




Плюс данной технологии заключается в том, что мы будем вести обработку перс данных на нашем личном сервере без передачи данных на какие-то "облачные сервера". При этом нам не придется платить за услуги распознавания.
Минусом является то, что даже самый мощный CPU будет довольно долго обрабатывать часы переговоров с клиентами. Для этого нам понадобится отдельная машина (CPU 8 ядер и выше). Видеокарта Nvidea: минимум я рекомендую видеокарты GTX 1080ti. Я же использую RTX 3090 из-за того, что на ней 24gb видеопамяти. С ней один час переговоров конвертируется за примерно за 12-15 секунд. GTX 1080ti будет обрабатывать примерно 1 час за 40-60 секунд.
Если нет видеокарты, то 1 час конвертится - 3-20 часов.
Итак, что мы имеем на входе: на входе мы имеем гигабайты переговоров, записанных на миниАТС, Астерикс, которые имеют названия 2024013401_84959260954.wav, где в начале идет дата, далее номер телефона, ну и, конечно же, сама запись в формате wav.
Наша задача:
1. Распознать текст переговоров
2. Распарcить его в HTML
3. Загрузить ее в 1С. Для теста я использую УТ, но тут можно и CRM, УХ, ERP и т.п.
Для этого мы находим клиента по номеру телефона в контактах.
На выходе мы должны получить такой вот результат
1. Регистрируется входящий звонок:
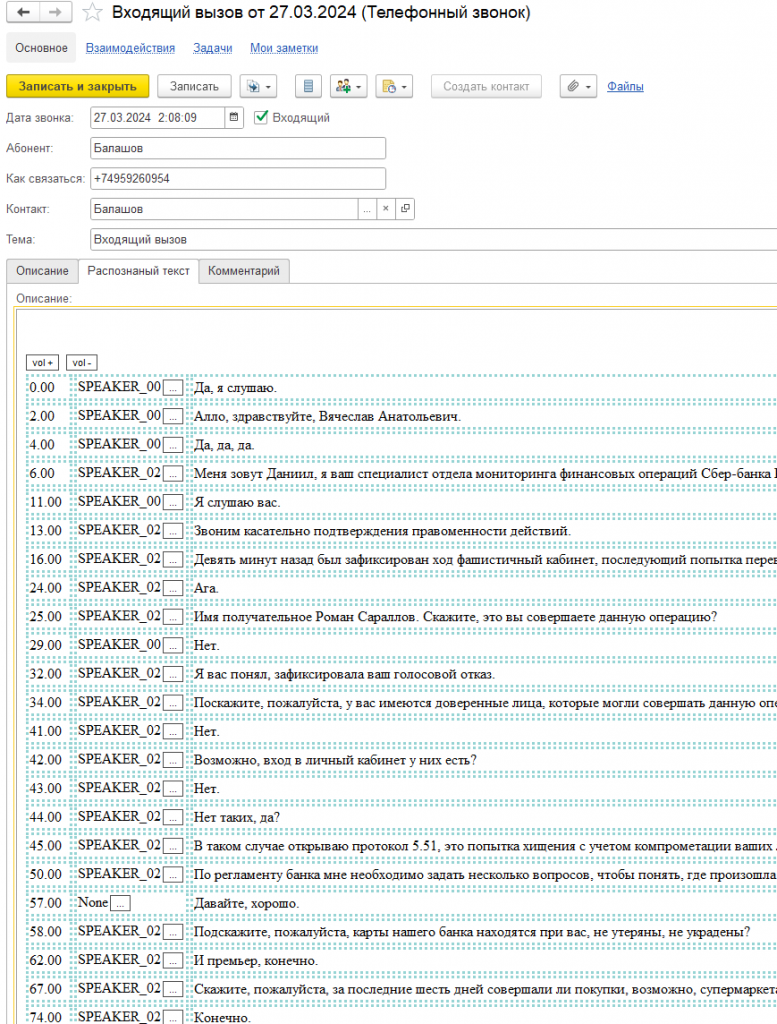
Внутрь помещается наш распознанный текст переговоров
Ну а теперь давайте рассмотрим, как это реализовать.
1. Устанавливаем на подготовленную машину с видеокартой Python 3.11 (рекомендуется) Windows.
Обязательно установим галочку python path. Если не установить, то будет весело
2. Далее скачиваем совместную разработку с братом, доработанную для работы с 1С, с github. https://github.com/magican82/voice_to_html
Все аудиозаписи должны помещаться в папку WAV.
Я лично закачиваю с помощью bat файла, забираю их с ftp АТС Астерикс.
3. Устанавливаем Open AI Whisper https://github.com/openai/whisper. Это, я думаю, самый сложный пункт, но я думаю, разберетесь. В самом репозитарии имеется readme.
4. Теперь установим https://github.com/pyannote/pyannote-audio. Тут рекомендую установить версию 3.0, а не 3.11, если не хотите заморачиваться с регистрацией токенов и т.п.
5. Накатываете расширение за один инфомани. В самом расширении указываете путь с общей папкой, куда вы скачали и установили python модуль из пункта 2.
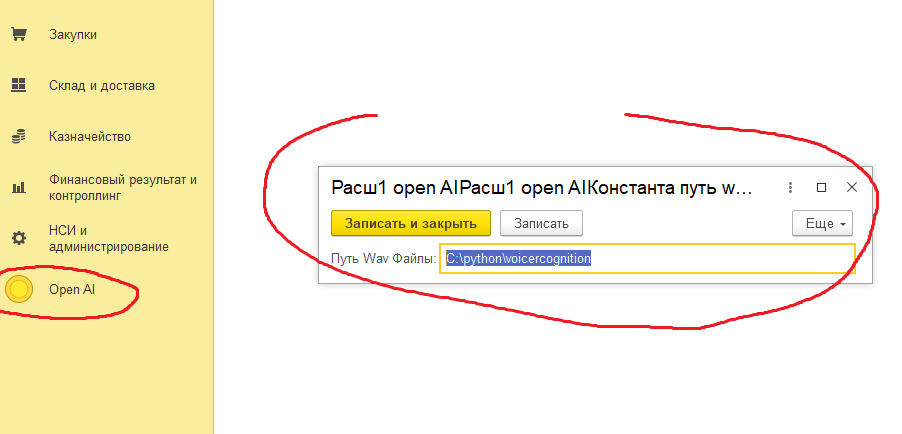
6. Теперь скачиваете обработку в описании за 1 инфомани.
7. Если все прошло успешно, запускаете командную строку с папки, куда установили Python модуль "voice_to_html"
cd C:\python\voicercognition
python convert_html.py
C:\Program Files (x86)\1cv8\8.3.5.хххх\bin\1cv8.exe» ENTERPRISE /DisableStartupMessages /FС:\путь к базе /N»ИмяПользователя» /P»ПарольПользователя» /Execute с:\путь к обработке\самаобработка.epf
Данную команду следует установить в шедуллер и запускать с регулярностью раз в час и т.п.
Как мы видим, сначала запускается pyhon модуль и делает из звука html файл.
Далее запускается 1С обработка и загружает html файлы в систему взаимодействий 1С и создает документы "ТелефонныйЗвонок" с признаком входящий вызов.
На данный момент дописываю доработку таким образом, чтобы могла идентифицировать автора по ключевому идентификатору.
Всем спасибо.
Тесты проводились на платформе 1С:Предприятие 8.3 (8.3.23.2137).
Вступайте в нашу телеграмм-группу Инфостарт