Меня зовут Дмитрий Макаревич, я хочу рассказать про методы и инструменты, которые мы применяли при разделении нашей ERP 2 на несколько отдельных самостоятельных компонентов – конфигураций.

Вкратце о себе. В 1С я с 2011 года, 4 года с перерывами работал в проектном отделе франчайзи, потом устроился в ГК «Содружество», где и работаю до сих пор. Сейчас занимаю должность руководителя отдела разработки.

Все то, о чем я собираюсь рассказать, происходило в ГК «Содружество», а именно в компании «Содружество-Инфо». Мы – резидент особой экономической зоны для ИТ в Калининграде.
Вся деятельность ГК «Содружество» сконцентрирована вокруг переработки семян масличных культур. У нас есть дистрибьюция, логистика, производство и много всего.

У нас в компании больше 70 баз 1С разного размера. Сюда относятся как совсем маленькие локальные базы, так и наша основная консолидирующая база, которая весит 700 гигабайт.
Используем RabbitMQ, SonarQube, Jenkins.

В докладе я хотел бы собрать практические приемы, которые мы использовали в нашем проекте. Но поскольку каждый прием хорош в определенных условиях и без контекста не обойтись, половина доклада будет посвящена контексту, а именно методам, а вторая половина будет посвящена инструментам.
Внедряли ЕРП2 -> Не внедрили. «Распилили». Как мы к этому пришли
С чего все началось? Откуда взялся этот монолит, который мы в конце концов распилили?

2018 год. Была собрана большая команда специалистов – как разработчиков, так и аналитиков, консультантов. Были привлечены внешние подрядчики. Мы стартовали реализацию портфеля проектов, который назывался «От поля до моря» с учетом специфики компании: «от поля» – от сбора урожая, «до моря» – до продажи на конкретном судне.
Была поставлена задача – создать консолидирующую систему на базе ERP2 для автоматизации бизнес-процессов и обеспечения непрерывного операционного, управленческого и бухгалтерского учета группы компаний. Все было хорошо – все знали, кому что делать.

Перенесемся в 2022. Что получилось спустя 4 года:
-
Из всех направлений в ERP автоматизировано только одно МТО, и то с натягом.
-
Сама конфигурация ERP2 превратилась в необновляемую или обновляемую за неадекватный срок.
-
В конфигурацию ERP2 встроено стороннее решение, в основе которого лежала работа с внешними алгоритмами - произвольным выполнением программного кода, текст которого задавался в пользовательском режиме.
-
Практически полностью отсутствовала ролевая модель – нормальная работа была возможна только под полными правами.
-
В консолидирующую управленческую систему были встроены подсистемы управления оборудованием АСУТП – шлагбаумами, которые требовали своей работы 24 на 7.
И самые главные минусы:
-
В системе практически не использовались типовые объекты – все функционировало на своих объектах.
-
Сотрудники в реальности не работали в ERP2. Они использовали ее как «набивашку», а потом все выгружали в Excel.

Что касается разработки, здесь тоже было не все хорошо.
-
Отдельные механизмы были необоснованно сложны.
-
Было много ошибок после релиза.
-
Разработчики плохо владели кодовой базой.
-
Некоторые «типовые» объекты выполняли нетиповые функции.
-
Показатель time-to-market, естественно, рос.
Что нас спасло при разработке. Почему «распил» стал возможен. Архитектурный подход «MonolithFirst»
Наблюдая за развитием системы со стороны разработчика я видел эти проблемы и понимал, что нужно предпринимать какие-то действия. Я тогда занимал должность эксперта по техвопросам и по совместительству занимался архитектурой и разработкой. Мне было не все равно, поэтому заранее, за полтора года до первого извлечения отдельного сервиса из конфигурации мы собрались с командой и выработали стратегию.
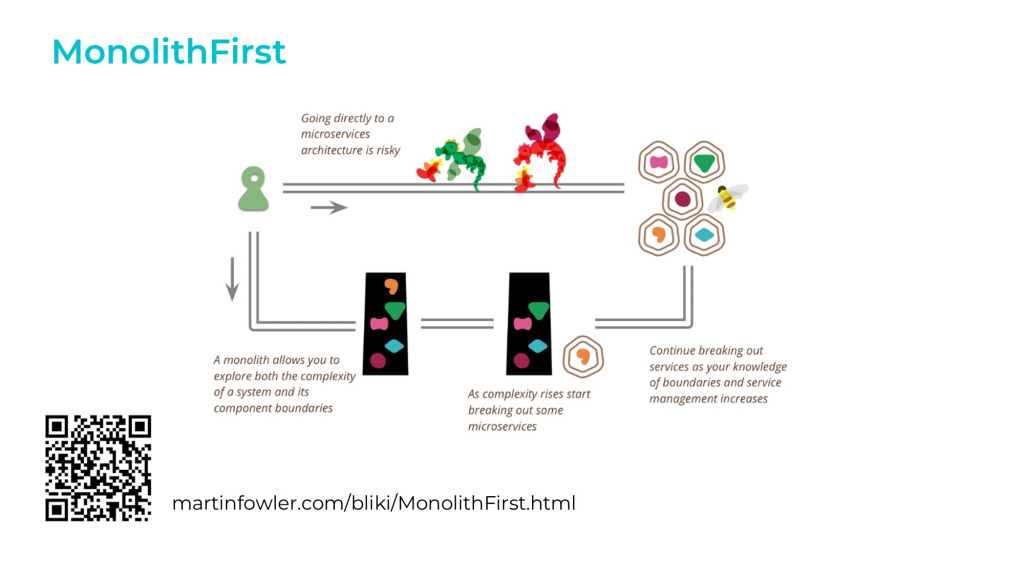
В первую очередь мы обратились к архитектуре. У Фаулера есть паттерн MonolithFirst, основную суть которого можно передать в двух утверждениях:
-
Почти все успешные истории внедрения микросервисов начинались с монолита, который стал слишком большим и был разрушен.
-
Почти всегда, когда система начинала разрабатываться как микросервисная с нуля, такой проект терпел неудачу.
Это значит, что не стоит сразу ввязываться в разработку распределенной системы, состоящей из микросервисов – это большой риск:
-
Согласно классическому принципу YAGNI, мы не знаем, «взлетит» ли та или иная гипотеза – не можем быть заранее уверены, что использование сервисов в нашем случае оправдано.
-
Делать отдельную систему без четкого понимания ее функциональных границ сложно. В работающем монолите границы установить гораздо проще.
Есть подход, а что делать дальше? Ряд простых правил
Несмотря на то, что многие архитектурные практики не применимы к конфигурациям 1С в полном объеме, а микросервисы – это вообще понятие из другого мира, все в команде понимали, что в таком монструозном виде наша система работать и развиваться не сможет.
У нас было только два варианта:
-
Либо нас увольняют и нанимают других, чтобы они все внедрили заново.
-
Либо произойдет перевнедрение нашими силами.
В любом случае система должна как-то разделиться.
Нащупать пути дальнейшего развития нам помог ряд простых правил для разработки с оглядкой на разделение. Все эти правила простые, но рабочие.

