




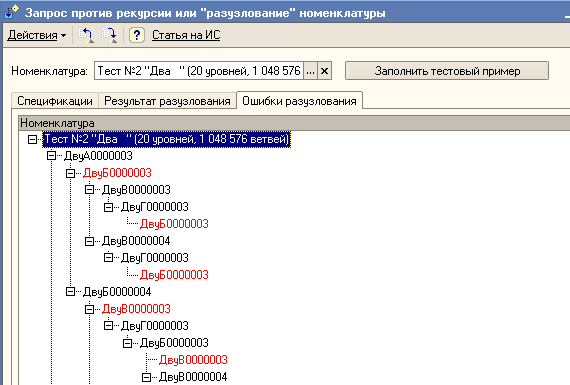
Предыдущие мои публикации Граф(ин) 7.7. и Граф(ин) 7.7. (дополнение) носили, скорее, умозрительный характер, имея одной из целей продемонстрировать, что деревья в частности и графы вообще вполне уживаются с семерочной платформой. Однако после появления статьи Запрос против рекурсии или "разузлование" номенклатуры мне просто некуда было деваться – и вот пришлось сваять небольшую конфигурацию для исследования «разузловательных» процессов. В конфигурации присутствуют два справочника: НоменклатурныеПозиции и Наборы. Содержимое справочника Наборы (с реквизитами Отец, Сын, Количество) как раз и определяет исследуемый граф.
Разумеется, я начал с
Тест № 1. "Десять" Справочник содержит 6-уровневый 10-арный граф , имеющий 1 000 000 различных ветвей и при обходе такого графа таблица ВремТаблица6 на выходе цикла алгоритма содержит 1 000 000 записей. Проще говоря, корневому элементу подчинены 10 элементов, каждому из которых подчинен одинаковый набор из десятка следующих элементов и т.д.
Ориентиром для меня служил пост № 118 из темы http://forum.infostart.ru/forum14/topic35991/ :
Через таблицу значений в 77 это сделать сложнее. У вас отсутствует команда НайтиСтроки , выбирающая по фильтру нужные строки из таблицы значений. Ну, раз взялся , то помни : - контроль зацикленности каждой ветки обязателен. 1. 4 мин - не о чем говорить 2. 3 мин - очень плохо 3. 2 мин - просто плохо 4. 1.5 мин - посредственно 5. 1 мин - хорошо 6. 40 сек - отлично 7. 20 сек - Арчибальд - СУПЕРСТАР на все времена ! ( в указанное время входит копирование элементов из справочника в таблицу значений)
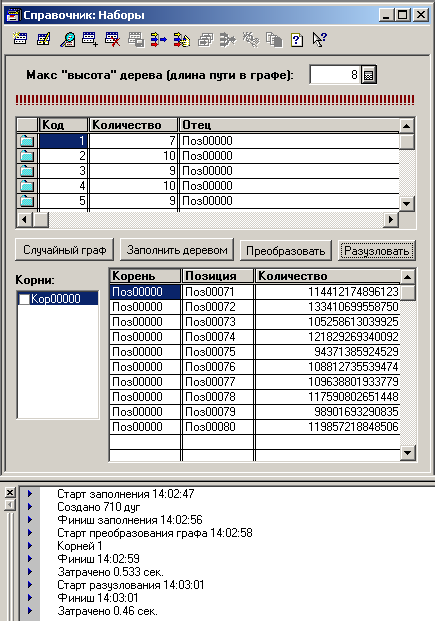
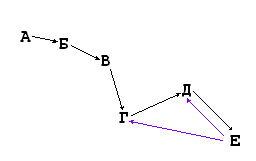
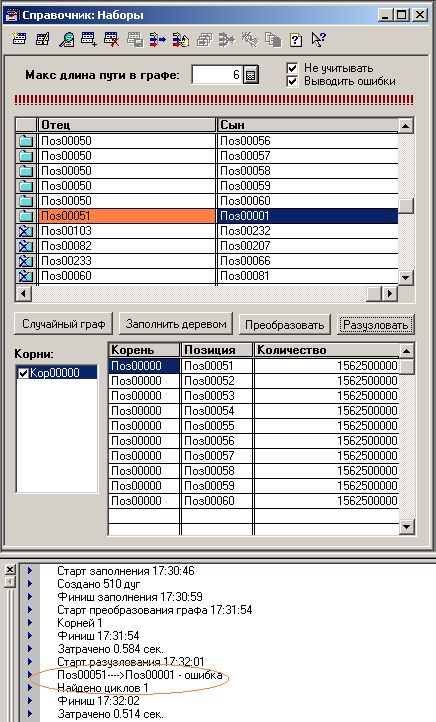
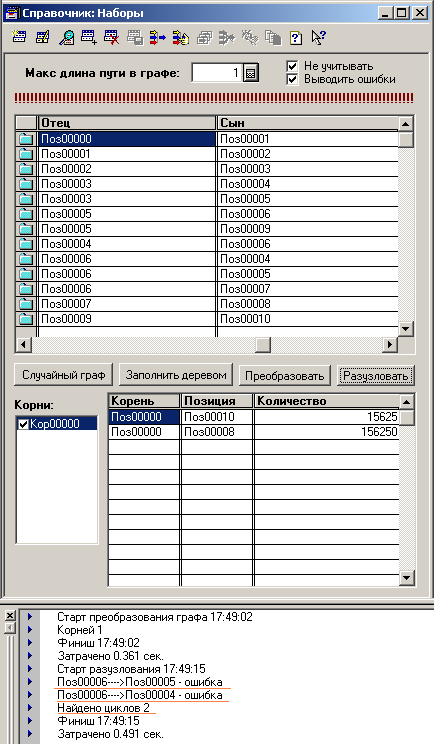
Ну, и сразу получил 0.777 секунды, из которых 0.5 - преобразование графа и 0.276 - собственно разузлование (скрин 1). Отнюдь не 20 сек, как в упомянутой статье. Но похуже, чем в статье Как не «попасть на миллион», решая задачу разузлования , хоть и не на два порядка.
