











Продолжение тут: //infostart.ru/public/1234475/
и вот тут: //infostart.ru/public/1264771/
Начну с описания проблем, которые стали для меня критическими при использовании веб-сервисов на базе 1С:Предприятия и что в конечном итоге заставило меня отказаться от 1С и забыть ее как страшный сон.
Для начала я рассматриваю ситуацию с непосредственным подключением через веб-сервис как на картинке ниже:
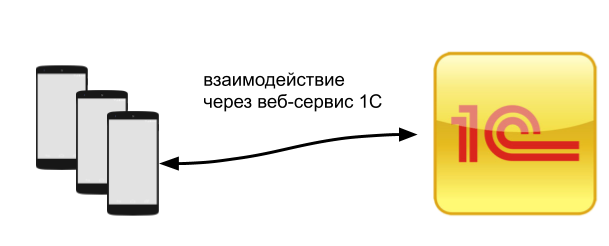
Проблема №1 Время реакции веб-сервиса
Пресловутая проблема первого обращения к сервису когда грузится сеанс и это подвешивает приложение на фронте. Это можно делать асинхронно, но это далеко не всегда устраивает – не все можно делать асинхронно. На больших конфигурациях и базах ситуация первого запуска настолько печальная что Андроид говорит «а не закрыть ли ваше приложение оно вроде немого сломалось». Человек не привыкший к 1С возможно даже успеет снести это приложение и найти другое в маркете пока сеанс грузится.
Некоторой помощью в этом является т.н. переиспользование сеансов – т.е. удержание сеансов через токены в заголовках запросов и увеличенное время жизни, но это порождает другую проблему – большое количество висящих соединений с веб сервисом и по каким то причинам зависшие «мертвые сеансы»
Также или еще хуже дела обстоят и с OData. В описании 1С так и говорится – первый раз нужно подождать. Я добавил в SimpleUI работу с OData но работать с ним можно если ваши пользователи готовы немного подождать.
Проблема №2 Высоконагруженный веб-сервер
Я не берусь ничего утверждать и не могу привести конкретные цифры но на практике при около 300 ТСД подключенных к 1С через HTTP сервис начинают доставлять некоторые неудобства в виде подвисающих и отваливающихся запросов. Могу предположить что если на сервис 1С повесить тот уровень нагрузки котрый рассчитан на то, что в мире разработки (уточню, не 1С-разаработки) называется «высоконагруженный веб-сервис» , то это закончится лавинообразным падением запросов.
Проблема №3 «Данные наружу»
Никто не хочет выставлять свою 1Ску и сервер на котором она стоит во внешний интернет. Тут начинаются всякие решения от VPNов до промежуточной базы (опять же на 1С).
Проблема №4 Доступность 24/7
Это проблема возникает если мобильные приложения вешают к основной базе где периодически требуется регл обслуживание или например изменение конфигурации данных которое в 1С почему то делается монопольно
Проблема №5 Производительность запросов к данным и масштабирование
На самом деле эту причину наверное надо было ставить на 1-е место, просто она не всегда актуальна. В некоторых случаях запросики простые – положить что то в табличку или взять из нее, а в табличках пару тысяч записей. И это просто не критично. Но есть задачи в которых это критично. Пример – WMS. Проблема возникает тогда, когда надо быстро посчитать итоги по табличкам в которых записей побольше - миллионы. На тему как раскочегарить 1С чтобы она работала чуть быстрее написано немало трактатов и есть даже специально обученные люди, которые занимаются не автоматизацией собственно бизнес-процессов а делают так, чтобы эта автоматизация не тормозила уж очень сильно. И для создателей например WMS-систем этот вопрос стоит очень остро. Настолько остро что они придумывают различные интересные архитектурные решения, например расчет и выдачу заданий распараллеленным способом в нескольких потоках. Ну и много чего еще. Какую часть времени разработчик тратит аспекты, связанные с производительностью? 1С это конструктор, на котором можно было быстро разрабатывать автоматизацию с простым языком программирования без ООП и типизации… Так вроде задумывалось? Но если решение проблем занимает больше времени чем сама разработка, может нужно эту ситуацию изменить?
А теперь главный вопрос: возможно ли предположить (в порядке бреда) что запрос в 2-х звенной системе (клиент-SQL сервер) на чистом SQLе выполнится быстрее чем такой же запрос в 3-х звенной системе (клиент-сервер бизнес-логики с интерпретатором-SQL сервер)? Как так получается что в облачных WMS элементарный поиск по штрихкоду в базе с 500 тыс. штрих-кодов выполняется за считанные мс, а чтобы 1C показала такой же результат нужно дорогостоящее оборудование и специальный человек который это оптимизирует.