Правило №1 «капитанское», оно описано на ИТС: каждый объект должен быть отнесен хотя бы к одной функциональной подсистеме.
Здесь стоит заметить, что по стандартам 1С подсистема может быть двух видов:
-
Интерактивная – для формирования интерфейса пользователя.
-
Функциональная.
Для простых решений допускается использовать одну подсистему одновременно и для функциональных, и для интерактивных целей, но мы у себя жестко их разделили, выделив для функциональных подсистем отдельную ветку «гкс_АдаптацияСодружество».
Мы договорились, что каждый объект должен быть обязательно включен в одну функциональную и произвольное количество интерактивных подсистем. Это нужно для того, чтобы разработчик прямо в конфигурации понимал, на что он влияет, и с чем работает.

Правило №2 – более воздушное. Мы минимизировали взаимодействие с типовыми регистрами через собственные объекты. Мы старались с ними взаимодействовать именно через типовые объекты, а свои доработки мы строили таким образом, чтобы они формировали эти типовые объекты и не вклинивались в саму механику их отражения.
На конференции Infostart Event 2022 Saint Petersburg был доклад про надсистемы – мы использовали что-то подобное, но более жестко, без применения внешних обработок. У нас все было встроено в саму конфигурацию, но делалось как бы извне.
Из этого правила у нас негласно вытекало другое правило – под сложный отчет мы разрабатывали свой отдельный регистр.

Правило №3. Это скорее не правило, а подход. Мы старались достигнуть низкой связанности (coupling) между объектами разных подсистем и высокой связности (cohesion) между объектами одной подсистемы.
-
Cohesion – это степень связанности, которая показывает насколько сильно и хорошо между собой взаимодействуют объекты одной подсистемы. Если упростить, то применимо к нам это означало, что объекты одной подсистемы или сильно связанных между собой подсистем (например, имеющих общего родителя) должны общаться друг с другом через “Служебный программный интерфейс”
-
Coupling – эта метрика показывает насколько много связей между объектами различных подсистем, насколько интенсивно они взаимодействуют между собой. Мы следили за тем, чтобы для взаимодействия между объектами различных подсистем использовались только методы из областей «Программный интерфейс» и контролировали количество таких объектов - точек входа взаимодействия
Оригинальная статья про влияние Cohesion and Coupling на развитие и масштабирование решений https://enterprisecraftsmanship.com/posts/cohesion-coupling-difference/.

На слайде небольшой пример. Мы с аналитиками условно-логически разбили всю деятельность нашего предприятия на так называемые экономические потоки: материальный поток, логистический поток, документарный поток, информационный поток и куча других потоков.
При этом мы обнаружили, что некоторые объекты, которые явно относятся к одному потоку, влияли на другой поток – coupling повышался.

Чтобы это разрулить, мы выделили отдельный объект «Движение запасов» и стали взаимодействовать с потоками через него. А объекты потоков стали взаимодействовать именно с этим объектом, но никак не напрямую с другим потоком.
Таким образом мы избавились от циклической зависимости, и тестировать стало проще – например, при изменении заявки на перевозку теперь нет необходимости тестировать работу материального потока.
SOA. Чем мы руководствовались при разделении конфигурации на отдельные компоненты
До сих пор я рассказывал про принципы, которые мы применяли, теперь о том, чем мы руководствовались при разделении на компоненты.
Мы уже понимали, что наш текущий проект будет свернут и придется поделить существующую систему на отдельные сервисы, поэтому заранее распределили объекты по подсистемам и реализовали между ними красивые контракты.
Но оставался вопрос – как все сделать правильно? Выделить существующие подсистемы в отдельные конфигурации – была одна конфигурация, а стало 3 или 5? Везде ли там нужен 1С? И с чего начать?
Мы начали с глоссария и архитектуры – наверное, это самое правильное решение, которое было принято за все время.

В глоссарии мы четко определили виды учета, системы, направления, чтобы все участники проекта, в том числе и бизнес, были в одном контексте – и могли на всех совещаниях и встречах касательно архитектуры оперировать одинаковыми терминами.
Причем у нас был не один глоссарий, а несколько, поскольку нам было важно, чтобы они были максимально полными и емкими, но не превращались в простыню.
Глоссарии мы составили в виде вордовских документов или в виде страничек в Confluence.

После глоссариев мы сформировали разные варианты архитектуры, в основе которых лежали важные для нас критерии, такие как:
-
обновляемость;
-
стоимость поддержки;
-
потенциальное время на регресс;
-
тестируемость;
-
сложность и остальное.
Мы провели интегральную оценку и получили несколько разных вариантов – на старте их было 10, свернули до 3.

В результате получился аналог общеизвестного треугольника Хопкинса, где нужно выбрать два критерия из трех: быстро; хорошо и дешево.
Только в архитектуре этот треугольник немного другой.

