
Меня зовут Василий Савунов, я в прошлом разработчик, а в последние семь лет выступаю как Agile-коуч – активно учу менеджеров и разработчиков тому, как делать хорошо. Я буду рассказывать про Канбан-метод.

Как ни печально, для многих, и даже для меня как для Канбан-тренера, основная ассоциация с Канбан-методом – это стикеры и доски.

Большинство людей считает, что Канбан – это когда повесили стикеры на доски, и наступило счастье. А почему должно наступить счастье? Что такого происходит? Это главный вопрос, на который я хочу ответить.
Канбан-метод – это не только стикеры и доски, в Канбан-методе заложено много всего:
-
и коучинг;
-
и вероятностное прогнозирование;
-
и теория ограничений – очень много чего.

Мы сегодня поговорим о двух вещах, которые, на мой взгляд, играют очень важную роль в понимании того, что такое Канбан-метод – это вероятностное моделирование (прогнозирование) и визуальный менеджмент.
Чем Канбан-метод может помочь менеджеру?

Итак, Канбан-метод – доски и стикеры. Чем это может помочь менеджеру?
Под менеджерами я понимаю широкий круг людей – это люди, которые управляют теми или иными заданиями для своих подчиненных. Это либо руководители проектов, либо линейные руководители, либо еще кто-нибудь.

У менеджеров всегда есть бизнес-заказчик, который постоянно придумывает какие-то задачи.

Например, он требует внести какие-то правки в код – конечно же, это нужно сделать срочно, и чтобы все-все-все сразу заработало. Он спрашивает: «Когда будет сделано?» И ему нужно срочно ответить.
Вы же для этого и работаете руководителем проекта, чтобы отвечать на такие вопросы, правильно?

Вы, как умный человек, говорите: «А ТЗ есть? Будет ТЗ – будет оценка». Без ТЗ и результат получится так себе – все же об этом помнят?

Бизнес-заказчик тоже не дурак и уже давно играет с вами в эту игру, он говорит: «Дайте примерный срок, мне для себя нужно понимать – это долго или нет».

Но вы же знаете, что есть риск. Если назвать примерный срок, он легко превратится в дедлайн – я думаю, многие из вас неоднократно испытали это на своей шкуре.

Поэтому многие руководители проектов в ответ на этот вопрос говорят: «Мне надо поговорить с техническим специалистом, который занимается этой проблемой (этой системой, компонентом – чем угодно). Я с ним поговорю и приду уже с уточненным сроком».

Идете к своему специалисту, который тихонечко программировал, ничего не подозревая, и просите его оценить задачу: «Там что-то придумали наверху, Нужен примерный срок».
Специалист, конечно, задает вопрос: «А есть ли ТЗ?» Он тоже уже давно в эту игру играет, чуть ли не всю жизнь – он может еще мастер похлеще вас в этом плане.

И когда он слышит: «ТЗ нет, но нужен примерный срок», он напрягается. И я его прекрасно понимаю – никто из разработчиков не любит, когда его выдергивают из комфортного программистского мирка.
В результате, проклиная все на свете, специалист называет завышенный срок – например, месяц на какую-то маленькую доделку. Либо чтобы отстали, потому что слишком долго. Либо, чтобы точно было время на то, чтобы в его загруженном графике сделать все.

Окей, берем этот срок и идем к нашему бизнес-заказчику.
Тут многие руководители проектов включают прошлый опыт, вспоминая, что срок от специалиста называть нельзя. Он его посчитал примерно, а что там по ходу дела будет – никто не знает. Надо заложить буфер – например, умножить это число на «пи» и прибавить 20%, тогда гарантированно успеем.

Вы говорите заказчику, что сделаете задачу за четыре месяца вместо одного, и глаза у него становятся вот такие.

Он в голове считает, что будет с его контрактными обязательствами, сколько будет стоить отодвинуть дедлайны, и говорит вам в ответ что-то неприятное.
А дальше начинается торг. Он говорит: «Я вам столько времени не дам». А вы говорите, что при текущем уровне проработки задачи и ресурсов уложиться в меньшие сроки – нереально.

В итоге он срезает обозначенный вами срок раза в два, и все довольны. Потому что, если бы вы месяц попросили, он бы вам только две недели дал. А теперь у вас два месяца есть – все вообще шикарно и замечательно, правда?
Эту ситуацию я в менеджменте наблюдаю очень много лет. И мне так обидно всегда за этих людей, потому что и бизнес-заказчик, и руководитель проекта, и специалист – они же все умные люди, институты заканчивали. Я уверен, что они все хотят хорошего – я еще не встречал человека, который приходит на работу с намерением сделать работу плохо.
Не бывает же такого, чтобы программист приходил на работу с мыслью: «Вот я сегодня наговнокодю…»
И не бывает руководителей проектов, которые думают: «Завалю-ка я парочку проектов сегодня…»
Нет, все хотят хорошего, но почему-то получается какое-то «колесо Сансары».

Проходит два месяца… Заказчик ваше обещание себе записал, напоминалку в календарь поставил – он же ничего обычно не забывает.

Но через два месяца вполне может оказаться, что вы скажете: «Извините, мы не успели. У нас ресурсов не хватило».
Получается, что при всех этих наших «умножим на число пи, прибавим 20%», мы все равно можем не попасть в срок. Все это потому, что будущего никто не знает.
Предсказывать будущее пока еще никто не умеет – может быть, искусственный интеллект что-то поменяет, но мы как люди пока этому не научились.

Мы опять слушаем эти неприятные слова, и все повторяется заново.

Давайте порассуждаем, на основании чего обычно дается оценка или прогноз срока:
-
Либо это прошлый опыт – если мы задачу в прошлом за такой срок делали, значит и в будущем за такой срок сделаем.
-
Либо это экспертное мнение сотрудника – я как раз такой пример приводил.
-
Либо это просто бюджетные и временные ограничения – когда у нас срок и бюджет четко прибиты гвоздями. А вы – как хотите, так в эти ограничения и влезайте.
Но погодите, мы же с вами живем в 21 веке. У нас под ногами валяется куча данных во всяких наших системах – в трекерах задач, в диаграммах Ганта, в чем угодно.

Это же просто золото, на котором мы с вами сидим – почему бы нам это не использовать?

Почему бы не превратить эти исторические данные во что-то, что позволило бы нам давать сроки, не отвлекая специалистов? Чтобы мы могли хотя бы с вероятностью 80% попадать в этот срок.
Неплохо было бы? По-моему, неплохо.
Вероятность времени выполнения для разных типов задач
Рассмотрим реальный процесс разработки.
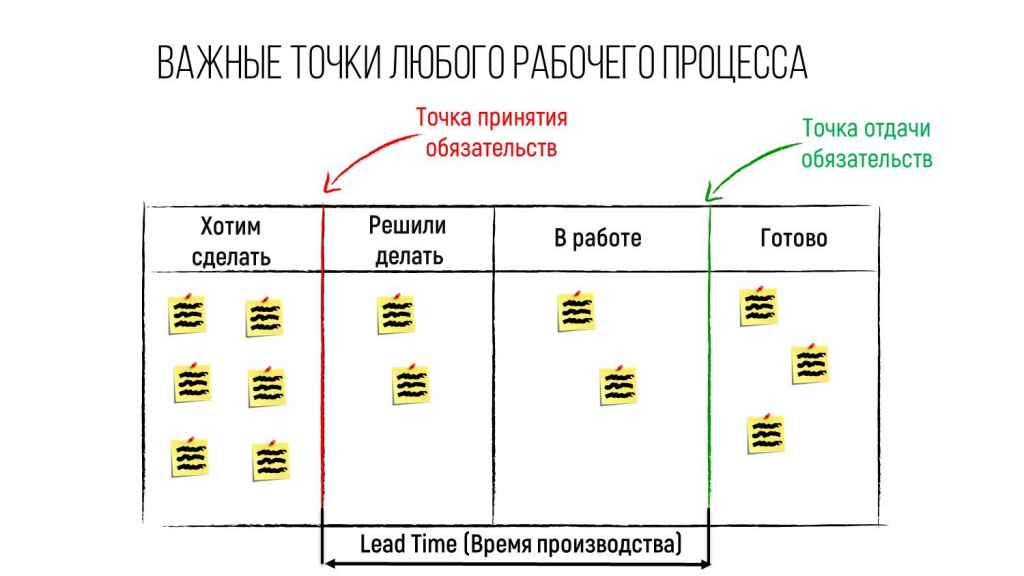
Все знают, что Канбан – это стикеры и доски. Но не все знают, что на Канбан-доске есть две важные точки.
-
Первая точка – это точка принятия обязательств, когда мы говорим заказчику: «Да, мы эту работу сделаем».
-
Вторая точка – это точка отдачи обязательств, когда заказчик принял у нас работу и сказал: «Все, претензий больше не имею».
Время между этими двумя точками в Канбан-методе называется Lead Time (или время производства) – у нас появляется очень полезный материал для прогнозирования.

