Меня зовут Станислав Алексенко, я работаю руководителем направления 1С в компании UTG. UTG отвечает за наземное обслуживание пассажиров и самолетов: регистрацию пассажиров, погрузку их багажа, подготовку самолетов к вылету, их буксировку, обслуживание и ремонт. В авиации такие компании называются «хэндлеры», и UTG самый крупный независимый хэндлер в России.
В своем докладе я расскажу, как можно организовать работу внутренней команды 1С с помощью Канбан.

Сразу скажу, чем Канбан не является и чем он является – что я буду иметь в виду в своем докладе.
Канбан – это не доска со стикерами. Точнее, не любая доска со стикерами выполняет роль Канбан-доски.
Я буду употреблять термин «Канбан» в его прямом значении: в переводе с японского это слово означает «знак, вывеска». Буду рассказывать о том, какие знаки нам подает Канбан-система, и как такую систему построить.
Сразу скажу, что в Канбане более сотни самых разных практик. Я буду говорить только о первых трех самых простых. Но Канбан хорош тем, что даже применение этих простых практик уже помогает и дает хороший эффект.
Команда и заказчик
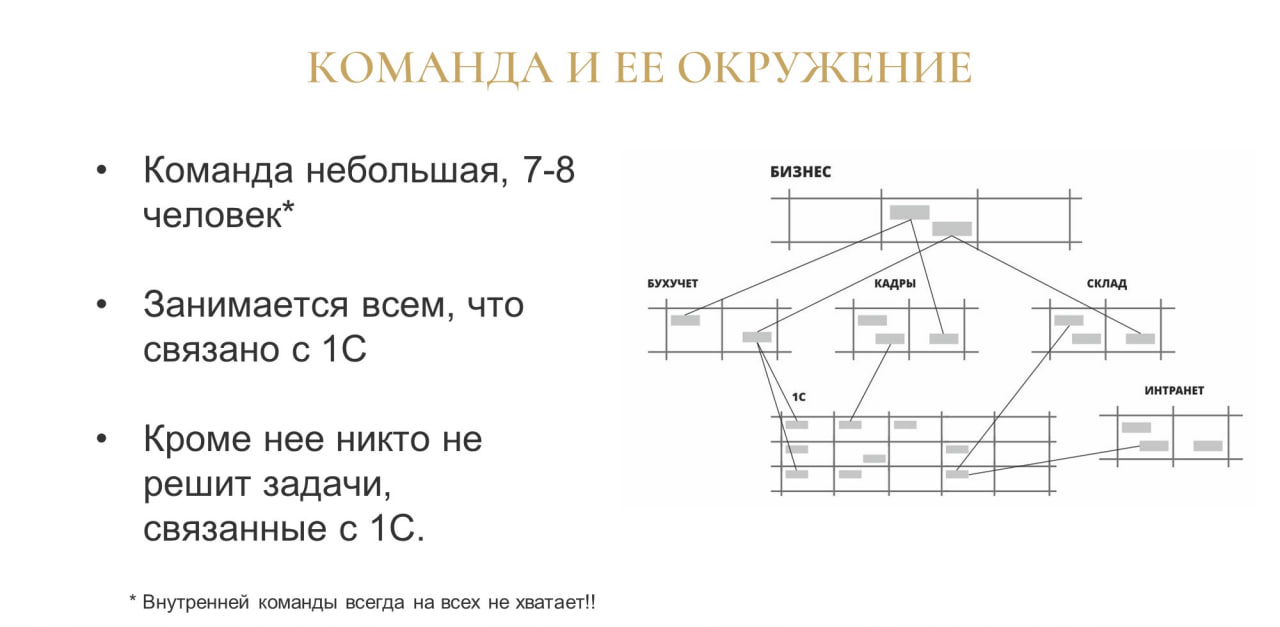
Для начала расскажу о команде, о которой буду вести речь.
-
Это небольшая команда из 7-8 человек, которая состоит из программистов, аналитиков и консультантов.
-
Это – внутренняя команда, которая занимается всем, что связано с 1С
-
Команда обычно работает в условиях жесткого прессинга – на схеме я попытался изобразить, что у команды есть много заказчиков (бухгалтерия, кадры, склад), которым что-то постоянно нужно. Задач гораздо больше, чем можно сделать и остро стоит проблема, какие задачи делать, а какие не делать, в каком порядке их делать и т.д.
-
Команда делает самые разные задачи, которые относятся к стратегическим проектам компании – например, компания решила выпустить новый продукт или новую услугу, а для этого нужна бухгалтерская, экономическая, кадровая, складская и пр. обвязка, и поэтому здесь есть работа для 1С.
