В этом посте я собираюсь показать результаты тестов недавно выпущенного PostgreSQL 10.1. Я проверил БД на этих ОС (все 64-битные):
- Ubuntu 16.04, ядро 4.10.0-38-generic
- openSUSE 42.3, ядро 4.4.87-25-default
- CentOS 7.4, ядро 3.10.0-693.2.2.el7.x86_64
- Debian 9.2, ядро 4.9.0-4-amd64
- FreeBSD 11.1
Методология тестирования
Целью теста было измерение производительности PostgreSQL в условиях, аналогичных(типичных) производственному развертыванию:
- клиенты подключаются через пул соединений, чтобы гарантировать, что нет постоянного переподключения к БД (я не использовал пул соединений, вместо этого я не использовал флаг -C pgbench)
- клиенты подключаются по сети, не через сокет unix
- директория с данными PostgreSQL находится на зеркале RAID 1
Для каждой из протестированных ОС была создана контрольная база данных ~74 ГБ:
pgbench -i -s 5000 pgbench
Тестовая инфраструктура состояла из двух выделенных серверов, соединенных с сетью 1 Гбит/с:
- EX41-SSD: Intel i7-6700, 4 ядра, 8 потоков, 32 ГБ оперативной памяти DDR4, использовался для генерации SQL-запросов с использованием pgbench
- PX121-SSD: Intel Xeon E5-1650 v3, 6 ядер, 12 потоков, 256 ГБ ОЗУ DDR4 ECC, 2 x 480 ГБ SATA 6 Гбит/с, дата-центр серии SSD, использовался в качестве сервера PostgreSQL
Меня интересовали эти тестовые комбинации:
32 ГБ только чтение: тест только чтения (только выборки без изменений данных), набор данных не помещается в кэш PostgreSQL
200 ГБ только чтение: тест только чтения, набор данных помещается в кэш PostgreSQL
32 ГБ TCP-B: чтение-запись, набор данных не помещается в кэш PostgreSQL
TCP-B 200 ГБ: чтение, запись, набор данных помещается в кэш PostgreSQL
настройка pgbench
Программа pgbench версии 10.1, запущенная на отдельном компьютере FreeBSD 11.1, использовалась для генерации нагрузки. Тестовый скрипт состоял из трех частей: vacuum + прогрев, тест только чтение и тест чтения и записи. Перед каждым тестом чтения-записи таблицы pgbench очищались (использовался флаг -v). Во время теста я постепенно увеличивал количество клиентов, обращающихся к базе данных.
#!/bin/sh
THREADS=8
DURATION=1800
PGIP=192.168.1.120
# warmup
pgbench -h ${PGIP} -U pgbench -j ${THREADS} -c 10 -T ${DURATION} -S -v pgbench
for clients in 1 10 20 30 40 50 60 70 80 90 100 110 120
do
echo "RO ${clients}"
pgbench -h ${PGIP} -U pgbench -j ${THREADS} -c ${clients} -T ${DURATION} -S pgbench > pgbench_ro_${clients}.log
done
for clients in 1 10 20 30 40 50 60 70 80 90 100 110 120
do
echo "RW ${clients}"
pgbench -h ${PGIP} -U pgbench -j ${THREADS} -c ${clients} -T ${DURATION} -v pgbench > pgbench_rw_${clients}.log
done
Настройки сервера PostgreSQL
Для дистрибутивов Linux PostgreSQL был установлен в файловой системе ext4 в настройке RAID1 (программный RAID с использованием mdraid) на двух SSD с отключенным atime. В случае FreeBSD файловая система OpenZFS использовалась на двух SSD при настройке RAID1. Набор данных ZFS с данными PostgreSQL был создан со следующими параметрами:
zfs get recordsize,logbias,primarycache,atime,compression zroot/var/db/postgres
NAME PROPERTY VALUE SOURCE
zroot/var/db/postgres recordsize 8K local
zroot/var/db/postgres logbias throughput local
zroot/var/db/postgres primarycache all default
zroot/var/db/postgres atime off inherited from zroot
zroot/var/db/postgres compression lz4 local
Конфигурация сервера PostgreSQL была одинаковой на всех ОС, кроме путей к файлам (каждая ОС использует свою структуру каталогов). Содержимое файла postgresql.conf (основные настройки) для экземпляра 32 Гб:
autovacuum = off
default_statistics_target = 100
maintenance_work_mem = 1GB
checkpoint_completion_target = 0.9
effective_cache_size = 24GB
work_mem = 104MB
wal_buffers = 16MB
shared_buffers = 8GB
max_connections = 300
Содержимое файла postgresql.conf для экземпляра 200 ГБ:
autovacuum = off
default_statistics_target = 100
maintenance_work_mem = 2GB
checkpoint_completion_target = 0.9
effective_cache_size = 144GB
work_mem = 640MB
wal_buffers = 16MB
shared_buffers = 48GB
max_connections = 300
Сравнительное тестирование
Я тестировал PostgreSQL на пяти разных операционных системах в двух режимах - только чтение и TCP-B (чтение-запись) с двумя различными профилями памяти. Тест каждой ОС занял около 30 часов (не считая времени, необходимого для настройки ОС). Результаты каждого запуска pgbench были сохранены для последующей оценки.
