



{kind=link}
Это моя первая в жизни статья, конструктивная критика приветствуется.
Целевая аудитория - те, кто первый раз сталкивается с РБД.
Задачи РБД
Первое с чего необходимо начать – это ответить на вопрос «Зачем нам нужна РБД?». Вариантов ответов много, в частности:
- У нас есть филиалы, работающие в несвязных БД. Теперь мы хотим, чтобы информация между ними синхронизировалась;
- У нас есть филиалы, однако нагрузка на базу слишком велика (имеются ввиду блокировки транзакций, не объем БД) и онлайн актуальность (не путать с актуальностью в несколько минут, онлайн – это когда после выполнения каждой транзакции данные передаются во второй узел) данных для филиалов не требуется;
- У нас есть филиалы, в которых происходит только ввод данных (например, розничные магазины), поэтому можно существенно снизить нагрузку на центральную БД;
- Из соображений безопасности мы хотим, чтобы в филиалах даже теоретически(с админ. паролем) не было доступа к важным данным, например балансу предприятия.
В одном случае для меня были актуальны вопросы 2 и 4, в другом 2 и 3. Первый пункт слишком обширный и в рамках тематики данной статьи рассматриваться не будет.
Также лучше сразу рассмотреть проблематику транспорта файлов обмена, потому что в некоторых случаях она может наложить существенные ограничения на реализацию обмена данных. Сначала необходимо определить в каких филиалах точно появятся узлы РБД (обычно это региональные филиалы). Далее рассматриваем, где ещё мы хотим установить узлы РБД, и нужна ли в них онлайн актуальность. Например, для розничных магазинов далеко не всегда есть возможность установки даже модема, а установка беспроводной связи будет слишком дорогая. Здесь необходимо принять решение – возможно, данный магазин может работать в оффлайне и периодически обмениваться с центром (раз в день/раз в неделю) с помощью физического носителя, например флешки.
В некоторых случаях обмен посредствам физического носителя невозможен, например это очень удаленный филиал, где есть существенные проблемы с наладкой высокоскоростной связи. Здесь стоит примерно подсчитать объем информации при обмене. Часто при актуальности раз в час либо несколько раз в день достаточно 32к модема. Однако стоить помнить, что вместе с обновлениями данных придется иногда присылать обновления самой конфигурации или внешних файлов (печатный формы, фотографии товаров), поэтому периодически будет возникать ситуация, когда файл обмена существенно увеличиться из-за таких обновлений.
Топология
Итого мы получили следующие вопросы, на которые необходимо ответить:
- В каких подразделениях мы гарантированно будем устанавливать узлы РБД и есть ли там возможность установить высокоскоростной канал;
- В каких подразделениях установка узла РБД не требуется;
- Какие подразделения могут работать с актуальностью в несколько часов;
- Какие подразделения могут работать в оффлайн режиме (обмен данными меньше 3-4х раз в день).
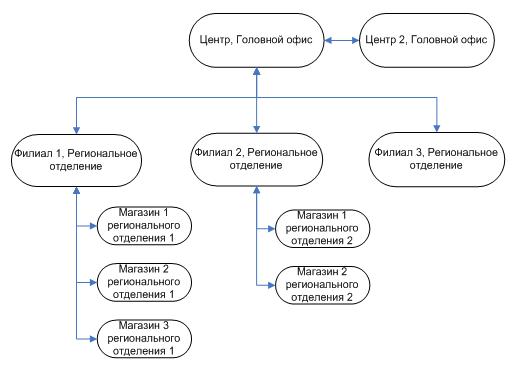
Ответив на эти вопросы, мы получаем приблизительную схему нашей РБД. Для крупных компаний обычно получается нечто следующее:

Рис 1. Типовая схема РБД крупной компании
Если с узлами «Филиал» все относительно ясно – это крупные центры, требующие автоматизации, то под узлами «Магазин» подразумевается узел с серьезной нагрузкой на БД при вводе данных, который для снижения нагрузки следует отделить. Например, магазин с 50-тью кассами и ежедневным товарооборотом больше 10000 единиц.
