



{kind=link}
Буфер обмена Windows поддерживает несколько стандартных форматов данных. Например текст и точечные рисунки. Кроме того, приложение может зарегистрировать свой собственный формат и скорее всего 1С:Предприятие пользуется этой возможностью.
Давайте проверим это! Узнать, какие форматы в данный момент содержит буфер обмена, можно с помощью стандартной утилиты Windows 2k/XP clipbrd.exe
Запускаем утилиту и давим ctrl+c на любом объекте дерева метаданных в конфигураторе:

Что мы видим?
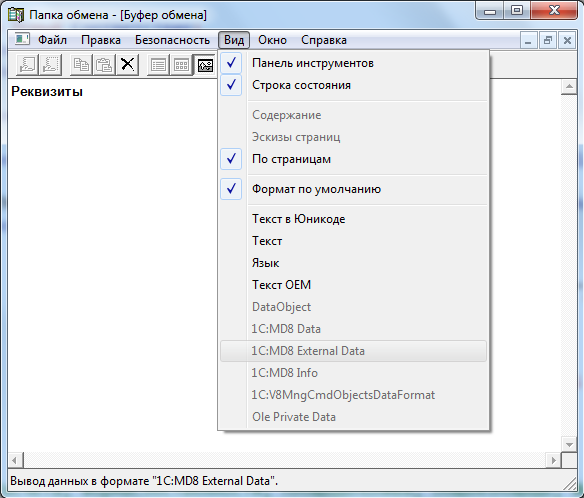
Я копировал реквизиты документа, и платформа поместила в буфер текст "Реквизиты". Кроме того, в меню "Вид" помимо стандартных форматов присутствуют 4 формата с префиксом "1С". Видимо это то что нам нужно :)
Плохо только, что эти форматы недоступны для просмотра. Что в общем логично, т.к. внутреннее их устройство "знает" только платформа 1С.
Чтобы увидеть содержимое нестандартных форматов нам понадобится более функциональная утилита. Например CLCL, которая умеет показывать неизвестные ей форматы в шестнадцатиричном виде. Скачать ее можно по этой ссылке: http://www.nakka.com/soft/clcl/index_rus.html
CLCL при запуске сворачивается в трей с иконкой в виде канцелярской скрепки. Открыть основное окно утилиты можно щелчком на этой скрепке.
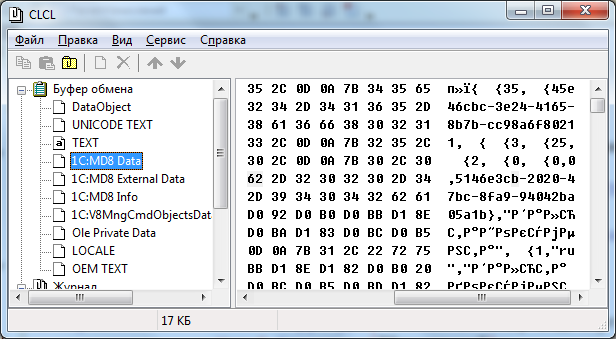
ОК. Что нам показывает CLCL?

Наиболее интересен формат "1C:MD8 Data". У него говорящее название и данных он содержит больше, чем все остальные форматы, вместе взятые. Внутри явно текст, только CLCL не знает кодировку. Щелкаем правой кнопкой мыши на подопытном формате, выбираем "сохранить как", и сохраняем в текстовый файл.

