Хочу затронуть проблему документации – в частности, отсутствие единого источника, в котором бы хранилась документация, информация по задачам и история изменения объектов метаданных.
Так как я в своей практике часто сталкиваюсь с хаосом и неразберихой в имеющейся документации в компаниях, как мне кажется, эта проблема связана именно с отсутствием этого единого источника.
Мы рассмотрим, как можно управлять задачами и документацией различного уровня в конфигурации 1С.
-
Познакомимся с конфигурацией Управление задачами: Канбан доска.
-
Посмотрим, как в управлении документацией нам поможет использование продуктов Atlassian Jira и Confluence, в частности, их REST API.
-
Посмотрим, как можно организовать хранение документации в разрезе объектов метаданных.
-
Бонусом я расскажу, как можно реализовать конструктор создания статей в Confluence.
Как обычно ведется документация
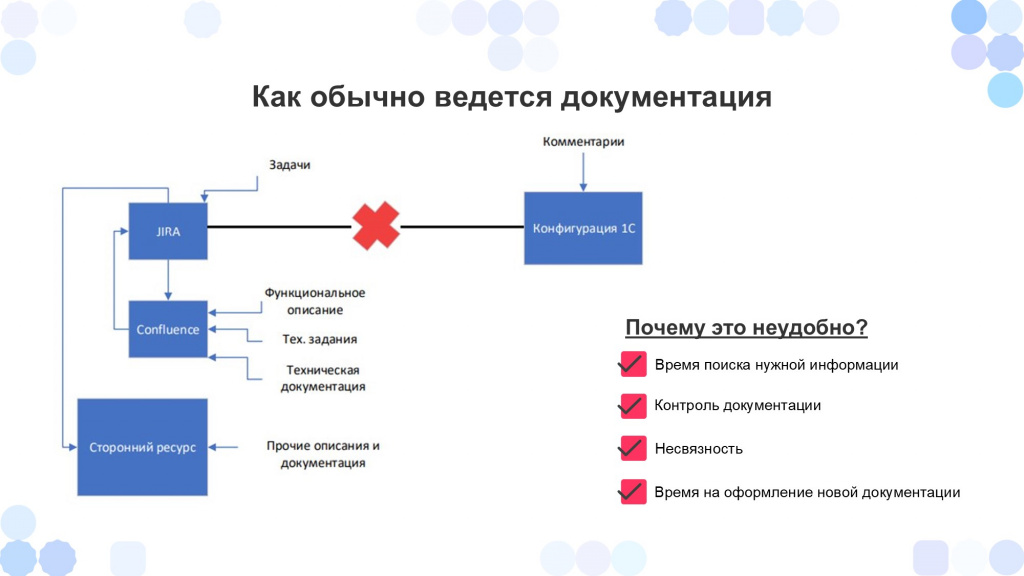
При ведении документации у нас обычно есть два не связанных между собой блока:
-
Есть какая-то система для учета задач, например, Jira. И какие-то сторонние ресурсы, где хранится функциональное описание, техзадания и прочая документация к нашей системе – в данном случае, это Confluence. Эти ресурсы могут быть связаны с системой задач, либо не связаны, но мы выделим их в один блок.
-
И есть второй блок, где хранятся сами конфигурации, которые мы дорабатываем
Зачастую единственная связь между этими двумя блоками – это комментарии, которые оставляет разработчик в коде со ссылкой на задачу. Но пользоваться такой связью неудобно, потому что:
-
Увеличивается время поиска нужной информации. Нам нужно зайти в конфигуратор, найти конкретный объект, посмотреть, есть ли в коде комментария ссылка на задачу, потом пойти в Jira, из нее перейти в Confluence. Затрачивается очень много времени.
-
Страдает контроль документации – мы не знаем, насколько на данный момент наша документация актуальна, в каком она в состоянии, ведется ли она своевременно, есть ли она вообще.
-
Несвязность – прямая связь объектов метаданных с нашей документацией отсутствует.
-
И затрачивается время на оформление новой документации, так как у нас, по сути, три разных источника и нам между ними нужно постоянно переключаться.
