





Обратимся к документации по платформе. В самом начале главы, посвященной анализу данных и прогнозированию, авторы прямо и без обиняков говорят нам, что не будут ничего говорить нам о способах использования того, что они описывают. И это, на мой взгляд, и есть первая и едва ли не основная причина того, что объект "АнализДанных" до сих пор применяется далеко не так активно, как он того заслуживает. Все-таки Data science по общему признанию является сплавом трех компонент: статистики, программирования и коммуникации. И без последней невозможно получить хоть какой-то результат.
Сейчас в арсенале специалиста по DS(data science) и ML(machine learning) есть довольно много различных средств и технологий. Что-то из этого есть в платформе 1С, чего-то нет. Но мы начнем знакомство со всем этим с одной проверенной и заслуженной технологии, которую коротко называют "регрессией".
В платформе 1С для всех возможных типов анализа используется один и тот же объект "АнализДанных". Регрессии в этом объекте соответствует тип анализа "Дерево решений".
Анализ=новый АнализДанных;
Анализ.ТипАнализа=Тип("АнализДанныхДеревоРешений");
Рассказывать, как работает регрессия, я буду на примере, который должен быть близок всем. Почти каждому из нас (прямо или косвенно, через родственников, друзей, знакомых) приходилось иметь дело с арендой или покупкой недвижимости. И, соответственно, так или иначе приходилось решать вопрос оценки. Мы будем использовать регрессию для того, чтобы не ломать голову, а получать оценку на научной основе. К тому же, вам по любому не будет жаль потраченного на чтение статьи времени. В конце вы получите на руки инструмент, который вам наверняка пригодится в будущем.
Учебные данные я взял на законной основе с Kaggle. Это одна их наиболее известных "тусовок" специалистов по DS и ML, с некоторых пор под эгидой Google. Это данные о реальных сделках по покупке-продаже недвижимости. Хороши они еще и тем, что достаточно детальны. Вы можете увидеть это на иллюстрации.
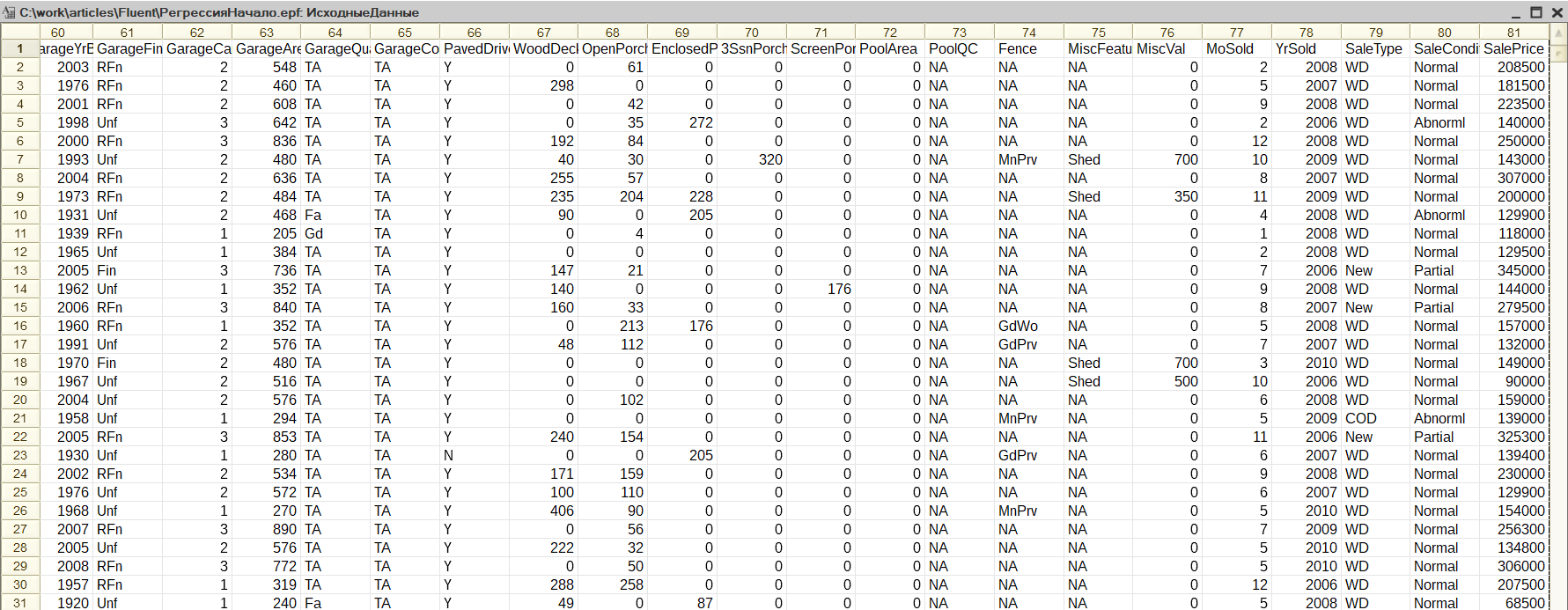
Прежде, чем обращаться к методам объекта "АнализДанных", не помешает разобраться как это работает в принципе. Математика тут совсем простая, если не сказать примитивная. Тем более должно быть удивительным - что из этой простоты можно получить. Вообще описаний метода регрессионного анализа существует чуть ли не миллион. Для разных людей подойдут разные. Я же попробую