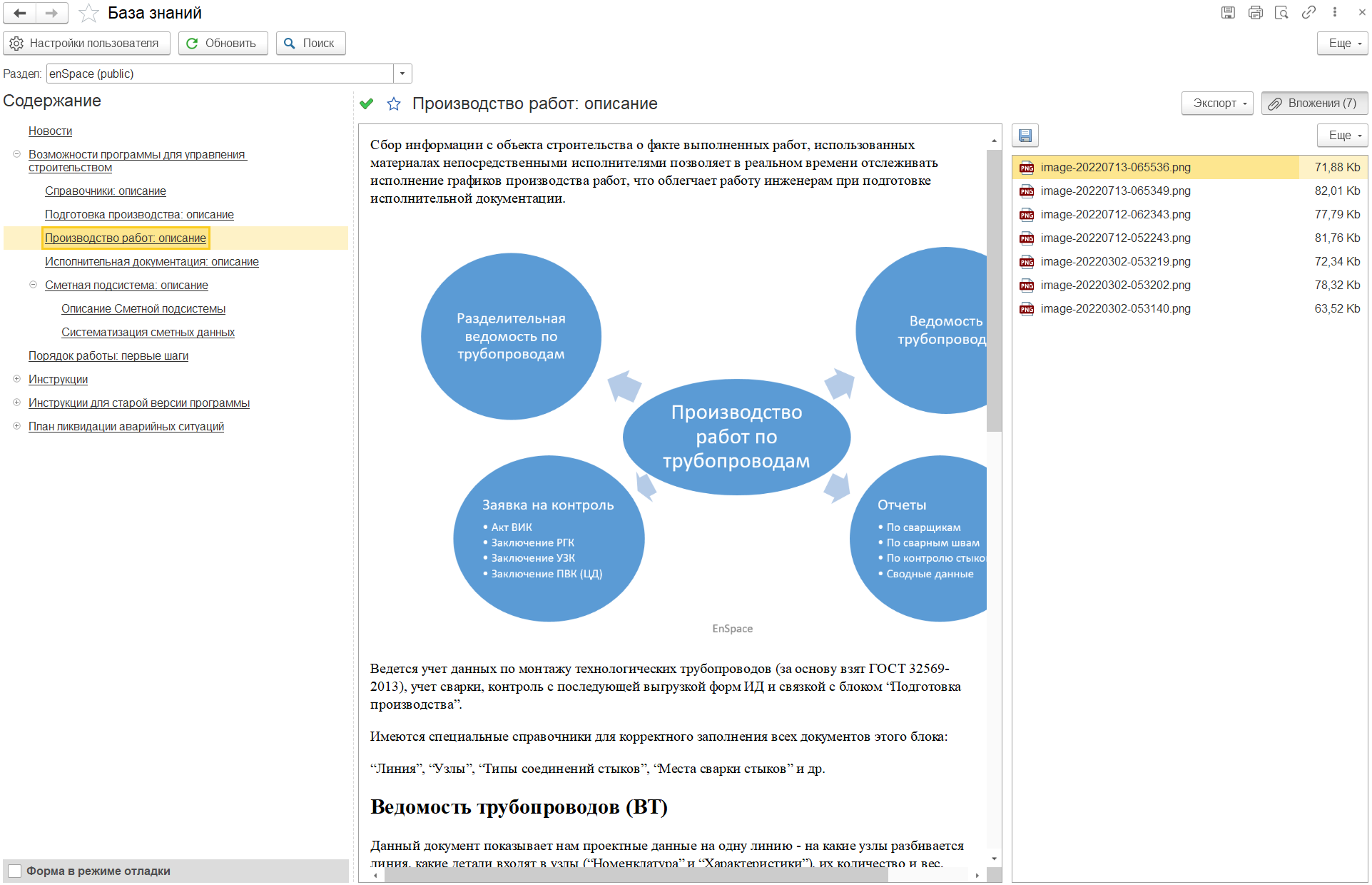
Мы писали инструкции в базу знаний, потом писали инструкции как работать с базой знаний, последние рассылали пользователям, учили их. Но со временем стало ясно. Почти никто не хотел делать закладку в браузере. Совсем никто не запоминал адрес. Ну, а то, что внутри есть некоторая организация данных, которую надо понять, это же надо вникать... в общем, никто вашу базу знаний читать не будет, даже вы сами. Если расстояние от вопроса до ответа дольше, чем позвонить или написать в Whatsapp и высказать "у вас тут все не работает". И с этим надо было что-то делать...
