










{kind=link}
Метод Дугласа-Пойкера
Идея метода заключается в том, что сырые данные аппроксимированы прямой линией. Минимальное расстояние от отрезка, до точки с данными меньше погрешности. Если это условие не выполняется, то в месте с наибольшим отклонением отрезок делится на два. Прямая превращается в ломаную. Рекурсивно повторяем процедуру для каждого нового отрезка, пока условие погрешности не будет выполнено.
Строго прошу на википедию.
Давайте в картинках
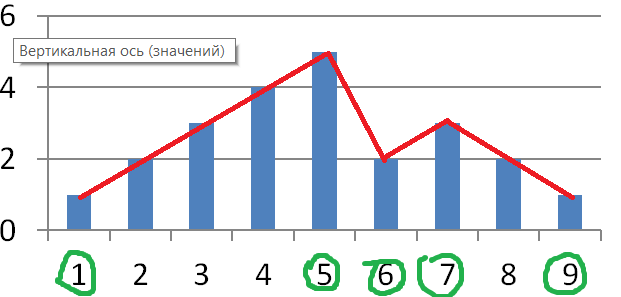
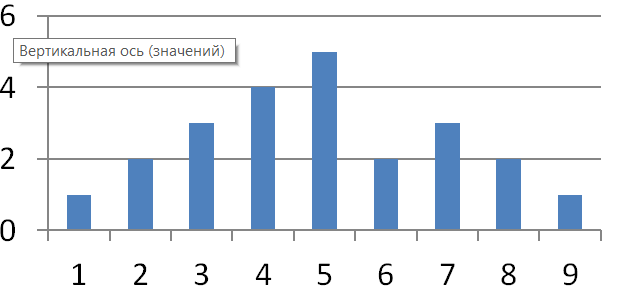
Вот простой график, а допустимую погрешность возьмем 1.
На графике значение функции аппроксимируем прямой. Максимальная погрешность в столбце №5, и она больше 1. Ломаем линию.
Теперь в столбце №6
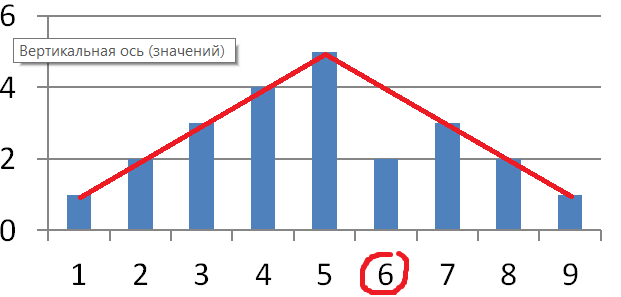
Теперь №7
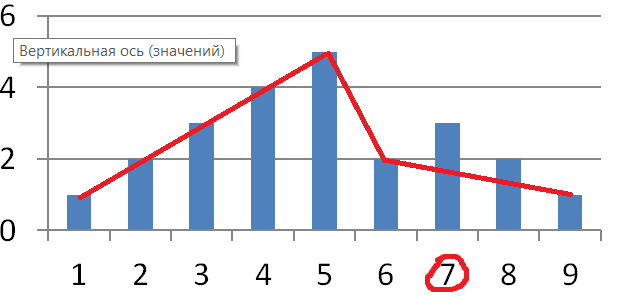
Готово!
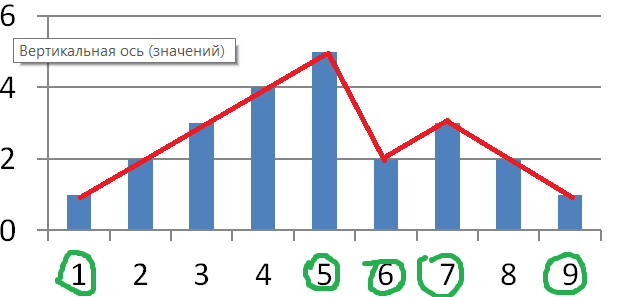
Итого: для того чтобы хранить данный график в памяти можно выкинуть 4 столбца из 9. Значения столбцов 2,3,4 можно восстановить по столбцам 1 и 5. Погрешность, кстати, получилась 0.