-
Помимо того, что команда делает локальные задачи своих внутренних заказчиков, она взаимодействует с соседними айтишными командами.

Хотя работа интересная и разнообразная, у команды есть проблемы.
-
Во-первых, команде постоянно приходится прерываться и бросать то, что они сейчас делают, чтобы взять новую срочную задачу. Как ни планируй, как ни пытайся построить работу с заказчиком, очень часто прилетает что-то внеплановое.
-
Как следствие, обещания по срокам, которые команда дает заказчику, не выполняются. Сроки срываются. Отношения с заказчиками из-за этого портятся.
-
И команде постоянно приходится прерываться, чтобы дать точную оценку новых задач. Почему-то это часто не считается за работу, хотя на самом деле отнимает кучу времени, и заказчик ждет эти оценки с очень высоким приоритетом.

Проблемы есть и у заказчика.
Задачи делаются долго:
-
трехдневная задача (job size) может делаться неделями;
-
вторая аналогичная или похожая задача может делаться дня за четыре;
-
а другая подобная задача не делается вообще – она погрязает в бэклоге и ее оттуда ничем не вызволить.
Сколько времени займет та или иная задача – непонятно ни команде, ни заказчику, и эта нестабильность поставки всех бесит.
Заказчику постоянно приходится пинать команду, чтобы получить свои задачи в срок или вообще когда-нибудь. Команде тоже не нравится, когда ее пинают.
Так дальше жить не хотелось ни заказчику, ни команде. Пробовали разные способы оценки задач, планирования, прогнозирования сроков, но получалось не очень. Узнали о Канбан, решили попробовать и стало получаться.
Методы работы в Канбан

Первый и главный метод Канбана – это визуализация.
На слайде всем вам знакомая Канбан-доска. Это еще не Канбан, потому что данная доска нам еще никаких сигналов не подает. Мы просто выложили на нее все задачи, какие есть.
Для начала важно действительно вывести на доску все задачи команды.
Не менее важно, чтобы формулировки этих задач были для заказчика узнаваемыми, чтобы он понимал, что он именно это заказывал. Не нужно дробить задачи на части и делать эти кусочки вразнобой, а потом пытаться что-то из этого собрать. Такая доска будет не особо полезна.
Обратите внимание на две жирные линии на слайде – парадоксально, но эти линии в Канбане называются «точками»:
-
Линия слева, которая отделяет бэклог от колонки «сделать» — это точка принятия обязательств. Если задача пересекла эту линию, это означает, что заказчик готов ее принять в той формулировке, в которой она изложена. А команда обязуется эту задачу сделать. Почему я делаю на этом акцент? Потому что очень часто команда выступает в роли экспертов и участвует в обсуждении каких-то перспективных проектов и задач, которые то ли будут сделаны, то ли не будут, то ли нужны, то ли не нужны. Поэтому важно разделять те задачи, под которыми мы подписались, от тех задач, которые мы просто обсуждаем с заказчиками.
-
Толстая линия справа – это точка поставки. Здесь немного проще, по крайней мере, в 1С. Это точка, после которой задача считается сделанной. Например, у нас сделанной считается задача, которую мы выложили на прод, она работает и прошло какое-то разумное время, в течение которого к ней нет особых претензий. После этого мы считаем ее готовой и закрываем.
Почему для признания задачи готовой должно пройти определенное время? Потому что здесь внутри команды может возникать конфликт о том, что значит «задача сделана».
-
Программист может считать, что задача сделана, хотя она не протестирована, но у него есть какие-то ощущения, что все хорошо и программа должна работать.
-
По мнению тестировщика задача тоже может быть сделана, так как он ее протестировал и вроде все хорошо.
-
Но у заказчика может быть совсем другой взгляд на эту задачу. Протестированную задачу могут вернуть по разным причинам: мы не поняли ТЗ, появились новые требования, которые нужно учесть и прочее.
Поэтому для нас точкой поставки является задача на проде, которая принята заказчиком и прошло какое-то разумное время (для маленьких задач – пару дней, для больших – пару недель). Тогда мы ее закрываем.
В точке принятия обязательств мы просим заказчика сформулировать критерии готовности задачи definition of ready в определенном формате бизнес-требования. Это небольшой и простой шаблон, который заказчик заполняет, плюс мы с ним обсуждаем, правильно ли мы это бизнес-требование поняли.
