Вышла первая версия бесплатного .Net-компонента Elisy.CfInspector для чтения CF-формата, совместимого с форматом 1С-конфигураций и внешних обработок. Для использования требуется .Net framework 4.0.
Вы можете ознакомиться с описанием CF-формата здесь.
Хотя использовать компонент можно из 1С при помощи компонента Elisy .Net Bridge, но максимальный эффект будет получен при использовании из .Net-проектов.
Для использования необходимо создать подходящий проект в Visual Studio. Добавить ссылку на сборку Elisy.CfInpector.dll. При необходимости вставить директиву:
using Elisy.CfInspector;
Пример обращения к компоненту:
var stream = new FileStream(@"D:\228\1Cv8.cf", FileMode.Open, FileAccess.Read, FileShare.Read);
Image image = ImageReader.ReadImageFrom(stream);
В результате вызова ReadImageFrom произойдет создание объекта типа Image. Image содержит несколько свойств, самым полезным из которых является Rows. Rows возвращает массив объектов ImageRow[]. Это и есть содержимое файла, записанного в формате CF. ImageRow определяет несколько свойств: Id – идентификатор данных, BodyRawData – тело в виде массива данных, Body – распознанное содержимое, которое может принимать типы: String, Image, byte[]. BodyType определяет тип данных:
- CompressedUtf8MarkedString – сжатая строка;
- CompressedImage – сжатый объект составного типа;
- Utf8MarkedString – несжатая строка;
- CompressedMoxcel – сжатый объект Moxcel;
- Unknown – неизвестный тип.
Пример простого запроса к свойству Row – получить все данные с составным типом:
var request = from ir in image.Rows
where ir.BodyType == ImageRowTypes.CompressedImage
select ir;
var array = request.ToArray();
В .Net framework 4 есть достойная фича: Parallel LINQ. Используя параллельные вычисления, запрос можно выполнить значительно быстрее. Достаточно воспользоваться конструкцией AsParallel():
var request = from ir in image.Rows.AsParallel()
where ir.BodyType == ImageRowTypes.CompressedImage
select ir;
var array = request.ToArray();
Вот еще несколько примеров запросов:
Выбрать все макеты:
var request = from ir in image.Rows.AsParallel()
where ir.BodyType == ImageRowTypes.CompressedMoxcel
select new { a = ir.Id, b = Convert.ToString(ir.Body) };
var array = request.ToArray();
Выбрать все основные объекты:
var request = from ir in image.Rows.AsParallel()
where !ir.Id.Contains('.')
select new { a = ir.Id, b = Convert.ToString(ir.Body) };
var array = request.ToArray();
Найти корневой элемент:
var request = from ir in image.Rows.AsParallel()
where ir.Id == "root"
select ir.Body as string;
var root = request.FirstOrDefault();
Желаем успехов в экспериментах.
Статья описывает CF-формат, совместимый с форматом 1С-конфигураций и внешних обработок. Планируется, что описание данного формата ляжет в основу .Net-компонента Elisy.CfInspector. Появление такого инструмента даст возможность запустить новые проекты:
- CfXmlDoc - построение файлов помощи (SDK help) для 1С-разработчиков на основе XML-комментариев модулей 1С;
- CfProject – распаковка и сборка конфигураций 1С для удобного хранения в системах управления версиями, например, Subversion (SVN);
- CfSecurity – защита конфигураций через компилирование 1С-модулей в сборки .Net и запуск их из 1С через Elisy .Net Bridge.
Общее расположение блоков CF-файла представлено на рисунке:
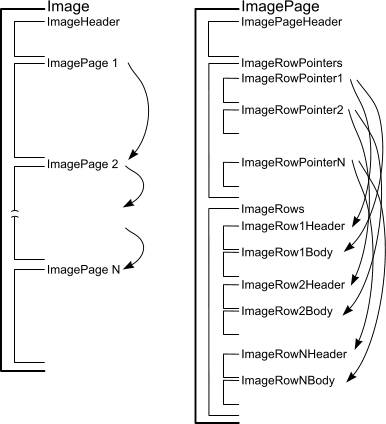
Файл состоит из заголовка образа (ImageHeader) и следующими за ним страницами (ImagePage1-ImagePageN). Заголовок образа состоит из 4х байт сигнатуры, которая равна 0xFF 0xFF 0xFF 0x7F, 4х байт размера страницы и 8 зарезервированных байт. После заголовка файла идут по порядку страницы с данными. Каждая предыдущая страница ссылается на последующую.
Каждая страница (ImagePage) состоит из заголовка страницы (ImagePageHeader), группы указателей на записи данных (ImageRowPointers) и области данных (ImageRows).
Заголовок страницы ImagePageHeader содержит в себе: зарезервированные 2 байта 0x0D 0x0A, 27 байт текстовой информации и еще зарезервированные 2 байта 0x0D 0x0A. Текстовая информация содержит 3 шестнадцатеричных числа: общий размер данных всех страниц (FullSize), размер текущей страницы (PageSize) и адрес следующей страницы в файле (NextPageAddress). FullSize проставляется только для первой страницы цепочки страниц. Для остальных страниц цепочки это значение 0. Для последней страницы цепочки NextPageAddress принимается равным 0xFF 0xFF 0xFF 0x7F.
Блок указателей на данные (ImageRowPointers) занимает размер, указанный в значении PageSize страницы. Каждый указатель состоит из 4х байт адреса заголовка данных (HeaderAddress) и 4х байт адреса тела данных (BodyAddress). В конце каждого указателя помещается сигнатура 0xFF 0xFF 0xFF 0x7F. Адреса указывают на расположения внутри текущей страницы на область данных (ImageRows).
Заголовок данных (ImageRowHeader) начинается с блока заголовка страницы ImagePageHeader, который сообщает, сколько байт отведено под заголовок. Далее идут 20 зарезервированных байт, UTF-16 строка идентификатора данных (Id) и 4 зарезервированных байт.
Тело данных (ImageRowBody) начинается с блока заголовка страницы ImagePageHeader, который сообщает, сколько байт отведено под тело данных. Если тело данных начинается на 0xEF 0xBB 0xBF (сигнатура UTF8), то тело содержит UTF-8 строку. Иначе тело данных содержит упакованные данные. Если распакованные данные начинаются на 0xFF 0xFF 0xFF 0x7F, то содержимое – совокупность объектов данных, и они записаны в CF-формате. Иначе содержимое данных – это строка сериализации.
Вступайте в нашу телеграмм-группу Инфостарт