Варианты:
- сразу же местные программисты предложили: "Распечатайте им все инструкции, отдайте и пусть не говорят что не знают". Ну подход у них такой, если пришел пользователь с проблемой, сначала надо отшить, и вот если этот пользователь со своим вопросом дойдет до генерального ну или другого зур (на местном наречии это большой) начальника, тогда и будем решать. А еще лучше: пишите служебку там и рассмотрим...
- с нами такой подход не прокатывает. Любая попытка ответить: мы учили, мы показывали, мы инструкцию давали, мы... от заказчика (и самих "программистов") выводилось в поле "ну вам что сложно, покажите еще раз... ну или мы вам акт не подпишем". В общем кто сталкивался с подобными заказчиками, понимает как это бывает.
Я некоторое время подумал и решил, а сделаю я им доступ из 1С к инструкциям. Но: никаких выгрузок, никаких переносов данных, максимальная оперативность между нашими изменениями и доступом со стороны заказчика. Надежда, что на этом мы договоримся и поток повторных обучений снизится, во мне никак не собиралась умирать последней.
Confluence Cloud
На тот момент мы довольно давно отказались от базы знаний в 1С (была такая разработка у меня) и перешли в Confluence cloud. Данные были перенесены в нее и там продолжают наполняться. Есть, конечно, некоторые заморочки с оплатой (после некоторых событий), но тут не об этом. Работает и отлично.
И вот тут кажется можно заканчивать статью, у confluence есть REST API, всего-то надо сделать:
- интерфейс для пользователя
- обработку действий в интерфейсе
Я тоже так думал и с полными штанами энтузиазма начал это делать. Хотя нет, тут будет не честно сказать, что я ничего не знал. Помните историю про перенос данных из 1С в облако, конечно же его я сделал тоже используя REST API. Но тогда я сделал это "на коленке", а главное я не придал большого значения тому, что есть определенный формат хранения данных для статей. Я просто под него "прогнулся", все получилось, красиво, удобно, хорошо. Я порадовался и пошел решать другие задачи.
В Confluence все есть "статья". Будь то запись в блоге (новость) или сама статья. При этом формат хранения является собственной разработкой. Это не xml, не html и не какой-нибудь JSON. Ближе всего он к html разметке с использованием web-компонент. По крайней мере именно подобное вы увидите если провалитесь в исходные данные.
<ac:layout><ac:layout-section ac:type="fixed-width" ac:breakout-mode="default"><ac:layout-cell><ac:structured-macro ac:name="tip" ac:schema-version="1" ac:macro-id="941154d1-9b1b-43d7-863e-75b961994e18"><ac:rich-text-body>
<p>Это домашняя страница стандартов разработки ПО на базе платформы 1С (версия 8.х) используемые в компании ПрогТехБизнес. </p></ac:rich-text-body></ac:structured-macro><ac:structured-macro ac:name="note" ac:schema-version="1" ac:macro-id="f6a1bfa7-4596-4345-8a98-7a765c04c895"><ac:rich-text-body>
<p>Все вопросы относительно разработки обсуждаются в канале #devs в Slack</p></ac:rich-text-body></ac:structured-macro>
Как вы понимаете, отобразить подобный формат у вас не получится. Ну или вам придется "нарыть" или написать собственные веб-компоненты для отображения данной статьи. Кроме веб-компонент есть еще и макросы, они определенным образом обрабатывают данные и выводят на экран в различном оформлении.
В общем, если хотите просто GET с сайта и ПолеHTML = Ответ.ПолучитьТелоКакСтроку() - то не выйдет ни разу
Но тем не менее, я решил не отступать, тем более некоторое время на опыты и изучения позволили мне найти решение проблемы. Сначала надо получить "сырые" данные в формате storage: view, потом через запрос POST в узлу convert получаете подготовленные данные.
Там были несколько подводных камней:
- конвертация данных
- вывод картинок для не анонимного доступа
- экспорт в PDF и Word
Конвертация данных
Для получения полноценных данных необходимо "подсказать" при конвертации раздел и родительскую статью. Тут два варианта: если вы не знаете их "до" обращения, то придется сначала вычислить. Впрочем, в моем случае, поскольку происходит пользовательская "навигация", программе прекрасно известно и раздел и родитель.
Но даже после конвертации данные не выглядят полностью идентично базе знаний, мне так и не удалось этого добиться. Как и у других (судя по "этим вашим интернетам"). И я могу понять почему так сделано, если бы внешне это было как на сайте, то часть аудитории confluence бы потерял.
