










Предисловие
На написании данной статьи и более глубокого погружения в материал меня сподвигла моя текущая профессиональная деятельность и несколько статей, связанных с парсингом:
- Разбор технологического журнала без боли и страданий
- Выгрузка журнала регистрации 1С в ClickHouse с помощью Vector
- Инструменты экспорта журнала регистрации 1С в ClickHouse/ElasticSearch
В данной статье я детально рассмотрю пример реализации мониторинга производительности кластера 1С (своё видение разбора технологического журнала и журнала регистрации опубликую отдельными статьями, подписывайтесь, если понравится) и сделаю акцент на деталях работы конкретного решения.
По мониторингу производительности кластера есть несколько статей:
- Мониторим производительность с помощью 1С RAS
- Мониторим доступную производительность рабочих процессов в реальном времени
- Мониторинг доступной производительности рабочих процессов кластера 1С:8.3
Но лично я не сторонник хранения огромных массивов данных в 1С (так например реализовано в 1С:ЦКК).
Выбор инструмента
Инструментов для сбора, парсинга и доставки логов много, к примеру – Logstash, Filebeat, Fluentd, Fluent-bit, Vector и т.д. По совокупности факторов лично я отдал предпочтение Vector. Он написан на Rust, чрезвычайно быстрый, лёгкий к изучению и применению. Для погружения в выбор решения и детали работы можно посмотреть видео «Logstash или Vector // Курс "Observability: мониторинг, логирование, трейсинг"», так же там в 1:28:19 есть сравнение производительности разных популярных решений.
Архитектура (идеология) Vector поддерживает работу одновременно с двумя моделями данных – журналы и метрики (с возможностью конвертации из одной в другую). Модель конвейера Vector основана на компонентах ориентированных ациклических графов, содержащих независимые подграфы. События должны двигаться в одном направлении, от источников к приемникам, и не могут создавать циклы. Каждый компонент может создавать ноль или более событий.
Всего три вида компонентов – Sources, Transforms и Sinks (на момент написания статьи была заявлена поддержка 40 видов источников, 13 видов трансформации и 52 вида вывода). Наглядная инфографика с сайта продукта:
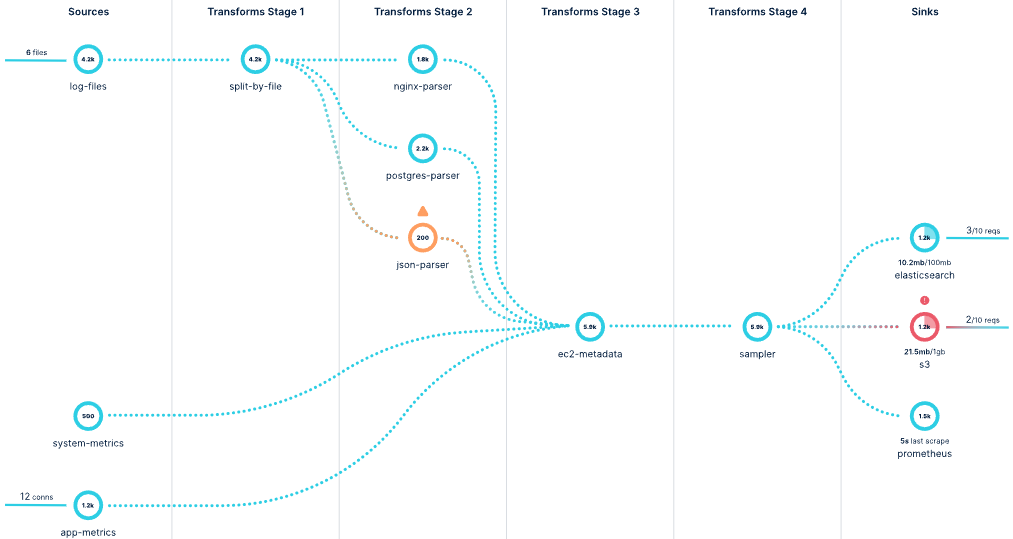
Для особо сложных случаев в блоке трансформации есть тип «Lua», который позволяет писать процедуры и функции на одноимённом языке программирования.