Допустим, мы собрали данные по этим временам завершения за три месяца или за полгода – замерили, за сколько дней, недель, месяцев завершались задачи.
Раскладываем эти сроки на такой диаграмме.
-
По оси x – само время – один день, два дня, три дня.
-
А по оси y – сколько раз мы такое время наблюдали.
Видно, что за пять дней завершилась одна задача, за три дня – четыре задачи, за восемь дней – тоже одна. Т.е. количество крестиков – это столько задач завершилось.
Первое, что интересно на этой диаграмме – мы видим какие-то пики или горбики. Почему-то какой-то пласт задач тусуется возле времени три дня, а какой-то пласт задач – возле времени семь дней.
С точки зрения статистики – это некое вероятностное распределение. А с точки зрения Канбан-метода – это с большой долей вероятности разные типы работ.
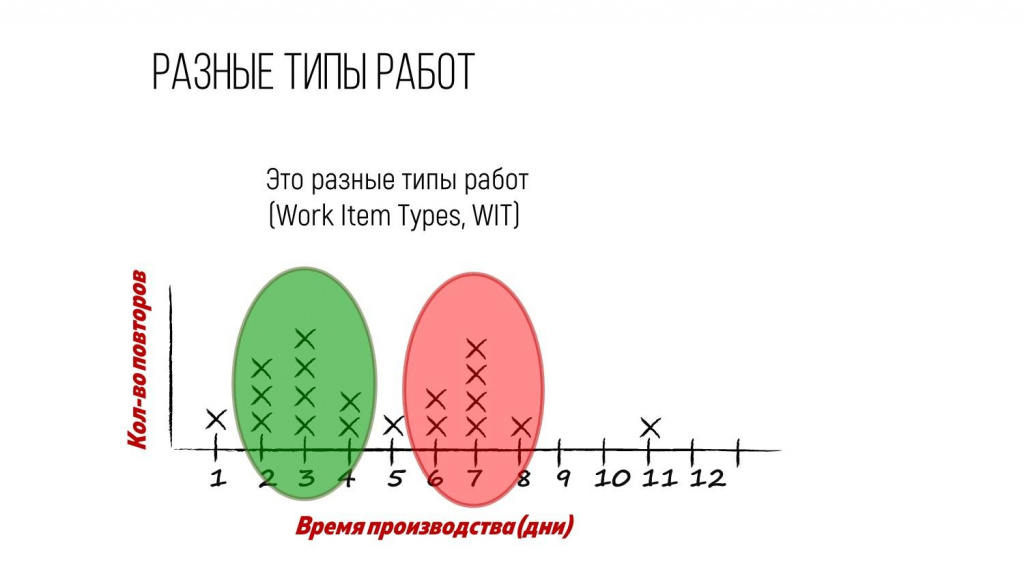
Например:
-
зеленая область – это какие-то мелкие дефекты, которые мы дорабатываем до трех дней;
-
а розовая область – это уже небольшие доработки бизнесового характера, которые занимают до недели.
Разная природа работ диктует разное распределение по времени.
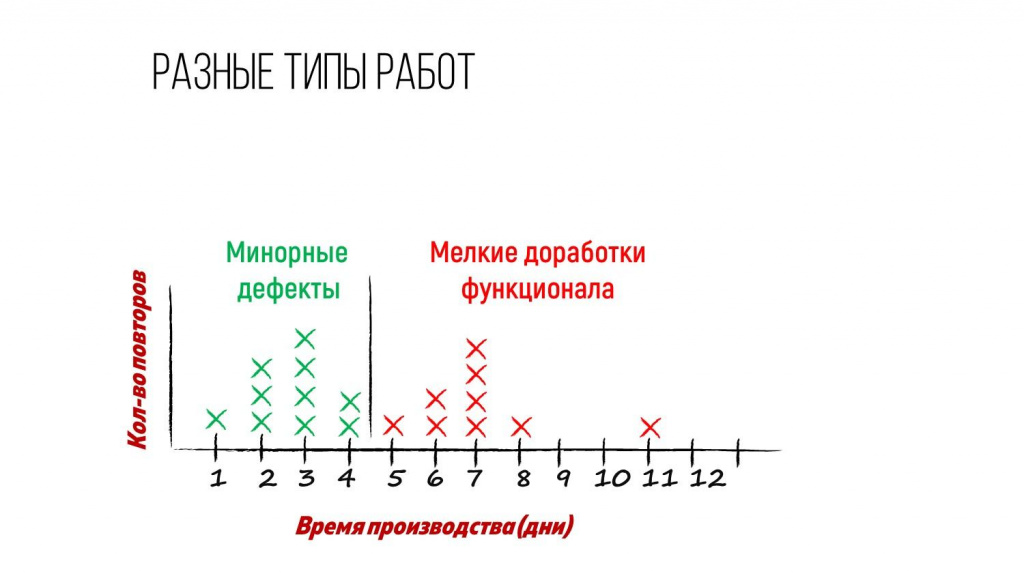
Либо мы можем пойти от обратного, и заранее поделить задачи по типам работ – дефекты, доработки, исследования, интеграции – и тоже отобразить их на графике.
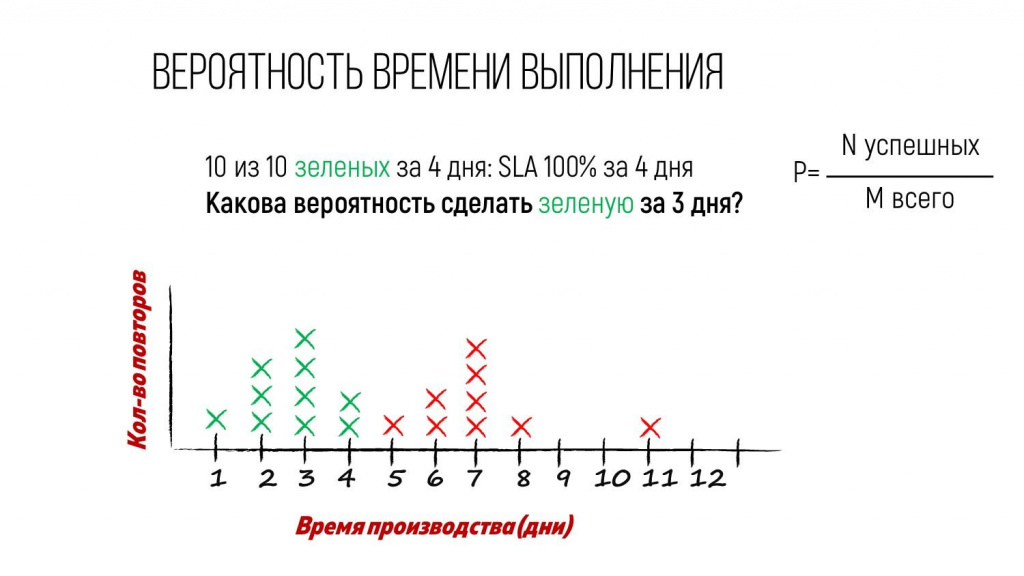
Когда мы эту статистику поделили по типам задач, оказалось, что с вероятностью 100% любую задачу типа «зеленый» мы никогда не делали дольше, чем за четыре дня.
Причем, это уже не мое экспертное мнение – это я взял данные за длинный период, разложил их на частотной диаграмме и могу с уверенностью сказать, что с вероятностью 100% срок по «зеленым» задачам – 4 дня.
Если мой заказчик хочет этим поспорить – ради бога. Только не со мной надо спорить, а с данными, которые я собрал. Пожалуйста, они все открыты, хотите – перепроверьте. Если в данных ошибка – мы их поправим, и тогда придется поверить тому, что я говорю. Если в них нет ошибки, значит, я прав – это действительно реальный срок, на который можно ориентироваться.
Но в каких задачах действительно нужно 100% попадание в срок? Только если это какое-нибудь регуляторное требование от министерства или от правительства – когда с какой-то определенной даты стартует новая норма или маркировка, и мы обязаны к этой дате все сделать. В этом случае для оценки мы берем самый длинный срок – самый пессимистичный, 100%.
Но для большинства задач нет необходимости брать самый пессимистичный срок. Если вы как менеджер смотрите на эту статистику и спрашиваете: «Окей, 4 дня – это 100%. А какая вероятность сделать зеленую задачу за 3 дня?»
Те, кто в университете изучали теорию вероятностей, эту формулу знают.
-
в знаменатель ставим общее количество попыток;
-
а в числитель – количество нужных нам исходов.
То же самое мы делаем с этой диаграммой.
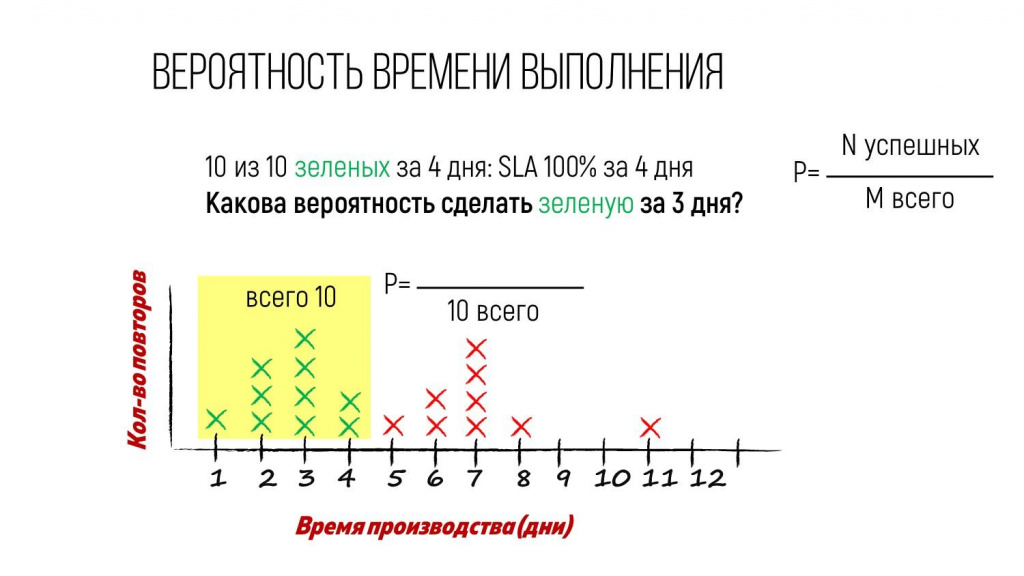
Итак, общее количество задач «зеленого» типа на этой диаграмме 10 штук – мы видим здесь 10 зеленых крестиков.
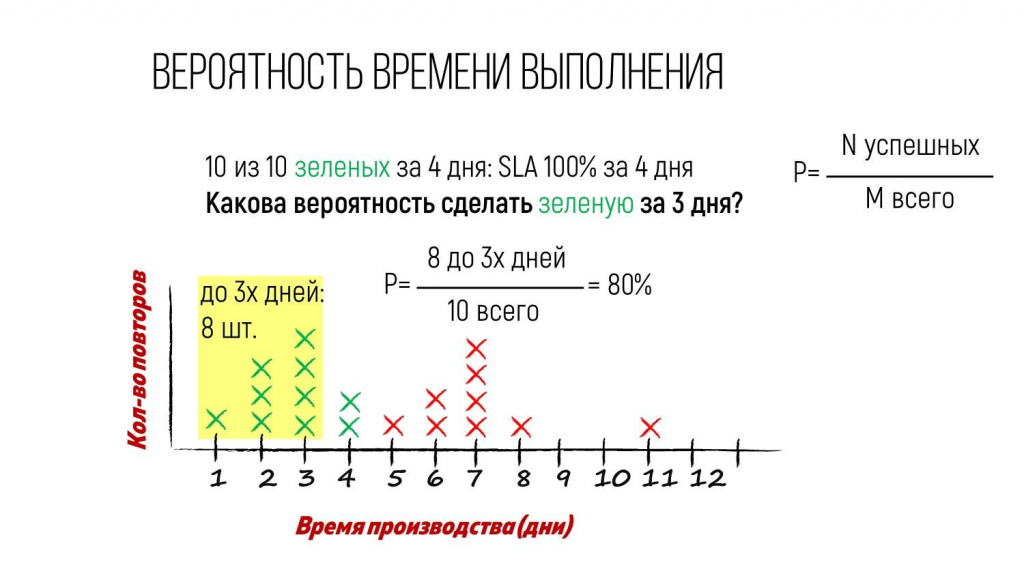
При этом в течение 3 дней было сделано 8 задач – 8 зеленых крестиков в период до 3-х дней.
Соответственно, вероятность сделать «зеленую» задачу в течение трех дней равна 80%. А в течении двух дней – 40%.
Смотрите, как интересно – я теперь могу давать прогноз с заданной вероятностью.
Никакой магии. Я просто собрал данные, правильно их обработал и посчитал по формуле.
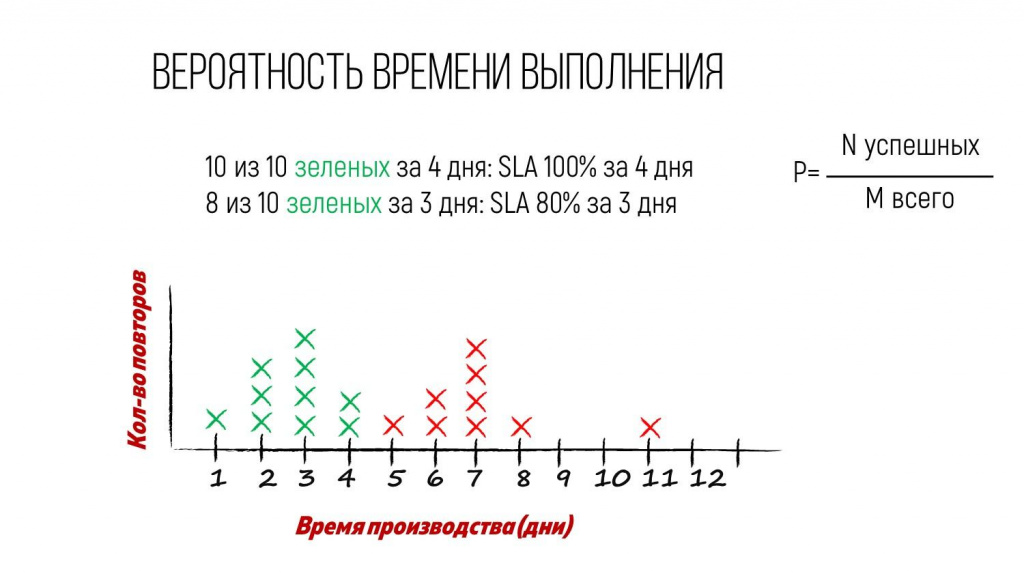
Из практики Канбан-метода известно, что для большинства бизнес-задач достаточно использовать вероятность 80-90%, потому что для обычных задач несколько дней – не особо критично. Критично, только если у нас регуляторная задача – тогда срок измеряем по 100% вероятности.

