
{kind=link}
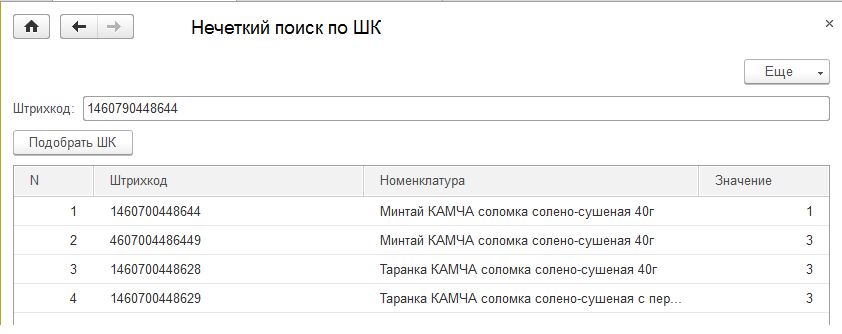
Делюсь обработкой, вдруг кому понадобится. Обработка написана для УТ 11.2, но подойдет для любой конфигурации, где есть таблица "Штрихкоды номенклатуры" с полями "Штрихкод, Номенклатура".
Для оценки "похожести" строк используется расстояние Левенштейна. Алгоритм достаточно простой, но хорошо показал себя на практике.
Обработка в цикле перебирает все записи из регистра сведений "Штрихкоды номенклатуры" и для каждого штрихкоды вызывается функция, которая возвращает расстояние между словами. Если расстояние не превосходит заданного параметра (для себя установил значение 3), то штрихкод добавляется в таблицу найденных значений.
При необходимости код можно доработать, добавив условие, которое будет отбразывать заранее неподходящие по длине штрихкоды.
Код основной функции:
Функция РасстояниеЛевенштейна(Строка1, Строка2)
л1 = СтрДлина(Строка1) + 1;
л2 = СтрДлина(Строка2) + 1;
Если л1 = 1 ИЛИ л2 =1 Тогда
Возврат 449;
КонецЕсли;
м = Новый Массив(л1 + 1, л2 + 1);
Для ы = 0 По л1 Цикл
м[ы][0] = ы;
КонецЦикла;
Для ы = 0 По л2 Цикл
м[0][ы] = ы;
КонецЦикла;
Для ы1 = 1 По л1 Цикл
Для ы2 = 1 По л2 Цикл
дифф = Сред(Строка1, ы1, 1) = Сред(Строка2, ы2, 1);
м[ы1][ы2] = Мин(м[ы1-1][ы2] + 1, м[ы1][ы2-1] + 1, м[ы1-1][ы2-1] + ?(дифф, 0, 1));
КонецЦикла;
КонецЦикла;
Возврат м[л1][л2];
КонецФункции
Вступайте в нашу телеграмм-группу Инфостарт