На слайде – иллюстрация из книги Роберта Мартина «Чистая архитектура». Здесь надо выбрать два из трех принципов:
-
REP стремится к объединению компонентов для удобства пользователей;
-
CCP тоже объединяет компоненты для удобства разработки и сопровождения
-
а CRP призывает разделять компоненты, чтобы избежать лишних выпусков.
Это значит, что мы:
-
либо мы объединяем компоненты для удобства сопровождения и удобства пользователей;
-
либо мы их разделяем для устранения лишних выпусков.
По какому направлению идти – уже принимали решение коллегиально.
Мы пошли по направлению «Слишком много ненужных выпусков», чтобы выпусков было больше, функциональность доходила до пользователей быстрее, и разработчикам было проще.

Приняли решение и нарисовали архитектуру – на слайде выдержка из огромной схемы в Draw.io. Это всего лишь ее часть – то, что касается 1С.
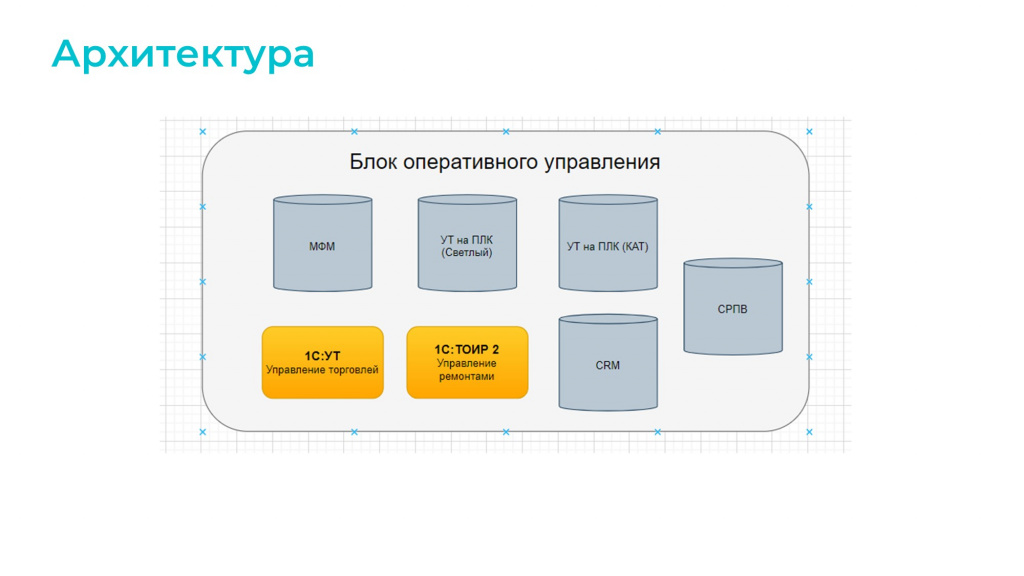
Блок оперативного управления ERP2 теперь представлен в таком виде – то, что раньше было одной конфигурацией, теперь представляет собой 7 самостоятельных блоков:
-
пять блоков – это конфигурации 1С, две из которых типовые;
-
а два оставшихся – это сторонние решения,
-
СРПВ – это прикладной продукт, который предназначен для управления подвижным составом;
-
CRM – это сделки, тоже не на 1С было реализовано. 1С в данном случае играла роль бэка.
-
Схема не идеальна. То, что здесь называется МФМ – это конфигурация для управления материальными потоками. На мой взгляд, ее можно было бы облегчить еще сильнее, но здесь все-таки сыграли роль REP и CCP. Нам пришлось сделать ее более функциональной, чтобы пользователям было удобнее работать – соблюдался эффект одного окна и не приходилось переключаться меджду различными системами.

Промежуточные выводы. Что мы получили?
-
«Продуктовые гипотезы» стали реализовываться быстрее.
-
Относительно низкий coupling позволил нам делать релизы чаще.
-
Влияние одной системы на другую стало меньше – обновление происходило с меньшими рисками.
-
Тестирование отдельных систем стало проще. Как ручное, так и автоматизированное.
-
Контроль технического долга стал проще за счет большей прозрачности функций.
-
В противовес этому интеграционное тестирование стало сложнее.
-
Увеличилось само по себе количество интеграций, их стало больше. И об этом расскажу дальше.
Как мы разрабатываем?
Теперь переходим к инструментам практики – как мы разрабатываем.
БСП

Все наши собственные решения построены на базе «Библиотеки стандартных подсистем» – у нас есть перечень подсистем, которые мы рекомендуем к встраиванию в каждый такой компонент. Сюда относятся подсистемы:
-
Базовая функциональность;
-
Пользователи;
-
Обновление версии ИБ – это стандартно;
-
Подключаемые команды;
-
Печать;
-
Варианты отчетов;
-
Отчет о движениях документа;
-
Мультиязычность, потому что некоторые из наших решений переведены на английский;
-
и некоторые другие

Тем не менее одной БСП было мало, и каждый наш модуль, помимо этого, содержит нашу внутреннюю начинку:
-
Интеграционный адаптер «Содружество» – это комплект подсистем для интеграции: взаимодействия с RabbitMQ и иными способами интегрирования взаимодействия.
-
Если мы знали, что наше отдельное решение будет взаимодействовать с ДО, в него встраивалась DMIL – библиотека интеграции с Документооборотом.
-
Кроме этого, в каждый отдельный модуль устанавливались два интеграционных расширения:
-
Расширение, содержащее форматы обменов. У нас в качестве стандарта обмена используется Enterprise Data и для разных обменов применяются свои доработанные форматы. Они выведены в отдельное расширение, которое по умолчанию встраивается во все наши базы.
-
Расширение, содержащее правила обмена в отдельных модулях – чтобы можно было с минимумом воздействия на обновления типовой базы быстро обновлять правила обмена в проде.
-
-
И есть ряд наших контролирующих расширений, которые смотрят за полными правами, контролируют служебные параметры и рассылают статистику.