дать описание, подходящее для программистов. Такое, после которого вы могли бы сказать себе: ага! ну этот алгоритм я мог бы быстренько написать. Давайте снова взглянем на данные. Что вообще можно с ними с делать? Так прямо в лоб? Можно взять среднее значение цены продажи. Тоже ведь метод оценки. Да, не очень точный. Но насколько неточный? Как сильно мы будем промахиваться "в среднем", если воспользуемся этим методом? Чтобы понять это, нам надо рассчитать что-то типа среднего отклонения. Для каждой строки таблицы получим разность цены и средней цены. Просуммируем, а затем разделим на количество строк. Если суммировать не просто разности, а квадраты разностей, и потом извлекать квадратный корень, получим так называемое "стандартное отклонение". Оно и будет у нас мерой точности. Как ее можно повысить? Очень просто. Сгруппируем записи исходной таблицы по значениям какой-нибудь очевидно значимой колонки, например, "количество комнат". Что произойдет со стандартным отклонением внутри каждой из групп? Интуиция подсказывает нам, что стандартное отклонение должно уменьшиться. И так оно и есть! Теперь, я надеюсь, понятно что надо делать. Сгруппируем исходную таблицу по каждой из колонок отдельно. Рассчитаем уменьшение (регрессию) стандартного отклонения для каждого случая и выберем самый лучший. А далее будем повторять этот процесс рекурсивно внутри каждой группы записей. В результате получим иерархическую структуру или дерево решений. Узлами этого дерева будут значения группировок, а в листьях будет то, что мы ищем. В нашем случае, это будет предполагаемая цена объекта недвижимости.
Чтобы построить дерево решений в 1С, надо сделать следующее:
Анализ=новый АнализДанных;
Анализ.ТипАнализа=Тип("АнализДанныхДеревоРешений");
Анализ.ИсточникДанных=ТЗМодель;
Анализ.Параметры.ТипУпрощения.Значение=ТипУпрощенияДереваРешений.НеУпрощать;
РДерево=Анализ.Выполнить();
А для того, чтобы получить расчет предполагаемых цен, надо сделать вот это:
Прогноз=РДерево.СоздатьМодельПрогноза();
Прогноз.ИсточникДанных=ТЗПрогноз;
Результат=Прогноз.Выполнить();
Как видно, все сводится к тому, чтобы задать источники данных для модели и для прогноза. Учебные данные я сохранил в макет внешней обработки. И хотя объект "АнализДанных" допускает табличный документ (а также и результат запроса) в качестве источника данных, я все же буду использовать таблицу значений. Причины этого будут понятны ниже.