Задачу, для которой сформулированы критерии готовности, и команда понимает, что нужно сделать, мы можем брать в работу. Перемещаем ее из бэклога в колонку «Сделать» и берем на себя обязательство по ее выполнению.
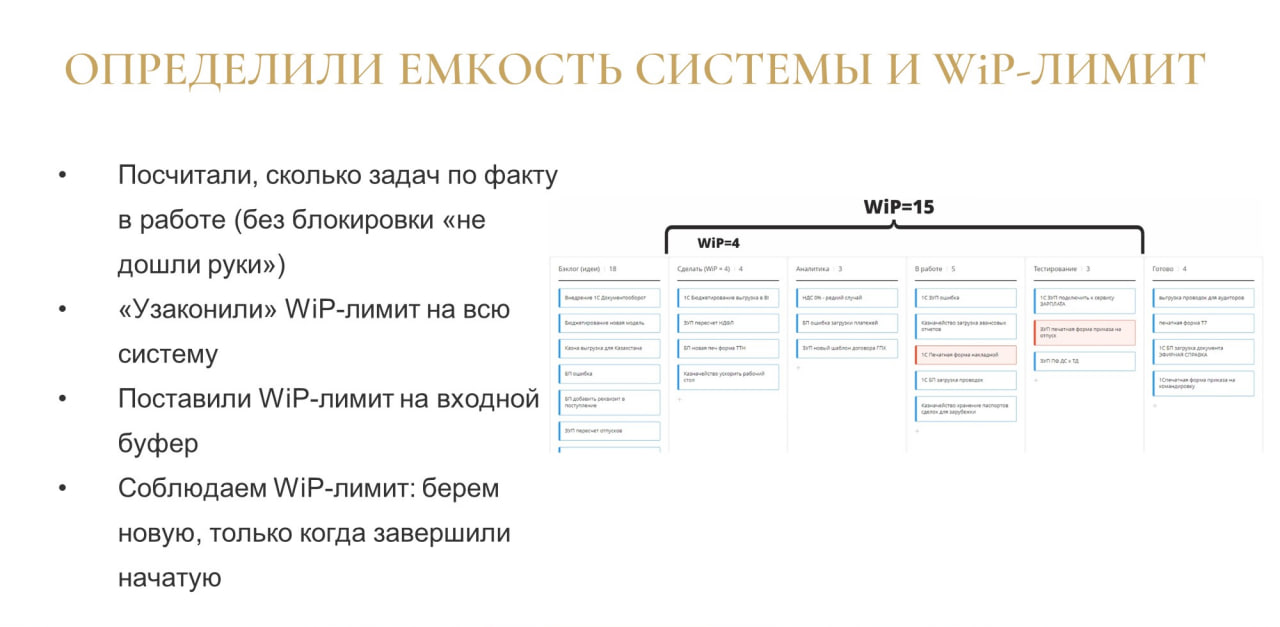
Как я уже сказал, Канбан-доска еще не является Канбан-системой и никаких сигналов еще не подает. А что нужно сделать, чтобы она начала подавать сигналы?
Для этого есть вторая практика – это определение емкости системы и WiP-лимита. WiP-лимит – это от английского Work in Progress, количество или объем незавершенной работы.
Интуитивно понятно, что если нас завалить задачами, мы, скорее всего, каждую из задач будем делать дольше. Но, если мы будем заниматься только одной какой-то задачей, это будет неэффективно. Нужен какой-то разумный компромисс.
Канбан предлагает определить WiP-лимит, но не говорит, как это сделать. К сожалению, каких-то расчётных методов для определения нет. Нет такого, что вы количество программистов умножите на что-то и у вас получится какая-то цифра. Задачи разные, заказчики разные, команды и технологии разные (в 1С – одна технология разработки, а в Java – другая) и т.д. Поэтому значение WiP-лимита определяется экспериментальным образом.
Как сделали мы. Мы стали ежедневно проводить Канбан-митинг (о нем расскажу подробно чуть позже, но если вкратце, это просто планерка по утрам) и стали в обязательном порядке отмечать блокировки по задачам – они на схеме помечены красным.
Jira блокировать задачи умеет, и можно пометить задачу, как заблокированную: она окрасится красным. Это значит, что над этой задачей мы конкретно сейчас не работаем. По разным причинам. Может, потому что кто-то заболел или ушел в отпуск, или мы ждем соседнюю команду, ждем админа, ждем приходящего специалиста, который у нас доступен по средам (а сейчас, допустим, четверг), ждем выкладки на прод и прочее. В таких случаях мы задачей не занимаемся и не можем ее подвинуть на доске вправо ближе к завершению.