Создание новой системы выглядит примерно так, как на слайде: используя специальные ветки без родителя мы подгружали в основную ветку разработки интересующие нас библиотеки и получали каркас для разработки.
Была идея обернуть все это в свою поставку и выпускать, но, честно говоря, идея эта не взлетела, потому что все-таки набор подсистем для каждого решения немного свой. И не хотелось пихать в отдельные базы то, что там будет не нужно.
EDT

Мы используем EDT. За последнее время по EDT появилось много информации, поэтому я скажу только то, что нам действительно помогло при работе по извлечению и разделению функциональности на разные решения.
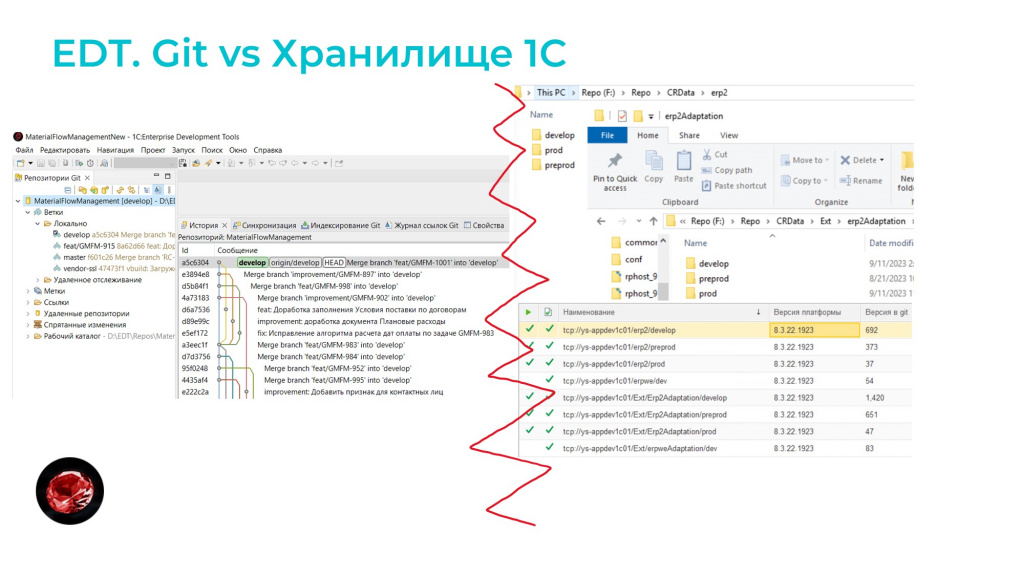
Первое – при старте проекта мы сразу решили, что не будем использовать хранилища. Все технологии разветвленной разработки очень тяжеловесны и сильно замедляют работу. Нам надо много релизов, много фич, много исправлений.
Для нас Git – это киллерфича №1, потому что она нам позволяет приоритизировать принципы REP и CCP над CRP. Больше выпусков при старте – это то, что нам нужно.