//получение данных
Макет=РеквизитФормыВЗначение("Объект").ПолучитьМакет("ИсходныеДанные");
ТЗМодель=новый ТаблицаЗначений;
ТЗМодель.Колонки.Добавить("ПлощадьУчастка");
ТЗМодель.Колонки.Добавить("ГодПостройки");
ТЗМодель.Колонки.Добавить("Площадь1этажа");
ТЗМодель.Колонки.Добавить("Площадь2этажа");
ТЗМодель.Колонки.Добавить("КоличествоПолныхСанузлов");
ТЗМодель.Колонки.Добавить("КоличествоСпален");
ТЗМодель.Колонки.Добавить("КоличествоКомнат");
ТЗМодель.Колонки.Добавить("Цена");
ТЗПрогноз=ТЗМодель.Скопировать();
для й=2 по Макет.ВысотаТаблицы цикл
нстр=ТЗМодель.Добавить();
нстр.ПлощадьУчастка=число(Макет.Область(й,5).Текст);
нстр.ГодПостройки=число(Макет.Область(й,20).Текст);
нстр.Площадь1этажа=число(Макет.Область(й,44).Текст);
нстр.Площадь2этажа=число(Макет.Область(й,45).Текст);
нстр.КоличествоПолныхСанузлов=число(Макет.Область(й,50).Текст);
нстр.КоличествоСпален=число(Макет.Область(й,52).Текст);
нстр.КоличествоКомнат=число(Макет.Область(й,55).Текст);
нстр.Цена=число(Макет.Область(й,81).Текст);
если й<11 тогда
нстрпрогноз=ТЗПрогноз.Добавить();
ЗаполнитьЗначенияСвойств(нстрпрогноз,нстр);
конецесли;
конеццикла;
//подготовка
Анализ=новый АнализДанных;
Анализ.ТипАнализа=Тип("АнализДанныхДеревоРешений");
Анализ.ИсточникДанных=ТЗМодель;
Анализ.Параметры.ТипУпрощения.Значение=ТипУпрощенияДереваРешений.НеУпрощать;
РДерево=Анализ.Выполнить();
//прогноз
Прогноз=РДерево.СоздатьМодельПрогноза();
Прогноз.ИсточникДанных=ТЗПрогноз;
Результат=Прогноз.Выполнить();
//визуализация
ТабДок.Очистить();
ТабДок.УстановитьРастягиваниеПоГоризонтали(Истина);
для й=1 по Результат.Колонки.Количество()-1 цикл
ТабДок.Область(1,й).Текст=Результат.Колонки[й-1].Имя;
ТабДок.Область(1,й).Шрифт=Новый Шрифт(ТабДок.Область(1,й).Шрифт, ,, Истина);
конеццикла;
для й=1 по Результат.Количество() цикл
для ы=1 по Результат.Колонки.Количество()-1 цикл
ТабДок.Область(й+1,ы).Текст=строка(Результат[й-1][ы-1]);
конеццикла;
конеццикла;
По умолчанию платформа считает, что получать прогноз нужно для самой последней колонки, а группировать по всем прочим. Для построения модели я взял все строки исходных данных и 7 колонок. Для проверки работы прогноза - первые десять строк. И вот что получилось:

Потрясающая точность прогноза! Но, я думаю, все уже догадались - в чем здесь "секрет". Я проверяю работу модели на тех же данных, которые использовались для ее построения. Конечно же это неправильно. Разобьем исходные данные на две части. Первую используем для построения модели, а вторую для поверки точности прогноза. Чтобы точно не зависеть от того, в каком порядке данные попадали в подборку, воспользуемся генератором случайных чисел.