То же самое и по остальным типам работ: любую «красную» задачу мы 100% можем сделать за 11 дней, а с вероятностью 77% – за 7 дней.
Теперь можно даже не теребить наших разработчиков – можно просто собрать статистические данные от ИТ-отдела и посмотреть временные характеристики, которые характерны для этого отдела.
Если очень хочется, можно их поделить на данные по конкретному разработчику – за сколько он примерно сделает.
Эти данные можно нарезать как хотите – на любые слои и любые подуровни.
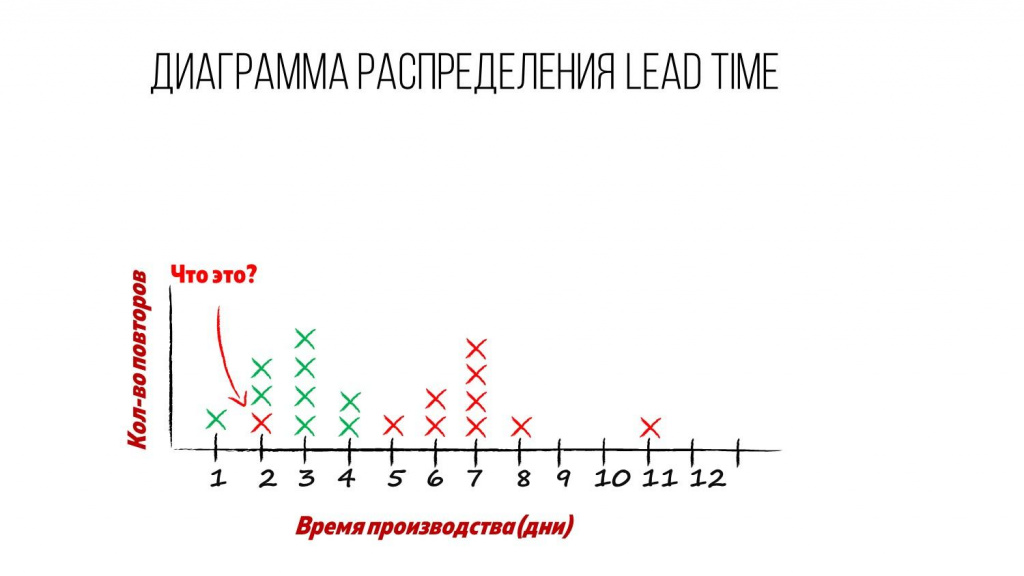
Но иногда бывает, что отдельная задачка – хотя и «красная», но все «красные» тусуются здесь, а она улетела куда-то влево.
Это как-то странно – приходится копаться в этой задаче.
Смотрите, это по-прежнему красный крестик – это один и тот же тип работ.
Но часто выясняется, что этот красный крестик к нам принес генеральный директор со словами: «Меня не интересует, что вы обычно делаете задачи за 8 дней, эта должна быть сделана за 2 дня максимум». Вы напряглись, напрягли своих программистов, аналитиков, и они сделали вам задачу за 2 дня.
По сути, вы для данной задачи подняли класс обслуживания – это все та же «красная» задача, но теперь с другим классом обслуживания.

Что это нам дает? Если в рамках конкретного типа работ мы правильно разделим их на классы обслуживания и соберем статистику по отдельным классам, то мы можем очень спокойно отвечать на вопросы:
-
когда будет сделана срочная задача;
-
когда будет сделана задача типа «норма»;
-
и когда будет сделана задача типа «когда-нибудь».
Наложение типа и класса обслуживания дает нам большую точность в прогнозировании.
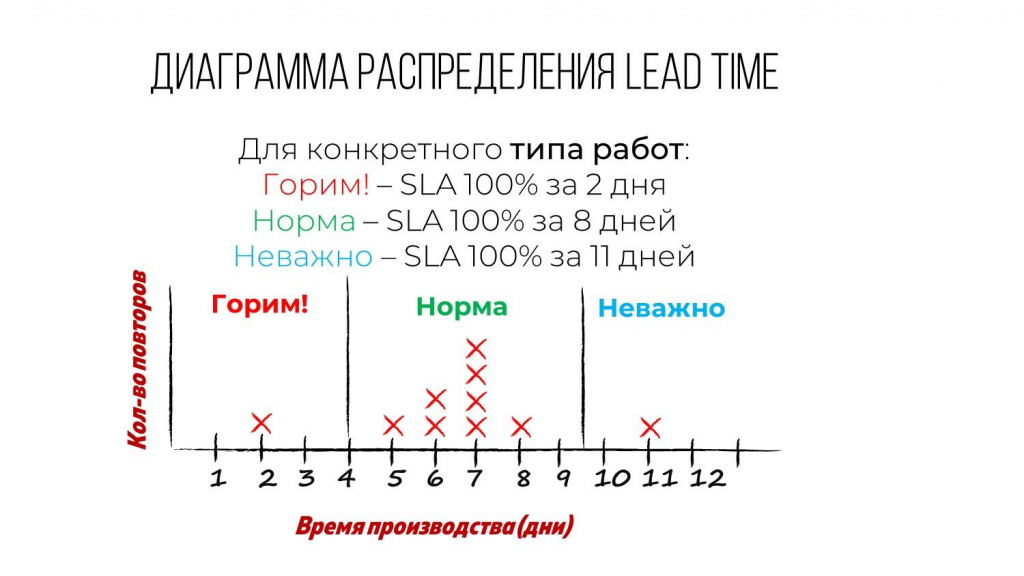
Например:
-
приходит «красная» задача с классом обслуживания «Горим» – мы ее можем сделать за 2 дня;
-
приходит «красная» задача обычного класса – мы ее можем сделать не больше чем за 8 дней;
-
приходит «красная» задача класса «когда-нибудь» – мы ее можем сделать за 11 дней.
Все это статистика и математика – никакой магии.