Возможное решение
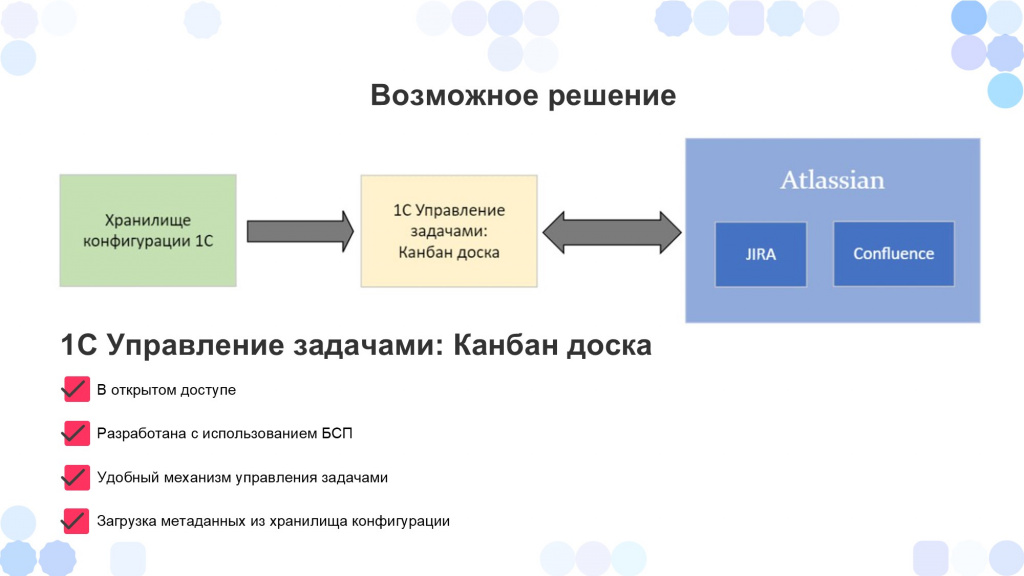
Я хочу предложить вариант решения для этой проблемы.
Возьмем три блока, которыми мы будем манипулировать.
-
За основу возьмем конфигурацию Управление задачами: Канбан доска.
-
В нее мы будем загружать из хранилища конфигурации наши объекты метаданных.
-
И настроим двухстороннюю синхронизацию с продуктами Atlassian – Jira и Confluence.
Такое решение позволит нам буквально парой щелчков мыши выбрать какой-то объект метаданных, который мы хотим, и узнать всю полезную информацию: какие были сделаны доработки, когда, кем, в рамках каких задач.
Почему была выбрана именно конфигурация Управление задачами: Канбан доска?
-
Она в открытом доступе, ее можно скачать на GitHub, она поддерживается.
-
Она разработана с использованием БСП, что упрощает нам доработку.
-
В нее уже встроен удобный механизм управления задачами – не нужно ничего с нуля создавать.
-
И, что нам важнее всего, в ней уже реализована загрузка метаданных из хранилища конфигурации.
Схема взаимодействия
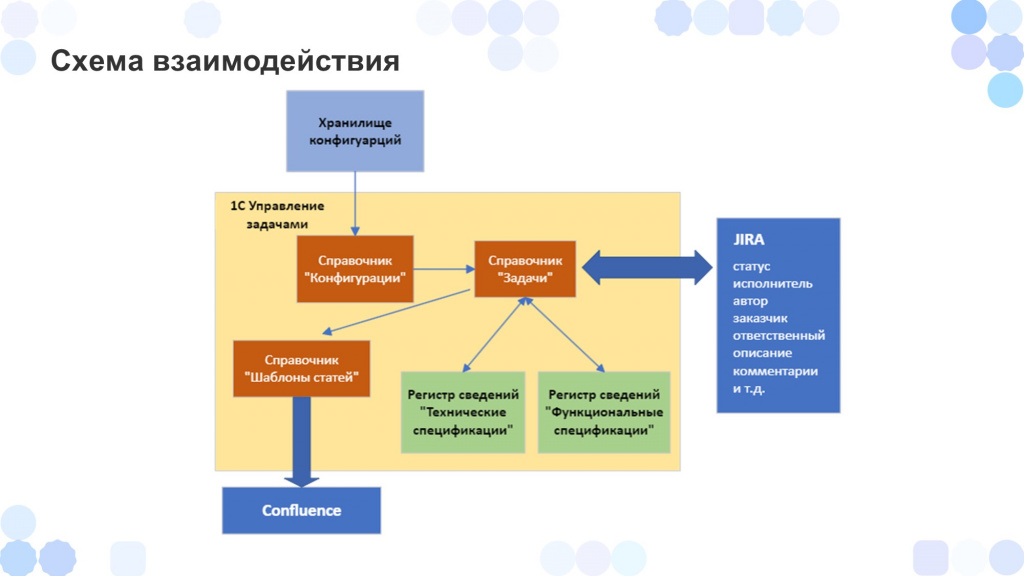
Объясню схему взаимодействия.
