
Здравствуйте, коллеги. Меня зовут Дмитрий Белозеров. Я работаю системным архитектором в компании LM Soft. Мы занимаемся внедрением систем проектного управления, управления жизненным циклом изделий и другими сложными и интересными решениями.
Также мы являемся владельцами нескольких собственных программных продуктов на платформе 1С, в процессе разработки которых у нас появился некоторый опыт и некоторые практики. И сейчас я бы хотел с вами ими поделиться.
Что такое кодогенерация?

Сразу скажу, что кодогенерация и метагенерация в мире 1С пока не очень распространены. По крайней мере, я честно пытался найти что-то подобное тому, что мы делаем, но пока не нашел.

Но в самой идее, которая заложена в основе, нет ничего особо нового.
Если вы в поисковике напишите слово «кодогенерация», то можете найти на эту тему много хороших статей и видео, в том числе и на русском языке – в последнее время я видел на YouTube несколько классных докладов по кодогенерации от разработчиков из мира Java, .NET, Swift и т.д.
Но надо понимать, что наша 1С – это достаточно специфическая среда разработки, и все эти практики требуют некоторой адаптации под особенности платформы.

Давайте сначала дадим определение, что такое кодогенерация. Это – очень широкое понятие:
-
Когда вы просто пишите код в конфигураторе, вы тоже в каком-то смысле занимаетесь кодогенерацией.
-
Или, когда, например, вы в «Конвертации данных 3.0» пишите правило, а потом на его основе формируете код на языке 1С, это тоже кодогенерация.
-
Или, например, когда вы заходите на сайт Facebook или ВКонтакте, то в этот момент тоже выполняется кодогенерация – весь Web2.0 технически основан на кодогенерации.
-
Но в нашем случае кодогенерация – это когда одна программа на языке высокого уровня пишет другую программу на языке высокого уровня. Я буду говорить сегодня именно об этом.
В общем виде это можно представить примерно так, как показано на слайде – у нас есть код на исходном языке, есть генератор и есть код на результирующем языке.
После такого определения, я думаю, у вас должен возникнуть вопрос – зачем такие сложности? Зачем генератор? Зачем код на исходном языке?
Попробую объяснить. В любой работе всегда есть некоторые задачи, которые не требуют творческого подхода, и где просто нужно что-то механически сделать.
Например, вам нужно в типовую конфигурацию добавить новый документ. Просто добавить объект метаданных недостаточно, потому что этот документ у вас должен обеспечивать некоторую общую функциональность – версионирование, просмотр структуры подчиненности, движений по документу, что-то еще. И, чтобы подключить этот созданный объект метаданных к общим механизмам вашей конфигурации, вы пользуетесь функциональностью стандартных библиотек и выполняете ряд действий по инструкции:
-
Расширяете состав определяемого типа;
-
Включаете объект в состав подписки на событие;
-
Добавляете какую-то строчку в модуль формы, еще что-то.
Это – простые действия, не требующие раздумий, но при этом их выполнение отнимает время. Тем более что в современных больших конфигурациях достаточно много подобных примеров. Например, в ERP есть огромное количество объектов, которые имеют функциональность присоединенных файлов, и для каждого такого объекта создается свой собственный справочник присоединенных файлов. В результате получается огромное количество дублирующихся объектов метаданных и кода – несмотря на то, что с дублированием мы пытаемся бороться. Как раз такие задачи очень хорошо было бы переложить на плечи машины.

Потому что машина может выполнить все эти операции за вас, причем она это сделает лучше, чем вы, поскольку исключается возможность ошибки по причине человеческого фактора.
Конечно, в скрипте кодогенерации, который мы напишем для автоматизации этих действий, у нас тоже может возникнуть ошибка, которая будет тиражироваться на весь сгенерированный код. А это означает, что будет много багов. Но мы можем исправить эту ошибку в исходном скрипте, выполнить перегенерацию, и все опять станет хорошо.

Если выражаться на языке бизнеса, то получается, что кодогенерация – это способ:
-
Во-первых, уменьшить себестоимость разработки;
-
А во-вторых, увеличить качество продукта.
Примеры применения кодогенерации для 1С

Чтобы вы не думали, что я говорю про каких-то «сферических коней в вакууме», я сразу приведу вам реальные примеры, с которых, собственно, и началась разработка нашего инструмента.
Первый, наиболее понятный пример – это наш программный продукт, MDM-система (от английского Master Data Management), с помощью которой мы управляем нормативно-справочной информацией. Фактически это конфигурация на платформе 1С, которая содержит большое количество справочников. Причем, все эти справочники обладают общей функциональностью – возможность поиска дублей, нормализации и т.д. По сути, они разные, но однотипные.