Вторая штука, которая не совсем относится к EDT, а в целом относится к Git – это Merge request-ы.
И здесь для нас киллерфича – это не тесты, не SonarQube, который сюда привязывается, а именно сам процесс переноса доработок на прод. Он стал единым для всех команд, ведь у нас на проекте могут работать еще и внешние подрядчики.
Мне не нужно мержить 20 cf-ников или путаться с хранилищами, где лежат эти доработки.
У меня один репозиторий и 15-20 merge request-ов, к которым уже можно прикрутить и тесты, и SonarQube (у нас все это прикручено), и я в целом уже могу понимать, приоритизировать и видеть эту работу. Очень удобно, особенно для работы с внешними подрядчиками.
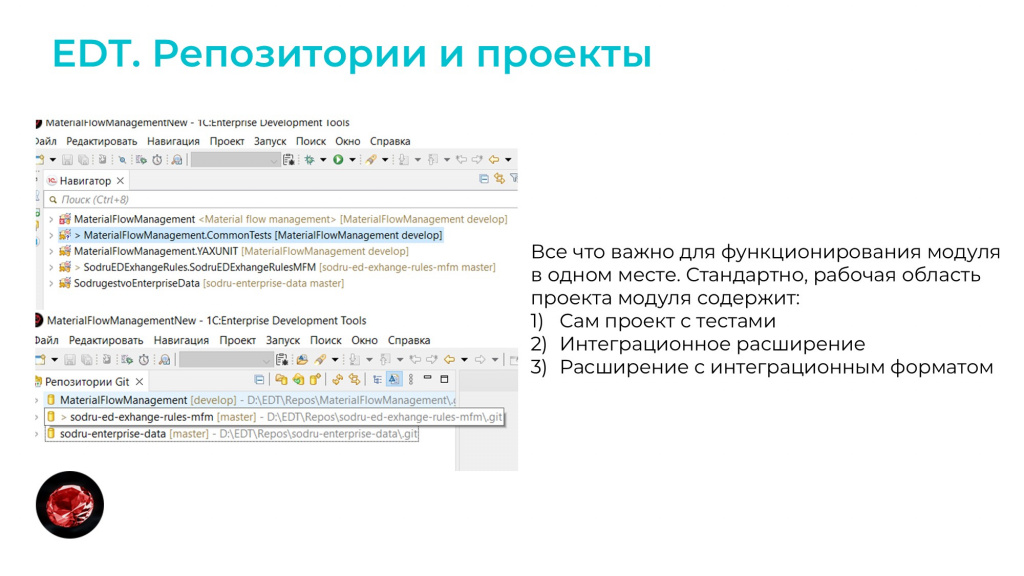
Третий плюс EDT, который был для нас значим при разделении – это одно окно для разработчика.
В одном рабочем пространстве у нас находятся все репозитории сразу:
-
и репозиторий с основной конфигурацией;
-
и репозиторий с тестами;
-
и репозиторий с расширением для формата обмена
-
и репозиторий с расширением для правил обмена;
-
и при желании сюда можно подсунуть репозиторий любого другого модуля.
Все это гибко бьется внутри одного workspace, и получается очень удобно.
Что мы контролируем?
При таком подходе, когда у нас одновременно ведется разработка во множестве отдельных конфигураций важен контроль.
Контроль особенно важен, когда мы говорим о Merge request-ах, потому что они имеют свойство копиться и «прилетать» внезапно. А бизнесу эти изменения нужны здесь и сейчас.
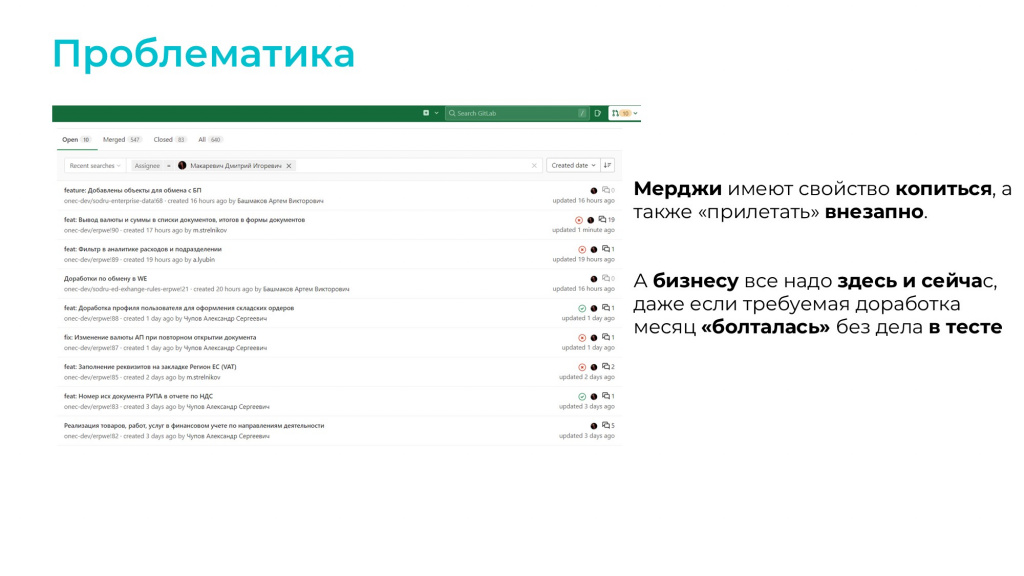
Проблема в том, что зачастую ревью и прием Merge request-ов делает человек, который может быть вообще вне контекста того, что он принимает. Либо он не до конца погружен в контекст, либо просто устал и не помнит, какую именно функцию реализует этот Merge request.
Для быстрого погружения в контекст мы используем СППР.
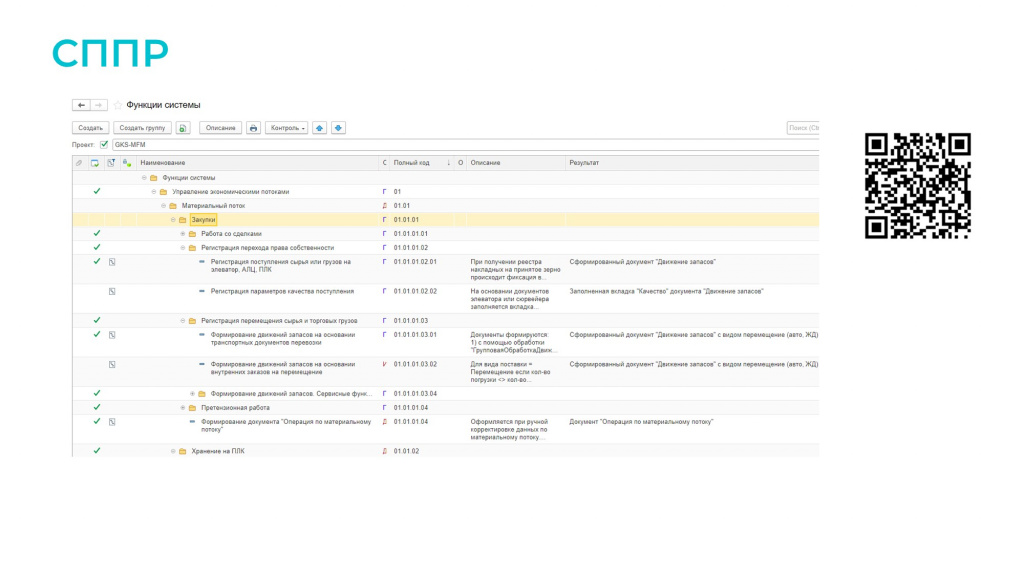
В СППР у нас ведется функциональная модель системы, которая представляет собой набор логически взаимосвязанных между собой функций. Это совместный труд и разработчика, и аналитика.
Причем мы ведем в СППР функциональную модель только наших собственных разработок, до типовых мы пока еще не дошли.

Зачем нам нужна функциональная модель в СППР, какой в этом смысл?
Дело в том, что помимо GitLab у нас используется Jira, где для каждой юзер-стори обязательно добавляется связь с СППР. С помощью этой связи при принятии Merge request ревьюер:
-
Сразу видит, с какой задачей Jira это связано.
-
Может перейти из GitLab в Jira, и там помимо ссылки на документацию в Confluence есть еще и ссылка на дорабатываемую функцию в СППР.
-
В СППР он сразу видит вход и выход функции – это позволяет ему логически понимать, к чему относится данный Merge request.
-
Поскольку вся архитектура решения описывается внутри СППР, ревьюер может быстро вникнуть и задать разработчику вопросы, если у него они возникли.
Проактивный подход в обработке пользовательских ошибок
Когда шел запуск всего этого зоопарка, ошибок было много.