За основу взята конфигурация Управление задачами. В нее встроена обработка, которая позволяет загрузить объекты метаданных из хранилища конфигурации в специальный справочник «Конфигурации».
Мы немного доработаем конфигурацию «Управление задачами» – введем два новых периодических регистра сведений, которые будут у нас хранить ссылки на документацию. Регистра два, потому что, мне кажется, лучше разделять:
-
Технические спецификации – документацию, которую пишет разработчик.
-
И функциональные спецификации – документацию, которую будут писать аналитики. Туда будут входить пользовательские инструкции и ТЗ для программистов.
Кроме этого, мы настроим двустороннюю синхронизацию с Jira и будем получать в справочник «Задачи» поля, которые нам необходимы, например:
-
Статус;
-
Исполнитель;
-
Автор;
-
Заказчик;
-
Ответственный;
-
Описание;
-
Комментарии;
-
и так далее – можем получить любые поля.
Причем поскольку синхронизация двусторонняя, мы можем внести изменения на стороне 1С, а потом из 1С их обратно загрузить в Jira.
И добавим справочник «Шаблоны статей» – он будет выступать как конструктор документации, в котором можно для определенных объектов метаданных задать шаблоны, чтобы их основе потом создавать статьи Confluence.
Работать это будет так:
-
Когда разработчик либо аналитик хочет создать документацию, он выбирает объект метаданных и нажимает кнопку «Создать».
-
Если для этого объекта метаданных в справочнике «Шаблоны статей» заполнен шаблон, он автоматически через API будет передан в Confluence.
-
В результате в Confluence будет создана предзаполненная страница с готовой структурой: шапкой, наименованием, макросами, таблицами и другими элементами. Останется только ее заполнить.
Это довольно удобно – особенно если нужно унифицировать документацию, чтобы все писали ее плюс-минус одинаково, не вразнобой.
Технические спецификации

Покажу, как выглядят технические спецификации, и что это такое.
На слайде показана карточка задачи, у нее есть табличная часть «Технические спецификации». Здесь видно:
-
период, когда была сделана запись;
-
по какому объекту метаданных создавалась документация;
-
кто эту документацию написал – кто ответственный;
-
и ссылка на Confluence на эту документацию.
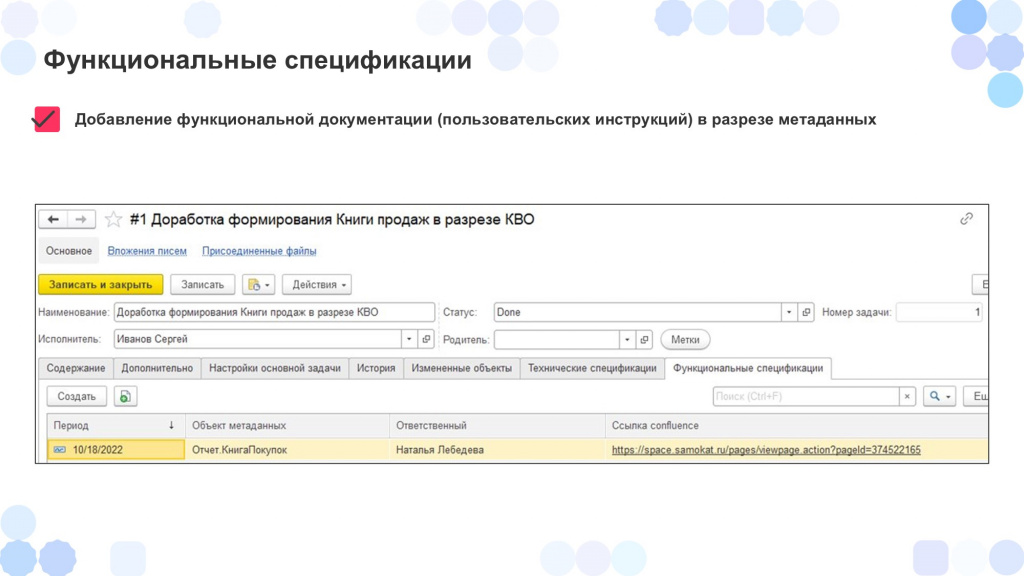
Такая же история здесь с функциональными спецификациями: практически такая же табличная часть, только ею в основном будут пользоваться аналитики, они будут писать ТЗ и пользовательские инструкции.