Макет=РеквизитФормыВЗначение("Объект").ПолучитьМакет("ИсходныеДанные");
ТЗМодель=новый ТаблицаЗначений;
ТЗМодель.Колонки.Добавить("ПлощадьУчастка");
ТЗМодель.Колонки.Добавить("ГодПостройки");
ТЗМодель.Колонки.Добавить("Площадь1этажа");
ТЗМодель.Колонки.Добавить("Площадь2этажа");
ТЗМодель.Колонки.Добавить("КоличествоПолныхСанузлов");
ТЗМодель.Колонки.Добавить("КоличествоСпален");
ТЗМодель.Колонки.Добавить("КоличествоКомнат");
ТЗМодель.Колонки.Добавить("Цена");
ТЗПрогноз=ТЗМодель.Скопировать();
МодельСтроки=новый массив;
ГСЧ=новый ГенераторСлучайныхЧисел(1969);
й=0;
пока й<цел(Макет.ВысотаТаблицы/2) цикл
сч=ГСЧ.СлучайноеЧисло(2,Макет.ВысотаТаблицы);
если МодельСтроки.Найти(сч)=неопределено тогда
МодельСтроки.Добавить(сч);
й=й+1;
конецесли;
конеццикла;
для й=2 по Макет.ВысотаТаблицы цикл
если МодельСтроки.Найти(й)=неопределено тогда
нстр=ТЗПрогноз.Добавить();
иначе
нстр=ТЗМодель.Добавить();
конецесли;
нстр.ПлощадьУчастка=число(Макет.Область(й,5).Текст);
нстр.ГодПостройки=число(Макет.Область(й,20).Текст);
нстр.Площадь1этажа=число(Макет.Область(й,44).Текст);
нстр.Площадь2этажа=число(Макет.Область(й,45).Текст);
нстр.КоличествоПолныхСанузлов=число(Макет.Область(й,50).Текст);
нстр.КоличествоСпален=число(Макет.Область(й,52).Текст);
нстр.КоличествоКомнат=число(Макет.Область(й,55).Текст);
нстр.Цена=число(Макет.Область(й,81).Текст);
конеццикла;
//Подготовка
Анализ=новый АнализДанных;
Анализ.ТипАнализа=Тип("АнализДанныхДеревоРешений");
Анализ.ИсточникДанных=ТЗМодель;
Анализ.Параметры.ТипУпрощения.Значение=ТипУпрощенияДереваРешений.НеУпрощать;
Анализ.Параметры.МинимальноеКоличествоСлучаев.Значение=0;
РДерево=Анализ.Выполнить();
//Прогноз
Прогноз=РДерево.СоздатьМодельПрогноза();
Прогноз.ИсточникДанных=ТЗПрогноз;
Результат=Прогноз.Выполнить();
//Визуализация
ТабДок.Очистить();
ТабДок.УстановитьРастягиваниеПоГоризонтали(Истина);
для й=1 по Результат.Колонки.Количество()-1 цикл
ТабДок.Область(1,й).Текст=Результат.Колонки[й-1].Имя;
ТабДок.Область(1,й).Шрифт=Новый Шрифт(ТабДок.Область(1,й).Шрифт, ,, Истина);
конеццикла;
для й=1 по Результат.Количество() цикл
для ы=1 по Результат.Колонки.Количество()-1 цикл
ТабДок.Область(й+1,ы).Текст=строка(Результат[й-1][ы-1]);
конеццикла;
конеццикла;
Теперь картина гораздо ближе к реальной.