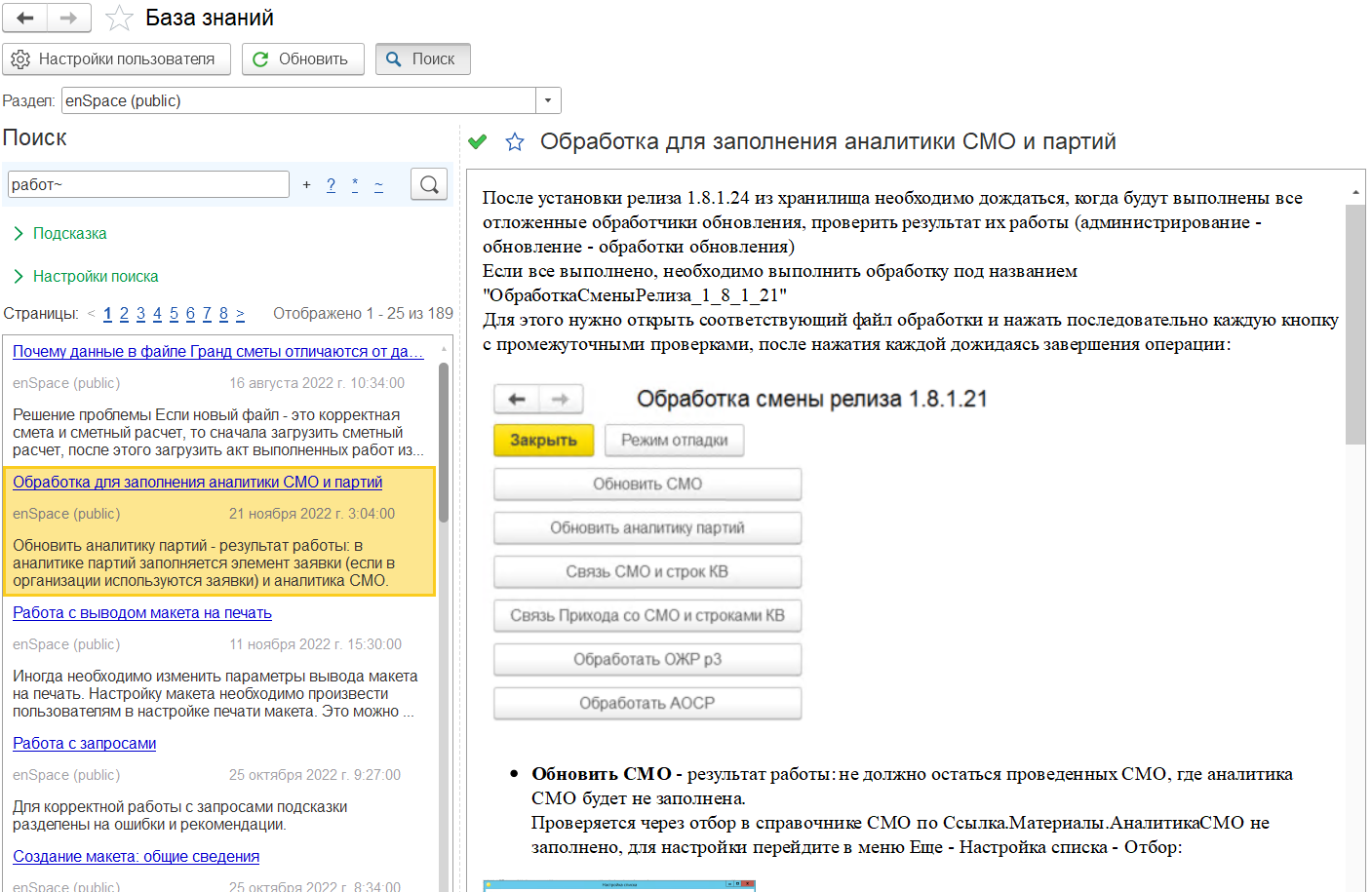
Вот пример картинки из базы знаний и потом из 1С


Основные отличия в форматировании. Конечно можно поиграть с css в самом файле и доработать его, чтобы например заголовки таблиц были оформлены, границы выставлены и т.д. Возможно со временем я до этого доберусь.
Тем не менее, для чтения этого более чем достаточно, а значит можно двигаться дальше...
Картинки
Файлы картинок хранятся отдельно от статей, это понятно. img src содержат адрес расположения картинки, а не двоичные данные. И это тоже верно, с целью уменьшения размера самой статьи, а картинки все браузеры умеют грузить хорошо, красиво, быстро, незаметно. Но тут есть подстава.
Если вы используете анонимный доступ, тогда (возможно) с картинками все будет хорошо, они отобразятся. Но, если вы используется логин пользователя + token ID (см. тут), то статья придет со ссылками на картинки, которые находятся в защищенной зоне. И в таком случае поле под картинку есть, а картинки нет.
Проблема решается следующим образом: после загрузки статьи, обработка разбирает html, вытаскивает адреса картинок и заменяет их на полученные публичные ссылки. В итоге пользователь сначала видит загруженный контент, а потом "подлетают" картинки.