Схема реализации
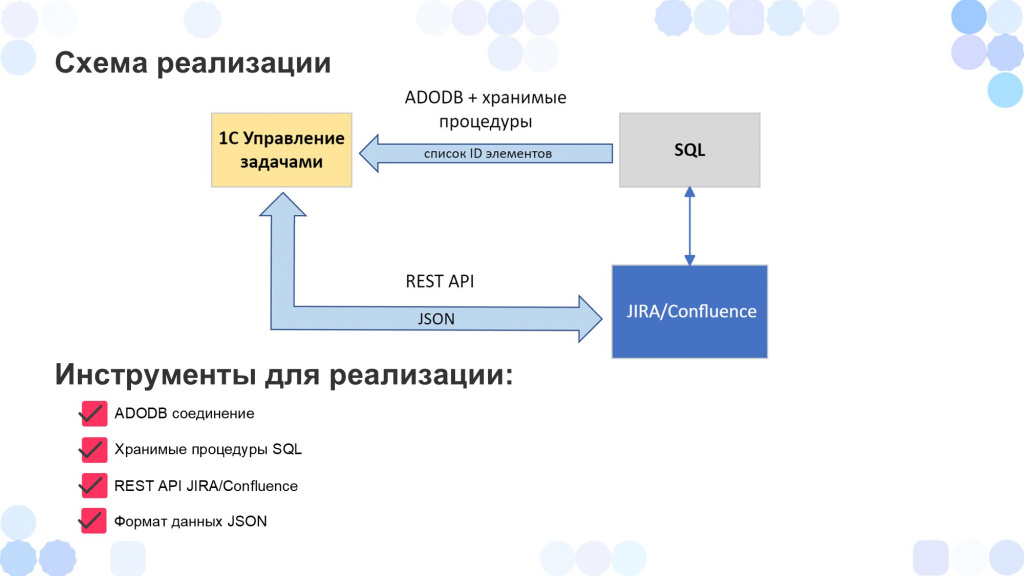
Опишу схему реализации – что было нужно для этого и чем пользовались.
Были использованы четыре главных инструмента для реализации:
-
соединение ADODB и хранимые процедуры SQL нам нужны лишь для того, чтобы подключиться к SQL-базе Jira и забрать оттуда список ID наших задач.
-
чтобы вообще запустить и подрубиться к SQL, мы пользуемся ADODB-соединением;
-
а хранимыми процедурами мы берем ID.
-
-
Дальше мы создаем в нашей конфигурации элементы справочника «Задачи» и заполняем их. Но все поля, которые нам нужны, мы берем из Jira через API. Таким образом мы реализуем двустороннюю интеграцию:
-
если мы что-то изменим в 1С, это также прилетит в Jira;
-
и если что-то изменится в Jira, это также прилетит в 1С;
-
а ADODB-соединение нужно для того, чтобы постоянно пополнять задачи, чтобы они попали в 1С, если были созданы только в Jira.
-
-
Также был использован формат JSON, потому что вся синхронизация через API реализована через этот формат.
Про каждый инструмент расскажу подробнее.

Подключение к SQL через ADODB-соединение выполняется довольно просто. Здесь нужен COM-объект ADODB.Connection и строка подключения с пользователем, которому доступны заранее созданные в SQL-базе хранимые процедуры.

Запросы к REST API выполняются через HTTP-соединение.
Подключаемся к серверу Jira через заранее заведенного системного пользователя Atlassian с определенными правами. Я чуть позже скажу, какие права ему для этого нужны.
И дальше мы просто через объект HTTPЗапрос выполняем запросы к API.
Причем есть пять различных видов запросов – POST, GET, PATCH, PUT, DELETE.
Как понять, какой вид запроса и когда нам нужен, я сейчас расскажу.
Для этого имеется документация Atlassian, она довольно удобная. Здесь я приложил ссылки:
Там слева довольно удобно организован список объектов – при раскрытии показывается перечень доступных методов, которые помечены цветными маркерами в зависимости от вида запроса.