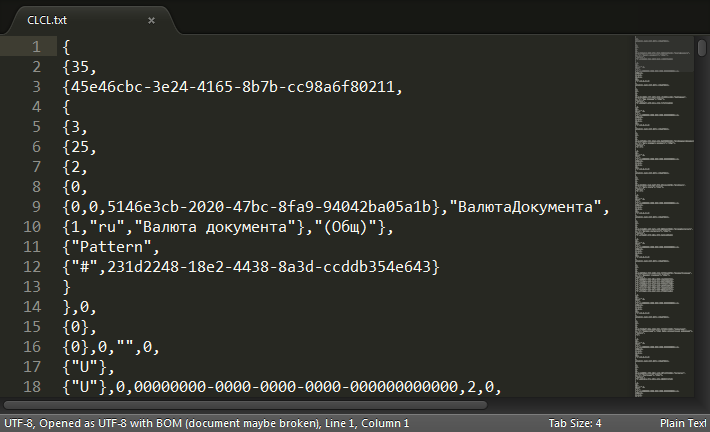
Открываем в любимом текстовом редакторе (на скрине Sublime Text 2) и видим, что это действительно текст. Кодировка "родная" для платформы 1С UTF-8 с маркером порядка байтов (BOM)
Итак, перед нами метаданные (в данном случае реквизиты документа). Судя по наличию фигурных скобочек можно догадаться, что это результат работы внутреннего сериализатора платформы 1С. Такой же формат возвращает метод глобального контекста ЗначениеВСтрокуВнутр.
Структура текста довольно простая. Это простой список внутри фигурных скобок. Элементы списка разделяются запятыми. В качестве элементов списка выступают: числа, строки в кавычках, UID'ы и вложенные списки.
Довольно легко можно написать парсер. Например так:
Функция РазобратьТекст(Источник) Экспорт
Дерево = Новый ДеревоЗначений;
Дерево.Колонки.Добавить("Значение");
ТекущаяСтрока = Дерево.Строки.Добавить();
ТекущаяСтрока = ТекущаяСтрока.Строки.Добавить();
ТекущийРодитель = ТекущаяСтрока.Родитель;
ИсходныйТекст = Источник.ПолучитьТекст();
КоличествоСимволов = СтрДлина(ИсходныйТекст);
ТекущийСимвол = "";
Позиция = 0;
Пока ТекущийСимвол <> "{" И Позиция < КоличествоСимволов Цикл
Позиция = Позиция + 1;
ТекущийСимвол = Сред(ИсходныйТекст, Позиция, 1);
КонецЦикла;
Если ТекущийСимвол = "{" Тогда
Буфер = "";
РежимЧтенияСтроки = Ложь;
Пока Позиция < КоличествоСимволов Цикл
Позиция = Позиция + 1;
ТекущийСимвол = Сред(ИсходныйТекст, Позиция, 1);
Если НЕ РежимЧтенияСтроки И ТекущийСимвол = "{" Тогда
ТекущийРодитель = ТекущаяСтрока; ТекущийРодитель.Значение = "{...}";
ТекущаяСтрока = ТекущаяСтрока.Строки.Добавить();
ИначеЕсли НЕ РежимЧтенияСтроки И ТекущийСимвол = "," Тогда
Если Буфер <> "" Тогда
ТекущаяСтрока.Значение = Буфер;
Буфер = "";
КонецЕсли;
ТекущаяСтрока = ТекущийРодитель.Строки.Добавить();
ИначеЕсли НЕ РежимЧтенияСтроки И ТекущийСимвол = "}" Тогда
Если Буфер <> "" Тогда
ТекущаяСтрока.Значение = Буфер;
Буфер = "";
КонецЕсли;
ТекущаяСтрока = ТекущийРодитель;
ТекущийРодитель = ТекущаяСтрока.Родитель;
ИначеЕсли ТекущийСимвол = """" Тогда
РежимЧтенияСтроки = НЕ РежимЧтенияСтроки;
Буфер = Буфер + ТекущийСимвол;
ИначеЕсли РежимЧтенияСтроки Тогда
Буфер = Буфер + ТекущийСимвол;
ИначеЕсли НЕ ПустаяСтрока(ТекущийСимвол)
ИЛИ (ТекущийСимвол = " ") Тогда
Буфер = Буфер + ТекущийСимвол;
КонецЕсли;
КонецЦикла;
КонецЕсли;
Возврат Дерево;
КонецФункции