Vector представляет из себя одиночный бинарный файл, не требующий установки (поддерживаются все современные ОС). Для *nix систем только одна зависимость libc. Поддерживается работа в качестве службы в Windows или демона в Linux.
Возможны разные сценарии использования – распределённое, централизованное, на основе потока, но лучше это изучить непосредственно на оригинальном сайте, документация и описание там отличные (особое внимание советую уделить тонкостям – высокой доступности, буферам, «обратному давлению», работе с «секретами» и т.д.).
Конвейер Vector определяется с помощью файла (или файлов) конфигурации в одном из форматов YAML, TOML или JSON. В своей работе я остановился на YAML. Основные параметры работы задаются или в командной строке, или с помощью переменных среды (можно динамически изменять в процессе работы). Vector поддерживает изменение конвейера (горячую перезагрузку для применения любых изменений конфигурации) в режиме реального времени без перезапуска процесса. Так же есть поддержка API, который позволяет в режиме реального времени наблюдать за работающим экземпляром Vector и управлять им.
Практическая часть
Рассмотрим «магию преобразований» на примере результатов вывода списка процессов утилитой администрирования платформы 1С:Предприятие RAC:
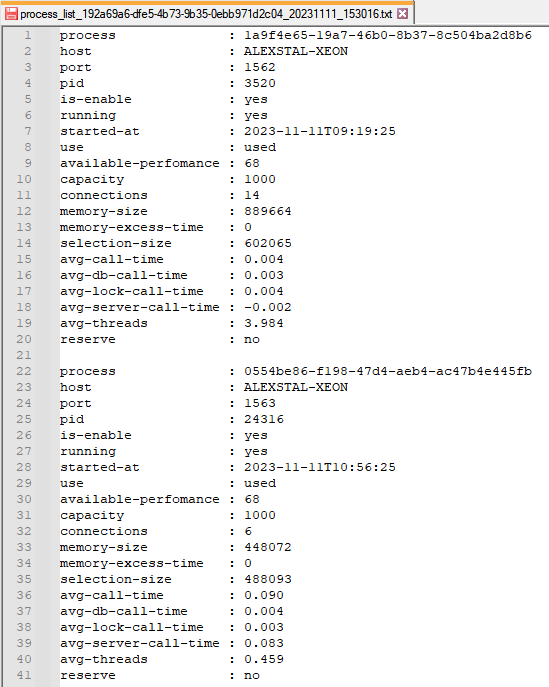
Для получения исходных данных я выбрал вариант перенаправления стандартного потока выводы консольного приложения в файл с именем по заданному шаблону (в примере тип вывода, гуид кластера, дата/время вывода, приложенный конфигурационный файл рассчитан именно под данный шаблон):
@Echo off
chcp 65001 > nul
set hr=%time:~0,2%
if "%hr:~0,1%" equ " " set hr=0%hr:~1,1%
set datetime=%date:~-4,4%%date:~-7,2%%date:~-10,2%_%hr%%time:~3,2%%time:~6,2%
"D:\vector\RAC\rac.exe" process list --cluster=192a69a6-dfe5-4b73-9b35-0ebb971d2c04 --cluster-user=[user] --cluster-pwd=[123] >> D:\vector\RAC\process_list\process_list_192a69a6-dfe5-4b73-9b35-0ebb971d2c04_%datetime%.txt
Примечание: D:\vector\RAC\rac.exe это ссылка, к примеру, на C:\Program Files\1cv8\8.3.23.1912\bin\rac.exe (что бы при обновлении платформы достаточно было изменить только ссылку, а не изменять код скрипта; ещё можно было реализовать это на переменных среды).
Хотя Vector сам умеет вызывать exec и забирать данные со стандартного потока вывода, но я посчитал эту архитектуру более безопасной и надёжной в использовании - запуск скрипта по расписанию легко реализуется в любой ОС с помощью штатного планировщика заданий.