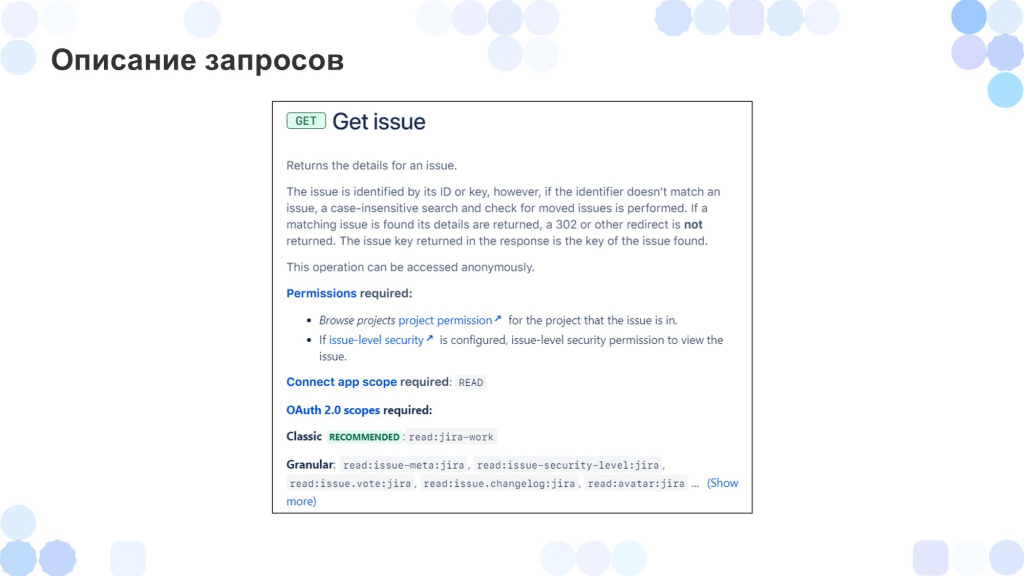
Например, вот так выглядит описание GET-запроса для объекта Issue – он подойдет, если нам нужно получить задачу. Мы видим:
-
вид запроса, очевидно – GET;
-
что он возвращает;
-
что нам нужно подать на вход – либо ID, либо ключ задачи;
-
какие права нужны пользователю для того, чтобы воспользоваться этим запросом.
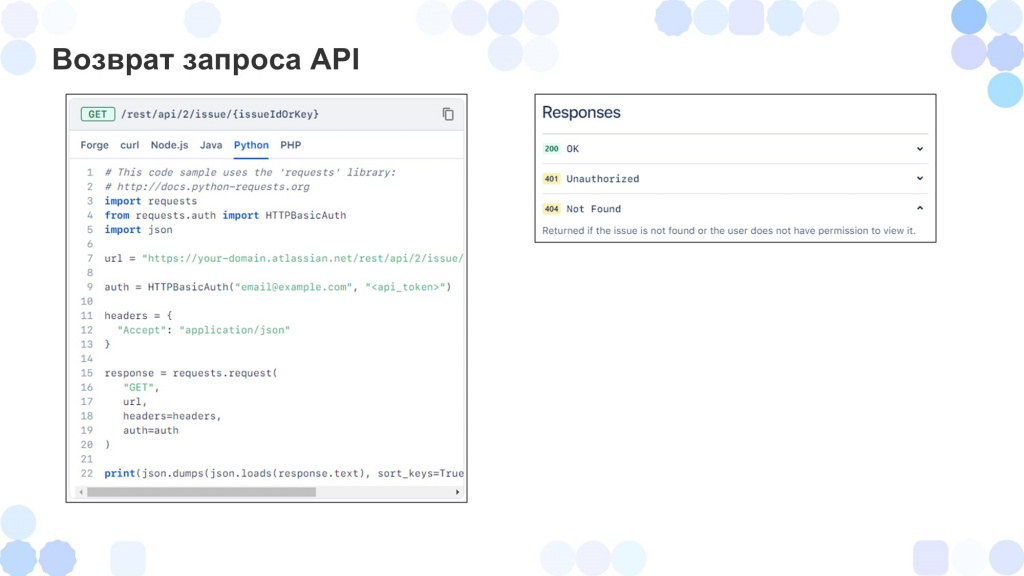
Также можно посмотреть:
-
как пишется запрос, и что нам для него нужно;
-
коды возврата, которые нам предоставляет API для этого запроса;
-
и пример обращения к API на шести языках программирования, которые мы можем использовать как референс, чтобы перевести на 1С.
Этим очень удобно пользоваться.

Ну и также нам, как я уже сказал, понадобится работа с данными формата JSON:
-
Так как любые параметры, которые мы передаем через API, должны быть оформлены в виде JSON, нам понадобится ЗаписьJSON.