Когда мы на наших проектах собирали MDM-конфигурации для конкретных клиентов, у нас всегда возникал вопрос создания вот этих справочников, поскольку их состав от случая к случаю может очень сильно отличаться. Даже была инструкция о том, как добавить новый НСИ-справочник в нашу систему. Со скриншотами она занимала около 30 страниц.
В какой-то момент мы решили, что так больше жить нельзя, и реализовали собственный инструмент, который позволил выполнять эту работу автоматически.
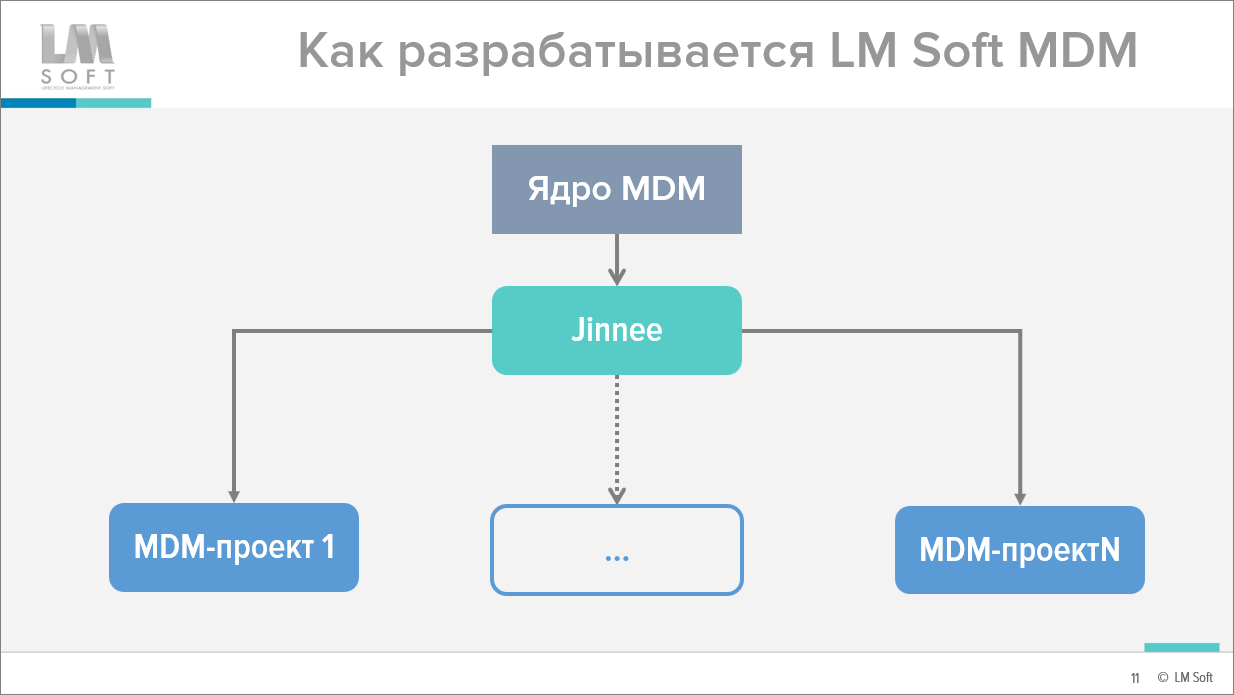
Как теперь выполняется разработка нашей MDM-системы?
-
У нас есть «ядро MDM» – некий набор общих механизмов, некая базовая конфигурация, в которой нет справочников НСИ, но есть некий эталонный справочник.
-
Дальше есть Jinnee (джинн) – мы так назвали наш кодогенератор, который:
-
Берет эталонный справочник, копирует его;
-
Изменяет его необходимые свойства – добавляет нужные реквизиты, выводит их на форму;
-
И подключает справочник ко всем нужным механизмам. В общем, генерит уже готовую конфигурацию для клиента.
-
Соответственно, если мы вносим изменения в ядро – мы можем перегенерировать конфигурацию еще раз, и все эти изменения туда попадут.
Таким образом, у нас, во-первых, решилась проблема скорости внесения изменений, а во-вторых, повысилось качество разработки, потому что отпали ошибки, которые могли возникнуть по причине человеческого фактора.
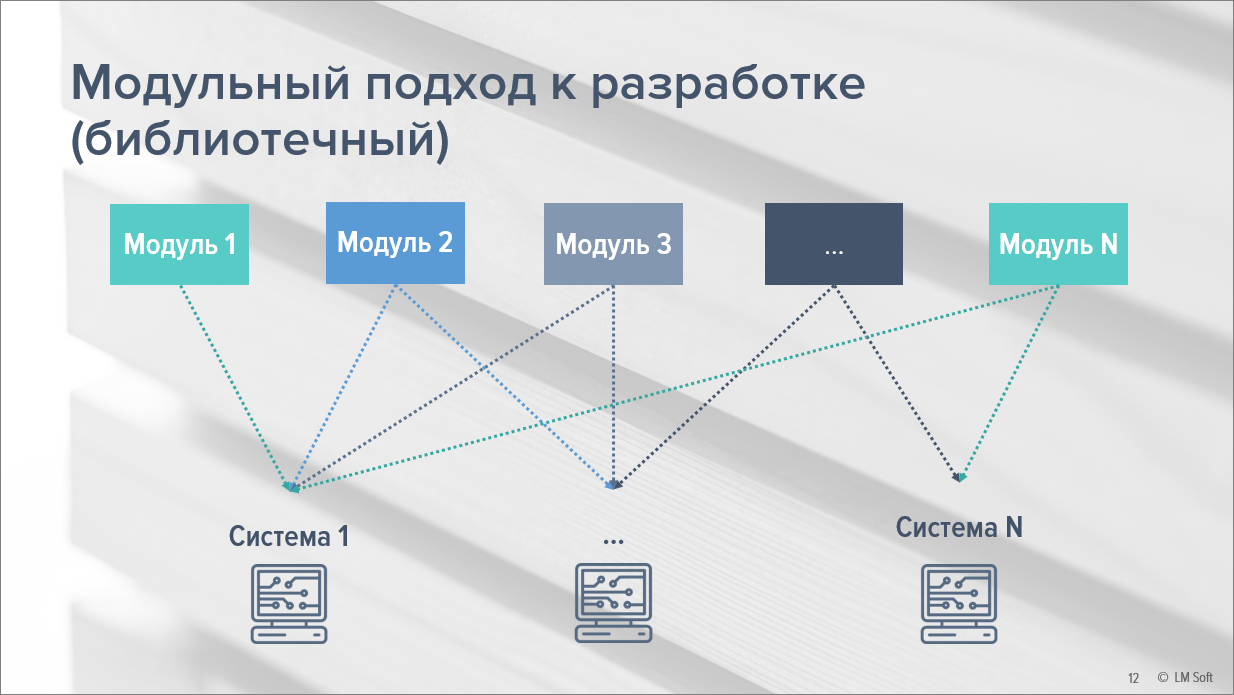
Но наша MDM-система – это не единственный пример того, как мы используем этот инструмент. В процессе разработки мы пользуемся библиотеками (как стандартными библиотеками 1С, так и собственными) – у нас есть некоторые подсистемы, которые «кочуют» из проекта в проект, используются более чем в одной конфигурации. Соответственно, возникает вопрос поддержки такого кода, потому что не очень интересно внести какое-то изменение в библиотеку, а потом копировать его в десять конфигураций.
Вот как раз Jinnee и решает эту проблему. Мы можем внести изменения только в ту конфигурацию, где ведется разработка этой подсистемы, а потом выполнить перегенерацию, и эти изменения попадут во все нужные нам места.
Получается «умный Continuous Integration» – именно интеграция на уровне кода, когда машина сама знает, что, куда и как нужно внести.