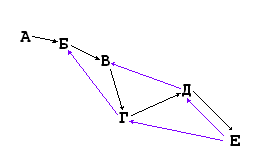
Ладно, думаю, попробуем 100 000 000 (скрин 2). 0.993 секунды.
Добрался аж до 100 000 000 (скрин 3). 1.525 сек. То есть "деревья" (которые и не деревья вовсе, на самом-то деле) из Теста №1 обходить неинтересно.
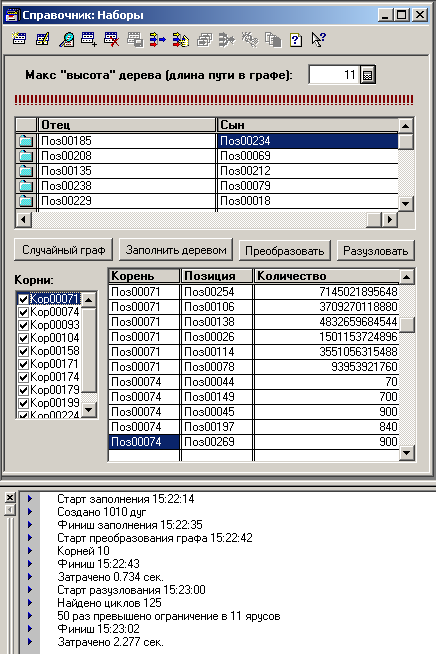
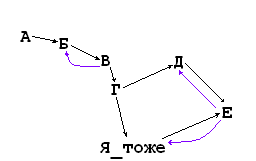
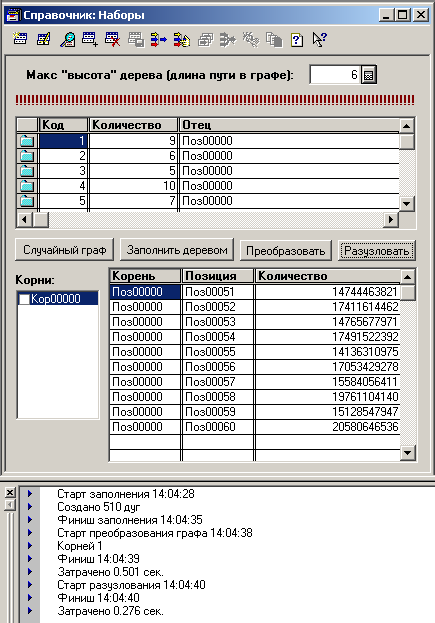
А вот заполнять список дуг (справочник Наборы) произвольным (псевдослучайным) образом, находить в полученном графе вершины, не имеющие родителей (корни), и разузловывать сразу все эти корни, либо несколько (по отметкам в списке корней) – достаточно познавательно (скрин 4). Все-таки 3.02 секунды. Правда, разузловывались десять позиций. Бывает и больше.
Все действия производятся в форме справочника Наборы. В частности, на форме кнопки для двух вариантов заполнения исходного справочника. Кнопка Преобразовать запускает конвертацию представления графа дугами в представление вершинами. Все коды открыты. В архиве – сохраненная конфигурация.
Попробуйте поиграться!
Ну и, наконец, вывод. Успешность (эффективность) решения задач весьма призрачно зависит от платформы. Зато сильно зависит от спроектированной структуры данных...
29.11.2010. Еще несколько слов о задаче разузлования. Теоретическая сложность этой задачи - О(N * lg N), где N - число (различных) узлов графа. Именно так вел бы себя алгоритм в упомянутой статье "Запрос против рекурсии...", если бы автор не отказался от конструкции "СГРУППИРОВАТЬ ПО" и не искал вместо ошибочной дуги графа все ошибочные цепочки, порожденные этой дугой. Применительно к задаче разузлования такой подход не учитывает наличия стандартизации узлов и деталей - а она реально существует. Гайка М10х17 - она и есть гайка...
Вступайте в нашу телеграмм-группу Инфостарт


















{kind=link}