В какой-то момент мы обратили внимание на то, что многие задачи блокируются с формулировкой «Не дошли руки». Оказалось, что из примерно 28-30 задач, которые мы приняли в работу, у нас одновременно выполняется не больше 14-16. Остальные простаивают. На это обратили внимание, когда заказчик поинтересовался задачей, которая давно взята в работу, но не выполняется, а она ему сейчас очень нужна. Мы бросили другую задачу и взялись за эту. Получается, что у нас в работе те же 15 задач, но уже немного другие.
После этого мы решили, что, скорее всего, 15 задач – это и есть реальная емкость нашей Канбан-системы, куда включаются задачи между точкой принятия обязательств и точкой поставки. Это количество на удивление стабильно – если мы берем чуть-чуть больше задач, то мы в любом случае над какими-то из них перестаем работать. После того как мы это значение определили, мы его узаконили и написали над доской «15». Но, к сожалению, Jira не умеет ставить лимит на всю систему, только по колонкам.
Сейчас немного отвлекусь на инструменты.
Я говорю про Jira, но Jira не самая лучшая система для Канбана. Она поддерживает далеко не все практики, а те, которые поддерживает, поддерживает не в полном объеме или частично. А еще вы Jira часто делите с кем-то еще, и полностью под себя вам ее настроить не дадут. Это еще больше снижает ее возможности по поддержке практик Канбана.
Для Канбана по всем параметрам идеальна физическая доска. Вы ее разрисовываете, как хотите, клеите стикеры – красота. Но с ней невозможно работать, когда команда удаленная. И, самое важное, физическая доска не собирает статистику, а Jira собирает. Поэтому и нужна Jira. А зачем нужна статистика, я расскажу попозже.
Итак, мы узаконили WiP-лимит и стали его придерживаться. Честно говоря, это потребовало усилий, потому что хороший менеджер максимально утилизирует ресурсы и не допускает простоев в команде. Однако, если взять новую задачу и не передать на прод предыдущую, можно столкнуться с ситуацией, когда при тестировании задача потребовала привлечения программиста. Мы теряем время на переключение, приходится бросать ту, заниматься снова этой – от этого едут сроки.

Когда программист освобождался, но пока не мог взять новую задачу в работу, у него была возможность:
-
Помогать коллегам с задачами справа, например, помогать их тестировать.
-
Взять какую-нибудь задачу из техдолга.
-
Посмотреть статьи или видео с конференции.
-
Подготовиться к сдаче экзаменов и т.д.
Какие сигналы нам стала давать эта система.
Если у нас WiP-лимит – 15, а у нас в работе 14 задач, то она подает сигнал «вытяни еще одну задачу». Канбан – это вытягивающая система. Пока что это один примитивный сигнал, но дальше она будет подавать больше сигналов.

Я рассказал о двух практиках (визуализация и WiP-лимит). Они позволяют сделать так, чтобы однотипные задачи проходили по системе за более-менее стандартное время. До этого похожие задачи часто решались от двух дней до двух недель. Это не очень хорошо.
Но третью проблему – с заказчиком, который заваливает нас новыми срочными задачами, эти две практики решить не помогут. Для этого есть третья практика Канбан – разделение WiP-лимита всей системы еще и по сервисам.
Почему это разделение нужно? В предыдущем примере у нас есть система, в которой WiP-лимит равен 15. Допустим доска стала пустой, и система всеми силами начинает говорить: «Возьми еще 15 задач». При этом один из заказчиков, например, отдел кадров, умудрился наделать как раз 15 бизнес-требований. Мы посмотрели, решили, что можем взять эти 15 задач в работу. Если мы вытянем эти 15 задач себе в систему, все будет забито задачами отдела кадров. А это не очень хорошо, потому что завтра придут другие отделы, которые припозднились с задачами, а мы их уже взять в работу не можем.
И снова складывается ситуация, что мы что-то нарушаем. В данном случае мы нарушаем неписанное для внутренней команды SLA по работе с разными заказчиками.
Как можно решить данную проблему? Для этого необходимо порефлексировать над теми сервисами, которые команда оказывает внутренним заказчикам, проанализировать, какой на них спрос, и для каждого сервиса определить WiP-лимит.
В результате в нашу систему с карточками добавляются еще свим-лайны (горизонтальные плавательные дорожки). Каждая «плавательная дорожка» — это один из сервисов, который мы оказываем нашему внутреннему заказчику.