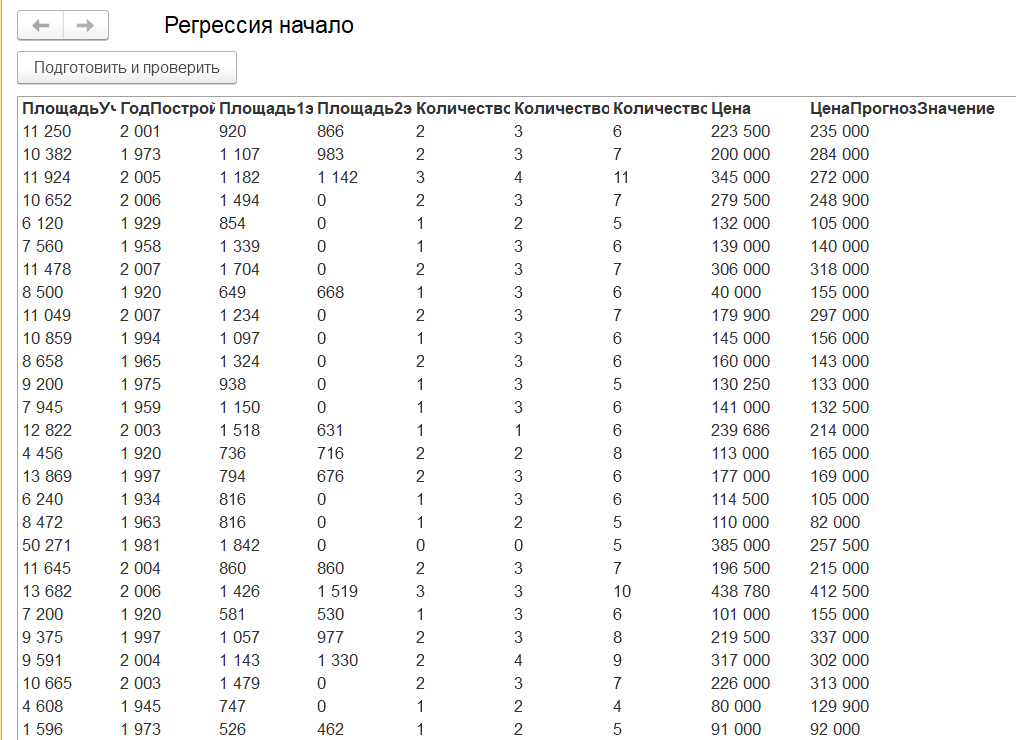
Где-то прогноз довольно точен. Где-то не очень. Для того, чтобы увидеть насколько точен прогноз вообще, вычисляют так называемую Среднюю абсолютную ошибку (Mean absolute error MAE).
СуммаОшибок=0;
для каждого стр из Результат цикл
СуммаОшибок=СуммаОшибок+макс(стр.Цена-стр.ЦенаПрогнозЗначение,стр.ЦенаПрогнозЗначение-стр.Цена);
конеццикла;
СредняяАбсолютнаяОшибка=СуммаОшибок/Результат.количество();
В нашем случае средняя абсолютная ошибка будет вот такой
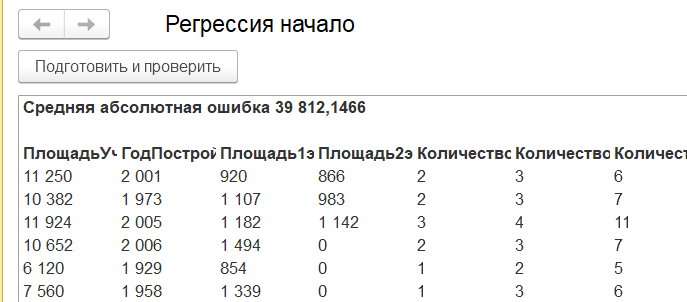
Вот тут-то многие и ломаются. Пробовали мы этот ваш мэшин ленинг, не работает вообще! Действительно, оценка с разбросом в 40 тысяч вряд ли кого-то устроит. Прежде чем перейти к ответу на вопрос: что с этим делать, разберем один момент. Заглянем "под капот" объекта "АнализДанных".
