


Введение
Я хочу представить вам результат своих экспериментов с алгоритмами распознавания образов с обучением с первого раза (так называемый One Shot Learning). В результате экспериментов выработались определённые подходы к структуризации изображения и в итоге они воплотились в несколько взаимосвязанных алгоритмов и рабочее приложение на Android которое уже можно использовать для работы совместно с решениями на 1С посредством приема HTTP-запросов от приложения.
Ссылка на приложение: https://play.google.com/store/apps/details?id=ru.travelfood.bitmaps
Моя цель была создать алгоритм с понятным принципом работы который может найти абстрактные зависимости в картинке с первого раза (обучиться) и показать приемлемое качество распознавания (поиска подобных абстрактных зависимостей) на последующих циклах распознавания. По сути цель алгоритма структурировать изображение чтобы его можно было распознавать как к примеру штрих-код, т.е. идентифицировать предметы без использования штрих-код или иных меток
Как это устроено
Основная идея такая: изображение- образец должно быть структурировано, т.е. информация в нем должна быть уменьшена до необходимого минимума, но так чтобы не терялся смысл. Например художники рисуют скетчи – всего в несколько точных линий художник может изобразить лицо человека или какой то предмет и зрителю будет понятно что изображено. Фотография содержит матрицу N*M пикселей каждый пиксель содержит сколько то бит информации о цвете, а если представить это все в виде параметров линий то объем информации резко уменьшается и обработка такой информации гораздо проще. Примерно тоже самое должен делать алгоритм. Он должен выделить главные детали в кадре – то что несет в себе основную информацию и отбросить все лишнее.

Алгоритм находит структуру векторов по границам объектов в образце и такую же структуру в распознаваемом изображении. Для того чтобы получить вектора изображение проходит несколько стадий обработки
- Переводится в монохром по простой формуле (Red+Green+Blue)/3
- Вычисляется градиент для каждой точки матрицы
- Находятся наиболее значимые в весовом отношении области градиента
- Ищутся цепочки векторов, покрывающих эти области
- Далее происходит зацикливание шагов для получения в итоге минимального количества векторов несущих в себе максимум информации.