И получается, что стикеры и доски, о которых я в самом начале упомянул – это инструмент сбора данных.
Если мы правильно спроектировали доску, правильно работаем с ней – не просто вешаем стикеры на доску, а осознанно перемещаем их и отмечаем время, которое они провели на доске – у нас появляется когорта данных. На основе этой когорты можно делать вероятностные прогнозы.
Как именно это делать, я сейчас не буду рассказывать, но в конце доклада покажу книгу, где это очень хорошо описано.
Реальный кейс применения Канбан-метода в компании SOKOLOV

Хочу рассказать реальный кейс применения такого подхода в реальной компании SOKOLOV, с которой я активно сотрудничаю в последние 3 года.
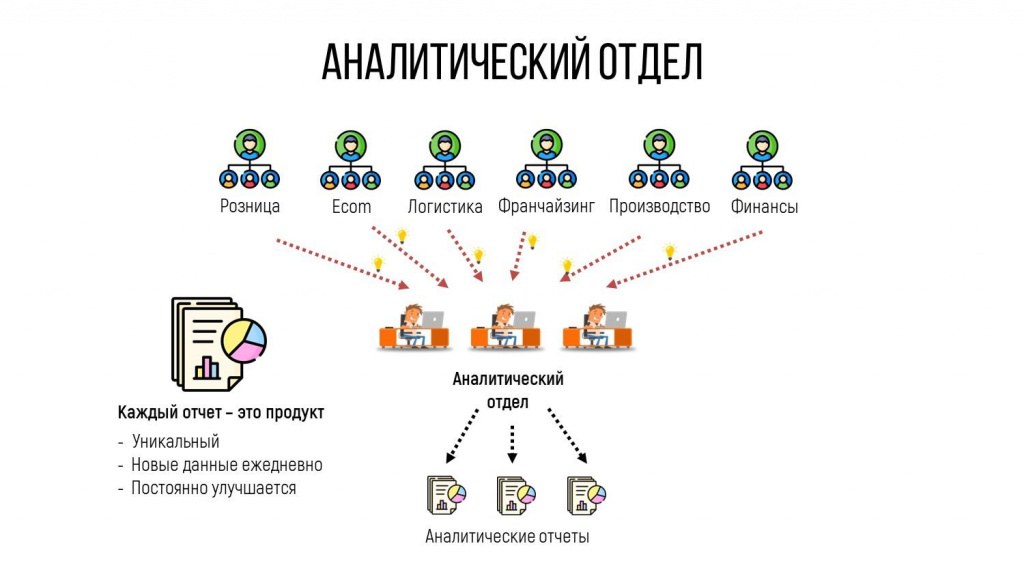
Так как компания занимается различными направлениями деятельности – от производства до распространения, у них достаточно большое количество бизнес-подразделений. И руководителям этих бизнес-подразделений каждый день требуются аналитические данные по разным срезам: производство, логистика, какие-то финансовые отчеты и так далее.
У них есть аналитический отдел, куда стекаются хотелки этих подразделений о том, какие отчеты им надо автоматически на регулярной основе собирать и отсылать.
Каждый из этих отчетов сам по себе – это такой мини-проект. Потому что надо понять, что там внутри – достать данные, все это оформить. Потом надо обсудить с заказчиком, правильно ли мы все сделали, и так далее – очень много действий.

И когда я туда пришел, там была ситуация следующая.
-
Заказчики были недовольны тем, что сроки непредсказуемы, они долгие, и аналитический отдел не может точно спрогнозировать, когда что будет сделано.
-
А ребята из аналитической группы – дата-инженеры, бэкенд-программисты, фронтенды – были перегружены, и им никто не помогал в важных для них вопросах.
С этого состояния мы начали.
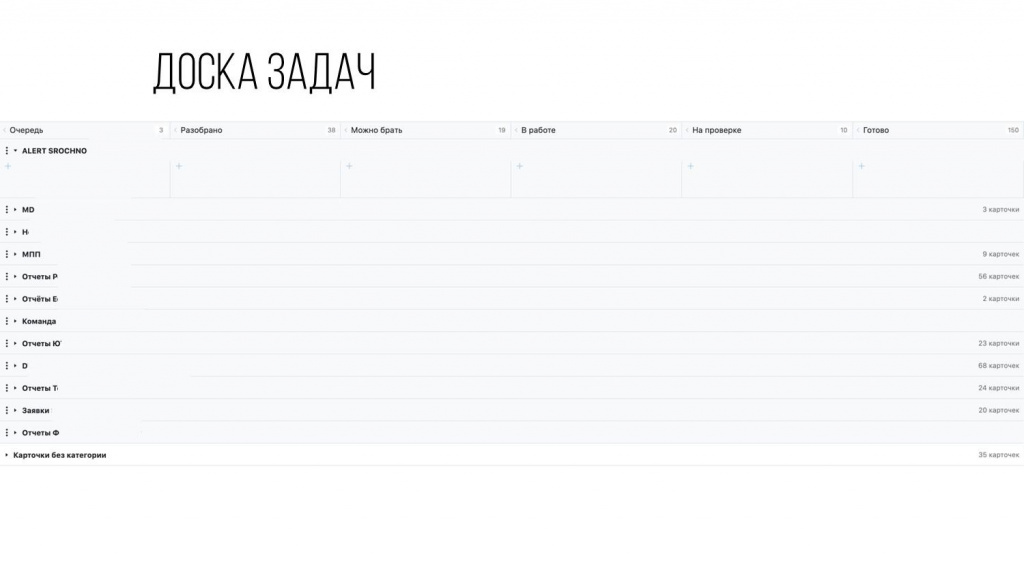
Первое, что я сделал, это спросил: «А как вы ведете задачи?» Они мне показали вот такую доску в системе YouTrack.