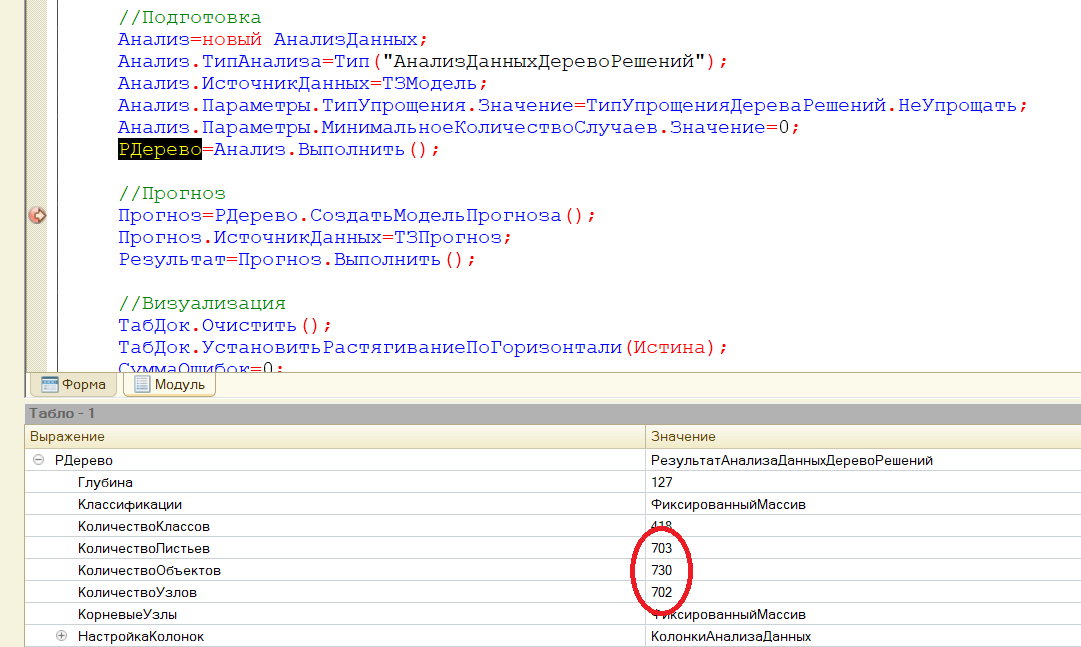
Мы видим, что на 730 исходных строк получено 703 листа в дереве решений. Т.е. большинство групп состоит ровно из одного элемента. Какое будет стандартное отклонение в случае 1 элемента? Самое лучшее, круглый 0. Только это так не работает. Как и вообще везде в статистике, нам нужно иметь не один и не два и даже не десять случаев, чтобы оперировать средними значениями. Другими словами нельзя давать оценку на основании одного уникального случая. Наше дерево решений получилось чересчур подробным, или "переученным" (overfitting). Это надо исправить. Те, кто повнимательнее, могли заметить что у меня появился еще один параметр.