Я занимаюсь 1С с 2002 года, с тех времен когда еще встречалась 7.5, но в основном была 7.7 и мы для регистрации чеков на кассе не испытывали судьбу (задержка кассы могла обернуться проблемами, бизнесмены тогда были суровыми), а просто писали их в SQL таблицу через ADO, а потом читали. Прошло 18 лет, 1С выпустила 8.3 и конфигурации которые весят Гигабайты, а я не могу придумать ничего лучше для решения проблем сейчас.
Я еще вернусь к проблеме производительности в разделе «Тестирование»
Путь к решению
Итак, что я должен был сделать чтобы решить все эти проблемы? Из Проблемы №5 вытекает что я должен использовать реляционную СУБД как промежуточное звено между фронтом и 1С. Но в чистом виде это вещь в себе, для того чтобы к ней цеплялись и клиенты и 1С нужно какое то API. SQL сервера сами по себе имеют API в виде драйверов ODBC и 1C может цепляться через них. А клиенты? А если эта база в облаке?

Вообще решения по бекендам для мобильных приложений на текущий момент такие (имеется ввиду если не использовать 1С):
- Собственно, взять и написать свой бекенд, т.е. свой сервер с каким то API. Если вы не фуллстек разработчик то придётся привлекать бекендщика который это сделает. Отсюда вытекает минус: бекенд пишется под конкретное решение/внедрение и его нужно поддерживать. Со временем это превращается в т.н. легайси, специалисты которые это писали уходят на другие проекты и знания теряются. Их надо добывать по новой. Но учитывая какая карусель со стеками технологий происходит в последнее время, скорее всего в нагрузку придется изучать «старый» стек технологий. Да, да в мире за пределами 1С творятся страшные вещи.
- Облачные бекенды от Гугл, Майкрософт, Амазон и менее известные например Backedless. Вроде бы плати деньги каждый месяц и наслаждайся готовым решением. Но нет и тут есть проблемы. Вкратце они такие:
- Они почему-то No-SQL т.е. нереляционные субд. Видимо считается что так проще для разработчика но во-первых множество вещей типа агрегатных функций в NoSQL базе сделать нельзя, во вторых вместо стандартного SQL нужно изучать местный стек технологий и вроде бы это и просто но есть нюансы
- Ты не хозяин сервера и от тебя ничего не зависит. Однажды одна из вышеперечисленных компаний решила сменить версию своего решения допустим с 4 на 5 в результате, многое из того что было сделано в решении перестало работать, требовалось разобраться в новых доках и пились новую интеграцию. А да, и сделали они это с 1 января)) С утра мне стали поступать письма пользователей. Но коммент)
- Не смотря на то что это вроде как технологические гиганты подобные облачные сервисы выглядят настолько сырыми что вызывают недоумение. Косяки и неочевидные решения, ради которых надо сидеть на формах и перечитывать кучу доков. Да и функционал убогий.
- Собственно сторонний OData либо RESTful API для различных SQL-серверов т.е. решение которое прицепляет к SQL серверу API которое сделали уже за Вас, нужно только поставить и пользоваться. Сочетаний много есть такие, которые работают с разными серверами. Например DreamFactory. Ничего не могу сказать про него потому что он платный и довольно недешевый. Но это почти то что нужно.
Решение
Пришло время раскрыть карты. Формула решения всех проблем – это перенос высоконагруженных операций в отдельный SQL на том же сервере или в облаке, а для связи использовать REST API со стороны фронта(клиентов) и тотже REST API либо ODBC со стороны 1С. Либо можно посадить на брокер сообщений типа RabbitMQ но со стороны 1С не так уж это важно.
И это очень, очень просто! Все гораздо проще чем можно себе представить. Потому что есть PostgREST . Именно так пишется. Смысл: это бесплатный опенсорс REST API для Postgre SQL который организует веб интерфейс для CRUD и некоторых других операций для вашего PostgreSQL. Точнее таких API два – есть еще pREST (они говорят что они лучшие, а PostgREST -… ну вы поняли).

Таким образом мы имеем: бесплатную современную СУБД PostgreSQL 12, бесплатный открытый веб сервер к ней PostgREST через который можно простыми запросами хоть даже в браузере просматривать, создавать, удалять и т.д. Но ведь эта штука еще и ставится на Линукс! А это значит что можно арендовать VPS сервер за пару евро в месяц, поставить туда PostgreSQL c PostgREST и мы получим облако которое будет работать 24/7! И еще которое можно легко масштабировать по производительности – поменять конфигурацию на вирт. сервере при необходимости.
