
Вводные условия
Работая в высоконагруженных базах, я часто встречался с таким феноменом: когда возникают проблемы производительности быстро решить их с использованием стандартных средств практически невозможно или крайне неудобно. Это обусловлено следующими причинами: все данные о проблемах разрознены, а чтобы выявить реальный источник нужно анализировать их во-взаимосвязи. На данный момент я имею на вооружении следующие источники данных и инструменты:
- Запрос по TOP текущих выполняющихся запросов PostgreSQL (я работал в основном с этой СУБД последние 10 лет), отсортированных по времени выполнения в обратном порядке. Там же используется функция определения блокирующих процессов. Его приблизительный вид такой (можно запускать с отбором без автовакуума):
SELECT pg_stat_activity.datname, NOW() - query_start AS duration, query_start, pg_stat_activity.pid, pg_blocking_pids(pg_stat_activity.pid) as blocked_by, query, state, wait_event_type, wait_event, pg_stat_activity.backend_start FROM pg_stat_activity left join pg_stat_progress_vacuum on pg_stat_activity.pid = pg_stat_progress_vacuum.pid where COALESCE(state, '') <> 'idle' --and not query like 'autovacuum%' --and query_start is not null ORDER BY duration DESC, query; - Консоль администрирования 1С: Предприятия. Главным ее недостатком является неудобство интерфейса: данные не обновляются, ручное обновление крайне неудобно (надо кликать несколько раз мышью, а не горячей клавишей), зависимые данные - а именно блокирующие соединения из сеансов вынуждают переключаться в соединения, что в часы высокой нагрузки могут приводить к зависанию. Есть pid СУБД, но какой запрос выполняется по этому pid не отображается, а чтобы понять необходимо обращаться к запросу TOP из п.1 (см. выше)
- Консоль заданий от ИР (ToromzIT - шикарнейшей подсистемы, не нуждающейся здесь в рекламе). При выставленных настройках - отключенные успешные задания и без отбора по методу регламентного список фоновых отображает активные фоновые задания и ошибки, что часто дает понять: происходят какие то проблемы! А иногда понять, кто является причиной
- Техно журнал 1С и замечательная обработка от Анализ техножурнала ИР от того же ToromzIT. Тут я смотрю наиболее тяжелые запросы, блокировки и в каких местах программы они происходят с точностью до строки кода (но часто это оказываются довольно очевидные проведения документов и программные блокировки тяжелых объектов, что не дает понять истинную причину замедлений)
- Анализ метрик в Zabbix, как общих по нагрузке на диск / процессор /память, так и специфических от Mamonsu именно по PostgreSQL (самые важные на данный момент в моем понимании - это активность автовакуума, а так же попадание в буфер кэша). Но это как правило “посмертный анализ” и на принятие экстренного решения не сильно оказывает влияние
- Также раньше использовал pgBadger - анализатор логов PostgreSQL на Perl, достаточно красиво предоставляющий отчет о проблемах с БД, а также самые тяжелые запросы. При этом удобно "бить" логи сервера по дням (циклически на 1 неделю). В связи с настройкой Zabbiх на предприятии актуальность немного упала. Также наиболее нагруженные запросы за последнее время можно получить из представления pg_stat_statements, но здесь я не буду приводить ее описание, так как это источник данных, а анализ строится с помощью различных запросов, тема, которая выходит за пределы этой статьи.
- Из важных инструментов, которые используются при борьбе с “тормозами” был анализатор планов запросов от компании Тензор - он помогает понять причину и тюнинговать тяжелые запросы, являющиеся узкими местами, если их удавалось обнаружить при помощи предыдущих инструментов. Да PostgreSQL ведет себя несколько иначе, чем MS SQL, и надо учитывать эти особенности. И планы запросов, представленные в удобном виде иногда помогают понять, как переписать запрос или добавить недостающий индекс.
Весь этот набор инструментов невозможно применить в кратчайшие сроки, если наступает “беда” в час пик. Во-первых, их можно применять только последовательно, на каждый уходит какое-то заметное время, а проблема не терпит - предприятие или задерживает отгрузку товара из-за медленной работы, или вообще стоит, счет идет на минуты. Во-вторых про часть из них в экстремальной ситуации вообще можно не вспомнить.
