
{kind=link}
Приветствую, коллеги!
Хотелось бы поднять вопрос удобства загрузки больших файлов на сервер.
Очевидно, разработчики не рассматривают сценарий работы с большими файлами через 1С, поэтому даже в профильных решениях вроде Документооборот Корп загрузка файлов на сервер выполняется скрыто и атомарно. Вот щелкнули по файлику, он ушел, повисло сообщение о том, что пошла загрузка.. и вот он загрузился.
Жизнь же порой ставит такие задачи, что на сервер нужно в тома загонять файлы по гигабайту - и в этом случае штатная загрузка просто повисает на пару часов и понять что там происходит решительно невозможно.
Ситуация, когда проект предусматривает возможность удобной загрузки файлов, а платформа ничего предоставить не может, вызывает некоторую грусть:)
Проанализировав проблему, я, в общем, увидел только 2 решения:
1. Использование JS-класса XMLHttpRequest в полеHTMLдокумента и HTTPСервиса с Post запросом (у класса XMLHttpRequestUpload есть событие onprogress). Попытка зайти с этой стороны вызывала ожесточенное сопротивление контрола IE, используемого для парсинга в полеHTMLдокумента в платформе. Проблемы решаемы, но возни тут много. Во-первых, HTML создаётся в location: about:blank, в то время как post запрос нужно слать на домен публикуемого http сервиса. Вроде как нужно использовать XDomainRequest, но он отказывается перенаправлять запрос, т.к. видит смену схемы - было непонятно что, стало http. Теоретически решаемо размещением служебной странички на IIS/Apache, из которой вызывать POST.Во-вторых, в веб-клиентах обработка JS идёт уже нативными средствами конкретного браузера - а это значит, что код нужно писать кроссбраузерный.
2. Новые объекты для работы с двоичными данными в платформе 8.3.9.
Интерес вызвали следующие классы: ЧтениеДанных,ЗаписьДанных, ФайловыйПоток, БуферДвоичныхДанных, МенеджерФайловыхПотоков.
Основная идея тут такая:
- С помощью метода НачатьРазделениеНаЧастиПо у класса ЧтениеДанных разделить двоичные данные на равномерные куски. Можно указывать собственные размеры частей, в моём решении используются куски по 5 Мбайт. Очень важно, что использование этого метода не загружает данные в память - происходит всего-лишь разбивка больших данных на маленькие
- Передавать данные на сервер по маленьким кусочкам
- На сервере с помощью менеджера файловых потоков дописывать добавленные куски в файл. Для этого есть специальный метод ОткрытьДляДописывания
- Различными решениями на форме обеспечить контроль загрузки кусков, отображать состояние, выполнять докачку только тех кусков, которые не были загружены ранее
В результате решил идти в ногу со временем и сделал вариантом №2:)
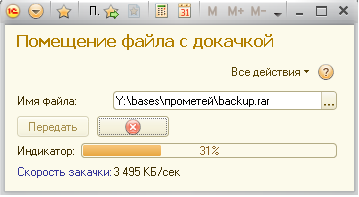
В прилагаемой обработке реализована передача из тонкого клиента во временную папку сервера сколь угодно больших файлов без перерасхода памяти, с индикацией прогресса и возможностью ставить на паузу и докачивать.
В настоящий момент в веб-клиенте новые методы платформы работают криво и выливаются в краши, так что функционирует пока только для тонкого клиента.
Вступайте в нашу телеграмм-группу Инфостарт