Таким образом у вас в облаке организуется сервер который может делать такие вещи:
- Запросы на запись, обновление (upsert) в том числе в Bulk-режиме (POST). 5000 записей принимаются и сохраняются за 50 мс
- Различные запросы на выборку данных из таблиц и views (GET). Самый простой запрос аналог запроса Select * from goods выглядит так: /goods далее при необходимости к строке прибавляются условия, упорядочивание и т.д.
- Выполнять хранимые процедуры и функции
- Работать с бинарными данными. Это актуально для мультимедиа и больших документов.
- Удаления
- Работает через JSON но может выгружать и в дргом формате, через текст с разделителями. Это настраивается в заголовках
Т.е. организации бекенда нужно зайти в БД через pgAdmin, создать таблицы, вьюшки при необходимости остальные элементы. Дать права и все – дальше можно взаимодействовать с базой через веб-сервис. Примерно тоже самое нужно сделать в люом другом варианте бекенда, в т.ч. на 1С.
Вот инструкция как поставить и как начать пользоваться: http://postgrest.org/en/v6.0/tutorials/tut0.html
Я сам ставил это и на виндовс и на CentOS 7. В инструкции для линукс я не использовал Докер. Больше всего времени я потратил на то чтобы подключить pgAdmin к базе на VPS сервере точнее сделать так чтобы к самому Postgre можно было цепляться извне. Ну я не линуксоид, вообще профан в этих делах, а так как проект экспериментальный все делал своими силами. Остальное проще.
Связь с 1С
Если PostgreSQL доступен через драйвера ODBC то можно подключаться через них. Хорошей возможностью является использование Внешних источников данных. С ними потом легко стоить отчеты СКД.
Ну и конечно 1С может работать через REST интерфейс. Т.е. точно через то же API что и клиенты.
Вот пример отправки товаров через HTTP - запрос:
АдресТерминала =Константы.АдресБекенда.Получить();
Соединение = Новый HTTPСоединение(АдресТерминала);
Заголовки = Новый Соответствие();
Заголовки.Вставить("Content-Type","application/json");
Заголовки.Вставить("Prefer","resolution=merge-duplicates");
Запрос = Новый HTTPЗапрос("/goods", Заголовки);
З = Новый Запрос;
З.Текст = "ВЫБРАТЬ
| ШтрихКоды.Штрихкод КАК Штрихкод,
| ШтрихКоды.Владелец.Наименование КАК Наименование,
| ШтрихКоды.Владелец.Артикул КАК Артикул
|ИЗ
| РегистрСведений.ШтрихКоды КАК ШтрихКоды" ;
ТаблицаДанных = З.Выполнить().Выгрузить();
CтpoкaJSON = "[";
Для каждого строкаТаблицы из ТаблицаДанных Цикл
CтpoкaJSON = CтpoкaJSON+?(СтрДлина(CтpoкaJSON)>1,",","")+"{"+"""name"":"+""""+СокрЛП(строкаТаблицы.Наименование)+""""+","+"""article"":"+""""+СокрЛП(строкаТаблицы.Артикул)+""""+","+"""barcode"":"+""""+СокрЛП(строкаТаблицы.Штрихкод)+""""+"}";
КонецЦикла;
CтpoкaJSON =CтpoкaJSON+ "]";
Запрос.УстановитьТелоИзСтроки( CтpoкaJSON,КодировкаТекста.UTF8);
Ответ = Соединение.ОтправитьДляОбработки(Запрос).ПолучитьТелоКакСтроку();
А вот пример отчета на СКД и модуль его заполнения:
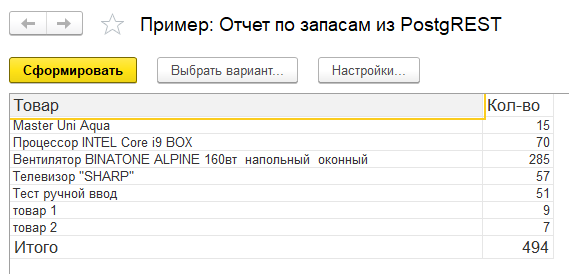
Процедура ПриКомпоновкеРезультата(ДокументРезультат, ДанныеРасшифровки, СтандартнаяОбработка)
СтандартнаяОбработка = Ложь;
Настройки = КомпоновщикНастроек.ПолучитьНастройки();
ДанныеРасшифровки = Новый ДанныеРасшифровкиКомпоновкиДанных;