Я только что привел два вполне реальных примера нашей разработки. А дальше я приведу еще два кейса, которые пока что являются только плодом моего воображения, но вполне реализуемы.
Дело в том, что проблема 1С-ных доработок – их слабая отчуждаемость. Например, если вы доработали что-то в типовой конфигурации, вы не можете выложить свою доработку на Инфостарт просто так, потому что выкладывать в качестве публикации типовую конфигурацию запрещено. Конечно, вы можете выложить расширение, но, во-первых, механизм расширений имеет ограничения, а во-вторых, вам придется писать отдельное расширение под каждую дорабатываемую конфигурацию.
Эту проблему можно решить с помощью скрипта кодогенерации – можно написать некое «умное расширение», которое само знает, что ему нужно сделать при внедрении в конкретную конфигурацию. Вы запускаете скрипт, а он сам проанализирует, что это – такая-то конфигурация, с такими-то объектами метаданных, значит, нужно произвести такие-то действия. В итоге получается одно расширение, которое подходит для множества различных конфигураций.
Соответственно, те авторы, которые раньше не могли ни с кем поделиться своими доработками типовых конфигураций, смогут, ничего не нарушая, выложить их на Инфостарт и заработать на этом какие-то деньги.
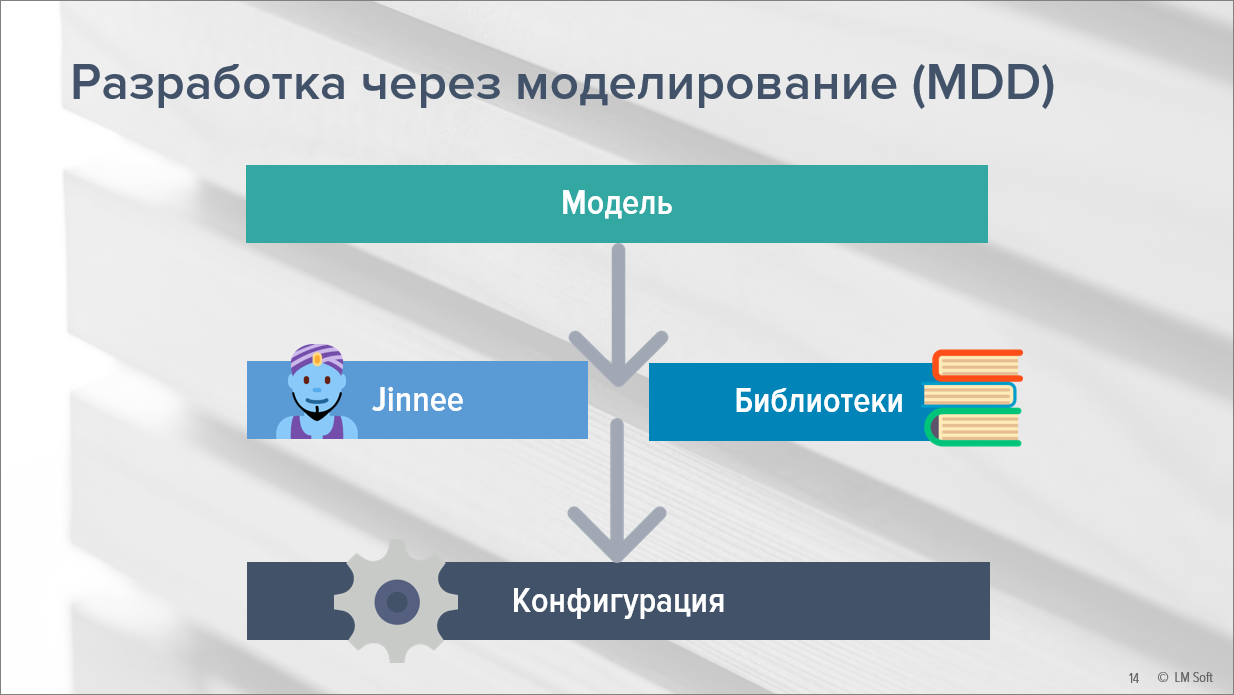
Следующий возможный кейс – это то, к чему мы все придем в ближайшее время – разработка через моделирование.
Дело в том, что писать сценарий для генерации – это, конечно, здорово. Но гораздо интереснее было бы нарисовать в любой нотации функциональную схему решения, а потом сгенерировать на основании этого код. Все это реализуемо.
Как я это вижу?
-
У нас есть некая модель. Мы реализуем ее в любом редакторе, в любой нотации, в которой хотим.
-
Следующим шагом мы выгружаем эту модель в формат XML.
-
Полученный результат конвертируем в Jinnee-сценарий.
-
И этот Jinnee-сценарий, полученный на основе модели, используя некие библиотеки, выдает на выходе готовую конфигурацию.
Дальше я покажу, как это у нас реализовано. Я надеюсь, что так будет понятнее.
Основные принципы проектирования инструмента
Но перед тем как я буду показывать сам инструмент, я расскажу о трех основных принципах, которые мы закладывали при его проектировании.