Для себя я принял общую концепцию конфигурирования – основной файл (описывает все глобальны параметры и функции – каталог с данными для работы самого Vector, параметры API, внутренние логи и метрики, «секреты» и т.д.) и каталог с отдельными файлами под каждую задачу (RAC, журналы регистрации 1С, технологические журналы 1С, журналы работы транспорта RabbitMQ, журналы работы web-серверов и т.д.). Пример строки параметров запуска Vector:
vector.exe --log-format json --config D:\vector\RAC\global.yaml --config-yaml D:\vector\RAC\yaml\*
Рассмотрим по этапам сам процесс конвейера.
Первым этапом всегда идёт блок с видом Sources. Для нашего примера его тип – File. На данном этапе получается следующая внутренняя картина (отладочный вывод в формате JSON; правая часть строк message обрезана на скриншотах, она содержит многострочную строку до разделителя пустой строки):
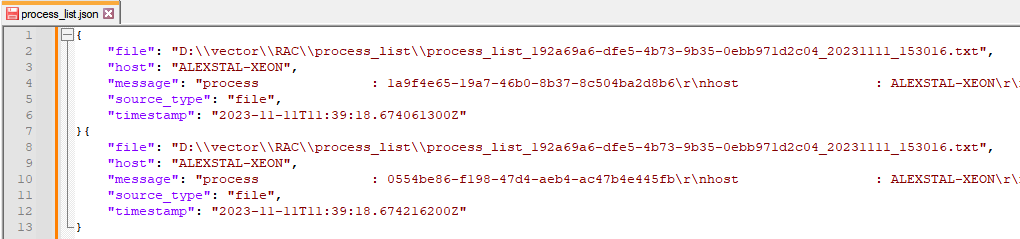
Далее пойдут блоки с видом Transforms.
Добавим нужные нам поля маркировки с помощью типа преобразования Remap (при необходимости; может потребоваться, когда у нас несколько Sources, а модель преобразовании данных одна). В примере это добавленное поле «_timezone»:
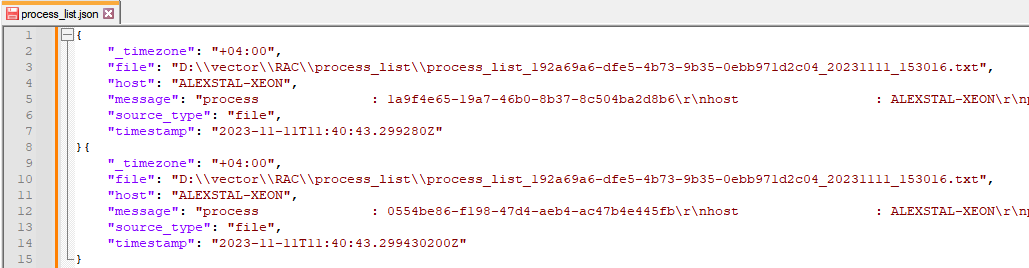
Далее, с помощью следующего блока с аналогичным типом Remap, с помощью простого регулярного выражения разложим Message на части и удалим лишнее:
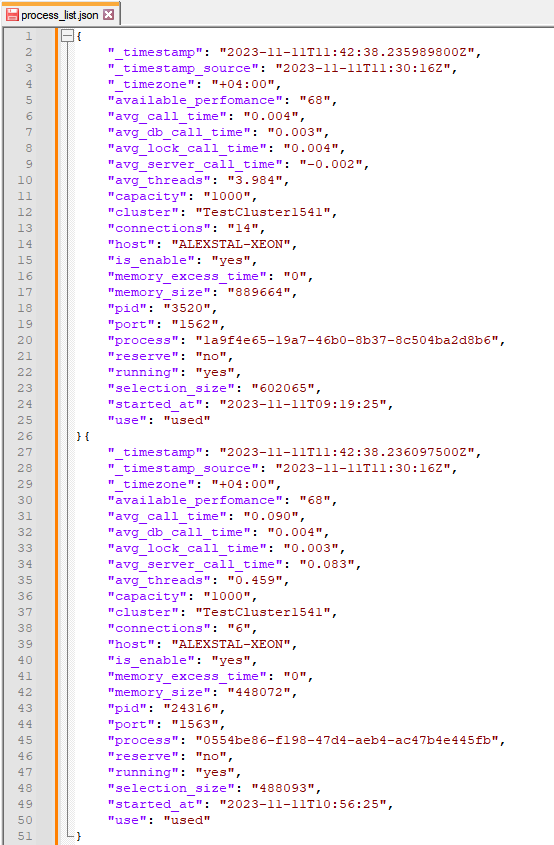
Вот так мы за два простых действия получили конечный результат преобразования, который с помощью следующего блока вида Sinks можно сразу отправить в точку хранения и анализа данных, к примеру, в ElasticSearch, ClickHouse, Socket или через http-сервис в 1С (выбор огромен).