КомпоновщикМакета = Новый КомпоновщикМакетаКомпоновкиДанных;
СхемаКомпоновкиДанных = ПолучитьМакет("ОсновнаяСхемаКомпоновкиДанных");
МакетКомпоновки = КомпоновщикМакета.Выполнить(СхемаКомпоновкиДанных,
Настройки, ДанныеРасшифровки);
ВнешниеДанные.Очистить();
АдресТерминала = Константы.АдресБекенда.Получить();
Соединение = Новый HTTPСоединение(АдресТерминала,3000,,,,,);
Заголовки = Новый Соответствие();
Заголовки.Вставить("Content-Type","application/json");
Запрос = Новый HTTPЗапрос("/bal");
Результат = Соединение.Получить(Запрос);
СтрокаJSON = Результат.ПолучитьТелоКакСтроку();
Чтение = Новый ЧтениеJSON;
Чтение.УстановитьСтроку(СтрокаJSON);
Данные = ПрочитатьJSON(Чтение, Ложь);
Если типЗнч(Данные) = Тип("Структура") Тогда
НовСтр = ВнешниеДанные.Добавить();
ЗаполнитьЗначенияСвойств(НовСтр,Данные);
ИначеЕсли типЗнч(Данные) = Тип("Массив") Тогда
для каждого стр из Данные Цикл
НовСтр = ВнешниеДанные.Добавить();
ЗаполнитьЗначенияСвойств(НовСтр,стр);
КонецЦикла;
КонецЕсли;
Чтение.Закрыть();
ПроцессорКомпоновки = Новый ПроцессорКомпоновкиДанных;
ПроцессорКомпоновки.Инициализировать(МакетКомпоновки,
Новый Структура("ВнешниеДанные", ВнешниеДанные.Выгрузить()),
ДанныеРасшифровки);
ДокументРезультат.Очистить();
ПроцессорВывода = Новый ПроцессорВыводаРезультатаКомпоновкиДанныхВТабличныйДокумент;
ПроцессорВывода.УстановитьДокумент(ДокументРезультат);
ПроцессорВывода.Вывести(ПроцессорКомпоновки);
КонецПроцедуры
Тест производительности
Для экспериментов я нашел в сети самый слабый вариант какой только смог найти: VPS за 45р/мес: 1 проц Athlon, 1Гб ОЗУ, 5 ГБ HDD (не SSD) на CentOS. И сравнивал с 1С файловый вариант на i5 ,SSD, 16ГБ ОЗУ, Windows.

Методика у меня конечно примитивная, но некоторые выводы можно сделать. Для проведения сравнительных тестов я встроил в SimpleUI возможность измерять время исполнения команд. Так, я помещаю на экран определенную группу команд и выполняю и в 1С и в бекенде. Потом сравниваю результат. На экраны я поместил следующие команды:
- Поиск по штрихкоду – 1 штрихкод
- Вывод списка номенклатуры в таблицу
- Запись в базу (или в бекенд) 1й операции
Примерно так выглядят результаты теста, теперь их можно организовывать самим – возможности для этого есть:

Еще я не создавал индексы в Postgre, а в 1С они есть.
Вот такие получились результаты:
Сначала я провел тест при заполненности таблицы товаров в р-не 20 строк:
1С: 1-й запрос – 330 мс, запросы после первого запроса – 19-20 мс в среднем
Postgre: 1-й запрос - 38 мс, последующие запросы – 32 мс
Т.е. сервис 1С может работать быстро, если его раскочегарить. Но давайте проверим что будет на реальном справочнике:
Я добавил 5000 товаров в обе базы, кстати это заняло у меня:
- 150,34с в 1С (в режиме транзакции)
- 1,05с в Postgre (в Bulk режиме)
И после этого я снова замерил результаты:
1С: 1-й запрос – 480 мс, запросы после первого запроса – 230 мс в среднем
Postgre: 1-й запрос - 40 мс, последующие запросы – 33 мс
Вывод который я сделал: Postgre проглотил справочник и не заметил, разница в обработке запросов на уровне погрешности. 1С - заметно погрустнел. К слову сказать это очень маленький справочник по сравнению с тем, с чем приходится сталкиваться.
