Введение
Те, кто следит за развитием проекта Vanessa Automation, могли заметить, что в релизе 1.2.030 появились изменения в feature-файлах, связанные с задачей "Адаптация feature-файлов проекта VA для использования в StoryMapper". В своём большинстве эти изменения такого вида:
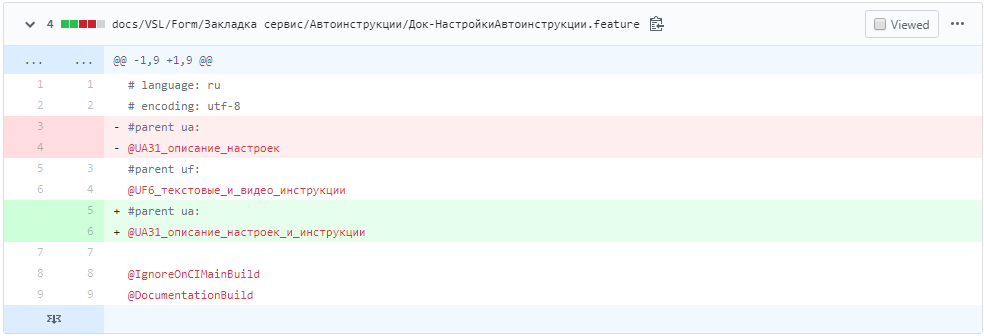
Закономерный вопрос: что это за теги и зачем они нужны?
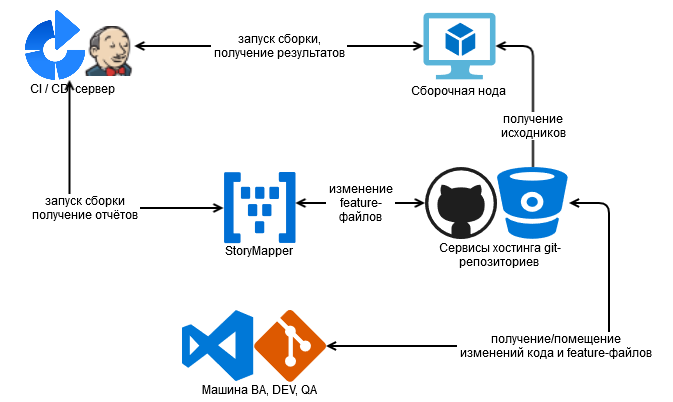
В наших предыдущих статьях ([1], [2]) упоминался StoryMapper - инструмент для организации feature-файлов в виде карты пользовательских историй. В статье [2] он использовался для организации разработки по методике BDDSM, в [1] предлагалось использовать его для упорядочивания своего репозитория feature-файлов. В этой статье мы хотим продемонстрировать, как можно использовать StoryMapper для упорядочивания ваших фич, так чтобы их было удобно и наглядно демонстрировать вашему руководству или стейкхолдерам.
По согласованию с @Pr-Mex (aka Леонид Паутов) мы решили провести такое упорядочивание на примере очень большой коллекции feature-файлов (порядка 700) из ветки develop репозитория Vanessa Automation. Цель данного действия: визуализировать и тем самым повысить прозрачность и понимание того, как работает Vanessa Automation. На сегодняшний день feature-файлы VA распределены по тематическим папкам, но их распределение носит отражение технического подхода к их написанию (регрессионное тестирование), а не точки зрения пользователя или возможного нового контрибьютора. Составление карты историй позволит поменять перспективу рассмотрения feature-файлов и взглянуть на них под пользовательским углом.
Собственно, отвечая на вышезаданный закономерный вопрос: теги в feature-файлах - это способ их структурирования для отражения на карте пользовательских историй в StoryMapper.
Выбор UF
Первый этап упорядочивания - это составление скелета карты пользовательских историй. Скелет в StoryMapper состоит из двух уровней: UF (Usage Flow) и UA (User acivity). Верхний уровень - это некие крупные блоки пользовательской активности, которые мы ожидаем от продукта. В случае VA и её feature-файлов нужно понимать, что не все фичи относятся к пользовательской активности по своей техногенной сущности, соответственно и UF будут не всегда о пользователях.