-
И когда мы получаем ответ от API, нам нужно прочитать JSON через ЧтениеJSON, распарсить эти данные и распределить их по местам в нашей конфигурации.
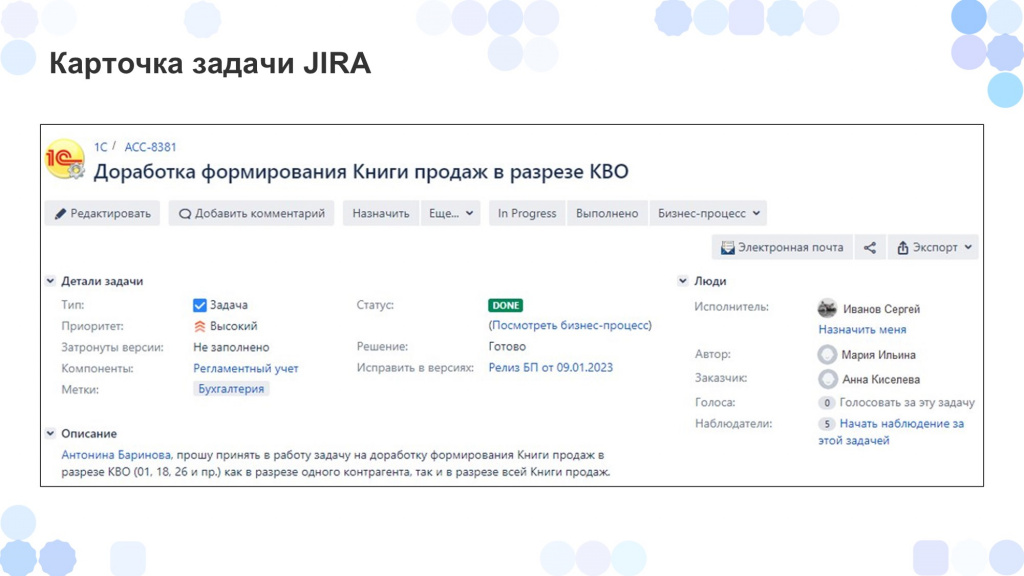
Я покажу, как мы реализовали эту доработку.
Изначально у нас была карточка задачи Jira – на слайде показана шапка задачи.
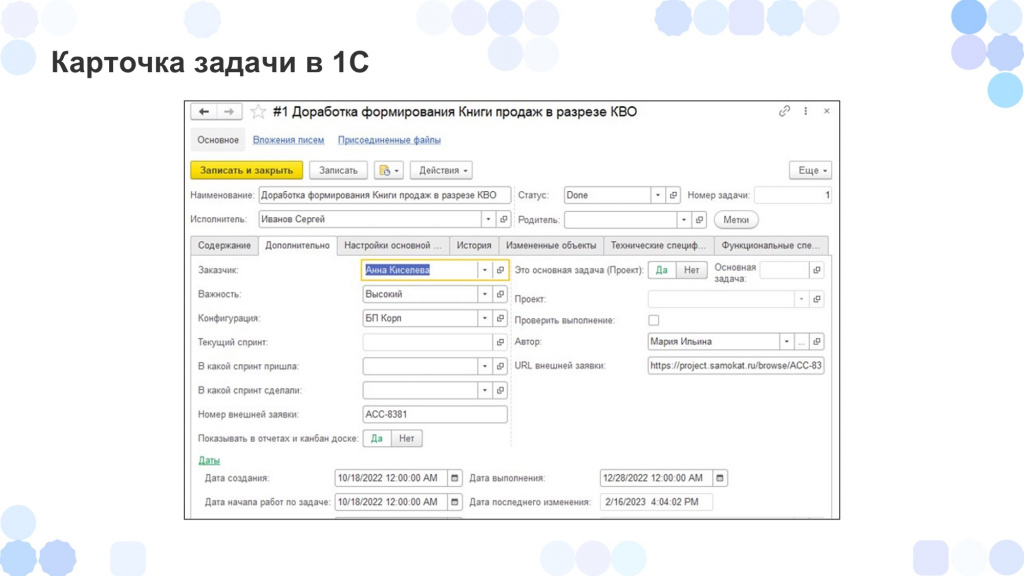
Вот так в итоге это выглядит в карточке задачи 1С
Основные поля – Статус, Наименование, Исполнитель – мы взяли из Jira.
Плюс здесь добавились новые поля – например, Конфигурация, ссылка на одноименный иерархический справочник, куда у нас загружаются объекты метаданных из хранилища конфигурации.