Большие данные
Я взял данные о занятом дисковом пространстве из системы мониторинга Zabbix. Zabbix каждую минуту записывает занятое место на разделе. В этом разделе мы храним резервные копии Postgres.
Один раз в 2 суток в раздел падает свежая полная резервная копия БД, а самая старшая копия из 4х удаляется. В течении дня на этот раздел падает архив журнала транзакций. Иногда это 5МБ/минута иногда больше, а ночью меньше. Все зависит от интенсивности работы с БД.
Вот такой график рисует Zabbix
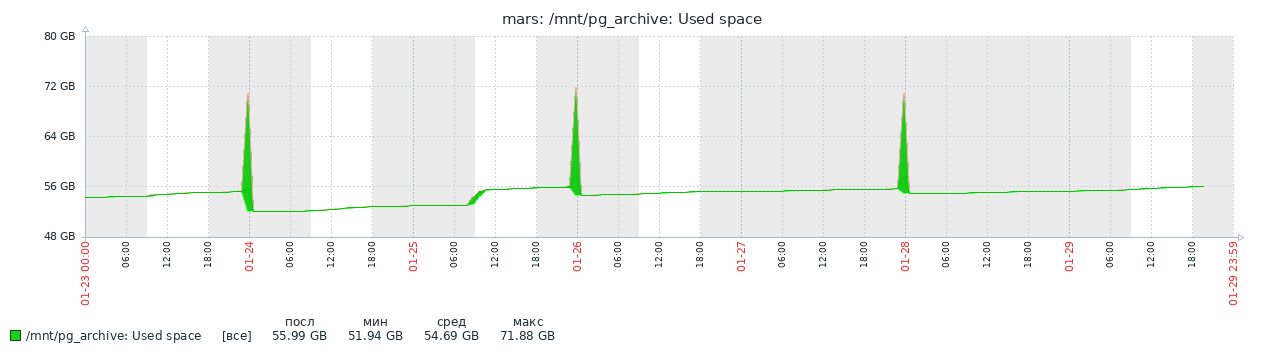
На графике видны периоды полного резервного копирования и аномалия на 25.01.24 09:00. Во время "аномалии" выполнялась обновление не самой маленькой 1С:Бухгалтерии, изменений много вот и скачок архивированных данных.
На графике 10.000 значений. Мне удалось сократить это число до 144.
Реализация алгоритма
Данные записаны в CSV-файл без заголовка. В каждой строчке записана временная метка и значение занятого объема. Файл упорядочен по метке времени. Значения целочисленные. Всего ~10000 строк.
Сперва читаем файл, ничего сложного
ЧтениеТекста = новый ЧтениеТекста;
ЧтениеТекста.Открыть(Диалог.ПолноеИмяФайла, "windows-1251");
МассивДанных = новый Массив();
Пока Истина Цикл
Стр = ЧтениеТекста.ПрочитатьСтроку();
Если Стр = Неопределено Тогда
Прервать;
КонецЕсли;
МассивПодстрок = СтроковыеФункцииКлиентСервер.РазложитьСтрокуВМассивПодстрок(Стр,",");
Д = новый Структура("ДатаВремя,Значение", неопределено, неопределено);
МассивДанных.Добавить( СтруктураДанных(Число(МассивПодстрок[0]), Число(МассивПодстрок[1])) );
КонецЦикла;
Ну и сама процедура реализующая метод Дугласа-Пойкера
// Функция - Применить метод Дугласа-Пойкера https://en.wikipedia.org/wiki/Ramer%E2%80%93Douglas%E2%80%93Peucker_algorithm
//
// Параметры:
// МассивДанных - Массив - Массив структур данных с полями ДатаВремя,Значение. Поля структуры целочисленые значения. Упорядочено по ДатаВремя
// Погрешность - Число - Целое Положительное.
//
// Возвращаемое значение:
// - МассивДанных с удаленными "ненужными" столбцами.