Связь с Simple UI и новые фишки
Я развиваю собственную платформу-конструктор мобильных приложений - Simple UI. Конечно же я пустился на поиски замены 1С не от хорошей жизни и очень рад что нашел Postgre. Сложно переоценить важность этого инструмента для моих проектов. Теперь легко можно собрать себе свой бесплатный бекенд в максимально упрощенном режиме, прицепить к нему бесплатные клиенты на Simple UI и полноценная система готова.
Пока все возможности работают в режиме беты, они не прошли полноценную проверку в рабочих проектах. Я только начал осваивать это направление. Сервис которым можно поиграться пропишется в настройках приложения при обновлении, авторизации для запросов там нет.
В Simple UI я добавил возможности для CRUD- операций и выполнения процедур:
Вот так например выглядит запрос типа Select..Where:
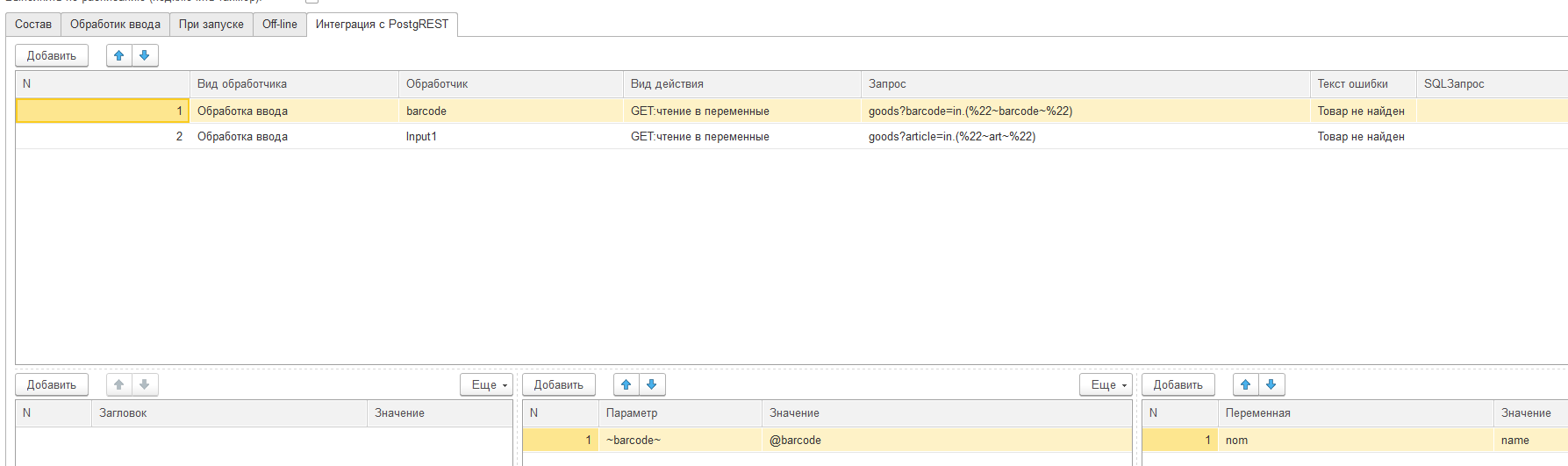
А вот так запрос на добавление строки в таблицу:

И конечно же теперь на своем сервере можно организовать свой облачный магазин приложений. Магазин не в смысле продавать за деньги – а просто место, куда можно выкладывать конфигурации, чтобы на клиентах их скачивать/обновлять. Конфигурация в Simple UI – это XML-строка. Вот так выглядит отправка конфигурации из 1С:

А вот так сам магазин в приложении:

Кстати, теперь можно не скачивая демо базу проверить работу с оборудованием – одна из конфигураций позволяет в off-line режиме (не через бекенд) протестировать работу оборудования штрихкодов и распознавания текста (которое тоже кстати улучшено в последнем релизе).