Решение
Поэтому я озадачился о том, чтобы иметь в арсенале какой-то инструмент с одной стороны достаточно простой в использовании, с другой достаточный для решения 95% всех проблем с производительностью. Больше всего недоволен я был консолью администрирования 1С. Она, по идее, должна была давать самую ценную информацию - о сеансах пользователей 1С, т.е. по ней точнее всего можно в онлайне понять, где проблема именно в системе 1С, в каком именно пользователе или процессе. Это отличает ее от других инструментов, где нужно идти "снизу вверх" от проблем в SQL или системных показателей, которые не привязаны ни к пользователю ни к бизнес-процессам в 1С.
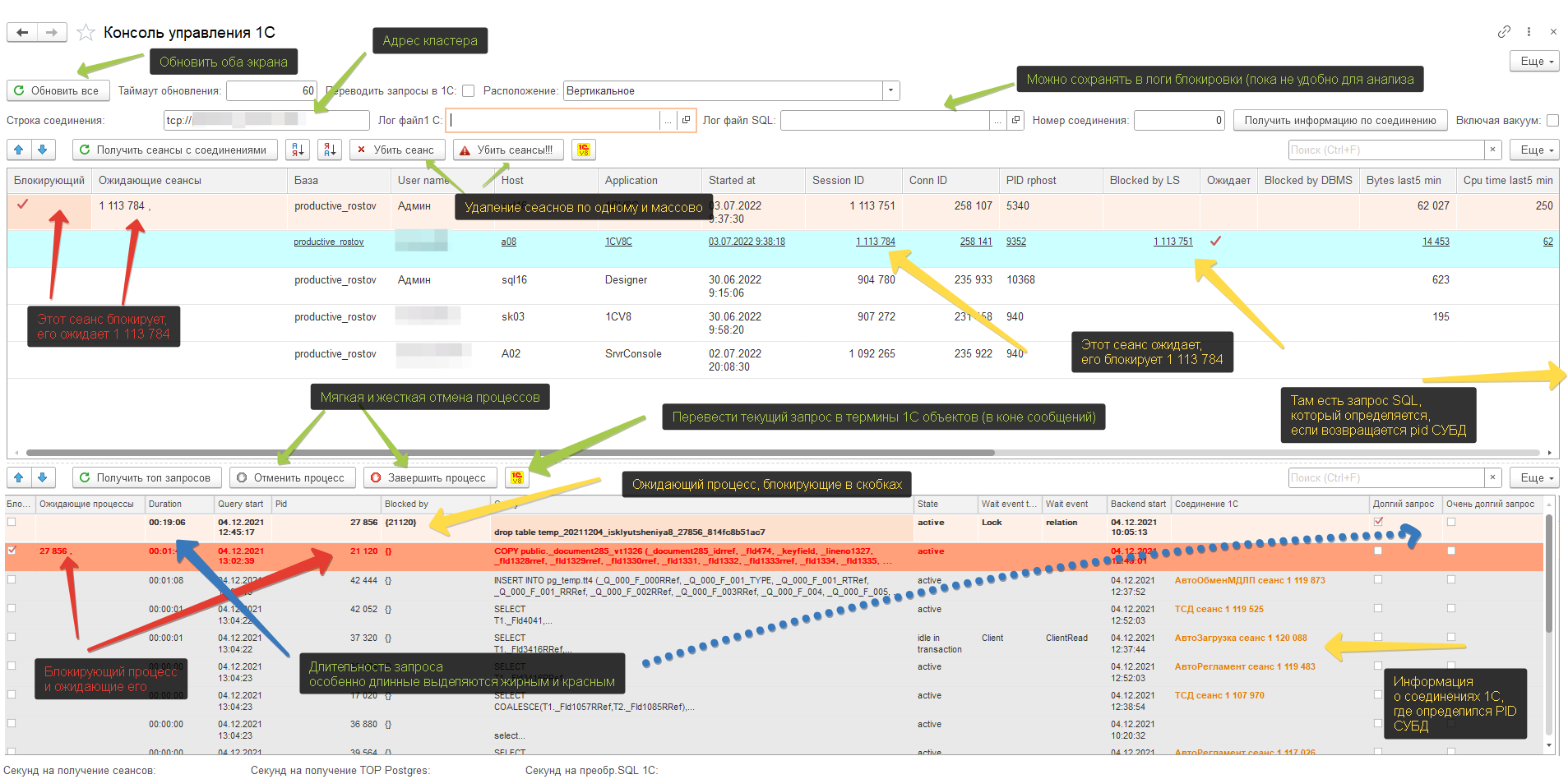
В общем, я сделал обработку "Консоль управления блокировками 1С", которая решала 3 задачи
- связанное отображение блокирующих и ожидающих процессов,
- отображение SQL запросов, также с зависимостям по блокировкам,
- по сеансам в которых 1С возвращает pid СУБД отображается запрос SQL, который выполняется данным pid (и в запросах SQL также отображается пользователь 1С, сеанс).