На этой доске мы с руководителем проекта выяснили, что:
-
Точка принятия обязательств находится между колонками «Разобрано» и «Можно брать». Это какой-то накопитель, куда перемещаются задачи, по которым руководитель проекта сказал: «Да, мы это сделаем».
-
А точка отдачи обязательств находится после колонки «На проверке». На этом этапе задачу проверяет бизнес-заказчик и задача переходит в «Готово».
Время прохождения задачи между этими двумя точками я попросил выгрузить.
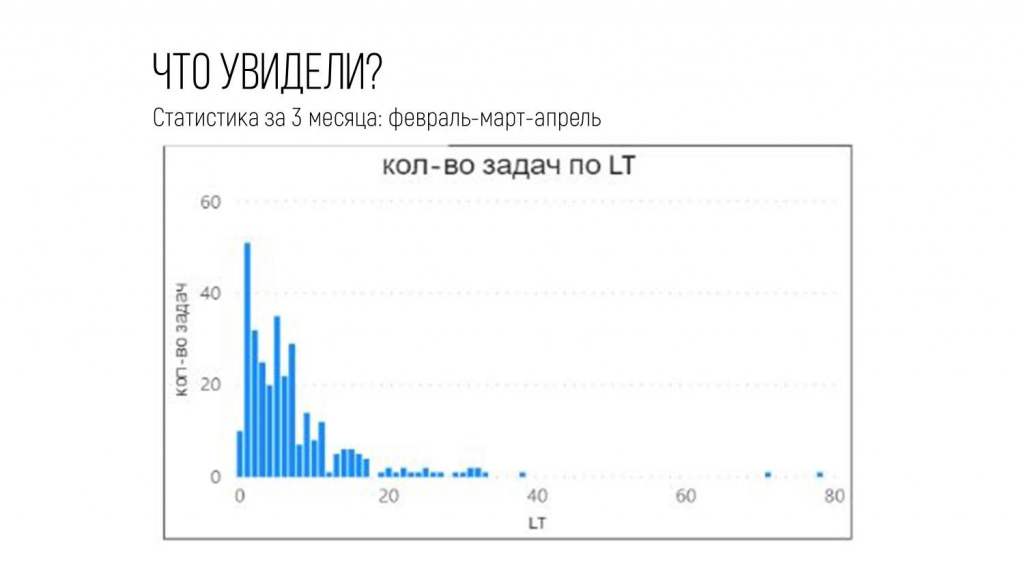
Получился вот такой график.
Первое, что привлекло мое внимание – что основная масса данных до 40 дней, и есть какие-то непонятные задачи, которые очень далеко. Это вызывает вопросы.
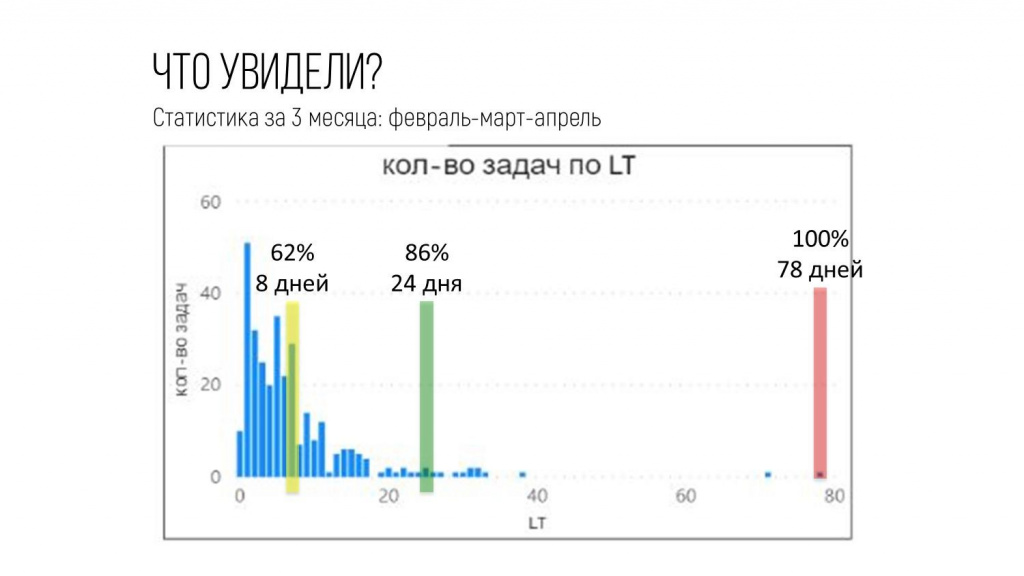
Если увеличение срока по таким задачам произошло по регулярным причинам, и мы каждый день сталкиваемся с чем-то, что отбрасывает срок наших задач очень далеко, тогда 100% срок выполнения в рабочей системе будет равен 78 дней, что довольно долго.
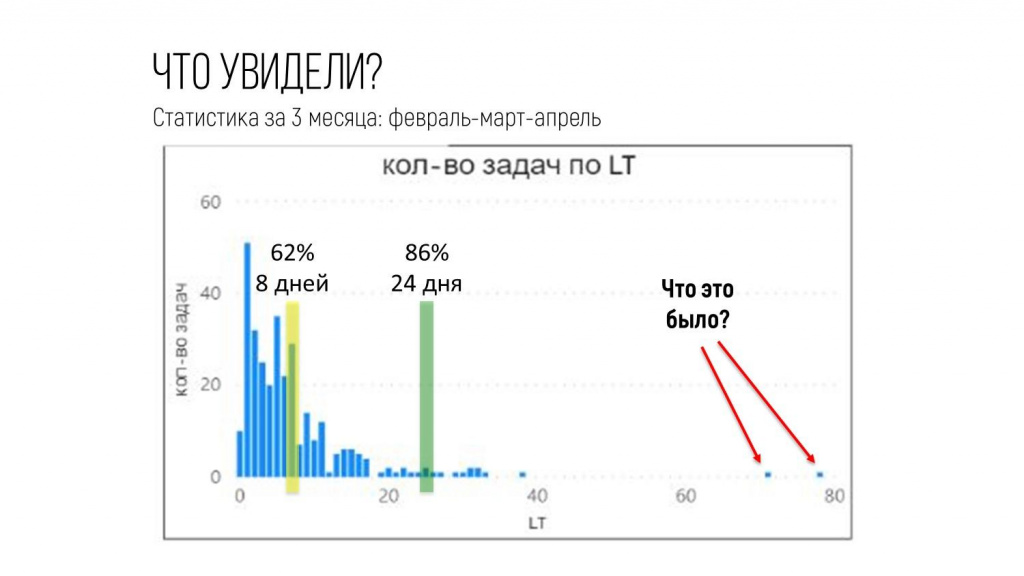
А если это какие-то случайности, аномалии, то, наверное, для долгосрочного прогнозирования я могу их отбросить из рассмотрения.
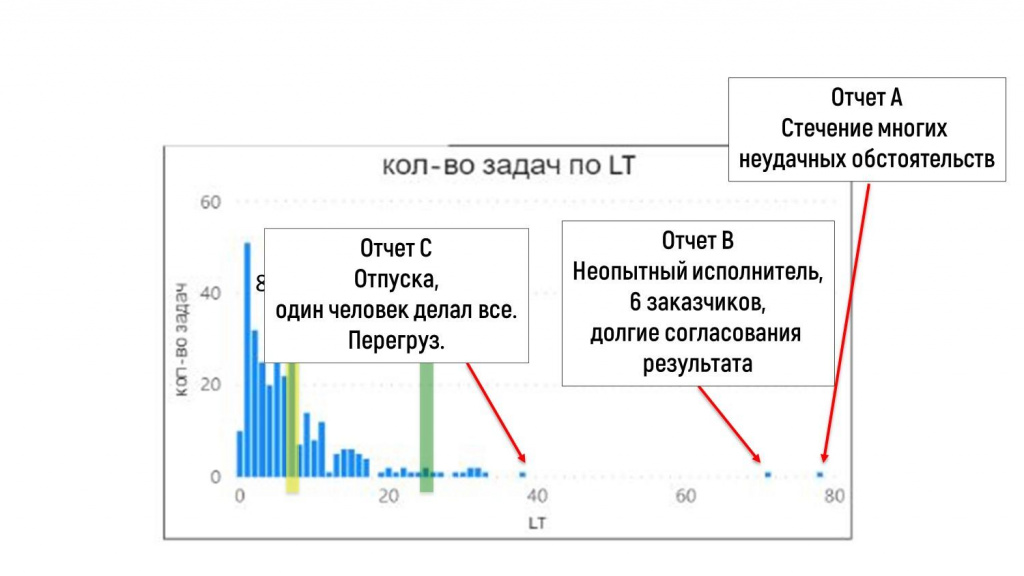
Стали разбираться, что это было.
-
В одном случае там произошло все, что могло пойти не так. Заказчик заболел, разработчик уволился, сервер сломался. Все, что могло пойти не так, пошло не так, поэтому отчет делали очень долго – 78 дней.
-
В другом случае у отчета было 6 заказчиков и один неопытный исполнитель. Пришлось его спасать – от этого срок тоже уехал.
-
И еще один момент был, когда был период отпусков, и на одного разработчика свалилось все сразу – из-за этого он одну задачу не удержал, она уехала по срокам.
Все эти три случая не являются чем-то, что происходит каждый день – это что-то форс-мажорное, исключительное, аномальное.