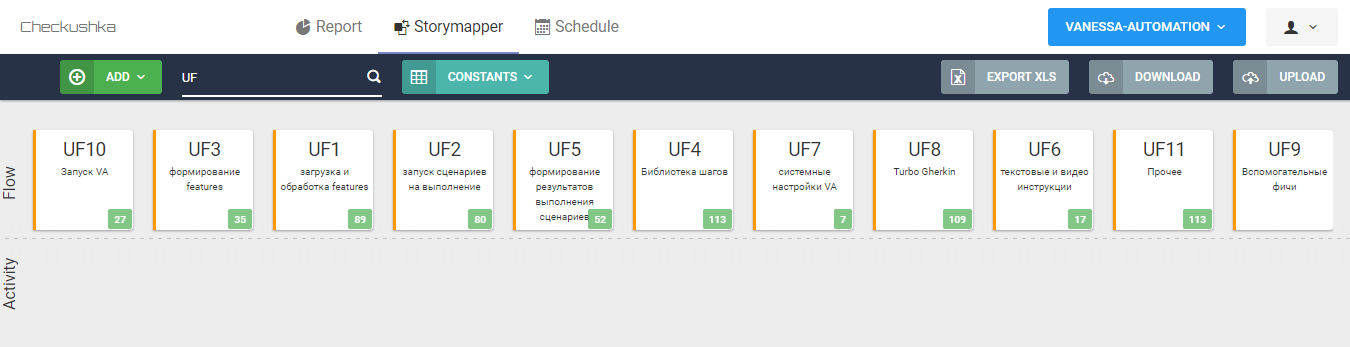
Итак, мы выделили ряд UF, которые описывают пользовательский опыт взаимодействия с VA, другие, в которых будут содержаться фичи с библиотечными шагами и с особенностями реализации Gherkin, вспомогательные технические фичи, которые в VA используются как макеты данных для учётных задач (данные для тестирования), и отдельный UF для (пока) неклассифицированных фич.
Напомню, что в самом начале процесса все фичи репозитория будут лежать в первой колонке под UF0 - поскольку они ещё ни к чему не привязаны.
Составление UA
Второй уровень составить было сложнее. Поскольку разработка VA шла не от карты пользовательских историй, а по пути инкрементного наращивания функционала, нельзя было просто взять и составить список пользовательских активностей. Поэтому мы восстанавливали UA обратным ходом - от US. Когда под UF0 находилась очередная фича, про которую было понятно к какой UF она относится, но под этой UF не было подходящей UA - тогда подходящая UA создавалась.

То, что не получалось никак классифицировать, то уносилось под "UF11 Прочее", чтобы потом можно было разобраться более тщательно. Понятно, что сразу получались какие-то избыточные сущности и при повторном проходе что-то сливалось, что-то удалялось. Но в итоге удалось получить картинку более-менее соответствующую реальной пользовательской активности. На картинке поместились далеко не все UA, полную версию можно посмотреть в StoryMapper (доступы в конце статьи).
Разнесение фич под UA
Из предыдущего раздела уже понятно, что UA формировались по ходу разнесения фич. Основная цель, которую мы преследовали на первом этапе - это сделать так, чтобы под UF0 не осталось ни одной фичи. Чтобы все они стали классифицированными, а уж потом можно переподчинять их согласно реальному предназначению. То есть к текущей версии карты пользовательских историй я пришёл за 4 итерации упорядочивания. Во-первых, вынес все фичи из-под UF0, во-вторых, отделил реальные фичи от служебных, которые используются как макеты, в-третьих, пересмотрел подчинённость фич пользовательским активностям, и в-четвёртых, получил результаты выполнения сценариев и, соответственно, увидев те фичи, которые реально выполняются на CI-контуре, убрал вспомогательные фичи с экспортными сценариями в "UF11 Прочее".

Конечно, не обошлось без трудностей. Надо понимать, что StoryMapper работая с feature-файлами, ориентирован не на название файла, а на название фичи, то есть тот текст, который идёт после ключевого слова "Функционал/Функция". Поскольку за уникальностью этого значение в репозитории никто не следил (а за неимением соответствующего инструментария это делать достаточно проблематично) получались ситуации, когда фича вроде бы уносилась из-под UF0, но после отправки изменений в git - возвращалась обратно. В результате пришлось провести работу по унификации названий фич, что на текущем этапе вылилось в добавление цифр в конце названия. В дальнейшем нужно будет либо слить эти фичи в одну, либо дать им более осмысленное название.
