



{kind=link}
Универсальный нагрузочный тест для баз данных 1С. Позволяет оценивать производительность работы в конкретной базе данных при подборе параметров сервера.
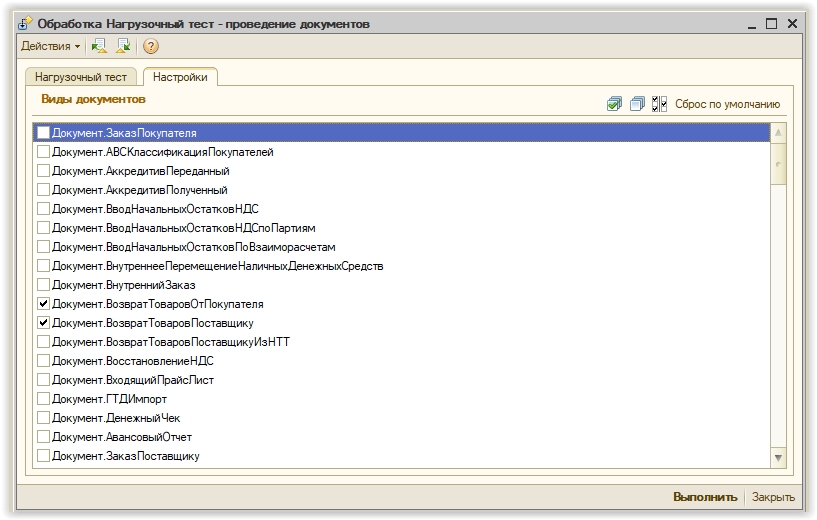
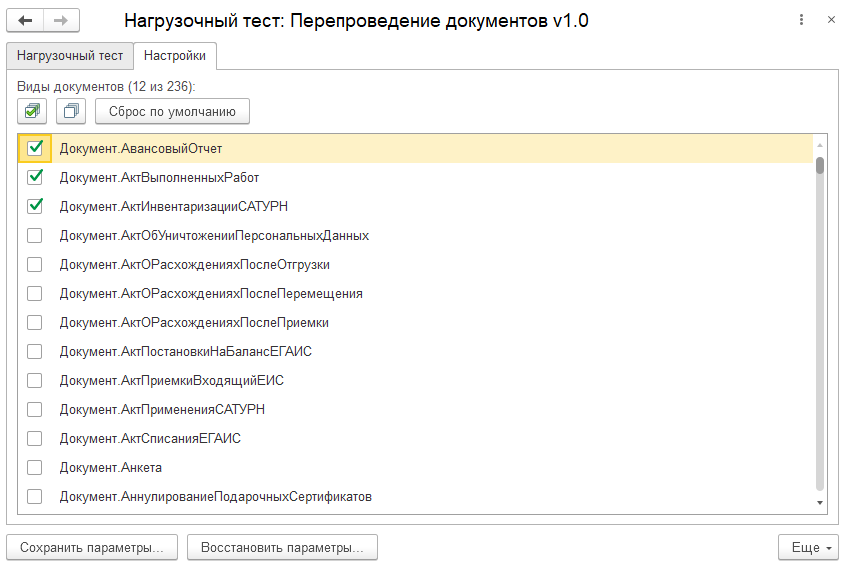
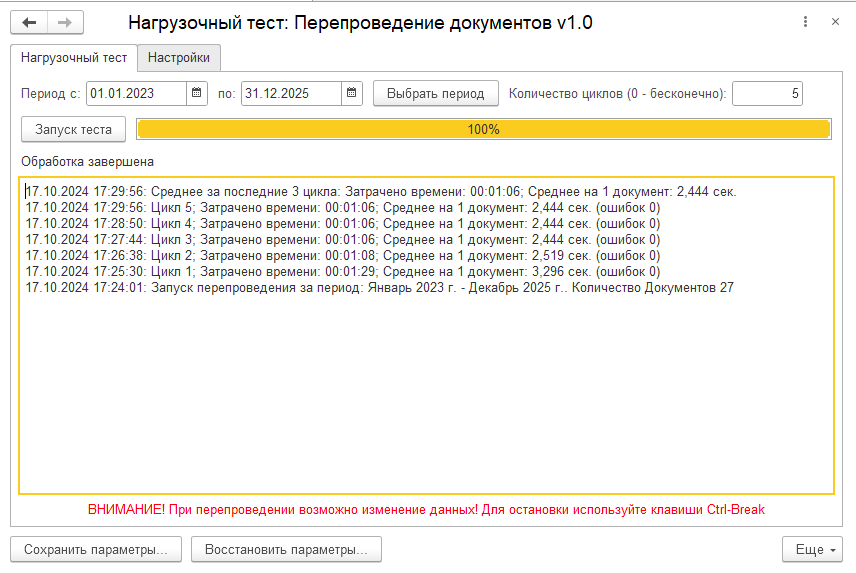
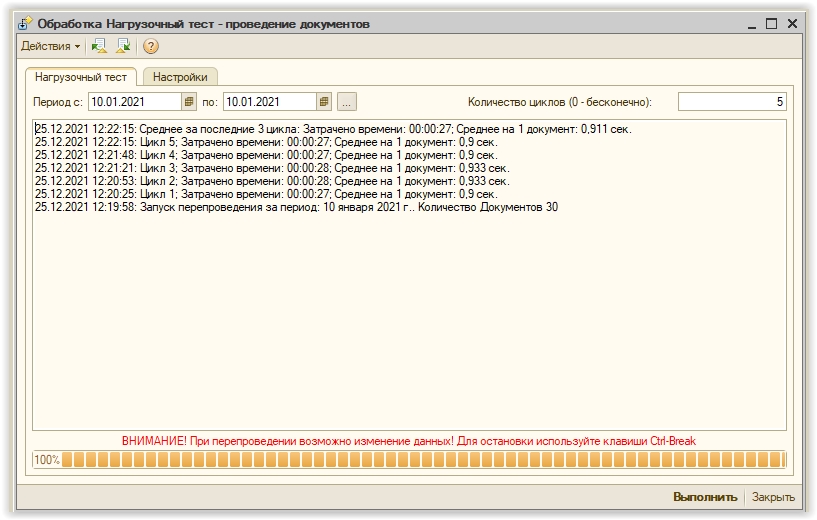
Тест производит циклическое перепроведение документов и замер скорости на каждом цикле. Выбирается интервал документов и виды документов для перепроведения. Можно задать определенное количество циклов или бесконечное тестирование до принудительной остановки.
При завершении тестирования выдается средний результат за три последних цикла.
Можно организовать стресс-тестирование сервера запустив непрерывный тест в нескольких базах данных. При работе оценить узкие места сервера. Например если будет малая загрузка процессора (меньше 50%), то это означает, что слабое место сервера - дисковая система или неоптимальные параметры СУБД.
Для работы теста требуется база данных, работающая на обычных или управляемых формах, например Управление Торговлей 11, в которой есть проведенные документы. Лучше использовать копию рабочей базы данных. Для сравнения производительности разных серверов, или например файловой и серверной баз данных, следует использовать идентичную базу данных, загруженную из одного и того же архива.
Внимание! Тест перепроводит существующие в базе данных документы! Возможно изменение данных! С осторожностью использовать в рабочих базах данных!
Протестировано на платформе версии 8.3.25.1374, конфигурация Управление Торговлей 11.5.17.143.
Проверено на следующих конфигурациях и релизах:
- Управление торговлей, редакция 10.3, релизы 10.3.88.3
- Управление торговлей, редакция 11, релизы 11.5.17.143
Вступайте в нашу телеграмм-группу Инфостарт