В анализируемом алгоритме происходит тоже самое. Далее полученные массивы векторов сравниваются:
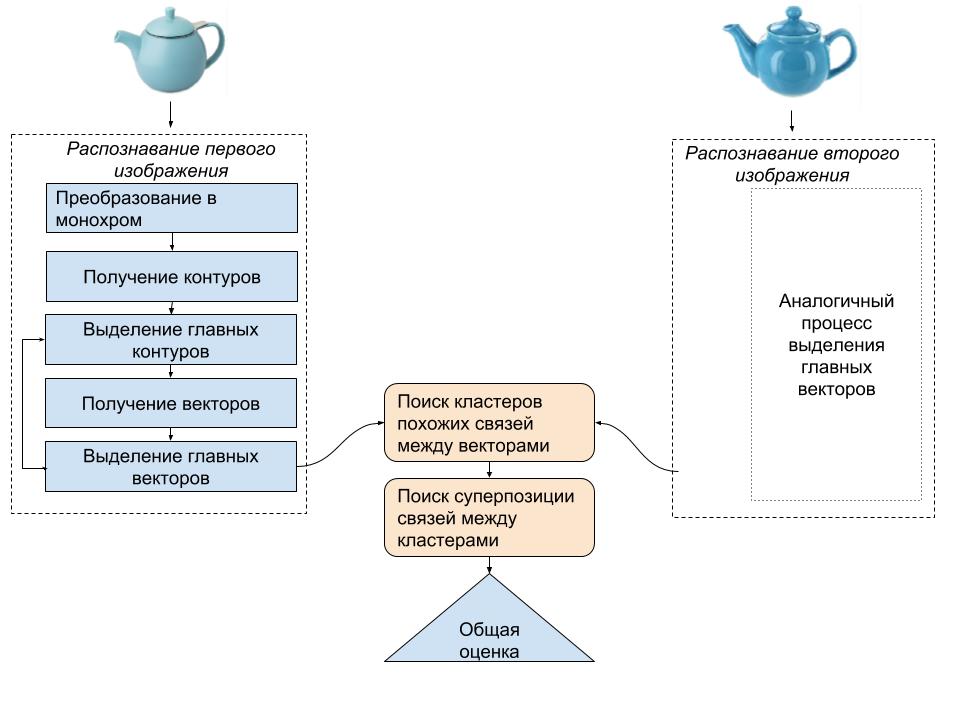
Сначала алгоритм пытается зацепиться за какие то похожие части (локальные кластеры). Например он может найти бровь похожую на бровь в образце, а потом найти нос, похожий на нос.
А потом ищется уже похожее взаимосвязь между локальными кластерами. Например бровь + нос + еще бровь. Уже получается более сложный кластер.
И т.д. пока не получится картина из отношений между кластерами которая соберет в себе все или почти все векторы изображения. Т.е. например из бровей, глаз, носа и т.д. не получится лицо.
Таким образом маленькие детальки входят в общую картину и происходит лавинообразное распознавание распознавание (узнавание) образа.
Сама классификация построена по принципу поиска наиболее похожего изображения из хранимых. Наиболее похожее – это имеющее наибольшее количество совпадающих векторов с наименьшими отклонениями по отношению к общему объему векторов в образце.
Обучение в несколько этапов
Не смотря на то что алгоритм может эффективно работать с одного образца, имеется возможность повышать точность распознавания, анализируя несколько образцов. Это не реализовано в данной версии, поэтому я просто расскажу про такую возможность, это очень просто. Принцип обучения на нескольких образцах заключается в отбрасывании лишних векторов. Лишние – это те которые не вошли во взаимно найденный кластер векторов. Например на образце может быть тень, которая распознается как граница, а на следующем образце ее может не быть.
Таким образом если вектор входим в состав кластера который найден в сохраненном образце и в анализируемом то он получает +1 балл, а если нет то ничего не получит. Спустя нескольrо обучений вектора которые набрали мало баллов удаляются из сохраненного образца и более не используются для анализа.
Почему не нейросети?
Приведу несколько причин против нейросетей:
- Требуются большие датасеты для обучения, которых может просто не быть в распоряжении. Т.е. например имеется один образец или его изображение и сразу же система должна начать его распознавать
- Большие мощности для обучения. Если помножить на большой размер классификатора то требуются серьёзные вычислительные мощности
- Непрозрачность алгоритма, невозможность отладки и прямого влияния на результат. Очень сложно если не сказать невозможно понять логику распределения весов. Это и сила и слабость.
Работа приложения и связь с 1С
Приложение работает с матрицей 100*100 пикселей, преобразует картинку к монохромной матрице такого размера. Алгоритму не важно под каким углом находится образец и его размеры в некоторых пределах тоже.
Принцип работы с приложением такой: показывается один образец, после чего его нужно как то обозвать и сохранить, потом показывается следующий(в этот момент он уже пытается найти что то похожее и это может выглядеть как полная чушь – это нормально в процессе наполнения классификатора) и т.д. с каждым образцом Т.е. в памяти приложения храниться база классификатора. После того как все образцы по 1 разу показаны и сохранены можно проверять распознавание.
Слева показывается результат выделения значимых областей текущего изображения и совпадающие векторы в нем (зеленым цветом), а справа показываются структуры векторов найденная и наиболее подходящая из сохраненных и красным цветом выделены похожие вектора на сохраненной структуре. Таким образом красным и зеленым цветом подсвечены структуры векторов которые алгоритм считает похожими.
Можно сохранить несколько образцов. И показывая новое изображение алгоритм найдет наиболее подходящее из них и покажет похожие части.
Для связи с 1С или другими программами приложение отправляет GET-запрос на адрес указанный в настройках. По сути он добавляет наименование распознанного изображения к строке запроса.
В настройках должен быть адрес с ключом параметра в таком виде
[АдресВашегоСервиса]/hs/oneshot/result/?res=
Например http://192.168.1.4:2312/testws/hs/oneshot/result/?res=
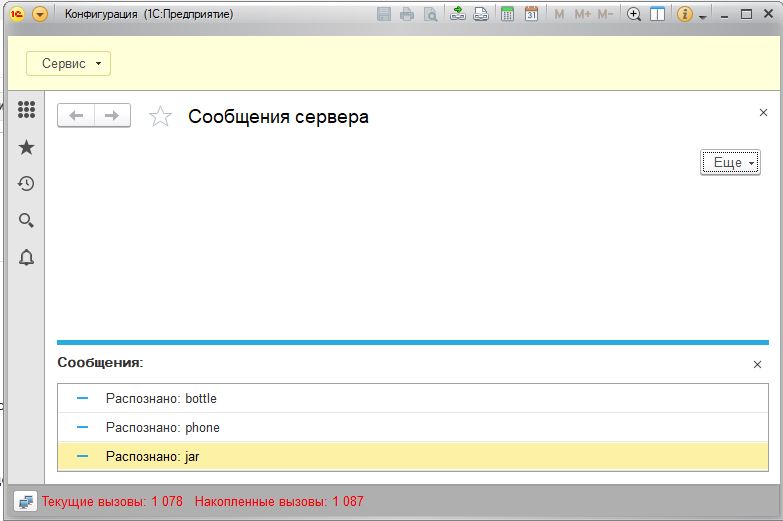
Для демонстрации приложена тестовая база, в которой реализован веб-сервис и обработка для показа сообщений веб-сервиса. Ну и работа всего этого вместе такая – делается снимок в приложении, распознается и посредством веб сервиса выводится сообщение в 1С:
Для чего может применяться
Применение алгоритма обусловлено его возможностями и ограничениями. Этот алгоритм ближе к линейным алгоритмам чем нейросети, следовательно уровень абстракции его ниже. Но это компенсируется простотой обучения и предсказуемостью результата.
Я вижу его применение для идентификации промышленных объектов, товаров и сырья требующих идентификации. Например сканирование продукции на производственной линии. Также например это может быть сканирование объектов на которые нельзя или нерентабельно наносить штрих-коды или другие метки.
Также естественно этот алгорим может применяться для любых задач классификации и распознавания для которых применяются другие алгоритмы распознавания. Например для распознавания лиц
В данный момент работа над улучшением алгоритма и приложением продолжается. Не смотря на то что он сейчас показывает достаточно хорошее качество распознавания он пока не вполне готов к промышленной эксплуатации. В частности планируется добавить потоковую обработку изображения, повысить быстродействие.
Вступайте в нашу телеграмм-группу Инфостарт