Анализ.Параметры.МинимальноеКоличествоСлучаев.Значение=0;
В этом параметре мы можем задать минимальный размер группы и, таким образом, избежать "переучивания". По умолчанию там стоит 0, т.е "не задано". На практике это приводит к тому, что дерево строится что называется "до упора". Не спешите пенять на на разработчиков платформы. Они все сделали правильно. Дело в том, что не существует никакой формулы, по которой можно было бы вычислить оптимальный минимум в каждом конкретном случае. Если бы такая формула была, то самого Data science не было бы, а был бы еще один раздел математики. В математике доказали теорему Пифагора, и все. Бери любой треугольник и все будет строго по этой формуле. А в Data science все не так. Тут нет доказательств, а есть только "работает" или "не работает". Прогноз совпадает с реальностью? Вот вам и доказательство. Поэтому, берешь и делаешь цикл с перебором различных вариантов, с целью выбрать лучший. "Ты ж программист" )))
//Подготовка
Анализ=новый АнализДанных;
Анализ.ТипАнализа=Тип("АнализДанныхДеревоРешений");
Анализ.ИсточникДанных=ТЗМодель;
Анализ.Параметры.ТипУпрощения.Значение=ТипУпрощенияДереваРешений.НеУпрощать;
МинСредняяАбсолютнаяОшибка=99999;
ЛучшийРазмер=0;
для й=1 по 10 цикл
Анализ.Параметры.МинимальноеКоличествоСлучаев.Значение=50+й*10;
РДерево=Анализ.Выполнить();
//Прогноз
Прогноз=РДерево.СоздатьМодельПрогноза();
Прогноз.ИсточникДанных=ТЗПрогноз;
Результат=Прогноз.Выполнить();
//Визуализация
ТабДок.Очистить();
ТабДок.УстановитьРастягиваниеПоГоризонтали(Истина);
СуммаОшибок=0;
для каждого стр из Результат цикл
СуммаОшибок=СуммаОшибок+макс(стр.Цена-стр.ЦенаПрогнозЗначение,стр.ЦенаПрогнозЗначение-стр.Цена);
конеццикла;
СредняяАбсолютнаяОшибка=окр(СуммаОшибок/Результат.количество(),4);
если СредняяАбсолютнаяОшибка<МинСредняяАбсолютнаяОшибка тогда
МинСредняяАбсолютнаяОшибка=СредняяАбсолютнаяОшибка;
ЛучшийРазмер=50+й*10;
конецесли;
конеццикла;
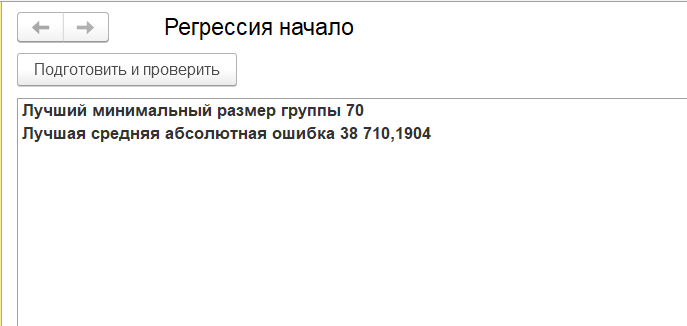
ТабДок.Область(1,1).Текст="Лучший минимальный размер группы "+строка(ЛучшийРазмер);
ТабДок.Область(1,1).Шрифт=Новый Шрифт(ТабДок.Область(1,1).Шрифт,,,Истина);
ТабДок.Область(2,1).Текст="Лучшая средняя абсолютная ошибка "+строка(МинСредняяАбсолютнаяОшибка);
ТабДок.Область(2,1).Шрифт=Новый Шрифт(ТабДок.Область(1,1).Шрифт,,,Истина);
В результате получим
Можно сказать, что наше достижение совсем небольшое. Но это всего лишь один из множества моментов, и он работает! Существует большое количество способов улучшения модели. Один из самых очевидных: можно добавить к нашим 7 колонкам еще парочку. Поглядеть вдумчиво на список колонок и выбрать самые подходящие. Есть, конечно, и другой путь. Повыбирать 9 колонок из 80 всеми возможными способами. Следует только учесть, что в этом случае у нас будет больше 200 миллиардов итераций. В общем, чтобы решать задачи в области Data science нужно иметь или очень хорошую интуицию или очень мощную вычислительную технику. А зачастую требуется и то, и другое. Впрочем, наша задача считается совсем несложной. И вы можете сами попробовать добиться хороших результатов. На учебных данных, которые использовал я, или на своих собственных.
В приложении обработка с учебными данными.
Обработка тестировалась на управляемых формах. Платформа 8.3.19.1467. Код обработки полностью открыт.
Вступайте в нашу телеграмм-группу Инфостарт