Этот запрос SQL можно перевести в термины названий объектов 1С вместо таблиц хранения Postgres.
Самое главное - все это на одном экране! Не надо скакать между программами или окнами, судорожно нажимая кнопку "Обновить" и перематывать списки в поиске нужного сеанса. Время обновления можно настроить (слишком частое мешает анализу). Можно нажимать на кнопку обновляя вручную, но обновляя сразу все данные, а не по очереди (как в случае со стандартной консолью). Кроме того, в программе выделяются цветом проблемы, чего нет в стандартной консоли.
Ну и, естественно, тут можно завершить сеанс 1С или pid Postgres либо "мягким способом", отменив текущий запрос, либо "жестким" убиванием процесса, с отваливанием пользователя, если первый не помог.
Как пользоваться
1. Настроить Строку соединения с 1С кластером в формате : tcp://ИмяКластера:Порт (для порта по-умолчанию двоеточие и порт можно не указывать)
2. Настроить параметры соединения с сервером СУБД:
- Сервер БД в формате ИмяСервера; port=Порт ( "; port=Порт" можно не указывать, если он по-умолчанию и равен 5432 для Postgres )
- Имя базы на сервере СУБД
- Имя пользователя
- Пароль
3. Прочие настройки: таймаут обновления (комфортный от 20-30 сек), перевод запросов в 1С имена (лучше не включать, если метаданных в конфигурации много, например в типовых иначе при обновлении будет тормозить. Перевод в 1С можно делать по каждому запросу кнопкой)
Все настройки сохраняются в данных формы и повторно вводить их при каждом открытии не нужно
Лучше запускать обработку на какой-то копии базы, так как в момент торможения обновление процессов может также тормозить из-за накладывающейся нагрузки параллельно открытых окон. Как альтернатива можно запускать в отдельном сеансе рабочей базы только консоль, чтобы другие окна не мешали ее работе
UPD. Убрал зависимости от внешних функций, перенес все в обработку
UPD. Сделал адаптацию под MS SQL в режиме бета-тестирования. Чтобы работала необходимы права на системные таблицы
Что можно было бы еще сделать и может быть появится в будущих версиях, если будет интерес:
- Доделать нормальное (сейчас есть, но пока неудобно используемо) ведение логов длительных запросов и блокировок в таком формате, чтобы потом можно было строить отчеты
- Сделать настройку автоматического убивания сеансов или запросов SQL если они превышают какие-то временные границы
- Сделать адаптацию под MS SQL (уже начата - в процессе тестирования пользователями MS SQL)
- Сделать более умный переводчик запросов на язык 1С (сейчас только имена таблиц на объекты, но не сложные выражения), или как минимум более быстрый - на данный момент он достаточно неоптимально делает анализ текстов запросов и замены
- Добавить другие показатели из консоли, сделать их перевод на “человеческий язык”, разобраться как их можно использовать. Скажем, потребление памяти.
Вступайте в нашу телеграмм-группу Инфостарт

{kind=link}