Отображение результатов выполнения сценариев
Что ещё интересного есть в StoryMapper, кроме карты пользовательских историй. Цифры в правом нижнем углу показывают количество выполненных сценариев. Поскольку в VA всё фичи зелёные (а разве бывает по-другому?) - то и на карте мы видим только цифры на зелёном фоне. Если бы сценарии падали, или у них были бы не реализованные шаги - то эти цифры также отобразились бы на карте на красном или сиреневом фоне соответственно. Данные о результатах выполнения сценариев берутся из json-файла c результатами выполнения в формате Cucumber. Сопоставление идёт по названию фич и сценариев.
Также в StoryMapper можно увидеть и результаты выполнения сценариев в формате Allure (без необходимости ходить на CI-сервер, либо публиковать результаты каким-то иным образом), что позволяет исследовать результаты выполнения до шагов, а также анализировать скрин-шоты в случае падения того или иного сценария.
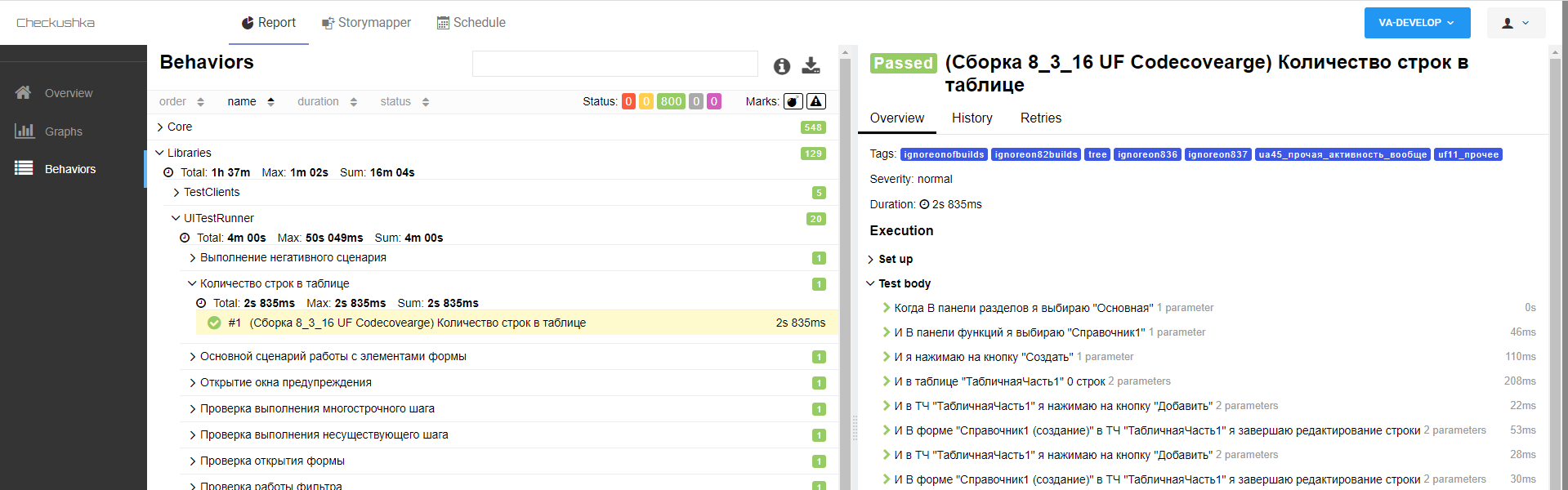
Отправка результатов сборок формата Cucumber и Allure в Storymapper осуществляется POST-запросом. На сейчас я взял у Леонида json-файлы после очередной сборки и отправил их вручную. Если к инструменту будет проявлен интерес, и им будут пользоваться на постоянной основе, то можно будет вставить запрос по отправке результатов в сборочную линию VA и результаты выполнения сценариев в StoryMapper будут актуализироваться автоматически.
Также в StoryMapper есть полезная функция по выгрузке результата упорядочивания в Excel, выстраивающая табличную иерархию UF->UA->US->Сценарий.
Доступы к StoryMapper
Все манипуляции с feature-файлами происходили в моём форке VA, после очередной итерации я создавал pull-request, разрешал конфликты, VACIbot запускал автотесты - и после удачного прохождения тестов изменения по фичам попадали в ветку develop основного репозитория VA. Ветка develop основного репозитория также подключена к StoryMapper, но в режиме "только чтение". Всем желающим посмотреть на фичи VA под другим углом - добро пожаловать:
URL: https://app.checkushka.com/storymapper/VAdevelop/
login: VA_user
password: BDDSM2020