Рассмотрим свим-лайны, которые показаны на слайде:
-
Самая верхняя дорожка называется Expedite – это термин Канбана, означающий критичный баг. Эта дорожка идет вне общего WiP-лимита системы, потому что когда у нас критичный баг, прод лежит, и нам точно не до развития. Мы все бросаем и направляем все силы на то, чтобы его починить. В данном случае WiP-лимит для дорожки Expedite составляет 1, потому что даже с двумя одновременными багами мы не справимся, у нас не очень большая команда.
-
Следующие два свим-лайна посвящены проектам уровня всей компании. Я уже говорил, что когда мы продаем новый товар или услугу, для этого нужна какая-то бухгалтерская (кадровая, складская, какая угодно) обвязка или интеграция с чем-то. В моем примере на картинке это два свим-лайна: один проект называется «Затраты», второй называется «Склад». На каждый из них мы отвели по 4 из 15 наших емкостей системы, итого на 2 проекта получается 8 из 15, что уже достаточно много. У этих задач высокий приоритет.
-
Следующая строка – это «Прочие», у нее WiP-лимит равен 5, а заказчиков у нас больше, чем 5. Это задачи, у которых обычно не четкой даты, это текучка. Можно сделать раньше, можно сделать позже – в этом ничего страшного нет. Приоритет у них, конечно, ниже, чем у критичных багов и чем у каких-нибудь стратегических проектов.
-
Отдельно выделена красным дорожка с задачами отдела кадров. На ней WiP-лимит составляет 1, потому что мы так договорились. Мы договорились, что отделу кадров мы всегда будем делать какую-то одну задачу. Сейчас эта дорожка пустая – в ней ни одной задачи нет. Для нас это сигнал, что по неписанному SLA нужно что-то для кадров делать, но сейчас нам делать нечего. Мы можем сходить в отдел кадров, спросить, есть ли у них для нас какая-нибудь задача. Скорее всего, они скажут, что есть, что через пару дней ее принесут. Если так, мы этот слот ничем не забиваем, занимаемся чем-то своим, например техдолгом, и ждем, когда принесут. Если они скажут, что в этом месяце никаких задач не ожидается, мы ставим в эту колонку «0» с пометкой: «До такого-то числа мы у отдела кадров задачи не берем», а эту «1» переписываем в другое место.
Распределение ёмкости системы по сервисам не прибито гвоздями – оно меняется в зависимости от спроса. Сейчас, допустим, нет спроса на кадровые задачи, так зачем мы будем резервировать систему под это дело?
Ниже нарисованы еще несколько дорожек, они обведены прерывистой линией – это сезонные работы, которые мы делаем.
Например, мы обновляем наши 1С, которые сильно модифицированы, и это занимает не день, не два, а несколько недель – срок полноценного небольшого проекта. Мы их обновляем не каждый месяц. Сейчас WiP-лимит по ним «0», но, когда мы будем готовиться к сдаче отчетности, WiP-лимит у них изменится. Стало быть, мы эти задачи в работу возьмем, но по каким-то другим своим сервисам WiP-лимит урежем.

WiP-лимит по сервисам может меняться и в течение месяца. Например, если ИТ-отдел 1С-ников участвует вместе с бухгалтерами в закрытии периода, то в эти 10-15 дней мы ничего не возьмем в работу. На все эти 10-15 дней WiP-лимит на все задачи будет «0», кроме задач о закрытии периода. Потом его можно будет открыть.

Здесь можно увидеть приоритеты по типам задач, которые мы определили – в таком порядке задачи берутся в работу.

А здесь – классы обслуживания для типов задач.
Подобная визуализация создает предпосылки к тому, чтобы заказчики сами перераспределяли эти цифры и бились за ресурсы команды между собой. Для команды эта ситуация гораздо лучше, чем когда заказчик бьется напрямую с командой, давит на нее и пинает. Это неприятно. А эта визуализация помогает четко понятно показать, чем мы занимаемся, в какой пропорции и предложить заказчикам между собой поторговаться.
Три практики Канбана, о которых я рассказал, позволяют решить эти проблемы.
Канбан-митинг, собрание по пополнению и прогнозирование

Еще я хотел рассказать про особенности проведения Канбан-митинга. Казалось бы, это обычная планерка, но у нее есть свои особенности.
-
Проводить Канбан-митинг нужно каждый день;
-
Занимает этот митинг поначалу прилично времени, но потом все меньше и меньше;
-
Канбан-митинг направлен на то, чтобы задачи выпускались как можно быстрее.
Чтобы достичь этого эффекта мы обсуждаем задачи в особом порядке.