Я думаю, многие из вас сталкивались с такими сообщениями.
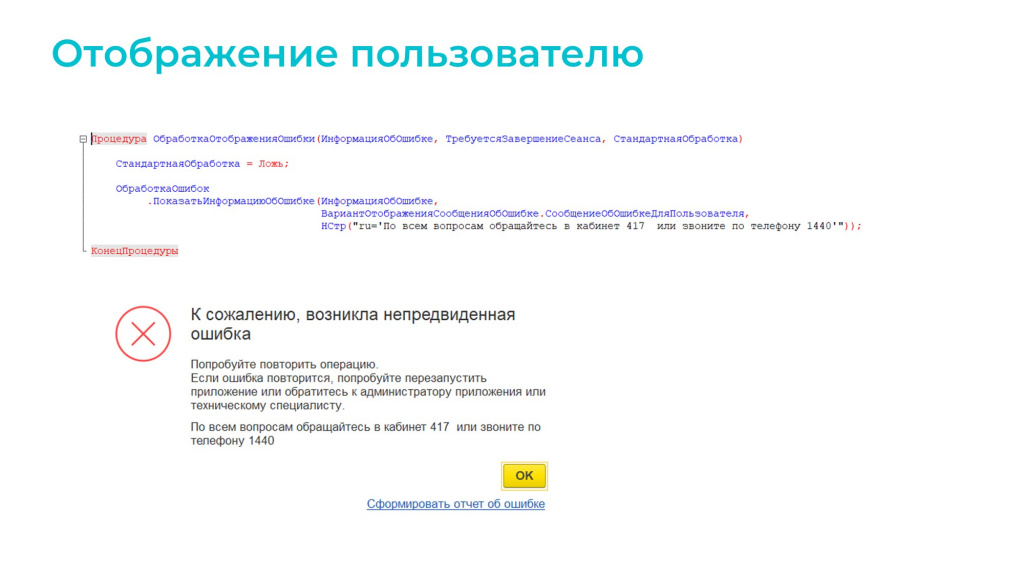
А некоторые даже сами писали для них обработчики.

Начиная с версии 8.3.17, фирма «1С» реализовала новый механизм отображения ошибок:
-
Были введены категории ошибок.
-
Стало возможно подменять текст ошибки перед тем, как выводить ее пользователю.
-
Также появилась такая сущность, как отчет об ошибке – он агрегирует в себе всю полезную информацию об окружении, где произошла ошибка, а также в эту сущность можно прикладывать дополнительные данные.

Особый интерес у нас вызвала возможность использовать в качестве сервиса обработки ошибок 1С свое решение, которое соответствует определенному контракту, и использовать его для агрегации ошибок.
Это очень удобно, потому что пользователи часто не сообщают об ошибках, они могут промолчать, а потом сказать: «Ваша программа не работает», и пожаловаться где-нибудь на техкомитете.
На ошибки нужно реагировать оперативно. А когда есть такой сервис, ты вооружен – можешь вовремя обнаружить проблему и сделать правильные выводы.
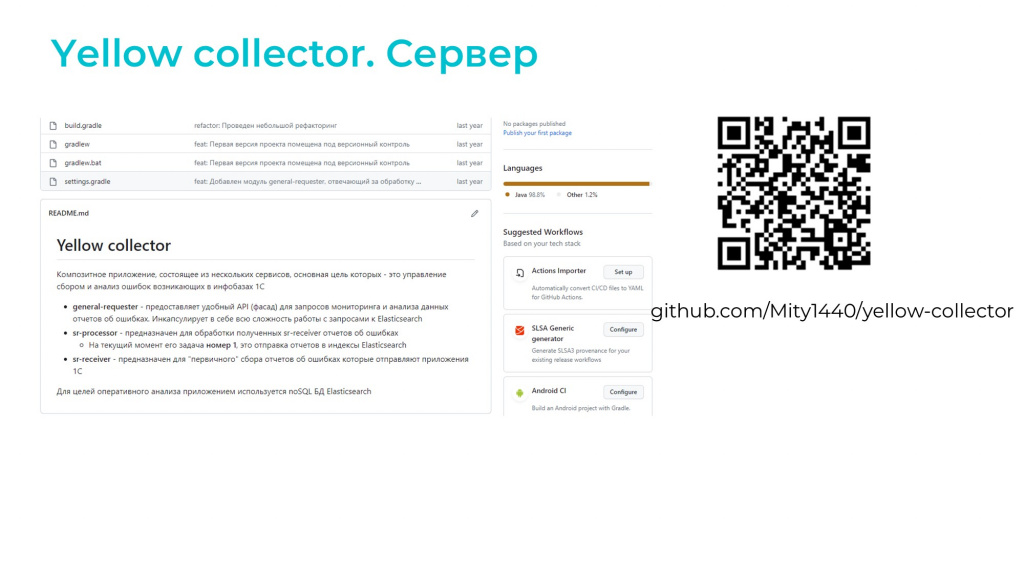
Мы разработали собственный сервис для обработки ошибок и назвали его Yellow collector – я его выложил на GitHub.
Это композитное решение, которое написано на Java с использованием фреймворка Spring Boot. Сервис построен как многомодульный Gradle-проект, который можно масштабировать. Он включает в себя три модуля:
-
Модуль сборщика – отвечает за сбор зазипованные файлы отчетов.
-
Модуль обработчика – обрабатывает полученные файлы и извлекает из них полезную информацию.
-
Модуль запросника – предоставляет внешний API к коллектору для доступа к уже обработанной информации.
Для быстрого поиска и агрегации данных в сервисе используется база ElasticSearch.
Репозиторий содержит файл docker-compose.yml, который позволяет развернуть сервис одной командой docker up.

Если есть сервер для обработки ошибок, к серверу нужен клиент. Вначале я хотел сделать клиента на вебе, чтобы все было красиво, но мне не хватило времени, поэтому я реализовал клиента на 1С – исходники конфигурации и само решение также выложены на GitHub.