Потоки данных
Далее необходимо рассмотреть функциональную нагрузку на каждый из узлов, например:
- Магазины – ввод данных о собственном товарообороте и движении денежных средств. Аналитика поверхностная, только по своему магазину.
- Филиалы – ввод данных неавтоматизированных точек, бухгалтерия, зарплата и кадры, производство и т.п. Аналитика в рамках собственного филиала.
- Центр – ввод данных неавтоматизированных филиалов. Аналитика предприятия в целом.
Важно понимать в каких целях будет использоваться БД в каждом узле. От целей выстраиваются задачи, необходимые к реализации, например:
- Филиалы видят историю взаиморасчетов с контрагентами друг друга;
- Магазины видят остатки товаров во всем (либо части) предприятия;
- Аналитика доходов/расходов, выполнения бюджета и т.п.видны только в рамках иерархии собственного подразделения;
- Бухгалтерия, зарплата и кадры видны только в рамках иерархии собственного подразделения;
- Номенклатура, все её свойства и характеристики видны во всех узлах РБД;
- Относительно иерархии подразделений все данные попадают вверх, но фильтруются вниз;
- В центр попадает абсолютно вся информация о компании.
Ставя перед собой подобные вопросы можно ответить на самый сложный вопрос – какая информация, где и как должна курсировать между узлами РБД? Почему самый сложный? Зная, какие наборы данных курсируют между узлами, можно однозначно понять, как «нарезать» текущую БД, чтобы данные оставались логически целостными. Например, нельзя данные об остатках товаров отрывать от данных о текущих резервах.
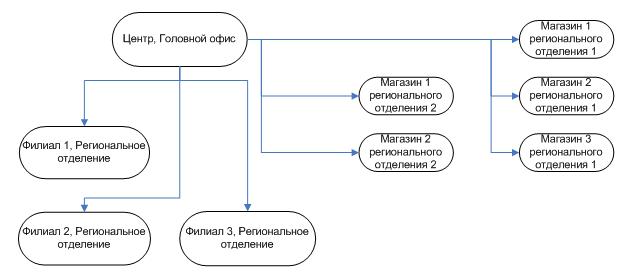
Теперь, в зависимости от потоков информации, перерисуем схему РБД:

Рис 2. Типовая топология РБД крупной компании
Что мы видим на рисунке 2? Согласно иерархии подразделений компании выстроилась топология потока информации между узлами БД. Также добавился узел «Центр 2», почему? При реализации топологии «Звезда» нагрузка на центр всегда выше, чем нагрузка на периферийные узлы, при этом часто нагрузка, генерируемая самим узлом, и так высока. Примеры использования узлов «Центр 1» и «Центр 2»:
- «Центр 1» служит только для консолидации данных остальных узлов РБД. Доступ к нему имеет только администратор. «Центр 2» служит для работы головного офиса;
- «Центр 1» служит для работы головного офиса. Однако тяжелые аналитические, тестовые, создающие огромную нагрузку на БД, операции выполняются в узле «Центр 2»; например восстановление последовательности, перепроведение закрытых периодов, формирование сводных отчетов по всему предприятию за длительный промежуток времени, формирование аналитики, приводящей к изменению данных;
- «Центр 1» служит для работы головного офиса. «Центр 2» является резервным, на случай непредвиденных ситуаций для быстрого восстановления всей РБД.
Реализация обмена
Существуют 2 варианта работы РБД:
- Автоматический – происходит без участия пользователя. Контроль за внештатными ситуациями,возложен либо на администратора БД, либо на продвинутого пользователя;
- Ручной – обмен происходит только по желанию пользователя.
По своему опыту приводил все реализации всегда к автоматическому варианту. Если были проблемы с транспортом файлов обмена (наличие сети в узле не постоянно), то максимум, что позволял пользователю – это нажать кнопку «Произвести обмен сейчас». Ситуации, когда помимо обновления данных идет обновление конфигурации желательно приводить тоже к полностью автоматическим (например, используя стороннее ПО).