-
Мы не начинаем обсуждение с новых задач, мы можем до них вообще не дойти, особенно поначалу, когда WiP-лимит еще не определен – вы нахапали больше, чем можете проглотить. Сначала мы обсуждаем задачи, которые в самом правом столбце (у меня это «Тестирование»). Стараемся сосредоточиться на задачах, а не на сотрудниках – определяем необходимый порядок действий, чтобы довести задачу до прода. Что нужно, чтобы задача пересекла эту линию и ушла из системы, чтобы можно было втянуть в систему какую-нибудь новую задачу.
-
Потом мы переходим к следующему столбцу – это «Разработка».
-
Потом к «Аналитике».
-
Потом к новым задачам.
Как я уже говорил, поначалу, когда мы еще не ограничили в системе WiP-лимиты, совещание занимает час-полтора, и за это время мы можем даже не дойти до колонки «Аналитика». Какая «Аналитика», когда у нас в работе много задач, и нужно ли это обсуждать сейчас? Это такой звоночек, что вы и вправду набрали много задач.
Когда вы установили WiP-лимит и придерживаетесь его, ежедневный Канбан-митинг занимает всего 10-15 минут, и на нем вы уже обсуждаете только заблокированные задачи.
И, кстати, блокировку задач нужно вести каждый день без особой рефлексии. Просто пишем: «Над этой задачей мы не работаем, по такой-то причине».
А потом менеджер ИТ может порефлексировать о причинах простоев в задачах. Может быть, у нас нет какой-то компетенции или еще чего-то? Для такого анализа можно написать свой отчет в Jira. Стандартного отчета там нет.
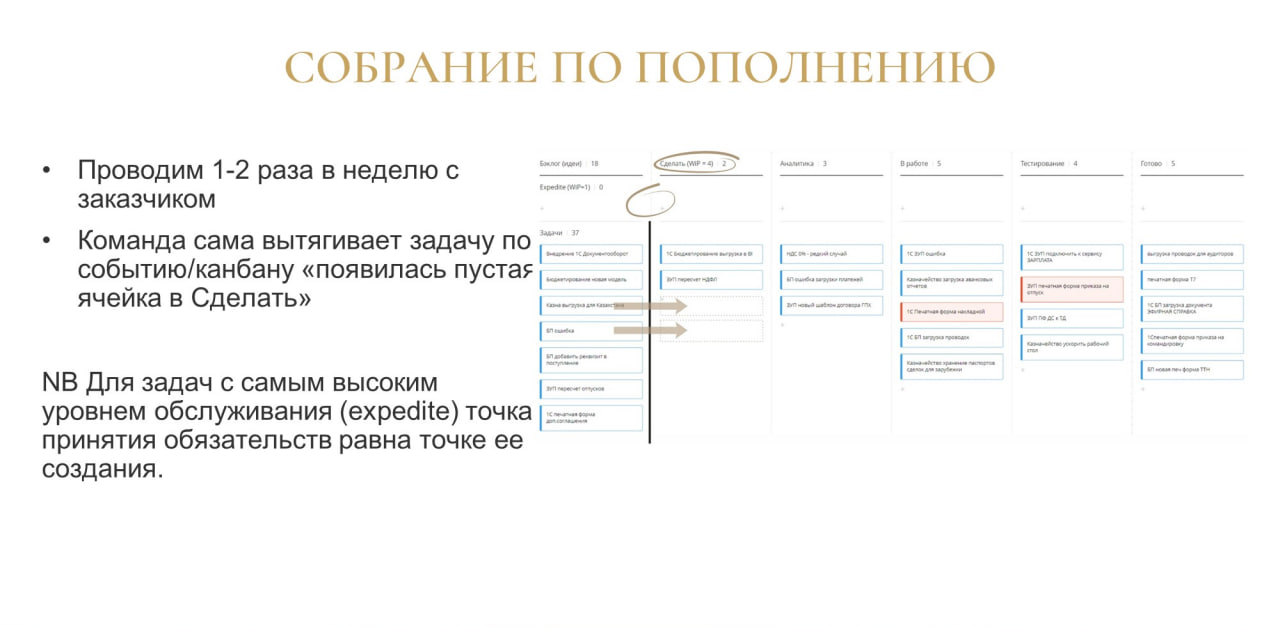
Еще одно мероприятие, которое есть в Канбане, одно из обязательных собраний – это собрание по пополнению. Если по-русски, это – планирование какого-то периода.