Это простая конфигурация, которая, по сути, состоит из одного отчета СКД с двумя вариантами вывода информации:
-
Либо просто перечень ошибок, упорядоченных по времени возникновения.
-
Либо статистика по ошибкам за накопленный период.
Это конкретно то, что нам было нужно при внедрении. При желании возможности решения можно доработать.
Интеграции в распределенной системе. А как не запутаться?
Расскажу про интеграции – это последний пункт в инструментах. Последний по порядку, но не последний по важности.
Когда мы разделили систему на несколько, количество интеграций выросло. Как в этом вообще не запутаться? Потому что как только добавляется новая система, новый модуль, интеграций становится еще больше.

На самом деле эта задача была поставлена руководством, потому что у нас много всего используется:
-
У нас используется RabbitMQ.
-
Осталась одна интеграция по COM.
-
Есть обмены через файловую систему.
-
Используем веб-сервисы.
-
Есть внешние источники данных и много другого.
Еще до разделения была поставлена задача от руководства отдельно описать эти интеграции.

Мы пробовали описывать эти интеграции в Excel и Confluence, но результат получился не систематизированным – нам не хватило опыта в упорядочивании подобной информации. Отдельные странички с документацией остались, но создать цельное и структурированное описание не удалось.
Такие описания удобны, когда нужно документировать что-то одно, но когда нужно охватить все в целом и как-то это агрегировать, нам это не подошло. В итоге мы отложили эту идею и вернулись к ней только после обновления до платформы 8.3.20.

В платформе 8.3.20 поменялся механизм взаимодействия с внешними компонентами, и используемая у нас внешняя компонента по работе с RabbitMQ перестала работать на Linux. Она просто зависала намертво и все.
Четыре месяца общались с КОРП-поддержкой. За это время зарегистрировали порядка пяти разных ошибок. Эти ошибки были исправлены, но вопрос с зависанием так и не решился.

Наш адаптер был написан гибко, и мы решили, что убираем компоненту, берем 1С:Шину и используем ее транспорт. Логика по конвертации остается, как у нас есть в адаптере, и все будет отлично работать.

Я пришел на комитет продавать эту идею, и тут же мне в лоб прилетело несколько интересных вопросов:
-
А сколько это будет стоить?
-
А сколько у нас вообще интеграций?
-
А хватит ли нам ресурса?
-
А сколько у нас вообще систем, которые связаны друг с другом?
-
Где у нас идет какой обмен? Например, во сколько систем у нас передается номенклатура?
Вопросы хорошие, но на них я не смог ответить исходно.

Поэтому в процессе анализа, как любой нормальный разработчик 1С в сложной ситуации я разрабатываю на 1С.
Разработали свою простую конфигурацию на минималках для описания интеграций – 5 или 6 справочников, связанных между собой. Также все доступно на GitHub.

Конфигурация максимально простая. Попробуйте, думаю, всем понравится. Она родилась в процессе мозгового штурма. Мы сидели с командой, описывали интеграции. Вопрос был: «Что надо?» и тут же это делали. Так она и родилась.
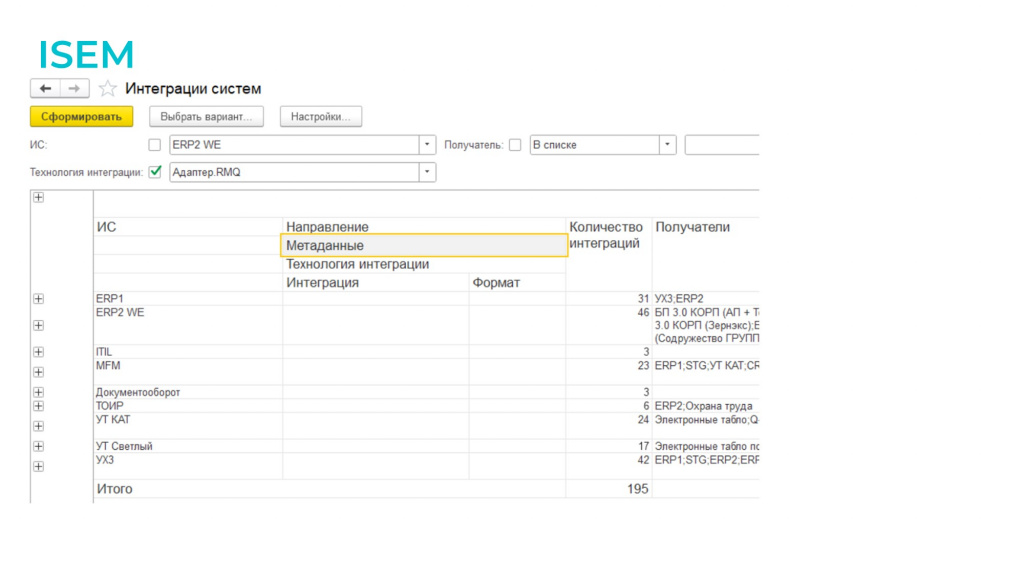
В результате мы за короткий срок описали все интеграции – всего у нас оказалось около 2000 интеграций. Сейчас мы можем ответить на вопросы:
-
Какая система у нас с чем меняется.
-
По какой технологии они меняются – в продукте ISEM есть отдельная сущность для описания технологии.
-
По какому протоколу.
-
Какие метаданные.
Теперь стало возможно ответить на вопрос: «Куда у нас передается номенклатура, в каких направлениях, в каких форматах, по какому расписанию?» Поэтому берите, пользуйтесь, плохого не посоветую.