Формирование пакетов обновлений
Так как есть однозначное решение о том, на какие узлы РБД возложены какие функции, то можно сформировать только тот пакет данных, который нужен этому узлу. С одной стороны, необходимо указать какие типы объектов будут синхронизироваться между узлами. Например, регистры бухгалтерии для узла «Магазин 1» не должны вообще синхронизироваться, т.к. данные вводятся только на уровне узла филиала. С другой стороны те типы данных, которые подлежат обмену необходимо фильтровать с привязкой к подразделению. Например, данные о поступлении денег узла «Магазин 1 филиала 2» могут находиться только в узлах «Филиал 2», «Центр 1» и «Центр 2».
Однако есть и обратная проблема, если слишком сильно фильтровать данные обмена, то пакет данных потеряет логическую целостность. Например, остатки товаров учитываются в разрезе складов, а резервы учитываются в разрезе фирмы в целом, тогда если фильтровать остатки товаров по складам и не фильтровать резервы, то данные будут некорректными.
Также следует решить, на каком этапе своей жизни объект подлежит обмену. Например, обмену подлежат только проведенные расходные накладные, но никак не просто сохраненные. Либо Расходные накладные магазинов никогда не выгружаются из узла «Центр», даже после их корректировки, однако нужно учитывать обратный эффект – данные могут быть рассинхронизированы, либо какие-то изменения могут быть затерты.
Важно понимать – при обмене между узлами, какой-то из них является приоритетным. Рассмотрим ситуацию:
- В узле «Магазин 1» создали документ;
- При обмене он попал в узел «Филиал 1»;
- Документ корректируется одновременно в обоих узлах.
Какой из документов будет считаться истинным? В 1С 8.х при использовании механизма «Планы обмена» по умолчанию приоритетным является главный узел, т.е. в данном случае изменения, сделанные в узле «Магазин 1» будут утеряны и заменены на данные из узла «Филиал 1».
Есть другая, более сложная ситуация, когда корректируют одновременно два связных объекта. Например, расходная накладная и ПКО по ней корректируются в разных узлах, здесь существует вероятность потери целостности, если изменят цены, сумму оплаты, контрагентов и тп.
Также немаловажно контролировать удаление объектов, иначе это может привести к тому, что, например, расходной накладной уже существовать не будет, а движения по бухгалтерскому учету останутся.
Механизмы обмена в 1С 8.х
Существуют два подхода для реализации:
- Механизм «Планы обмена»;
- Собственная реализация регистрации объектов.
Рассмотрим оба варианта.
Механизм планов обмена позволяет, без какой либо настройки, за несколько минут, создать РБД с полным обменом данными. Если установить флаг «Распределенная информационная база», то при создании пакета обновления будут выгружены и обновления конфигурации. Всего за несколько минут можно настроить и правила разрешения/запрета обмена различными типами данных, открыв состав плана обмена. Если установить флаг «Авторегистрация» в положение «Запретить», то данный тип объекта, без дополнительных усилий, никогда обмениваться не будет.
Под термином «Авторегистрация» понимается следующее – при любой записи объекта либо изменении его состояния, объект помечается как измененный, и при следующем цикле обмена будет выгружен.
Зачем нужна регистрация, почему не выгружать все и сразу? В любом случае файл, содержащий только изменения состояния БД, будет меньше полного снимка самой БД. Поэтому вариант полной выгрузки рассматриваться не будет.
Как настроить фильтрацию данных по принадлежности к подразделению? Здесь уже придётся программировать. В моей реализации на запись любого объекта была установлена подписка на событие «При записи», где, посредством свойства «ОбменДанными.Получатели», можно установить список получателей данного объекта. Т.е. при выгрузке стандартными средствами для узла, которого нету в списке, объект выгружен не будет. Есть и другое решение – выбирать выгружать ли объект можно непосредственно при выгрузке объекта, в процедурах «ПриОтправкеДанныхПодчиненному» и «ПриОтправкеДанныхГлавному» модуля плана обмена.
Оба варианта имеют право на существование. Однако в качестве лучшего варианта выбрал первый, потому что вычисление признака выгружаемости происходит сразу же при записи объекта, что увеличивает длительность записи объекта на 3-5% (можно оптимизировать, в некоторых случаях можно досвести до 0.01%) т.е. в среднем 0.1-0.3 секунды, а в случае расчета выгружаемости объекта непосредственно при отправке данных, которая и так создает существенную нагрузку на БД, это время будет составлять до нескольких минут.