Поэтому я с чистой совестью мог отбросить эти значения и ориентироваться на 95-процентный прогноз, который составлял 32 дня. Это уже лучше, чем 78.
В итоге первым поинтом разговора с бизнес-заказчиком стало обещание о том, что в течение 32 дней мы сделаем любую задачу – вообще любую, какую бы нам ни закинули. Я предложил ориентироваться на это время, а время, которое кратно меньше этого, считать явно очень оптимистичным и маловероятным.
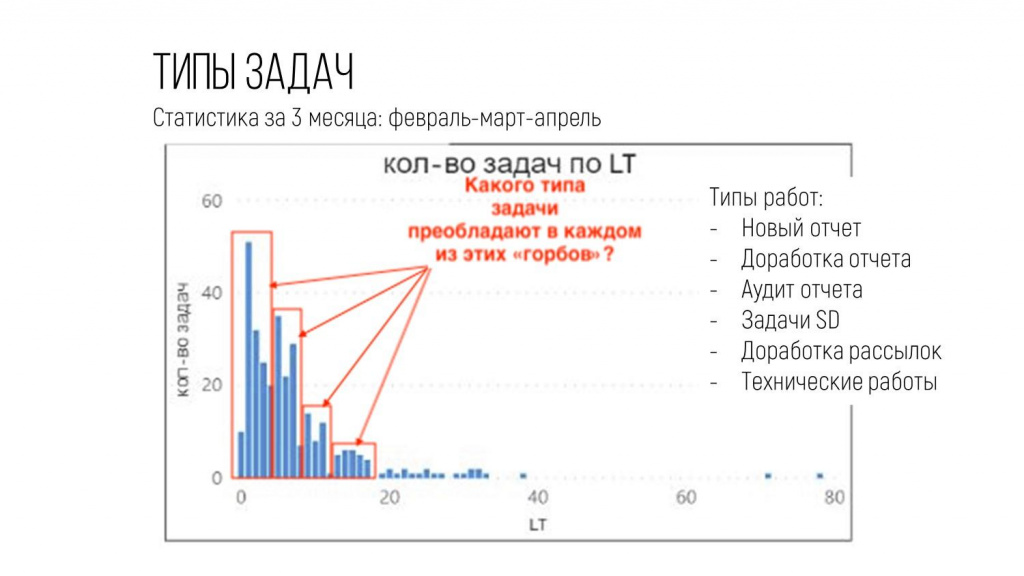
Дальше я обратил внимание, что на диаграмме есть не очень ярко выраженные «горбики», и захотел разобраться, какого типа задачи преобладают в каждом таком «горбике».
Мы с ребятами недельку потратили на это, и выяснилось, что в каждом «горбике» повторяется какой-то один из типов работ, которые мы делали: новый отчет, аудит отчета, какие-то доработки и так далее.
Зная эту типологию, я смог разделить статистику по типам работ.
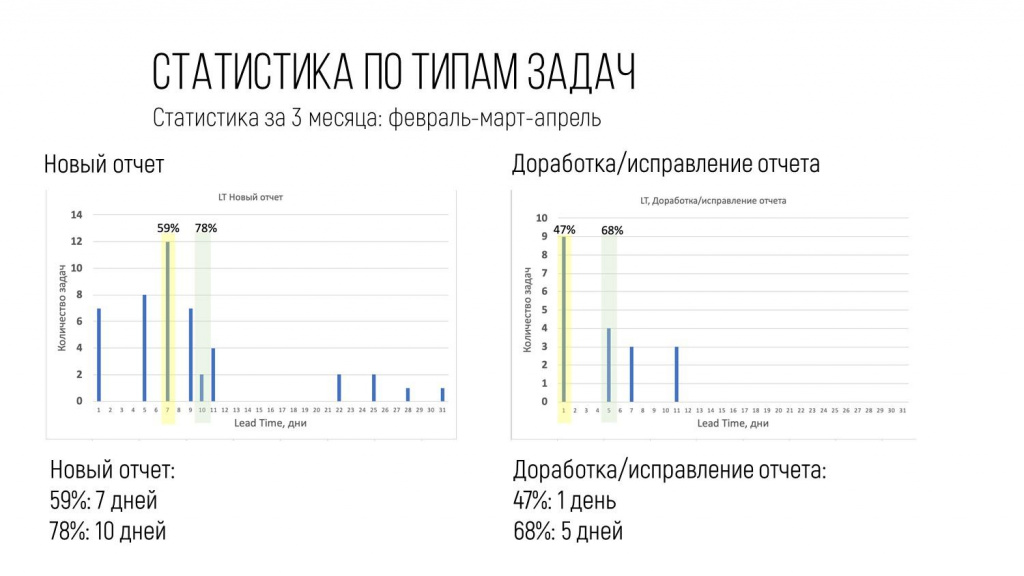
Например, вот так выглядит статистика реализации первой версии аналитического отчета.
Первой версии – потому что на тот момент, когда мы собирали данные, ребята не умели мерить время одновременно и по первой версии, и по доработкам. Никто не пытался их в единую цепочку склеить, это были отдельные задачи.
Теперь, когда заказчик приходит с вопросом: «Когда будет сделан такой-то отчет?», ему можно ответить: «С вероятностью 78% – 10 дней, ориентируйся на этот срок».
А доработки – до 5 дней.
Соответственно, можно прикинуть среднее количество доработок, умножить, и вот мы получаем примерный срок реализации практически любого отчета.
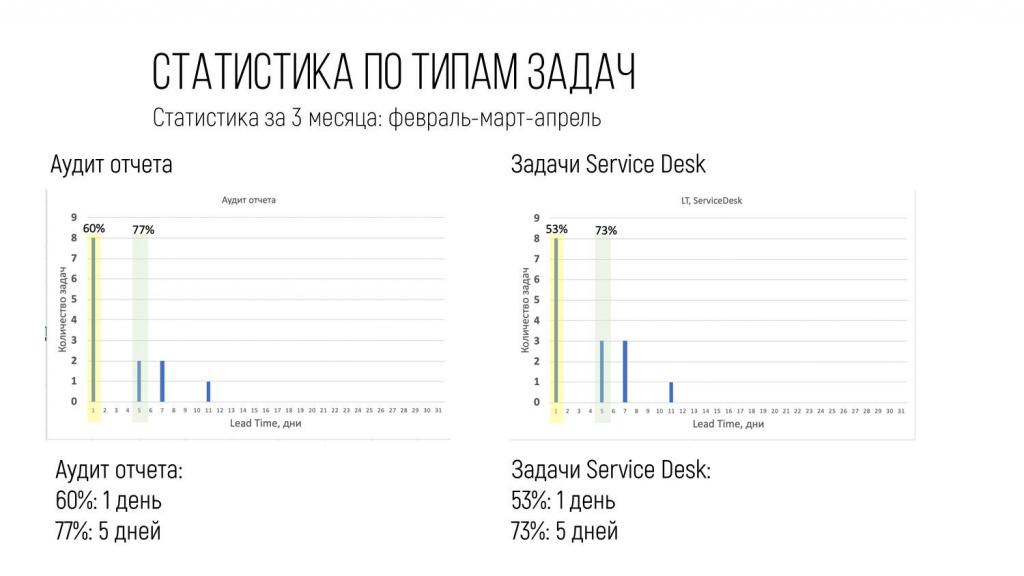
То же самое по всем остальным типам работ.
Аудит отчета – это когда они цифры проверяли.
Задачи Service Desk – это когда по техподдержке что-то прилетало.
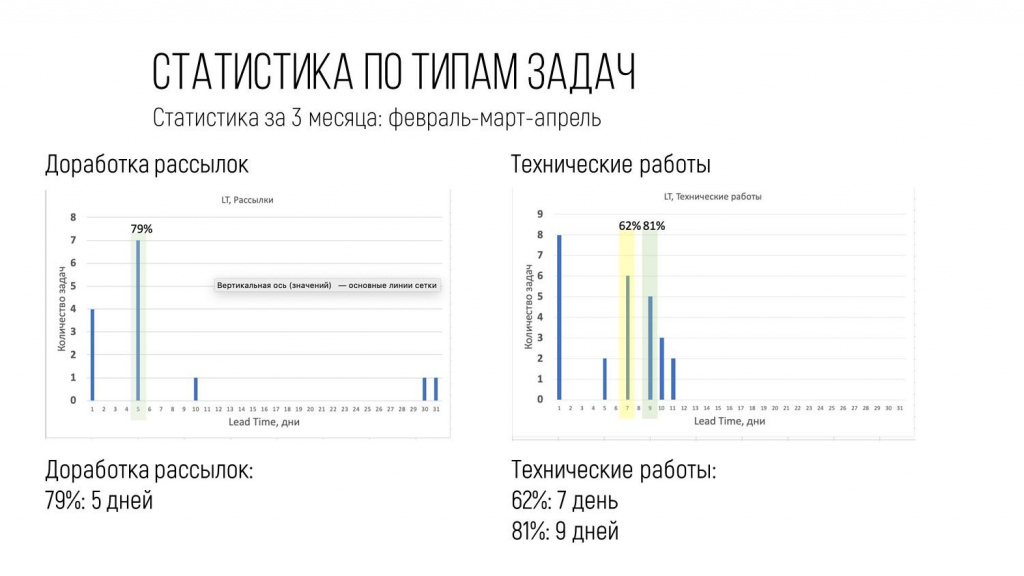
Доработка рассылок, технические работы и так далее.
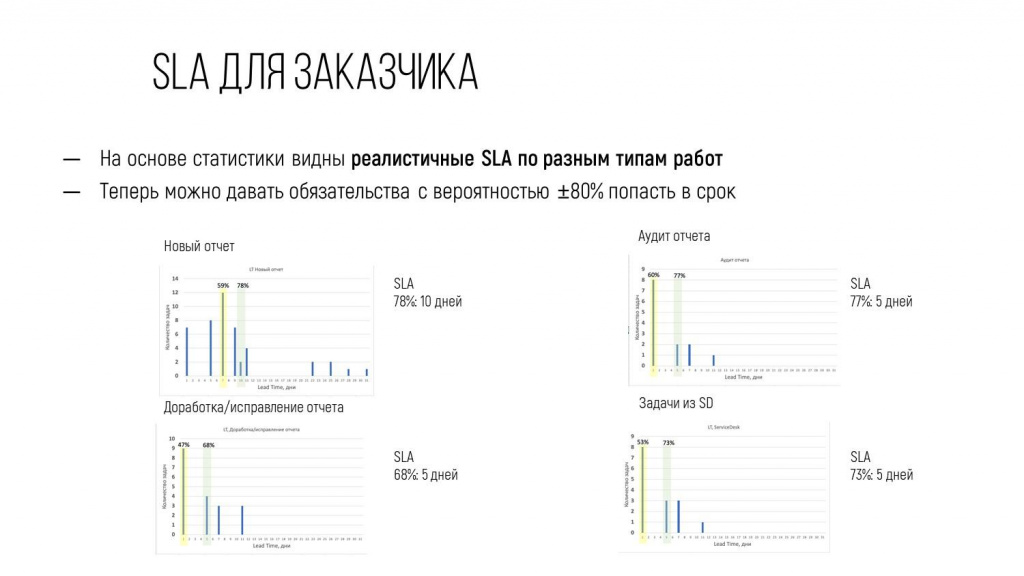
Теперь мы заказчику уже могли говорить предметно, какое ожидание по данному типу работ он себе должен заложить в свои планы.
Конечно, это не было простым разговором, но трое заказчиков из шести сказали: «А это интересно. Наконец-то у вас есть данные на которые можно опираться!»
Эти три заказчика действительно стали пилотными, с которыми мы начали работать по этой структуре. Они закладывали эти сроки в свои планы и на них ориентировались при разработке. Это позволило несколько стабилизировать нагрузку на ребят, упорядочить ее, и спустя буквально месяц-два эти показатели стали подтверждаться все более и более точно.
Благодаря этому мы остальных заказчиков тоже смогли убедить и затащить в эту схему.
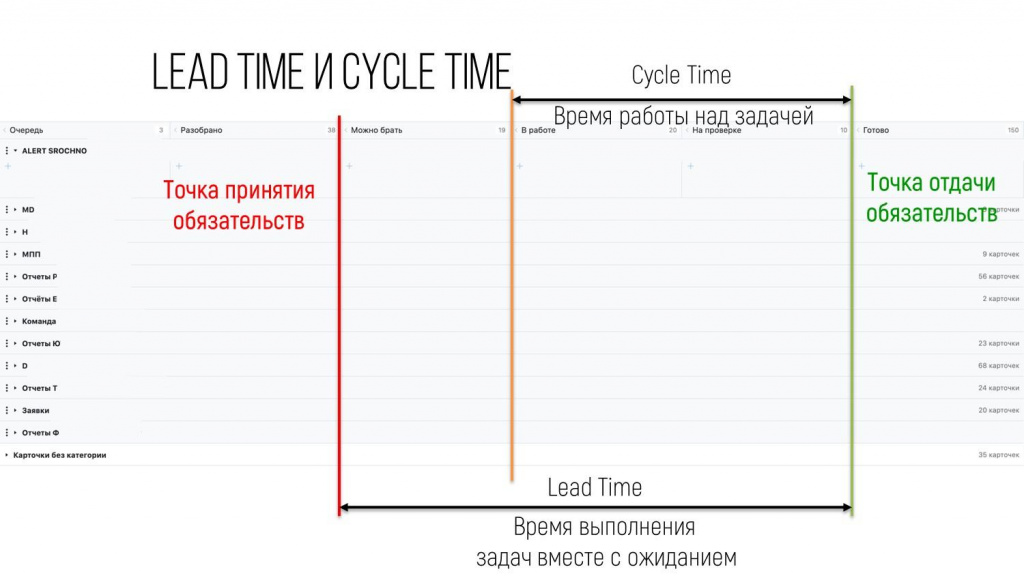
Помимо точки принятия обязательств и точки отдачи обязательств мы увидели еще одно интересное время – это время от момента, когда реальный сотрудник (бэкенд-программист или дата-инженер) взял в руки какую-то задачу и начал что-то делать до момента, когда он ее отдал. Это другое время.
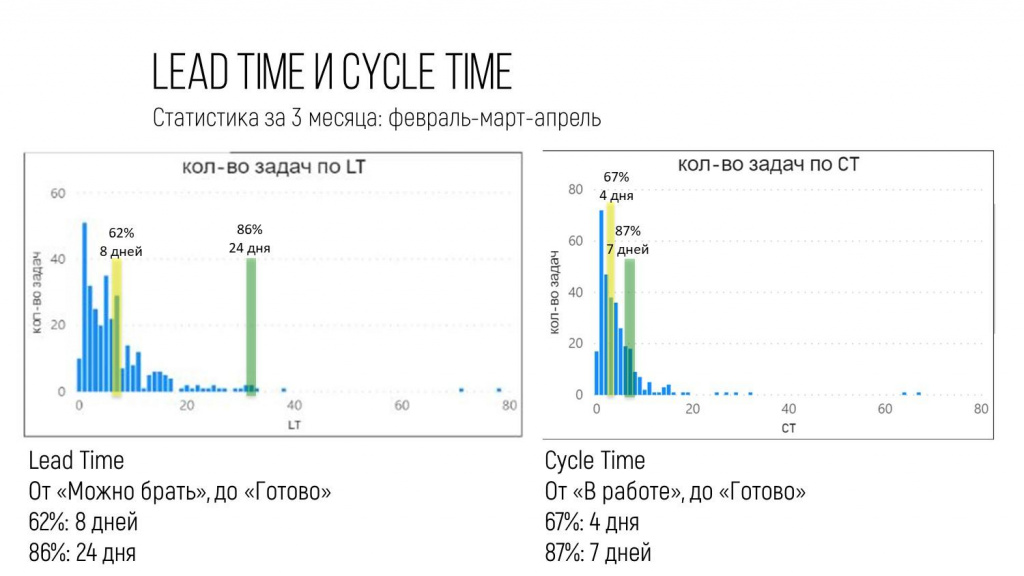
Мы тоже его посмотрели и сравнили с показателями общего времени жизни задачи:
-
Слева на слайде – диаграмма общего времени жизни задачи, про которую я вам уже рассказал.
-
А справа – время, за которое делается задача от момента, когда реально технический специалист ее начал, до момента, когда он ее отдал.
Обратите внимание, наиболее вероятное время, пока заказчик ждет задачу – 24 дня, а делаем мы ее примерно 7 дней. Разница в три раза. Как-то очень странно.
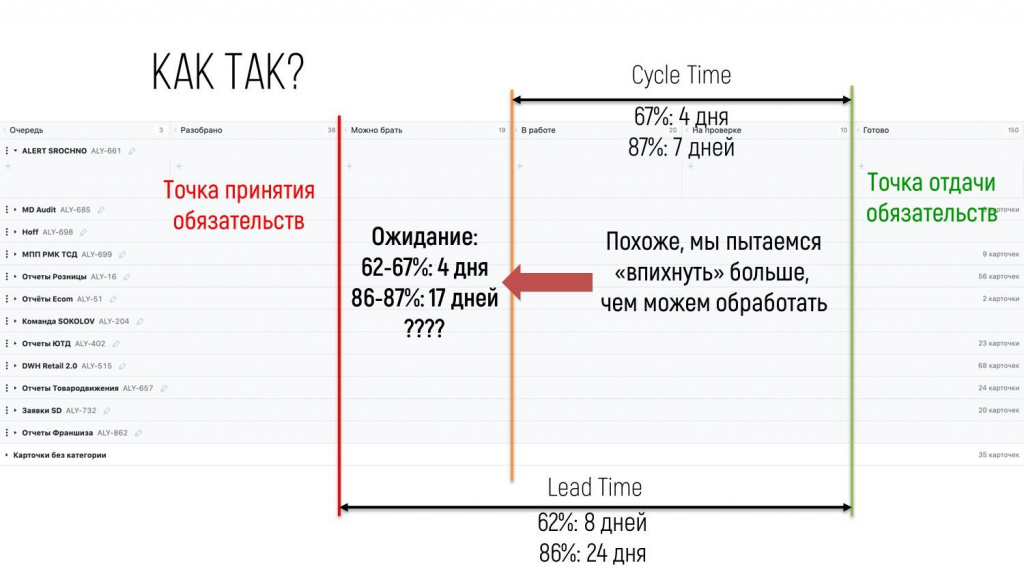
Стали выяснять, что происходит. И действительно выяснилось, что в колонке «Можно брать» задача с большой долей вероятности валяется до 17 дней – она чего-то ждет.
А с точки зрения Канбан-метода, если в какой-то колонке копится работа, это означает, что процесс после этой колонки, не вытягивает задачу с такой скоростью, в которую мы в него напихиваем. Если бы он быстрее вытягивал, там бы ничего не копилось. А раз копится, значит, исполнители не успевают сделать то, что им напихивают.
Это было вторым пунктом к разговору. О том, что пропускная способность нашего аналитического отдела не бесконечна, она имеет пределы. И вы, дорогие заказчики, ориентируйтесь на завышенное значение наших возможностей. Вы хотите чего-то большего, а мы при текущем уровне ресурсов и инфраструктуры этого не можем. Давайте ориентироваться на более реалистичные показатели пропускной способности.
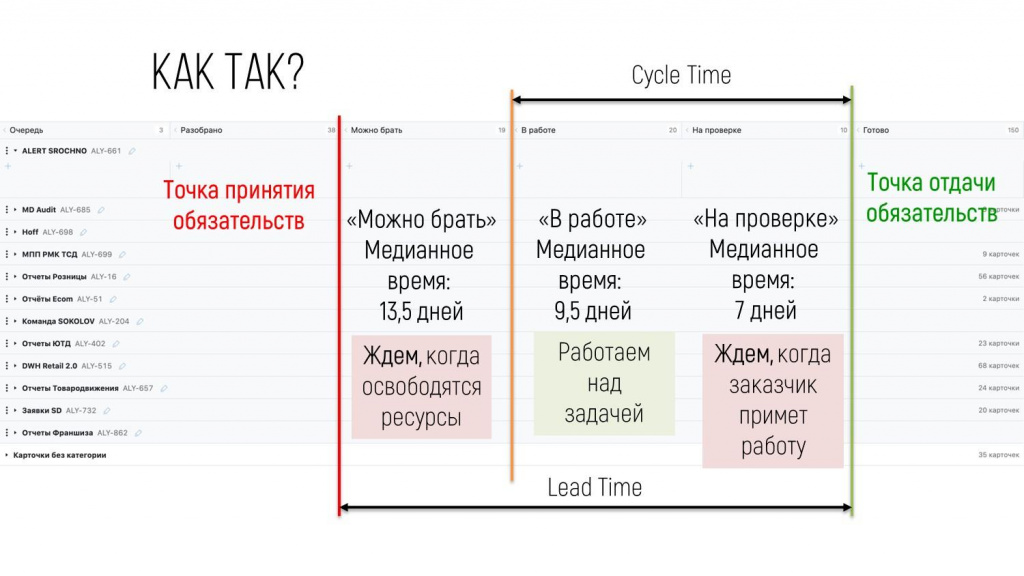
Дополнительно мы посмотрели медианные значения каждого из этапов – на слайде можно увидеть, что:
-
20 дней задача чего-то ждет,
-
9 дней над ней работают,
-
И 7 дней ее заказчик принимает. Причем на время приемки заказчик мог повлиять непосредственно – достаточно принимать в течение одного дня, а не семи, и уже существенно сэкономится время.