Ну а если есть необходимость сразу отправлять в централизованную систему мониторинга, без посредников, к примеру, Prometheus? Да легко! Добавим ещё один блок Transforms с типом Log_to_metric (для примера я взял только 2 параметра – available_perfomance и memory_size, ключевое уникальное поле – process):

Превосходно! А если усложнить задачу, и в Prometheus отправлять только агрегированные данные по кластеру, без разреза по Process? Тогда, наверное, нужно на первом этапе рассматривать весь файл как одну строку лога. Но, а если нам нужно это делать в одной итерации, чтобы отправлять в разные получатели данных? Немного подумав, можно нестандартным подходом реализовать и это. Сделаем второе ответвление (отдельными блоками Transforms) с типами Log_to_metric и Aggregate:
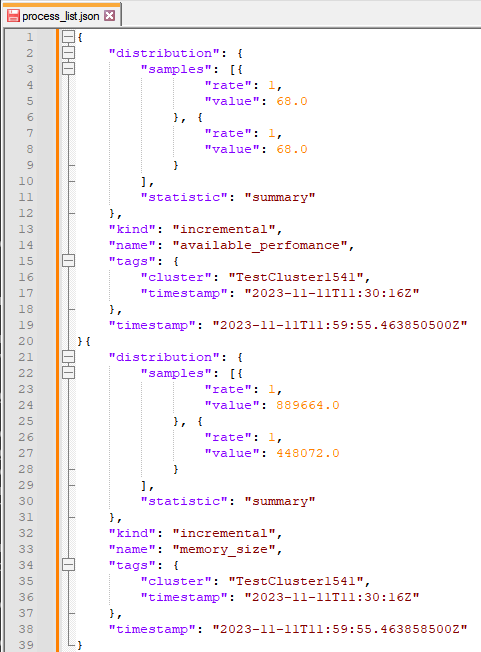
Выполнить каких-либо преобразования с форматом данных Метрика нет возможности, поэтому сконвертируем данные метрик обратно в модель данных Журналы с помощью Metric_to_log и вычислим сумму (или среднее) по агрегированным значениям (с помощью отдельного блока Remap):