Когда мы еще не использовали Канбан и пытались делать прогноз по задачам на будущий период, нужно было собрать со всех отделов и заказчиков планы, если у нас есть соседи-ИТшники, то еще и с них собрать планы, согласовать эти планы и так далее.
Это было очень муторно, могло занимать дни, и очень часто ни к чему не приводило, потому что у нас не очень хорошо получается с прогнозированием. Если мы где-то ошиблись, то приходится объяснять, в чем была ошибка, что мы не предусмотрели – на это уходит куча нервов и времени.
Когда у нас есть WiP-лимит и мы этот WiP-лимит разделили по оказываемым нами сервисам, собрание по пополнению (что брать следующим) может вообще практически исчезнуть. Вместо него достаточно общения с заказчиком в чате в формате: «Привет! Мы вот такую вот задачу сделали! Можем взять еще одну из 4-х задач, какую нам выполнить?»
Ответ от заказчика о том, какую задачу взять, приходит в течение пары минут. Никакого собрания для этого не нужно. В результате часть с оценкой, прогнозированием, муторным планированием, может уйти или сильно сократиться.

Теперь про прогнозирование.
Раньше у нас одна из проблем состояла в том, что куча времени уходило на оценку задач. Использовался очень дорогой метод оценки:
-
Сначала мы просили оценку от аналитика, которому в обязательном порядке нужно было предоставить бизнес-требования. Но аналитику редко нравятся бизнес-требования от заказчика, потому что в большинстве случаев они неполные, и по ним оценка получается плохая.
-
Потом шли за оценкой к программисту или к консилиуму программистов, чтобы они обсудили данный вопрос, то есть отрывали их от работы. Они тоже давали свою оценку с комментарием, что аналитика неполная, и в ней может быть что угодно.
-
Потом, собрав все эти оценки, руководитель начинал делать прогноз сроков с поправками на то, что сотрудник работает не все 8 часов, а может приболеть, уйти в отпуск, потратить время на совещания, на исправление бага или внеплановой задачи, которая влияет на календарный срок задач и прочее.
Получалась очень громоздкая, сложная и неэффективная система прогнозирования сроков.
Такую систему прогнозирования можно вообще убрать, если порефлексировать и заметить, что:
-
Когда вы работаете во внутренней команде внутри предприятия, окружение у вас, скорее всего, очень стабильное – оно вам ставит примерно одни и те же задачи.
-
Заказчики у вас примерно одинаковые.
-
Команда тоже резко не меняется.
Поэтому, вместо того, чтобы оценивать, можно обратиться к статистике (здесь Jira очень сильно помогает).
В статистике уже есть все эти поправки, о которых я говорю:
-
на оптимизм программиста;
-
на пессимизм программиста (оценку этого программиста умножаем на два, а этого делим – так бывает);
-
на какие-то вещи из разряда: «этот тип задач обязательно ждет приходящего программиста»;
-
или: «с этим типом задач нужно обязательно идти к админам, а они раньше, чем за неделю, ничего не сделают».
Если вы нормально типизируете задачи – более-менее точно на каждую входящую задачу можете подобрать аналог из уже сделанных – вы можете просто по статистике в Jira посмотреть, сколько вообще такие задачи делаются.
Когда вы посмотрите статистику, вас скорее всего удивит, что вроде несложная 3-4-х часовая задача может занимать несколько дней, а может быть даже неделю. Вы узнаете, что основное время тратится на то, что задачу нужно показать, согласовать, протестировать. Но этой статистике можно верить.
Когда вы научитесь типизировать задачи и такую статистику по ним соберете, вы сможете уже на этапе, когда вытягиваете задачу из бэклога в колонку «Сделать», называть заказчику какой-то правдоподобный срок, не тратя на это никакого времени. По крайней мере, не тратя времени программистов.