Первый принцип – это низкий порог вхождения. Тут мы не дошли до такого состояния, как на слайде – это не пример нашего разработчика, но мы сделали все, чтобы порог вхождения снизить.
Почему это важно? Потому что писать код, который напишет за вас код, экономически выгодно только в том случае, если его написание не занимает у нас много времени.
Например, если вы написали скрипт на 100 строк, который вам сгенерировал 1000 строк, вы сэкономили время и исключили риски человеческого фактора – это хорошо.
Но чтобы сэкономить это время, сам псевдоязык, на котором вы пишете скрипт для генерации, должен быть для разработчика максимально простым – в случае с 1С идеально было бы использовать родной 1С-ный синтаксис. Только в этом случае такая разработка становится экономически выгодной. Иначе можно и не начинать.

Второй принцип – это правильный выбор уровня абстракции. Что это означает? Дело в том, что наш инструмент работает на уровне XML. Это означает, что:
-
У нас есть исходный набор XML-файлов (мы выгрузили конфигурацию из конфигуратора в XML);
-
Что-то там с этими XML-ками программно сделали;
-
А потом их загрузили в конфигуратор и получили готовую конфигурацию.
Так вот, вся эта программная модификация XML не должна сильно напрягать разработчика. Разработчик не должен думать, как это реализовано на уровне XML. Например, чтобы изменить имя объекта метаданных, нужно внести изменения в нескольких местах XML-файла. Зачем разработчику это знать? Он просто напишет «ИзменитьСвойствоОбъектаМетаданных(<Имя>, <Значение>)».
Получается, что в нашем случае разработчик может мыслить именно в терминах объектов метаданных. Он вообще не знает, как это устроено с точки зрения XML, он делает то, что делал бы сам в конфигураторе руками.
В этом есть и другие плюсы – если XML-формат выгруженных файлов изменится (а такое периодически бывало и с форматом конфигуратора, и с форматом EDT), нам не придется переписывать наши уже написанные скрипты.