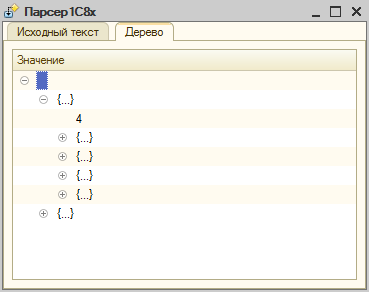
Теперь у нас есть возможность "пощупать" структуру файла :)
На скрине видно, что корневой список содержит два вложенных списка. В первом из них хранится количество (первый элемент) и список реквизитов. Каждый реквизит предсталяет из себя структуру свойств. Т.е. все свойства реквизита, которые можно изменить в конфигураторе. Расположение свойств в структуре можно выяснить простым сравнением файлов до и после изменения этих самых свойств.
Пришло время воспользоваться нашими знаниями!
Мы сделаем утилиту в виде скрипта, которая будет вытаскивать имена реквизитов из метаданных в буфере обмена и помещать их обратно уже в виде простого текста.
Писать скрипт будем на языке Lua
Скачать дистрибутив для Windows можно по этой ссылке: http://code.google.com/p/luaforwindows/downloads/list
Кроме того нам нужна библиотека для работы с буфером обмена: http://files.luaforge.net/releases/jaslatrix/clipboard/1.0.0
(установить можно простым копированием clipboard.dll в каталог "...\Lua\5.1\clibs\")
Язык Lua был выбран не просто так. Дело в том, что в Lua основным типом данных является хэш-таблица (в 1С аналогом является соответствие), которая имеет очень похожий на нашу структуру конструктор. Выглядит это так:
tbl = {1, 2, "three", {4, 5}}
Таблицу можно обойти циклом:
for key, value in pairs(tbl) do
print(key, value)
end
Проверить, как работает этот код, можно с помощью онлайн интерпретатора: http://repl.it/Emn/1
На языке 1С это выглядело бы так:
Таблица = Новый Соответствие;
Таблица[1] = 1;
Таблица[2] = 2;
Таблица[3] = "three";
Таблица[4] = Новый Соответствие;
Таблица[4][1] = 4;
Таблица[4][2] = 5;
Для Каждого Элемент Из Таблица Цикл
Сообщить("" + Элемент.Ключ + " " + Элемент.Значение);
КонецЦикла;
Т.е. Lua автоматически назначает целочисленные ключи, начиная с единицы. Таким образом, луашная таблица может эмулировать массив (настоящих массивов в Lua нет). Ключи можно и явно указывать, но нам сейчас это не нужно. Интересующиеся могут почитать документацию: http://www.lua.ru/doc/
Итак, давайте для начала вытащим из буфера обмена текст в формате 1С:MD8 Data
require'clipboard'-- подключаем библиотеку
format={}-- создаем пустую таблицу для хранения соответствия [ИмяФормата - КодФормата]
for k,v in ipairs(clipboard.getformats()or{})do
formatname = clipboard.formatname(v)
if formatname then
format[formatname]= v
end
end
data = clipboard.getdata(format["1C:MD8 Data"]) -- получаем данные
if data then
print(data)
end

Теперь нужно заставить Lua работать с этими данными как с родной хэш-таблицей. В этом деле нам поможет одна луашная фича. У нас есть возможность динамически загрузить функцию из строки содержащей луашный код. Например так:
f = loadstring("i = i + 1") -- получаем функцию
i = 0
f(); print(i) --> выводит 1
f(); print(i) --> выводит 2
Чтобы функция возвращала значение, нужно добавить return:
f = loadstring("return i + 1") -- получаем функцию возвращающую значение
i = 0
i = f(); print(i) --> выводит 1
i = f(); print(i) --> выводит 2
Также функция может создать и вернуть таблицу:
f = loadstring("return {1, 2, 'three', {4, 5}}")
tbl = f()
for key, value in pairs(tbl) do
print(key, value)
end
Думаю, вы уже догадались что мы будем делать :)
f = loadstring("return"..data) -- прим.: две точки означают конкатенацию строк
tbl = f()
Но это не будет работать... :(
Lua не понимает UID'ы в тексте и кроме того она не знает UTF-8. К счастью, обе проблемы легко победить. Все UID'ы в тексте можно найти с помощью регулярного выражения и заменить на пустые таблицы {} например.
А кодировка UTF-8 по большому счету вообще не проблема, т.к. все важные для разбора символы кодируются в ней одним байтом и не отличаются от таковых в ASCII. Нам будет мешать только маркер порядка байтов (BOM), но мы можем просто проигнорировать первые три байта:
s = "123456"
print(s:sub(4)) --> 456
Когда мы наконец получим метаданные в виде луашной таблицы, можно будет обращаться к любому элементу примерно так:
print(tbl[1][2][2][1][2][2][2][3])
Этот код выведет на экран имя первого реквизита.
Чтобы узнать "адрес" нужного вам элемента, можете воспользоваться этим принтером таблиц:
function print_r (t, indent, done)
done = done or {}
indent = indent or ''
local nextIndent -- Storage for next indentation value
for key, value in pairs (t) do
if type (value) == "table" and not done[value] then
nextIndent = nextIndent or
(indent .. string.rep(' ',string.len(tostring(key))+2)) -- Shortcut conditional allocation
done[value] = true
print(indent .. "[" .. tostring(key) .. "] => Table");
print_r(value, nextIndent .. string.rep(' ',2), done)
else
print(indent .. "[" .. tostring (key) .. "] => " .. tostring(value).."")
end
end
end
Эта функция выводит таблицу в таком виде (жирным выделен путь к имени первого реквизита):
и т.д.
Ну вот и все :) Готовый к использованию скрипт приложен к данной публикации.

Надеюсь, было интересно 
Публикация смежной тематики: Создание табличных частей объектов конфигурации
Вступайте в нашу телеграмм-группу Инфостарт