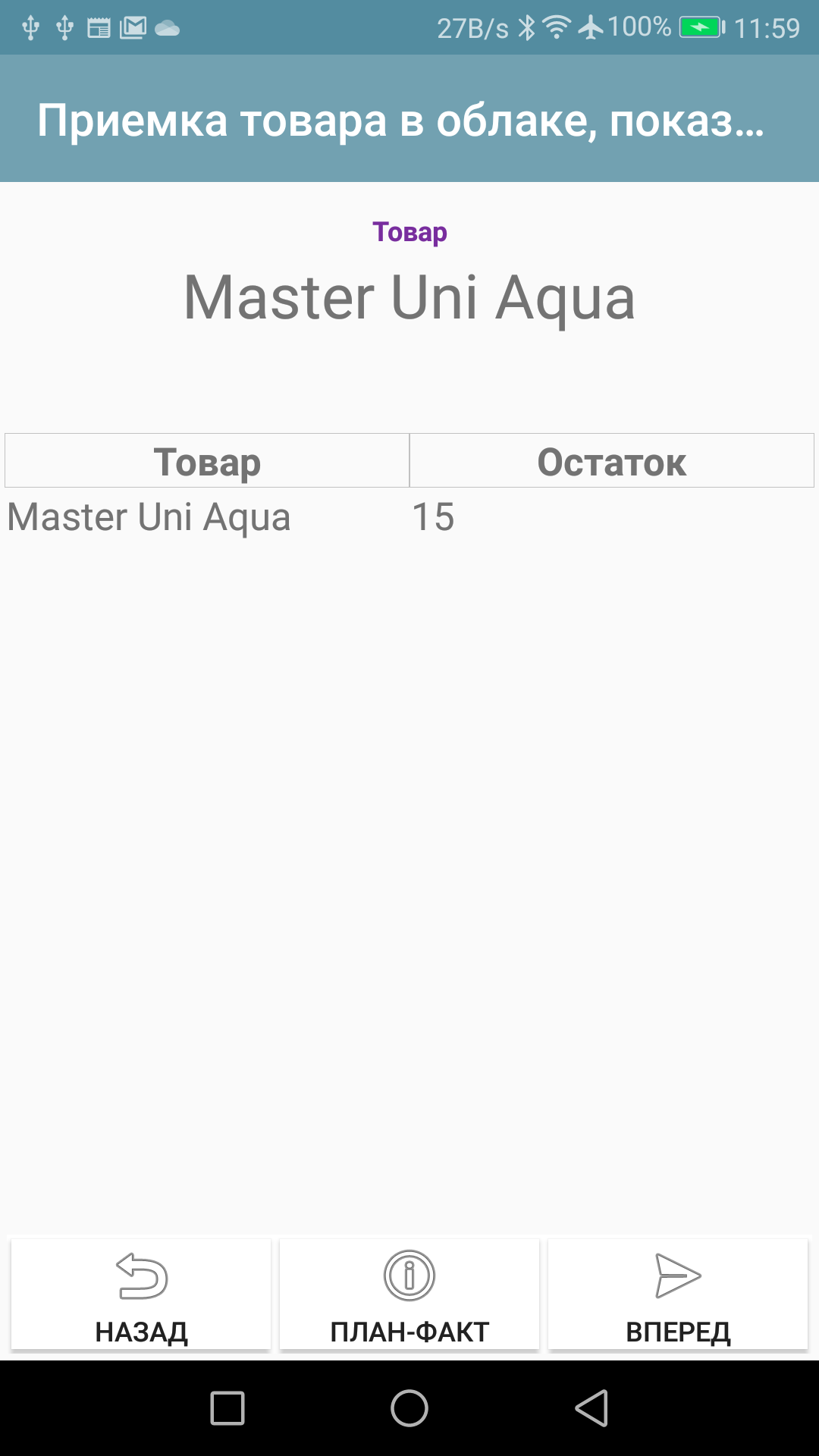
Ну и коротко, что можно посмотреть в тестовой конфе для работы с бекендом, которую тоже можно скачать из магазина без скачивания базы 1С: показан пример где можно ввести в справочник в бекенде свою номенклатуру. Потом, в проекте есть процесс, в котором имитируется приемка: сканируется либо вводится артикул номенклатуры, она идентифицируется, показываются текущие остатки, вводится количество которое отправляется в облако и, соотвественно меняет остаток. Это можно увидеть в приложении, можно в 1С. Можно отправить/получить данные из 1С. Основная статья, где демо база, доки и остальное тут: //infostart.ru/public/1153616/
Для Pro-версии доступны также дополнительные возможности:
Можно отсылать и получать данные в фоновом потоке (не UI-потоке приложения) – т.е. если надо скачать или закачать большой объем данных программа будет выполняться без торможения. При этом само приложение может взаимодействовать чисто с собственным SQL полностью автономно (без связи) и при необходимости обмениваться с бекендом в фоне.
Кроме того, можно назначить процессы, которые будут выполняться при запуске конфигурации. Для этого в конфигурации есть реквизит в котром можно указать экран, в котором в свою очередь перечислены команды,сам экран не будет выполняться – только команды.
Вступайте в нашу телеграмм-группу Инфостарт

{kind=link}