Третий архитектурный паттерн, который мы применили, я назвал «Сыктывкар». Объясню почему.
Пять лет назад я ездил в командировку в этот северный город, и тот район, где нас разместили, был очень печальный. И когда поздно ночью один мой коллега сказал: «У меня сигареты закончились, давайте сходим, купим», другой, более опытный коллега, который уже пожил в Сыктывкаре и знал, насколько этот район криминально опасный, ответил ему: «Тут за сигаретами нужно ходить с сигаретами».
Перефразируя эти слова применительно к нашему случаю – разрабатывая инструментарий 1С, нужно использовать инструментарий 1С.
Примеров такого подхода тоже много – это Конвертация данных, АПК, Инструменты разработчика. Разработчики, используя платформу 1С, уже существенно облегчили себе жизнь.
Работа с инструментом на практике
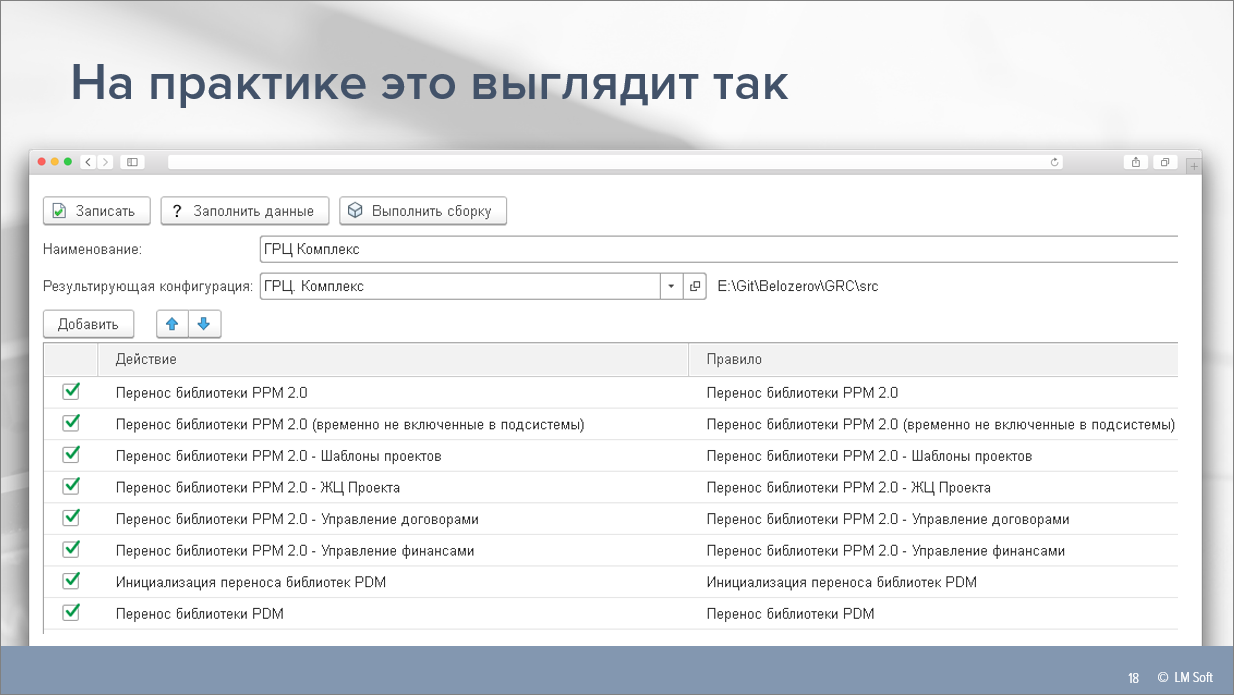
Перейдем к самому инструменту – рассмотрим, как он выглядит.
На слайде показан пример реального сценария генерации – в табличке перечислен список действий, каждое из которых выполняется по определенному правилу. Причем, действие – это просто текстовая строка, понятная для человека (чтобы было понятно, что тут делается). А вся магия кодогенерации выполняется в правиле.
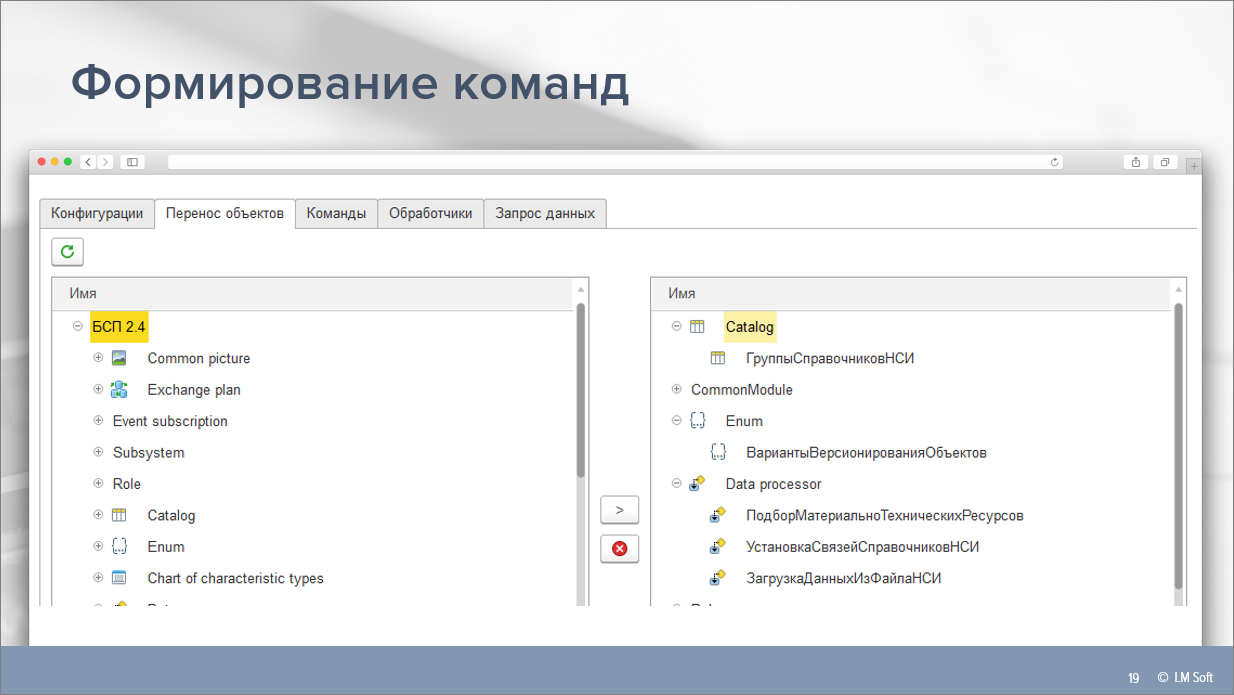
Перейдем к правилу, посмотрим, как оно устроено.
Принцип реализации правила независимо от используемой платформы всегда примерно один и тот же:
-
берется некий шаблон;
-
неким образом модифицируется;
-
и получается итоговый результат.