Результаты и выводы
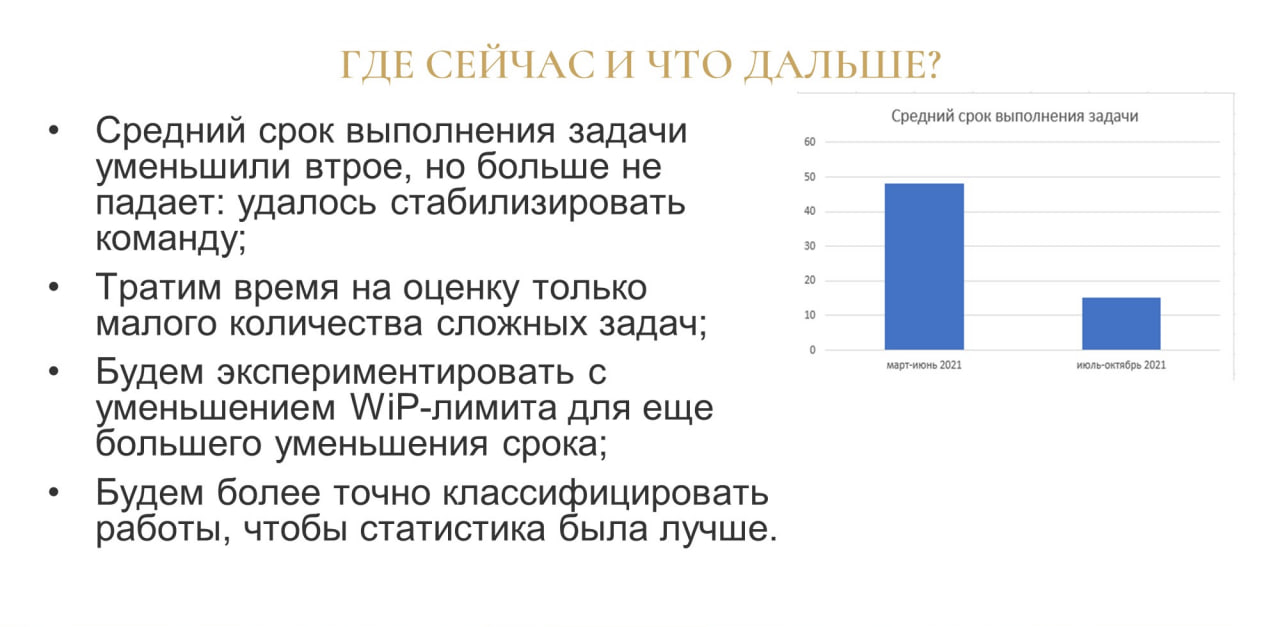
Где мы сейчас, и что дальше?
Даже те три практики Канбана, о которых я говорил – WiP-лимит, визуализация и распределение по сервисам – привели к тому, что:
-
У нас улучшились отношения с заказчиком.
-
Объективно средний срок выполнения задач снизился где-то в три раза: ранее он был 48 дней, а стал 14. Кстати, пообщался с коллегой, и он сказал, что у него срок выполнения задач после перехода на Канбан тоже уменьшился с 96 до 32 дней. Мы еще удивились, что у него уменьшение так же произошло в три раза, как и у нас.
-
Мы перестали тратить много времени на детальную оценку задач. Конечно, мы оцениваем, но только самые сложные, самые критичные.
-
Будем экспериментировать с уменьшением WiP-лимита. Когда мы «поджимаем» WiP-лимит, скорость задач увеличивается – можно будет поиграть с этим.
-
Постараемся более точно классифицировать работы, чтобы давать заказчику оценку почти сразу, чтобы он знал, когда задача будет выполнена.

Ну и последнее, что скажу: почему не Скрам?
Мы пробовали Скрам, но мне кажется, что для внутренних команд, которые работают на внутренней автоматизации с большим числом заказчиков, Канбан подходит лучше.
-
Канбан ориентирован на работу с потоком задач, а у нас поток задач не прекращается, независимо от того, работаем мы по спринтам или без спринтов. Когда мы пытались работать по спринтам, к нам точно так же приходила задача, мы все бросали, а потом приходилось перепланировать. Это со Скрамом поток задач слабо совместим.
-
Еще Скрам – это очень требовательный фреймворк, вы должны его использовать полностью – перестроить все процессы. Если вы что-то не сделаете из того, что требует технология, у вас уже не будет Скрама. У вас может быть будут преимущества, но не все. То есть 50% Скрама – это уже не Скрам, а что-то странное. Я много раз видел такие недоСкрамы, которые непонятно зачем нужны.
-
В то же время даже уже 5%-ый Канбан – только первые три практики – уже приносит ощутимый результат и пользу. Канбан позволяет улучшать процесс небольшими шагами, никого при этом не передвигая в служебной иерархии.
-
Заметьте, я ничего не говорю про производственный процесс или про изменение ролей, когда аналитик становится не аналитиком, а программист становится не программистом – когда они все становятся кроссфункциональными членами команды, как в Скраме. Канбан ничего такого он не делает, он просто ограничивает объем незавершенных работ в системе.
Канбан позволяет начать улучшения очень дешево, с небольшими затратами, и постоянно – практически бесконечно – улучшать процесс разработки.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции Infostart Event 2021 Moscow Premiere.