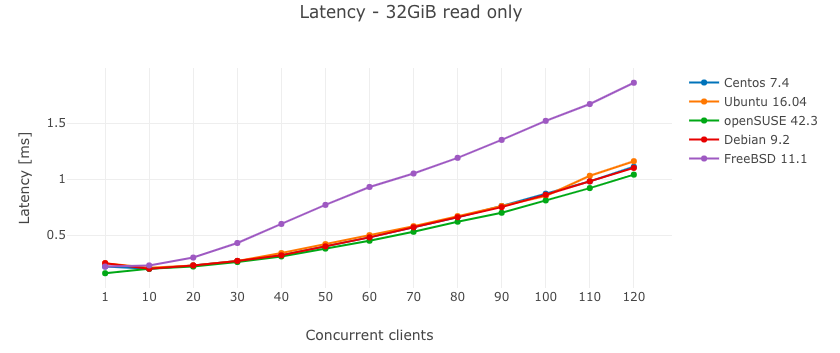
Результаты - Только чтение



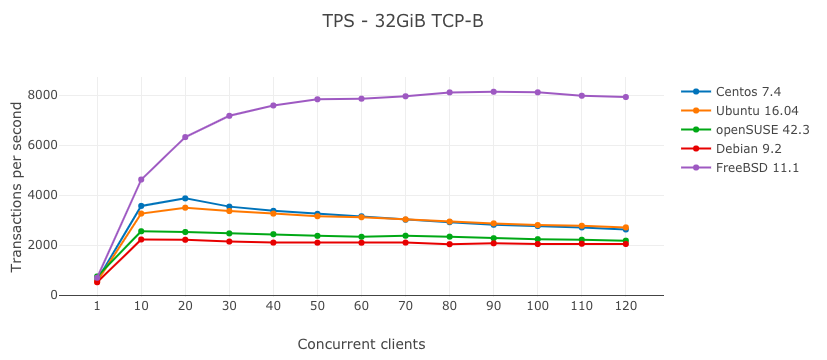
Результаты - TCP-B


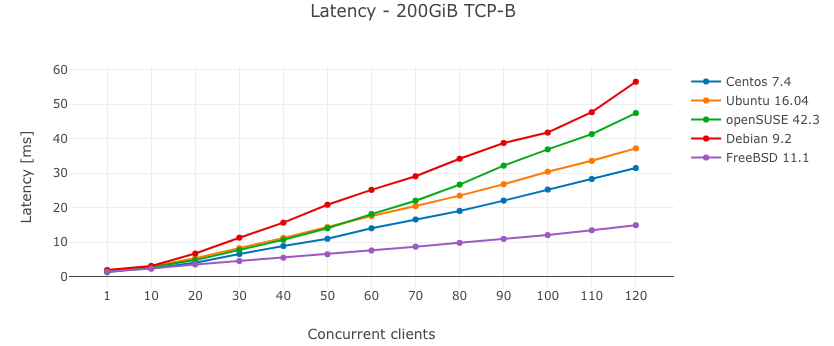
Итоги
Тест показал, что разница между различными дистрибутивами GNU/Linux не очень значительна. Лучшей операционной системой в тесте только для чтения была openSUSE 42.3, в то время как FreeBSD работала примерно на 40% медленнее. К сожалению, я не выяснил, что вызвало такую посредственную производительность FreeBSD.
Более реалистичная картина производительности PostgreSQL была получена в тесте чтения-записи (TCP-B). Среди дистрибутивов GNU/Linux Centos 7.4 был самым быстрым, а Debian 9.2 - самым медленным. Я был приятно удивлен FreeBSD 11.1, которая работала более чем в два раза быстрее, чем лучший Linux, несмотря на то, что FreeBSD использовала ZFS, которая является файловой системой copy-on-write. Я предположил, что такая разница была вызвана издержками на программный RAID в Linux, поэтому я сделал еще три теста TCP-B для 100 одновременно работающих клиентов, на этот раз без программного RAID:
- FreeBSD 11.1 + UFS: 5623,86 TPS
- FreeBSD 11.1 + ZFS: 8331,85 TPS
- CentOS 7.4 + ext4: 8987.65 TPS
Результаты показывают неэффективность Linux SW RAID (или эффективность ZFS RAID). Производительность CentOS 7.4 без SW RAID лишь немного выше, чем у FreeBSD 11.1 с ZFS RAID (для TCP-B и 100 одновременных клиентов).
P.S. Более подробно графики можно посмотреть в оригинале статьи хабр
Вступайте в нашу телеграмм-группу Инфостарт