Все ли инструменты из тех, что мы использовали, я сейчас перечислил? Нет, не все. Я вообще не касался вопросов коммуникации, а на мой взгляд это очень важно. Это коммуникация между разработчиками, между разработчиками и аналитиками, между командой разработки и заказчиками.
Но то, что я перечислил – это те 20% инструментов, которые точно работают и точно нам помогли.
Выводы
Какие можно сделать выводы по итогам этого всего?
-
Есть архитектурные принципы. Это принципы, а не догмы. Один и тот же принцип везде работает по-разному.
-
Все архитектурные подходы хороши, но они часто бывают противоречивы. Какой нужен вам – подберет архитектор, такой человек нужен.
-
Есть много инструментов, но это не значит, что вашу задачу уже решали. Порой нужно делать свои инструменты, а еще лучше ими делиться.
-
Если вы сделали свой выбор, принимайте решение, несите ответственность за него до конца.
И от себя добавлю: чтобы распилить ERP, нужно быть сильным. Поэтому, коллеги, качайте мышцы, качайте мозг. Да пребудет с вами сила.
Используемая литература и источники
-
Роберт Мартин. Чистая архитектура. Искусство разработки программного обеспечения. Питер. 2018.
-
Интернет-ресурс. https://v8.1c.ru/static/1c-shina
-
Интернет-ресурс. https://enterprisecraftsmanship.com/posts/cohesion-coupling-difference/
Вопросы и ответы
Вы отказались от ERP, распилили ее на несколько баз, но в основе трех ваших конфигураций – Управление торговлей?
База «Управление торговлей» у нас используется одна, причем вместо нее уже ERP.
А остальные две базы называются «УТ на ПЛК». Их две, потому что у нас два комбината. А конфигурация у этих баз, по сути, одна.
Это две локальные базы, которые должны работать 24/7. На них завязаны шлагбаумы, проезды, взвешивание, оборудование. Там сложная интеграция с системой управления двором.
Для каждой из них развернут свой локальный кластер. Они территориально распределены – одна в Светлом, в Калининградской области, вторая в Курске. И они работают 24/7 независимо. Но по факту это один модуль, просто он как две базы.
Почему именно УТ, а не ERP с отключенными подсистемами, если они не нужны?
Сейчас уже ERP2. По ERP2 есть проблема – чтобы ее внедрять, ее нужно хорошо знать. Нужен по ней аналитик или человек, который ее знает. Сейчас с этим есть проблема.
Когда используется много баз, всегда возникает вопрос с аналитикой – бизнесу нужны данные, которые дергаются изо всех баз. Как вы эту проблему решаете?
У нас в базах есть сервисы, к которым можно обращаться по HTTP, и они возвращают нужную информацию, в том числе могут вернуть готовый отчет.
Пока что у нас корпоративный стандарт – это Power BI, потому что в компании есть не только 1С-ники, но и другие отделы разработки.
Поэтому у нас есть BI-инженеры, которые собирают витрины данных не просто с разных баз, но и с разных приложений. Допустим, у того же подвижного состава все данные хранятся в MySQL.
Получается, у вас отчет не только из 1С, поэтому 1С:Аналитику здесь не получилось применить?
1С:Аналитику хотелось попробовать, но пока не пробовали. Хотелось бы, чтобы 1С:Аналитика умела получать данные из разных приложений, потому что я работаю с 1С, и мне интересно, чтобы в компании развивались 1С-решения, но пока нет.
Как контролировали соблюдение соглашений при разработке?
Когда мы еще собирали монстра на ERP2, у нас еще не было технической возможности применять EDT, потому что она прожорлива и на тот момент еще плохо работала с большими конфигурациями. Все-таки это был 2018 год.
Тогда я, по сути, все релизы собирал руками. У меня была куча cf-ников, я собирал релиз, запускал какой-то дымовой тест и смотрел, есть у меня объекты без подсистем или нет. Если такие объекты есть, просил разработчика добавить.
Также глазами смотрел на архитектуру решения тот, кто собирал релиз – это был либо я, либо меня замещали коллеги. Мне было выделено для этого время, я туда вникал.
И я мог стопорнуть спорные архитектурные моменты – решить, что и как сделать правильнее.
Просто это было не так удобно, как сейчас, потому что, когда ты работаешь с конфигуратором, ты это делаешь уже постфактум. А сейчас я могу это делать почти в онлайне.
Судя по рассказу, большая часть работы была выполнена «в одно лицо», верно? А сколько всего разработчиков в команде?
Сейчас у нас в команде 12 человек. А по поводу «в одно лицо» – есть разные роли в команде, разные модели лидерства. У меня в команде роль разгоняющего: я разгоняю проект, разгоняю технологию. Тем не менее во всех этих процессах участвовала вся команда.
Допустим, Yellow Collector и менеджер интеграции ISEM написал я самостоятельно, но его же, во-первых, нужно еще заполнить, по нему нужно давать обратную связь, и здесь была задействована вся команда. Поэтому поработали все.
Распилив систему-монолит, вы не огребли кучу проблем с дублированием НСИ?
Мы еще распиливаем его. У нас еще остались другие области.
Да, проблемы с НСИ есть, мы их постепенно решаем.
С НСИ есть проблемы разного рода – например, как определить, где какая именно НСИ нужна. Этот вопрос у нас пока не решен, здесь нужна методология, а у нас ее пока нет.
Да, проблемы есть, но они пока не особо мешают.
У вас много интеграций, в том числе НСИ гоняется между базами. А сталкивались ли с проблемами встречного изменения в разных базах НСИ и как их решали? Я же правильно понимаю, что практически все на очередях построено? И в очереди одновременно во встречном направлении могут быть одни и те же объекты.
НСИ регистрируется к обмену тоже не во всех базах. По факту у нас сейчас одна база, которая управляет НСИ. Причем она не была изображена на слайдах.
У нас исторически так сложилось, что НСИ начали делать на «Управлении холдингом». На мой взгляд, это была большущая ошибка, но оно и сейчас так есть. Поэтому контрагенты, номенклатура, организации – все это приходит из «Управления холдингом».
Да, есть проблемы с НСИ, но они возникают там, где интеграция реализовала не через Шину, а там, где у нас остались интеграции по КД2, через планы обмена.
Там, где идут эти хитрые выгрузки по ссылке – выгружать объект целиком, выгружать по требованию, по необходимости, где еще буферные регистры есть, там, где регистрируются. Там да, периодически возникают проблемы, но с этими проблемами успешно справляется Service Desk.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции INFOSTART EVENT.
