








Как скачать и установить у себя локальные модели генеративного ИИ, я писал в предыдущей статье, теперь перейдём к практической реализации. Будем решать конкретную задачу, а именно: нужно сформировать краткое содержание входящего документа, причём документ в формате Adobe PDF без текстового слоя. Для распознавания будем использовать OCR Tesseract, как это сделать описано в этой статье.
На самом деле не очень сложная задача. Пользователь выбирает файл, по которому нужно сформировать краткое содержание, файлов может быть несколько, т.е. можно выделить несколько строк. Потом программа проверяет, есть ли текстовый образ у текущих версий выделенных файлов, если нет, то распознаёт изображения и PDF или пытается извлечь текст из текстовых файлов. Далее, полученные тексты собираются в единый файл, к ним добавляется промпт и всё это добро отправляется на сервер Ollama для обработки. Полученный результат вставляется в соответствующий реквизит документа. Пользователь сам решает, сохранять результат или нет.
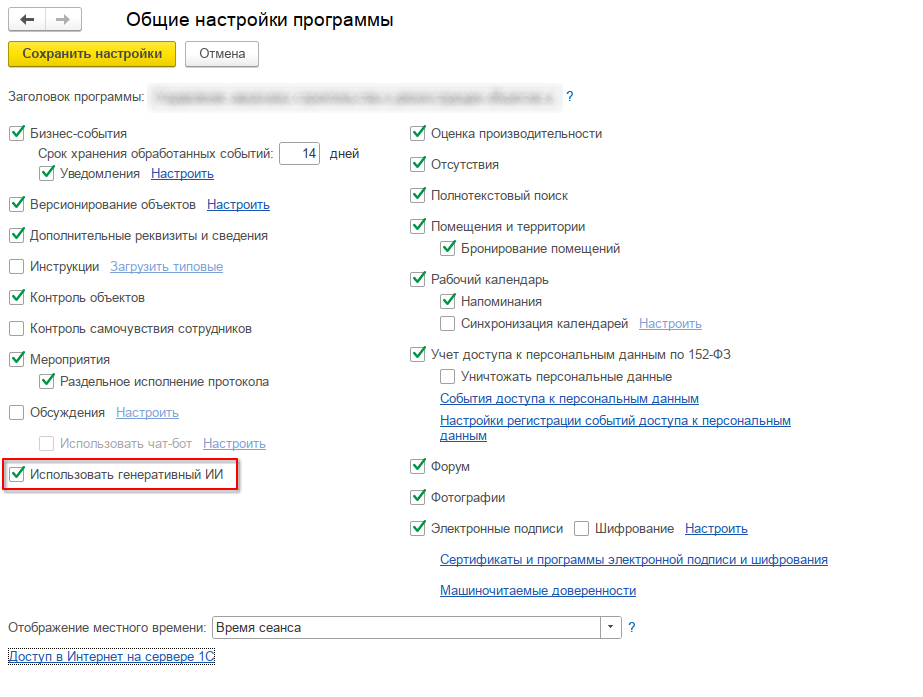
В расширении реализована функциональная опция, чтобы можно было включить или выключить обработку с помощью ИИ.
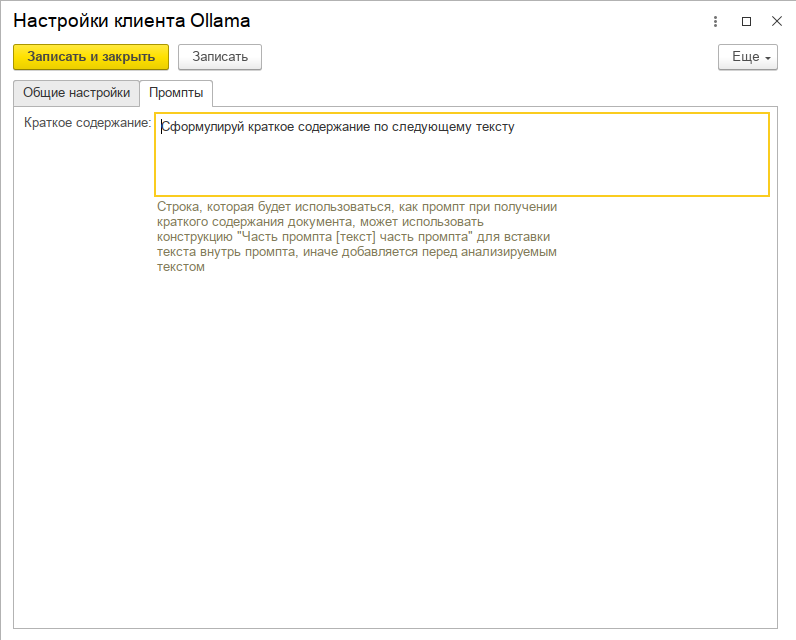
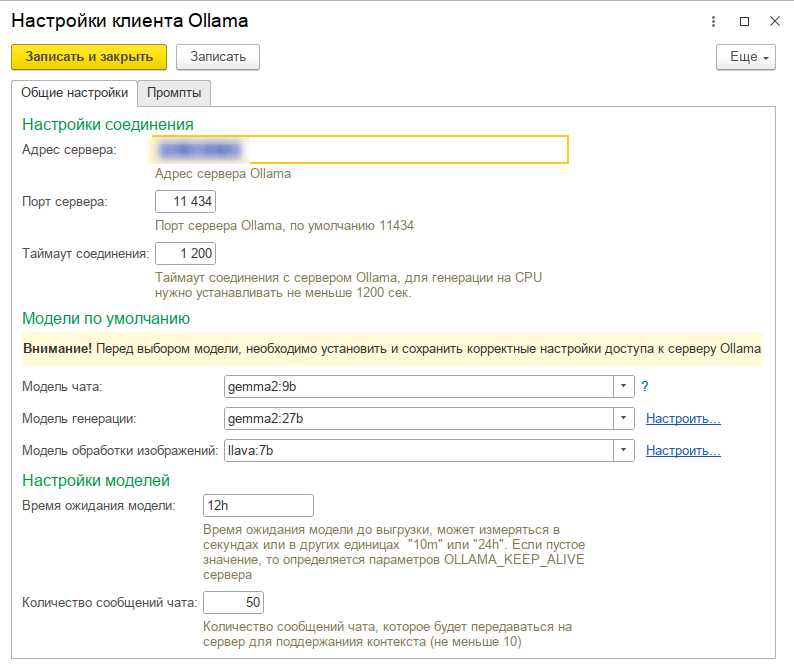
Есть форма настроек, она сделана «на вырост» для будущего внедрения чата и распознавания изображений. В отдельную вкладку вынесены используемые промпты.
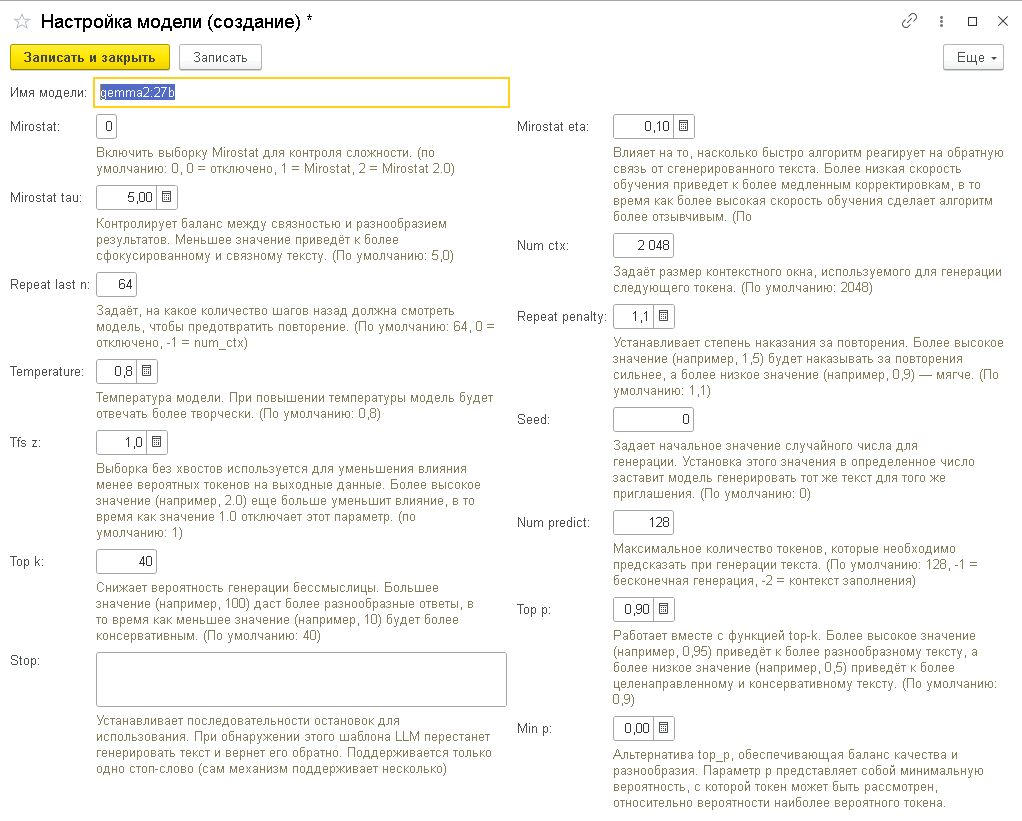
Каждую модель можно дополнительно настроить.
В расширении создана специальная роль для доступа на чтение к настройкам и основному функционалу, не забываем добавить её в полномочия нужных пользователей.
Чтобы воспользоваться функционалом, выбираем файл и нажимаем сверху кнопку.