Дальше мы подумали, что надо бы посмотреть вглубь. Например, у нас была одна колонка «В работе», и было непонятно, что там происходит. Мы не могли это померить, а в Канбан-методе, как вы поняли, все на метриках и на измерениях.
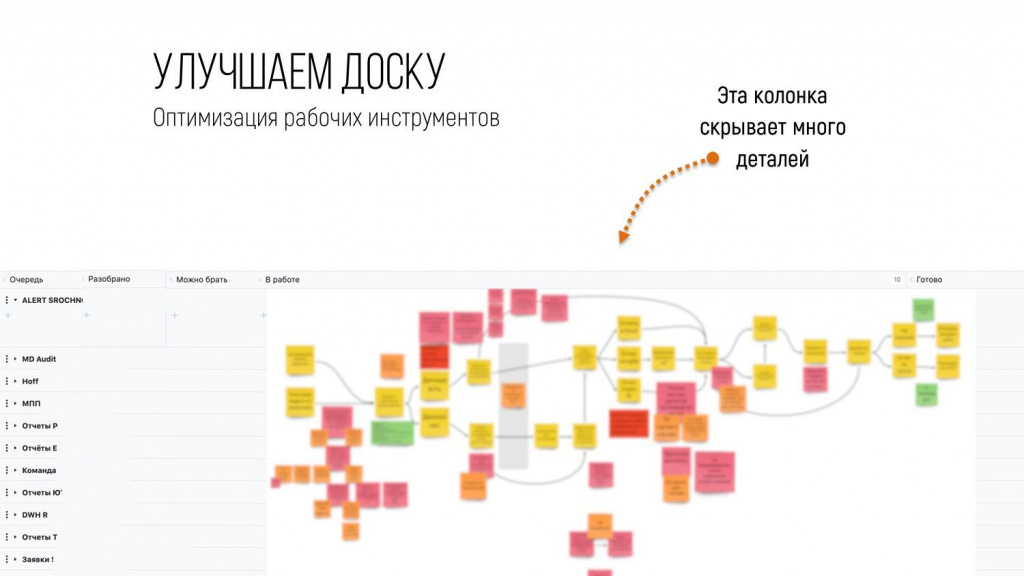
Я сел с ребятами, которые непосредственно работают руками, и мы расписали с ними их рабочий процесс в виде value stream map (потока создания ценности). Это схема, где видно – куда задача попадает, кто ее берет первый, как она потом идет и т.д.
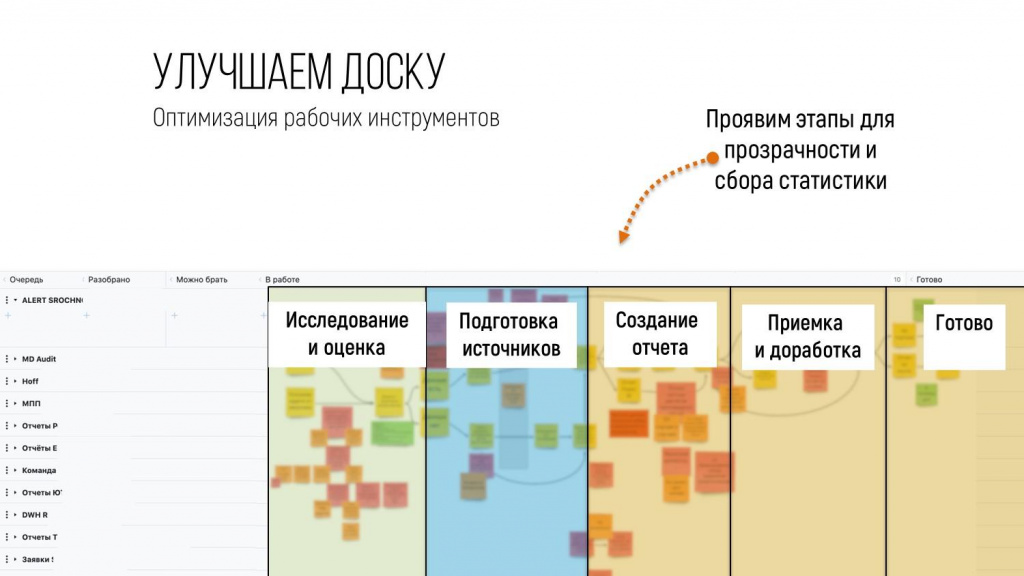
В этом потоке создания ценности мы выделили ряд этапов, которые повторялись постоянно, для большинства задач.
И теперь у нас появилась возможность замерять время не в целом на колонку «В работе», а на отдельных ее этапах. Чтобы увидеть, какой именно этап тормозит больше всего, и, покопавшись там, найти причину и ее устранить.
Забегая вперед, хочу сказать, что самым долгим оказался этап «Подготовка источников». Они забирали данные из 1С:Бухгалтерия, из Битрикса и других систем, которыми владели другие подразделения. А у тех подразделений была своя очередь, свои приоритеты, они не жаждали помогать. Эти задержки не давали возможности аналитическому отделу выполнять задачи так быстро, как мы бы могли.
Это и стало главной проблемой, которую мы дальше решали.
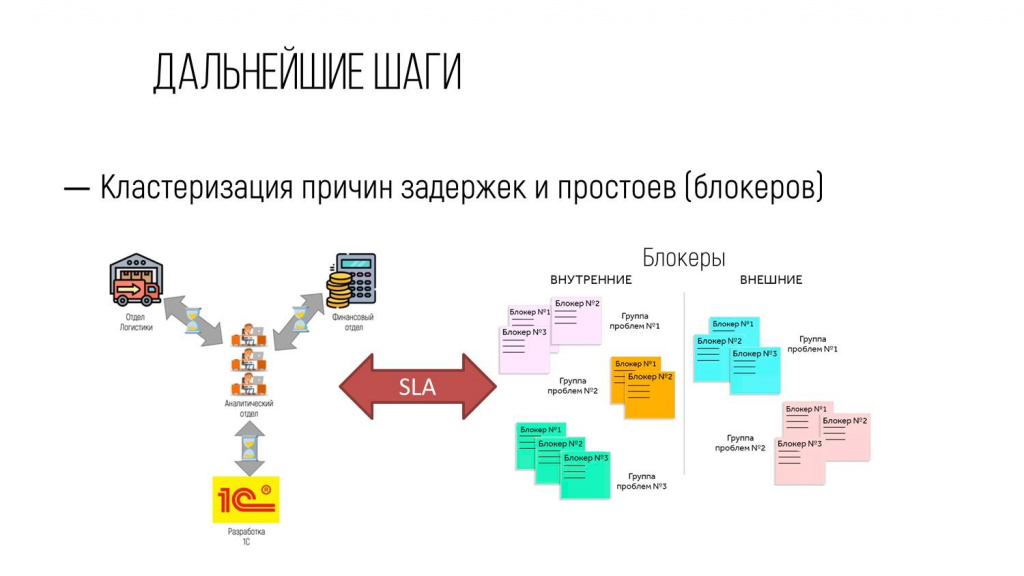
Мы стали собирать факты, когда нас стороннее подразделение, другое в этой компании, блокировало.
Если сотрудник с утра на планерке говорил: «Я ничего по этой задаче сейчас сделать не могу – я запросил у соседнего подразделения доступы, а доступы мне не дали», мы обозначаем эту задачу специальным маркером – блокером.
Эти блокеры мы коллекционируем и в конце месяца выясняем, каких блокеров было больше:
-
внутренних – когда мы неправильно сделали;
-
или внешних – когда соседнее подразделение нас задержало.
Дальше мы статистику переводим во временные и денежные показатели, и идем с ней в подразделение со словами: «Дорогой отдел логистики, по нашей статистике вы за последний квартал нас задержали на 21 день. Суммарно это составило вот столько примерно денег. Мы с этой статистикой пока еще никуда не ходили, мы к вам первым пришли. Давайте поговорим». И дальше там диалог завязывался.
Там было два характерных случая:
-
В одном случае соседнее подразделение работало по Scrum. Они нам сказали: «Вы к нам приходите посреди спринта. Мы посреди спринта не можем вам в моменте что-то обещать. Приходите, когда у нас планирование, и мы будем договариваться о квоте». Договорились о точках, когда приходить, и все стало нормально.
-
А отдел логистики сказал: «Ну да, мы долгие. Давайте ориентироваться на 21 день. Вы себе будете закладывать это в SLA, что мы вам будем отдавать за 21 день. Если на 18-й день мы вам ничего не отдали, вы нам пишете. Если на 20-й день мы вам ничего не отдали, вы нам звоните. А на 21-й день мы сами себе злобные бакланы – эскалируете, что делать».
Появляются какие-то правила взаимодействия. И это начало выравнивать дальше наш рабочий поток и его предсказуемость.
С чего стоит начать?