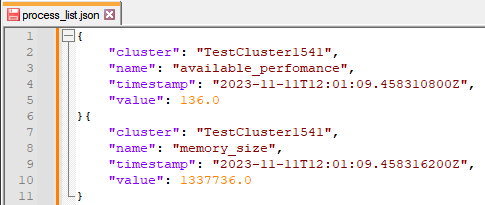
И заключительным блоком будет обратное преобразование (чисто техническое) из модели данных Журналы в модель данных Метрики:
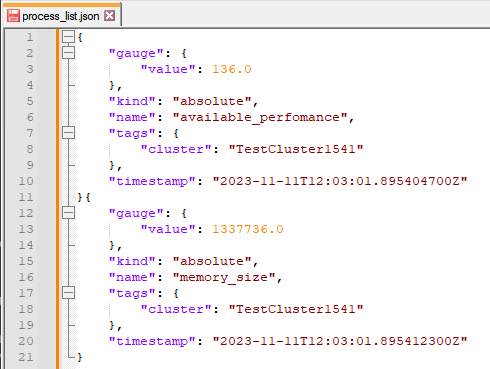
Заключительный этап – отправка данных получателю. Блок с видом Sinks и для нашего примера с типом Prometheus_remote_write. Проверяем:
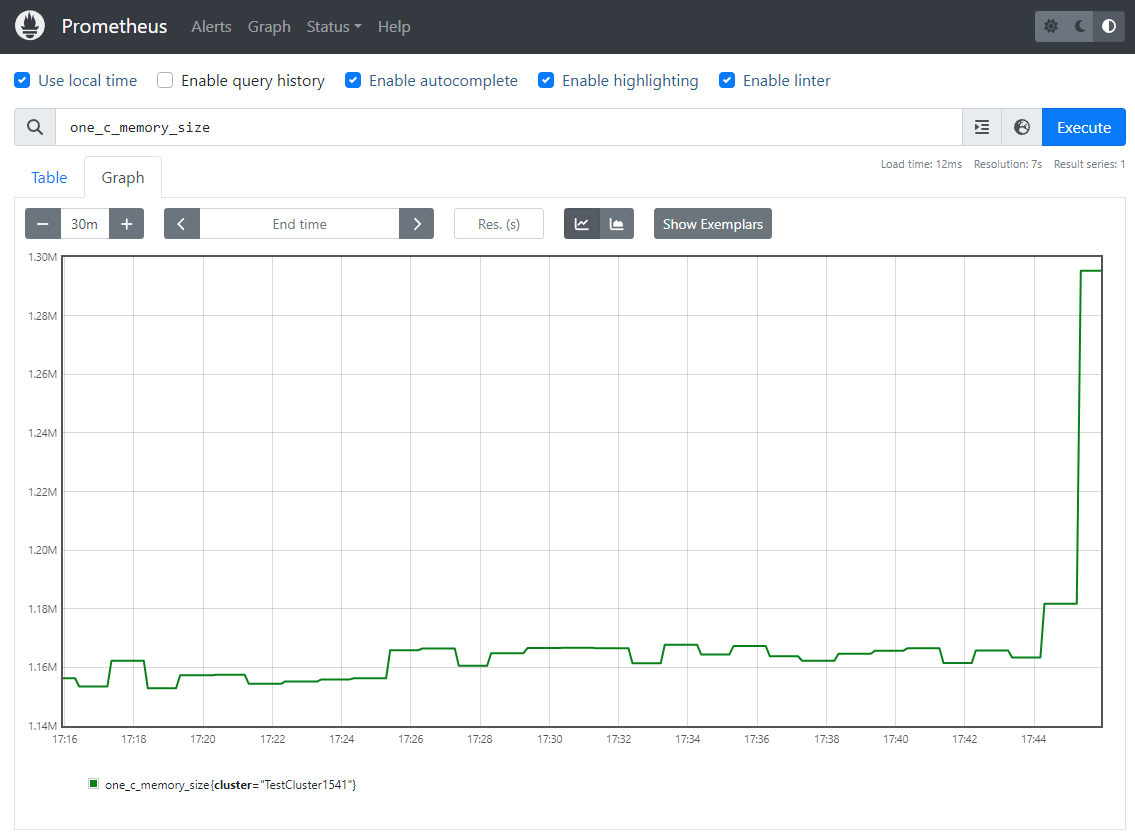
Бонус
Внимательные читатели, возможно, заметили имя «TestCluster1541» на скриншотах? Но откуда оно взялось? В первом блоке «маркировки» (где добавляли часовой пояс) мы не маркировали таким образом события. Ответ простой – Vector поддерживает «таблицы обогащения», при чём они индексируются и не оказывают какого-либо существенного влияния на производительность:

К статье прикладываю примеры (шаблоны) – основной конфигурационный файл и файл для process list.
Вступайте в нашу телеграмм-группу Инфостарт