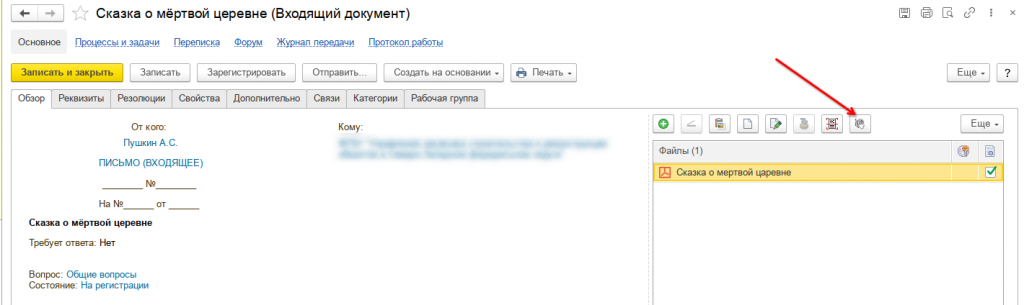
После некоторого ожидания, получаем результат
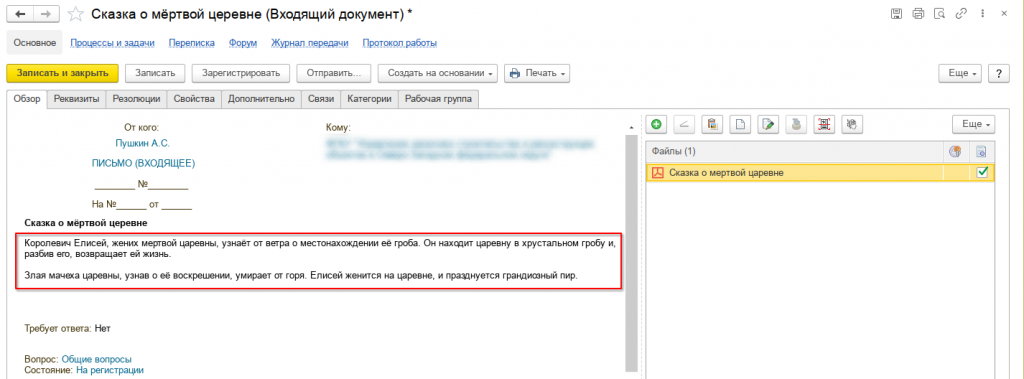
И теперь просто при просмотре документа в списке будет понятно, о чём он. Мне кажется, что очень удобно.
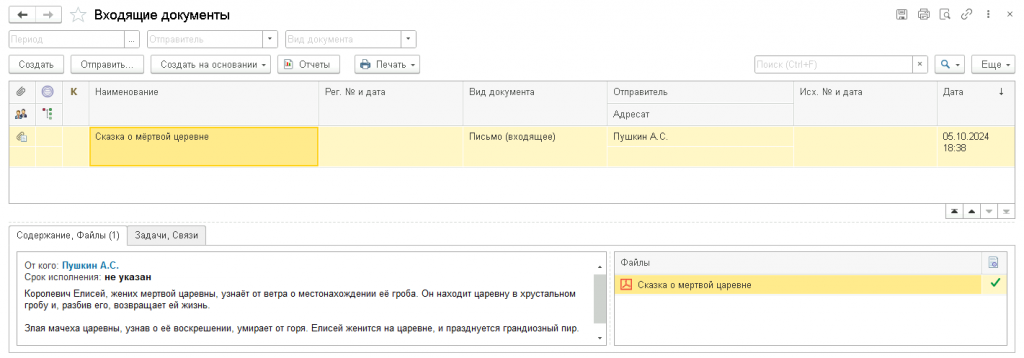
Понятно, что функционал немного не доработан. Очевидно, что эту задачу нужно выполнять в фоновом режиме по ночам, но тут есть нюанс. Не всегда понятно, какой из документов несёт основной смысл, я, например, встречал, что в карточку документа крепят скан резолюции начальника. Такие файлы нужно исключать. А ещё может быть, что приходит сопроводительное письмо, к нему приложения и к ним ещё приложения, например, при пересылке жалоб. В этом случае только человек (пока) может выбрать тот файл (или файлы), которые несут основной смысл. В общем много ещё работы...
Расширение разрабатывалось на ДГУ версии 2.1.34.1 и 2.1.35.15, должно работать и на классической версии КОРП.
Обновление от 27.10.2024. Исправлены выявленные ошибки, добавлена возможность задавать системное сообщение для чата, оно позволяем "погрузить" модель в текущий контекст и назначить основной язык (работает для модели qwen2 и llama 3.1 и не работает для gemma2)

Распознавание и загрузка сканов в 1С
Решение «Распознавание и загрузка сканов в 1С» — интеллектуальный инструмент, превращающий сканы накладных, счетов, УПД или Excel-файлов в готовые документы 1С. Без ручного ввода и ошибок — с распознаванием даже нечетких фото. Оптимизируйте документооборот и автоматизируйте рутину с помощью ИИ-распознавания.
Проверено на следующих конфигурациях и релизах:
- Документооборот КОРП, релизы 2.1.35.15, 2.1.34.1
Вступайте в нашу телеграмм-группу Инфостарт