Таким образом мы к задаче подтянули нашу конфигурацию. И когда разработчик либо аналитик будет писать документацию, он выберет, какой конкретно объект метаданных он хочет описать, и какие изменения он сделал.
При выборе объекта метаданных (элемента справочника «Конфигурации») документация привязывается к объекту метаданных и к задаче – у нас получается связь, которой до этого не было.
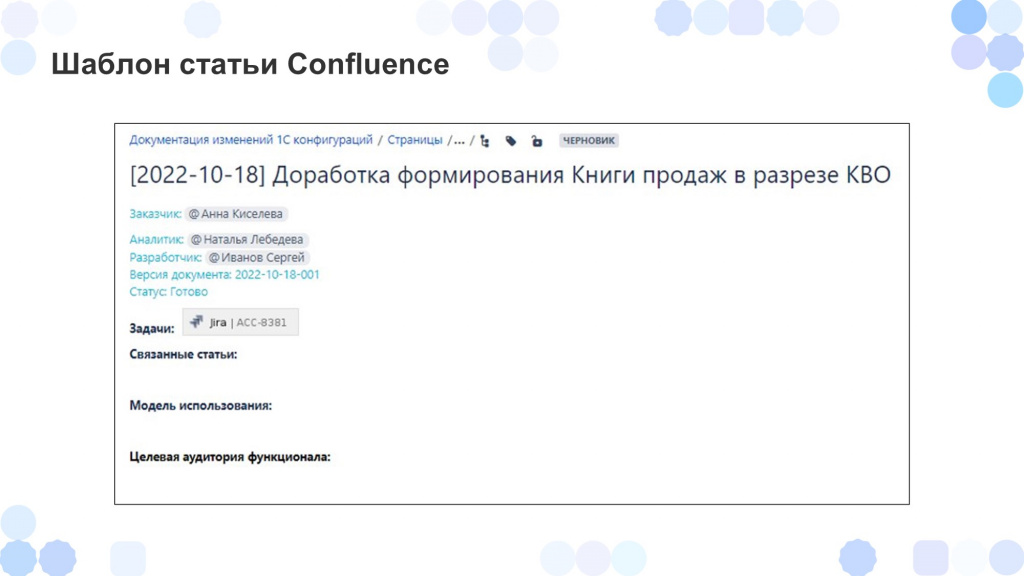
Так может выглядеть пример шаблона статьи Confluence. Здесь есть предзаполненные значения:
-
Наименование, которое мы взяли из задачи;
-
Заказчик;
-
Аналитик;
-
Разработчик и так далее.
Можно пользоваться макросами – как это сделать, описано в документации. Причем можно пользоваться как стандартными макросами, так и покупать дополнительные – у нас был такой случай.
Альтернативы использования

Еще хочу поговорить об альтернативах Atlassian. Их довольно много, и я не вижу смысла углубляться в каждый из них в отдельности, чтобы как-то сравнивать.
Но я для себя выделил три основных преимущества Atlassian перед другими системами:
-
Продукты Atlassian популярны – скорее всего, у вас в компании уже есть Jira и Confluence вместе или только Jira.
-
Jira и Confluence уже между собой синхронизированы «из коробки» – не нужно ничего настраивать.
-
У них хорошая документация, и это упрощает настройку интеграции с ними – можно разобраться очень быстро.
В моем случае я сделал синхронизацию, используя продукты Atlassian, но привязываться именно к этим продуктам необязательно.
Если есть достаточно гибкий API, в котором есть все, что нам нужно – этот же механизм мы можем спокойно перенести на любую другую систему.
Преимущества и недостатки

Поговорим о преимуществах и недостатках этого механизма.
Из преимуществ:
-
У нас появился быстрый доступ к документации в одном месте. Это то, чего мы добивались.
-
Удобство ведения задач – так как все теперь в одном месте, все очень прозрачно видно в отчетах.
-
Эффективное тестирование доработок. Например, если у нас есть какой-то уже доработанный объект метаданных, который мы хотим еще больше доработать, то при написании сценария тестирования мы можем построить по нему отчет и посмотреть, какие уже были доработки. Это поможет нам написать качественный сценарий тестирования, чтобы ничего из прошлых доработок не затерлось и не поломалось.
-
У нас появляется ведение документации в разрезе метаданных конфигураций. Мы этого добивались, мы это получили.