Теперь о том, с чего начать.
Первое, что надо сделать – это определиться с тем, от какого момента до какого надо мерить время.
И тут главная проблема – определить точку принятия обязательств и точку отдачи обязательства. Если мы это сделаем неправильно, статистика будет кривая.
Дальше нужно дать кому-то задание делать выгрузку по отчетам Lead Time.

А что делать, если доска физическая? Конечно, после двух лет пандемии я в этом сомневаюсь, но вдруг у кого-то до сих пор вся деятельность в офисе.
В этом случае – все то же самое, просто чуть сложнее.

Вы определяете, где у вас находится точка принятия обязательств. И в момент, когда стикер переходит эту точку, пишете стартовую дату – это значит, что работа над задачей началась.
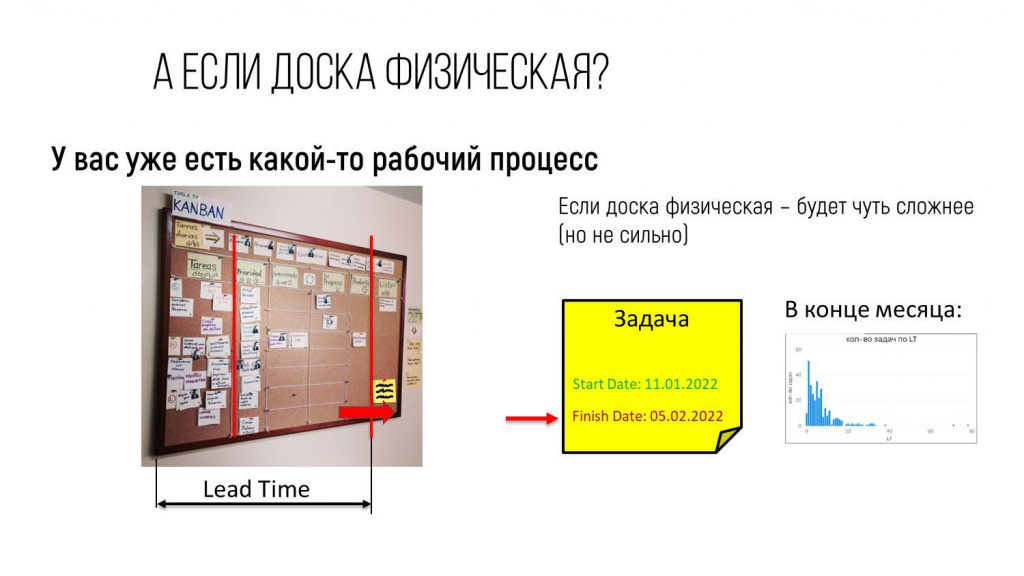
А когда стикер переходит финишную черту, вы пишите финишную дату.
И в конце месяца собираете эти стикеры, подсчитываете время и строите диаграмму, которую я вам показал.
Это то, с чего стоит начать, если вы хотите прогнозировать сроки выполнения задач и понимать возможности вашей команды. А потом уже можно пойти глубже – разделить задачи по типам работ или что-то еще с ними сделать.

На слайде – книги, которые я рекомендую.
-
«Цель» и «Цель 2» Голдратта – я думаю, многие знают. Теория ограничений в данном случае имеет огромное значение. Эти книги написаны в формате бизнес-романа, там все довольно понятно. Когда я был техническим директором, эти книги перевернули мое мировоззрение.
-
Доминика Деграндис «Визуализируйте работу» – о том, как проектировать Канбан-доски и использовать стикеры, чтобы можно было снимать статистику.
-
И толстый том «Канбан-метод» от Майка Барроуза. Он хорошо написан, понятным языком – очень рекомендую к прочтению. Можно почитать «Канбан. Альтернативный путь в Agile» от Дэвида Андерсона, основателя Канбан-метода, но он довольно занудный, а вариант от Барроуза повеселее.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции INFOSTART Анализ & Управление в ИТ-проектах.