Вопрос только в том, что в случае 1С считать шаблоном? Мы посчитали, что шаблоном могут быть какие-то объекты метаданных исходной конфигурации. Соответственно, у нас здесь есть визуальный интерфейс, где мы в дереве метаданных можем выбрать, какие объекты исходной конфигурации нам нужно переместить в нашу результирующую конфигурацию. Этот состав объектов мы можем буквально «накликать» мышкой.
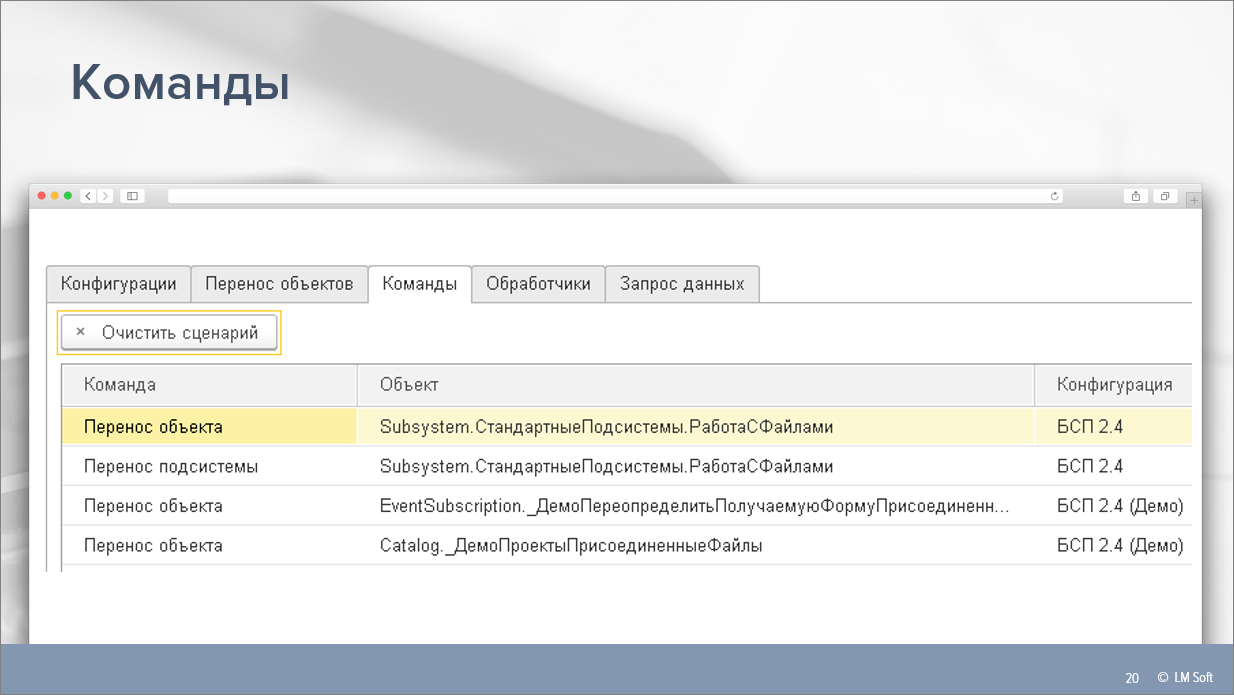
В результате, при переходе на соседнюю вкладку у нас получится вот такой сценарий. Причем, обратите внимание – в сценарии есть один и тот же объект (имя объекта метаданных одинаковое), но команды разные. Это означает, что мы можем переносить как объекты метаданных в отдельности, так и подсистему целиком.
Это очень удобно, когда мы, допустим, в правиле указали, что нужно взять из исходной конфигурации такую-то подсистему целиком, и дальше, даже если разработчики подсистемы в ней что-то изменят, добавят в нее новые объекты, нам не придется переписывать само правило.
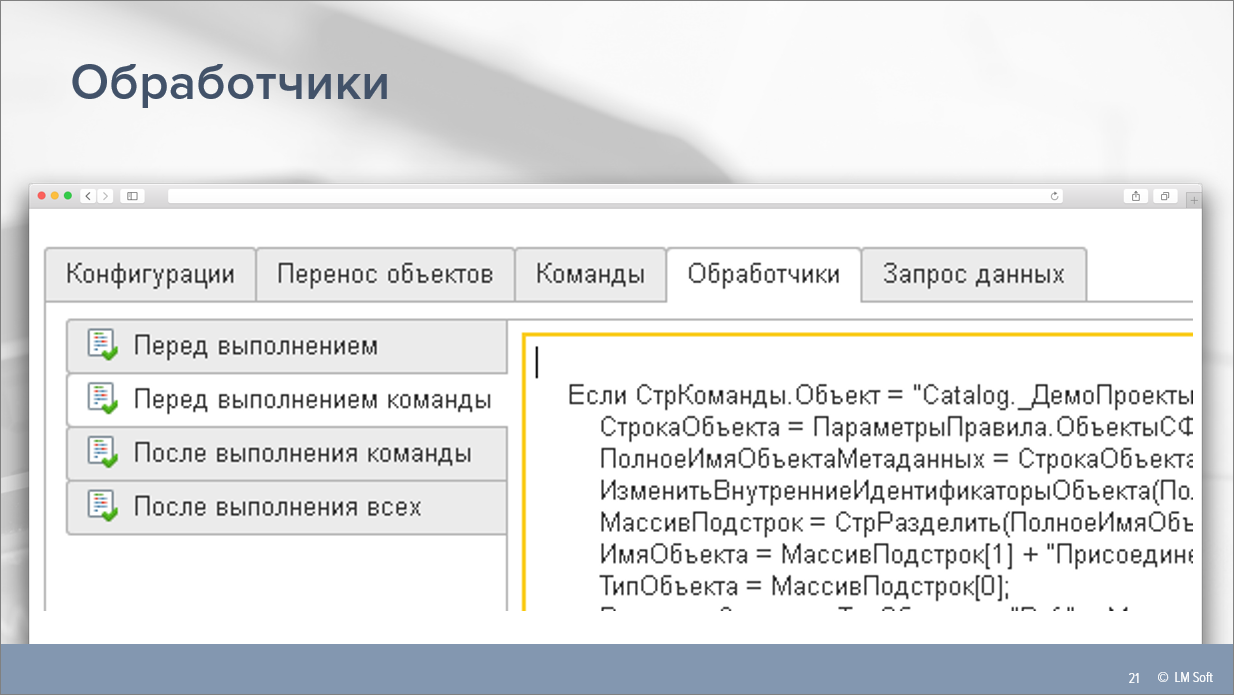
Возможность переносить объекты – это, конечно, хорошо. Но с ними, как правило, еще и нужно что-то сделать. И тут на сцену у нас выходят обработчики. Как раз все волшебство выполняется в обработчиках.
Как я уже говорил, мы старались максимально упростить работу с инструментом, чтобы разработчик мог там что-то описать, просто мысля в терминах метаданных, – изменить какие-то объекты, добавить реквизит, добавить табличную часть и т.д.
На текущий момент у нас написано 84 правила (84 скрипта). Это уже достаточно большая кодовая база.