-
Конструкторы заполнения статей Confluence и задач. Мы можем сделать предопределенные конструкторы не только для статей Confluence, но и для задач, чтобы пользователь не выбирал сам все подряд, а чтобы это заполнялось автоматически или полуавтоматически. Это все тоже можно в 1С через API доработать.
-
Возможность расширения функциональности в плане гибкости. Здесь тоже можно все что угодно надстраивать без каких-либо проблем.
-
Простота доработки системы. Правда здесь важно оговориться, что имеется в виду именно доработка системы – когда все уже работает и синхронизация с системой документации настроена.
Здесь переходим к недостаткам:
-
Сложность реализации с нуля такой системы довольно высокая, особенно если разработчик никогда не работал с API и конфигурация «Управление задачами» для него новая. Потому что для самостоятельной реализации таких доработать нужно изучать документацию, а она на английском. На это потребуется время.
-
Время на обучение персонала. Поскольку механизм новый, нужно будет написать пользовательские инструкции, чтобы все понимали, как с этим работать – куда что писать, где что забивать, куда что нажимать. На обучение потребуется довольно много времени.
-
Возникает необходимость поддерживать дополнительную конфигурацию – нужно выделять на это разработчика, чтобы он тратил на это время.
-
Контроль заполняемости документации. Да, стало лучше, прозрачнее, удобнее, но проблему контроля заполняемости документации мы здесь не решим. К сожалению, мы должны полагаться на добросовестность сотрудников, что они действительно заполняют описания, делают это своевременно и так далее. К сожалению, мы никак не можем решить эту проблему автоматическим путем.
-
При ведении документации возникают высокие шансы на ошибку. Даже когда пользователи уже не первый месяц с этой системой работают, все равно из-за сложности такой схемы всегда будет шанс на ошибку – не туда записать документацию, выбрать не тот объект и так далее. Потом придется это все откатывать. Причем это все тоже можно реализовать, поэтому это не критичный недостаток, тем не менее он есть.
Вопросы и ответы
Какое хранилище использовалось – 1С или Git? Доступ в него осуществлялся напрямую или через промежуточное трансформирование в конфигурацию и выгрузку файлов?
Было хранилище 1С, не Git. Загружалось в «Управление задачами» через встроенную обработку: она напрямую берет файлики, их парсит и заполняет в справочной конфигурации.
По TCP он тоже работает?
Точно не могу сказать, надо смотреть более детально.
Зачем в части интеграции Confluence с системой 1С нужен ADODB, если все по API поддерживается? Или были какие-то нюансы?
Когда я реализовывал, мне выбора не предоставили. Поэтому я говорю, что здесь как вариант ADODB.Соединение.
Скорее всего есть другие варианты, но это мой случай, мой кейс. Я говорю, что здесь как вариант можно использовать COM-объект ADODB.Connection и хранимыми процедурами брать ID. Но да, я понимаю, что COM-объект не для всех подходит.
Вы говорили про документацию в привязке к объекту метаданных. А документация у вас для кого? Для пользователей, для службы поддержки, для разработчиков, для аналитиков? Что это за документация?
Для всех. У нас получается три варианта документации.
-
У нас есть техническая документация, которую пишут разработчики.
-
Есть документация для разработчиков – это ТЗ, который пишут аналитики.
-
И также есть документация для пользователей – это пользовательские инструкции.
Допустим, у нас есть задача по доработке книги продаж. И есть соседняя задача для доработки книги продаж, которая была сделана год назад. Как описания к этим задачам связаны между собой? Дорабатывается имеющаяся документация или пишется новая? Вопрос в связке. Именно сейчас я вижу задачу, изменения конфигурации и изменения документации. Есть ли отчет о том, что есть такой объект метаданных, и по нему история изменения?
У меня на слайдах примера отчета нет. Но я рассказываю, как это внутри выглядит, просто как я реализовывал. Вот и все.
А если документация затрагивает несколько объектов метаданных, как здесь быть? Можно привязаться ко всем?
Да, конечно. У нас задача может затрагивать изменения многих объектов – например, требуется доработать несколько форм или несколько модулей. Все эти объекты можно привязать к одной задаче, чтобы дальше мы видели, что сделано в рамках одной задачи.
Правильно ли я понимаю, что к задаче может быть привязано только одно хранилище? А как быть с интеграционными задачами, когда у нас есть две конфигурации? Это будет поддерживаться или нужны доработки?
Я думаю, это надо будет дорабатывать.
*************
Статья написана по итогам доклада (видео), прочитанного на конференции INFOSTART EVENT.