//
&НаКлиенте
Функция ПрименитьМетодДугласаПойкера(МассивДанных, Погрешность)
Результат = новый Массив();
МассивОтрезков = новый Массив();
МассивОтрезков.Добавить(новый Структура("Начало,Конец", 0, МассивДанных.Количество()));
ВставитьДанныеВРезультат(Результат, МассивДанных[0]);
ВставитьДанныеВРезультат(Результат, МассивДанных[МассивДанных.Количество()-1]);
Пока МассивОтрезков.Количество()>0 Цикл
Отрезок = МассивОтрезков[МассивОтрезков.Количество()-1];
МассивОтрезков.Удалить(МассивОтрезков.Количество()-1);
ц=Отрезок.Начало+1;
МаксДельта = Погрешность;
МаксЦ = неопределено;
Пока ц < Отрезок.Конец Цикл
ПрогнозируемоеЗначение = МассивДанных[Отрезок.Начало].Значение +
(МассивДанных[ц].ДатаВремя - МассивДанных[Отрезок.Начало].ДатаВремя)*(МассивДанных[Отрезок.Конец-1].Значение - МассивДанных[Отрезок.Начало].Значение)/
(МассивДанных[Отрезок.Конец-1].ДатаВремя - МассивДанных[Отрезок.Начало].ДатаВремя);
Дельта = Макс(ПрогнозируемоеЗначение-МассивДанных[ц].Значение, МассивДанных[ц].Значение-ПрогнозируемоеЗначение);
Если Дельта > МаксДельта Тогда
МаксЦ = ц;
МаксДельта = Дельта;
КонецЕсли;
ц = ц + 1;
КонецЦикла;
Если МаксЦ<>Неопределено Тогда
МассивОтрезков.Добавить( новый Структура("Начало,Конец", Отрезок.Начало, МаксЦ+1) );
МассивОтрезков.Добавить( новый Структура("Начало,Конец", МаксЦ, Отрезок.Конец) );
ВставитьДанныеВРезультат(Результат, МассивДанных[МаксЦ]);
КонецЕсли;
КонецЦикла;
Возврат Результат;
КонецФункции
Процедура ВставитьДанныеВРезультат(Результат, Данные)
Для ц=0 По Результат.Количество()-1 Цикл
Если Результат[ц].ДатаВремя = Данные.ДатаВремя Тогда
Возврат;
ИначеЕсли Результат[ц].ДатаВремя > Данные.ДатаВремя Тогда
Прервать;
КонецЕсли;
КонецЦикла;
Результат.Вставить(ц, Данные);
КонецПроцедуры
Обработка
Приложенная обработка (Работает в режиме совместимости 8.2.19, сорри) и формирует две таблички.
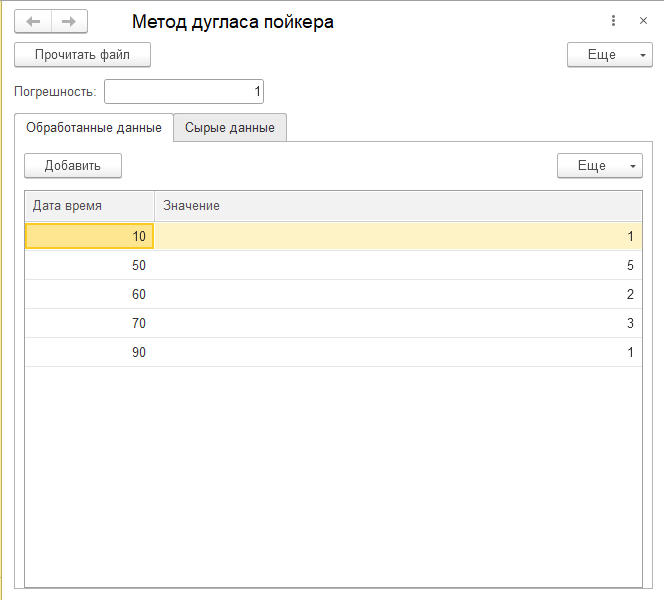
Табличка «обработанные данные» содержит нашу таблицу с удаленными «лишними» столбцами.