Здесь на слайде приведен пример функций программного интерфейса, которыми пользуется разработчик:
-
ИзменитьСвойствоОбъектаМетаданных;
-
ПолучитьСвойствоОбъектаМетаданных;
-
ДобавитьЭлементФормы;
-
УдалитьЭлементФормы.
Принцип, я думаю, понятен.

Разберем одну из этих функций.
Как на практике происходит программная модификация объекта метаданных?
-
Мы пишем «ИзменитьСвойствоОбъектаМетаданных()»;
-
В качестве первого параметра передаем полное имя изменяемого объекта – это у нас определяемый тип ВладелецФайлов;
-
Далее указываем, какое свойство этого объекта мы хотим изменить, и какое значение ему присвоить.
Получается, что, выполнив такую строку кода, мы расширим состав определяемого типа – точно так же, как если бы мы зашли в определяемый тип в конфигураторе и поставили там галочку.
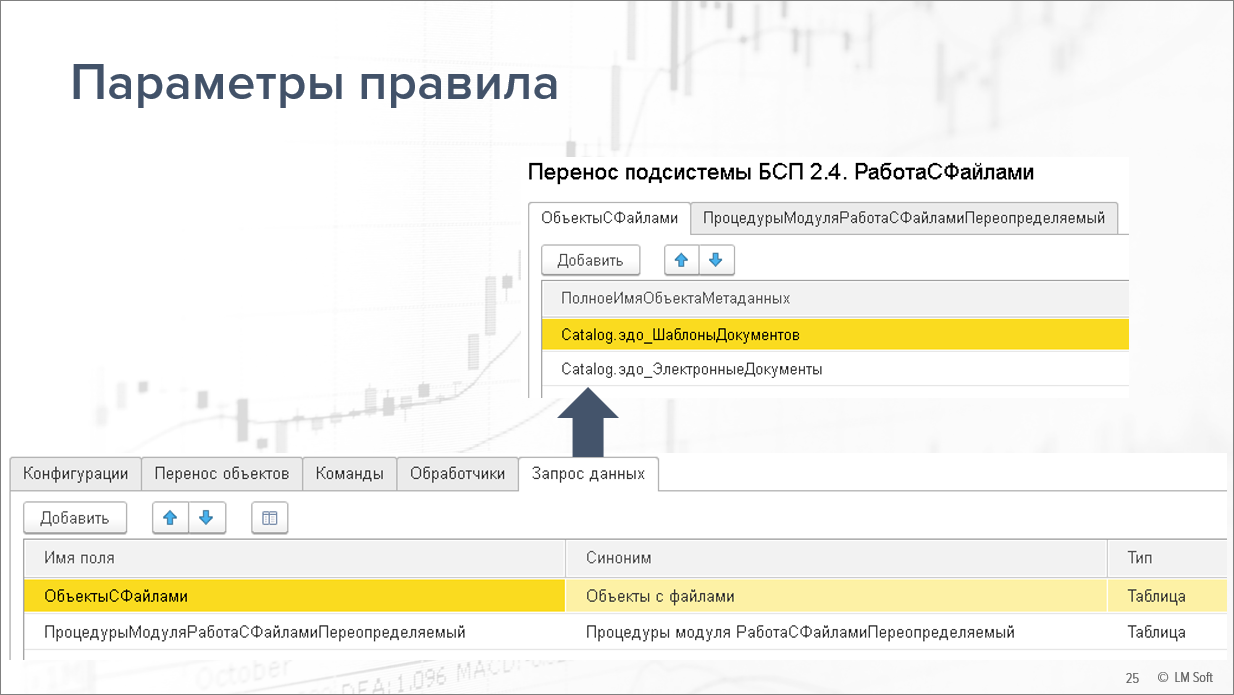
Расскажу про возможность параметризации правила. Что это значит?
Я уже рассказывал про пример нашей MDM-системы, где мы генерировали справочники, у каждого из которых свой реквизитный состав. Для генерации каждого такого справочника использовались:
-
Одно и то же правило;
-
Один и тот же алгоритм, по которому все должно задаваться;
-
Но в этот алгоритм нужно было как-то передать данные – с каким именем, с каким атрибутным составом, с какими свойствами мы должны создать справочник.
Соответственно, у правила есть возможность задать некие параметры, которые потом при настройке сценария можно будет заполнить, и дальше, при выполнении сборки они будут передаваться на вход правила.
На слайде можно увидеть пример настройки такого правила и то, как при настройке сценария в него передаются значения параметров.
Версионирование правил при помощи Git
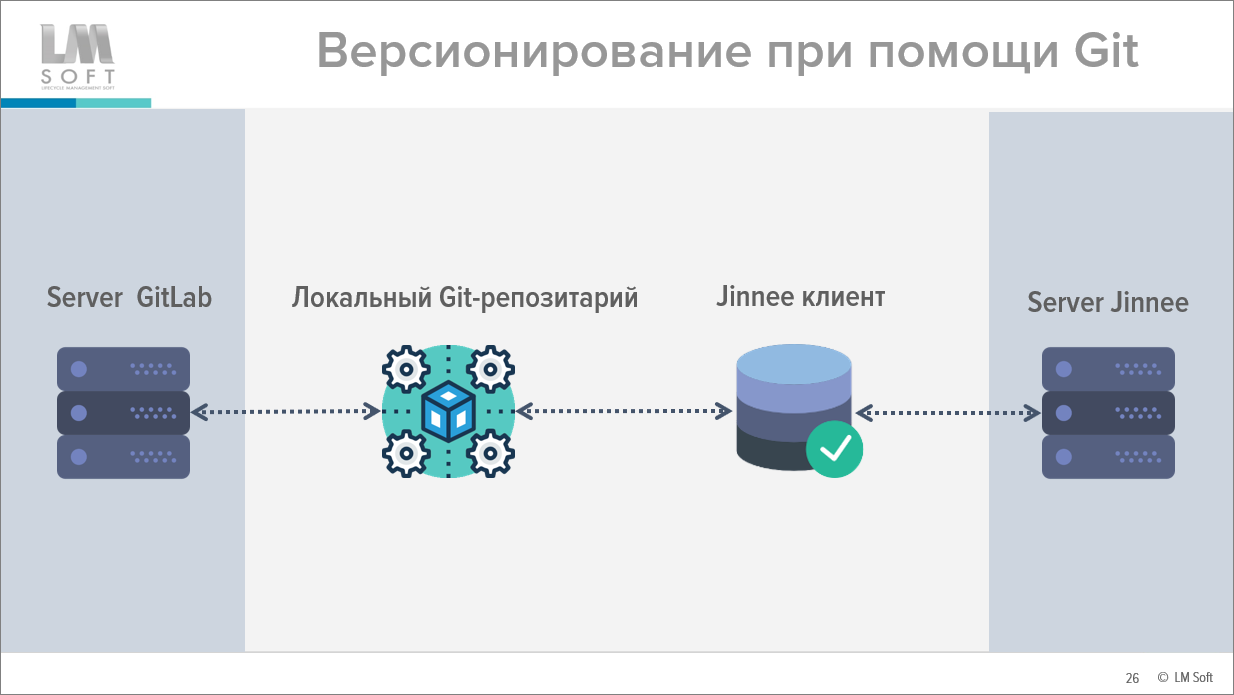
Расскажу про версионирование. Почему у нас вообще возникла необходимость версионирования?
Дело в том, что, как я уже говорил, мы начали писать правила, их со временем стало больше, и мы поняли, что эта генерация – это замена одной проблемы на другую. Раньше у нас были тысячи строк, которые нужно было писать вручную, а сейчас нам нужно написать сотни строк, которые за нас напишут эту тысячу строк.
Когда у нас появились эти сотни строк, оказалось, что их нужно как-то контролировать, потому что это такой же код, как и код в конфигураторе – он точно так же требует проведения CodeReview, его точно так же нужно версионировать. Поэтому общая архитектура выглядит так, как показано на слайде.
-
У нас есть некая серверная часть – база, где хранятся общие данные,
-
И есть клиентская часть – именно клиент является средой разработки правила.
-
Но само правило в базе вообще не хранится, оно хранится в XML-файле под версионированием Git. Самая ближайшая аналогия – это EDT.
В результате получается, что правила хранятся вместе с основным кодом и версионируются тоже вместе с основным кодом, и точно так же отправляются на CodeReview. Примерно такая архитектура у нас сейчас реализована.
Проблемы и их решения