Для полного понимания работы механизма «Планы обмена» рекомендую прочитать главу 15 книги «Профессиональная разработка в система 1С:Предприятие 8», Габец А.П., Гончаров Д.И.
Любая собственная реализация, на мой взгляд, либо повторит механизм «Планы обмена», либо будет выгружать объект сразу при изменении, либо будет выгружать больше, чем механизм «Планы обмена» (например, выгрузить все изменения за сегодняшний день). Данный вопрос не рассматриваю за неимением опыта реализации.
Транспорт
Задача транспортировки файлов от главного к подчиненному узлу сводиться к максимальной отказоустойчивости. Не редко файлы шифруются либо передаются по защищенному каналу. Для передачи файлов желательно использовать несколько различных служб, либо подготовить несколько различных вариантов подключения. Например, основной способ передачи – это используя FTP-сервер, подключенный через VPN-туннель; резервный – это e-mail сервер с TLS-подключением. Зачем нужен резервный канал с другой службой? Как показывает практика, использовать 2 различных FTPсервера менее надежно, чем FTPсервер и E-Mail.
Рекомендую службу создания пакета обновления отделять от службы транспорта, это повысит отказоустойчивость всего комплекса обмена данными. В случае, если служба, занимающаяся транспортом файлов, не отработает, то служба создания пакетов обновлений продолжит нормально работать и при некоторых условиях будет перезапускать службу транспорта и наоборот.
Моя реализация РБД
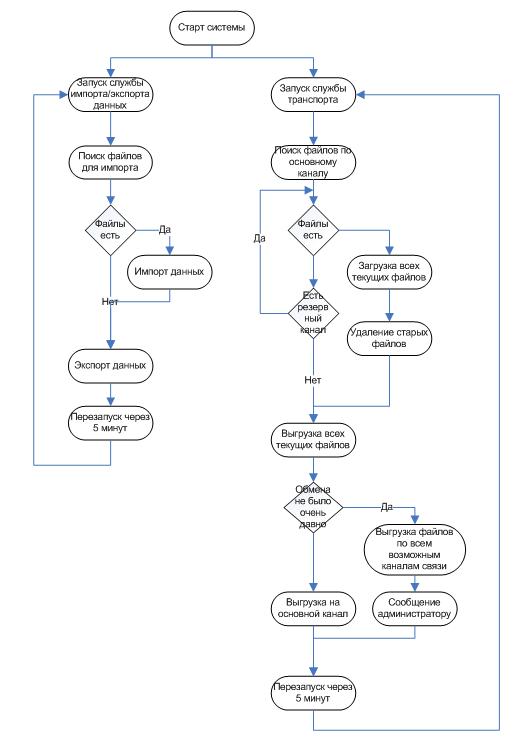
Реализация полностью автономна, поэтому как подзадача выступала максимальная отказоустойчивость. Отсюда получилось 2 службы – служба транспорта обновлений и служба импорта/экспорта данных. Обе службы работают независимо друг от друга.
После каждого успешного цикла импорта-экспорта данных сохранялось время последнего обмена с этим узлом. Если обмена не происходило очень долго, то транспортная служба начинала выгружать файлы во все, доступные ей, каналы связи из расчета на то, что второй узел все-таки получит обновления и выгрузит свои файлы. В случае исключительных ситуаций система сама отправляет сообщение администратору с подробным описание ошибки.
Для сокращения объема траффика xml-файлы упаковывались в zip-архивы. Система поддерживает два вида транспорта – FTP и E-mail.
В качестве настроек для фильтра данных существуют две таблицы. В одной (табличная часть планов обмена) хранятся условия по общим реквизитам (для каждого объекта система пытается найти этот реквизит), в другой настройки под конкретный объект метаданных. При записи любого объекта сначала происходит поиск условий по общим реквизитам (например, Подразделение), после чего система пытается определить, есть ли персональное правило на этот тип объекта по всем его реквизитам. Не рекомендую фильтровать списки – велика возможность ошибиться, например, из табличной части расходной накладной исчезнут несколько строк, а остатки при этом будут двигаться все и наоборот.
