
В свое время мне пришлось решать следующую задачу: загрузить отчет комиссионера, состоящий из порядка 10 000 строк, предоставленный в электронном виде, в базу данных комитента (УТ 10.2). Проблема была в сопоставлении номенклатуры, так как кодов не было, а наименования не совпадали - вводились различными людьми в разных местах независимо, иногда с ошибками и по разным принципам.
Для хранения соответствий номенклатуры я добавил регистр сведений и решил заполнить его наиболее похожими позициями из справочника номенклатуры базы данных. Далее оператор должен только утвердить найденный автоматически вариант или выбрать другой, ориентируясь при этом по коэффициенту "похожести", сформированному при автоматическом подоборе номенклатуры.
Для решения этой задачи мне нужна была функция, которая позволит вычислить для заданного наименования товара из отчета коэффициенты "похожести" по всем позициям справочника номенклатуры, чтобы в качестве соответствия выбрать номенклатуру с наибольшим коэффициентом. Для возможности такого сравнения необходимо, чтобы функция выдавала результат сравнения из одинакового для любых входных строк диапазона (то есть оценка должна быть нормированной). Подходящей функции я тогда не нашел (одна из них не давала нормированной оценки, другая не понравилась мне алгоритмом - нужно было вводить количество символов в анализируемых комбинациях непонятно исходя из чего), но это меня даже обрадовало, так как задача показалась мне интересной и я решил написать собственную функцию на языке 1С. В скором времени функция была написана и с ее помощью задача была успешно решена.
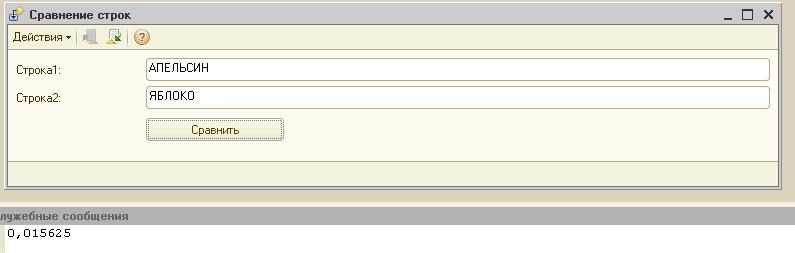
Результат представляю вашему вниманию - во вложении обработка с двумя полями ввода - Строка1 и Строка2 и кнопкой "Сравнить", результат - коэффициент похожести в диапазоне от 0 до 1 выводится в окно сообщений. Алгоритм чувствителен порядку следования символов в строках - 2 разных набора одних и тех же символов дадут в общем случае различные результаты сравнения.
Немного об особенностях реализации - сначала вычисляются автокорреляционные функции для каждой из строк, после чего бОльшая из вычисленных величин выбирается в качестве нормирующей. Далее вычисляется взаимная корреляция строк и нормируется вычисленной на предыдущем этапе величиной (путем деления результата на нее), что гарантирует нахождение определенного таким образом коэффициента в диапазоне от 0 до 1.
При вычислении исходные строки преобразуются в массивы, что позволит, если будет необходимо, легко перевести этот алгоритм на другие языки программирования. Недостатком данного алгоритма является относительно низкая скорость работы - за все приходится платить. Надеюсь, кому нибудь пригодится!
P.S.
Модуль СКБ Контур говорит автору спасибо - пожалуйста.
Готовое решение
ККТ-ОНЛАЙН 54-ФЗ: Обработка для работы онлайн касс АТОЛ, ШТРИХ, VIKI PRINT и т.д. МАРКИРОВКА (Разрешит. режим) + ЭКВАЙРИНГ + БЕСПЛАТНЫЙ ДЕМО
Универсальная обработка для фискальных регистраторов! Подключайте любые ККТ, включая Веб сервер АТОЛ, без обновления 1С и работайте с несколькими кассами одновременно. Тестовый доступ — бесплатно!
Вступайте в нашу телеграмм-группу Инфостарт

{kind=link}