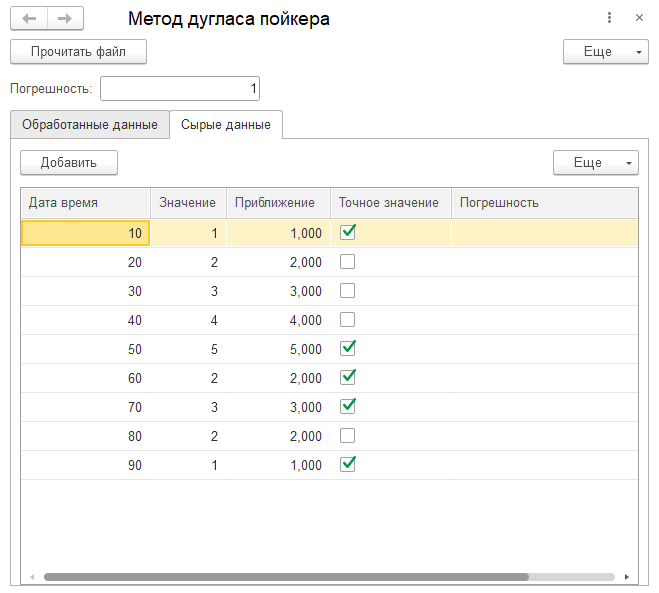
Табличка «Сырые данные» содержит данные файла, столбец с приближенными значениями и столбец с «погрешность». Мне эти данные нужны были, чтобы отладить обработку.
Для моего большого файла по таблице «Сырые данные», я построил два графика, чтобы визуально сравнить сырые и обработанные данные. По моему, выглядит похоже. Важно, что пики и "анамалия" сохранились в аппроксимации.
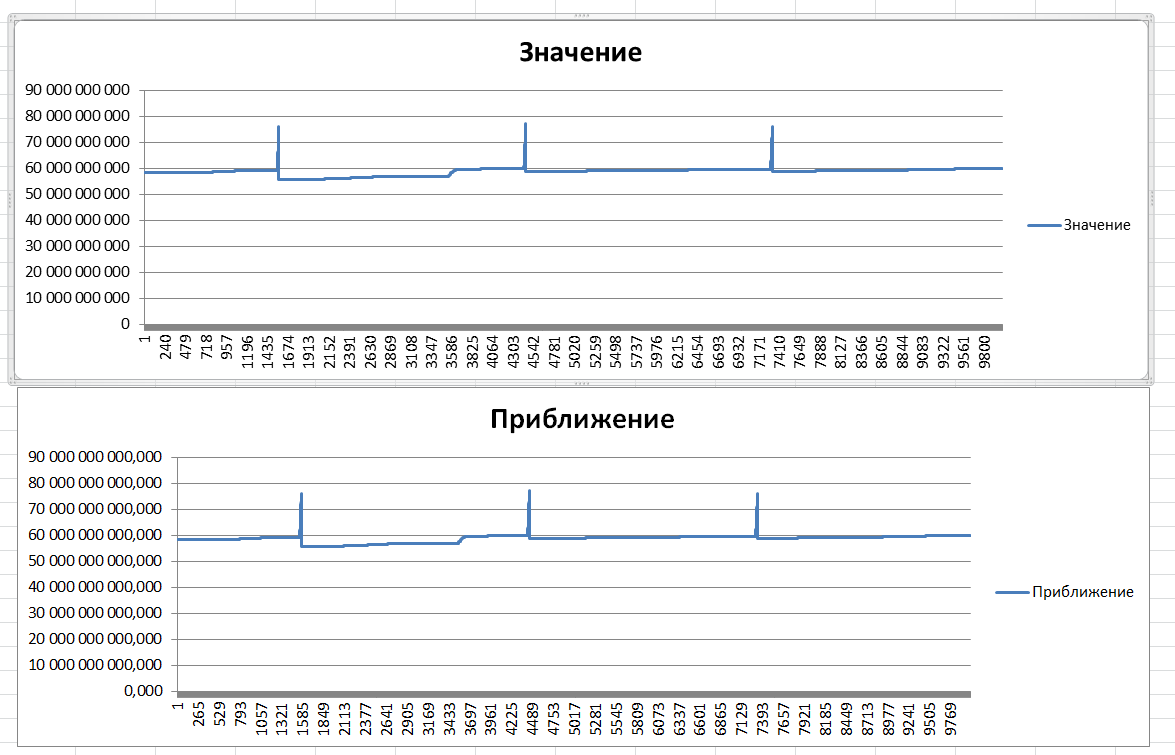
Проверить можно, если скачать обработку. Исходные данные в архиве, слишком большой объем для формата статьи.
А вот так выглядит обработка с данными из моего примера «с картинками».
Вывод
Сырые данные можно эффективно сокращать.
Вступайте в нашу телеграмм-группу Инфостарт