Экспорт в PDF, Word
Штатно у Confluence есть такая возможность, а вот API не содержит данного функционала. HTML в 1С в PDF тоже сохранить не так просто, да и вообще конверторов html->pdf в мире не так много и каждый со своим приколом. А предлагать сохранять пользователям html+картинки не хотелось. Понятно что можно, но извините, а PDF удобнее. Да и к тому же, если в confluence настроить шрифты и локализацию при экспорте, результат выглядит очень красиво. И хотелось "как у них", а не "как получилось"... ну что же. Для начала сходим посмотрим, а как они делают.
- пользователь нажимает экспорт в PDF
- отображается окно ожидания подготовки файла
- когда все будет выполнено, появляется ссылка на скачивание
Гипотетически предполагаем, значит браузер инициирует выгрузку, получает данные о процессе, контролирует процесс и потом получает адрес ссылки. Видимо и мы можем попробовать это сделать...
Оговорюсь сразу, я не то чтобы все раскопал сам, я конечно рыл интернет и наткнулся на репозиторий парня, который сделал удобную обертку вокруг API для python (вот его репозиторий). В том числе и экспорт в PDF. Изучил его код, перепроверил все сам, доработал (на момент реализации, у него было несколько устаревшая реализация) и получилось.
Правда, недавно (месяц или около того) в запрос инициирования экспорта теперь необходимо передавать токен доступа, который хранится в cookie, так что надо сначала их получить, потом передать, в общем немного пришлось еще копнуть. Но лопата была недалеко, да и я находился в отпуске, и так хорошо между прогулками немного полезного закодить...
Ах да, экспорт в Word. Тут меня ждала халява, ссылка там формируется по шаблону и работает хорошо. Так что обошлось без танцев с бубном. Поэтому диплом магистра кафедры бубна всея-одинэс университета мне и не понадобился.
Расширение
Завернуть это все в расширение это уже дело техники. Оно построено на базе БСП и использует некоторые общие модули. Не работает в веб-клиенте, поскольку ждем реализации http объектов для веб-клиента. А таскать это все "сервер-клиент" мне пока не хотелось. Поэтому вы уж извините.
Что еще из хорошего есть в расширении:
- общие модули для реализации методов обертки вокруг API. Они пока не полные, редактирования там нет. Если будет интерес пишите, может договоримся. Мне пока нужды нет, а времени увы маловато;
- методы для поиска в базе знаний. Это я думаю может кому-то пригодится;
- ну может кому-то зайдет в качестве источника для обучения, ну вдруг кто не очень с этими всякими api. Код старался сделать получше.
Послесловие
Замечания и пожелания можно оставить на Github. Буду рад звездочкам и новым подписчикам. В моем репозитории есть и другие интересные (наверное) разработки. Тут уж кому что. В любом случае, заглядывайте, пишите, всегда рад конструктивной критике и правильным рекомендациям.
Скрины сняты с публичной части нашей базы знаний, с инструкций по нашему программному продукту для работы с исполнительной документация, сметами и всяким таким для строительных организаций. Если кому интересно, обращайтесь.
Техническая информация:
- платформа 8.3.21+ (используются методы Асинх)
- БСП 3.1.7 (допустимо все версии БСП 3.1+)
- режим совместимости расширения 8.3.12
Возможно понижение до 8.3.18+, но необходимо удалить использование Асинх методов HTTP-запросов (см. общий модуль confluence_ApiClientAsync и его вызов)
История изменений
- 1.0.4.1 от 20.06.25
- исправлены некоторые ошибки
- добавлена кнопка перехода по ссылке в браузер
- добавлена возможность сохранения вложений по двойному клику
- 1.0.3.1 от 18.10.23
- исправлены ошибки авторизации (по логин + токен ID)
- исправлена загрузка PDF страницы
- оптимизирована загрузка картинок для страниц без публичного доступа
- проведен рефакторинг кода
- ВАЖНО: требование к платформе 8.3.21 и выше
- 1.0.2.6 от 28.11.22
- исправлена ошибка чтения настроек при установленных ограничениях по статьям
- 1.0.2.5 от 26.11.22
- добавлена возможность экспорта пространств в XML и PDF
- добавлены новые методы в для работы с api: get_space_as_pdf, get_space_as_xml, get_page_labels
- исправлена ошибка чтения токена доступа пользователя
- исправлена ошибка экспорта статей в PDF для не анонимного доступа
- 1.0.2.4 первая публикация
Проверено на следующих конфигурациях и релизах:
- Бухгалтерия предприятия, редакция 3.0, релизы 3.0.176.38
Вступайте в нашу телеграмм-группу Инфостарт

{kind=link}