Чтобы начать этим пользоваться, нужно было все это пережить и разрулить проблемы. У нас это получилось не сразу. Расскажу про самые интересные проблемы, с которыми мы столкнулись.
Первое – это проблема ссылочной целостности. Когда вы забираете в вашу конфигурацию какую-то подсистему из БСП, вы не задумываетесь о том, что ваши объекты метаданных имеют ссылки друг на друга, потому что, когда вы их переносите, конфигуратор эти проблемы автоматически решает – он удаляет ссылки на несуществующие объекты, если такие есть. Но в случае, если мы сами манипулируем XML-файлом, никто за нас этого не сделает. Поэтому, когда мы пытались загрузить нашу конфигурацию из XML-файлов, то получали вот такую простыню ошибок.
Мы решили эту проблему, просто добавив в программный интерфейс специальные функции для очистки ссылок.

Вторая проблема – это проблема повторной генерации идентификаторов. Дело в том, что все объекты метаданных имеют внутренние идентификаторы. При создании объектов копированием мы специально заменяем внутренние идентификаторы, чтобы они не дублировались. Но при следующей сборке у этих объектов опять генерятся новые идентификаторы, и получается, что если мы обновимся таким CF-ником, то можем потерять данные, потому что идентификаторы объектов изменились.
Для этого мы в нашем инструменте реализовали механизм, который сохраняет уже сгенерированные идентификаторы. Это решило проблему.

Третья важная проблема – это кастомизация. Представьте, что вы сгенерировали какую-то конфигурацию, а потом решили внести изменения в ваш сгенерированный код. Если вы выполните перегенерацию, эти изменения у вас опять затрутся.
Для этой проблемы нет общего решения, но можно попробовать разные способы. Например, в случае с нашей MDM-системой у нас возникал вопрос, как кастомизировать формы – мы решили его с помощью программной модификации форм. Кроме этого, можно было воспользоваться расширениями и т.д. То есть, эти вопросы решаемы.
Роль кодогенератора в решении архитектурных проблем

Тут стоит задуматься вот о чем. Если вы решили пойти по пути модульной разработки, когда у вас есть подсистемы, которые собираются и изменяются с помощью какого-то инструмента, вы должны решить ряд архитектурных проблем, ответить себе на вопрос: «Как мне проектировать мои механизмы, чтобы они были отчуждаемые, встраиваемые и т.д.?»
И сейчас на следующем слайде мы увидим ответ, как наш кодогенератор решает эти архитектурные проблемы.

Никак он их не решает. Что вы хотели? Но это, наверное, и хорошо. Иначе, зачем мы были бы нужны?
Этим я просто хочу подчеркнуть, что необходимость грамотного проектирования никуда не делась. Скорее, наоборот, она встает еще более остро.
Заключение

И еще один архитектурный антипаттерн, который тоже нужно учитывать – называется «Золотой молоток». Это – когда разработчик освоил какую-то крутую технологию, и она ему настолько сильно понравилась, что он начинает ее использовать везде. Даже там, где это нецелесообразно. Поэтому помните, что любая технология имеет границы применимости и подходить к её использованию нужно с позиции здравого смысла и экономической целесообразности.
Два слова о том, как мы видим дальнейшее развитие инструмента. Во-первых, это реализовать поддержку формата EDT. Интересно было бы научит Jinnee парсить код на языке 1С и формировать AST-tree (хотя у нас большой потребности в этом не было, но это могло бы открыть новые интересные возможности). Есть много идей по развитию внутреннего инструментария, а также хочется попробовать реализовать конвертацию моделей в jinnee-сценарии, т.е. приблизится к разработке через моделирование.

Ну и напоследок, приведу реальную цитату с Инфостарта, которую прочитал в одном из обсуждений. Оказалось что идея подобного инструмента была не только у нас:

Данная статья написана по итогам доклада, прочитанного на конференции INFOSTART EVENT 2018 EDUCATION.

Вступайте в нашу телеграмм-группу Инфостарт