




{kind=link}
Приветствую, коллеги!
Недавно в телеге был конкурс от Инфостарта, в котором предлагалось найти слова в матрице из букв, причем направление слов может быть по всем 4 сторонам света.
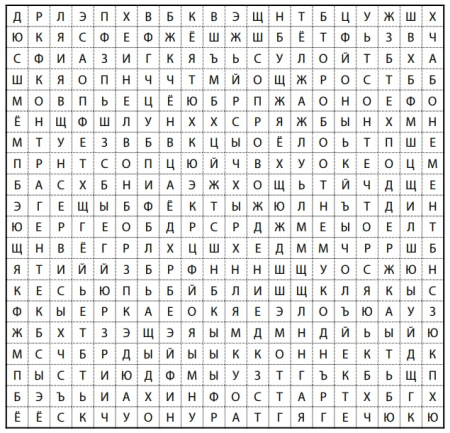
Я подумал, почему бы не доверить данную работу компьютеру?
Сначала прикинул суть алгоритма: изображение распознается, получается матрица из букв, строятся все возможные линии, берется словарь, загружается в регистр и запросом 1С происходит поиск. Изи!
Так набросал расширение, в котором 1 регистр сведений и 1 обработка.
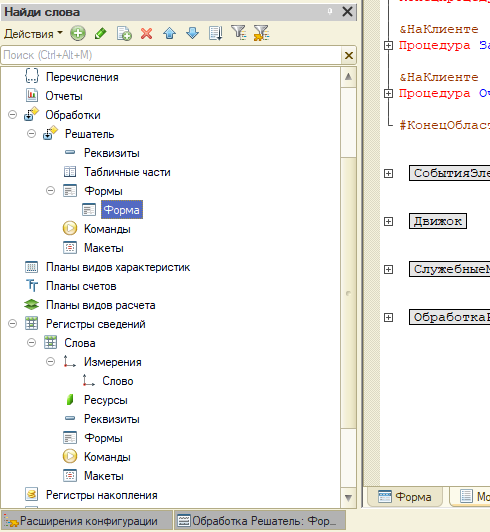
Скачал с Инета словарь на 45 килослов:
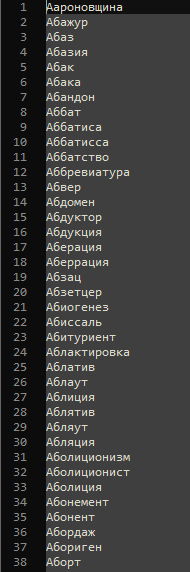
Ну а далее накидал на форму немного интерактива, закодил алгоритм и получилось нечто.

Думаю, что более детальное описание тут ни к чему, всё просто и быстро (уложился в 200 строк г. кода).
Tesseract очень хорошо распознает (сначала попробовал на старом CuneiForm из документооборота, но из него вылезла каша).
Так что кому интересно, берите, пользуйтесь. Код открыт.
Tesseract в комплекте НЕ идёт, скачать и установить придется самим, ну и подключить русский язык к нему, если нужен )
Из тонкостей механизма: перед поиском многострочный словарь нужно загрузить в РС (по дефолту кодировка cp1251), из всей картинки оставить только поле с буквами (иначе не пройдет проверку корректности распознавания). Работает на платформе 8.3.18 и 8.3.20 (будет и на более младших, т.к. специфики нет).
Данный алгоритм можно применять в качестве OCR в 1С.
Проверено на следующих конфигурациях и релизах:
- 1С:Библиотека стандартных подсистем, редакция 3.1, релизы 3.1.11.155
Вступайте в нашу телеграмм-группу Инфостарт