Важно понимать, под каким системным пользователем будут работать службы, т.к. может не хватить прав на создание файлов даже во временной папке 1С. Для отладки крайне рекомендую писать каждую, успешно выполненную, операцию в журнал регистраций, либо в txt-файл. В 1С 8.1 выполнение серверного кода отладить нельзя.
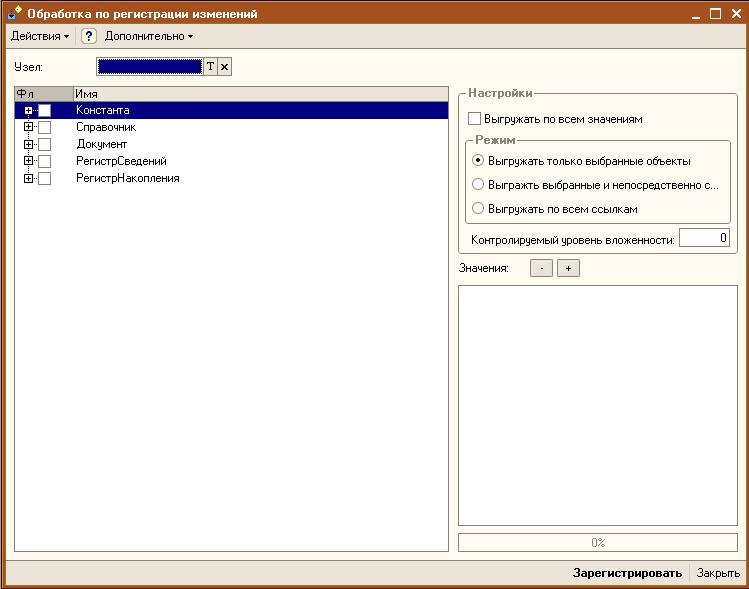
Для удобства отладки и настройки своей реализации прикладываю обработку "Регистрация изменений", описание которой находится в самой обработке.
Общая схема работы комплекса обмена данными указана на рис 3.

Рис 3. Собственная реализация РБД
Фильтрация данных происходит в подписке на событие «ПередЗаписью» каждого объекта. Не стоит забывать, что при создании начального образа узла данные тоже необходимо отфильтровать. Процедура создания начального образа довольно длительна, поэтому рекомендую оптимизировать по максимуму её код (например, кэшировать настройки фильтрации).
Послесловие
Главная задача – это ответить на список вопросов:
- Зачем нам нужна РБД?
- Чем не устраивает работа через RDP-клиент?
- Где и почему мы хотим установить узлы РБД?
- Как будет происходить транспорт обновлений?
- Какой уровень отказоустойчивости будет реализован?
Обработка "РегистрацияИзменений"
Обработка позволяет принудительно регистрировать изменения в объектах. Есть несколько вариантов регистрации изменений:
- Если установлена галочка на каком-либо метаданном и НЕ выбран ни единый объект и НЕ установлен флаг "Выгружать по всем значениям", то РЕГИСТРИРУЕТСЯ ТОЛЬКО ВЫБРАННАЯ ТАБЛИЦА;
- Если установлен флаг "Выгружать по всем значениям", то выбранные метаданные будут выгружен по всем объектам в цикле;
- Если переключатель установлен в режим "Выгружать только выбранные объекты", то буду выгружены исключительно выбранные объекты (например: установка флага на метаданном без выбора объектов равносильна включенному флагу "Выгружать по всем значениям" и переключателю в позиции "Выгружать только выбранные объекты";
- Если переключатель установлен в режим "Выгружать выбранные и непосредственно связанные объекты" то буду выгружены выбранные объекты и те объекты, существование которых зависит от существования выбранного объекта(например: у справочников - подчиненные справочники);
- Если переключатель установлен в режим "Выгружать по всем ссылкам", то буду выгружены ВСЕ объекты в которых присутствует ссылка на выбранный объект.
Из дополнительного функционала доступно:
- Перерегистрация зарегистрированных объектов, часто требуется для отладки;
- Удаление зарегистрированных, часто требуется для отладки;
- Печать изменений - печать полного перечня объектов, которые помечены как измененные;
- Печать дерева конфигурации - только для удобства просмотра всей конфигурации.
Вступайте в нашу телеграмм-группу Инфостарт